
Abstract
With the increasingly growing internal and external attacks on computer systems and online services, cybersecurity has become a vibrant research area. Countering intrusive attacks is a daunting task with no universal magic solution that can successfully handle all scenarios. A variety of machine-learning and computational intelligence techniques have been applied extensively to detect and classify these attacks. However, the effectiveness of these techniques greatly depends on the adopted data preprocessing methods for feature extraction and engineering. This paper presents an extended taxonomy of the work related to intrusion detection and reviews the state-of-the-art techniques for data preprocessing. It offers a critical up-to-date survey which can be an instrumental pedagogy to help junior researchers conceive the vast amount of research work and gain a holistic view and awareness of various contemporary research directions in this domain.
Keywords
Introduction
Computer networks and systems play a major role in information management in various domains such as military, education, medical, business, etc. Many private and governmental organizations rely heavily on their computer networks to store, manipulate and exchange data and provide local or remote services to their employees and clients. This tremendous growth in the use of computer networks and the Internet was accompanied by an unprecedented increase of illegitimate (hacking) actions that may result in severe consequences.
Intrusion detection has become a major concern and a challenge for cybersecurity practitioners to overcome the resulting security threats. It is defined as the process of monitoring events occurring in a computer system or network and analyzing them for signs of possible incidents of malicious activities or policy violations [1]. These incidents include, but are not restricted to, unauthorized access, misuse, modification, or denial of resources and services. A classification of various cyber attacks and tools available for defenders is presented in [2].
An intrusion detection system (IDS) is a device and/or software application that automates the process of identifying the presence of intrusions. In general, IDSs employ two principal categories of methods to detect intrusive incidents: (1) misuse-based detection and (2) anomaly-based detection. Methods in the former category can identify possible incidents by comparing the monitored events against pre-defined signatures of known attacks. On the other hand, anomaly-based methods compare the monitored events against the normal behavior of the system. There are a number of surveys related to anomaly-based intrusion detection in general [3–6] and for specific domains such as MANETs [7], wireless sensor networks [8], cloud computing [5, 9], heterogeneous 5G [10], and cyber-physical systems [11]. Figure 1 shows the research trend of intrusion detection literature over the period from 1973 to 2017 based on publications cited in Scopus.com and having the “intrusion detection” term in the article title. It is clear that this area started in 1972 and has been gaining increasing attention from the research community since mid-1990s with the evolution of cyber attacks.

Research trend of intrusion detection in terms of publications per year.
The area of anomaly-based intrusion detection has been very attractive to the machine-learning community and several approaches have been proposed. Machine-learning techniques have been used to construct models to classify observed activities in the system under surveillance as either normal or abnormal. However, the performance of the constructed model depends not only on the learning algorithm, but also on the nature of the adopted training dataset and preprocessing procedures.
Data preprocessing is an essential step in any data mining process. Its main objective is to eliminate or reduce undesirable characteristics of input data such as high-dimensionality, redundant/irrelevant attributes, missing attribute values, unsuitable formats (e.g., symbolic values), and class imbalance. These characteristics have a negative impact on the performance and accuracy of the detection method. Another factor that can affect the performance and accuracy of the detection method is the huge size of input data in terms of number of samples and number of attributes (or features). This can be handled using data reduction, projection and sampling methods. In this paper, we survey various directions of intrusion detection techniques and present an extended taxonomy. Moreover, we give an up-to-date review of data preprocessing mechanisms for feature engineering which can help intrusion detection systems to have higher accuracy and lower computational complexity. Due to the vast amount of literature in this area, it is not intended to review all relevant work but to focus on the state-of-the-art techniques and refer interested readers to earlier surveys for more details.
The rest of the paper is organized as follows. Section 2 discusses related work. Section 3 presents and briefly describes an extended taxonomy of the state-of-the-art in intrusion detection. Section 4 reviews data preprocessing and preparation techniques applied prior to machine learning. Section 5 focuses on dimensionality reduction methods. Finally, conclusions are reported in Section 6.
There were some attempts in the past towards a taxonomy of intrusion detection systems [3, 12, 13]. Table 1 shows a comparison between these taxonomies. As it can be seen from the table, the taxonomy by Axelsson [13] provides more comprehensive classifications based on particular system characteristics. However, some of the characteristics adopted in this taxonomy are not commonly referenced in the literature, e.g. the time of detection, the security of the IDS itself, and the degree of interoperability with other systems. Another point that can be noticed is the inconsistency between this taxonomy and the one provided by Debar [12] in terms of the classifications of the detection methods. In addition to that, the three taxonomies still lack some details about IDSs characteristics such as the response to instances and detection methods. These variations in the IDSs taxonomies might be attributed to the vast number of techniques and applications that exist as well as the continual introduction of methods for carrying out intrusion and for detecting intrusion. Two more recent taxonomies of IDSs were discussed in [14, 15]. However, these taxonomies are limited to certain types of IDSs. The focus of [14] is on techniques that apply contextual information for intrusion detection. The work presented in [15] concentrates on collaborative intrusion detection.
Comparison of three intrusion detection taxonomies
Comparison of three intrusion detection taxonomies
Davis and Clark [16] indicated that data preprocessing can have a direct impact on the accuracy and capability of the anomaly-based network intrusion detection systems. They reviewed data preprocessing for anomaly-based intrusion detection. However, they mainly concentrated on the different types of features used in anomaly-based network intrusion detection systems and the methods used to derive these features. Their review does not give details about the data preprocessing techniques and their classifications. The survey and taxonomy in [17] considered only feature selection algorithms.
Figure 2 shows a more extended taxonomy of intrusion detection systems. It includes several factors in the classification such as the source of audit data, the response of IDS to detected intrusions, IDS architecture, detection method, usage frequency, and attack characteristics. However, these categories are not mutually exclusive, which means a typical intrusion detection system can belong to several categories.
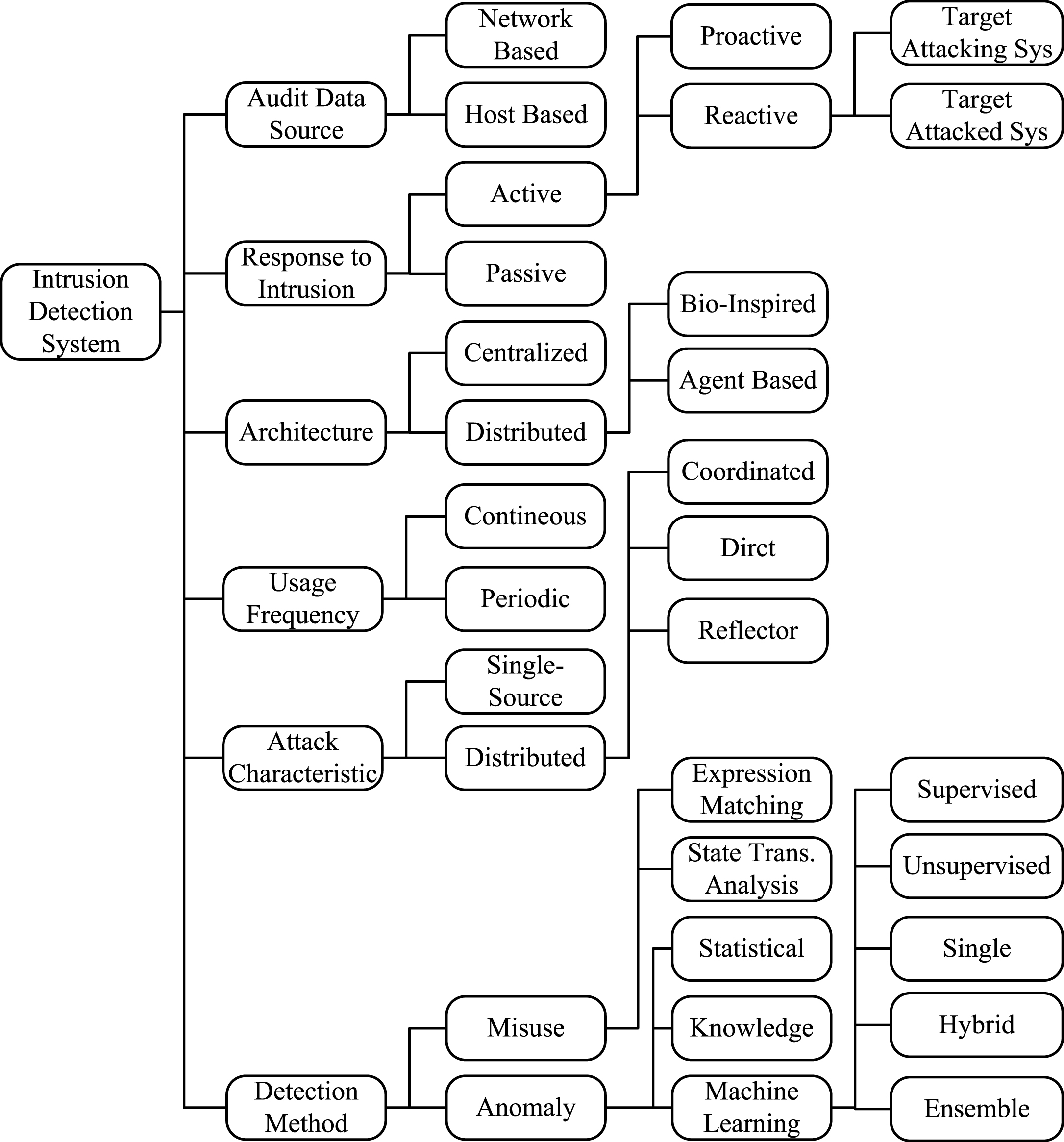
Taxonomy of intrusion detection systems.
Considering the source of audit data, IDSs can be classified into two main categories: host-based and network-based. Host-based IDSs (HIDSs) monitor and analyze activities on a particular host (or device) whereas network-based IDSs (NIDSs) monitor and analyze traffic in network segments. Host-based IDSs can be classified further depending on the layer at which data is collected as kernel-based, application-based or network-traffic-based. Also, network-based IDSs can be subdivided based on where they are installed (e.g., in active network devices such as routers, or in each host node) and what type of network to be protected (wired, wireless, MANET, and general). IDSs in wired networks are usually deployed at the boundaries between network segments to monitor and detect suspicious activities such as denial of services attacks, policy violation, probing and port scans, etc. IDSs in wireless networks work in a similar manner to wired networks but with no definition of crisp boundaries. Thus, the risk of some threats such as eavesdropping, transitive trust, and denial of service (DoS) is stressed more in the case of wireless networks due to the use of radio paths [18]. IDSs in MANETs face a new set of non-trivial challenges, as opposed to wired and wireless networks, due to their peer-to-peer architecture, system resource constraints, and highly dynamic network topology [19]. IDSs in general networks need to account for the various challenges and security risks of the three types of networks altogether.
Response to attack
Upon detecting an incident, an intrusion detection system can respond in a variety of ways [20]. At one extreme, it might work in passive mode and just trigger an alarm or send a notification leaving the action to be taken manually by the security administrator or user. However, with the increased complexity and frequency of intrusive activities, automated active response systems have become of crucial need. Stakhanova et al. [21] discussed several characteristics of passive and active intrusion response systems and provided a taxonomy for them. Active response attempts to hinder an attack in order to minimize the risk to victims [20]. This can be done in different ways: targeting the attacking or attacked system (e.g., terminating the network connection or session used by the attacker), changing the configuration of network devices (such as firewalls, routers, switches, etc.) to block the communication between attacker and the target, or deleting or replacing the malicious portion of the attack (e.g., deleting the infected attachment of an e-mail) [1]. The active response approach is further divided into two main categories: proactive and reactive [20]. A proactive response tries to prevent potential incidents before they happen whereas a reactive response reacts only after the intrusion is detected. Reactive responses can target the attacking or attacked system [13]. Reactive responses targeting the attacked system try to modify the state of the system (e.g., changing the network configuration, limiting bandwidth, terminating network connection) in order to prevent or reduce the effect of the attack. On the other side, IDSs can target the attacking system itself by executing a counterattack such as reconfiguring a router to block the attacker’s address. Examples of techniques using proactive and reactive responses are given in [22, 23].
Architecture
Intrusion detection systems have a variety of architectures, e.g., centralized or distributed. In centralized IDSs, the analysis of data is performed at a fixed number of locations, regardless of the number of monitored hosts. By contrast, distributed IDSs analyze data at a number of locations proportional to the number of monitored hosts.
Two main approaches typically used in distributed IDSs are: agent-based and bio-inspired. Agent-based IDSs such as [23–26] use software entities (agents) independently running on various hosts to monitor the network activities. Each agent processes its audit data and integrates its local outcomes with the outcomes of the other agents to achieve global intrusion detection. The other tack of distributed IDSs is inspired by biological systems such as artificial-immune system [27] and particle-swarms [28]. The self-organizing and distributed attributes of bio-inspired techniques can lead to building fully distributed, autonomous, and highly adaptive intrusion detection systems [28].
Detection methods
Intrusion detection systems can also be classified based on the methodology used to analyze and detect intrusions. In this regard, two main categories can be identified: misuse (or sometimes is referred to as signature-based), and anomaly-based. The basic idea of misuse detection methods is to compare monitored events against previously known attack signatures to identify possible incidents. These methods are very effective in detecting known attacks. Hence, they have become an industry standard for the past decades. However, they are highly ineffective in detecting unknown attacks as well as many variations of known attacks [1].
Several signature-based methods have been proposed in the literature [29]. These methods use two main models of detection [30]: expression matching, and state-transition analysis. Expression matching methods search into the event stream (e.g., log entries and network traffic) for occurrences of specific signatures or patterns. State-transition analysis, on the other hand, represents patterns of known attacks as a set of finite state machine (FSM) instances each representing an attack scenario; an example is shown in Fig. 3. Each FSM consists of a number of states with an initial state representing a normal (or safe) event and a deadlock state representing an attack. Every observed event is applied to each one of finite-state machines. Once an FSM reaches its deadlock state, the corresponding attack is reported.

An example of a state transition analysis model.
On the other hand, anomaly-based intrusion detection methods compare monitored events against models (or profiles) defining what is considered as normal activities (or behavior) of entities such as users, processes, connections, and applications. Thus, they are very effective in detecting unknown intrusions. In addition to that, they can produce signatures for signature-based methods. However, anomaly-based approaches usually produce more false positives (false alarms) due to the complexity of the network or system activities and the unpredictable behavior of network users.
Three main categories of approaches typically used in anomaly-based detection: statistical, knowledge, and machine-learning [31].
A) Statistical Approaches. The basic idea of these approaches is to build a statistical model representing the normal behavior of the network based on a number of metrics such as the traffic rate, the number of packets per protocol, etc. Subsequently, the model is trained to capture the stochastic nature of the normal behavior of the network from the observed network activities. The detection operation is performed by first constructing a new statistical profile from the currently observed activities of the network. Then, an anomaly score is estimated by comparing this profile with the profile constructed during the training of the model. The estimated score measures the degree of deviation between the two profiles. When this score exceeds a certain threshold, an intrusive incident is reported.
There are three main models used in the statistical-based approaches: univariate, multivariate, and time series. The univariate model was used in early detection methods such the one described by [32]. This model represents the features (or parameters) as independent Gaussian random variables with a separate threshold value for each variable. The multivariate model takes into consideration the correlation between multiple features (or parameters) rather than considering them as independent, e.g., [33]. Detection based on these models can show better detection results compared to methods based on the univariate model. Finally, the time-series model accounts for the fact that data points taken over time represent a sequence or stream that may have an internal structure. This model observes network activities taking into account their order, inter-arrival times as well as their values. Then, during detection stage, any observed event with a very low probability of occurrence at a given time is considered as abnormal (i.e., the event is inconsistent with normal activities observed on the time series). Examples of techniques using this model in anomaly-based detection are given in [34].
B) Knowledge/Specification Approaches. The basic idea of these approaches is to derive a set of classification rules, parameters or procedures based on different features or characteristics of the observed network data. These rules and procedures can be derived by an expert, automatically created by the system, or use a combination of both. Then, the observed network activities are classified as normal or abnormal according to the derived rules. One example of knowledge-based detection techniques is presented in [35].
C) Machine-Learning Approaches. The objective of using machine-learning algorithms in intrusion detection systems is to construct an explicit or implicit model that categorizes observed activities as either normal or abnormal, and hence be able to detect an intrusion. Several machine-learning schemes have been used in anomaly-based intrusion detection systems such as Bayesian classification, decision trees, hidden-Markov models, neural networks, support-vector machines, etc. A survey of machine-learning techniques used in intrusion detection is given in [36].
Based on usage frequency, IDSs can be either continuous or periodic [12]. Some IDSs monitor the system on continuous real-time basis whereas others run periodically.
Attack characteristics
Intrusion detection systems can be classified based on the characteristics of attacks they target. An attack can be either a single-source or a multi-source [37]. A multi-source (also called distributed) attacks can be further classified into coordinated, direct and reflected attacks.
In a coordinated attack, a number of facilitators or compromised systems are used in a coordinated manner to launch an attack on a victim’s host or network [38]. Coordinated attacks, such as large-scale scans, worm outbreaks and distributed denial-of-service (DDoS) are extremely hard to detect using regular intrusion detection systems (IDSs) that monitor only a limited portion of the network [39]. In order to detect such coordinated attacks, collaborative intrusion detection systems (CIDSs) which can correlate suspicious evidence of attacks from multiple IDSs have been proposed. Examples of CIDSs are given in [15, 41].
In a direct attack, the attacker launches attacks directly towards the victim; whereas, in a reflector attack, innocent reflectors (e.g., routers and servers) are used as attack launchers [42]. An example of an IDS detecting both direct and reflector DDoS attacks is given by [43].
Data preprocessing
Data preprocessing is recognized as an essential stage in all knowledge discovery tasks, including anomaly-based intrusion detection, which attempts to classify audit data as normal or abnormal using statistical or machine-learning methods [16]. The representation, size, and quality of input data can have a major impact on the computational performance and accuracy of the detection method. In particular, using a dataset with high dimensionality and many redundant and/or irrelevant features is expected to make the knowledge discovery during training more difficult [44]. To overcome this hurdle, one needs to process input data prior to the training phase in order to eliminate or reduce undesirable characteristics of the data. The preprocessing is also required to format the training data according to the requirements of the considered learning method (e.g., some methods can handle only numerical values while others can work better with symbolic data).
In the context of machine learning, data preprocessing methods may include: discretization, normalization, dimensionality reduction and sampling, handling missing feature values, and handling symbolic features [44]. These methods will be discussed in the following subsections except dimensionality reduction and sampling which will be discussed in details in Section 5.
Feature discretization
The main idea of discretization is to transform continuous features into a finite discrete set, by dividing the continuous range into a number of intervals and then assigning categorical/nominal values to these intervals. It is defined more formally in [45] as follows. Given a dataset S of n examples and C target classes, a discretization algorithm would discretize the continuous feature A in S into m discrete intervals D = {[d0, d1] , (d1, d2] , …, (dm-1, d m ]}, where d0 is the minimum value of A, d m is the maximum value, and d i < di+1, for i = 0, 1, …, m - 1. The discrete set D is called a discretization scheme on feature A and P = {d1, d2, …, dm-1} is the set of cut points of feature A. Discretization has two main objectives: (1) to facilitate the use of certain learning algorithms (e.g., algorithms that accept only nominal features), and (2) to simplify information representation and hence improve knowledge discovery [46].
In general, discretization techniques can be categorized as: static/dynamic, univariate/multivariate, supervised/unsupervised, splitting/merging, global/ local, and direct/incremental. Dynamic methods discretize continuous values when the classifier is being built; thus take into account the dependencies between different features, yielding more compact and accurate results for the considered learning algorithm. In static methods, however, the discretization is done for every individual feature prior to the learning task. In multivariate techniques, discretization is performed for all features simultaneously, whereas univariate techniques consider a single feature at a time. Unsupervised discretization algorithms discretize the features without taking into consideration the class labels while supervised algorithms do. Splitting methods define a new interval by creating a cut point to divide the considered domain into two intervals. By contrast, merging methods create a new interval by removing a previously defined cut point to combine both adjacent intervals. To make a decision, a discretizer can either require all available data in the feature space or use only a partial subset. Local discretizers work on a subset of instances while global methods use the entire instance space. Direct methods divide the range into k intervals simultaneously, where the value of k is determined based on some additional criterion provided by the user. By contrast, incremental methods start with a simple discretization and iteratively improve it; stopping when a certain criterion is satisfied. A taxonomy and more detailed analysis of various discretization techniques can be found in [45].
Feature normalization
Feature normalization or standardization is used to handle significant variations in the values and ranges of numerical features in training and testing datasets which may bias the learning algorithm. The two most commonly used normalization techniques are min-max and z-score (zero mean) methods [47].
Given a d-dimensional feature vector
The z-score (or z-mean) normalization transforms the values of the feature vector such that their overall distribution has an average of 0 and a standard deviation of 1 as shown in the following equation:
A review of other normalization techniques such as rank normalization, normalization by decimal scaling, and normalization by fitting distributions can be found in [47, 49].
Missing data is a common problem in machine learning and other related areas, such as data-mining and knowledge discovery from databases. Unless properly treated, missing data may introduce bias into the knowledge induced, and hence affect the accuracy of the learned model [50].
Basically, there are four main approaches to handle missing data, namely deletion, single or multiple imputation, and maximum-likelihood estimation. These approaches are explained with analysis examples in [51]. However, in this section, we will only summarize the main idea of each approach and its different types.
A) Deletion Approach. There are two main approaches to delete data with missing values. The first approach, known as list-wise deletion, discards instances with missing values. In the second approach, which is known as pairwise deletion, incomplete instances may or may not be deleted based on the contribution of their missing variables (or features) into the performed task (e.g., statistical analysis, classification, etc.). Although these deletion methods produce a complete dataset, they can dramatically reduce the sample size.
B) Single Imputation Approach. This approach refers to missing data handling techniques where missing values are replaced with estimated ones using information available in the dataset. There are three common techniques to estimate the missing values: mean imputation, regression imputation, and stochastic regression imputation. Mean imputation replaces missing values with the mean of the available data. Regression imputation uses a regression equation to estimate values that will substitute the missing data. Stochastic regression imputation estimates the substitution values in the same way as in regression imputation, then adds to each value a random error term generated from a normal distribution.
C) Multiple Imputation Approach. This approach involves three steps: (1) creating multiple imputed datasets with different imputation values, (2) carrying out the required task (e.g., analysis, classification, etc.) on each dataset, and (3) combining the results of all tasks using a suitable method (e.g., pooling, voting, etc.).
D) Maximum-likelihood Approach. This approach does not fill missing values. Instead, it uses all of the available data to find the parameter values having the highest probability of producing the sample data.
Handling symbolic features
Since several machine-learning techniques, such as Artificial Neural Networks (ANNs) and Support-Vector Machines (SVMs), can handle only numerical features, we need to map symbolic attributes to numeric values. Several mapping approaches exist such as indicator variables, conditional probabilities and Separability Split Value (SSV) criterion based method [52].
A) Indicator Variables. This approach uses binary coding to map a feature A of m categories to a m-dimensional vector of 1’s and 0’s where 1 indicates the occurrence of a category and 0 indicates the absence of that category. The drawback of this approach is that it significantly increases the dimensionality of the dataset in the presence of several symbolic features with a large number of different categories. Therefore, it is necessary to reduce the number of variables by grouping similar categories together before creating indicator variables.
B) Conditional Probabilities. The basic idea of this approach is to replace each symbolic value x
k
of a feature A with an N-dimensional vector of conditional probabilities for obtaining each class given that the attribute A has the value x
k
:
C) SSV Criterion Based Method. This approach uses a decision tree based on split values, called the separability split values (SSV), to partition the categories of a symbolic feature into subsets such that the members of one subset are mapped to a single value in the interval [0, 1]. The decision tree is constructed recursively using the algorithm presented in [53]. Two different categories may end up in a single leaf only if all the input vectors containing any of those categories belong to the same class. In such a case, the two categories are considered to be undistinguished, and hence, can be mapped to the same real value.
One of the main challenges in applying machine-learning algorithms for intrusion detection is the large size of audit data in terms of both the number of samples and the increased number of features. This may affect not only the computational performance of the machine learning algorithm, but also its accuracy. Basically, the data reduction techniques, as demonstrated in Fig. 4, fall into three main groups: data partitioning or sampling, feature selection and feature extraction. Data partitioning or sampling techniques can be used to select a representative subset or sample of smaller size. On the other hand, feature extraction and feature selection are used to handle the more intricate problem of selecting a subset of significant features, which is known as dimensionality reduction problem [54–56].
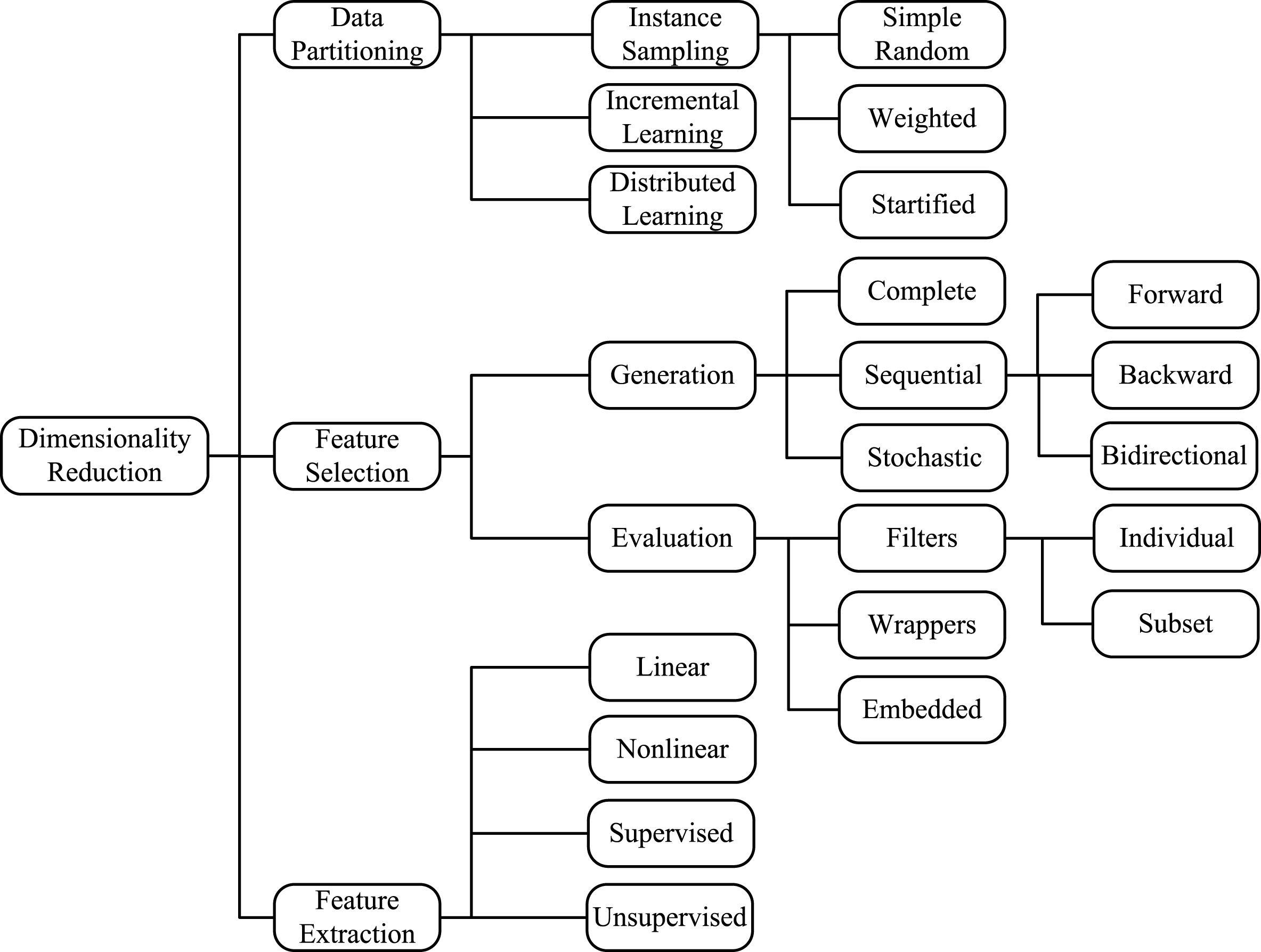
Classification of data reduction methods for machine learning and data mining.
Here, the original dataset is partitioned into smaller subsets, and a model is constructed using one of three learning methodologies, namely instance sampling, incremental learning and distributed or ensemble learning [57].
A) Instance Sampling Method. This method selects a single data subset for training. There are three types of data sampling techniques, (1) simple random sampling which gives each individual data record an equal chance of being selected, (2) weighted sampling in which each record has a different likelihood of being selected, (3) stratified sampling which divides the entire population into different categorical subgroups (or strata) and the population is randomly sampled within each category (or stratum). An example of applying stratified sampling to improve the performance of intrusion detection is given in [58].
B) Incremental Learning Method. This method uses multiple data subsets in sequence to gradually build a prediction model. It uses the knowledge obtained from one subset to guide the training process on the next subset. An example of using incremental learning for intrusion detection is given in [59].
C) Distributed Learning Method. Distributed or ensemble learning methods use multiple data subsets and multiple learning algorithms in parallel. Each algorithm is trained on an individual data subset. Then, the outcomes of different models are combined to build the final prediction model. Some examples of intrusion detection techniques based on this approach are given in [60, 61].
Feature selection
The ultimate goal of feature selection is to find an optimal subset of the original features that best characterizes the considered system, and which eliminates irrelevant and redundant features. However, finding such an optimal subset in many problems is intractable due to the high-dimensionality of their domains [62]. Therefore, heuristics and optimization techniques are usually used to select suboptimal features. Feature selection methods fall into four categories: wrapper, filter, hybrid and embedded approaches [17, 63].
Wrapper methods, use machine learning algorithms to evaluate the goodness of feature subsets. Filters utilize the underlying characteristics of the features to filter out irrelevant and redundant ones rather than using machine learning algorithms. Hybrid methods combine both approaches of wrappers and filters. Embedded methods perform feature selection during the training of the prediction algorithm.
Feature selection methods involve four key steps as shown in Fig. 5 [64].

Key step of feature selection.
1) Subset Generation. The objective of this step is to find candidate feature subsets. Different search strategies have been used for this purpose: complete, sequential and stochastic search [62]. Feature selection methods with a complete search that explores all possible feature subset combinations guarantee to find the optimal subset. However, for a dataset with N features, there exist 2 N candidate subsets. This makes the complete search intractable even with moderate N. Feature selection methods based on sequential (greedy) search strategies gradually construct feature subsets by adding or removing features based on a certain evaluation criterion. This search strategy avoids the computational complexity of the complete search, however, it may get trapped in local optima. Using stochastic search methods such as simulated annealing and genetic algorithms provides a means to escape local optima, and hence improve the overall solution.
An important factor that influences the search of a candidate feature subset is the search direction [17]. The search process may start with an empty set and gradually select the best features according to the evaluation criterion (i.e., forward selection). In contrast, the search process may start with the full set and gradually eliminates the least significant features (i.e., backward elimination). Another alternative is to start with both ends and add and remove features simultaneously (i.e., bidirectional search).
2) Subset Evaluation The objective of this step is to measure the optimality (or goodness) of the select feature subset using some evaluation criterion. Evaluation criteria can be classified as either independent or dependent based on their dependency on learning algorithms that will be applied to the selected feature subset [17]. Some examples of independent criteria are distance, information gain, correlation, similarity, dependency and consistency measures.
Filters use independent criteria to judge the significance of a feature (i.e., individual evaluation) a subset of features (i.e., subset evaluation) regardless of the classifier to be used [65]. Individual evaluation, also known as feature ranking, evaluates individual features and ranks them according to their degrees of relevance to the predicted variable. Subset evaluation uses some search strategy such as genetic algorithms to search through the space of possible feature subsets and evaluate each subset using a particular evaluation metric or fitness function. In each stage of the search process, the best subset with respect to the evaluation metric is selected until a given stopping criterion is satisfied. As compared to the individual evaluation approach, this approach uses the evaluation metric against subsets rather than individual features which allows it to consider overlapping and redundancy among features. Because filters are computationally efficient and independent of any classifier method, they have been adopted in a number of intrusion detection techniques as a preprocessing phase for feature selection [66, 67].
Wrappers are similar to subset evaluation filters in the search approach, but instead of evaluating feature subsets against an independent measure, they use the prediction performance of a certain learning algorithm (e.g., ANN or SVM) as an evaluation criterion. Wrappers are usually computationally expensive compared to filters, but they are expected to give better results. Several wrapper-based feature selection methods have been suggested in recent years to improve the performance of machine-learning techniques for intrusion detection [68–70].
Hybrid approaches make use of both independent and dependent evaluation criteria to evaluate selected feature subsets. They use independent measures to select the best subsets for a given cardinality and use the learning algorithm to select the final subset among the best subsets across different cardinalities. Park et al. [71] proposed a lightweight intrusion detection system based on a hybrid feature selection approach. This approach is a crafted combination of correlation-based feature selection (CFS) filter, support vector machines (SVM) and a genetic algorithm (GA). The GA is used to generate subsets of features from given feature set. Then, these subsets are evaluated by CFS and SVM to obtain an optimal feature subset.
In contrast to the previous three approaches, embedded methods do not separate the learning process from the feature selection. Instead, they perform feature selection during the process of the training of the prediction model [57]. This approach was applied by Lin et al. [72] to intrusion detection using a feature selection mechanism based on simulated annealing (SA) and support vector machine (SVM). In this approach, the SA optimizes the parameters of SVM and selects features with the best testing accuracy.
3) Stopping Criteria. This step determines when to stop the feature selection process. The choice of a stopping criterion is influenced by both subset generation and subset evaluation processes [64]. Examples of stopping criteria based on subset generation include: completing the search, selecting a predefined number of features, and reaching a predefined number of iterations. Examples of stopping criteria based on subset evaluation include: obtaining an optimal subset according to the used evaluation function, and addition (or deletion) of any feature does not produce a better subset.
4) Result Validation. This step tries to test the validity of the selected subset using either a prior knowledge about the dataset or by carrying out some experiments on the selected feature subset using different learning/clustering algorithms. In [56], the KDD Cup 99 dataset has been used to empirically evaluate a wide spectrum of feature selection methods.
Feature extraction reduces the dimensionality of a dataset by projecting the original d-dimensional feature space onto a space with fewer dimensions through a linear or non-linear transformation [73] using supervised or unsupervised learning methods. Examples of these transformation methods are linear-discriminant analysis (LDA), and principal-component analysis (PCA).
LDA is a supervised learning method used to find a linear combination of features which separates two or more classes of objects. The resulting combination can be used as a linear classifier or a dimensionality reduction tool. In [74], Katos evaluated the use of discriminant analysis in the examination of intrusion detection data.
PCA is an unsupervised technique commonly used for data transformation. It can be formulated to find linear combinations of features which show the directions of the largest variance of the data. The linear combinations of features transform the data to a new coordinate system such that the greatest variance by any projection of the data lies on the first coordinate (called the first principal component), the second greatest variance lies on the second coordinate, and so on. The dimensionality of the original data can be significantly reduced (without substantial loss of information) by using the largest variance directions as features. PCA has been used as a feature extraction tool to reduce the dimensionality of training datasets in a number of intrusion techniques such as [75].
Conclusion
Defending computer systems and networks against internal and external malicious activities is a crucial aim in cybersecurity. This problem is very challenging and continues to be an active research area. In this paper, we reviewed recent research directions for intrusion detection and presented an extended taxonomy. In addition to that, we reviewed data preprocessing mechanisms for feature engineering which have been proposed to improve the detection accuracy and reduce the computation complexity of constructed models.
To the best of our knowledge and as pointed in [76], there is no intensive study in the literature that benchmarks various combinations of preprocessing procedures and machine-learning techniques for anomaly-based intrusion detection. Most of the proposed techniques in the literature apply preprocessing methods on considered datasets in an ad-hoc manner. For future work, we are planning to design a test bench that can help the designers of anomaly-based IDSs to select the right combination of tools (i.e., learning technique and data preprocessing mechanisms) for their models.
Footnotes
Acknowledgments
The authors would like to acknowledge the funding provided by King Abdulaziz City for Science and Technology (KACST) for this work through the Science Technology Unit at King Fahd University of Petroleum and Minerals (KFUPM) under Project 11-INF1658-04.