
Abstract
With the field of technology has witnessed rapid advancements, attracting an ever-growing community of researchers dedicated to developing theories and techniques. This paper proposes an innovative ICRM (Intelligent Citation Recommendation Mechanism), designed to automate the process of suggesting the appropriate number of citations for individual brackets within a document. The proposed ICRM comprises three phases: Coarse-grained Weighted Bag of Word (WCBW), Fine-grained SciBERT (FSB) and Citation Adjustment phases. Firstly, the WCBW phase employs TF-IDF to extract keywords from both target and candidate documents, forming vectors that capture word significance along with metadata like authorship, keywords, and titles. It aims to identify relevant papers from a database, serving as initial candidates for each bracket. Secondly, the FSB phase employs the SciBERT model to assess the similarity between candidate documents and the local context around brackets, enhancing the precision of recommendations. It refines this selection by analyzing candidate-document relationships within the proximity of the brackets. Lastly, the Citation Adjustment phase tackles overlapping citations and ensures that recommended citation numbers align with user-defined criteria, resolving issues of imbalance. The simulation results demonstrate that the proposed ICRM outperforms existing models significantly in terms of precision, recall and F1-score.
Introduction
Research in the field of technology has been experiencing rapid advancements in recent years. An increasing number of researchers are involved in developing theories and techniques in this field and sharing their research results with others in no time. Therefore, researchers often struggle to keep up with the pace of new publications, leading to difficulties in summarizing related work. The goal of this study is to develop a system that provides accurate citation recommendations, reducing redundant citations and ensuring the appropriateness of citations in each bracket.
The advanced development of natural language processing (NLP) [1–3] in AI technology makes extracting a few keywords and formulating a summary from a document possible. The technique of extracting keywords from a document has been now widely applied in the areas of news processing, article recommendations, sentiment analysis, and so on. Making a summary from a document can also improve work efficiency and reduce the effort of readers for processing the document. To research related work in a specific field, researchers are now able to use the AI technique to find the connections among a large number of documents. Therefore, it is an essential research topic to develop the mechanism of automatic citation recommendations to specific brackets in the research paper. The purpose of this paper is to develop the technique of citation recommendations based on the technology in natural language processing.
In the literature, previous researchers have proposed citation recommendation mechanisms falling into two main categories: word vectors and deep learning. The first category [4, 5] applied TD-IDF [6, 7] to find keywords from the document and then adopted word2vec to embed keywords into word vectors. Based on the vectors of words, the developed techniques facilitated the extraction of connections among various documents. In addition, related studies falling in the second category developed the mechanisms of citation recommendations based on deep learning. These mechanisms adopted either LSTM [8–12] or BERT-based [13–15] models to find the connections among documents and recommend suitable citations to certain brackets. However, most of them still had some room for improvement. First, the representation of each document was generated in hidden states which were inexplicable and not transparent. The connections among documents built based on this inexplicable technique led to inaccurate citation recommendations. Moreover, most of the proposed approaches recommended citations to a certain bracket, leading to overlapping citations in different brackets or an improper number of citation recommendations.
This study proposes the ICRM, aiming at automatically recommending an appropriate number of citations for individual brackets in research papers. The main drawback of current systems is their overly simplistic approach to citation feature extraction, mostly considering only the contextual embedding features, which lack diversity, leading to inaccurate citation recommendations. Furthermore, most existing methods can only recommend citations for specific brackets, resulting in overlaps or inappropriate quantities of citations between different brackets.
This paper aims to propose a citation recommendation mechanism that consists of three phases. In the first phase, the coarse-grained approach is proposed, aiming to make some candidate recommendations. To achieve this, this phase applies the technique of the Weighted Bag of Words to construct a set of features as a basis to generate a vector for each document. These document vectors are transparent and explicable. Therefore, the candidate citation recommendations generated in this phase are more accurate and trustworthy. In the second phase, the fine-grained approach is proposed, aiming to examine the relationship between each of the candidate citations and the local context of a certain bracket. Therefore, this phase can further recommend the best citations to a certain bracket from the candidate citations. Nevertheless, the best citations in different brackets are very likely to be identical. Also, the number of citations might be improper. As a result, the third phase aims to remove overlapping citations and adjust the number of citations for each bracket. From the user’s perspective, the proposed ICRM can help scholars save time in searching and comparing a large amount of related work, thereby enhancing their work efficiency. Moreover, it offers more precise and personalized citation recommendations, assisting researchers in quickly locating relevant literature, thus improving the quality and accuracy of their research.
The following gives the major contributions of this paper:
In the first phase of the proposed mechanism, the document vectors are generated by using the Weighted Bag of Words technology, which extracts some keywords to play the role of features for the documents. Therefore, the document vectors are explicable and transparent. Compared to studies [10] and [14], the candidate citation recommended in this paper are more accurate and reliable.
Various techniques are used in different phases. In the coarse-grained approach, the Weighted Bag of Words is used to extract keywords from documents, while in the fine-grained approach, BERT [16, 17] is used to select a certain number of the best candidate citation recommendations based on how similar the candidate recommendations are to the local context of the target bracket. On the contrary, studies [10] and [14] used only the techniques of deep learning, such as LSTM or BERT, to achieve the proposed goals. The use of various techniques can help increase the accuracy and reliability of the results of recommended citations.
The third phase further applies the Voronoi Diagram [18, 19] to partition the overlapped brackets such that the repeated citations falling in Voronoi Cell will be assigned to the bracket in that cell. As a result, all repeated citations can be removed.
Based on the user-predefined lower and upper bounds on the number of citations for each bracket, the third phase also adjusts the number of citations for each bracket. This guarantees the number of citations in each bracket satisfies the user requirement.
The remaining part of this paper is organized as follows. Section II presents the existing studies related to this paper. Section III presents the assumption and problem formulation of this study. Section IV presents the proposed citation recommendation mechanism. The performance of the proposed mechanism is then evaluated in Section V. Finally, Section VI concludes this work and gives the future work of this study.
Related work
In the literature, many studies have been proposed for citation recommendation. According to different NLP technologies of citation recommendation, they can be divided into two categories: Context-based and Attention-based Recommendation.
Context-based recommendation
Many studies [8–10] used traditional product recommendations for uses. These approaches adopted the content-based, user-based or collaborative filter mechanisms and considered the papers as the product. Therefore, these mechanisms were applied to extract the relationship between authors (user) and papers (product). Then a set of papers can be recommended as the candidates of the citations to a certain author. The process of relationship extraction between authors and papers mainly applied the Bag-of-Words model to generate a vector for each paper or for each author. Then the cosine similarity mechanism was applied to find a set of candidates as the citation recommendation.
Lee et al. [8] presented a recommendation mechanism that recommended articles relevant to the research field of the users based on the traditional product recommendation mechanisms. Finally, the K-Nearest Neighbors was applied to estimate the preference of a target user and then recommended the most preferred papers. Nogueira et al. [9] proposed a two-stage approach: candidate generation followed by reranking. Initially, they assigned a vector to each paper based on the Bag of Word model. Then the abstract and title of the target paper are treated as a query. By taking the query and each vector of document as a pair of inputs, the BERT model will generate a score to represent the relation between the target paper and the input document. According to the scores, the papers with higher scores were selected as the candidates for citation recommendation. However, the Bag-of-Words techniques didn’t consider the context of the words, which represented the semantic similarity between the articles. Dai et al. [10] proposed a novel neural network model called ASL (Attentive Stacked Denoising AutoEncoders (ASDAE) with Bi-LSTM) for context-aware citation recommendation. The proposed ASDAE was used to capture the global attention from citation context when encoding cited paper. They also extended Bi-LSTM with a local attention layer to learn the hidden vectors for citation context, which could capture the key information for effective embedding and benefit for extracting suitable citation context. Personalization also embedded valuable author information to produce personalized citation recommendations. To overcome this limitation, this paper uses the Feature-based Ruler to exploit the context relation between the target article and the considered articles. The Feature-based Ruler extracts the features based on the word2vec model which assigns a vector based on n-skip gram or CBOW. Since the n-skip gram and CBOW establishing a vector to each word is based on a large number of contexts, the vector embeds the semantic similarity among articles. This paper also utilizes the Voronoi Diagram to partition the overlapped citations, aiming to remove the redundant citations and balance the citations.
BERT-based recommendation
Many studies [13–15] proposed embedding-based approaches to capture the resemblance between the query and the considered article according to the cosine distance or the Euclidean distance between their embeddings. Gökçe et al. [13] derived a subset of papers from the databases according to a user-defined keyword-based filter. They used the document embedding model, called Sent2Vec, to rank the filtered papers. Jeong et al. [14] proposed a BERT-GCN model for context-aware paper citation recommendation. It computed for each paper embeddings of the citation graph and the query context. The learning presentation of context sentences, through pre-trained BERT, achieved high performance. The GCN model was used to represent the citation relationship between papers and to extract a learning representation of them. The BERT-GCN model was evaluated on small datasets of only thousands of papers, partly due to the high cost of computing the GCN, which limited its scalability for recommending citations from a large paper database. In addition, similar to the disadvantage of the previous category, the recommendation only considered the global context of the target article. To recommend citations for the bracket of the target article, the local context near by the bracket is still needed to be further considered.
Gu et al. [15] proposed a novel two-stage local citation recommendation system, which contained prefetching stage and reranking stage. The prefetching stage used an embedding-based paper retrieval system, in which a Siamese text encoder first pre-computes a vector-based embedding for each paper in the database. The query text was then mapped into the same embedding space to retrieve the K nearest neighbors of the query vector. To encode queries and papers of various lengths in a memory efficient way, it designed a two-layer Hierarchical Attention-based text encoder (HAtten) that first computed paragraph embedding and then computed from the paragraph embedding the query and document embedding using a self-attention mechanism. After that, the reranking stage fine-tuned the SciBERT to rerank the candidates retrieved by the HAtten prefetching model. However, the functions of the proposed two stages were similar, which major relied on the attention scheme to extract the relation between citations of previous referenced papers and suffered with overlapping references. This paper proposes Feature-based Ruler and attention-based mechanisms that recommend candidates in two stages, the coarse grain and fine-grain. The two mechanisms can extract the features of each article based on different aspects. In addition, the proposed ICRM adopts the Voronoi Diagram to tackle the overlapping brackets. An Improper-Size Adjustment (ISA) Mechanism is proposed to further balance the number of citations for brackets.
Table 1 presents a detailed comparison between the proposed ICRM and prior related work in various aspects, including context extraction, embedding method, scalability, overlapping citations and citation balance. It highlights the limitations of existing research methods and illustrates how ICRM addresses these limitations with its innovative solutions and advantages.
The proposed ICRM compared previous related work
The proposed ICRM compared previous related work
For context extraction, previous research [8–10] depended heavily on the Bag-of-Words model and lacked a comprehensive understanding of context. The proposed ICRM utilizes a combination of TF-IDF and WCBW to extract more diverse features, enhancing the context and relevance of citations. In terms of the embedding method, ICRM introduces SCI-BERT with features derived from both TF-IDF and WCBW, which contrasts with the homogeneous feature extraction via embedding [13–15] used in previous studies, offering more accurate and complementary feature extraction. In addressing scalability, models like BERT-GCN [14] demonstrated limited scalability. The proposed ICRM uses Voronoi Diagrams for overlapping citations, allowing for more efficient handling of large databases and providing unique categorization. For the challenge of overlapping citations, prior research [13–15] suffered from overlapping references. The ICRM effectively utilizes Voronoi Diagrams for better management and differentiation of such citations. Lastly, in the aspect of citation balance, the ICRM introduces an Improper-Size Adjustment Mechanism, addressing the absence of a balancing mechanism in previous studies [9, 10] and ensuring a balanced distribution of citations across various brackets.
This section introduces the problem statement and objectives of this study.
Problem statement
Assume that there is a set D = {D1,D2, . . . ,D
m
} which consists of m papers D
i
, for 1≤i≤m. Let U
i
,A
i
,T
i
,K
i
,C
i
denote the authors, abstract, title, keywords, and conclusion of the paper D
i
, respectively. The paper D
i
can be denoted by Exp. (1).
Let D
t
denote the target paper that needs to find citations. Let U
t
,A
t
,T
t
,K
t
,C
t
, and L
t
denote the authors, abstract, title, keywords, conclusion, and citations of the paper D
t
, respectively. The paper D
t
can be denoted by Exp. (2).
Assume that there is an ordered list of citations, considered as the labels, which are cited in n positions of D
t
. The citations L
t
can be denoted by Exp. (3).
Let M be a mechanism that predicts the citations of D
t
. Let
Let Boolean variable
Let Boolean variable μ
i,j
denote whether the paper D
i
is in label
According to the values of
The
Let
The
Let TP M , FP M , and FN M denote the true positive, true negative, false positive and false negative of the confusion matrix for n citations of the paper D t , respectively. TP M denotes correct prediction that n citations are cited in all brackets. FP M denotes incorrect prediction that n citations are not actually cited in all brackets. FN M denotes incorrect prediction that n citations are cited in all brackets.
The TP
M
, FP
M
, and FN
M
can be derived by Exps. (12)–(14).
Let PC M denote the precision of prediction. It can be calculated by Exp. (15).
Let RC M denote the recall of prediction. It can be calculated by Exp. (16).
Let F1
M
denote the F1–score which can be calculated by Exp. (17).
Let Φ denote the set of all possible citation mechanisms, M ∈ Φ, that predict the citations for the target document D t .
Objective function
The objective of this paper is to find the best mechanism M
best
which satisfies:
This paper introduces an Intelligent Citation Recommendation Mechanism, called ICRM. The proposed ICRM is designed to automate the process of suggesting the appropriate number of citations for individual brackets within a target document. It consists of three phases: Coarse-grained Weighted Bag of Word (WCBW), Fine-grained SciBERT (FSB), and Citation Adjustment Phases. In the WCBW phase, candidates are identified from document D for each bracket using WCBW and TF-IDF schemes. The FSB phase employs the SciBERT model to evaluate how closely the candidate documents align with the specific context surrounding the brackets in the target document. However, the initial two phases may result in some brackets sharing identical citations. Therefore, the citation adjustment phase aims to resolve this issue by eliminating overlapping citations among different brackets based on user-defined constraints. The following presents the details of each phase.
Coarse-grained weighted bag of word (WCBW) phase
This phase aims to find the top η appropriate candidates from D for each bracket of the target document. The η candidates are selected based on Weighted Bag of Words and TF-IDF schemes.
Recall that there are m articles in database D. Recall that notations U i ,A i ,T i ,K i and C i denote authors, abstract, title, keywords, and conclusion of the article D i , respectively. That is D i = {U i ,A i ,T i ,K i ,C i }. And D t is the target paper. Let Φ D denote the set of words in all documents D i , for 1≤i≤m, as shown in Fig. 1. That is,
The content of Φ
D
.
Let notations U
t
,A
t
,T
t
,K
t
and C
t
denote authors, abstract, title, keywords, and conclusion of the target paper D
t
, respectively. Let Φ
i
denote the union of A
i
and C
i
. That is,
Let Φ
t
denote the union of A
t
and C
t
. That is,
The next step aims to extract the most important q keywords to organize a Weighted Bag of Words from Φ
t
and Φ
i
for 1≤i≤m. Let fTF - 1DF (w, D
i
,Φ
D
) denote the TF-IDF function applied on word w in D
i
. Let
The value of
Similarly, we may extract the most important p words to organize another Bag of words from Φ
t
. Let
Let Ft,A,C denote the set of the p most important words in D
t
, where A and C denote the words in Abstract and Conclusions. The Ft,A,C can be obtained by applying the following Exp. (25).
Till now, we have obtained the p and q most important words from Φ t and Φ i , respectively.
Next, we will illustrate how to present the document vector using the features in F. Let f
j
denote the j-th feature in Ft,A,C. That is,
Till now, the set of Ft,A,C has collected the p most important words which are extracted from the abstract and conclusion of the target document D
t
. The next step is to include the authors, keywords and title in Ft,A,C. Let F
t
be the set extended by including authors, keywords and title of D
t
to Ft,A,C. That is,
Let β be the number of words in F t . The β words will be used as the features to measure the similarity between the target document D t and each document D i .
Similarly, each D
i
should extract the important features to compare the similarity between itself and D
t
. Recall that
The words in F t will be organized as a Bag of Words to construct a vector for each D i . However, the Bag of Words uses the words in the Bag to represent a vector of a sentence, a paragraph or a document. One disadvantage of the Bag of Words is that the vector only presents the property of appearance of those words in the Bag. That is, the relationship of the words that appeared in a sentence has been ignored. Since the word2vec adopts the n-skip gram or CBOW to generate the vector for each word w by looking at the relationship of the word w and the neighboring words that appeared in the same sentence of a large number of documents in WiKi, the vector can represent a certain level of semantic.
To cope with this problem, the Weighted Bag of Words is proposed. Each word in F
t
should be transferred to a vector by applying the Word2Vec. Let V
t
denote the ordered list each element is a vector transferred from each word in F
t
. The V
t
will be treated as the Bag of Words. When the Word2Vec generates the vector for one word, it has been trained to extract the relationship of those words in the same sentence. Therefore, the embedded vector of each word has the advantage of exploiting the relationship among words in the same sentence. To achieve this, each feature word in F
t
and F
i
should be transferred to an embedded vector. Let f
w
2v be the function of word2vec which returns the embedding vector of a given input word. Let wi,j∈F
i
denote the j-th word in F
i
. That is, wi,j is an important keyword of the article Φ
i
. Let vi,j be the embedding vector generated by f
w
2v for a given input word wi,j∈F
i
. Let V
i
denote the set of all vi,j. That is,
Similarly, let
Figure 2 gives a conceptual explanation of the abovementioned operations. As shown in Fig. 2, F i collects α important words from each document D i . That is, it uses TF-IDF to initially identify the top q important words from the abstract and conclusions of D i . It then selects α-q important words from authors, title, and keywords to create F i . Afterward, these words are converted into word vectors using word2vec. Similarity, F t collects β important words from D t . The V i and V t and be derived through the Exps. (29) and (30), respectively.

The conceptual explanation of WCBW.
Till now, we have transformed each important word of the article D i and D t to a vector by applying the word2vec scheme.
The next step is to represent each document V
i
as a vector DV
i
=(ρ
i
,1,ρ
i
,2, . . . ,ρ
i,
β) with length β. Then the cos similarity scheme can be applied to select the η most related documents as the candidates for the target document D
t
. Let
Let
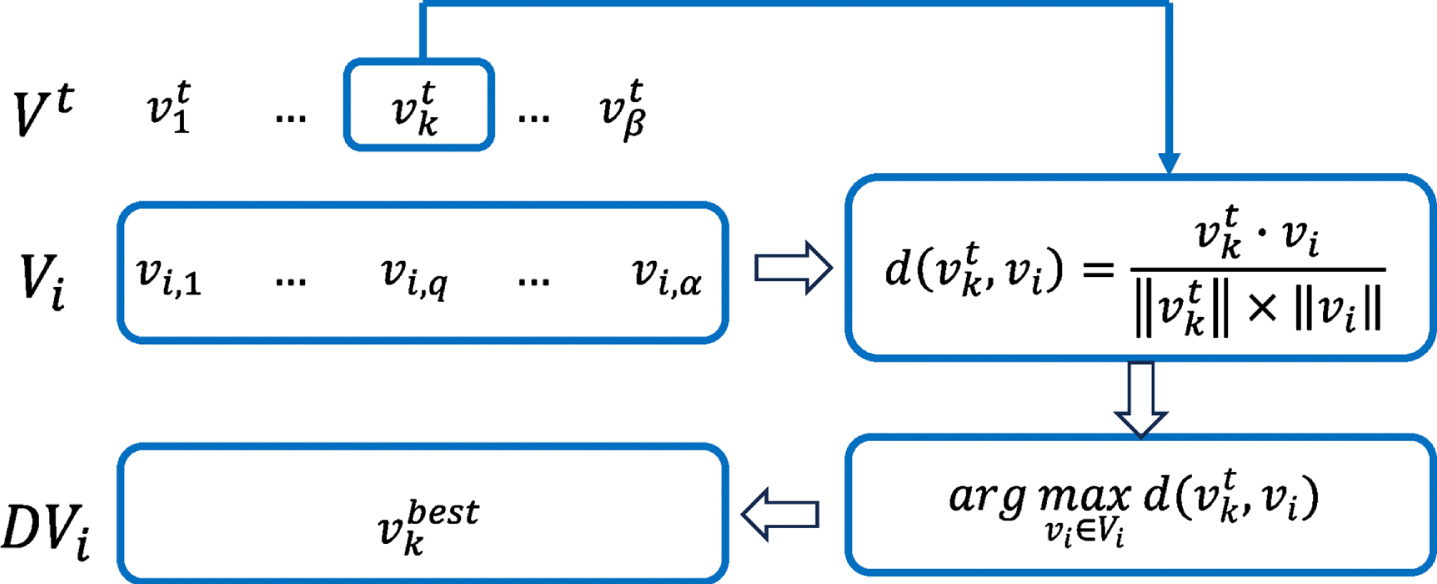
Weighted Bag of Words (WBOW).
Next, we will select the η candidates that are mostly related to target paper D t using the document vectors. As shown in Fig. 4, let D I denote the candidates found by the first phase of the proposed mechanism. Let δi,t = f cos (DV i ,V t ) denote the cosine similarity function which compares the documents vectors V i and V t and outputs a similarity value δi,t. That is,
The set D
I
of k candidates can be derived by applying Exp. (34) as shown in the following.

The most related candidate documents are selected according to their WBOWs.
During this phase, the SciBERT model is utilized to assess the degree of alignment between the candidate documents and the contextual information surrounding the brackets within the target document.
Let
Let function f
sciBERT
take
A large value of
Let n
j
denote the number of required citations for the bracket b
j
. The next step is to select the n
j
documents that are most related to the local context of the bracket b
j
from k candidates. Let C
j
be the set of recommended citations for bracket b
j
. The value of C
j
can be derived by Exp. (37).
This phase aims to adjust the recommendation results obtained from the previous two phases. Each bracket b j of D t has been recommended with a set C j consisting of n j recommended citations for b j . However, this result still has two problems: overlapping and improper size problems. Firstly, the overlapping problem refers to the overlapping citations existing in two or more brackets. This occurs because our model recommends the same citations in different brackets, especially for the neighboring brackets. The other problem is the improper size that some certain brackets might have too many or not enough citation recommendations.
Overlapping adjustment mechanism
This paper introduces the “distance-based mechanism,” which employs Voronoi diagrams to partition citation points, effectively addressing the issue of overlapping citations by considering the distances between all possible pairs of brackets and citations.
Let R
citation
denote the set of all recommended citations. That is,
Let O
citation
denote the set of citations appearing in more than one bracket. Let O
bracket
denote the set of brackets with overlapping citation recommendations. That is,
The next step is to assign a vector to each element in O citation and O bracket . The vector therefore can be treated as a point in pace, aiming to define the distances among these points. The distances among these points are useful to decide the bracket to which each overlapped citation should be finally belonging.
Herein, we will apply the function f
BERT
which takes Φ
i
as its input. Let
Therefore, each c
i
∈O
citation
already has a vector which is the vector corresponding to the vector V
i
of document D
i
∈D∪D
t
. However, each bracket still needs a vector. The next step is to assign a vector to each bracket. Recall that notation L
j
denotes the closest r words before and after the bracket b
j
. The r words in L
j
represent the local features of the bracket b
j
. Let
Till now, each element in O
citation
and O
bracket
has its own vector and can be mapped as a point in the vector space. The next step is to define the distance d(a, b) between any pair of two points (a, b) as
The following introduces the distance-based mechanism. First, we should construct a Voronoi diagram for all points b
j
∈O
bracket
. Let Ω
j
be the voronoi cell of bracket point b
j
. One principle of Voronoi diagram is that all points in a Voronoi cell Ω
j
are closest to the bracket point b
j
, as compared with other bracket point b
k
for all j≠k. This implies all citations points falling in voronoi cell Ω
j
are closest to bracket point b
j
. As a result, each overlapped citation c
i
∈ O
citation
can be assigned to one bracket b
j
∈O
bracket
if the following condition is satisfied.
Assume that the citation point c i falling in Ω j . This indicates that c i and b j satisfy Exp. (43). Therefore, the overlapped citation point c i will be included in bracket b j .
Figure 5 gives an example where all elements in O
citation
and O
bracket
have been mapped to the two-dimensional vector space. There are three bracket vectors b1 = [c1,c2,c3,c4,c5], b2 = [c3,c4,c5,c6,c7] and b3 = [c6,c8,c9] where b1 and b2 are overlapped and b2 and b3 are overlapped. The following presents how to decide that each overlapped citation finally belong to a certain bracket. The set O
citation
of overlapped citations can be derived as c3,c4,c5,c6. Then the mechanism prepares Φ3, Φ4, Φ5, Φ6 according to c3,c4,c5,c6. Then the L1,L2,L3 can be derived from the closest r words before and after the bracket b1, b2, and b3, respectively. Each element in sets Φ3, Φ4, Φ5, Φ6 and L1,L2,L3 serves as an input of BERT model. The
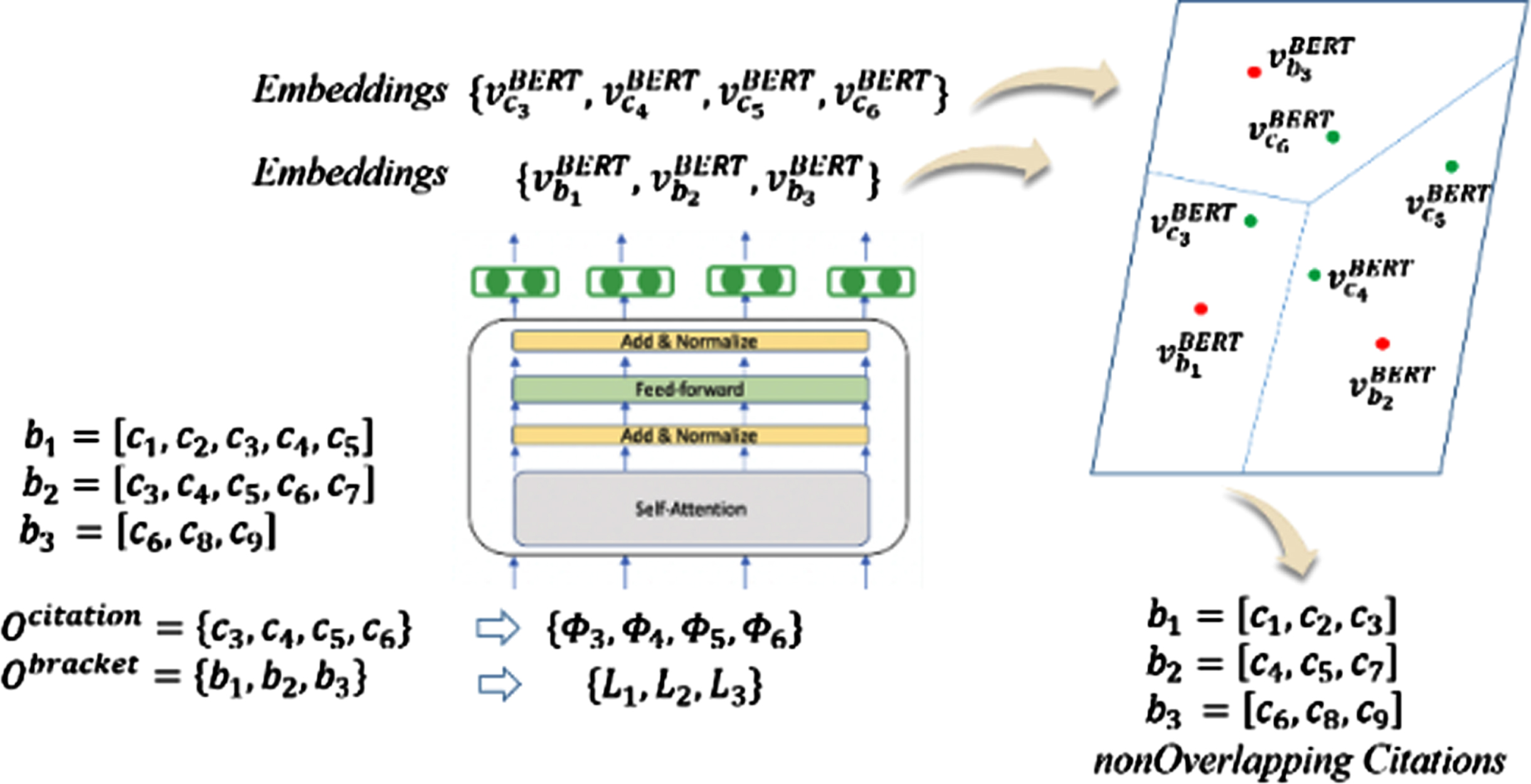
The set of overlapped citations Ocitation = {c3, c3, c3, c3} of brackets b1, b2 and b3 can be partitioned into different brackets.
This mechanism aims to cope with the problem of imbalanced number of recommended citations among brackets. Let
Let Bsort_less = (oversetlower0.5emsmash ⌢ → b1, …, oversetlower0.5emsmash ⌢ → b|B
less
|) denote the sorted list according to the size
The process of Improper-size adjustment mechanism
This section evaluates the performance improvement of the proposed ICRM against Coarse-grained WCBW and the existing HAtten-SciBERT (Hierarchical-Attention Text Encoder and SciBERT-based Reranking) [15]. The WCBW recommends the most related top k papers from D in a coarse-grain manner. The existing HAtten-SciBERT proposed a two-stage local citation recommendation, including prefetching and reranking stages. The prefetching stages scored and ranked all papers in the database to fetch a rough initial subset of candidates by a two-layer Hierarchical Attention-based text encoder (HAtten). On the other hand, the reranking stage was used to fine-tune the SciBERT to rerank the candidates retrieved by the HAtten prefetching model. Finally, the proposed ICRM applies coarse-grain and fine-grain policies to recommend the citations for each bracket. The code of the proposed ICRM can be found at http://aiit.csie.tku.edu.tw/. The following gives the simulation environment and results.
Data sets
The datasets including PubMed, ACL (Association for Computational Linguistics) and arXiv are used for measuring the performances of the compared studies. The PubMed is a biomedical literature database maintained by the U.S. The National Library of Medicine contains over 37 million abstracts and full-text articles. The ACL Anthology currently hosts 83313 articles on the study of computational linguistics and natural language processing. The arXiv is an online preprint platform, covering papers in fields such as physics, computer science, mathematics, statistics, and biology. This dataset contains a large number of academic papers that can be used for research in areas such as machine learning and natural language processing. It contains over 1.7 million articles.
Simulation results
Table 3 compares the WCBW, HAtten-SciBERT and ICRM in terms of precision, recall and F1-score. The number of articles in dataset varies ranging from 100 to 500. All the compared mechanisms have the common trend that the precision, recall, and F1 are increased with the number of articles in dataset. More articles in dataset help the model distinguish between relevant and irrelevant citations with greater precision. Consequently, the values of precision, recall and F1-score are increased. The proposed ICRM outperforms the WCBW and HAtten-SciBERT mechanisms in all cases. The main reason is that the proposed ICRM incorporates the WCBW and TF-IDF schemes to recommend the most related papers from D as the potential candidates. Additionally, it further examines the detailed relationship between each candidate paper and the given sentences to enhance the Precision, Recall and F1-score of citation recommendation.
Comparison of WCBW, HAtten-SciBERT and ICRM in terms of precision, recall and F1-score
Comparison of WCBW, HAtten-SciBERT and ICRM in terms of precision, recall and F1-score
Figure 6 (a), (b) and (c) compare the PubMed, arXiv and ACL in terms of Precision, Recall and F1-Score, respectively. The number of citations in dataset varies ranging from 10 to 50. It is obvious that the performance of ACL dataset is generally better than the other datasets.
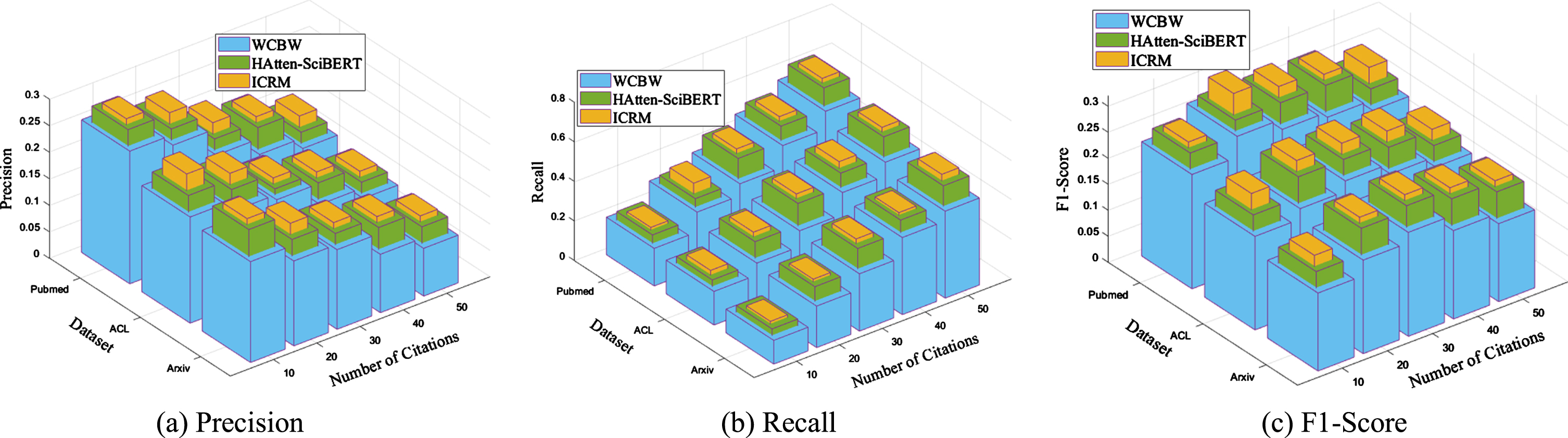
Comparison of WCBW, HAtten-SciBERT and ICRM with different datasets.
Table 4 further compares WCBW and ICRM with the PubMed, arXiv and ACL datasets in terms of MRR (Mean Reciprocal Rank). The value of MRR can be calculated by the Exp. (45).
Comparison of WCBW, HAtten-SciBERT and ICRM with different datasets in terms of MRR
Recall that notations α and β denote the user-defined lower and upper bounds for the number of citations in each bracket, respectively. The values of α and β will highly impact the number of citations for each bracket and also affect the number of overlapping citations.
Figure 7 compares the overlapping of different α and β (β≥α). The values of α and β vary ranging from 1 to 6. The overlapping refers to the commonality or shared citations among different brackets under various α and β settings. It is calculated by Exp. (46).

The relationship between Overlapping and bounds (α, β).
Figure 8 (a) and (b) compare the HAtten-SciBERT and ICRM in terms of overlapping in each bracket, respectively. The top-k documents will be recommended, where 2≤k < 6. The similarity can be calculated by applying Exp. (42). The similarity threshold varies from 0 to 0.7, which is used to allow the maximal similarity for any pair of brackets. A small similarity threshold will restrict the overlapping citations in different brackets. This constraint can reduce the overlapped citations. However, the HAtten-SciBERT did not cope with the overlapping problem. As a result, as shown in Fig. 8(a), the similarity threshold did not impact the overlapping ratio. On the contrary, as shown in Fig. 8(b), the proposed ICRM significantly reduces the overlapping ratio for a smaller similarity threshold value. When the similarity threshold is zero, the ICRM mechanism utilizes Voronoi diagram to assign each citation to a distinct branch, ensuring that there is no duplication as shown in Fig. 8(b).
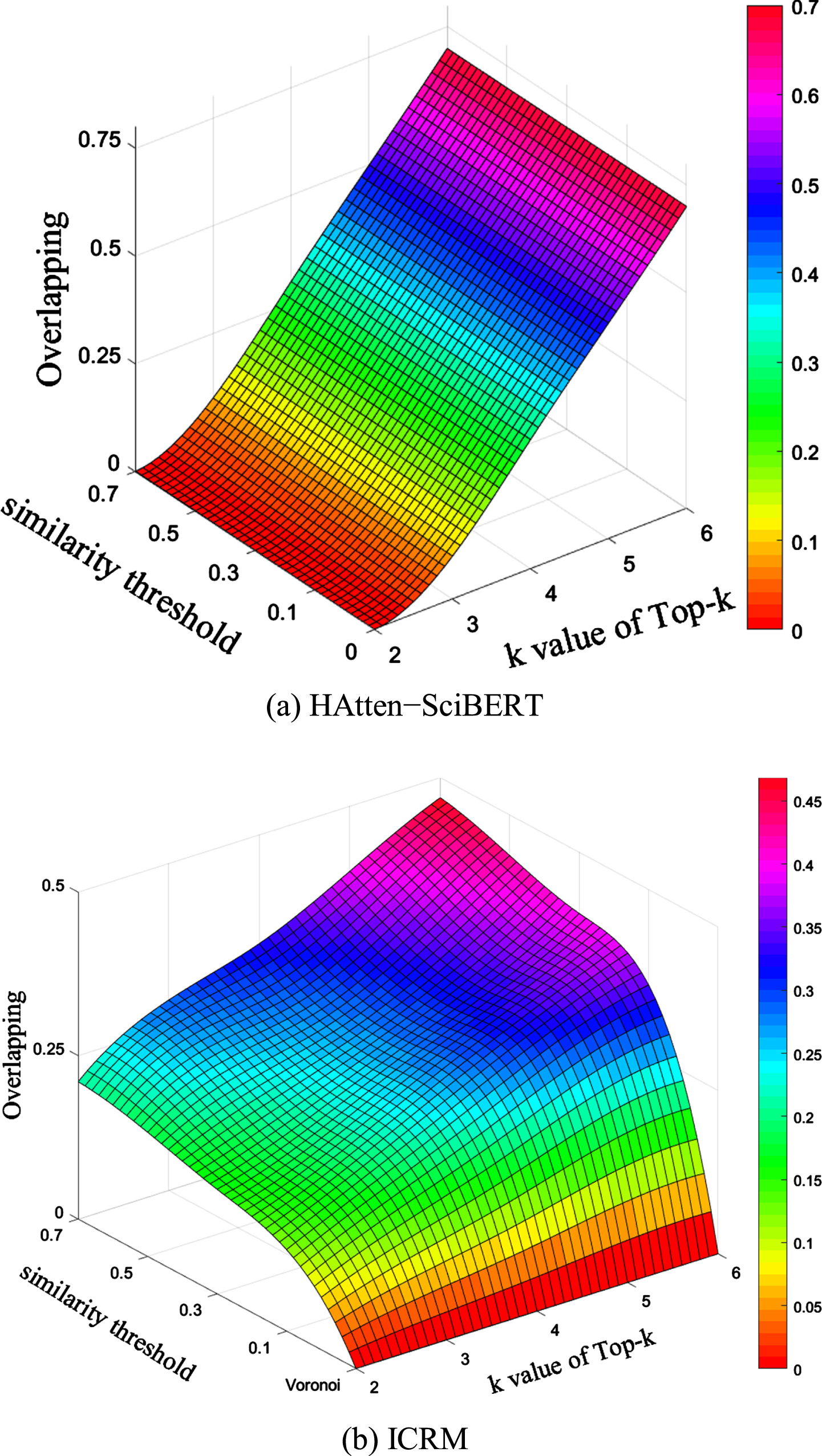
Overlapping.
Figure 9 further investigates the impact of (α, β) on the Voronoi average distance. The range of (α, β) varies from (1,1) to (1,6). We intend to observe two brackets with overlapping citation, and the variation in distance between the overlapping citation and the Voronoi edge formed by the two brackets. If the distance is greater, it indicates that the overlapping citation is more likely to be assigned to a specific bracket based on semantics. In this experiment, we attempt to perform the above-mentioned analysis by introducing overlapping citations into two brackets at different distances within the article. To control the variation in distance, we select these two brackets from different sentences within the same paragraph, or from different paragraphs within the same chapter, or from different chapters within the same article for the analysis and investigation. In the experiment, the distributions of citations in different locations, including inter-sentence, inter-paragraph, and inter-chapter, are represented by the proportions (0.5,0.25,0.25), (0.333,0.333,0.333), (0.25,0.5,0.25), and (0.25,0.25,0.5), respectively. As shown in Fig. 10, we use different colors to denote different distances of the two brackets. The number of citations varies from 10 to 25. As shown in Fig. 10, the Voronoi average distance is shortest for inter-sentence citations and farthest for citations placed between chapters. This occurs because that the semantic context of different brackets will exhibit more noticeable differences as the distance between the brackets within the article increases. This makes it easier to distinguish, based on semantics, which bracket an overlapping citation belongs to. Consequently, the distance from the Voronoi edge will also be greater. In addition, an increasing number of citations leads to a rising trend in the Voronoi average distance. This indicates that with a greater number of citations, the similarity between citations decreases, resulting in an increased average distance in the Voronoi diagram.

The relationship between Voronoi average distance and bounds (α, β).
The experimental results indicate that the proposed ICRM can effectively recommend the appropriate number of citations for individual brackets within a document. However, this paper has several limitations, which are presented in the following.
Data accessibility limitation
This study relies on having access to information such as titles, abstracts, authors, and conclusions. In this paper, we assumed the inability to access full-text journal and conference publications. However, if access to, or partial access to, many published conference and journal papers were possible, a more comprehensive and accurate analysis can be conducted. This will help to better understand the relevance of the papers, rather than solely relying on authors, titles, abstracts, and conclusions. We believe that exploring the semantics of the whole document can recommend more suitable citations.
Limitation of contextual sentences nearby the brackets
This paper assumed that when authors give the citation brackets, they should provide complete preceding and subsequent contextual sentences. Then the developed ICRM recommends citations based on the relevance of contextual sentences to related research. In the future, it may be possible to relax such restrictions, allowing authors to provide only the preceding context within parentheses, or even omit the parentheses altogether. In such cases, citation recommendation technology can automatically add citations.
Conclusion
This paper introduces the ICRM mechanism for automated citation recommendation within brackets of a target document. The proposed ICRM consists of WCBW, FSB, and Citation Adjustment phases. The WCBW phase efficiently identifies a pool of candidate papers based on authors, abstract, title, keywords and conclusions. The FSB phase adds depth to the recommendations by considering the local context around brackets. It employs advanced techniques like SciBERT to assess document similarity, resulting in more precise citation selections. Finally, the Citation Adjustment phase tackles overlapping citations and ensures that each bracket receives the desired number of citations. It utilizes a distance-based mechanism to assign overlapping citations to their appropriate brackets and maintains balance in citation numbers. The simulation demonstrates that the proposed ICRM holds promise for improving the quality of academic writing and information retrieval systems.
In future work, two aspects can be explored. The first one is the analysis of citation interconnections. This future work might analyze the interconnections and placement of citations in the literature to gain a better understanding of the relationships between citations. The other future work is the development of a dynamic citation adjustment mechanism. The main task of the dynamic citation adjustment mechanism is to dynamically adjust the number of citations based on the complexity and significance of the target document’s content, aiming to enhance the quality and comprehensibility of the document.