
Abstract
In this paper, the use of collection term frequencies (i.e. the total number of occurrences of a term in a document collection) in the BM25 retrieval model is investigated by modifying its term frequency (TF) and inverse document frequency (IDF) components. Using selected examples extracted from TREC collections, it was observed that the informative nature, for retrieval purposes, of terms, either with the same TF (in a document) or IDF (in a collection) may be better revealed with the use of collection term frequencies (CTF). From three new heuristics based on those observations and deviations from a random Poisson model, collection term frequencies were integrated to TF and IDF factors. The novel formulations were tested by employing the TREC-1 to TREC-8 collections in the ad hoc task, for which BM25 was first developed and tested. Consistent and significant improvements were observed in mean average precision (MAP) reaching up to 17.67% for the TREC-8 dataset, and 7.16% averaged over all tested collections. These results were considerably better in comparison to other approaches surveyed aiming to improve BM25, proving in this way the effectiveness of the proposed heuristics and formulae. The proposed approach requires only additional offline pre-computations and does not entail extra computational complexity for retrieval while keeping the original spirit and parameter robustness of BM25.
Keywords
Introduction
Okapi BM25 [26] is one of the most accepted retrieval models and has maintained its state-of-the-art status in information retrieval (IR) for nearly 20 years since its inception. From the perspective of information it uses, BM25 is similar to the even better-known cosine tf.idf model [27]. Both models rely on document frequencies of the terms of a query, as collected across the indexed document collection, and their frequencies within each candidate document.
Although several other successful retrieval models such as deviation from randomness [2] and language modeling [20] employ collection term frequencies (CTF), defined as the total number of occurrences of a term in a document collection, BM25 does not make use of these statistics. In the following, we investigate the usefulness of CTF for improving the retrieval performance of BM25. Rather than proposing a radically new retrieval model, we keep the original formulation structure of BM25 and integrate CTF to its term frequency (TF) and inverse document frequency (IDF) components.
The use of CTF in retrieval functions was introduced by Kwok (1990) and later used by others [13, 19]. In our empirical evaluations, we compare CTF and document frequencies (DF) on TREC data.We observed that terms that occur in the same number of documents in a collection (i.e. same IDF) have a different level of informativeness for retrieval based on their CTFs. For instance, the terms “London” and “or” occur roughly in the same number of documents (∼213,000) on TREC’s disks 4 and 5, but “or” occurs almost three times more than “London” in the same collection (considerably different CTFs). In this case, CTFs distinguish the higher keywordness of “London” over “or”, which is indistinguishable by IDF. A similar pattern occur for term frequencies in a document w.r.t. CTFs. For instance, “holocaust” and “take” occur 12 times each in document CR92E-7563 (i.e. same TF), but the CTF of the latter is considerably higher than that of the former. These and other patterns occur systematically, which lead us to formulate three new IR heuristics that relates TF, IDF and CTF following the methodology of Fang et al. [6]. These heuristics provide additional support for the proposed retrieval model.
We strive to ground the proposed model on both theoretical and empirical foundations. From a theoretical standpoint, we start from the well-known observation that deviations from a Poisson generative model can be used as measures of keywordness of words [4]. We integrate these deviations in IDF to derive a new weighting scheme called Poison IDF (PIDF). Additionally, we integrate into this scheme the ICTF factor [12]. Given that both IDF and ICTF have plausible theoretical and empirical foundations [1, 22], rather than selecting only one of them, our model combines both, along with the proposed PIDF, in a global weighting scheme, comparable to IDF, called Boosted-IDF (BIDF). Similarly, we integrate deviations from another model, with similar assumptions to Poisson, into the TF component, in a new model named Boosted-TF (BTF).
An experimental evaluation of the proposed modified BM25 formula is performed by using the ad hoc task in the documents and queries/topics from the TREC-1 to TREC-8 conferences [10]. In these experiments, the models are compared by using their optimal parameters (k1 and b) for each TREC collection in an experimental setup similar to the used by Fang & Zhai [7]. Once determined the best combination, we carry out experiments for the second stage, in which we determine default values for the parameters of the proposed model. In the final experimental stage, BM25 and BM25-CTF are compared using their respective default parameter values on several retrieval evaluation measures. The results show that BM25-CTF provides significant improvements and less variance across collections in comparison with the original BM25 model. To put these results in the perspective, we survey related work that attempted to improve the BM25 model (as discussed in Section 3), and compare relative improvements in retrieval performance.
Finally, Section 6 provides a comprehensive summary of the model. We also discuss the additional computational cost of the proposed model. This arises because of the need of keeping track of the collection frequencies in addition to the document frequencies already required by BM25 and the calculation of the additional factors in the novel formula. However, these extra costs are rather negligible given the substantial improvements observed in retrieval performance.
The BM25 retrieval formula
The retrieval model Okapi BM25 [24, 25] has the following formula:
Here, df (w) is the document frequency of the term w and |D| the number of documents in the collection. The TF component is represented by tf (w, d) and tf (w, q), which account for the number of occurrences of a term w in a document d or query q, respectively. The impact of TF values is controlled by saturation functions that prevent a linear growth. This control is typically stronger for document terms, by employing small values for k1 (usually, between 1.2 and 2.0), and weaker for query term, by using large values for k3 (typically, 500 or 1,000).
Finally, the document-length-normalization component is provided by the expression:
Here len (d) is the document length and avdl is the average document length for the collection. The parameter b ∈ [0, 1] provides a way to regulate the intensity with which the normalization applies. The current BM25 formulation is a practical simplification of a two-Poisson generative model [24], which has also proven to be robust with respect to the optimization of parameters k1, k3 and b. In addition, as observed by Fang et al. [6], BM25 mets to a better degree than other retrieval models an important desideratum in IR, namely obtaining good, consistent performance in large and heterogeneous test collections and the fulfillment of a set of formalized heuristics.
Related work
There have been several attempts to improve BM25 by making changes to its formula using the TREC collections and the ad hoc task for evaluation. In the remainder of this section, a not exhaustive, but representative review of previous work is presented. See [33] for an empirical comparison of various BM25 variations.
Attempts to improve BM25 that do no make use of relevance (or pseudo-relevance) information can be classified into several categories. First, there are approaches that only modify the BM25 formulation
The approach proposed in this paper adds collection term frequencies to the BM25 formula and keeps the same parameters. The candidate formulations tested were obtained by measuring deviations from randomness. Therefore, our approach could be labeled
Summary-of-reviewed-improvSummary of improvements obtained by the reviewed approaches
Summary-of-reviewed-improvSummary of improvements obtained by the reviewed approaches
na: not available.
The intent of IDF is to capture the degree of information of a term for purposes of retrieval in a collection of documents, based on statistics gathered from the entire collection [30]. The effectiveness of IDF effectiveness has been demonstrated both empirically and theoretically [4, 22], and its use is widely accepted. Although IDF uses only document frequencies, other term weighting approaches, which use CTF [2, 35], have also been shown as effective. In this section, we analyze various combinations between document frequencies df (w) and collection term frequencies ctf (w) in IDF-like factors that also satisfy some newly-proposed IR heuristics involving the two statistics.
One observation that motivates the integration between document and collection frequencies is the fact that most IDF scores in a collection encompass only very few values. This is a consequence of the Zipf’s law [36], which states that the vast majority of the words in the vocabulary of a document collection have low collection frequencies, and hence low document frequencies. For instance, on the disks 4 and 5 from the TREC collections, the vocabulary size is 1,159,440 terms (without using stemming). Of these terms, 1,129,637 have document frequencies less than or equal to 30. Thus, 97.43% of the vocabulary maps only to 30 possible values of IDF. An IDF factor formulated as a combination of document and collection frequencies could have a wider range and thus, provide a more fine-grained mapping.
Inverse collection term frequency (ICTF)
The disks 4 and 5 of TREC collections contain |D|=556, 077 documents. From that collection, Table 2 shows some illustrative examples of pairs of frequent words with similar document frequencies (hence, same IDFs), but with considerable differences in their CTFs (stemming was not performed and capitalization was ignored in these counts). In that table, the terms in the column labeled “w1” seems to be less informative than their counterparts in the “w2” column. Consider the following heuristic according to that data:
Some frequent terms in TREC disks 4 and 5 with same df (w)
Some frequent terms in TREC disks 4 and 5 with same df (w)
Therefore, CTF could provide an additional clue for distinguishing the informative nature of terms. In our scenario, terms that occur with overall high frequencies in a document collection are per se low-informative terms, more likely to be stop-words. Unfortunately, some “good keywords” that appear in a similar number of documents are indistinguishable from the stop-words using the current IR heuristics [6].
Originally proposed by Kwok [12], the inverse-CTF factor (ICTF) makes use of collection term frequencies ctf (w) to weight the terms in a document collection. In this section, we incorporate ICTF as a complement for IDF implementing the proposed heuristic
Thus, ICTF could be integrated to IDF into a weighting scheme able to distinguish between terms having the same idf (w) score by employing the collection frequency ctf (w). The formula for ICTF is
The co-domain of ictf (w) is the interval [0, log(M)], which when multiplied by that of idf (w) makes the co-domain of ictf. idf (w) become considerably larger than the co-domain of idf (w). The values returned by ictf. idf (w) range from 0 to log(M) × log(|D|+0.5/1.5). Therefore, ictf. idf (w) provides a finer-grained and wider discrimination of the informativeness of the terms in comparison with idf (w).
For example, let us compare the scores obtained by idf (w) and ictf. idf (w) for a pair of terms from Table 2: w1= “who” and w2= “london”; note that idf (w1) =0.2097 ≅ idf (w2) =0.2057, while ictf. idf (w1) = 0.5686 < ictf. idf (w2) = 0.6170 (M = 298, 349, 366). In this example, it is possible to say that ictf. idf (w) reveals the informativeness of “london” versus “who”.
Now, let us analyze the ictf. idf (w) function across the entire spectrum of document frequencies. Figure 1 shows a comparison between the scores obtained by idf (w) and ictf. idf (w) in the same document collection used before. In this figure, all curves are standardized to [0, 1] and the horizontal axis is a logarithmic scale of df (w). It can be appreciated that the scores obtained with ictf. idf (w) shows a similar tendency as rising idf (w) to a power. For comparison, idf (w) 1.5, idf (w) 2.0 and idf (w) 2.5 are within the same figure as dotted lines. In addition, the ictf. idf (w) scores of a sample of 5% of the documents in TREC 8-6 are shown as small gray markers. The upper bound of these triangles draws a line that is mostly between the 1.5 and 2.0 powers of idf (w). Singhal [28] tested these powers obtaining the best improvement using idf (w) 1.5 in TREC 2-4. These results improved the retrieval performance considerably especially at high-recall levels with marginal losses at low recall. It is clear that the upper bound of ictf. idf (w) behaves like idf (w) 1.5 and most of the terms with df (w) >100 lie between idf (w) 1.5 and idf (w) 2.0.
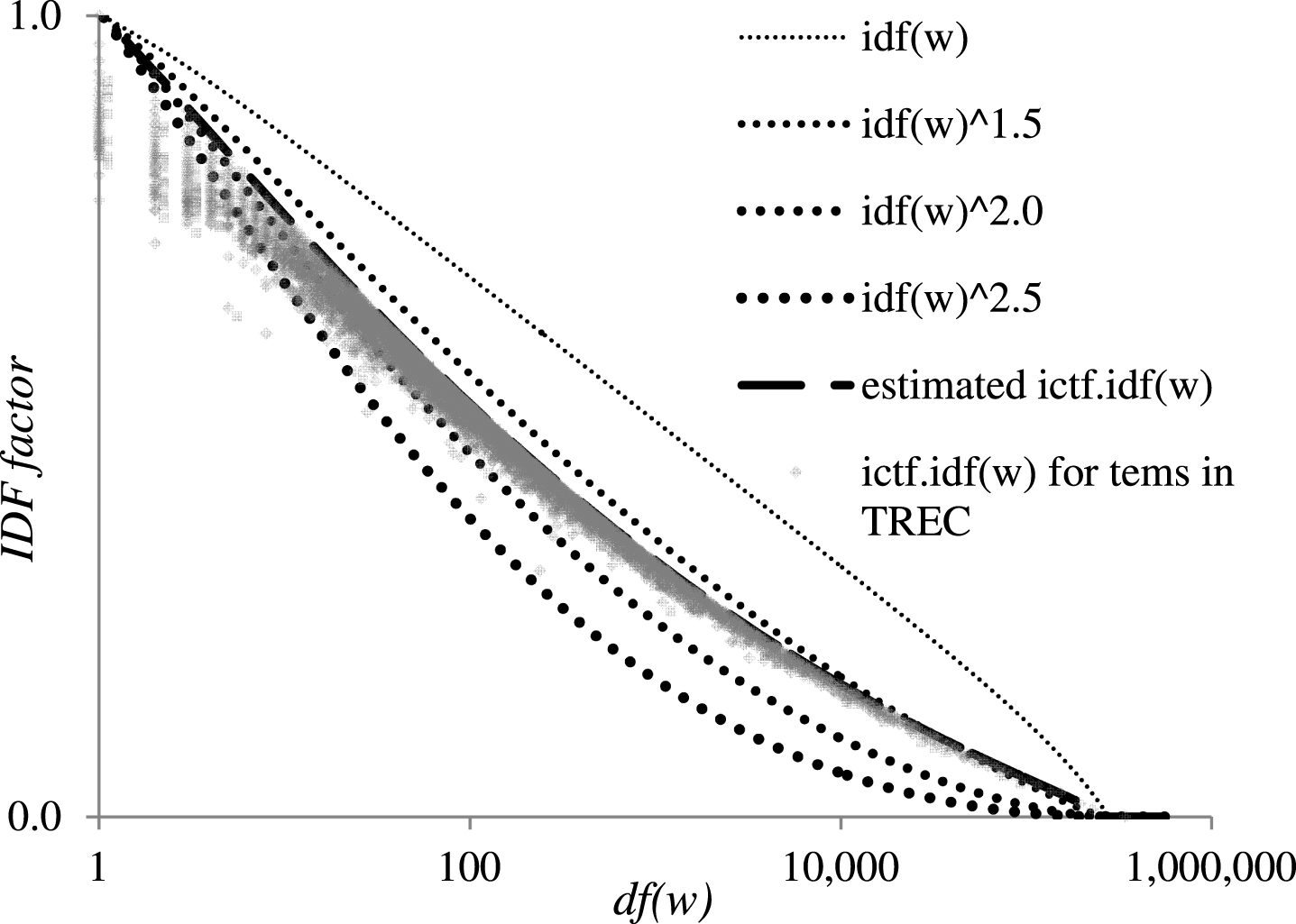
ictf. idf (w) versus idf (w) and some of its powers).
Figure 1 also shows a dashed line in black with an estimate (proposed by Church and Gale [4]) for ictf. idf (w) using the Poisson model as follows:
In Fig. 1, the upper bound of the marker coincides with this estimate showing that the ictf. idf (w) scores are consistent negative deviations from that model.
From this analysis, it can be observed that the ICTF factor produces two effects when multiplied by IDF. First, the resulting function behaves similar to raising the idf (w) function to a power, leading to an eventual improvement in retrieval performance according to the observations of Singhal. Second, the differences between ctf (w) and df (w) produce negative deviations in the resulting ictf. idf (w) function with respect to the case when df (w) ≅ ctf (w), i.e. no deviation. Although, this behavior implements the heuristic
Table 3 shows some examples of relatively low-frequent pairs of terms from TREC’s disks 4 and 5 that have the same document frequency but differ importantly in their collection term frequencies. Unlike Table 2, terms in the column labeled w1 seem to be better keywords than those in the column w2. Thus, assuming that the TF heuristic is valid (see TFCs in [6]), we propose our second heuristic:
Some low-frequent terms in TREC disks 4 and 5 with same df (w)
Some low-frequent terms in TREC disks 4 and 5 with same df (w)
As
Church and Gale [4] showed that, apart from the original motivation of IDF, it also captures deviations from a Poisson model. The Poisson model assumes that the occurrences of terms in a collection are evenly distributed across documents. Therefore, when the occurrences of a given term w unexpectedly accumulates in some documents, its document frequency df (w) is less than its expected value under Poisson,
Deviations from the Poisson model can be measured explicitly only when both ctf (w) and df (w) are available. Knowing ctf (w), it is possible to obtain an estimator for df (w) and vice versa. The Poisson estimator
Figure 2 shows the relationship between collection term frequencies, document frequencies for the Poisson model (Equation 2), and observed data points. While, at low frequencies both values are almost equal, as ctf (w) grows, df (w) is asymptotically limited by the number of documents in the collection |D|. Thus, the inverse function of this function provides an estimator for

ctf (w) versus df (w), estimated df (w) and deviations of real data from the Poisson model.
As mentioned above, under the Poisson assumption, when the occurrences of w accumulate in some documents lead to the order relationship:
The above expressions make explicit deviations from the Poisson model, the observed ctf (w), and df (w), their respective estimates. In this formula, a log-ratio was used to be consistent with the logarithmic formulation of IDF. Also, when the observed ctf (w) and df (w) deviate from the Poisson model the corresponding pidf (w) score diverges positively from idf (w) in a logarithmic rate.
Apparently, in the low-frequency range, if df (w) = ctf (w), then it means that w follows the Poisson model. Our hypothesis is that as df (w) and ctf (w) diverge, the informativeness of w increases, which diverge from Poisson,
The reader may notice that the proposed heuristics
Improving TF using CTF: Boosted-TF
Similar to the previous section, here the integration of factors CTF and TF was made by the observation that, in a document, the informativeness of terms with the same TF can be distinguished by their CTFs. Then, a new heuristic for information retrieval was formulated in accordance with that observation. Next, Boosted-TF, a new TF factor that implements that heuristic was proposed by using deviations from randomness.
Table 4 shows examples of pairs of terms that occur the same number of times in a particular document (i.e., same TFs), but differ importantly in their CTFs. This particular document has a length of 10,753 words. Unlike the terms in “w1” column, “w2” terms provide a good intuition about the topic of the document. In that example, CTF reveals an informative nature in the terms that TF alone is unable to distinguish. Consider the following heuristic:
Pairs of terms in document CR93E-7563 (in TREC disks 4 and 5)
Pairs of terms in document CR93E-7563 (in TREC disks 4 and 5)
This heuristic can be analogously formulated using document frequencies instead of collection document frequencies, because, if, ctf (w1) ⪢ ctf (w2), then it is pretty likely that df (w1) ⪢ df (w2) too.
The methodology for obtaining a new TF factor integrated with CTF is similar to that used for the development of PIDF (Subsection 4.2). That is, by comparing the deviation of an observed tf (w, d) value with a plausible estimate
Consider the portion of the length of the document due to repetitions of terms. The length of this portion is len (d) - |d′|, where len (d) is the document length, d′ is the set of terms in document d, and |d′| is the vocabulary size of d. Note that len (d) and |d′| must be computed including stop-words. According to our assumption, this portion should be distributed among the terms in the document vocabulary in a weighted manner by CTF. Therefore, the more frequent the terms in the collection, the larger their share on that portion. The expression for such term frequency estimator is given by:
The initial 1 in this expression results from the fact that at least one occurrence of w in d is assumed. Note that, this estimate keeps the document length unchanged since it satisfies the following restriction:
The formulation of Boosted-TF can be proposed by the intuition that terms w, whose observed tf (w, d) values are larger than their estimates
Table 4 also shows
Finally, the proposed expression for Boosted-TF uses the ratio between observed and estimated term frequencies adjusted by the factor C (d), as follows:
The purpose of C (d) is to maintain the values of btf (w, d) close to the original tf (w, d) by satisfying the constraint ∑w∈d′btf (w, d) = len (d). Incidentally, this factor could prevent unexpected interactions with the pivoted-document-length-normalization component of BM25.
In this section, we present a summary of the BM25-CTF retrieval model. Thus, the relevance score of a document d for a query q is:
Where w is an index term (i.e. a word), d is a document as a collection of index terms, and K (d) is the same document-length normalization factor of BM25. The parameters of the model and their proposed defaults values are k1 = 1.25, b = 0.90, and k3 =any value from 100 to 1000 (1000 was used in our experiments). Values for k1 and b are determined experimentally in Section 7.
Unlike BM25, during the indexing stage, BM25-CTF requires keeping track of all collection-term frequencies ctf (w), which requires the same space as df (w). Next, computing and storing bidf (w) would require practically the same time and space than idf (w). Similarly, the same space used for tf (w, d) can be used now for btf (w, d) with the marginal cost of storing data on type real instead of integer. Note that btf (w, d) requires an additional off-line pass through the documents to calculate the scaling factor C (d). Finally, if the documents in the collection are relatively short, then ctf (w) ≈ df (w), and so BM25-CTF≈BM25. Consequently, the improvement of BM25-CTF over BM25 can be only observed when BM25-CTF is used in collections containing relatively large documents.
Experimental validation
Experimental setup
The aim of the experiments performed was to compare the original BM25 formula versus BM25-CTF. As a testbed, the ad hoc task was carried out in TREC data using the same configuration of collections of documents (disks), queries (topics) and relevance judgments (qrels) of TREC-1 to TREC-8 [10]. Also to compose the query terms, all fields of the topics were used, i.e. verbose queries. In addition, both documents and queries were pre-processed by tokenization (English tokenizer in the NLTK 2.0), stemming (Porter stemmer) and removal of 410 words from the InQuery stop-list. Next, tokens containing only numeric characters were removed with the exception of the years between 1900 and 2010. Finally, special characters such as underscore, punctuation marks, parenthesis and others were replaced with space characters.
For each combination of a collection of documents, set of queries and retrieval function, a list was retrieved containing 1,000 documents with the highest score. Next, the program trec_eval v8.1 produced evaluation measures (MAP, P@10 and others) for this sorted list by comparing it with its corresponding qrels. Finally, the statistical significance of differences between BM25 against the proposed function was obtained using the Wilcoxon’s signed-ranks test.
Parameter analysis
The robustness of the BM25 parameters has been widely accepted and demonstrated [32], which means that small changes in them also produce small changes in retrieval performance and default values are usually a good choice for different collections. On this basis, we compared the optimal k1 and b throughout the tested collections between BM25 and BM25-CTF (see Table 5). The most important result of this comparison is the fact that all standard deviations for both parameters in both test settings (i.e. TREC-8 to 1 and 8 to 4) are lower for BM25-CTF. Thus, the robustness of BM25 is not only preserved but improved by BM25-CTF, making unnecessary usual cross-validation for adjusting model parameters.
Optimal parameters for BM25 and BM25-CTF using MAP across collections
Optimal parameters for BM25 and BM25-CTF using MAP across collections
Figure 3 shows a comparison of the retrieval performance of BM25-CTF (left) and BM25 (right) in the search grid of parameters. The surface represents the average MAP over TREC-8 to TREC-1 using the corresponding parameters in the grid floor.
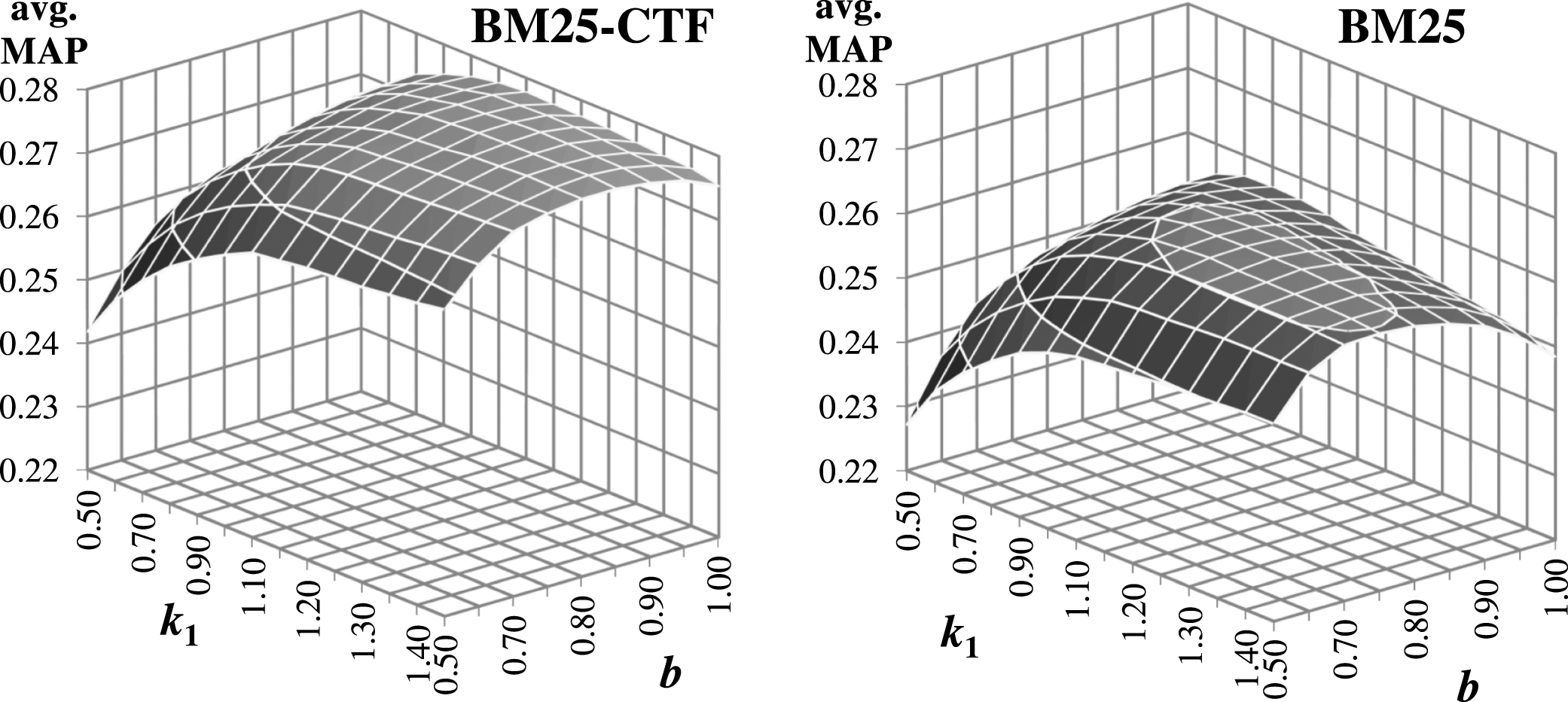
Average of MAP from TREC-8 to TREC-1 in a parameters search grid for BM25 and BM25-CTF.
Regarding robustness of parameters, one can see in Fig. 3, that the surface of BM25-CTF looks a bit “flatter” than that of BM25. This result shows that changes around the optimal parameter values produce smaller variations in performance for BM25-CTF than for BM25, which lead us to conclude that the robustness of the proposed model is comparable to (or even better) that of BM25. Table 6 shows the optimal parameters for both models using MAP and P@10. The resulting optimal parameters for BM25 are very close to the well-known default parameters suggested by Robertson [23], i.e. k1 = 1.2 and b = 0.75. However, the values of k1 differ between MAP and P@10 for BM25. Unlike BM25, the optimal parameters for BM25-CTF agreed for both measures.
Optimal parameters for BM25 and BM25-CTF for TREC-1 to 8
Table 7 compares retrieval performance between BM25 and BM25-CTF for each document collection. Results, using MAP measure, show consistent improvements of the proposed BM25-CTF over BM25 in all collections except for TREC-2, in which a marginal loss was observed. It is important to note that in TREC-4 to TREC-8, BM25-CTF obtained significantly better results. Although, the improvements of BM25-CTF measured using P@10 were not as significant and consistent as those using MAP, no significant loss was observed.
Comparison for each collection using its default parameters
Comparison for each collection using its default parameters
[*] significantly better using Wilcoxon’s test (p-value < 0.05).
Table 8 shows a comparison between BM25 and BM25-CTF when used with their corresponding default parameter values for various evaluation measures. BM25-CTF obtained improvements in all measures, particularly in MAP and GMAP. Regarding statistical significance, for each measure we counted the number of times that BM25-CTF were significantly better (labeled B*) and worse (labeled W-) in comparison to BM25. In the 7 performance measures considered, BM25-CTF was significantly better 20 times, and worse in only 2 out of the 56 comparisons (8 collections × 7 evaluation measures). In addition, the results and improvements averaged from TREC-8 to TREC-4 were much better than the average across all TRECs. This result shows that BM25-CTF perform better with shorter and less structured queries as those in the more recent TRECs [10], which are more common in practical applications.
Results for other performance measures
[B*] number of collections where BM25-CTF improved BM25 significatively (p-value < 0.05). [W-] ditto, but vice versa.
Although, our experimental setup differs from many of the works surveyed in Section 3, it is worth to highlight that the average relative improvement in MAP, from TREC-8 to TREC4 (13.08%), is larger than many of the improvements in these works. Considering magnitude and consistency, we believe that our results are comparable with those obtained by Troy and Zhang [34]. It is important to note that the improvements obtained by BM25-CTF are consistently better than any of the previously published improvements when direct comparison is possible.
We described an approach to improve the BM25 model by including collection term frequencies in its formulation. The proposed model was obtained by measuring deviations from randomness and implementing three newly proposed heuristics. Consistent and significant improvements of the proposed model against the classic BM25 proved that the three heuristics and the proposed formulation were convenient. Since collection term frequencies are readily available in most retrieval systems, the proposed approach does not increase the computational complexity of BM25. In our experiments on TREC data, the new model performs consistently better than BM25, and exhibits less variance across the collections. Furthermore, results indicate that the new model is robust with respect to the parameters k1 and b for which new empirically-determined default values are recommended.
Footnotes
Acknowledgments
The fourth author acknowledges the support of the Mexican Government via SNI, CONACYT, and the Instituto Politécnico Nacional, SIP grants 20172008 and 20172044.