
Abstract
Reasonable structure of human resource is of great significance to development of an organization, so accurate prediction of human resource structure is a very important research problem. Adaptive Neuro-Fuzzy Inference System (abbreviated as ANFIS) is a high-efficiency learning model, and its distributed network structure has very effective result in establishing nonlinear model and constructing time series prediction model. However, classical ANFIS has some disadvantages, such as difficult determination of structure and large randomness of training parameter setting. This paper provides a hybrid prediction model of human resource structure by using the algorithm based on fusion of PSO with random weight, RPSO, and ANFIS, named RPSO-ANFIS. The novel algorithm uses RPSO to train relevant parameters of ANFIS and determine network structure of ANFIS. Empirical results shows that, compared with GA-ANFIS and PSO-ANFIS, RPSO-ANFIS has advantages of rapid learning speed, high prediction accuracy and smaller relative mean error, which indicated RPSO-ANFIS has good practical application value in predicting the structure of human resource.
Keywords
Introduction
Talents in any organization are of complicated structure and hierarchy [1–4]. In a society, a region or an industry and even in an enterprise, talents of different specialties and educational backgrounds constitute a multi-hierarchy complicated system—talents swarm. Task of human resource structure prediction is not only exploring talent structure status within a certain period but also conducting scientific and reasonable prediction of specialty matching and hierarchical structure of needed all kinds of talents in order to form the optimal human resource structure, exert maximum economic benefits of talent cultivation and utility, provide better human resource guarantee for organizational development and promote sound development of the organization. Hence, human resource structure prediction within an organization is of great practical significance and practical values. However, human resource structure is usually of discontinuity and complexity. It’s always difficult for common prediction method (such as neural network, etc) to reach good prediction effects.
Adaptive Neuro-Fuzzy Inference Systems (abbreviated as ANFIS) can solve problems such as high nonlinearity [5], complexity and discontinuity, etc. [6–9], and it also has characteristics of high convergence rate, good stability, repeatable training process, high prediction precision, etc., and it’s especially suitable for handling problems related to time series prediction. Hence, ANFIS has provided a referable scheme for solving the problem of human resource structure prediction [10–12]. However, it’s found in practical application that ANFIS has some deficiencies which have greatly limited further promotion and application of this method and mainly manifested at establishment of its model structure has great difficulties, and randomness of its training parameter setting is large [13, 14].
In recent years, there are some novel computational intelligence algorithms, such as SVM [15–21], minimax probability machine [22], Fireworks Algorithm [23], swarm intelligence [24], and etc. Particle Swarm Optimization (PSO) is a random optimization algorithm based on swarm intelligence which was proposed by Kennedy and Eberhart in 1995, and this algorithm solves optimal solution of specific problem by simulating migrating and gathering behaviors of bird flock during foraging process. In this algorithm, individual behavior is influenced jointly by swarm behaviors and its own historical behaviors. At present, PSO algorithm has been widely applied to fields such as functional optimization, neural network training and fuzzy system control with its good optimization performance [25].
This paper adopted mixed learning method of PSO and least square method to determine parameters of ANFIS structure. This mixed-type method mainly used PSO to train antecedent parameters of ANFIS network model and least square method to train its consequent parameters.
Structure of this paper was arranged like this: Section 2 introduced human resource structure prediction model based on PSO and ANFIS, Section 3 adopted human resource data in recent years of one organization to conduct prediction analysis and compared PSO-ANFIS algorithm with standard ANFIS algorithm; Section 4 gave the conclusion.
Methods
ANFIS
ANFIS is an adative network based fuzzy inference system proposed by Jang on basis of Takagi-Sugeno model (or T-S model, Sugeno model0. Study shows that when membership function which adopts trapezoid or non-triangle is input, the number of fuzzy rules and input fuzzy sets needed by T-S system is small, thus this model is suitable for system modeling based on data collection. ANFIS has realized combination of fuzzy logic inference and neural network, so this structural form has both advantages of the two: the former can easily express human knowledge and the latter has advantages of distributed information storage and learning ability. ANFIS is a significant development of intelligence science and provides new effective method for processing of engineering information.
Common rule sets with two fuzzy if-then rules in ANFIS model:
Rule 1: if x is A1 and y is B1, then
Rule 2: if x is 2 and y is B2, then
Typical ANFIS structure is as shown in Fig. 1, in order to realize learning process of T-S fuzzy model, it’s generally transformed into a self-adaption network, namely ANFIS. This self-adaption network is a multilayer feedforward network, and square nodes in it need to conduct parameter learning. Nodes at the same layer have the same function.

The Structure of ANFIS.
Here output of the jth node at layer i is Oi,j.
The first layer, which is the membership function layer of input variables, is responsible for fuzzification of input signals.
Node i has output function: O1,i = μ A i (x), O1,i = μ B i (y), (i = 1, 2).
Whereby x and y are inputs of Node i, A
i
and B
i
are fuzzy sets, O1,i is membership function value of A
i
and B
i
and represents the degree of x and y belonging to A
i
and B
i
. Shapes of membership degree functions μ
A
i
and μ
B
i
are totally determined by some parameters, and these parameters are called antecedent parameters such as clock-type function:
The second layer, which is the rule strength release layer, is responsible for multiplying input signals.
Output of each node represents credibility of this rule.
The third layer is the normalization layer of all rule strengths. The ith node calculates normalization credibility of the ith rule.
The fourth layer can calculate output of fuzzy rules, each node i at this later is self-adaption node. Output of the ith node is:
Whereby
The fifth layer, which has one fixed node, can calculate total output of all input signals.
When antecedent parameters are given, output of ANFIS can be expressed as linear combination of consequent parameters through the following transformation:
Elements of column vector θ consist consequent parameter set {p1, q1, r1, p2, q2, r2}; least square method can be used to obtain optimal estimation
ANFIS generally adjust antecedent and consequent parameters of the system with mixing algorithm of BP algorithm and least square method. In the mixing algorithm, forward-direction phase calculates to the fourth layer, least square method is then used to identify consequent parameters. Error signals in reverse-direction phase conducts reverse transmission, and BP algorithm is used to update antecedent parameters. During forward-direction learning process of network, input values of N groups of training data are adopted to solve values of p i , q i and r i and the output value O5,i. According to rules of least square method, O5,i values calculate calculated values and originally expected error value of training data, and this error value will be reversely returned and corrects premise parameters according to maximum gradient method. During the process of changing these parameters, modification of membership function graphs is continuously realized, expecting to realize the goal of reaching minimum output error during set cyclic process.
In 1995, American social psychologist-James Kennedy and electrical engineer Russell Eberhart jointly proposed particle swarm algorithm, and its basic idea was enlightened by research results of modeling and simulating bird flock behaviors. Their model and simulation algorithm mainly modified model of Frank Heppner to make particles fly to solution space and land at the best solution.
In a D-dimensional searching space, n particles consist a particle swarm, and each particle is a D-dimensional vector, and its spatial position is expressed as x
i
= (xi1, xi2, …, x
iD
), i = 1, 2, … n. Spatial position of particles is a solution in target optimization problem, adaption value can be calculated by substituting this spatial position into adaption function, and advantages and disadvantages of particles can be measured according to size of adaption value; flying speed of the ith particle is also a D-dimensional vector and recorded as v
i
= (vi1, vi2, …, v
iD
); the position which the ith particle with the best adaption value has gone through is called the best historical value of the individual and it’s recorded as p
i
= (pi1, pi2, …, p
iD
); the best position which the whole particle swarm has gone through is called the best global historical position and it’s recorded as p
g
= (pg1, pg2, …, p
gD
), evolutionary equation of particle swarm can be described as:
Where by: subscript j represents the jth dimension of particle, subscript I represents particle I, t represents the tth generation, c1 and c2 are acceleration constants which are usually within (0,2), r1 ∼ U (0, 1), r2 ∼ U (0, 1) are two mutually independent random functions. It can be seen from above evolutionary equation that c1 is step length which regulates particle to fly to the direction of its best position, and c2 is the step length which regulates particle to fly to global best position.
By analyzing some features of basic particle swarm, it can be known that the first part in Equation (2,1) is previous speed of particle; the second part is “perception” part which represents though of the particle itself; the third part is “social” part which represents social information sharing between particles.
In this paper, RPSO is used to train the structure of ANFIS. In RPSO algorithm, random weight ω is used in the classical PSO.
So, formula 2.1 can be modified as follow,
Each learning process based on chaotic particle swarm learning algorithm includes antecedent parameter learning phase and consequent parameter learning phase, and its learning algorithm flow is:
Flow chart of this algorithm is as shown inFig. 2.
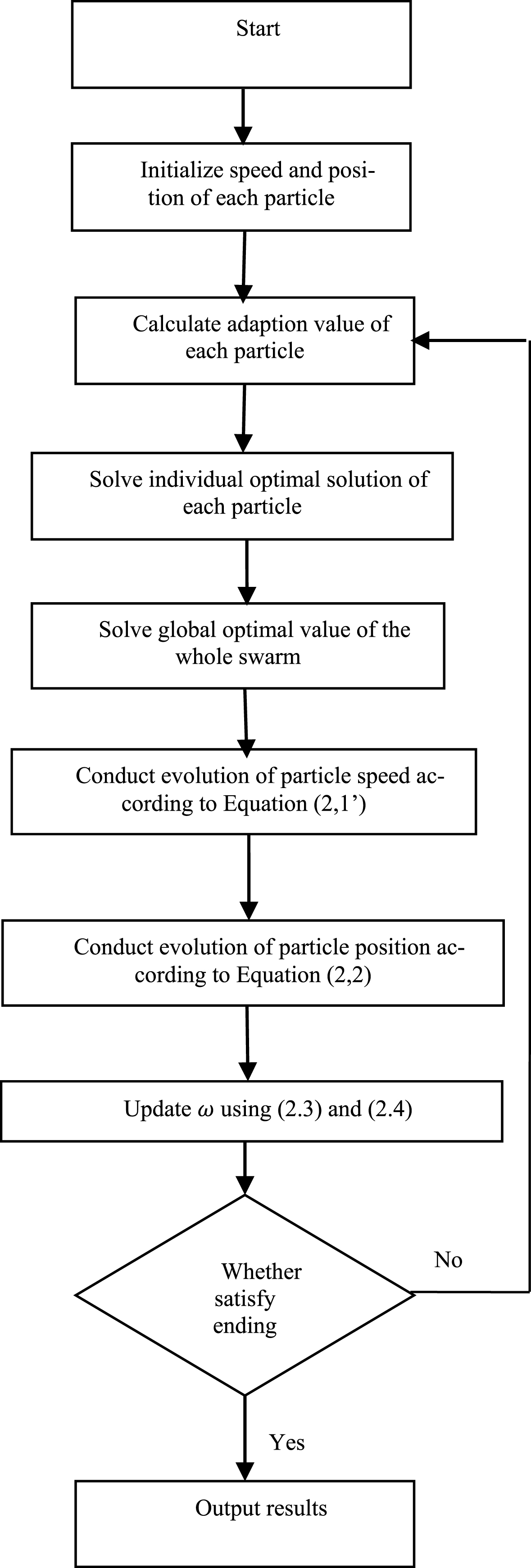
Flow Chart of PSO-ANFIS Algorithm.
Dataset
This paper adopted dataset as shown in Table 1, and this dataset represented human resource conditions of one large-scale company. This table includes 12 groups of data representing human resource conditions in recent 12 years of this company. The algorithm in this paper took gross output, economic benefits and total number of enterprise staff as input data and proportions of management personnel and technical personnel in total number of staff as output data to respectively establish human resource structure prediction model based on RPSO-ANFIS model.
Statistical table of human resources in 12 Years
Statistical table of human resources in 12 Years
Enterprise development relies on its occupation, allocation and usage conditions of human resources (mainly management personnel and technical personnel). Hence, when we predict human resource structure, the main prediction targets are proportions of management personnel and technical personnel. Data in Table 1 is divided into two parts, 10 groups of data are taken as learning and training set of PSO-ANFIS network, and the other 2 are taken as inspection dataset. The operating environment is i5 2.60 GHz CPU, 64-bit Windows7 operating system.
Experiment finds that: training precision reaching 10–5 satisfies expected requirements; Fig. 2 is training error curve of ANFIS network. It can be obviously obtained that: as the network adopts mixing algorithm namely least square method and RPSO algorithm during training process, initialization and learning convergence rate of the network are fast, and the network continuously corrects errors, and finally tend to be stable. The key of ANFIS network prediction is selection of the number of membership functions. After multiple experiments, the prediction effect is the best when 3 membership functions are selected.
In order to verify performance of this algorithm, this paper compared prediction effects of GA-ANFIS, PSO-ANFIS and RPSO on the same dataset. Convergence curves of the two algorithms in predicting proportions of management personnel and technical personnel are respectively as shown in Figs. 3 and 4. It can be found from Figs. 3 and 4 that no matter predicting proportion of management personnel or predicting that of technical personnel, convergence rate of RPSO-ANFIS algorithm is obviously superior to that of GA-ANFIS and RPSO-ANFIS, which process that in this dataset, RPSO-ANFIS model embodies good convergence performance.
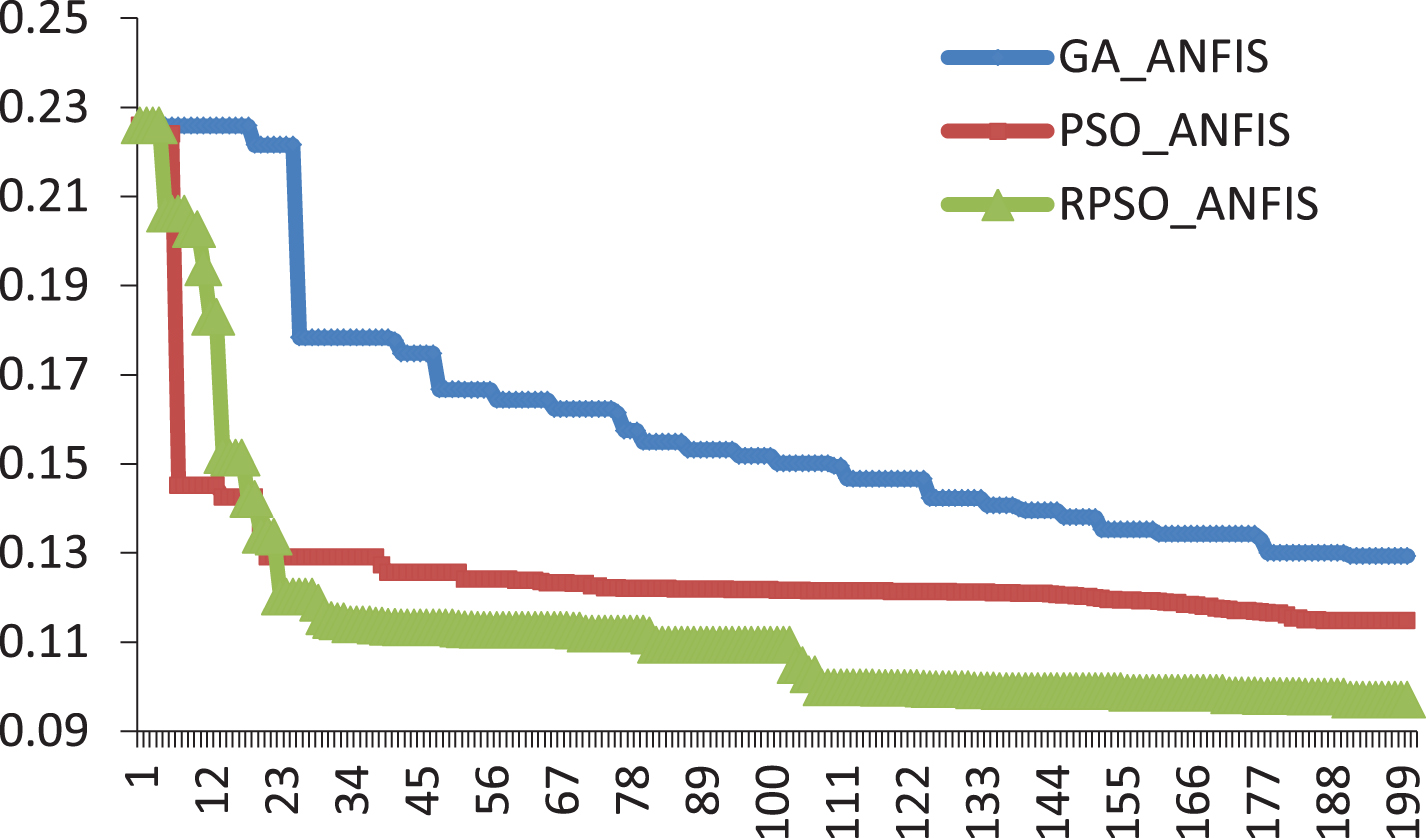
Convergence Curves of GA-ANFIS, PSO-ANFIS and RPSO in Predicting Proportion of Management Personnel.
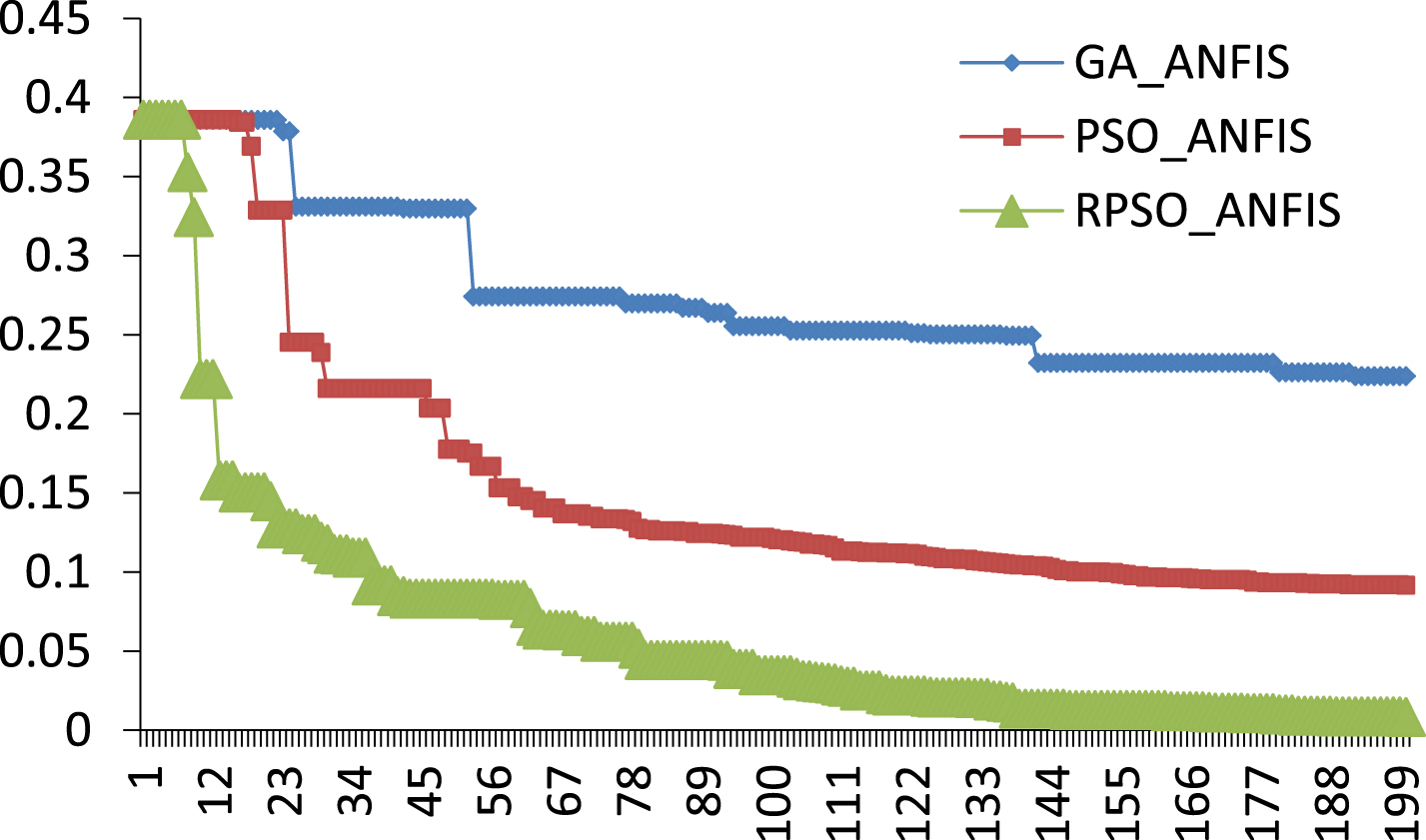
Convergence Curves of GA-ANFIS, PSO-ANFIS and RPSO in Predicting Proportion of Technical Personnel.
This paper presents a prediction model based on RPSO and ANFIS. The model is used to predict human resource structure need of one company. Prediction results show that RPSO-ANFIS model could reasonably handle all kinds of major factors within enterprise and had good convergence performance. It’s seen from numerical experiment that PSO-ANFIS model could highly precisely predict human resource structure of the enterprise and laid a foundation for scientifically formulating human resource plans and even making all kinds of human resource management decision of the enterprise. This model has provided a new approach for human resource structure prediction, and good experimental results also indicate that this new algorithm has the favorable application prospect.
Footnotes
Acknowledgments
This work is partly supported by Guangdong Natural Science Foundation (NO. 2015A030313664), Guangdong science and technology project (NO. 2016A070713004), Guangzhou science and technology project (NO. 2016A070713004 and 2017A040403068) and Special Foundation for applied science and technology development of Guangdong Province (NO. 2015B010131017). The authors have been supported by a Project Funded by the Priority Academic Program Development of Jiangsu Higher Education Institutions and Jiangsu Collaborative Innovation Center on Atmospheric Environment and Equipment Technology.