
Abstract
Given a question, a reference answer, and the answer given by the student, the aim of the automatic short answer grading task is to assign a grade to the student’s answer. We use for this a large number of matching rules relying on recognizing entailment relation between dependency structures of the two answers. Comparison of the grades generated by our method with those given by human judges on a computer science dataset shows a quite promising maximum correlation of 0.627.
Keywords
Introduction
Given a question (Q), a reference answer (RA),and the student’s answer (SA), the task of automatic short answer grading (ASAG) consists in assigning a grade to SA by comparing it with RA. A number of approaches to this task have been proposed by the natural language processing (NLP) community. Pattern-based approaches try to extract certain patterns from RA and apply them to SA. Text similarity-based approaches calculate semantic similarity between RA and SA. Machine learning-based approaches use classification algorithms.
In our previous work 0 we developed a method for the recognizing textual entailment (RTE) task, which consists in determining whether the meaning of a given text fragment (called hypothesis, H) is logically entailed by another given text fragment (called text, T). The method makes extensive use of a set of matching rules that compare each H dependency triple (two words from a sentence with their syntactic relation) of H with all the triples in T: the more of H dependencies are found to match a T dependency, the better the probability of entailment.
In this paper, we present a method that casts ASAG task to an RTE task: the better SA is entailed by RA (or RA by SA), the better its score should be. To determine the entailment, we use the rules from 0. However, whereas RTE is a binary classification task, ASAG is a scoring task, so we associate numerical scores with the matching rules and calculate, in a special way, the total score.
We use the matching rules and scores differently depending on the type of the SA tokens and triples. Namely, we categorize SA tokens basing on whether they match (by a WordNet lexical relations such as synonymy, hyponymy, antonym, derivationally related forms, causes, entailment, etc.) some word in Q or RA. Then we categorize the dependency triples basing on the types of their component words. The use of rules and scores depends on these categories.
For evaluation, we compare the obtained grades with those given by human judges.
The remainder of the paper is organized as follows. Section 2 gives a brief overview of the related work. Section 3 outlines our method. Section 4 illustrates it with a running example. Section 5 presents experimental results on the standard ASAG datasets. Section 6 gives error analysis. Finally, Section 7 concludes the paper.
Related work
A number of techniques have been proposed for the ASAG task. Mohler and Mihalcea [1] compared a number of knowledge-based and corpus-based text similarity measures, evaluated the effect of domain and corpus size on the corpus-based measures, and improved the performance by integrating automatic feedback from the student answers.
Mohler et al. [2] reported several graph-alignment and lexical semantic-similarity features using machine learning techniques for the task. Gomma and Fahmy [3] presented an unsupervised bag-of-words approach, where they tested different string-based and corpus-based similarity measures separately and then combined them together to improve performance.
Alotaibi and Mirza [4] proposed a method that integrates information extraction (IE), decision-tree learning (DTL), and machine learning (ML). Their IE technique employed parser and lexicon, whereas their ML techniques automated the free-text marking using classification rules extracted from DTL. Pulman and Sukkarieh [5] explored computational linguistics techniques for automatically marking short free-text responses. Initially they approached the problem with IE; however, since manually engineered IE requires skill and expertise on both domain and tools, they employed several ML techniques such as DTL and Bayesian learning to learn the IE patterns.
Sultan et al. [6] presented a fast and simple supervised method. From the given RA and SA, they extracted a number of text similarity features and combined then with key grading-specific constructs. Perez et al. [7] proposed a technique for evaluating free-text answers in an e-learning environment employing BLEU, a machine-translation evaluation metric. Selvi and Banerjee [8] used an enhanced BLEU method to assess a text basing on explicit word-to-word match between the SA and the RA.
Bachman et al. [9] approach the ASAG task in WebLAS, a web-based language assessment system. They provide an integrated approach to assess language ability for making decisions about placement, diagnosis, progress, and achievement in East Asian language programs. Sukkarieh and Blackmore0 describe the c-rater technique used by the Educational Testing Service (ETS) for automatic content scoring in short free-text responses. A c-rater consists of a set of clear, distinct, predictable, main or key points or concepts used to score the student’s knowledge related to those concepts basing on his or her answers.
Bailey and Meurers [11] focus on short-answer reading comprehension questions with a clearly defined target response. As their empirical basis, they constructed an English as a Second Language (ESL) learner corpus and developed a Content-Assessment Module, which performs shallow semantic analysis to diagnose meaning errors in short answers to reading comprehension questions.
Basu et al. [12] present a clustering approach for the task, with greatly reduces the number of actions required for manual evaluation of the answers. They train a similarity metric for student responses and use it to group responses in a tree of nested clusters to allow teacher to grade multiple responses with a single action. Finally, Roy et al. [13] present an unsupervised approach for this task based on sequential pattern mining as its first step and on intuitive scoring process as the next step.
Our method
Our method consists of the following steps: pre-processing, dependency parsing, lexical alignment, categorization of tokens, graph matching and assignment of scores, and calculation of the grade.
Preliminary steps
Pre-processing
All Q, RA, and SA pass by pre-processing steps, such as splitting words joined by a slash (e.g., “value/number” becomes “value number”) and expanding contracted tokens (e.g., “they’re” becomes “they are”).
Lexical alignment (token matching)
We check each SA token against each RA and Q token to see if they are identical or related by a WordNet relation such as synonymy, hypernymy, hyponymy, derivationally related forms, causes, entailment, antonymy, etc. This gives two sets of token matches in the form
Categorization of tokens
We categorize SA tokens into five types by whether they are aligned with at least one Q or RA token; see Table 1. OT stands for “other tokens”.
Categorization of SA tokens
Categorization of SA tokens
RA and SA are fed into dependency parser, which generates dependency triples in the form of R (W1, W2) representing a directed arc in the dependency graph originating from the governor node (token) W1, falling on the dependent node W2, and labeled by the relation R. To keep graphs connected, we subordinate the root nodes of different sentences of each text to a single root node, thus obtaining two trees: RA and SA.
Triple-matching and scoring mechanism
Our mechanism for scoring the SA starts from assigning three scores to each SA triple: the context relevance scores at the governing and at the dependent end of the relation, and the dependency association score. Given an SA triple, its scores are calculated by comparing it with each RA triple and then, by each score, taking the maximum by all RA triples (we assume unassigned values to be zero). Calculation of the scores for a given pair of SA and RA triples is done in three stages.
Rule-matching stage
In [14], we described a large set of matching rules, originally developed for the RTE task. Each rule is a condition on two dependency triples, which can be met or not. The rules in [14] are numbered as STD Rules 1 to 7 (standing for so-called single triple dependency rules) and JTD Rules 1 to 6 (joint triple dependency rules). In addition, [14] presents a semantic similarity matching module, which, when applicable to two triples, produces a numerical score.
The rules in [14] are very elaborate, each one being broken down into categories and their cases depending on the types of the tokens, the relations, and the context in the dependency structure. Much of the power of our method relies on those details; however, even their brief description is far beyond the scope and space limit of this paper.
At the rule-matching stage, conditions from Table 2 are tested. If a condition from the MR column is met (normally, only one condition can be met), the three values given in the table are used. If no MC is met, then three zeroes are assumed.
Assignment of scores on satisfying different matching criteria
Assignment of scores on satisfying different matching criteria
MC stands for the matching criterion number, MR for matching rules from 0, DA for dependency association, CR for context relevance, MM for matching module conditions (left) or for its return value (right).
In Table 2, notation such as S6.1–4:1–2 stands for the cases 1 to 2 of the categories 1 to 4of the STD (respectively, JTD) Rule 6 (respectively, matching module). S5:X refers to a special exception described in [14] under STD Rule 5. Say, the first row shows the matching criterion MC1, which is met when the two triples satisfy the rule STD 1 from [14], and in this case the dependency association score and the context relevance scores for the nodes s1 and s2 are all set to 1.
In MC12, the DA score is undefined (because if this MC is met, then the tokens have the categories for which the DA score is never used by our algorithm). Its CR value is negative if the corresponding lexical relation involved in rule S7 is antonymy, positive if it is any other relation, and the value returned by the matching module is used if there is no relation at all, i.e., the token is of OT type.
If a criterion from Table 2 matched and, in addition, in the SA triple RS (s1, s2) and RA triple RR (r1, r2) the tokens s1 and s2 are identical, or related by a WordNet relation (as described above), to r1 and r2, respectively, then the default values from Table 2 are replaced by 1,±1,±1. Note that in this case, s1 and s2 are of types A or QA from Table 1. Here, again, – 1 is used when the relation is antonymy and 1 otherwise.
Scoring mechanism
In addition to the out_dep and in_dep scores, each node of the SA dependency graph is assumed to have another scoring component called the context_relevance. This component measures the lexical or semantic similarity between the SA token with any of the RA tokens. On being lexically aligned with any of the RA tokens by some WordNet relations other than antonym, the context_relevance score of that SA token is set to a value of 1.0. However, antonym relation assigns a negative score of – 1.0 to the respective SA token. If an SA token is not directly lexically aligned with any RA token(s), then it is searched against all the RA tokens to find its semantically aligned counterpart according to certain matching criteria (MC19, MC20 as listed in Table 2). The corresponding semantic similarity score between the respective aligned token pair is set to the context_relevance component of that SA token. This score component indicates the degree of relevance of a particular SA token with respect to the RA context to measure how that SA token is contextually relevant to the RA tokens.
Each node of the SA dependency graph has7 scoring components; see Table 3.
Score components of each node in the SA dependency graph
Score components of each node in the SA dependency graph
Only A, QA and OT type tokens are assigned these scores; SW and Q tokens do not participate in our calculations.
Our hypothesis is that if a student repeats any question word (tokens belonging to the Q category) in his/her answer, no rewards should be credited for that. Moreover, stop words (belonging to SW category) being non-content words are of much less significance for being awarded any credits. Therefore, if a dependency triple connects a Q or SW type token to any other type token (belonging to A, QA, OT categories), then no scores are assigned to the corresponding out_dep or in_dep components of the governor or dependent nodes for that triple. Therefore, the values of the Avg_out_dep and Avg_in_dep score components of a node in the SA dependency graph are set by normalizing the values of Total_out_dep and Total_in_dep respectively by the number of outgoing/incoming branches towards/from A, QA and OT type tokens. Edges originating from or falling on Q or SW type tokens are not considered for this purpose.
The context_relevance components of the Q and SW-type tokens are also unused, since they do not contribute tocalculation of the final grade.
Finally the Effective_score of a QA, A,or OT node is computed as the average of Avg_out_dep, Avg_in_dep and Avg_context_relevance.
Each SA dependency triple R (s1, s2) is compared with all the RA dependency triples to come up with its corresponding matching pair. The matching operation is performed on the basis of a number of matching rules reported in [14]. On finding a successful matching pair, appropriate scores are assigned to the out_dep, in_dep and context_relevance components of the 2 nodes associated with the corresponding SA dependency triple according to Table 2.
Depending on the 5 types of categorization of the SA tokens as described in Table 1, 25 different combinations can be formed for an SA node pair.
These 25 combinations can be further grouped into 9 categories. For each of these categories, the calculation and assignment of scores on the SA tokens is presented in Table 4.
Assignment of values to the score components of an arc basing on dependency relation types
Assignment of values to the score components of an arc basing on dependency relation types
The node types are from Table 1, and the last three columns have the same as meaning as in Table 2. Notation is explained in Table 5.
Notation for Table 4
As shown in Table 4, dependency triples of type 1 combine a QA token and an A type token in different ways. Since both these types of tokens have their lexically aligned counterparts with some RA token/s, their context_relevance score is assigned according to the satisfied Matching Criterions (MC1-MC18) as presented in Table 2. On satisfying a suitable MC#, a certain score is assigned to the out_dep and in_dep components of the governor and dependent nodes of that triple. However, if none of the matching criterions is satisfied, then a score of 0 is assigned to the respective score components.
Type 2 dependency triples connect a QA or A type token to an OT type token. Therefore, they are checked to find a matching triple pair with any of the RA dependency triples according to MC20. On finding a successful match, a dependency association score of 1.0 is assigned to the out_dep and in_dep score components of the governor and dependent nodes of the triple. However, if MC20 is not satisfied, then the semantic distance between the associated token pair of the triple is considered to be the dependency association score.
Since the governor nodes (QA or A) have their corresponding lexically aligned counterpart with some RA tokens, their context_relevance score is set to a value of 1.0. On satisfying MC20, the semantic similarity score returned from the matching module is assigned to the context_relevance score component of the dependent node (OT). Otherwise, the highest semantic distance between the OT token with any of the RA tokens is set to the said score component of the dependent node (OT).
Similarly for dependency triples of type 3, MC19 is verified to check whether it is satisfied or not. On finding a suitable matching triple pair, a dependency_association score of 1.0 is assigned to the out_dep and in_dep score components of both the nodes. Otherwise, the semantic similarity between the token pair is considered to be the dependency association score. The context_relevance scores of the 2 tokens are assigned according to the same way as discussed under type 2 dependency triples.
Under dependency triples of type 4, the associated tokens belong to the Q and OT categories. Since a student should not get any reward for repeating the question words in the answer, no scores are assigned to the in_dep, out_dep and context_relevance components of the Q type tokens. However, since the OT type tokens do not have their aligned lexical or semantic counterpart, the highest semantic similarity score between any of the RA tokens with that particular OT token is considered to be the context_relevance score of the OT token associated to the dependency triple. Since the OT type tokens do not get aligned with any of the RA or Q type tokens, the dependency association score between the 2 nodes of that triple is set to the semantic distance between the associated token pair.
Dependency triples of type 5 connect two OT type tokens. Since none of the tokens has its lexically aligned counterpart with any of the RA tokens, both of them are checked individually with all the RA tokens to find their most semantically similar counterparts. The highest semantic similarity between each OT token with its semantically aligned RA token is assigned to the context_relevance score component of the respective node. Since none of the associated tokens is contained within the RA or in Q, the average of the semantic similarity score between the two OT tokens, the context_relevance score of OT1 and that of OT2 is set to the out_dep and in_dep score components of both the governor (OT1) and dependent (OT2) nodes.
Under type 6 of dependency triples, a Q type token is associated with an A or QA type token. Since Q type tokens are not considered for rewards, therefore no scores are assigned to the in_dep and out_dep components of any of the Q, A or QA tokens. Since, the A and QA type tokens are lexically aligned to some RA token/s, a score of – 1.0 (for antonymy) or 1.0 (other than antonymy) is assigned to their context_relevance components.
Type 7 dependency triples connect a stop word (SW category) to a token belonging to the A or QA categories. These less significant stop-words are also exempted from being assigned any values to their score components. Only a score of 1.0 is assigned tothe context_relevance component of the A and QA type tokens.
Dependency triples of type 8 link a SW type token to an OT type token. As already discussed, stopwords are not considered for scoring. However, the associated OT token is checked against all the RA tokens to establish the exact RA token with which it is associated with the highest semantic similarity score. This semantic similarity score between the pair of RA-SA token is assigned to the context_relevance component of the OT token.
Finally dependency triples of type 9 connect a pair of Q type tokens, a pair of stopwords (SW) or a Q type token to a SW type token. Since both these types of tokens are not considered to be given any rewards, no scores are assigned to the score components of any of the associated tokens.
The semantic similarity between the pair of tokens associated by a dependency triple (evaluated as the dependency_association score for the dependency relation types of 2,3,4,5) and between a RA-SA token pair (assigned as the context_relevance score for the relation types of 2,3,4,5,8) is measured using two corpus-based semantic similarity measuring tools: DISCO 1 and gensim 2 (word2vec model). The word2vec model was pre-trained on the google_news corpus and the DISCO was pretrained to compute the semantic scores on the British National Corpus and the English wikipedia corpus.
Experiments were carried out separately using these semantic similarity measures and the results are reported in the next section.
In our description above, we measured how well the SA is entailed (covered) by RA, i.e., whether all contents of SA is relevant. However, in the standard ASAG dataset, RAs are usually expressed in a very succinct manner compared to SAs, i.e., students often phrase the answer in a more elaborate manner, which covers the entire RA and augments it with some extra information, often correct and relevant for the question. In our algorithm as presented above, SA triples involved in such extra information are not matched with any RA triple, which unduly lowers the assigned scores.
This can be remedied by reversing the role of the RA and SA, i.e., matching RA tokens to SA and not SA tokens to RA. Such reversing of the entailment direction favors completeness over relevance, i.e., favors SAs that cover the whole RA and maybe say more, assuming that this extra part is correct. For example, consider:
Q: What is the scope of global variables?
RA: File scope.
SA: They have file scope when placed outside a function.
Our method as described above gives this SA a very low score, whereas reversing the entailment direction gives a perfect score of 5 out of 5. However, we currently have no way to check whether the extra portion of SA is correct: replacing outside by inside in this SA makes the extra portion incorrect, while preserving the same score.
We experimented with both strategies. Our results reported in Section 0 as Model 1 and Model 2 show that giving priority to relevance over completeness(the way it is described in the previous sections) performs better.
Calculation of grade
After the Effective_score is computed for the QA, A and OT type tokens in the SA dependency graph, the final grade for the SA is computed by taking the average of the Effective_score of the above mentioned 3 types of tokens and then multiplying this [0, 1] value with the marks carried by the question.
Running example
Consider the following example:
Q: What is a variable?
RA: A location in memory that can store a value.
SA: A variable is a location in memory where a value can be stored.
The SA categories of SA tokens are shown in Table 6, and the RA and SA dependency triples are shown in Table 7. The matching between the dependency triples as per the matching criteria (described in Table 2) and the assignment of scores on the SA tokens indicated as s1 and s2 are illustrated in Table 8.
Categorization of SA tokens
Categorization of SA tokens
SA and RA dependencies
DA stands for dependency association at the governing or dependent end, and CR for contextual relevance at the governing or dependent end.
After the scores have been assigned to the out_dep, in_dep and context_relevance score components of each triple, the Effective_score for that answer is calculated; see Table 9. The average of the Effective_score is then used to calculate the grade obtained by the student.
Score components of SA nodes. In the header, O stands for Total_out_dep_score, I stands for Total_in_dep_score,C for Total_context_rel_score, AO stands for Avg_out_dep_score, AI for Avg_in_dep_score, AC for Avg_context_rel_score, and E for Effective_score.
Statistics of the dataset used
Scores on DISCO (British National Corpus)
Since SA has four content words (shown in italic in Table 9) with token type A, the score obtained for the answer is the average of their Effective_score:(1+1+1+1) / 4 = 1 on the scale from 0 to 1. Since the question carries 5 marks, the final mark is 1×5 = 5.
Experiments were carried out on a standard computer science dataset which consists of a set of questions, model answers and student answers taken from an undergraduate computer science course [2]. 3 The dataset consists of 12 assignments each of which contains different number (7, 4 or 10) of questions thus having 87 questions in total. For each question (Q), a reference answer (RA) is provided and each question is also supplied with a number (29,30,31,28,26,27 or 24) of student answers (SA).
Each student answer is evaluated by two examiners and the average score of the two examiners is also provided.
The performance of our method was tested on the 12 assignments and the scores in terms of correlation with the average of human judgement scores are presented in the Tables 12–14 present the scores using DISCO on British National Corpus and English Wikipedia corpus respectively. Table 13 presents the correlation scores obtained using word2vec trained on google-News corpus. Each of the tables shows the scores using two models. The first of these two models is used to mark the student answer (SA) basing on comparison with the reference answer (RA). The second model reverses the direction of evaluation. It assigns a grade to the RA by comparing it with the SA. Ex1 and Ex2 indicate the correlation between the system generated scores with Examiner 1 and Examiner 2 respectively. Avg indicates the correlation between our system score and the average of those two examiners.
Scores on DISCO (English Wikipedia Corpus)
Scores on DISCO (English Wikipedia Corpus)
Scores on Word2Vec (Google News corpus)
Comparison with state of the art
As observed from the tables, Model 1 exhibits the best performance (correlation of 0.503) for Assignment 6 using DISCO on English Wikipedia corpus. Model 2 shows the best performance (correlation of 0.627) for Assignment 6 using gensim (Word2vec) on google-News corpus. The overall correlation score for the entire assignment has also been computed which reaches the peak value of 0.365 for Model 2 with DISCO trained on English Wikipedia corpus.
Figures 1– 3 show the comparison of correlation for Model 1 and Model 2 using DISCO_BNC, DISCO_Eng-Wiki and Word2vec based semantic similarity measures, respectively. However, we considered only the Avg of the 2 Examiners grades Ex1 and Ex2 for graphical representation. It can be observed from Figs. 1– 3 that for all the assignments except A2 and A3, Model 2 exhibits better performance than Model 1. This clearly reveals the rationale behind reversing the role of RA and SA and evaluating the RA with reference to the SA.
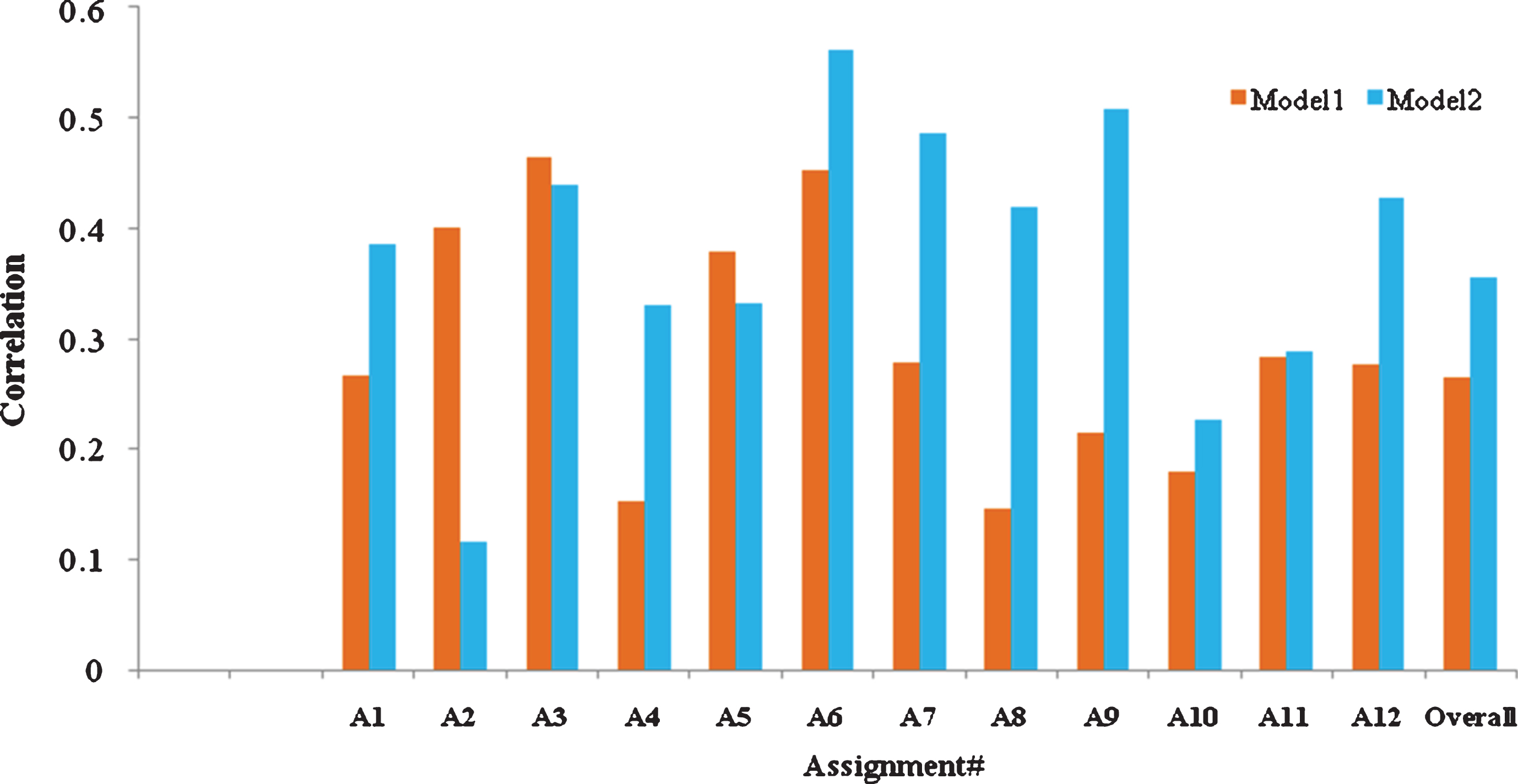
Comparison of correlation using DISCO-BNC.
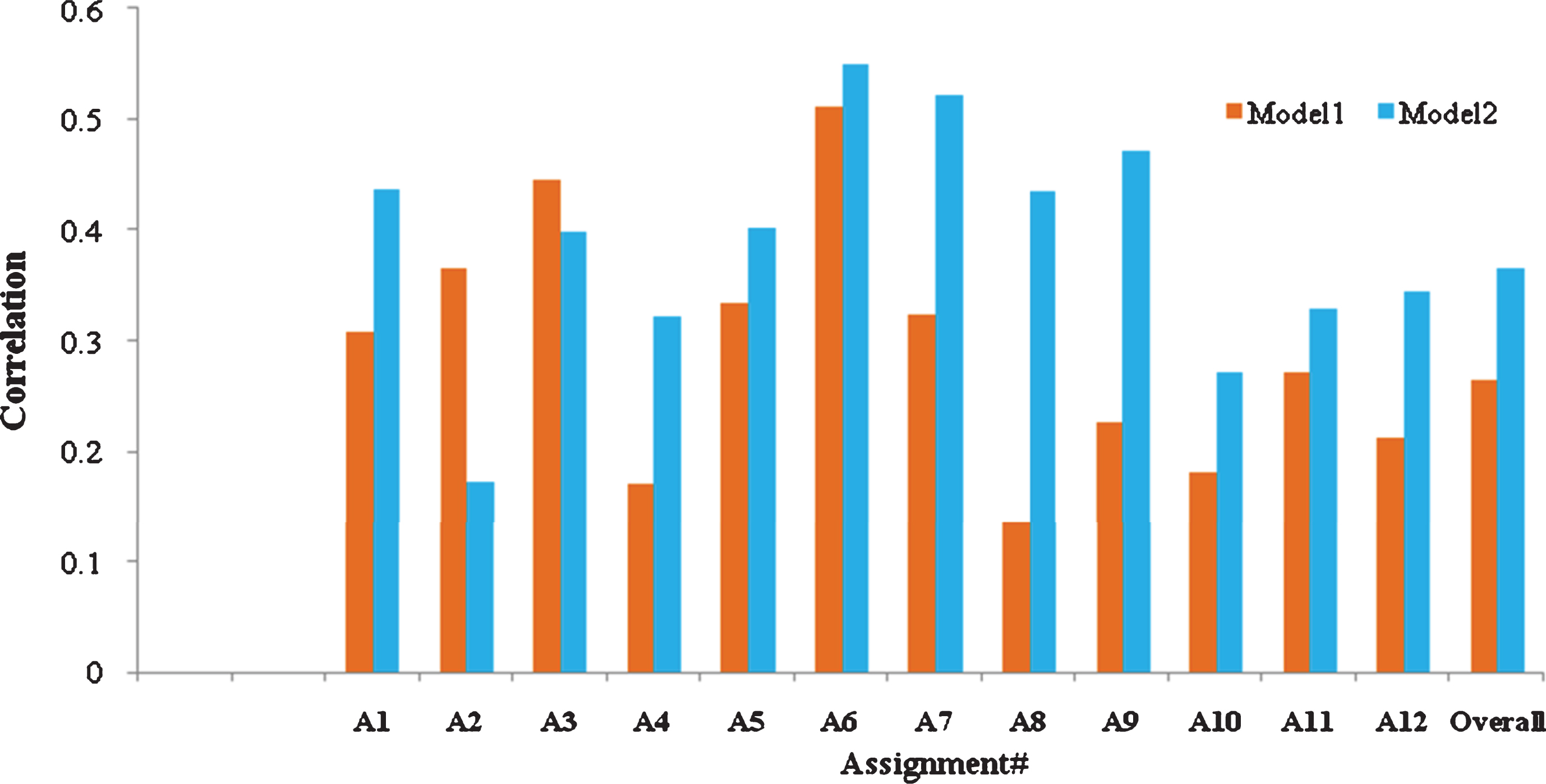
Comparison of correlation using DISCO-Eng_Wiki.
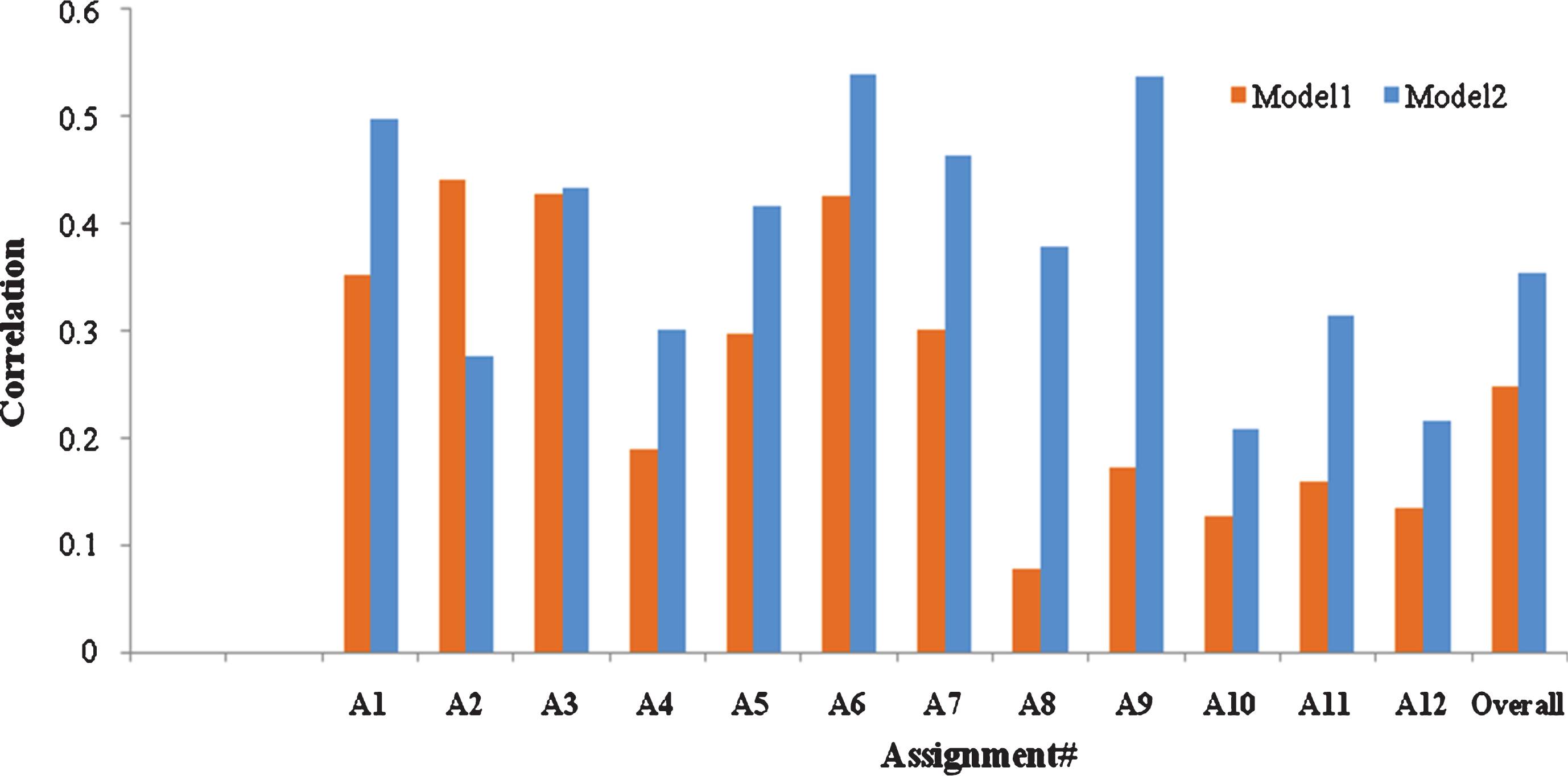
Comparison of correlation using word2vec.
Comparison of our method with previous state of the art is shown in Table 14.
Our method gives too low scores in some cases found in the dataset, such as in this example from Assignment 8:
Q: How can you implement a stack with an array?
RA: Keep the top of the stack toward the end of the array, so the push and pop operations will add or remove elements from the right side of the array.
SA: Allocate an array of some size, bottom stack element stored at element 0.
Here, none of the SA dependency triples is matched to RA dependency triples, thus low score is assigned. To handle such cases where the student conveys the answer in a way very different from the RA, deeper text understanding will be needed.
Conclusion and future work
The proposed rule-based method is proved to be quite efficient in assigning grades to the student answers sufficiently close to the human examiners. Given a question (Q) and a reference answer (RA), the method assigns a score (in [0, 1] scale) to the student answer (SA) with respect to the RA and then scale it up to the marks assigned to the question.
Experiments were carried out on a standard ASAG dataset and the correlation scores obtained between the system scores and the human judgements reveal that the proposed method can competently grade the student answers with scores approximately nearer to the human examiners.
In several cases, the RA conveys the gist of the answer in very few words whereas the student states almost the same answer using more words with some extra information. For those cases, if the SA is evaluated with respect to the RA, for most of the SA dependency triples, the corresponding matching RA triples may not be found which results in assigning low scores to the student answers.
Therefore, the motivation behind reversing the role of the RA and the SA and evaluating the RA with reference to the SA can be perceived from these cases as the method generates fairly high scores nearer to the ones given by the human judges. However, while evaluating the RA by reversing the role of RA and SA, we make an assumption that the extra information stated by the student is correct and therefore the provision for penalizing marks for incorrect extra information is out of the scope of the method.
In future, we will augment the method with some advanced mechanisms to detect whether the extra information stated by the student is incorrect or irrelevant to the given context and accordingly decision can be taken whether marks should be deducted from that SA or not.
The efficiency of the method in grading SAs with scores close to the human judgement scores depends largely on the semantic similarity scores produced by the corpus-based similarity measures DISCO and word2vec, which have been employed in this method. The semantic similarity scores returned by the corpus-based similarity module play a crucial role in generating scores nearer to the human judges. Moreover, the similarity score between a pair of semantically aligned tokens returned from the WordNet::Similairty package also has an important part in generating the final score on the SA. Therefore we can conclude that the accuracy of the proposed method is dependent not only on the set of synthesized matching rules developed as a part of the textual entailment recognition task, but also on the corpus-based similarity measures used in the present work.
There are several RA and SA in the dataset containing spelling errors. We evaluated our method without correcting these errors in the dataset. In the future, we will add spell checker or text normalizer to handle spelling errors, which should improve the performance to some extent.
Footnotes
Acknowledgments
Work done under partial support of the Mexican Government via grant SIP 20181792 from the Instituto Politécnico Nacional to the third author. The work was done when A. Gelbukh was visiting the Research Institute for Information and Language Processing, University of Wolverhampton, on a grant from the Sabbatical Year Program of the CONACYT, Mexico.
Sudip Kumar Naskar is supported by Digital India Corporation (formerly Media Lab Asia), MeitY, Government of India, under the Young Faculty Research Fellowship of the Visvesvaraya PhD Scheme for Electronics & IT.