
Abstract
Multi-variety and small batch production is one type of mainstream production methods. Currently, methods of enterprise risk warning have been abundantly researched by scholars, but the effect of its application to the multi-variety and small batch manufacturing practices is not ideal. In this study, the authors apply the transductive support vector machine and active learning to the study of enterprise risk and early warning methods. The experiment utilizes real-world enterprise data and demonstrates that this method may meet the practical needs of the enterprise risk early warning systems and contributes to solving problems of multi-variety and small batch manufacturing operations.
Keywords
Introduction
Due to increasing diversification and development of personalized user needs, significant numbers of manufacturers have shortened product lead times to quickly respond to the diverse needs of users. The production model is transforming. In recent years, multi-variety and small batch production methods began to occupy an increasingly important position in the industry. According to recent statistics from the United States, Japan and other countries, 75% of enterprises consist of both small and medium volumes. Multi-variety and small batch customization production is rapidly becoming the primary production mode, representing more than 90% of the manufacturing industry in China.
Multi-variety and small batch production methods possess the following characteristics: (1) Products are generally customized according to customer needs and include many varieties and specifications that require suppliers to quickly respond to the material needs of enterprises. (2) Complex product structures require a wide variety of processing methods and process parameters that, in turn, require professional skills. (3) Small quantity batches require less annual output of each product. Occasionally, trial runs are included in production outputs. (4) Multi-variety and small batch production modes require high-quality outputs, parallel production, high technical proficiency and production flexibility.
A need exists for effective risk management tools with regards to material purchasing and beginning production processes. Rational planning of purchasing activities may improve product quality and reduce inventory costs. This planning occupies an imperative position for multi-variety and small batch manufacturers. Studies have demonstrated that the cost of purchasing raw materials for manufacturing is between 50% and 80% of the total cost. In addition to these costs, delivery problems are related to problems with suppliers 80% of the time. The multi-variety and small quantities methods require corporate purchasing of small quantities, which makes it difficult to form economies of scale. If a purchase is less than supplier requirements for mass production, it may be difficult to establish cooperative relationships with suppliers. This barrier, along with numerous invoices for materials, different varieties of inputs and emergency deliveries, leads to an increased risk of delay in delivery of purchase orders, which often occurs. Based on expert knowledge and experience, numerous companies utilize a risk stratification approach for suppliers or material bills. However, this method may not achieve significant results and is difficult to implement and promote.
Early warning systems of multi-variety and small batch enterprises must respond to certain relevant particularities of data: sparse data, sequence correlation, unlabeled samples, high labeling cost, dynamic laws and the necessity of expert knowledge. In this study, we combine an active learning (AL) algorithm and a semi-supervised learning algorithm transductive support vector machine (TSVM) to study the relationship between risk and the use of early warning systems for multi-variety and small quantities manufacturing operations. This experiment utilizes enterprise purchasing data and demonstrates that this method may meet the practical needs of enterprise risk early warning systems. This study contributes to the field of early warning; we introduce the more applicable calculation method for concurrently utilizing data, models and expert knowledge. Semi-supervised learning and AL are new research fields. These two tools have been commonly used to process synthetic data in the laboratory. These two methods may prove to be valuable for the practice of risk management.
The remainder of this paper is organized as follows: Section 2 reviews related studies, introduces the active learning transductive support vector machine (ALTSVM), and analyzes specific issues related to risk early warning systems for both multi-variety and small batch procurement. Section 3 reports the process, results and validity of this empirical research. Section 4 concludes this article.
Active learning transductive support vector machine
Related work
Scholars have conducted numerous studies related to risk and early warning methods. According to research methods, current studies may be grouped into three categories: knowledge-driven early warning systems, data-driven early warning systems and model-driven early warning systems. Knowledge-driven early warning systems are most widely used and include expert systems [1, 2], index systems [3, 4] and fuzzy rough sets [5]. Data-driven early warning systems are the most studied type and include time series analysis [6, 7], neural networks [8–11], grey models [12], and geographic information systems [13]. Model-driven early warning systems extend partly from control theory and troubleshooting methods, including the Kalman filter, strong tracking filter, particle filter, kernel principal component analysis and cluster analysis.
A more recent research arena is that of semi-supervised learning. This method considers the use of a small number of labeled samples and a large number of unlabeled samples for classification. Active learning is a special type of semi-supervised learning. Active learning is designed to reduce the cost of labeling samples and improve learning performance. This method often requires the user (for example, experts in the field) to label an unlabeled example or unlabeled subset to acquire knowledge from the user to improve the quality of the model.
Utilization of risk early warning systems involves sample collecting, risk identification and risk evaluation. These spend considerable time and money. In many cases, manpower and material resources are too limited to collect large amounts of labeled data. Considerable amounts of the collected data are incomplete or are in the process of being updated. The theory of active learning suggests that we do not randomly select and label samples, but we instead select and label the samples that contain the most classified information. Marking fewer samples leads to maximum improvement of the classification performance.
Transductive SVM
Transductive SVM (TSVM) is a semi-supervised large-margin classification method based on the low density separation assumption [14]. Similar to traditional SVM, TSVM searches for a hyper-plane with largest margin to identify the classes, and simultaneously takes into account labeled and unlabeled samples.
Set a group of independent and identically distributed labeled samples
and u unlabeled examples
In general, TSVM can be formulated as the following optimization problem:
Training process of the TSVM is to solve the above optimization problem. TSVM training algorithm can be described as follows:
TSVM can give considerable improvement in generalization over SVM, if the number of labeled points is small and the number of unlabeled points is large. Unfortunately, TSVM algorithms (like other semi-supervised approaches) are often unable to deal with a large number of unlabeled examples [15–17]. It also has non-convex quadratic programming problem and presetting N problem[18, 19].
Active learning is a special case of semi-supervised machine learning in which a learning algorithm is able to interactively query the user (or some other information source) to obtain the desired outputs at new data points [20]. Query algorithms are determining which data points should be labeled.
In this section we introduce a semi-supervised learning algorithm newly proposed by Wang (2006), denoted as the active learning transductive support vector machine [21]. This technique may effectively solve the active learning problems inherent in a large amount of unlabeled sample data.
According to [22], the optimization function of TSVM is demonstrated below:
There is an optimization problem of a non-convex hat shape in formula (4), which is difficult to solve. Collobert et al. [17] proposed the concave-convex procedure (CCCP), which decomposes a non-convex function into convex and concave components, and then solves the equation iteratively. Based on [17], the CCCP for TSVM includes the following objective function:
Based on [21], Wang et al., defined L′ as a function of the Laplacian graph to capture the geometrical structure of data. These scholars added a regularization term that penalizes any abrupt changes of the function values to explore the neighbor sample structure. The optimization problem with abrupt penalization is demonstrated below:
The version space minimum-maximum division principle for active learning is applied to identify the most informative example. In [21], Wang et al. selects the unlabeled sample x* that leads to a small value for the objective functi gardless of its assigned class label y*. Based on this theory, the minimum-maximum division framework may be demonstrated as follows:
The optimal decision function f* is found in formula (7) and [21] has demonstrated that formula (4)
Therefore, the value of y i f (x i ) is smaller, the smaller portion is reserved by the hyper-plane of this sample (x i , y i ). As a result, the sample is more appropriate for the training classification model.
The procedure of ALTSVM is displayed in Fig. 1. Three conditions are outlined: C.1 denotes that positive examples and negative examples are not less than one; C.2 denotes that there are no unlabeled examples; C.3 denotes that there are sufficient current labeled examples for a given level of accuracy. The proposed technique is described in the following algorithm:
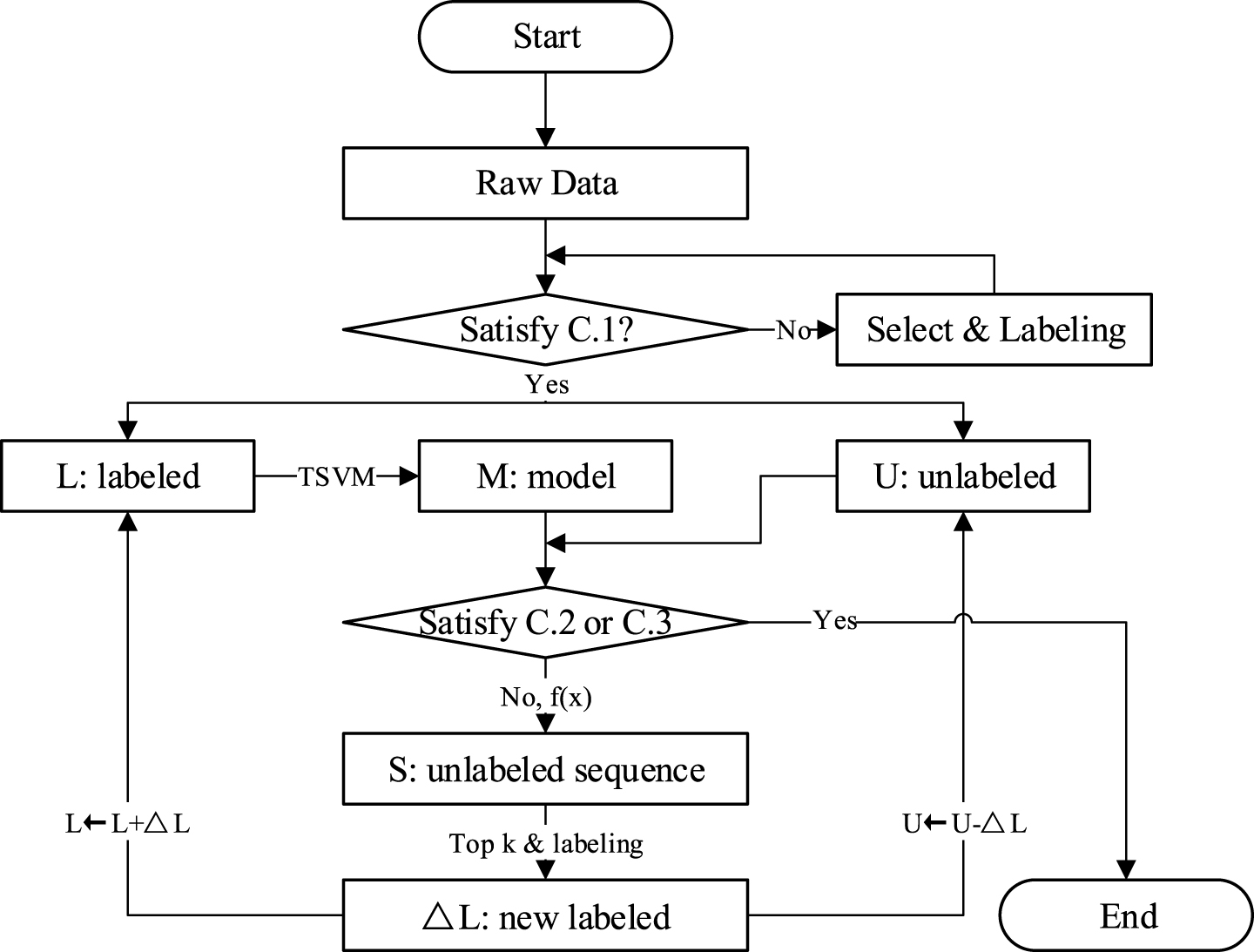
Structure of ALTSVM algorithm.
Specify the parameter C1 and C2. Select several examples from U and label them (positive examples and negative examples are not less than one), and add them to L. Use all labeled examples to build an initial classification model with inductive learning; Calculate the decision function values of all unlabeled examples. Form a sequence S of unlabeled examples, according to the values of f (x
i
) in increasing order; Select an example x
i
with the minimum objective function value to be labeled, while m = 1, 2, …, k do: select the adjacent sample xi+q in the different direction of S, and label it: y
per
= yi+q. Transfer the xi+q from U and S into L. Retrain the TSVM over L, and return f (x). If any unlabeled examples remain, return to 2.
Utilization of the enterprise risk early warning method is more complex than theoretical study. Models utilized in research usually require idealized assumptions and harsh requirements that are insufficient in real world applications. Thus, studies are difficult to apply in practice, and we cannot achieve the desired effect. ALTSVM is proposed for the following difficult situations: Few irrelevant features. Enterprise activities, such as staff number, order amount, equipment amount and sales volume, are highly relevant. The enterprise is complex system. Few irrelevant features exist. TSVM applies aggressive feature selection to manage few irrelevant features according to [22]. High dimensional input space. Due to diverse business and multifarious data form, risk objects become more complex. Input data are required to process as many features (hundreds or thousands) as possible for each risk factor, and features are elements associated with a risk factor. Input vectors are sparse. Risk warning is critical to business operations. The research process should utilize as much data as possible. Due to the increase of data dimensions, “Not Available” and missing values are increased. As a result, input data results in a sparsefeature. TSVM has been proven to be very effective in the field of text recognition. Text recognition generally contains thousands of characteristics for classification with only a few non-zero vectors (occasionally less than 1%) [17]. This indirectly demonstrates that TSVM may effectively manage high dimensional input space and input vectors that are well sparse. Risks are unobservable elements. According to its definition, risk is an uncertainty. Risk not an entity, but rather a concept. Risk may be evaluated, but it cannot be observed. In certain studies of data-driven risk warning, risk occurrence replaces risk as the dependent variable, which may lead to significant bias, as shown in Fig. 2. In this study, we acknowledge that risk is unobservable, so we utilize AL to obtain risk variables. Experts judge the sample identification selected by algorithm and indicate whether it is a risk. AL repeatedly selects the best samples for labeling and training. This leads to a more complete information model at a reduced cost and a faster speed. Exploiting the unlabeled examples problem. Enterprises generally have very large amounts of data for risk warning, but labeled samples may be rare. If only the labeled examples have been studied, a serious shortage of valid data may cause a large deviation in the results. TSVM includes an assumption that labeled and unlabeled samples come from the same population. This method utilizes unlabeled data to optimize the classification surface constituted by labeled data. This method is over-reliant on the scarcely labeled data to constitute the model, and the remaining data are only used for calibration efforts. Consequently, TSVM performs poorly in real-world scenarios. In contrast to TSVM, AL considers scarce labeled data insufficient to build a prediction model and the unknown should be explored for additional information from the remaining data. The use of a certain algorithm identifies the samples that most likely contain additional unidentified information. Next, experts evaluate the most valuable unlabeled samples to achieve the highest possible accuracy while incurring decreased costs. Evolving risk law. Risk rules change over time and for different business situations. Early warning models based on historical data may lag behind real world data needs. If a model does not possess certain characteristics that allow it to adapt to dynamic situations, the enterprise early warning system will generate considerable false positives and false negatives. The AL-based risk early warning model may automatically capture new features contained in the data, and then query the user to identify them. In this manner, the AL-based risk early warning model is an evolutionary model. ALTSVM was own coded and implemented using R and SVM-light. Risk cannot be replaced by risk happened.

Dataset
A domestic manufacturing firm is studied in this section. The company is a fiber optic components manufacturing enterprise including multi-variety and small batch methods. Most products are customized according to customer demand. Certain key components must be purchased from suppliers using design drawings. Component delivery times have a significant impact on the entire production process and product delivery times. This study aims to establish an early warning model for delayed delivery of procured input components. Combining the purchase order data and supplier data, this model attempts to predict delayed customer orders that will allow for measures to be taken to minimize therisk.
The research dataset consists of order and supplier information data. The first dataset includes the purchase order data from 2013 to 2014, with a total of 180,000 samples. Data contain 23 material categories, more than 700 suppliers and 6000 types of materials and components. Table 1 provides the types of data including variables.
Variables of firsthand research dataset
Variables of firsthand research dataset
In this section, we focus on a very specific subset of the first dataset in contrast with naive Bayes (NB), support vector machine (SVM) and TSVM. We select the “thread cutter” data in the category “TOOL”, which contains 150 samples of roughly 24 types of thread cutters from eight suppliers. Expert judgment criterion of a risk order denotes the following: whether the factory date is after the latest planned arrival date. In 150 samples, 118 samples were delivered on time, and the on-time delivery rate was 79%.
Initial labeled samples are designated as 10 labeled samples (five positive samples — on-time delivered orders, five negative samples — delayed orders) and 140 unlabeled samples. In an enterprise risk management practice, preparatory work related to risk assessment by experts is repetitive and costly. Therefore, we first select the most representative 10 samples each time to assess in the application of ALTSVM in the early warning model. Next, we correct the model with a modified dataset and predict the data again. According to this procedure, calibrated samples increase as follows: 10, 20, 30, …, 100.
This study identifies NB, SVM and TSVM as comparative research methods. Utilizing the labeled sample number of 10, 20, …, 100, various methods of forecast accuracy are demonstrated in Fig. 3. Naive Bayes, as a straightforward classification algorithm, requires the assumption of inter-variable independence. Variables of enterprise early warning have great relevance that lead to the failure of NB, in which all samples are forecasted as the same positive class. SVM performs well in solving the problem of small sample size, correlated variables and nonlinear data, but can only use the few labeled data and omit the abundant unlabeled samples. Compared with SVM, TSVM further improves forecast accuracy and is particularly useful when there are a small number of calibrated samples. ALTSVM, due to the use of an active learning process, makes it possible to locate the most beneficial sample to calibrate, which leads to an increased accuracy rate. If we request an 85 percent accuracy rate, ALTSVM requires 30 to 40 labeled samples, TSVM requires 50 to 60 labeled samples, and SVM requires 60 to 70 calibrated samples. Judging from the results of this study, ALTSVM is determined to be valid and highly effective in this case, and it is likely to be extended to the entire dataset.

Forecast accuracy utilizing different numbers of labeled samples.
We attempt to apply the ALTSVM method to the entire dataset of 180,000 samples. The data possesses the following characteristics: thousands of product orders are governed by different rules; the number of samples for each product will vary; custom and standard components make up differing percentages; partial records are incomplete; high dimensional input and data sparsity lead to the inability to conduct a comparative study; manual adjustment is required. Due to the complexity of the sample data, the overall results of the dataset are for reference only.
The overall prediction accuracy of ALTSVM was 83%. For most types of components, the accuracy of the prediction may range from 85% to 100%. However, for certain components the prediction accuracy is less than 70%. Further review of the data indicated that three key factors influenced the accuracy rate of the prediction: (1) component factor: standard or custom, old formed or new designed; (2) supplier factor: qualified supplier or trial supplier; (3) production state: busy period or idle period. ALTSVM for early warning systems may not only predict whether there is a delay in delivery risk, but it may also distinguish the difference of prediction accuracy in different situations. This makes it possible to establish a dynamic components purchasing strategy and supplier management strategy.
Conclusion
In this study, the authors applied active learning to risk early warning methods for multi-variety and small batch manufacturing operations. This study first introduces the difficulties involved in research of multi-variety and small batch production modes. Second, the ALTSVM algorithm, based on active learning and semi-supervised classification, is proposed. The applicability of this algorithm to solve the mentioned problems is analyzed. Third, this method is utilized to analyze procurement data of an optical fiber products manufacturing enterprise. One of the product categories is focus research, and the result of overall data is briefly reported. The study results demonstrate that ALTSVM may solve the problem of classification related to few labeled samples. This method may pay the minimum learning cost with a certain performance demand. This method provides good adaptability to the enterprise risk early warning systems and has great significance for further application in related learning problems.
Conflict of interests
The authors declare that there are no conflicts of interest regarding the publication of this paper.
Footnotes
Acknowledgments
This work was supported by the National Natural Science Foundation of China (Grant Nos. 71501007 & 71332003) and Technical Research Foundation (Z132014A001). The degradation data used in this paper removed classified content, and the authors thank the anonymous enterprise used for this study.