
Abstract
Biometric refers to the automatic identification of a person based on physiological or behavioural characteristics. Current modes of biometric systems are fingerprint, voice, face, signature, palm print, iris scan etc. The conventional biometric systems are unable to meet these authentication requirements as it can be forged. Hence, a novel biometric system which can overcome these limitations is proposed. Tongue is a unique vital organ which is well protected within the mouth and not affected by external factors. Dorsum of the tongue exhibits a great amount of information along with its visual differences in shape, texture and pattern which can be called the tongue print. As tongue exhibits rich textural patterns, Local Binary Pattern (LBP) algorithm is used for extracting features. Extracted features are then trained by a linear Support Vector Machine (SVM) for personal identification. From the database consisting of 136 tongue print images of 34 individuals, we achieved an accuracy of 97.05% for identification. Our study is the first of its kind where texture patterns are extracted from tongue images using Local Binary Pattern for biometric authentication. We achieved a level of accuracy compared to the technique used in other studies.
Introduction
A biometric system should support the facet of identification, authentication and non-repudiation in information security. The conventional biometric systems are unable to meet these authentication requirements as it can be forged. Hence tongue prints are gaining importance in biometric authentication as a new biometric system. Tongue is a unique vital organ and the characteristic features of the tongue exhibits remarkable difference even between identical twins. In traditional Chinese medicine, tongue was found to play an important role in diagnosing disease condition by observing characteristics such as colour and shape. Zhi Liu et al. [1] attempted to develop a 3D tongue image database that characterizes both texture and shape of the tongue images. Based on their research they concluded that the tongue can be used as a biometric trait. Li Q et al. [2] and Manoj Diwakar et al. [3] used different methods of capturing tongue images, creating image database and evaluated the possibility of using tongue in human identification.
Omer et al. [4] conducted a cross sectional descriptive study and concluded that tongues are different between identical twins and hence can be a new personal identification method which needs further elaboration. Radhika T et al. [5] reviewed the emergence of tongue as a novel biometric tool. They highlighted the uniqueness of tongue prints and its superiority over other biometric identification systems. Bob Zhang and Han Zhang [6], extracted geometric features from tongue images and tried to establish the relationship between a patient’s state, healthy or diseased, and human tongue. Stefanescu et al. [7], analyzed lingual morphological aspects and demonstrated their importance. Based on the results gathered from their analysis, they also put forth a classification of tongue features.
Salim Lahmiri [8], used wavelet transform for texture analysis and extracted six statistical features for tongue print verification Manoj Diwakar et al. [3], used the identified spots on the tongue for person identification using histogram as feature. Ryszard S. Choras [9] utilizes steerable filters and Weber Law Descriptor feature for identification. Zhang et al. [10] proposed a novel feature that make use of both shape and texture of the tongue for identification. They have taken geometrical features to represent the shape and texture codes for the textural features.
Tongue-print acquisition
The study group comprises a randomly selected 34 individuals from PMS College of Dental Science of both genders. The study was conducted in the Department of Oral Pathology and Microbiology in collaboration with Department of Computer Science, University of Kerala. Clinically recorded photographs of dorsal surface of healthy individual’s tongue falling under the age group of 18–25 years were included. The patient was informed and a written consent was obtained for the study. Images of dorsal part tongue were captured under the standardized lighting conditions using a Hi-tech digital SLR camera with fixed head position and tongue protrusion, maintaining the distance of subject to camera. From each individual four images from same position were taken.
The human tongue carries both geometric outline and physiologic texture information that helps to analyze the uniqueness of tongue and its possibility of it being used in human identification. Therefore a study was carried out, for an automatic identification of an individual where the tongue images are acquired digitally, with the objective of extracting the textural patterns seen on the dorsum of tongue. In this paper, an automatic person identification system using tongue-print is proposed. Local Binary Pattern is used to extract features from the given tongue image and a linear support vector machine is used to train the feature vector for identification.
The paper is organized as follows: Section 2 details Local Binary Pattern technique which is used to extract features from the tongue image Section 3 elaborates the proposed method for tongue identification. Section 4 gives the classification method used in this paper to classify the tongue images and Section 5 draws the conclusion.
Tongue-print as texture
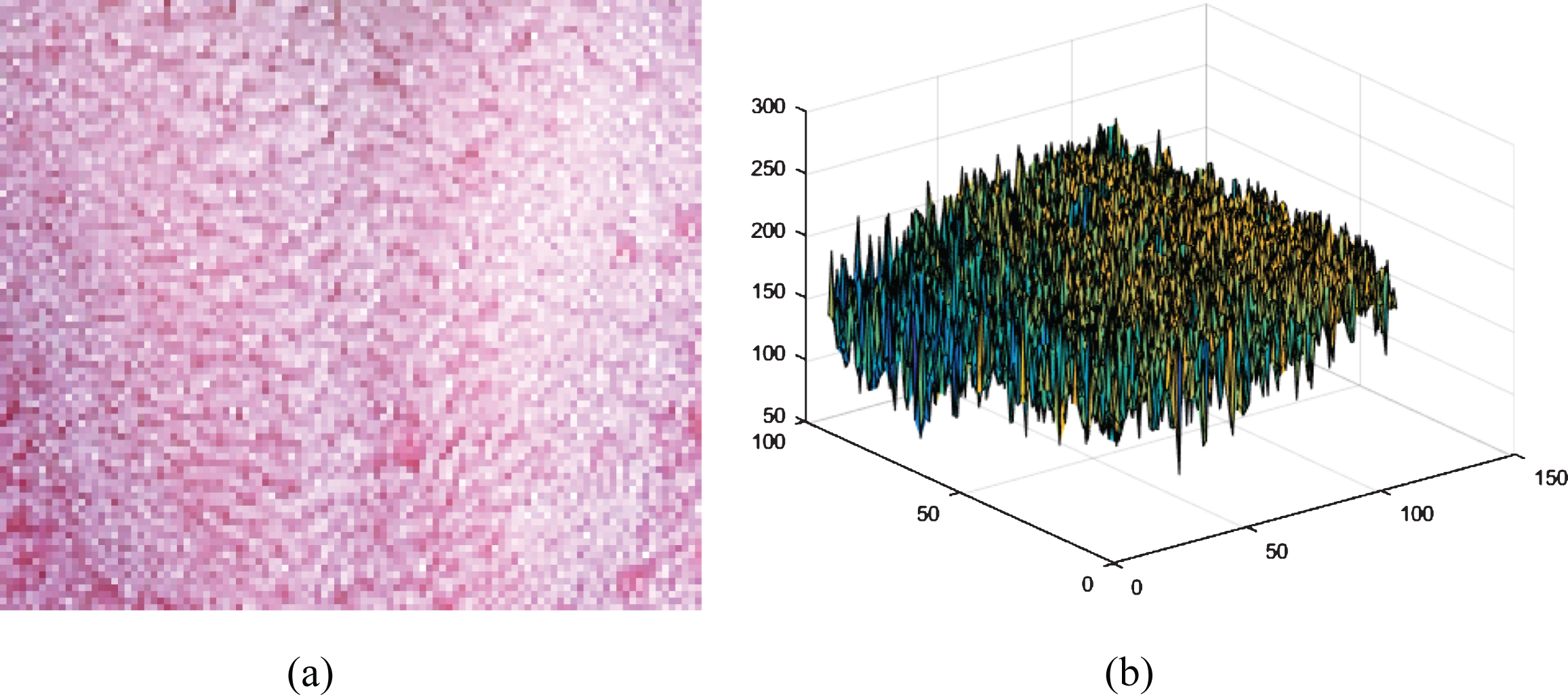
Tongue image characterizes a rich textural pattern (refer Fig. 1(a) & (b)). Texture is a repeated pattern of local intensity variations and characterizes important spatial relationships contents of an image. These textural patterns presents in the dorsum of tongue image can be well represented by the Local Binary Pattern (LBP).
The local binary pattern operator is a popular method proposed for texture description. In its original version [11], the operator assigns binary labels to each image pixels by thresholding the 3x3-neighborhood with the center pixel value and outputs its corresponding decimal value (refer Fig. 2). These labels computed over a region of image will be represented as a 256-bin histogram and used as a texture descriptor.

The basic LBP operator.
This operator was later extended [12] to use different neighborhood scales to overcome the limitation of capturing textural features at finer levels. This is done by defining a circular neighborhood denoted by (P, R) and bilinearly interpolate the neighborhood pixel values with respect to a center pixel for different radius and pixel points (refer Fig. 3). Here, P is the number of sampling points in the circle of radius R. The LBP label is obtained by
With LBPP,R operator, 2
P
possible pattern combinations will be produced. Not every patterns are necessary for the identification purpose. Moreover, the feature length will be large when all the possible patterns are considered for a feature vector. Therefore, it is further modified to include only a subset of Local Binary Patterns in the feature vector, which are called uniform binary pattern. A local binary pattern is called uniform if the pattern contains at most two bitwise transitions from 0 to 1 or vice versa when it is considered circular [12]. For example, 00000000, 10000001 and 00111000 are uniform patterns. Uniform LBP operator, denoted by

In the proposed method, first the tongue images are acquired using a Hi-tech digital SLR camera. The acquired color images are converted into gray scale images for processing. In the next phase features are extracted using LBP operator and the extracted features are trained for classification into different subjects using SVM classifier. For identification, the same LBP feature is extracted from pre-processed test image and give it to the trained classifier. Outline of the proposed method is shown in Fig. 4. In the coming sections, the different phases of the proposed method is detailed.

After computing the uniform patterns using the
A tongue image has rich textural patterns in its dorsum, called micro-patterns that are well described by LBP. However if it computes on an entire image, LBP histogram will not carry the spatial relationships of the image, it characterizes only micro-patterns of the whole image. Recently, studies [13, 14] has been reported that retaining spatial relationships along with textural information in the feature vector is crucial for recognition. Motivated by these studies, the tongue image is divided into different m regions, R0, R1, . . . . , Rm-1. LBP histograms are computed from each of these m regions separately and a final feature vector of size m × n is formed by combining m separate histograms where n is the length of a single LBP histogram. Since this spatially enhanced feature vector contains both local textural patterns and its spatial relationships, it describes the global characteristics of a tongue image [13].
For an automated person identification using LBP algorithm, selecting parameter values for LBP operator is crucial for the overall accuracy of recognition. For LBP operator
Time Vs. Accuracy of SVM Classifier
Time Vs. Accuracy of SVM Classifier
Automatic person identification using tongue is a process which takes an image as input and tries to find a subject having a close match with the features recorded in the database. Obviously this process can be treated as a classification procedure, where the input image is classified into a subject class having a close classification match. Every classification methods are either supervised or unsupervised learning algorithms. In this work, we used Support Vector Machine (SVM) as the classifier for tongue identification. In the next section we will brief SVM technique.
Support Vector Machine
Support Vector Machine (SVM) is a supervised learning technique for classification. We have used SVM to classify 34 different subjects for identification.
Given set of N training samples {X
i
, y
i
} , i = 1, . . . . . , N where X
i
∈ R
n
belong to the binary class labeled by y
i
∈ {1, - 1}, SVM implicitly maps of data into a higher dimensional feature space and separates the data in this space by finding a linear separating hyperplane with the maximal margin. When a new test sample X is presented, the following decision function of the SVM classifier is used to classify two classes.
The training samples Xi with α i > 0 are called support vectors, and SVM finds the separating hyperplane that maximizes the margin between the support vectors and the hyperplane. The most frequently used kernel functions are linear, polynomial and Radial Basis Function (RBF).
Being maximum margin classifier, SVM are designed to solve two-class problem, while tongue print identification is a q-class problem where q is the number of known individuals. Two approaches can be taken to solve the q-class problem. First is to reformulate the tongue print identification problem as a several separate two-class problems (one-vs-all). Employ a set of SVMs to solve a generic q-class recognition problem (one-vs-one). In this paper, we used the one-vs-all technique, which trains binary classifiers to separate one class from all other classes, and outputs the class with largest output of binary classification.
The captured color tongue image is converted into gray scale image for reducing the processing time and this will not make any change in the textural patterns appeared in the tongue dorsum. Though LBP operator is very robust with respect to the extracted features, we divided the tongue image into several regions (refer Fig. 5) to get more discriminative features. Since extracting LBP histogram feature from each region may effectively increase the size of the feature vector, we have conducted an experimental analysis to get the optimum size of the region (refer Table 1).
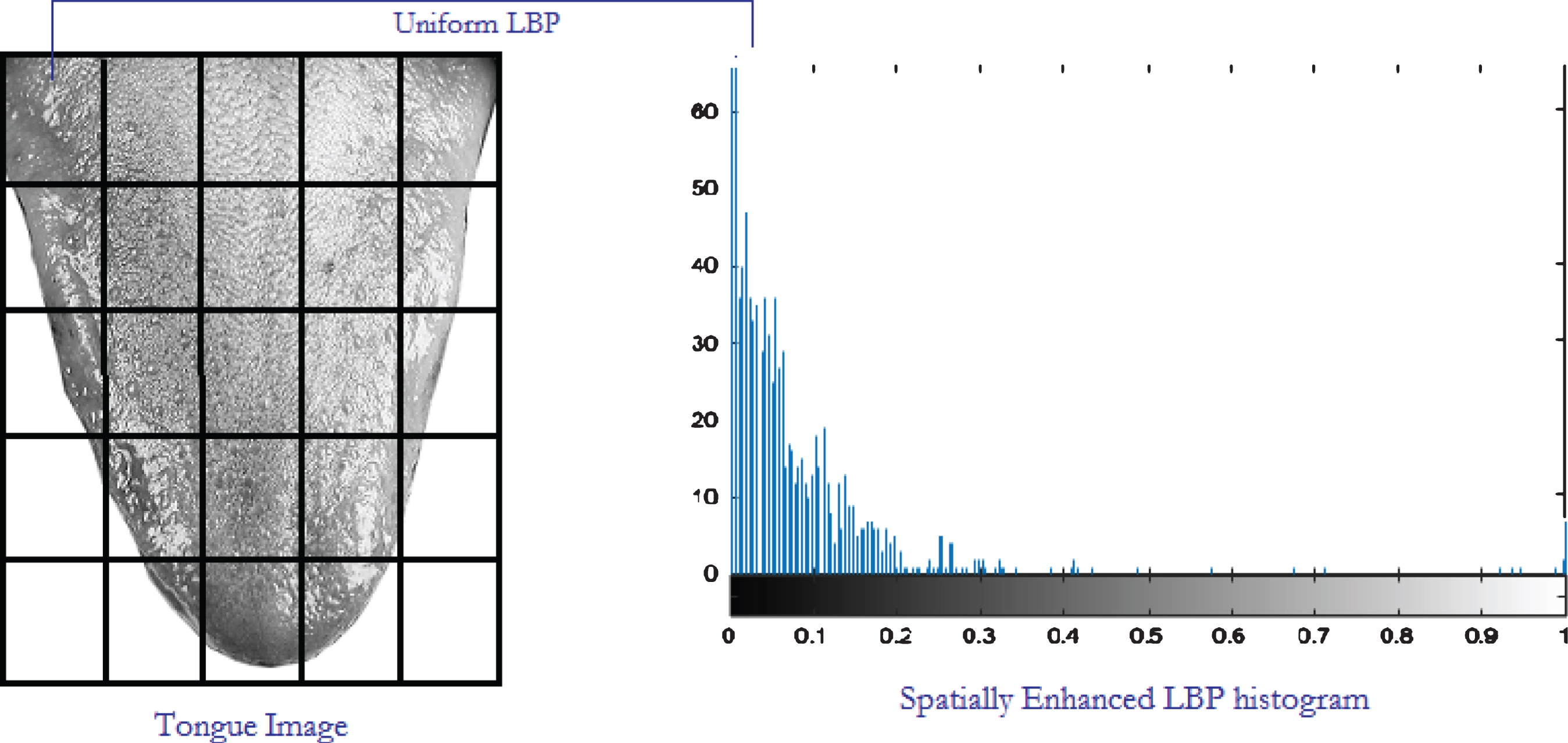
The field Region in Table 1 represents the different number of regions. Second field corresponds to the classifier accuracy while training and the third field gives the performance accuracy of the new test images. Fourth field Time, specifies the time in seconds taken for training. From the experimental analysis, we have found that increasing the number of regions from 5 × 5 increases the features extracted but will not contribute to the overall accuracy of the identification.
For identification, we used SVM classifier to train the extracted LBP histogram features with a linear kernel since it requires a low computational cost. For a one-vs-all approach, the algorithm trains SVM binary classifiers to discriminate each subject class from all the others. We have set the total number of support vectors α i = 3 and used 5-fold cross validation for training the samples.
We have achieved an identification accuracy of 97.05% in a dataset of 136 subjects (refer Table 1) with the proposed method by selecting the region size to an optimum size of 5 × 5. With the 5-fold cross validation, the linear SVM training took only 0.92 sec. to complete.
The proposed reference point detection method is implemented using MATLAB. For the comparison of performance accuracy, we have implemented two state-of-the-art techniques which is already proposed in the literature by Salim Lahmiri [8] and Zhang et al. [10] in the same dataset and the comparison result is shown in the Table 2. From the table, it is evident that the proposed method is giving better performance compared to other state-of-the-art techniques.
Performance comparison with other works reported in the literature
Tongue is a unique vital organ well protected within the oral cavity; hence tongue prints are immune to forgery and cannot be reverse engineered. Tongue image database will enable the possibility of using tongue prints as a novel biometric tool in forensic and biometric applications by replacing the conventional biometric system. In this paper an automatic tongue-print identification method is proposed. LBP histogram feature is extracted from the tongue image and a SVM trained classifier is used for identification. In our study we were able to develop a tongue image database and attained an accuracy of 97.05% for identification. The results shows that the proposed method is reliable as a novel biometric tool for user authentication.