
Abstract
ɛ-insensitive loss function is often employed in the twin support vector regression (TSVR). However, it can not effectively address the data with Gaussian noise. Huber loss function can suppress a variety of noise and outliers and yields great generalization performance. Motivated by this, we propose a novel twin support vector regression with Huber loss for the noise data in this paper. Experiments on nine benchmark datasets with different Gaussian noise show the validity of our proposed algorithm. Finally, we apply our method to the financial time series data that usually contain noise and outlier, and it also produces great performance.
Introduction
Support vector machine (SVM) [1, 2], motivated by Vapnik and co-worker, is a promising method in machine learning. It is related to the neural networks. The neural networks as the intelligent method with the excellent approximation ability have been widely used in many fields ranging from state time-delay [3], multiple-input multiple-output (MIMO) nonlinear systems [4, 5], adaptive control for a class of uncertain nonlinear stochastic systems [6], non-linear second-order multi-agent systems [7] to uncertain nonlinear strict-feedback systems with full-state constraints [8]. Although neural networks has been used widely, SVM has many advantages compared with neural networks. First, SVM has super learning ability and it can better solve the practical problem of small number of samples, nonlinear and high dimension. Second, SVM implements the structural risk minimization principle rather than the empirical risk minimization principle. SVM has been successfully applied in various aspects ranging from remote sensing image classification [9], text classification [10] to business prediction [11].
Although SVM owns better generalization classification ability compared with other machine learning methods, it has high computational complexity. The computational complexity of the SVM is o (l3), where l is the total size of training data. In order to improve the computational speed, Jayadeva, Khemchandani and Chandra [12] proposed a twin support vector machine (TSVM) for binary classification data in spirit of the proximal SVM in 2007 [13–15]. Then, many variants of TSVM have been proposed in literatures [16, 17]. The formulation of TSVM is very similar to the classical SVM except it aims at generating two nonparallel hyper-planes in order that each hyperplane is close to one class and as far from the other class. The strategy of solving two small sized quadratic programming problems (QPPs) instead of a single large one makes the learning speed of TSVM approximately four times faster than the standard SVM. In 2009, Peng [18] proposed a twin support vector regression (TSVR) for the regression problems. TSVR is the extension of TSVM. It aims at generating two functions such that each one determines the ɛ-insensitive down- or up-bound of the unknown regressor. To achieve it, TSVR solves two smaller sized QPPs instead of a larger one as in the usual SVR, this makes the TSVR work faster than the standard SVR.
SVR was proposed by Vapnik and his team work in 1995 [19, 20]. It adopts ɛ-insensitive loss function and has good generalization capability in some applications. However it is difficult to deal with the Gaussian noise data. Therefore, Wu [21, 22] constructedν-SVR with Gaussian distribution. If the noise obeys the Gaussian distribution, it yields good generalization performance. However, Gaussian loss function has its shortages, then Wu constructed ν-SVR with Huber loss function [23] and showed the advantages of using Huber loss function instead of ɛ-insensitive loss function and Gaussian loss function. They are all about the convex loss function, and we will discuss the corresponding non-convex loss function in the following part. A general framework for non-parallel classifier was given by Mehrkanoon [24]. It concluded that different loss functions perform well for different problem. Their models illustrated hinge loss, pinball loss, least squares loss but not Huber loss. Wang [25] extended quadratic insensitive loss function and got flexible loss function. Experiments showed the validity of proposed model, but it did not concern financial time series dataset. Then Wang [26] proposed a robust support vector regression based on a generalized non-convex loss function which combined two differentiable Huber functions. Experiments on nine benchmark datasets with noise and financial time series dataset showed the effectiveness of non-convex Huber loss.
Motivated by the studies above, we propose a novel twin support vector regression with Huber loss. The effectiveness of our proposed algorithm is demonstrated by numerical experiments on one artificial dataset and nine benchmark datasets with Gaussian noise. Finally, we apply our method to financial time series dataset, and it also produces great performance.
The paper is organized as follows: Loss function is described in Section 2. In Section 3, we describe TSVR with different loss functions including general loss function, ɛ-insensitive loss function and Gaussian loss function. TSVR with Huber loss function is proposed in Section 4. In Section 5, numerical experiments are conducted on one artificial dataset, nine benchmark datasets with Gaussian noise and financial time series dataset to demonstrate the validity of our proposed algorithm. We conclude the paper in Section 6.
Loss function
The loss function has significant effect on the performance of SVR [21, 27]. For the training sample D l , the regression function is unknown. The general method is to minimize objective function:
A set of training samples are generated by a function plus additive noise
Substituting P [f] and Equation (3) into Equation (4), we can see that maximizing the posterior probability of f is equivalent to minimizing the following function
The function is the same as Equation (1). By Equations (1) and (5), the optimal loss function in maximum likelihood estimation is
The probability distribution function is
We assume that noise obeys Gaussian distribution with zero mean and variance σ2. Then the probability distribution function is
Thus, using Equation (6), the loss function is
However, in real-world applications, the standard Gaussian density model N (0, 1) is commonly used to describe noise. Therefore, if the noise obeys Gaussian distribution, we can get the following form,
Thus, using Equation (6), the loss function of Gaussian is
Considering the above discussion and in order to make up for the inadequacy of Gaussian loss function with noise model, we can get the Huber loss function:
The Huber loss function is divided into three parts: |ξ| ≤ μ, that is μ dead zone, don’t penalty the deviation which is less than μ, make learning sparse. μ < |ξ| ≤ μ
ɛ
, which uses the Gaussian loss function |ξ| > μ
ɛ
, which uses the Laplace loss function ɛ (|ξ| - μ), and it can suppress some high noise and outliers effectively.
Thus, the Huber loss function is the combination of the Gaussian loss function and the Laplace loss function, and it has better performance than the Gaussian loss function.
For the convenience of analysis, the Huber loss function can be written as
The illustration of three loss functions are shown in Fig. 1.
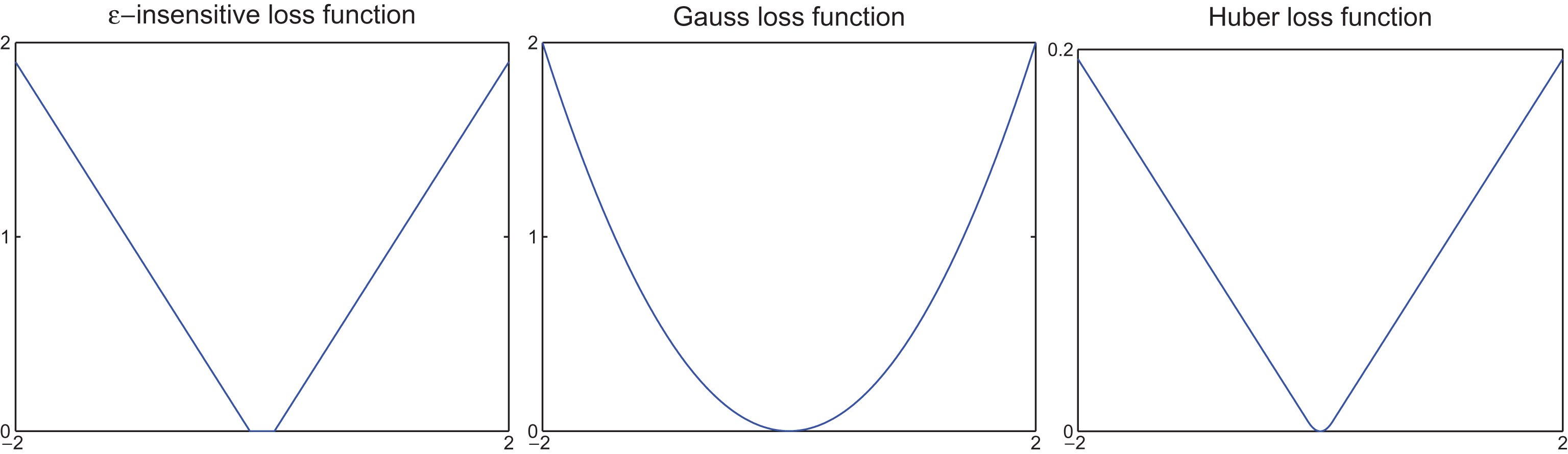
The illustrations of three different loss functions.
TSVR with general loss function
Given sample D
l
, we construct linear regression function f (x) = w
T
x + b. In the nonlinear case, we map the input vector x
i
∈ R
l
into the high dimension feature space with nonlinear mapping. Φ : R
l
→ H (H is Hibert space). In this case, the inner product of input vector (x
i
· x) in feature space is replaced with H (Φ (x
i
) · Φ (x
j
)). By using kernel function K (·), linear model can be extended to the nonlinear case.
First, we conduct uniform TSVR for the different loss functions. We solve the problem based on the general loss function c (ξ) and c (η). Training sample can be written as A = (A1 ; A2 ; . . . ; A n ), where A i = (Ai1, Ai2, . . . , A in ). TSVR mainly achieves the following two functions:
The primal problems of general loss function based TSVR are described as
When the loss functions c (ξ
i
) = ξ
i
, c (η
i
) = η
i
, the dual problems of TSVR are
GN-TSVR model for the Gaussian model, Suykens [28], Wu and Law [21, 22] studied the equality and inequality constraints of SVR, respectively. The Gaussian loss functions
It is assumed that the noise obeys standard Gaussian density model. But if the noise obeys Gaussian noise with N (0, σ2), the loss function are
As we mentioned previously, in real-word applications, the standard Gaussian density model N (0, 1) is commonly used to describe noise. Hence, if no special instructions, GN-TSVR we mentioned uses Equations (21) and (22) in the following experiments.
Noticing that it is difficult to deal with the Gaussian noise data with ɛ-insensitive loss function. Thus, Gaussian loss function was proposed. To make further improvements, Huber loss function was proposed based on Gaussian loss function. Combining Equation (14) with TSVR, a novel HN-TSVR is proposed in this section.
HN-TSVR [23, 29–31] for the Huber model, the Huber loss functions are
Similarly,
The primal problems of HN-TSVR are
and
We can derive the dual formulations of HN-TSVR as follows,
We only derive Equation (27) since Equation (28) is similar to Equation (27). Firstly, we introduce the Lagrange function as
According to KKT conditions, we have
Then we get
Where
Substituting the above KKT conditions into (29), we derive the corresponding dual problem of Equation (25) is
The following illustrations clarify that Equation (33) is equivalent to Equation (27). Equation (33) can be replaced as
For Equation (34), we introduce the following Lagrange function
According to KKT conditions, there are multiplier γ, δ, let
Due to f = Y - eɛ1, we can transform Equation (36) into
Let
Put
To demonstrate the validity of the proposed TSVR with Huber loss function, we compared it with TSVR and TSVR with Gaussian loss function on a collection of datasets, including artificial datasets, nine benchmark datasets with Gaussian noise and financial time series dataset.
The performance of these algorithms depend on the collection of parameters. In our experiments, we set
MAE: Mean absolute error, which is defined as
RMSE: Root mean squared error, which is defined as
SSE/SST: Ratio between sum squared error
SSR/SST: Ratio between interpretable sum squared deviation
In most cases, small SSE/SST means good agreement between estimations and real values, and to obtain smaller SSE/SST usually accompanies an increase of SSR/SST. However, the extremely small value of SSE/SST is in fact not good, for it probably means overfitting of the regressor. Therefore, a good estimator should strike balance between SSE/SST and SSR/SST.
In this section, we use Gaussian kernel function to evaluate TSVR, GN-TSVR and HN-TSVR.
It is well known that the performances of algorithms depend on the choice of parameters. The optimal values of the parameters were determined by applying five-fold cross validation [32, 34]. The optimal parameter C in each algorithm was searched from set {2
i
|i = -3, - 2, - 1, 0, ⋯ , 8}. The optimal parameter ɛ1, ɛ2 was chosen from set
Artificial datasets
The regressions of sinc function
In order to avoid of biased comparisons, we randomly generated ten independent groups of noisy samples which respectively consists of 150 training samples and 150 test samples. The test data are uniformly sampled from the objective sinc function without any noise. The comparisons of experimental results are summarized in Table 1.
Performance comparisons of three algorithms on Sinc with Gaussian noise
From Table 1, we can find that the HN-TSVR yields lightly lower regression error compared with TSVR and GN-TSVR. When the noise obeys N (0, 1), we find that the GN-TSVR is better than TSVR. However, when the noise obeys N (0, 0 . 152), we find that the performance of TSVR is better than GN-TSVR. In Section 3.3, GN-TSVR uses Equations (21) and (22). However, according to the experimental results, when the noise obeys N (0, 0 . 152), if we use Equations (21) and (22), the performance of TSVR is better than GN-TSVR. Thus, according to the discussion of Section 3.3, if the noise obeys N (0, d2), we should fix σ = d and then GN-TSVR can get the best performance. Now for GN-TSVR we use the Equations (23) and (24) which noise obeys N (0, 0 . 152), that is to say, we fix the σ = 0.15 in Equations (23) and (24). We want to compare TSVR, changed GN-TSVR and HN-TSVR, then we get Table 2.
Performance comparisons of TSVR, changed GN-TSVR and HN-TSVR on Sinc dataset with Gaussian noise
We can get changed GN-TSVR is better than TSVR, but HN-TSVR still obtains the smallest MAE and RMSE among three algorithms for two types of Gaussian noise.
From Tables 1 and 2, we can find that GN-TSVR, HN-TSVR are better than TSVR on the artificial datasets. Besides, HN-TSVR is better than GN-TSVR. And for different noise model, HN-TSVR has universality.
For the following experiments, we mainly discuss the case of noise data with variance one for the reason that the standard Gaussian density model N (0, 1) is commonly used to describe noise in real-world applications.
Curve sinc and fitting curves obtained by TSVR, GN-TSVR, HN-TSVR are illustrated in Fig. 2.

Curve sinc and fitting curves obtained by TSVR, GN-TSVR, HN-TSVR.
In this section, we use Chwirut, Cons, Bodyfat, Diabetes, Auto Mpg, Ozone, Pyrim, Triazines, Wisconsin Breast Cancer (Wis. BC) from the UCI machine learning repository 1 to test TSVR, GN-TSVR and HN-TSVR. We evaluate three algorithms by four estimation criteria: RMSE, MAE, SSE/SST, SSR/SST. The comparisons of experimental results are summarized in Table 3.
Performance comparisons of three algorithms on benchmark datasets with Gaussian kernel function
Performance comparisons of three algorithms on benchmark datasets with Gaussian kernel function
From Table 3 we can discover that TSVR yields better performance than GN-TSVR and HN-TSVR for most cases. But TSVR does not outperform other two algorithms in all datasets. In order to further evaluate, Table 4 shows the average rank of three algorithms. From it we can get the average rank of TSVR is far lower than GN-TSVR and lightly lower than HN-TSVR. That is to say, it is not suitable to apply algorithms with Gaussian loss and Huber loss to the data with non-Gaussian noise.
Average ranks of TSVR, GN-TSVR, HN-TSVR on MAE values
From above discussion, we know it is not suitable to apply algorithms with Gaussian loss and Huber loss to the benchmark datasets with non-Gaussian noise. Therefore, in this section, we add Gaussian noise to nine benchmark datasets and compare the performance of three models in order to further illustrate that Gaussian noise affects the performance of three models. The validity of our proposed algorithm is also demonstrated using nine benchmark datasets with Gaussian noise.
For the nine benchmark datasets, we divide each datasets into training samples and test samples. Every training samples with Gaussian noise, and every test training samples with no noise. The comparisons of TSVR, GN-TSVR,HN-TSVR on benchmark datasets with Gaussian noise are summarized in Table 5. In error items, the first item denotes the mean value of five times testing results, and the second item stands for plus or minus the standard deviation.
Performance comparisons of three algorithms on benchmark datasets with Gaussian noise
Performance comparisons of three algorithms on benchmark datasets with Gaussian noise
Table 5 shows the testing results of our proposed HN-TSVR, TSVR and GN-TSVR on nine benchmark datasets with Gaussian noise. We compare estimation criteria and we can see that except that MAE of TSVR on Chwirut, Ozone, Wis. BC are far lower than that of GN-TSVR and lightly lower than HN-TSVR, all the other testing errors of HN-TSVR are lower than TSVR and GN-TSVR. Otherwise, MAE of TSVR are far lower than that of GN-TSVR and lightly lower than HN-TSVR on above six datasets with no Gaussian noise. That is to say, HN-TSVR is better than TSVR and GN-TSVR for most datasets. Meanwhile we can see that our proposed HN-TSVR does not outperform other two algorithms on all datasets. Therefore, in order to further evaluate three algorithms, the average ranks are shown in Table 6, from it we can find that the average rank of HN-TSVR is lower than that of TSVR and GN-TSVR. It implies that our proposed HN-TSVR is better than other two algorithms.
Average ranks of TSVR, GN-TSVR, HN-TSVR on MAE values
In order to further check the validity of our proposed HN-TSVR, the financial time series dataset is analyzed in this section. The data of financial time series is random, which is usually high noisy and contains strong nonlinearity and outliers. And for Shanghai Stock Exchange Composite Index (SSECI) 2 , it has strong randomness since there are many influence factors. It is assumed that the influence factors of the closing price are decided by the day before the opening price (yuan), the closing price (yuan), the highest price (yuan), the lowest price (yuan), trading volume (share), volume of business (yuan). We also employ five-fold cross validation to evaluate the performance of algorithms. That is to say, the dataset is split randomly into five subsets, and one of those sets is reserved as a test set; this process is repeated five times. The comparisons of TSVR, GN-TSVR, HN-TSVR on financial time series dataset are summarized in Table 7.
Performance comparisons of three algorithms on financial time series dataset
Performance comparisons of three algorithms on financial time series dataset
From Table 7, we can get only for SSECI-2013 in the near six years SSECI we selected, TSVR is better than GN-TSVR and HN-TSVR. However, for other datasets, it has been seen that our HN-TSVR obviously outperforms other two models. To further evaluate three algorithms, the average ranks are shown in Table 8.
Average ranks of TSVR, GN-TSVR, HN-TSVR on MAE values
From Table 8 we can find that the average rank of HN-TSVR is far lower than that of TSVR and is lightly lower than that of GN-TSVR. That implies that our proposed HN-TSVR is better than other two algorithms. It further testifies that our HN-TSVR obtains the best performance among three models.
In this paper, a novel twin support vector regression with Huber loss is proposed for Gaussian noise data. We first derive TSVR with different loss functions. Specially, we mainly deduce the TSVR with Huber loss. Finally, the HN-TSVR yields lower prediction error compared with TSVR and GN-TSVR. Experiments with different Gaussian noise on one artificial datasets and nine benchmark datasets show the validity of our proposed algorithm. And then we apply our algorithm to the financial time series data, the experimental results show that our proposed HN-TSVR far outperforms TSVR and lightly outperforms GN-TSVR. In general, we can draw the conclusion that HN-TSVR has better generalization performance when dealing with the Gaussian noise data.
Footnotes
Acknowledgments
The authors gratefully acknowledge the helpful comments and suggestions of the reviewers, which have improved the presentation. This work was supported in part by National Natural Science Foundation of China (No. 11671010, 11271367).