
Abstract
We explore various machine learning-based classifiers applied to rule-based features for recognizing textual entailment. The features, extracted with a set of synthesized matching rules, reflect syntactic and semantic similarity between the text and the hypothesis. The fact that we use only seven relatively simple features makes our method suitable for low-resource languages. We test our method on the test sets of the RTE competitions and achieve accuracy of up to 69.13%.
Keywords
Introduction
Recognizing Textual Entailment (RTE) is a major challenge in natural language processing (NLP). Due to its applications in many NLP domains, such as information retrieval, information extraction, question answering [1], paraphrase acquisition, text summarization, reading comprehension, and machine translation, a number of RTE challenges have been organized by the PASCAL Network of Excellence, funded by the European Union, for many years.
RTE is the task of, given a pair of text snippets as input, deciding whether the meaning of one fragment (hypothesis, H) can be most likely inferred from the meaning of the other fragment (text, T) as would typically be interpreted by people. This establishes a directional relationship that holds from T to H (T entails H), but not necessarily from H to T (H does not necessarily entail T), as in the following example:
We present a hybrid method for solving the RTE task, which combines a small number of rule-based features with decision-making based on machine learning (ML). After pre-processing, the T– H pair is passed to a dependency parser to obtain a dependency graph structure. Next, a set of features is extracted to train a classifier to predict whether T entails H. This set of features includes summation of in-degree and out-degree of the nodes in the H’s dependency graph, named entity-matched ratio, antonym bit, negation bit, superlative degree modifier bit, and an overall entailment score. The features are calculated by a synthesized set of matching rules, which mainly reflect syntactic divergence augmented with semantic similarity measures. We test different combinations of our features on several ML-based classification algorithms available in the WEKA toolkit.
The paper is organized as follows. Section 2 discusses related work. Section 3 gives an overview of our method. Section 4 presents our feature set. Section 5 gives the experimental results. Section 6 presents error analysis. Section 7 concludes the paper.
Related work
A number of RTE methods have been reported in the literature. Some of them represent the text and hypothesis as syntactic dependency-parse trees and compare them to find out the degree of inclusion of H’s tree into T’s tree [2]. Many systems use some simple form of lexical matching such as n-gram matching, percentage of word overlap, longest common subsequence, or skip-gram matching. Some systems also use some form of semantic techniques such as semantic role labelling [3], atomic propositions [4], inference rules, universal networking language augmented with semantic similarity measures [5], etc. Recently, supervised classification techniques have become the predominant approach to the RTE task. ML-based techniques use text features classify the T– H pairs into those with and without entailment.
Rios and Gelbukh [6] assume entailment if the Levenshtein distance between T and H is below a threshold. Kouylekov and Magnini [7] use tree edit distance. Marsi et al. [8] use alignment of T and H dependency trees for the entailment decision. Herrera et al. [9] parse the T– H pair using Lin’s Minipar and then find a lexical entailment between each word in the hypothesis with some word in the text using WordNet relations such as synonymy, hyponymy, and antonymy to calculate the degree of inclusion of H in T. Blake [10] explores the degree to which the sentence structure plays a role in detecting textual entailment.
Pakray et al. [11] compare various features, including semantic roles, of syntactic structures of T and H. They use different weights for exact and partial matches. The weights are summed up and compared with a threshold to make the entailment decision. These authors also use anaphora resolution [12] and a combination of lexical, syntactic, and semantic features [13]. Dinu and Wang [14] use an inference rule-based technique. They start with a collection of inference rules acquired automatically basing on the distributional hypothesis and refined by obtaining more rules using a handcrafted lexical resource.
Malakasiotis and Androutsopoulos [15] use four support vector machines (SVM), one per subtask of the RTE3 challenge, with features based on string similarity measures at the lexical and shallow syntactic level. MacCartney et al. [16] use 28 features, such as polarity, adjuncts, antonymy, and factivity, to train a logistic regression classifier. Szpektor and Dagan [17] learn entailment rules for unary templates in an unsupervised way, using dependency parse trees. Mirkin et al. [18] use an integrated approach: they acquire the candidate entailment, construct a feature set for all candidates using pattern-based and distributional information, and train SVM on these features to integrate systemically different feature types.
Li et al. [19] extract features such as lexical semantic similarity, named entities, average distance, dependent content word pairs, text length, negation, etc. from the T– H pairs of the RTE3 dataset and run a decision tree (J48) on several feature combinations. Pham et al. [20] use features such as the longest common subsequence of T and H, word overlap, Levenshtein distance, named entity match, polarity match, etc., to train an SVM classifier. Zanzotto et al. [21] use supervised ML to derive first-order rewrite rules from annotated examples. Agichtein [22] use categories of features such as lexical similarity (word overlap, cosine similarity, substring similarity, etc.), syntactic similarity (mainly role similarity and POS similarity), and semantic similarity (several WordNet similarity measures such as Resnik, Lin, and Wu-Palmer measures, etc.) to train ML-based classifiers such as J48, SMO, and Naïve Bayes.
Saikh et al. [23] use as features a number of lexical and vector-based similarity measures, plus two machine-translation evaluation metrics: BLEU and METEOR. They use several feature combinations to train ML-based classifiers such as SMO, AdaBoostM1, J48, LibSVM, etc. Rios et al. [24] use a cosine similarity measure and a causal non-symmetric measure as features for ML, obtaining best results with SVM and Naïve Bayes classifiers. Castillo [25] trains a SVM classifier on a variety of lexical and semantic features such as TF-IDF measure, Jaro– Winkler distance, and Euclidean distance.
Basak et al. [26, 27] make the entailment decision by comparing the dependency tree structures of T and H based on a number of dependency triple matching rules manually extracted from the RTE datasets. In [26], for a matching T triple for an H dependency triple, a matching score in the range of [– 1, 1] is assigned to the dependent node associated with that H triple. Finally, the H dependency tree is traversed in level order from the bottom level and the scores of the nodes are calculated and propagated to the upper levels. The entailment score between the T– H pair is obtained at the root node of the tree at the end of the traversal process. In the present paper, we mainly use the features designed with matching rules described in [26].
Outline of the method
Our experiments included the following steps: pre-processing, dependency parsing, lexical alignment (using WordNet 2.1 and a stemmer), dependency graph representation, feature selection and analysis (using named entity tags and a set of matching rules), and entailment classification (using a combination of features and an ML-based classifier). Subsequent subsections illustrate the individual components.
Pre-processing
Before the actual TE recognition process is invoked, each T– H pair is fed to a number of pre-processing phases illustrated below.
Feature extraction and classification
After stemming of both T and H, the lexical alignment between the token pairs is performed; see Fig. 1. The arrows represent the alignment between the corresponding tokens of H with one or more tokens of T, and colors indicate different WordNet relations by which the tokens are associated. However, one hypothesis token may be lexically aligned to more than one text token. The dashed lines are used in the diagram to indicate one-to-many mappings and the thick lines indicate the one-to-one mappings.
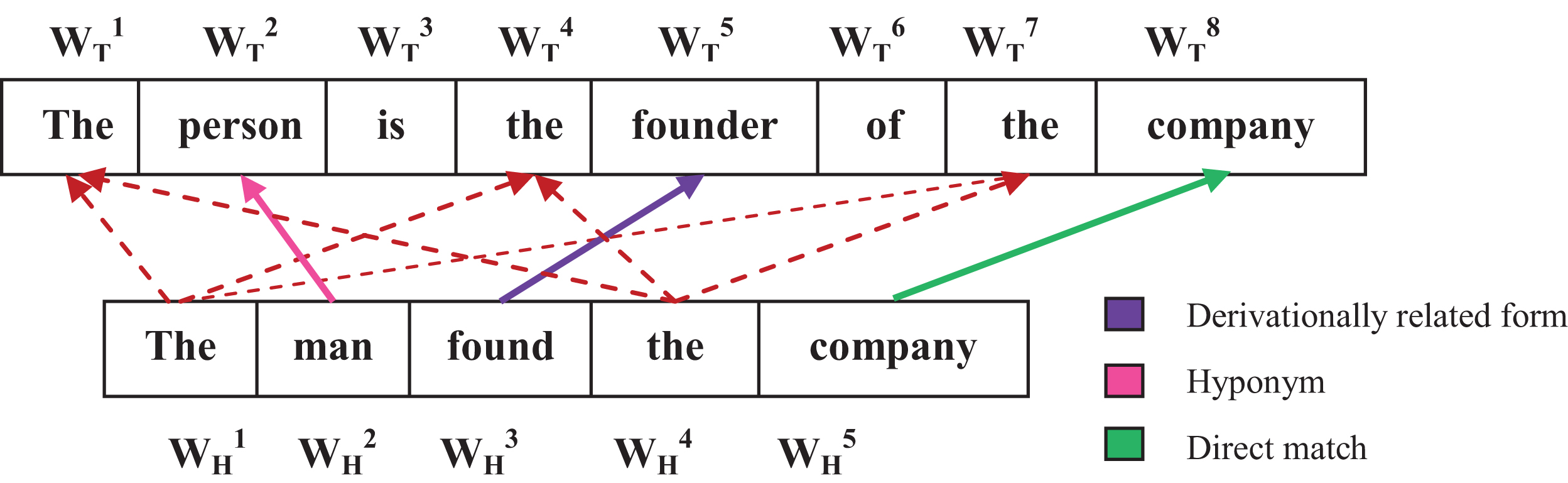
Lexical alignment between text and hypothesis tokens.
The features we used are summarized in Table 1.
Features used in our experiments
Features used in our experiments
Each node in the H dependency graph is assumed to have six score components of in_degree and out_degree, as summarized in Table 2.
Assignment of values on the in_degree and out_degree components of the hypothesis graph
Assignment of values on the in_degree and out_degree components of the hypothesis graph
After generating the dependency graph by combining all dependency triples, the in_t and out_t components of each node are calculated by counting their incoming and outgoing edges. The components in_m and out_m are calculated using various matching criteria. Each H dependency triple RH (W1, W2) is compared with all T triples. When a matching triple is found, a matching score in the range [– 1,1] is assigned to in_m and out_m components of the H nodes W2 and W1, respectively, by synthesizing a set of matching rules from [26] built by analyzing the development sets of RTE. The process can be illustrated by an example from the RTE1 development set, with dependency triples shown in Table 3:
Dependency triples of the T– H pair of Example 3
Simulation of matching between the T– H dependency triples of Example 3
Score components of each node in of Example 3
Named entities (NE) are important information carriers in text. It is a general assumption that each NE of the hypothesis H must be contained in the text T in order to be entailed by T. Otherwise it is very likely that H cannot be entailed from T.
This feature calculates the ratio of the number of NEs common between the text and the hypothesis to the total number of NEs in the hypothesis. If the hypothesis does not contain any named entities, this ratio is set to 1.
If NE_S(T) and NE_S(H) indicate the set of named entities in the text and hypothesis respectively, the named entity matched ratio is
Consider a T– H pair as example with the named entities being highlighted in bold fonts.
Here NE_S(T) = {John, Sam} and NE_S(H) = {John, Mary}, which indicates |NE _ S (T) ∩ NE _ S (H) |=1. Therefore this ratio for the given T– H pair is 0.5.
Antonym bit (F4)
If any hypothesis dependency triple RH (W1, W2) matches with any of the text triples according to matching rule 4 from [26], then a score of – 1 is assigned to the in_m component of the node W2 and to the out_m component of the node W1. Negative scores are assigned to the in_m and out_m components of hypothesis nodes W2 and W1 in order to lower the values of the feature variables F1 and F2 aiming to classify the T– H pair as a case of no entailment. Moreover, it also sets the value of an antonym bit (Feature F4) to 1. By default (on detecting no antonymy), the value of this bit is set to 0.
An example T– H pair from the RTE development set is presented in Example 5 to show how the presence of antonym between a text– hypothesis pair affects the values of the feature variables F1 and F2:
Some of its dependency triples are presented in Table 6. The tokens
Dependency triples of the T– H pair of Example 5
Dependency triples of the T– H pair of Example 5
Simulation of matching between the text– hypothesis dependency triples of Example 5
Table 8 lists the value of the six score components of each node of the hypothesis dependency graph of Example 5 after matching of triples is performed. The features of summation of in_degree (F1) and out_degree (F2) for Example 5 are:
Values of the score components of each node of the hypothesis dependency graph of Example 5
For a triple indicating a negation relation in the form of RN (W, WN) according to matching rule 5 from [26] in any of T or H, the in_m score component of each of the H nodes W’ originating from node W is set to in_m = in_m – 1 and the out_m component of the H node W is set to out_m = out_m – 2 × out_m. In addition, the value of a negation bit (Feature F5) is set to 1. A node W’ is said to be originating from the node W if they are connected by a triple in the form of RH (W, W′) in the dependency graph.
We choose the values of in_m and out_m components of the designated nodes as above to bring down the final values of the feature variables F1 and F2 to a significant extent so as to classify the given T– H pair as a case of NO entailment. The lower the values of F1 and F2, the more likely it is that the given T– H pair is classified as a case of no entailment.
However, if no such negation relations are found in the text and hypothesis or if both the text and hypothesis triples are associated with negated triples satisfying any of the categories of 1 or 2 of rule 5, the value of this feature variable F5 is set to 0.
Consider an example from the RTE dataset:
In order to show how the values of the feature variables F1 and F2 are calculated on encountering a negated triple, the dependency triples of the T– H pair of Example 6 are presented in Table 9.
Dependency triples of the T– H pair of Example 6
Dependency triples of the T– H pair of Example 6
From the triples in Table 9, it is clear that the H triples H1−H3 and H5 directly match with the text triples T1, T3, T4, T6, respectively, according to matching rule 1 and H4 satisfies the matching rule 7 from [26]. After performing these matching operations, the values of the score components (in_t, out_t, in_m, out_m) of each node in the hypothesis dependency graph are shown in Table 10, left.
Score components of each node before and after applying negation rule
Upon finding the negated triple T5 in the text, the out_m score component of the hypothesis token
Therefore, the features summation of in_degree F1 and of out_degree F2 are assigned as follows:
This feature bit is set to 1 if the superlative degree present in T and H is modified by same adjectival modifier or the arguments of the superlatives are modified by same modifier, as illustrated by the following examples, correspondingly:
On detecting a dependency triple involving a superlative degree either in the text or hypothesis, it is checked whether it is modified by some adjectival modifier. If that superlative degree is not modified by any modifier in the hypothesis or text or modified by some other modifier, then the out_m component of the node with the superlative degree (
On the other hand, if the superlative degree either in the text or hypothesis has some argument (
The motivation behind the way of assigning values to in_m and out_m score components of the respective hypothesis nodes is the same as that of negation handling as explained before (cf. the previous subsection). The aim is to lessen the final values of the feature variables F1 and F2 so that the given T– H pair may be marked as a case of negative entailment.
To show the impact of the presence of superlative degree in T or H on the features F1 and F2, Table 11 provides the text and hypothesis dependency triples of the T– H pair of Example 7.
Dependency triples of the T– H pair of Example 7
Dependency triples of the T– H pair of Example 7
From the triples as shown in Table 11, one can see that the H triples H1−H6 and H8 directly match with the T triples T1−T5, T7 and T9, respectively, satisfying the matching rule 1 from [26]. The four score components (in_t, out_t, in_m, out_m) of each node in the H dependency graph before applying the criterion of superlative degree are shown in Table 12, left.
Score components of each node before and after applying superlative degree criterion
Now on encountering the text triple T6, the out_m component of the H node
Therefore, the values of the features of summation of in_degree and of out_degree are as follows:
Following [26], we assign four score components to each node of the H dependency graph: a predecessor_score vector (P), average of the predecessor_score vector (A), child_score (C) and total_score (T) and 2 bits: ant_bit and neg_bit. On finding a text triple satisfying any of the matching rules for a hypothesis dependency triple RH (W1, W2), a matching score is assigned to the P score component of node W2 of the hypothesis graph. Finally the graph is traversed in level order starting from the bottom most level and gradually going up to the higher levels till the ROOT node is reached. During this course of traversal from the leaf nodes to the ROOT node, the other score components A, C and T of each node are calculated to come up with a final entailment score at the ROOT node. This final score obtained at the ROOT is used as a feature (F7) in our present work.
Experiments and results
We carried out experiments on several RTE datasets ranging from RTE1 to RTE4, in which the T−H pairs and the gold standard entailment decisions have been provided by the organizers of the corresponding RTE challenges. We used different combinations of the seven features, on which different models were trained using different ML-based classifiers; see Table 13.
Different models combining several features
Different models combining several features
Figures 25 show the performance of the classifiers with our models on RTE1 to RTE4 testsets. For all datasets, the LogitBoost classifier exhibits the best performance attaining 61.88%, 66.38%, 69.13% and 64.3% accuracy for RTE1 to RTE4 datasets, respectively. For the RTE3 testset (Fig. 4), the J48 classifier also attains the best accuracy along with LogitBoost.

Accuracy on RTE1 testset.
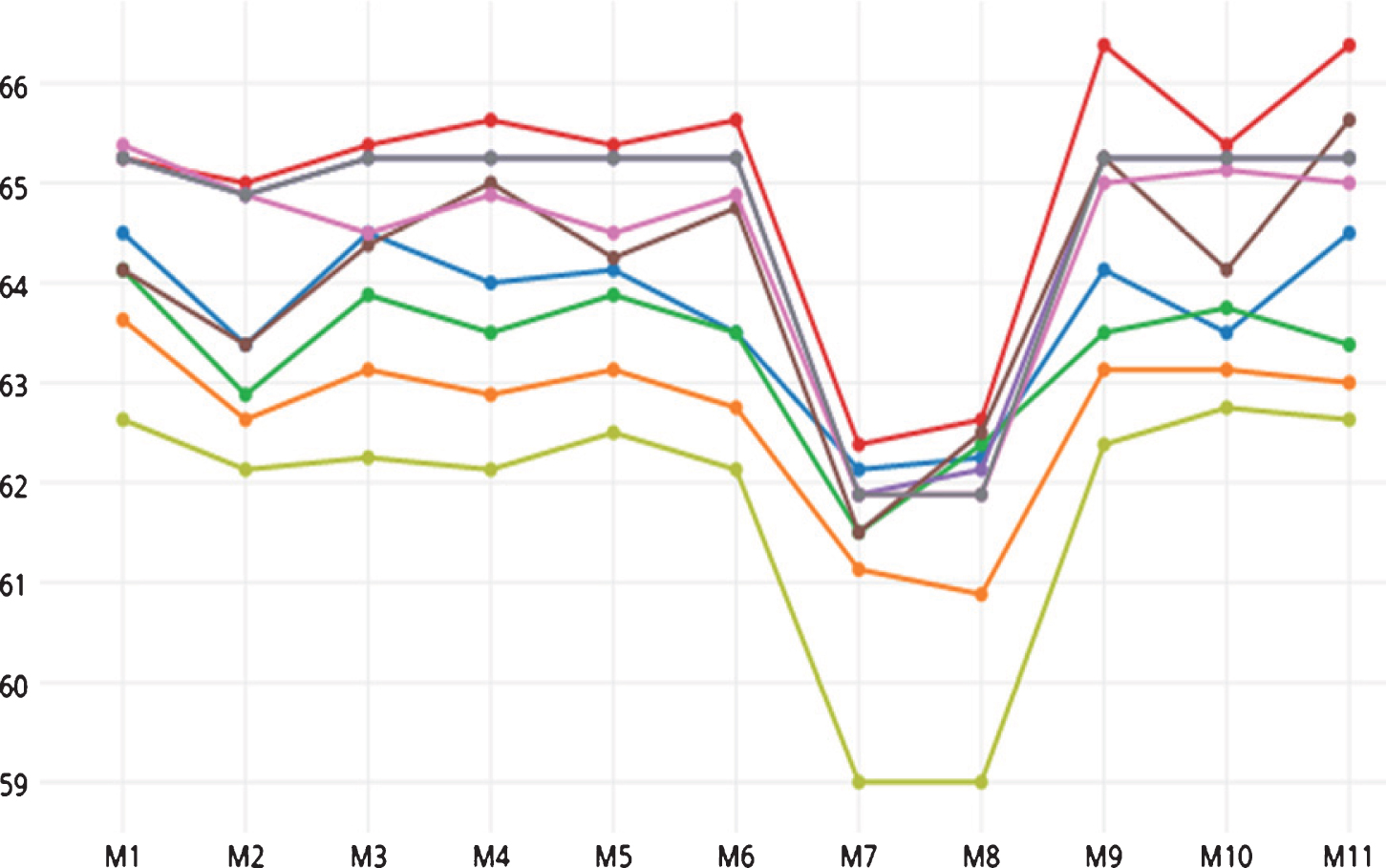
Accuracy on RTE2 testset.
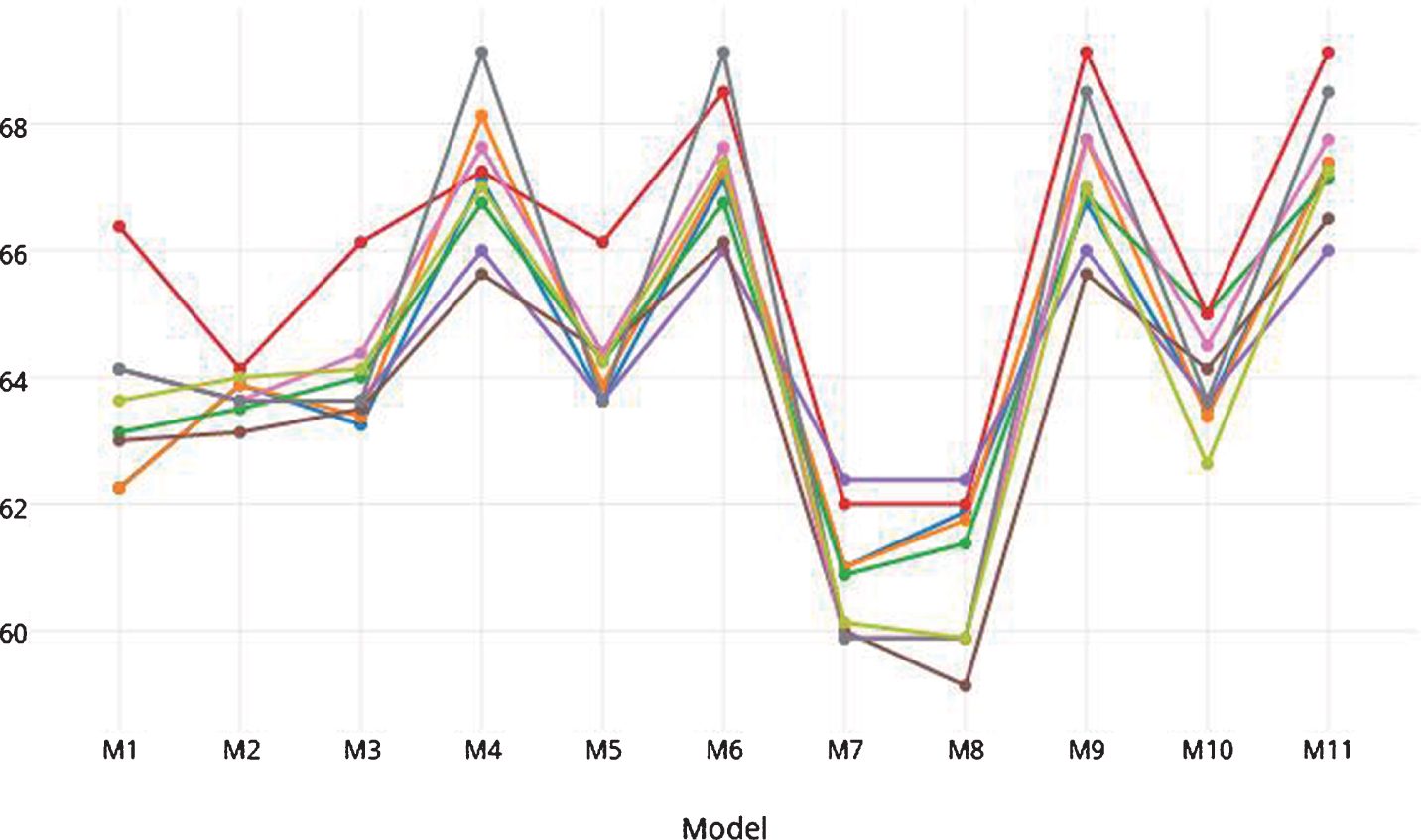
Accuracy on RTE3 testset.
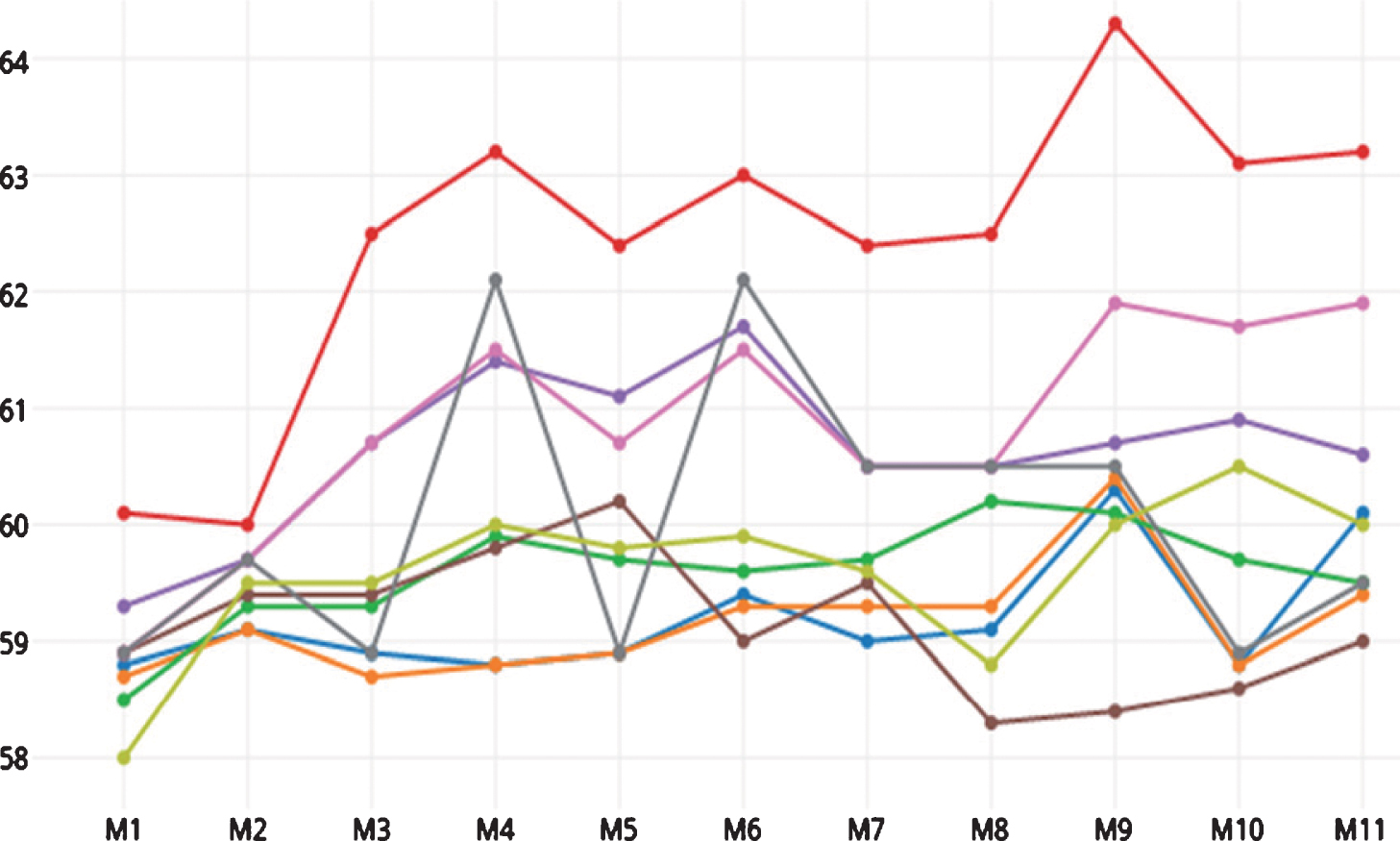
Accuracy on RTE4 testset.
Model-wise performance shows the role of different combinations of our seven features. Among these, F1 and F2 serve as the baseline ones. Since model M11 combines all features, all of which we deem as important in making entailment decision, one would hope that it should achieve the best performance. However, Fig. 6 shows that with some classifiers M9 performs slightly better than M11.
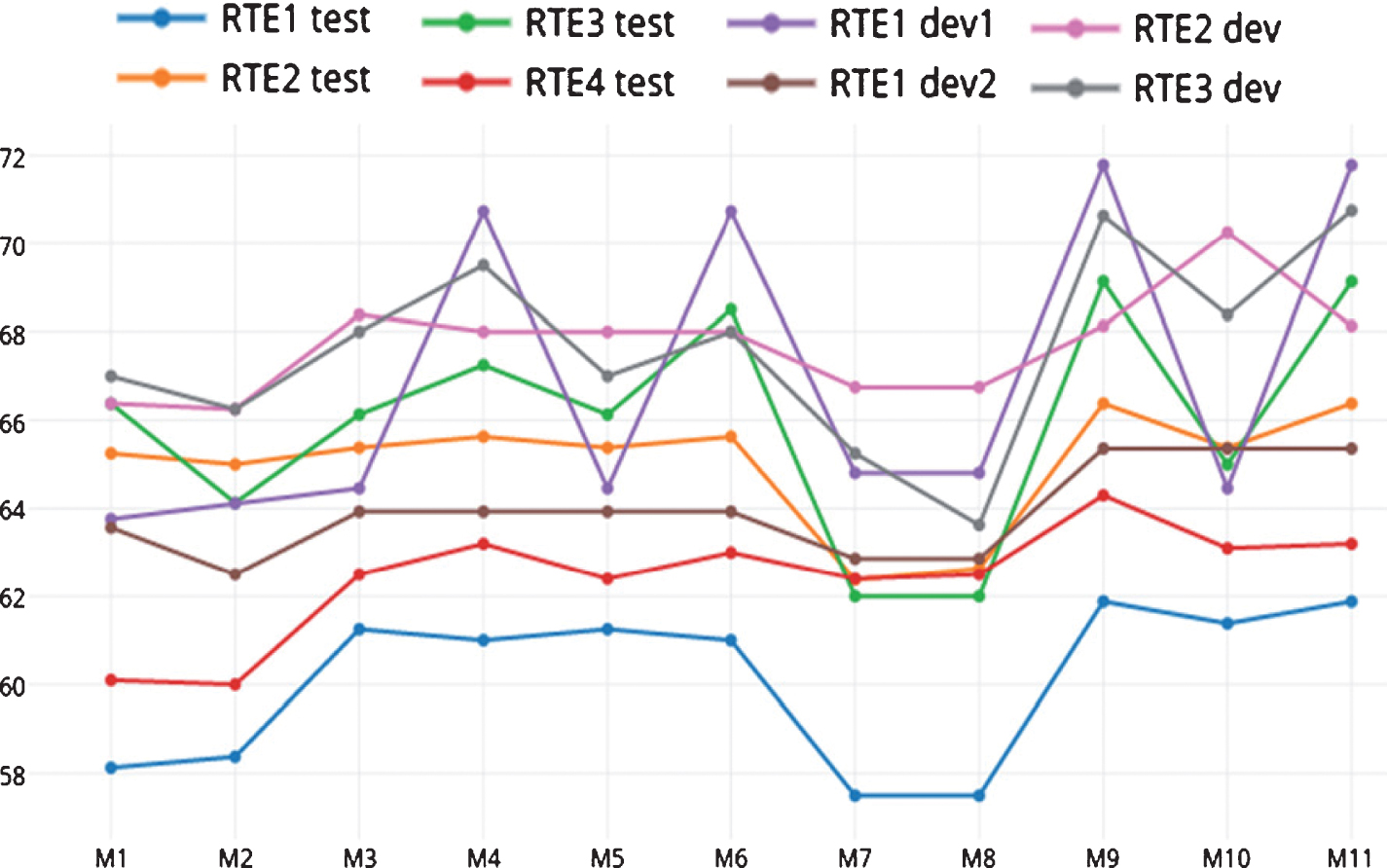
Model-wise performance evaluation using LogitBoost algorithm.
The role of F3 (named entity-matched ratio) is seen by comparing the model pairs M3– M4, M5– M6, and M9– M10 on different datasets and classifiers. The role of F4 (antonym bit), F5 (negation bit), and F6 (superlative degree modifier bit) is seen by comparing the pairs M3– M5, M4– M6, M7– M8 and M9– M11. The role of F7 (entailment score) is seen from the pairs M3– M10, M4– M9, and M6– M11.
From Fig. 2, comparing the performance of the model pairs M3– M4 (for Logistic, Simple Logistic, Multilayer Perceptron, and NaiveBayes) and M9– M11 (for Logistic, Simple Logistic, SMO, and LogitBoost) indicate that the feature F3 is useful in improveing the accuracy. Slight improvements in the model pairs M3– M5 (for Simple Logistic, SMO, Multilayer Perceptron), M4– M6 (for Simple Logistic, SMO, Multilayer Perceptron), M7– M8 (for SMO, Multilayer Perceptron, J48) and M9– M11 (for Simple Logistic, SMO, Multilayer Perceptron, J48, Naivebayes) show that F4, F5, and F6 are important.
The role of F7 is seen from the model pairs M3– M10 (for Logistic, Simple Logistic, SMO, LogitBoost, Multilayer Perceptron, and NaiveBayes), M4– M9 (Logistic, SMO, LogitBoost) and M6– M11 (Logistic, Simple Logistic, SMO, LogitBoost, Multilayer Perceptron, J48). The model pairs M3– M4 (for the curves of LogitBoost, Multilayer Perceptron, BayesNet) and M9– M10 (for Logistic, LogitBoost, Multilayer Perceptron) in Fig. 3 show the role of F3.
The model pairs M3– M5 (NaiveBayes), M7– M8 (for Logistic, SMO, LogitBoost, AdaBoost, Multilayer Perceptron) and M9– M11 (for Logistic, Multilayer Perceptron, NaiveBayes) show the role of F4, F5, and F6. The role of feature F7 is seen from the model pairs M3– M10 (for BayesNet, NaiveBayes), M4– M9 (for Logistic, Simple Logistic, LogitBoost, Multilayer Perceptron, BayesNet, NaiveBayes) and M6– M11 (for Logistic, Simple Logistic, LogitBoost, Multilayer Perceptron, BayesNet, NaiveBayes).
The curves in Fig. 4 reveal the importance of feature F3 on comparing the performance of the model pairs M3– M4 (for Logistic, Simple Logistic, SMO, LogitBoost, AdaBoost, Multilayer Perceptron, BayesNet, J48, NaiveBayes) and M9– M10 (for Logistic, Simple Logistic, SMO, LogitBoost, AdaBoost, Multilayer Perceptron, BayesNet, J48, NaiveBayes).
The role of the features F4, F5 and F6 is seen from the performance of the model pairs M3– M5 (for Logistic, Simple Logistic, SMO, Multilayer Perceptron, NaiveBayes), M4– M6 (for LogitBoost, Multilayer Perceptron, NaiveBayes), M7– M8 (for Logistic, Simple Logistic, SMO) and M9– M11 (for Logistic, SMO, Multilayer Perceptron, NaiveBayes).
The improvement of accuracy for the feature F7 can be seen by comparing the model pairs M3– M10 (for Logistic, SMO, Multilayer Perceptron, BayesNet), M4– M9 (for LogitBoost, BayesNet) and M6– M11 (for Logistic, Simple Logistic, SMO, LogitBoost, Multilayer Perceptron, BayesNet).
By observing the difference between the model pairs M3– M4 (for the curves of Simple Logistic, SMO, LogitBoost, AdaBoost, Multilayer Perceptron, BayesNet, J48, NaiveBayes) and M9– M10 (for Logistic, Simple Logistic, SMO, LogitBoost, BayesNet, J48) in Fig. 5, the role of feature F3 is seen.
The importance of F4, F5, and F6 is seen from the model pairs M3– M5 (for Simple Logistic, SMO, AdaBoost, Multilayer Perceptron, NaiveBayes), M4– M6 (Logistic, Simple Logistic, AdaBoost), M7– M8 (Logistic, SMO, LogitBoost) and M9– M11 (Multilayer Perceptron). The positive role of F7 is seen from the pairs M3– M10 (for Simple Logistic, SMO, LogitBoost, AdaBoost, BayesNet, NaiveBayes), M4– M9 (Logistic, Simple Logistic, SMO, LogitBoost, BayesNet), and M6– M11 (Logistic, Simple Logistic, LogitBoost, BayesNet, NaiveBayes).
Since the LogitBoost algorithm shows the best performance for all datasets of RTE1 to RTE4, Table 14 summarizes the results obtained from the 11 models with this particular algorithm only. Experiments were carried out separately on two devsets and testset of RTE1, devset and testset of RTE2, devset and testset of RTE3 and testset of RTE4. The table shows that in addition to model M11 (which is the combination of all the features) the accuracy of the method (for some datasets) reaches its peak value for the models M9 and M10 also. Figure 6 shows the variation of the performance of the method for the eleven models using LogitBoost classifier.
Accuracy (%) of the method for various RTE datasets using different models by LogitBoost Algorithm
Table 15 compares the accuracy of our hybrid ML method with the rule-based method presented in [26]. Our method outperforms the rule-based one by a good margin and has better rank with respect to the systems submitted to PASCAL RTE challenges.
Comparison of our ML-based method with the rule-based method
Comparison of our method with those submitted to the RTE challenges show that out of 28, 41, 45 and 45 submitted systems in RTE1 [28], RTE2 [29], RTE3 [30], and RTE4 [31] challenges, respectively, only 1, 2, 3 and 6 systems are ahead of us in terms of accuracy, which clearly indicates that the proposed method is quite competent with respect to the state of the art methods reported in the literature so far.
Our method can give wrong results for the following reasons: errors in datasets, wrong functioning of the embedded tools, and limitations of our method.
Table 16 presents some dependency triples produced by the Stanford parser for the T– H pair from Example 9 with wrong triples, shown in bold, caused by errors of the Stanford POS tagger, which propagate to parsing. The wrong POS-tagged output of the Stanford POS tagger is shown in Table 16 highlighted in bold. These erroneous hypothesis dependency triples H1 and H2 do not satisfy any of the matching criteria in [26] to find a match with any of the text triples thus producing low scores for the features F1, F2, and F7. Therefore, the accuracy of our method was limited by correctness of the embedded tools.
Generated incorrect dependency triples by Stanford parser for T– H pair of Example 9
Generated incorrect dependency triples by Stanford parser for T– H pair of Example 9
Moreover, the lexical database WordNet 2.1, which we used as the underlying knowledge base, does not provide sufficient coverage of antonymy relation. For the T– H pair from Example 10, the highlighted tokens
In the T– H pair of Example 11, each dependency triple of H finds a corresponding match with some text triples leading to generation of high scores for F1, F2 and F7. The high values of the feature variables eventually restrict the ML-based classifiers to mark the given T– H pair as a case of no entailment.
On the other hand, although a human reading of the hypothesis of the T– H pair in Example 12 infers the truth of the text, it is difficult to be captured by this method. Since the hypothesis conveys the same information as that of the text but in a completely different way, no dependency triples of H find their matching counterpart in the T triples thereby generating very low scores at the feature variables F1, F2 and F7 ultimately leading to incorrectly classifying the given T– H pair as a case of no entailment.
We have presented a hybrid approach for recognizing textual entailment, which blends a rule-based method for feature extraction with supervised ML-based framework for decision-making. A set of as few as seven features was extracted using matching rules that mainly compare syntactic structures of lexically aligned tokens, as well as semantic similarity between a pair of non-lexically aligned tokens.
We carried out exhaustive experiments on different combinations of those features using several ML-based classifiers, of which LogitBoost showed the best performance. Our results show that our hybrid approach efficiently labels a good percentage of T– H pairs as textually entailed or not. The technique, being a combination of rule-based and ML-based method, outperforms many systems reported so far. Although our method still does not outperform the best known methods, it is much lighter in terms of tools and resources used, thus being suitable for implementation for low-resource languages.
In the future, we will explore other features in order to increase the accuracy of the method.
Footnotes
Acknowledgments
S.K. Naskar is supported by Media Lab Asia, Meit Y, Government of India, under the Young Faculty Research Fellowship of the Visvesvaraya PhD Scheme for Electronics & IT. A. Gelbukh was supported by the SNI, Mexico, and Instituto Politécnico Nacional grants SIP 20172008 and SIP 20172044.