
Abstract
Retrieving out the most comparable images from huge databases is the challenging task for image retrieval systems. So, there is a great need of constructing a capable and rigorous image retrieval system. In this implementation, an exclusive and competent Content based image retrieval (CBIR) system is schemed by the integration of Color moment (CM) and Local binary pattern (LBP). A hybrid feature vector is created by the combination of these two techniques through the process of normalization. This hybrid feature vector is given as the input to the intelligent classifiers i.e. Support vector machine (SVM) and Cascade forward back propagation neural network (CFBPNN). After that, Relevance feedback (RF) technique is applied so as to get the high level information in order to reduce the semantic gap. So, here two Artificial Intelligent CBIR models are proposed, first one is (Hybrid+SVM+RF) and second is (Hybrid+CFBPNN+RF) and their performance parameters are compared. The implementations are performed on two benchmark dataset Corel-1K and Oxford flower dataset which contains 1000 and 1360 images respectively. Different parameters are figured such as accuracy, precision, average retrieval time, recall etc. The average precision obtained for the first model is 93% with Corel 1K database and 91% with Oxford flower database. And similarly for the second model, it is 97% and 94% respectively which is higher than the first model. This implemented technique is validated on both the datasets and the attained results outperforms with other related s approaches.
Keywords
Introduction
With the tremendous advancement in digital technology, there is a great up gradation in the field of digital imaging. Large number of image capturing devices and smart mobile phones has led to the creation of large image archives Storing, indexing and retrieving these images from huge databases is a very cumbersome task. So there is a considerable need of designing competent image retrieval systems. Traditionally, for retrieval of images, text based image retrieval system (TBIRS) was used in which images were retrieved by textual description of images. But with the expansion in the figure and complexity of images it becomes very difficult and challenging task for the man power to annotate the images. It suffers from various limitations like errors in spellings, synonyms etc.
In order to conquer the constraints TBIR systems CBIR systems were designed in which the visual attributes of an image are utilized for retrieving the comparable images from the databases. For constructing this system, foremost step is extracting the beneficial and decisive features from the images and the next step is the similarity measurement. The resemblance between the database and query image is computed with the help of their extracted features. The most important visual attributes are color, edge, texture and spatial information [25]. The basic flow of working of CBIR system is depicted in Fig. 1.
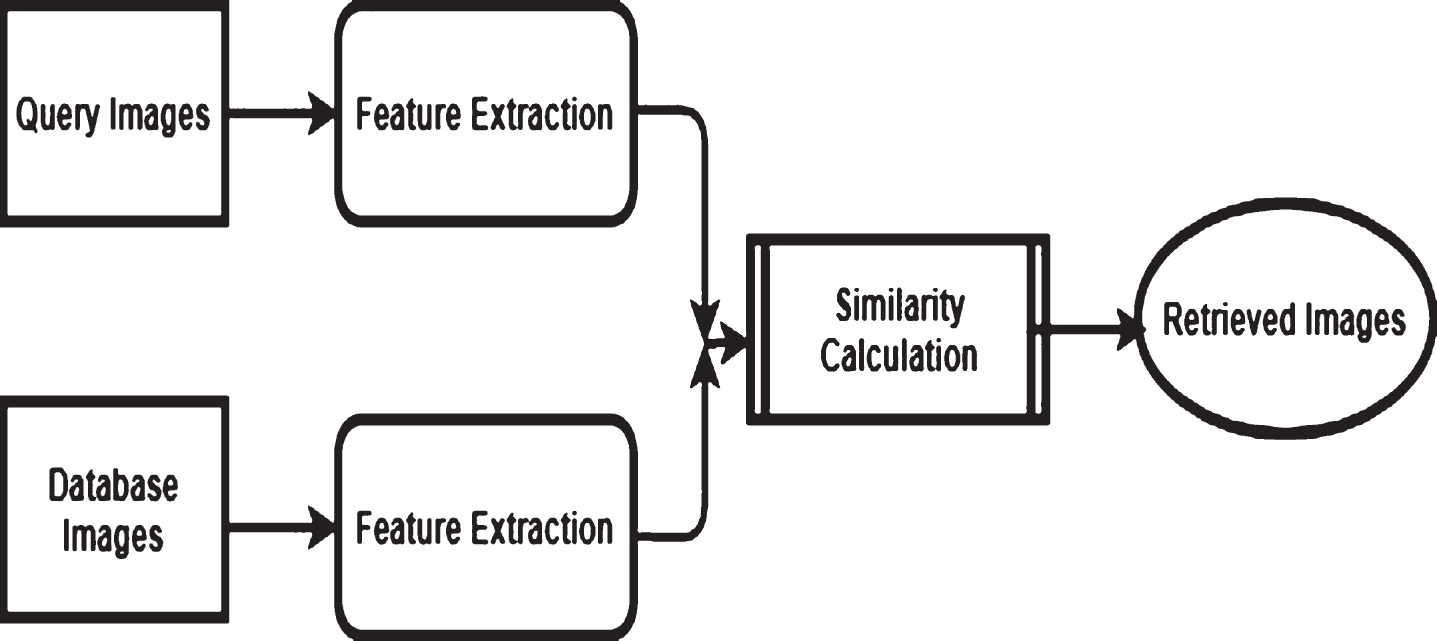
Basic flow of CBIR system.
Various types of image retrieval systems have been designed based on the single feature for the simple images. But for the retrieval of the complicated images, the best selected combination of features is required which forms a hybrid feature vector [4].
For increasing the accuracy and performance of CBIR systems, machine learning algorithms are now deployed. The hybrid feature vector obtained becomes the input to these machine learning classifiers. Several types of classifiers exist which falls under four categories: Supervised, Unsupervised, Semi-supervised and Reinforced learning classifiers [26]. Basically in CBIR systems supervised machine learning algorithms are preferred as they serves as classifiers and solves the complications of classification problem in case of large datasets. Because the retrieval of images from these huge image archives is a very time consuming task for CBIR system as query image has to be matched with every image of the database. After the process of classification, the query image is matched only with the particular class of the images and not with the entire database. So, the study focuses over this particular issue by using machine and deep learning classifiers.
Another major issue with these systems is the ‘semantic gap’ which is the difference between vision of computer and human perception. So now the research is being focused on much advanced and capable measures and different techniques have been emerged to overcome the complication that arises due to semantic gap [9].
The main motivation behind this study is to remove all the bottlenecks which occur while designing an accurate image retrieval system for larger datasets. Because of these huge image repositories, the effort of indexing, browsing and retrieving becomes very laborious and almost impossible.
The main purpose of this implementation is to develop a relevance feedback based hybrid CBIR system by employing suitable combination of feature extraction techniques of color and texture. For the classification of larger datasets, intelligent classifiers are used which makes the system much more efficient and accurate than other designed systems. [22].The proposed system is unique from other designed systems as: Firstly, a fused CBIR system is framed by the integration of CM and LBP which captures the color and statistical properties of the images. On this hybrid feature vector of images, intelligent algorithms (SVM/CFBPNN) are used as classifiers so as to classify the large datasets and make the CBIR system less complex. After that to make system more effective or to increase the precision rate Relevance feedback is applied here on the output images. All these steps are performed while designing an innovative and efficient CBIR system. The performance of CBIR system is evaluated on two benchmark datasets i.e. Corel-1K and Oxford flower. Moreover, the evaluated performance parameter is also validated with some references on both these datasets, which shows that the proposed system is novel and much more precise than others.
The remaining part of the paper is structured in various sections. Section 2 is about the important related work done in the CBIR systems. The next section describes the various techniques that are utilized here for implementation. Section 4 is the basic research methodology part. In the next section proposed work is explained. Experimental set up and outcomes are shown in the section 6 and 7, finally concluding summary is presented.
In this section numerous latest techniques related to the CBIR systems is discussed. In [10] the authors described a hybrid CBIR system based on texture and color. Wavelet decomposition technique was used to extract the texture feature and the characterization of texture classes with the variations in higher frequency coefficients. Another color and texture based retrieval system had been proposed by employing local extreme features which were able to capture the important information from the images [19]. In order to extract the edge information in the four directions Directional Local Extrema Pattern was proposed [14]. Another new method tetrolet transform had been used for the extracting texture features from an image along with edge and color. Edge histogram and color channel correlogram was used to extract edge and color features respectively [20].
Fadaei et al. proposed an effective CBIR system which is the triad of dominant color descriptor, discrete wavelet transform and curvelet transform [6]. This is combined by the optimized algorithm known as Particle swarm optimization (PSO). Color strings comparison based CBIR system was proposed. SVM is applied here for the classification of database [11]. Some of the latest CBIR systems that are designed using different feature extraction techniques and by employing divergent algorithms are tabulated in Table 1.
Latest surveyed CBIR systems
Latest surveyed CBIR systems
The main drawback of CBIR systems is semantic gap which is defined as discrepancy between the system understanding and human perception. To overcome these limitations different advanced algorithms were used. In [24] the efforts were put on to curtail the semantic gap by following the procedure of feature adaptation and selection. An efficient hybrid CBIR system was schemed and was compared using numerous distance metrics. Frequency and spatial features were used such as Stationary wavelet transform (SWT), Hue saturation value (HSV), histogram etc. [15].
Roung Zhao et al., 2000 presented a new approach named Latent Semantic analysis for image retrieval which was earlier used for text retrieval. The author had taken the database of 50 JPEG images containing ten semantic categories of five images each. By using LSA, the reduced dimensional feature image matrix was prepared and Singular value decomposition was performed on the matrix [30]. Mutasem K. Alsmadi, 2017 proposed an efficient CBIR system using memetic algorithm for retrieval of images from the large database. The important features like color signature, shape and texture were extracted and memetic algorithm was applied for the similarity measurement between query image and images in the database [1]. For increasing the accuracy of the CBIR systems, the researchers are now using various machine learning and deep learning algorithms for its designing. Different types of deep learning algorithms can be used here such as auto-encoders, Convolutional networks, back propagation networks, deep belief networks etc. for the purpose of feature extraction and classification [8, 13].
The considerable research gaps that exists in literature is Lack of intelligence Issue of semantic gap Complex and time consuming systems
Some of these issues are overcome to some extent in this implementation as the approach used in designing the CBIR system comprises of artificial intelligence algorithm and relevance feedback which solves the problem of semantic gap.
Variant techniques that are used for designing the proposed CBIR system are detailed in below headings.
Color moment
Color is the utmost considerable feature among all the low level features. Many techniques are being used for the extraction of color such as color histogram, color moment dominant color descriptor, color coherence vector etc. Out of all these techniques, color moment is deployed here as it is fast, more scalable, robust and much effective than others while other has some limitations also. Such as color histogram is fast technique but it does not provide spatial information. Secondly, Dominant color descriptor (DCD) is an effective technique and provides good results but this technique takes a large computational time. Other approaches used for this feature extraction are Color auto-correlogram (CAC) and Color coherence vector (CCV). Although these techniques provide spatial information and good results but the main issue with them is that they are noise sensitive and they also have a high computational time [17].
So, looking to all these points, color moment is preferred over other color extraction techniques. It is rotation and scale invariant technique. It also provides spatial information by calculating different moments. Color moments denote the metrics which conveys the color distributions present in the images. This technique provides spatial information present in the images. Different statistical measures are computed which are known as first and second order moment respectively and are defined in Equations (1) and (2).
Mean gives the information of the average color in an image.
X r = Information of color channel
M, N=Size of rows & columns
Pxy is the image pixel value in xth row and yth column
The second color moment is Standard deviation that is achieved by the distribution of color in the particular image. The square root of variance is called standard deviation and is given as:
The next color moment is Skewness which provides the information of the asymmetric characteristics present in an image. It is given in Equation (3).
Like color, texture is also the most important feature for retrieval of images and when these two features are combined they form an effective CBIR system. Texture techniques are basically divided into two categories statistical based and transform based. Transform based techniques implements faster and some of them are rotation invariant also but the main issue with them is that they are very much delicate to noise and environmental conditions. But the statistical techniques overcome all these limitations. LBP is a statistical based approach.
This approach is extensively used in many applications because of its simplicity, robustness and illumination invariance properties.
While its implementation, firstly the RGB images are transformed into gray scale [18]. The image is divided into smaller number of sub-matrices which are merged to form a one specific feature histogram which represents the entire image [21].
Support vector machine (SVM)
The Machine learning algorithms are categorized into three types: Supervised, Unsupervised and Reinforced learning algorithms.
First learning model i.e. Supervised learning, in which the system is trained on the basis of labeled data and the unlabeled data is used in case of unsupervised learning. SVM is based on supervised learning model which is analyzed here on two CBIR benchmark datasets. It basically works by finding a hyper-plane which classifies the data accurately. Here, multi-class SVM is employed as output classes obtained are more than two [2]. Various other classifiers can also be used such as Decision tree, Random forest, K-nearest neighbor (KNN) etc but there are some issues present in them such as Random forest do not yield accurate result, KNN takes so much training time etc [12]. Therefore, we have chosen SVM here for our experiments as classifier in machine learning model.
Cascade forward back propagation neural network
It is a type of deep learning technique which comprises of neurons just like a human brain. Their work is inspired and influenced by human brain which learns from huge amount of data. These deep learning are the subset of artificial intelligent (AI) models and uses the cascade of many layers of neurons for the operation. They have wide range of applications such as classification, feature extraction, pattern recognition etc. Here CFBPNN is used as a classifier along with SVM.
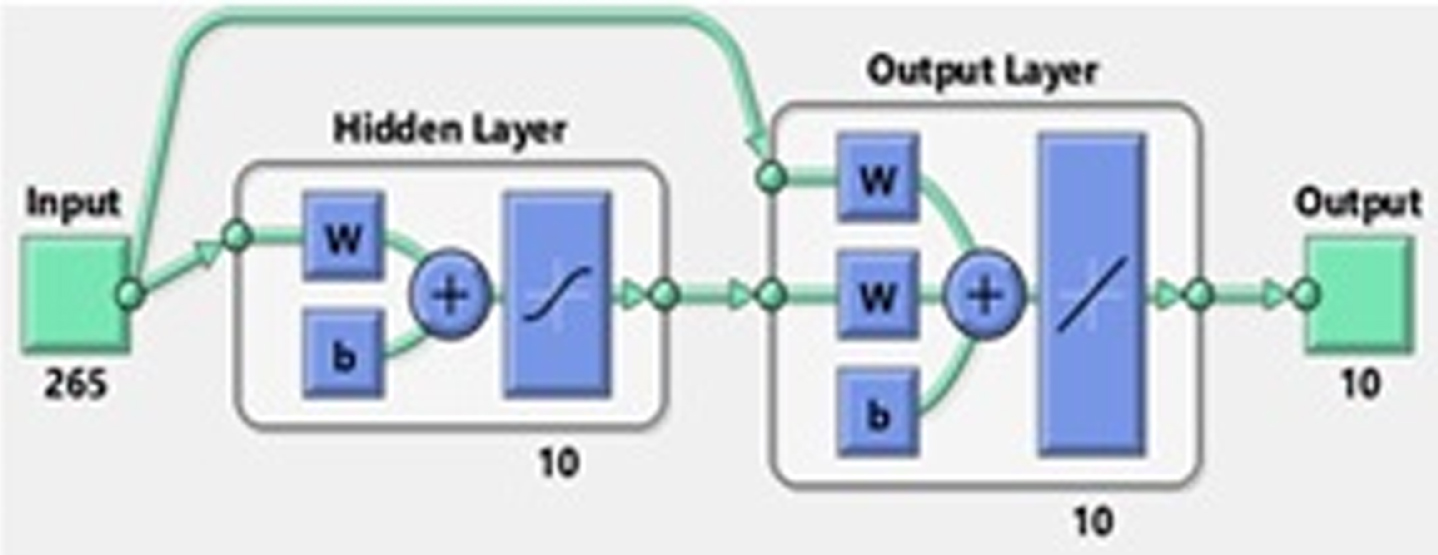
This AI model is the cascading of multiple layers comprising of one input, one output and multiple hidden layers. In its training time, while computations are going on from input to output layers the errors propagates back to the preceding layers. Hence, it is referred as Back Propagation (BP) network [16]. The layers of CFBPNN are described in Fig. 2.
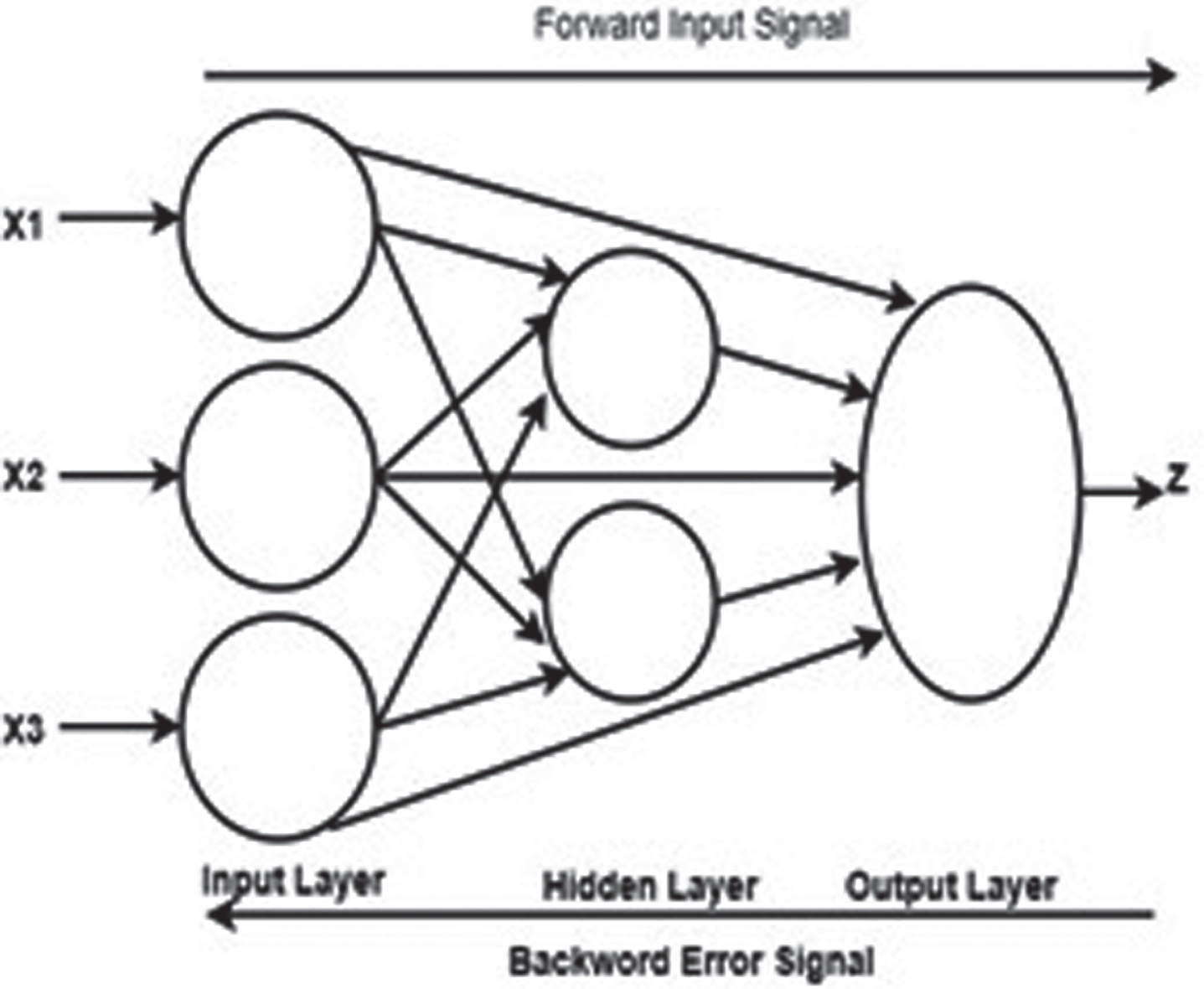
Basic architecture of CFBPNN.
In this network, all the neurons of the input layer are connected to the neurons of the hidden layer along with every neuron of the output layer [7].
Here, in this network Levenberg-Marquardt back propagation is used as a training function and Gradient descent with momentum weight and bias learning function is used as adaption learning. The training and updation of weights is done with the help of following equations.
In the above Equation (4) and Equation (5) x i (t) is the input value of i at time t. w in (t) is the weight that is assigned by neuron n at time t. b on (t) is the bias of neuron at time t and O n (t) is the output of neuron n at time t.
The weights are adjusted so as to minimize the errors between the desired and actual network’s output and this process is called as the learning phenomena of the network. Iterative procedure is used for the adjustment of weights. Using error function actual output is compared with the target output given in Equation (6)
Then, the error for the hidden layer neurons is given by Equation (7)
Here, δ n is the error function of the output and it is propagated backwards from output to input for amending the weights of every connection.
In Equation (8) γ is the learning rate and the momentum factor is α.
The underlying issue prevailing in CBIR systems is semantic gap which is the variation between the image features which are captured by the system and high level human perception. So, in order to overcome this gap Relevance Feedback (RF) technique has been used. It is a approach which helps in refining a specific image depending upon the feedback from the user. While working with CBIR systems set of relevant images are retrieved when a particular query image is entered into the system. The recovered images are then inspected by the user. Afterwards the query image features are optimized by the technique known as Relevance feedback which chooses the best matching images. The process works repeatedly till the user gets satisfactory results [3].
Here, in the designed framework to reduce the issue of semantic gap Rocchio’s algorithm is implemented. Rocchio’s algorithm is basically a query refitting technique whose objective is to take out an optimized query vector by raising the resemblance with relevant images and reducing the resemblance with irrelevant images. The optimized query vector by this algorithm is computed by Equation (9).
Where, q o is the original vector, q rel are set of relevant feature vectors and q nrel are the of non relevant feature vectors. q opt is the optimized query vector generated after iteration.
a, b and c are the weights which are combined with every term.
The basic research behind the implemented approach comprises of the following steps. These steps are shown graphically in Fig. 3. In the first step, images are transformed into required color space which is known as pre-processing of images.
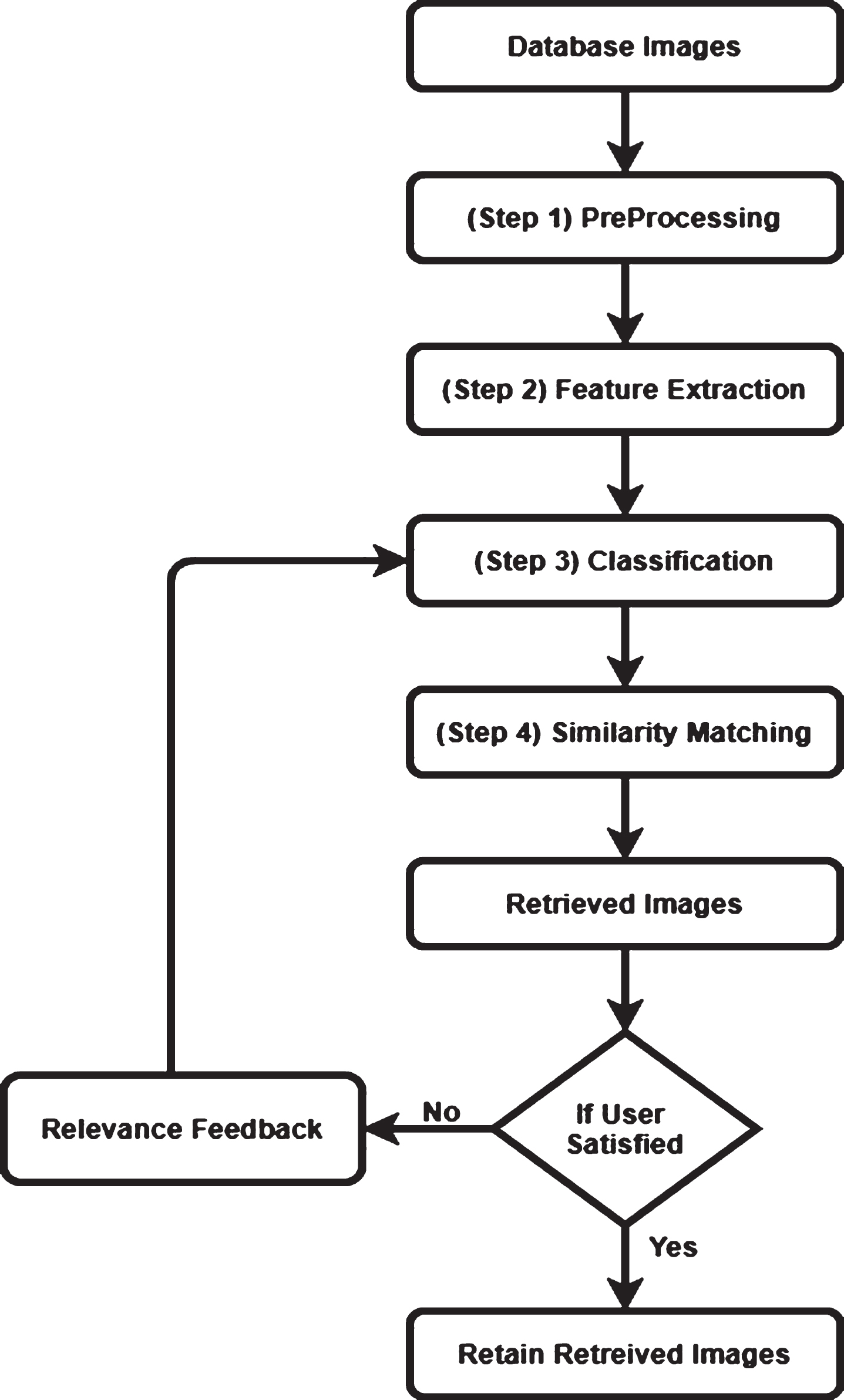
Basic steps of implemented work.
After that features are extracted from the images as they are necessary to define the contents present in the images. The next phase is classification. The feature vectors created after the step of feature extraction of database images are given as input to the classifier. Then the classifiers are trained with that particular database images. The output of classifier is categorization of images. Now the similarity matching of the query image is performed with its belonging category only. After this step the retrieved top N images are aligned according to the distance metric.
After this in this implemented work high level features comes into account i.e. human perception. To reduce the issue of semantic gap relevance feedback algorithm is applied if the output retrieved images are not according to the user. The classifier is again retrained with the feature vectors of relevant images. This is how all the steps of research methodology works.
In this designed framework, an exclusive CBIR system is designed in which color and texture features are used to describe an image. Color moment and LBP techniques are used here for the extraction visual features. The joint feature vector becomes incredible as color moment provides spatial features of an image and LBP has many characteristics such as scale and illumination invariant, noise resistant etc.
After that, two models are proposed and best among them is evaluated on two standard CBIR datasets. First is machine learning model (SVM+RF) and the second model is (CFBPNN+RF) which is based on deep learning network.
For enhancing the accuracy of the designed system, SVM/CFBPNN has been applied here whose purpose is the classification of images so that the similarity step becomes faster and easier. Relevance feedback is also incorporated here from which feature vectors are modified and based on that the SVM/CFBPNN is retrained by the features of output retrieved images till the user gets satisfied. Here, in our proposed work single iteration is performed in the process of relevance feedback. The testing and training images are taken in the ratio of 30 and 70. The training and testing phases are shown in the Fig. 4.
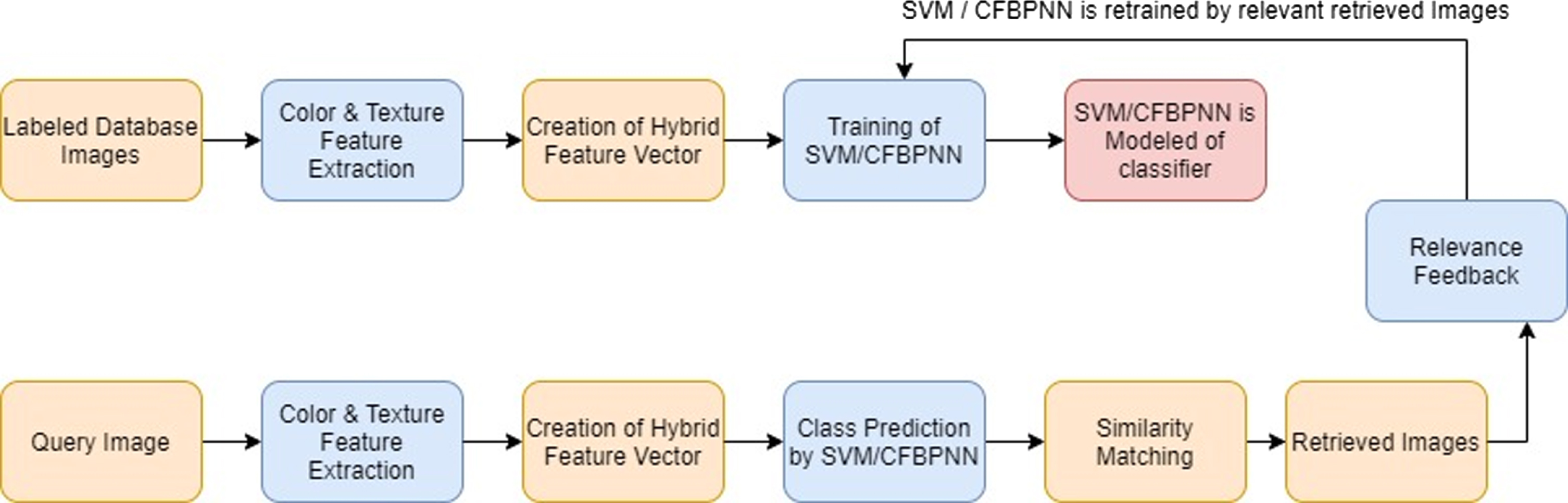
Proposed block diagram of CBIR system.
The steps of the training and testing are given as:
During training phase: Features of database images are extracted using CM and LBP technique. These are united for the formation of a hybrid feature vector through the technique of normalization shown in Equation (10)
Where, n is specific value of a defined feature, maximum is the highest and minimum is the bottom value of the feature. SVM/ CFBPNN is trained as a classifier by these hybrid feature vector of the images and modeled as a classifier and multiple classes are formed.
During testing phase: The features of the query image are extracted and a similar hybrid feature vector is obtained by the similar process. This image is classified into the most matching class and from that similarity matching step is performed. Top 10 images are retrieved and after that a single iteration of RF is performed and classifiers are retrained to get the desired results.
Performance evaluation parameters are computed such as precision, time, recall, accuracy etc.
The Graphical User Interfaces (GUI) are also devised to test the performance by pictures.
Experimental set up
For analyzing the capability of the designed framework, two benchmark datasets of CBIR systems are being tested. Divergent type of images are there in these datasets and have been used for examine various CBIR models. The small description of these datasets and their sample images are shown below in Fig. 5(a) and 5(b).

(a) Sample images from Corel-1K database. (b) Sample images from Oxford flower database.
For checking the competency of any designed CBIR system, many evaluation parameters exists but out of them precision and recall are the most important figures. Experiments are conducted by taking the above mentioned training and testing ratio and average precision and recall values are evaluated as shown in Equations 11 and 12.
For similarity matching between the query image and database images Euclidean distance measure has taken which is given in Equation (13) and in these experiments top 10 images are retrieved.
Here q x and c x are the feature vectors of query and classified images respectively. The working parameters are shown in Table 2.
Working parameters used in experiments
Firstly, experiments are conducted on the hybrid CBIR system i.e. CM+LBP and their average value of precision is evaluated. After that, the similar experiments are conducted on our designed CBIR systems which are Hybrid+SVM and Hybrid+SVM+RF which depict a high level of improvement as compared to the simple hybrid CBIR system. All these experiments are conducted on Corel-1K dataset and Oxford flower dataset with testing and training ratio 30 and 70 and the average value of precision is calculated. The experimental results of these three CBIR systems in terms of average values of precision when top ten images are recovered are shown in Table 3.
Average value of precision of all designed CBIR systems (%)
Average value of precision of all designed CBIR systems (%)
From the above table, it is observed that when machine learning classifier is amalgamated into the system then the performance is increased to a great extent. After that when we do a single iteration of RF then also the little bit performance increases.
The same procedure as described in the above model repeats here but the difference is that, instead of SVM which is a machine learning algorithm, here CFBPNN is applied as a classifier which is an intelligent deep learning classifier. The training of a hybrid (CM+LBP) is shown in Fig. 6.
Training of a hybrid CBIR system using CFBPNN.
The experimental results in terms of average precision of this model are shown in Table 4.
Average value of precision of all designed CBIR systems (%)
It is undoubtedly clear from both the tables that second model with deep learning algorithm provides highlighted results as compared to the first model. It basically means that the average value of precision increases as we increase the value of intelligence in the system. With the addition of high level of semantics, the system becomes more accurate and efficient.
It has also been observed, in both these tables that Corel-1K provides comparatively higher results as compared to other dataset. The Confusion matrix created of Corel-1K dataset by CFBPNN classifier is shown in Table 5
Confusion matrix showing the accuracy of CFBPNN
Percentage correct classification: 90.4%. The confusion matrix signifies the accuracy of the classifier. The diagonal elements of the confusion matrix shows that from total of 100 images in 10 categories, how much relevant images are present handed per group.
Precision vs. Recall curves are also the most chief measures in order to check the implementation or capability of CBIR systems. In PR space as we increase the number of image retrieval, the value of precision decreases and recall increases. This precision and recall curve of finally designed deep learning based CBIR system (Hybrid+CFBPNN+RF) is shown in Fig. 7. Here the number of retrieved images is varied from 20 to 50.
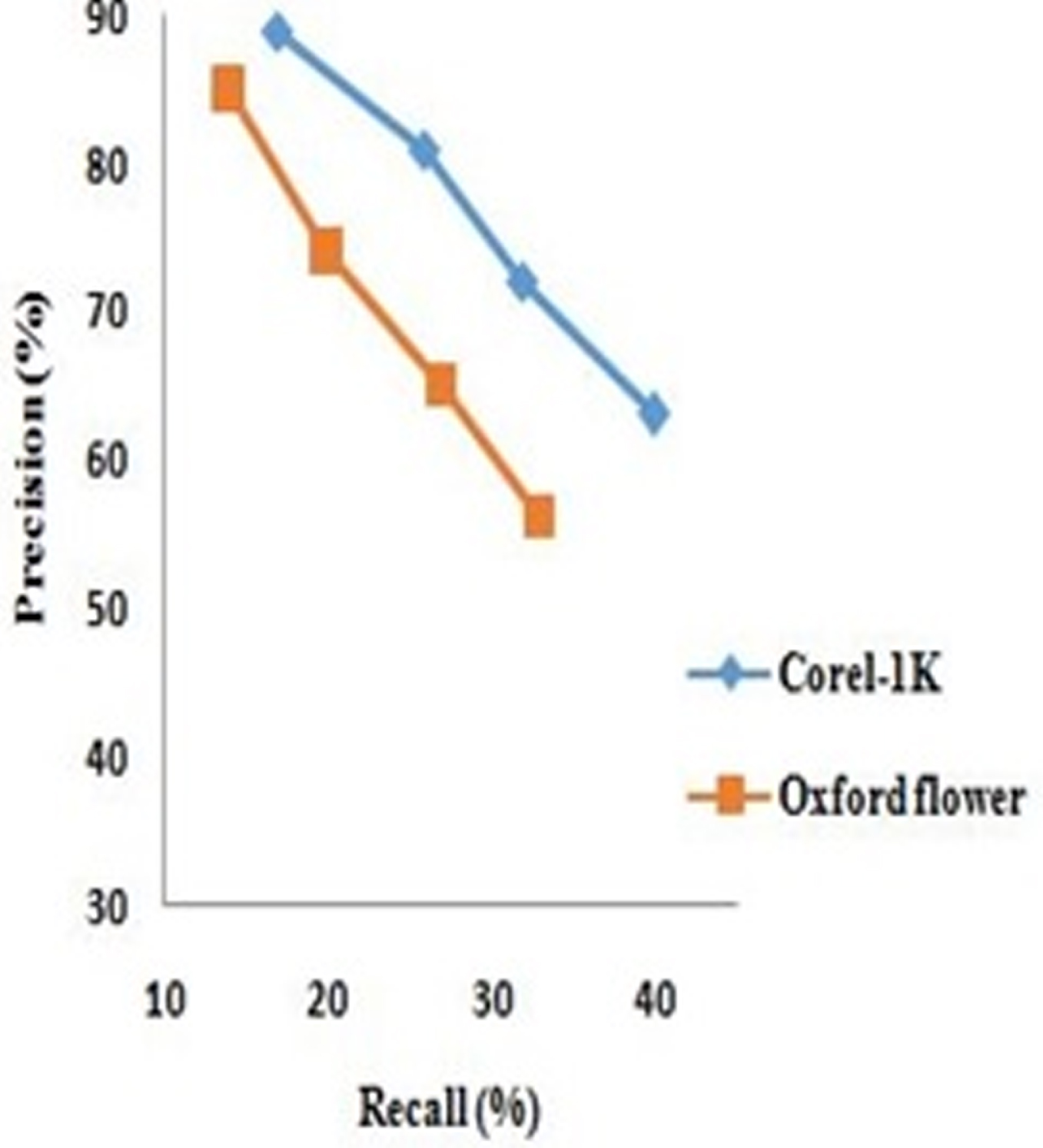
Precision Vs Recall plot of proposed system.
GUI’s are designed of both these databases on both classifiers. Based on the calculated distance measure finest ten images are retrieved by both datasets using our proposed model. Figure 8(a) and 8(b) shows the images retrieved from the Corel-1K dataset and Oxford flower dataset using CFBPNN classifier.
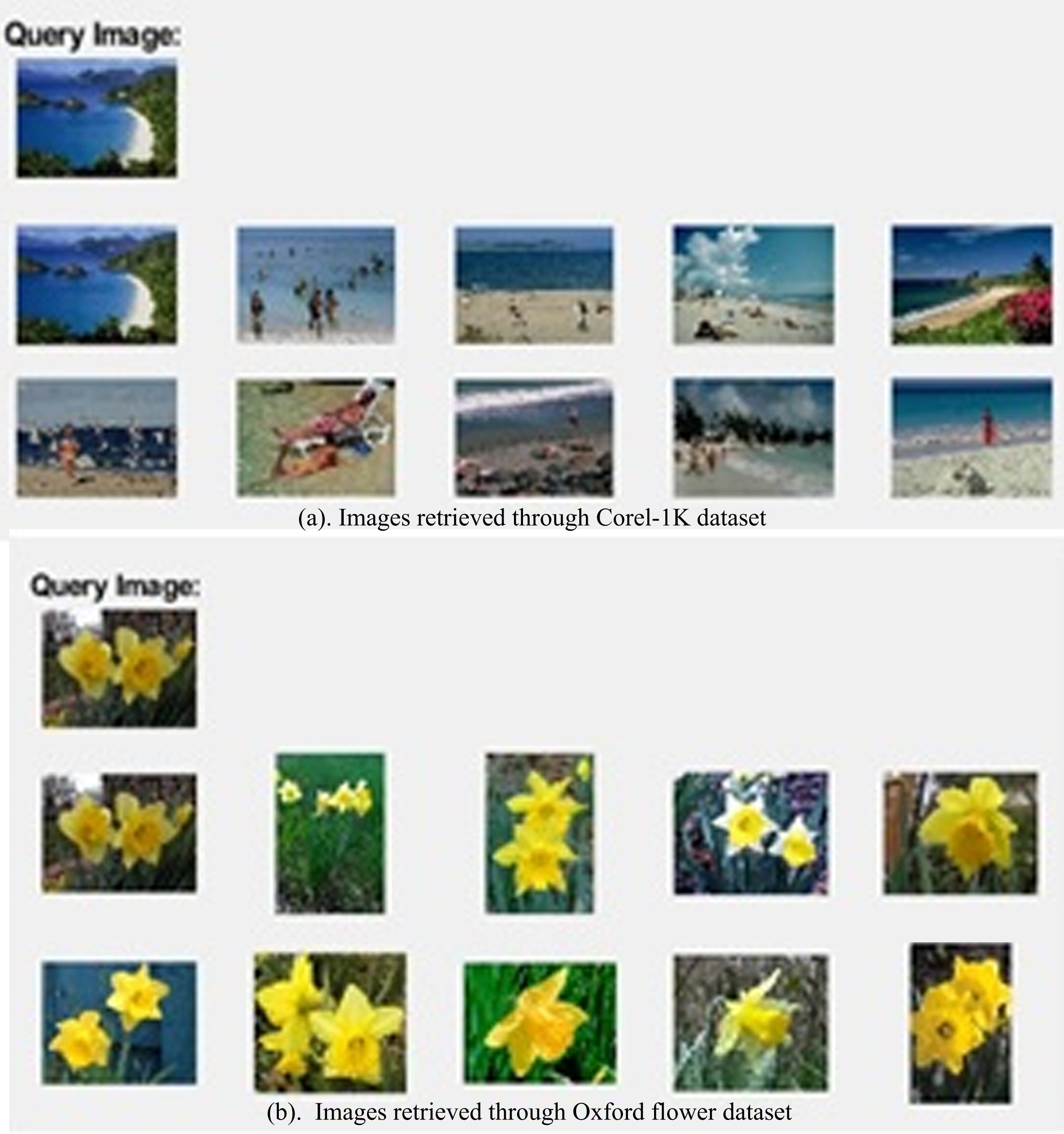
(a) Images retrieved through Corel-1K dataset. (b) Images retrieved through Oxford flower dataset.
From these figures it is clear that all the ten images are retrieved from its own category, thus the accuracy of the designed system is outstanding because of the formation of the hybrid feature vector and incorporation of the intelligent techniques.
In order to authenticate the performance of our designed system, it is compared with other related systems. The comparison is done in terms of very important parameter i.e. Average precision. The comparable analysis of the proposed model on both datasets i.e. Corel-1K and Oxford flower are shown in Table 6 and Table 7 respectively.
Comparison of the implemented model with other systems on Corel-1K database
Comparison of the implemented model with other systems on Corel-1K database
Comparison of the proposed model with other techniques on Oxford flower dataset
In Ref. [2] SVM classifier is used as a classifier and to extract the image features texture and shape techniques are used. In Ref. [6] PSO algorithm is used along with color and texture features.
On the basis of the results depicted in above tables it can be clearly visualized that our designed hybrid intelligent CBIR model is much more accurate and efficient than other techniques. The techniques which are compared here basically lacks in intelligence or having the issue of semantic gap which in turn reduces the retrieval efficiency.
Time investigation is also one of the most valuable parameter while considering the performance of CBIR systems. Time analysis of both the systems is done on both the models and is shown in Tables 8 and 9. The tables are further divided into feature extraction time, training time and retrieval or testing time.
Time analysis of Hybrid CBIR system with SVM
Time analysis of Hybrid CBIR system with SVM
Time analysis of Hybrid CBIR system with CFBPNN
The retrieval time of the designed framework is compared with other state of the art techniques in order to show its efficacy. As shown in Fig. 9 it has flashing retrieval time as related to other techniques. The comparison is done on Corel-1K dataset only.
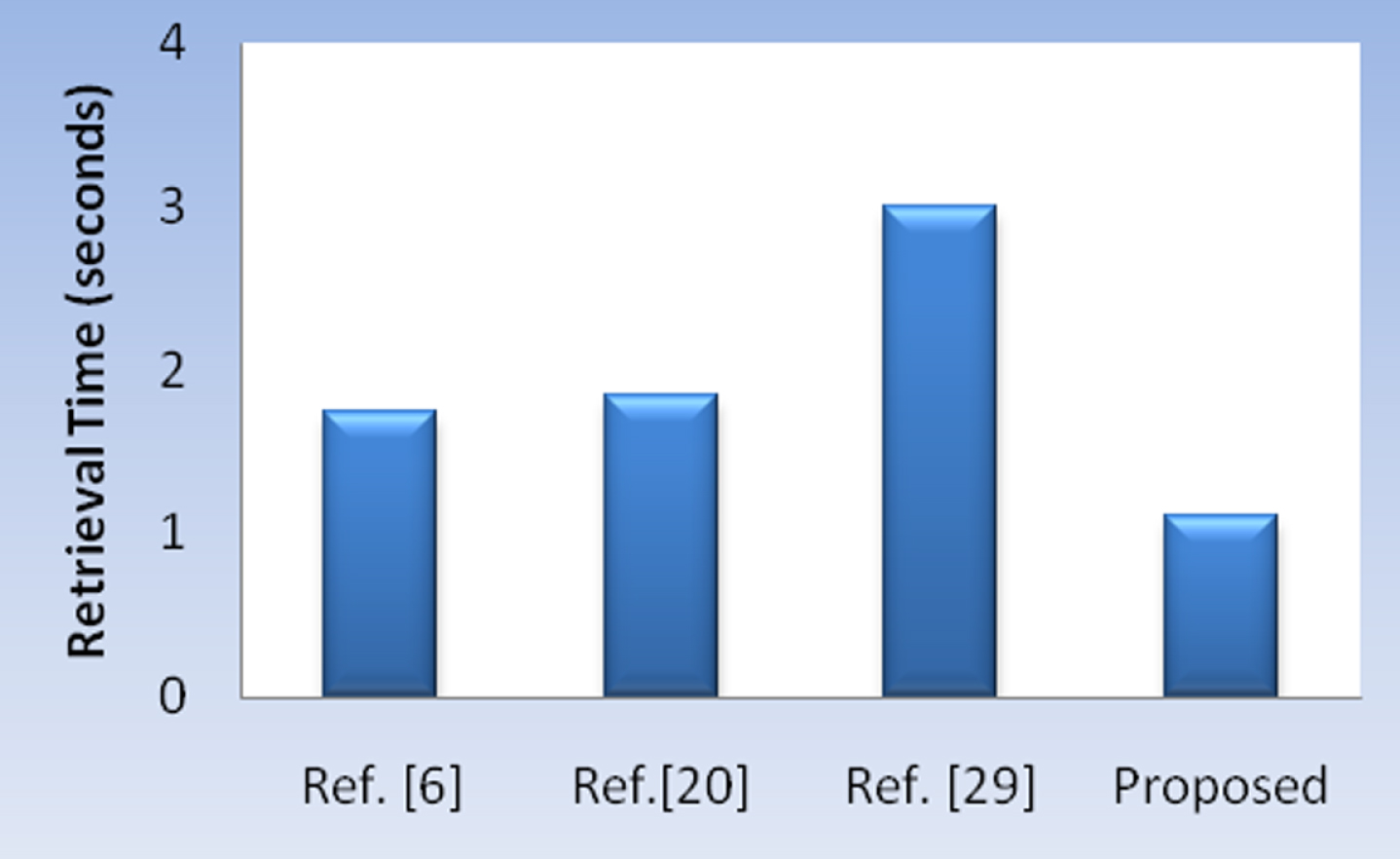
Retrieval time comparison of proposed method with others.
In this paper, innovative and efficient hybrid CBIR systems are designed in which intelligent techniques are incorporated. Also, the comparison between two CBIR models is carried out based on two classifiers which are SVM and CFBPNN. First model is based on machine learning algorithm and second one is based on deep learning algorithm. Firstly a capable hybrid feature vector is formed which is the combination of Color moment and Local binary pattern. After that this hybrid feature vector is fed to SVM and CFBPNN which acts as a classifier. Subsequently Relevance Feedback technique i.e. Rocchio’s algorithm is applied in a single iteration so as to grab the high level information of the images in both the models. Among these two models, the hybrid system with deep learning network (CFBPNN) hand over superior results as compared SVM based model but at the expense of training time.