
Abstract
Argumentation in academic writing is a challenging task required to communicate clear ideas. Exposed ideas have to be supported by reasoned arguments. Arguments are composed of components such as premises and conclusions. In this paper, we present an approach to classify argumentative components using language models and machine learning algorithms on a new corpus of academic theses and research proposals. We explore the use of lexical, syntactic, semantic and indicator features to tackle this task. We found that lexical features provide the best efficacy for the classification. For language models, the best features were syntactical. But our experiments showed that a document occurrence representation with unigrams achieved the best accuracy. We also tested the conclusions about the representation and classifier on theses according to their study level (undergraduate, master, and doctoral). We analyzed the information gain of features and found patterns that are part of argumentative markers.
Keywords
Introduction
Writing an academic text such as a thesis can be a challenge for students. This kind of writing requires argumentation skills to support presented claims with solid arguments. An argument is a set of statements (i.e. premises) that individually or collectively provide support to a claim (conclusion). In scientific texts, evidence has to be presented in the form of reasoned arguments so that the reader is led to an appropriate conclusion [21]. The automatic analysis of arguments in theses becomes a necessity in the academic field, to facilitate the analysis of long texts and shorten the times of revision. Academic theses are often written at the end of college and constitute one of the major intellectual requirements for a degree, being in consequence quite important for students. In previous studies, we approached the task of argument identification [13] and assessment at the paragraph level in justifications [11]. In the research here reported, we focus on a fine-grain analysis at argumentative component level.
In recent years, researchers have studied the task of automatic processing of arguments in a variety of fields such as Law, with the aim to facilitate access to jurisprudence that supports a case [23, 41]. In political documents, automatic argument analysis has been studied for classification of arguments into concepts and modes such as policy, fact, and value [9]. In scientific articles, particularly in biomedicine, automatic processing of arguments can be applied to more rapidly identify arguments for or against a hypothesis under investigation [15]. In social networks, argumentation analysis is also employed to identify the overall stance (for or against) of comments in a debate [5]. There are also studies oriented to the assessment of argumentation in essays [29, 34]. Still, there remains an absence of studies for larger and complex academic works such as academic theses, in particular in Spanish language.
In this paper, we present methods for argumentative component classification using language models and machine learning techniques with representations of several lexical, syntactic, semantic and indicator features. To evaluate our methods, we create a corpus of thesis sections (problem statement, justification, conclusions) with annotated argumentative components.
The paper is structured as follows. In Section 2, we discuss related work for argumentative component classification. In Section 3, we present a theoretical background for argumentation structures. Section 4 details the corpus used in the experiment. The proposed features and learning approaches are described in Section 5. In Section 6, we report the results of the efficacy of our models for argumentative component classification. Finally, we conclude with final remarks and work in progress.
Related work
Recently there has been intensive research in the field of argument detection and classification (e.g., claim or premise). Mochales and Moens [24] performed argument segmentation and classification in legal text from the European Court of Human Rights (ECHR) corpus. They first detect clauses with argumentation to later classify them into the respective argumentative component. They used lexical, syntactic, structural, contextual and discourse features. The classifier employed was a Support Vector Machine (SVM), reporting an F measure for premises of 0.68, and 0.74 for conclusions. In social media, Goudas et al. [14] identified text fragments that correspond to a component (i.e. claim or premise) using Conditional Random Fields (CRF) to achieved an F-measure of 0.4237. Sardianos et al. [32] presented a similar approach with CRF and distributed representations of words to identify segments that correspond to argument components. For the task, they reported an F1-measure of 0.3221.
Stab and Gurevych [33] employed a SVM to classify segments as non-argumentative, major claim, claim or premise, in academic essays. They considered several structural, lexical, syntactic, and contextual features, reporting an accuracy of 77%. Also, Nguyen and Litman [26] performed the same argument component classification with SVM, and they achieved a 79% of accuracy, using argument and domain words extracted from unlabeled persuasive essays, applying Latent Dirichlet Allocation (LDA). In [8], Daxenberger et al. analyzed claim detection across six datasets. They report the essence of a claim in the lexical features. They achieved an F1-measure of 0.625 on persuasive essays using a logistic regression classifier with discourse, embeddings, lexical and structural features.
Another approach to identify premises is applying techniques of sentiment analysis. Villalba and Saint-Dizier [37] identified discourse structures such as justification, elaboration and illustration, that support opinions (evaluative expressions) in a corpus of hotels and restaurants reviews. They designed argument extraction rules with lexical features such as: terms expressing polarity, adverbs of intensity, and domain verbs, to identify discourse structures. They reported a precision measure of 0.92 and recall value of 0.86, when identifying justifications.
The closest work to the analysis of academic theses in argument mining is that dealing with scientific articles. In [19], the authors reported the creation of a corpus with 24 scientific articles in education, for the sections of introduction and discussion. Four participants annotated argument components as premises or conclusions, as well as four relations (support, attack, sequence, and detail) between these argumentative components, with an average in the level of agreement of Fleiss Kappa of 0.41. Thus, we observed that obtaining acceptable levels of annotation agreement in scientific texts is a complex task, which depends on an appropriate annotation guide and regularly monitoring annotators during the corpus construction. Scientific articles are close to academic theses since they share a similarly complex structure and technical vocabulary. However, undergraduate theses have a longer extension for each section, and student writing often has argumentative errors. In contrast, scientific articles are often prepared by researchers who have more experience in writing.
Argument components
An argument consists of several components. These components are a set of assertions, that individually or as a whole support another statement [6]. The assertion supported is a conclusion (claim). The conclusion is the principal component of an argument. There is only one conclusion for each argument; however, each conclusion can be based on a series of supporting assertions. Assertions that provide support (or attack) are called premises. A premise is a reason provided by the writer to convince the reader of the conclusion. These components are linked with support or attack relations to model the structure of the argument. Among argumentation theories [10, 39], the consensus is that the structure of an argument consists of several argumentative components. In this work, we adhere to the conclusion-premise model presented by Freeman [10] since introduces structures employed in argument mining [16].
A graphical representation of an argument structure facilitates the understanding of how argument components are interacting. Argument diagraming is the area that supports students in formulating their arguments. Each premise and conclusion is associated to a letter that is further expressed as a node of a graph. Then, directed edges (arrows) are established between nodes to indicate relationships between the components. A simple argument has only one premise that is used to support one conclusion [38].
As we can observe in Fig. 1, the first sentence is a premise (in square brackets /P1) supporting a conclusion in the second sentence (in square brackets /C2). In a simple argument, a premise provides elements to sustain the veracity of the associated conclusion. Figure 2 illustrates a simple argument structure in which the premise P1 supports the conclusion C2 (on the right side).

Example of annotated text with a simple structure: A single premise supporting a conclusion.

A simple argument structure as graph: A premise with a support relation to a conclusion.
As we can notice in the argument example, the word “therefore” plays an essential role in the identification of a possible conclusion; these patterns of words are called argumentative markers and can help with the detection of elements in an argument. In Table 1 we present some argumentative markers to identify premises and conclusions [6].
Argumentative markers for premises and conclusions (claims). In parenthesis we include the argumentative marker in Spanish
As mentioned previously, arguments can have more than one premise as support. In Fig.3, four types of structures for arguments are depicted. A convergent structure (a) has several supporting premises. In this case, it is possible to eliminate either one of the two premises and the conclusion is still supported [38]. A linked structure (b) has two premises which together are used to provide support for a conclusion. A divergent structure (c) has a unique premise to supports several conclusions. A serial structure (d) has arguments deployed in a successive order. In this type of structure, the conclusion of one component acts as a premise for another element [10]. These structures can be joined to form a more complex graph.
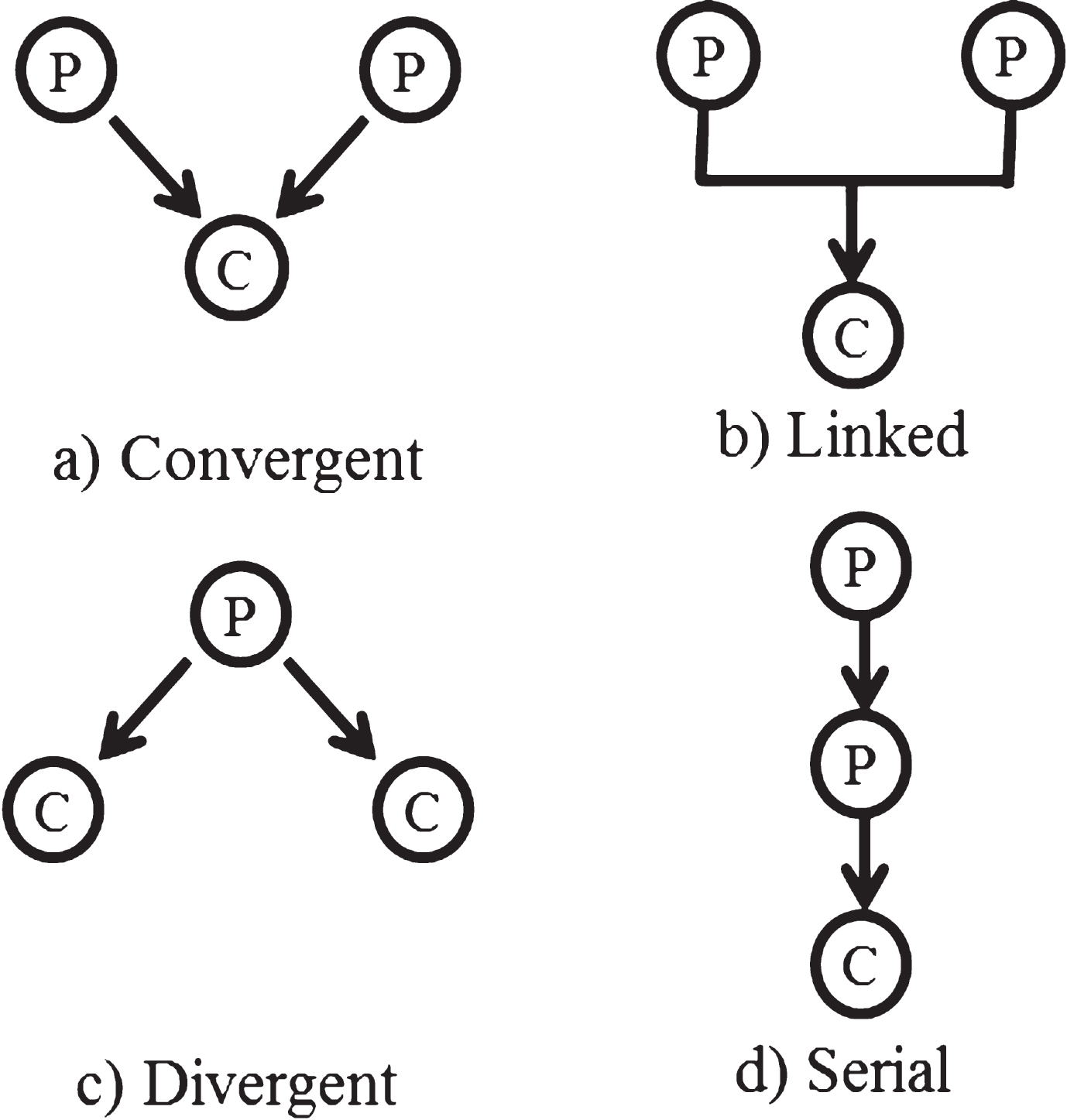
Types of argument structures.
For our experiments, we utilized an annotated corpus of theses and research proposals in the computer and information technologies domain, in Spanish. The texts are of undergraduate and graduate level, and come from Coltypi collection of theses and research proposals [12]. The annotated sections of each document were those considered highly argumentative [22]: problem statement, justification, and conclusions. The annotation was performed by two experts who have experience reviewing theses. The corpus contains annotations of argument components such as conclusions and premises. The inter-annotator agreement in terms of Kappa for argument component was 0.578, corresponding to a “moderate level” according to Landis and Koch scale [20]. The corpus consists of 1216 paragraphs in 300 sections (100 sections per type).
An example of an argumentative paragraph of a justification of undergraduate level, with annotated premises and conclusions, is the following:
[The lack of security measures in networks is a problem that is growing.]
The paragraph includes a convergent structure consisting of two premises (e.g., P2 and P3) which support a conclusion C1. We observed in this example an absence of argumentative markers, so the annotators had to carefully identify the semantic relation between the conclusion C1 and the premises P2 and P3.
For the annotation process of argument components, the annotators followed a procedure provided in an annotation guide which includes the following steps. First, the annotator is required to read the title and objective of the thesis or proposal. Then he had to identify if the text includes a conclusion. Next, the annotator had to determine the ideas that support the conclusion and mark them as supporting premises. Also, we advised the annotator to mark complete sentences or clauses as a conclusion or premise. The premises were indicated using square brackets and adding at the end /P, that is: [text of premise]/P. Similarly, in the case of conclusions, the text has to be enclosed in square brackets but now ending with /C, i.e. [text of conclusion]/C. This was the procedure suggested to the annotators to segment and label the argument components.
Class distribution among instances
Class distribution among instances
In total, 1683 instances were used for the experiments. Table 2 shows the class distribution. We only selected the annotated components with exact agreement in their boundaries. Instances of the class “None” were taken from sentences of paragraphs without argumentation. An instance of premise or conclusion class can be a clause (segment) or the complete sentence. We obtained a proportion of 49.5% for premises, 21.9% for conclusions and 28.6% for non argumentative example. We notice that there are more than twice the number of premises compared to conclusions. Such ratio between premises and conclusions is usually observed in academic writings, since the student often sustain his conclusion with one or more premises.
Distribution of argument components per level of study
We also considered the different levels of study in the corpus. We observe in Table 3 a majority of instances from the undergraduate level with a proportion of 60.4%, then the master level with a proportion of 29.1%, and finally doctoral with 10.5%. We employed several study levels to evaluate our model on more polished texts such as master and doctoral degree theses2
In this section, we discuss several features considered for the representation of argument components, and the learning approaches applied for the task.
Features
The features extracted from the components were lexical, syntactic, semantic, and about indicator.
Lexical features
Lexical features are based on words, lemmas, and terms in the text. These features are taken as unigrams for all terms in the component, including some punctuation marks (;:,.) and bigrams for consecutive pairs of terms in the paragraph, that also include punctuation marks. We computed a TF-IDF (Term Frequency - Inverse Document Frequency) weight for the lexical features, to assign higher values to the most discriminative terms.
Syntactic features
We used lemmas, part-of-speech tags (tagPOS) and the grammatical category (categoryPOS) i.e. the first letter of the POS tag, as syntactic features. We analyzed the part-of-speech (POS) tags, which indicates the type of role a token has in a sentence, e.g. nouns, verbs, adjectives, adverbs, etc. We employed the Freeling language analysis tool [27] for POS tagging. An example of a POS tag for the Spanish word “investigar” (investigate in English) is VMN0000 which indicates with the first letter “V” a verb category and the second letter M as the main verb. The POS tags have the format proposed by the EAGLES group for the morphosyntactic annotation of lexicons and corpus for all European languages. Freeling provides the lemmas which are the canonical form of the word. For example for “ya - que” (“since” in English) POS tags are “RG - CS” which indicates an adverb (“RG”) and a conjunction (“CS”).
Semantic features
The semantic features are expressed as word embeddings, specifically those of Polyglot [1] trained with Spanish Wikipedia. Word embeddings map the index of a word in a dictionary to a feature vector in a high-dimension space. This vector is learned with a neural network by back-propagating the error in the model to update the initialized embeddings. The model utilised is CBOW (continuous bag of words), since this used the context to train the vector of each word. The contexts is a set of word vectors randomly initialized, which are previous and following terms of the trained word. Polyglot contains words with vectors which represent the meaning of the word. The number of word embeddings contained in Polyglot for Spanish is 100,004. The word embedding vector has a size of 64 features. For each segment, we calculate the average of word embedding vectors contained in each argumentative component.
Indicator features
Argumentative markers reveal components of an argument. The indicator features correspond to five sets of word patterns (argumentative markers) that were applied to obtain the occurrence frequency of each of the following categories: justification, explanation, deduction, refutation, and conditional. We created the sets of patterns based on the review of different sources of argumentative markers in Spanish language [3, 31]. Examples of these patterns are “ya - que” (“since” in English) for justification category and related to the premise type, “por - ello” (“thus” in English) for explanation category, or “por-lo-tanto” (“therefore” in English) for deduction category, indicating a conclusion.
Document occurrence representation
We also explored a representation based on document occurrence which, to our knowledge, has not been tried in argument mining. The Document Occurrence Representation (DOR) is based on the “latent” semantics of a term, that can be revealed by the statistical distribution of occurrence over the documents in the corpus. A term is represented as a vector of weights associated with documents in the collection. The weights represent the contribution of a document to the semantics of a term [4]. The term vector size for a DOR representation is equal to the number of documents (segments) in the training set. In our case the training set size is 1513 segments, so the vectors generated by DOR representation had 1513 features. We associated a vector to each word in our vocabulary. We calculated the DOR representation using unigrams. The DOR representation for each instance is calculated adding all the word vectors in a given segment.
Learning approaches
We now present two learning approaches for the classification task of a text segment as premise, conclusion or none. We addressed only the classification task, and assumed that the segmentation task has already be done in some way. The segments employed were those determined by annotators in the corpus.
Our first approach is based on capturing the characteristics of components as sequences of words, lemmas and POS tags. For this approach, we tackle the problem with language models which had been used in several language processing tasks, such as speech recognition, machine translation, part-of-speech tagging, parsing, handwriting recognition and information retrieval. Our second approach formulates the problem as a straightforward classification task, employing machine learning algorithms. For training, we create representations based on several models, as described in the previous subsection.
Language models
Language models define probability distributions on word sequences. These probabilistic models are based on N-gram statistics as counts of unigrams, bigrams, trigrams, and so on. The language models are employed here to capture the regularities of the argumentative components. They can be used to predict the next word from previous words. Estimating the probability of the next word is close to estimating the probability of a sequence of words [18]. The perplexity is used to evaluate the probability that a given sequence belongs to the language model. The smaller the value of perplexity, the better the language model is at approximating the unseen supplied sequence.
The developed method used language models to capture the particularities of the sequences of terms in the premises and conclusions. The task was approached as a binary classification to determine if a segment belongs to the argumentative component (i.e. premise or conclusion). We split the corpus in 60% for training, 20% for tuning and 20% for testing. In Fig. 4, we describe the methodology for the classification task. First, we create five configurations for our sequences using words, lemmas and POS tags. In Table 4, we illustrate the sequence configurations of terms prepared beforehand to train the models.
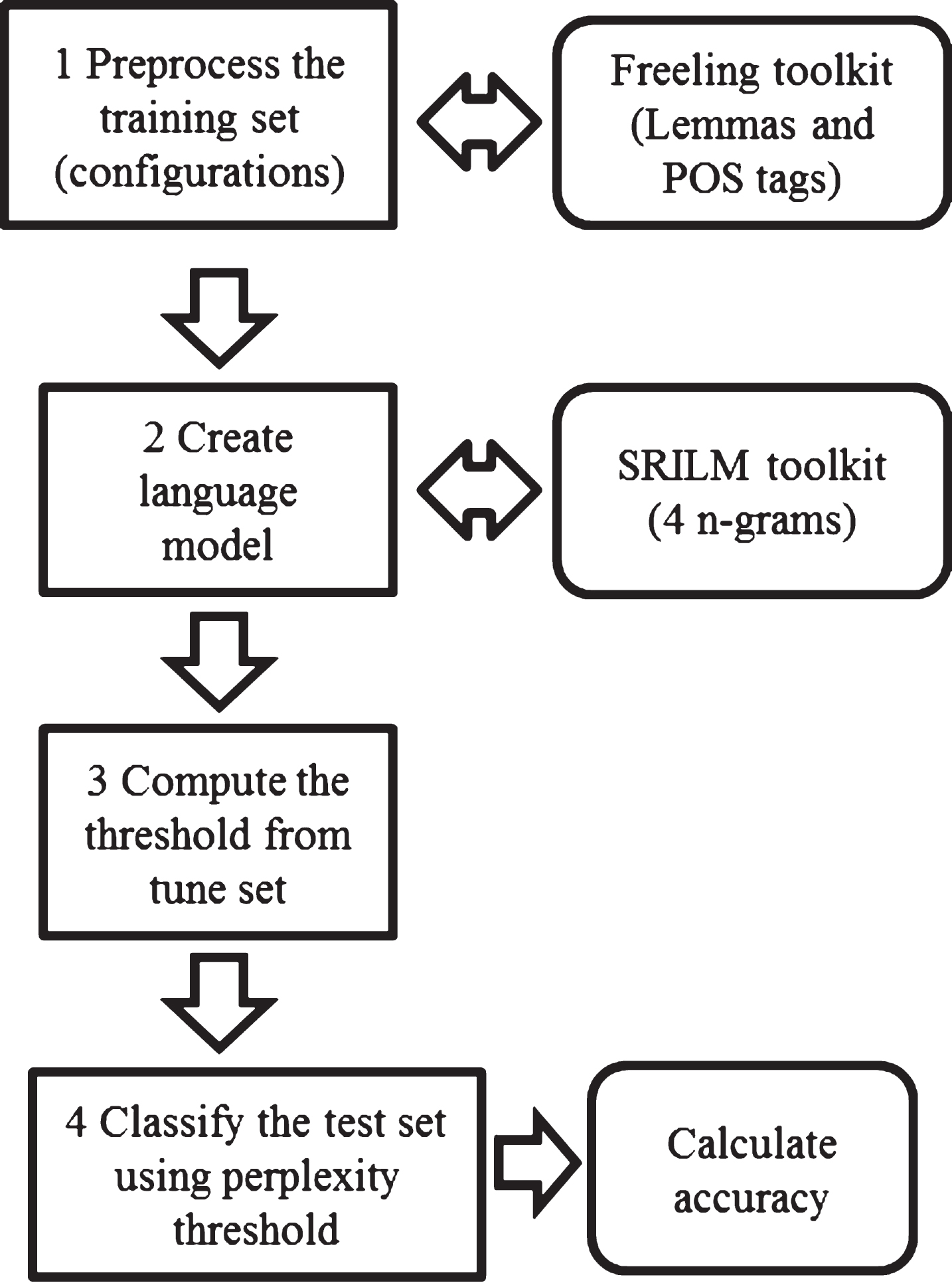
Process for classification using language models.
Sequence configuration examples for language model training
Second, we trained two language models one for premises and another for conclusions using the training set sentences. We obtained the two language models for each configuration of sequences of terms. We used SRILM [35] open-source software to train our language models with a 4-gram model. Third, to compute the threshold, we calculated the perplexity for the segments in the tuning set to find the mean and the standard deviation. We established a threshold of +/- 1 standard deviation around the mean to classify the argumentative component. Finally, we calculated the perplexity of the segments in the testing set to determine if they belong to the argumentative component. The classified instances were used then to calculate the accuracy for each configuration.
The machine learning approach for argument component classification relies on learning algorithms. These algorithms learn from annotated texts how to classify a new segment. However, before the text is fed to the algorithm, an important step is to create a representation. The first step is to pre-process the text with a text normalization, converting all words to lowercase. The next step is to perform a tokenization, that is, segmenting the text into tokens (basic units) as words or symbols [18], using the space symbol to separate words. We applied regular expressions for tokenization. Next, a representation can be created using a vector space model such as bag-of-words model, i.e. an unordered set of tokens, ignoring their position in the text, to represent each segment as a feature vector with the tokens in the vocabulary. The value of each feature is the frequency of appearance in the segment. That is, each text is represented by a vector of token counts (frequencies). The representation created for our experiments utilises diverse features as detailed in previous section. The vocabulary size for the features is presented in Table 5, we filtered the bigrams to get the 20,000 most frequent terms.
Sizes per feature type
Sizes per feature type
Once we have obtained the representation, a machine learning algorithm was employed to perform the classification task. The model was trained to choose the correct class (e.g. premise, conclusion, none) for a given text input. We applied several algorithms such as Support Vector Machine (SVM), Naive Bayes and Random Forest. The model was trained using the set of components previously annotated by human experts. For our experiments, the train set had 1513 instances, i.e. 90% of the corpus. The set of annotated texts acts as the instructor to our model. A test set is used to evaluate the model, and the efficacy depends on how similar the predictions of the classifier model are to the human annotation in the test set. The evaluation is done using customary metrics such as accuracy, recall, precision, and F-measure. We computed the accuracy metric to evaluate the efficacy of classifiers. It measures the fraction of inputs in the test set that the classifier model correctly separated [2]. We employed a test set from our corpus consisting of 170 instances to evaluate each configuration of features.
As previously mentioned, we also considered the Document Occurrence Representation. Once the corresponding vectors were built, we also applied a machine learning algorithm to train and test this DOR representation using unigrams since they achieved better results than bigrams and trigrams.
In this section, we report the experimental results for our two approaches, i.e. language models and machine learning. Also, we analyze the impact of testing the model at different academic levels. Finally, we present the information gain observed in several patterns of terms for the identification of argument components.
Language models
For identifying the best performing language model, we realized a series of experiments on the corpus using a 5-fold cross-validation with Scikit-learn Toolkit [28].
In Table 6, we show the different configurations for conclusion identification. We observed that lemmas with their tagPOS produced the best results in terms of accuracy. Although the accuracy in the experiments was not very high, the precision to identify the components exceeds 0.8. However, for the language model of conclusion, we can also notice that the second best accuracy corresponds to tagPOS configuration, with even higher precision.
Classification results using language model of Conclusions
Classification results using language model of Conclusions
In Table 7, we noticed that the language model of premises with the configuration of tagPOS obtain the best accuracy. For this model, we calculated a perplexity mean for the tune set of 16.99, for the training set the positive class (premises) with 16.97 and the negative class (conclusions) with 18.85. We observed levels of perplexity for the premises and conclusions quite close. We assume that this is due to the small number of instances, causing that the language model failed to extract the particularities of the premises and conclusions.
Classification results using language model of Premises
The detection of argumentative components was also approached as a multi-class classification task. We classified each segment in the corpus as premises, conclusions or none. Using lexical, syntactic, semantic and indicators features with algorithms of machine learning, we performed 10-fold cross-validation. We employed classifiers such as Support Vector Machine (SVM) [33], Naive Bayes [25] and Random Forest [7] since they have been previously used in argument mining. We ran their implementation from Weka machine learning toolkit [17], finding the best performance with the SVM classifier.
In Table 8, we observe that the lexical features obtain a good efficacy, however, when all the features are combined, the accuracy is slightly improved. The feature with lower accuracy is the indicators type, as expected.
Identification of argumentative components
Identification of argumentative components
After observing that lexical features had the best accuracy, we combined the lexical features with syntactic, semantic and indicators features. Table 9 shows the accuracy obtained with these combinations. We found the best combination with the lexical and semantic features. Both kinds of features achieved the highest accuracy individually. In addition, we explored using lexical, semantic and indicators features together, obtaining an accuracy of 74.09. Again the syntactic features combined with the lexical features produced the lowest accuracy, so syntax does not seem to contribute to differentiate components.
Combining features for identification of argumentative components
We performed experiments with several DOR representations using 10-fold validation with an SVM classifier of Weka. In Table 10, we present DOR representations for unigrams, bigrams and trigrams. We can notice that DOR unigram representation achieved the best accuracy with 76.35, an average F-measure of 0.74, that when analyzed in terms of particular classes, we have an F1-measure for premises of 0.80 and an F1-measure for conclusions of 0.50. The model identified better premises than conclusions, perhaps because the number of premises is more than twice that of conclusions. In terms of the representation, we confirmed in some way that DOR works well in classification of short texts.
Argument component classification with DOR representation
Argument component classification with DOR representation
We also performed experiments considering academic levels to test the efficacy of the best model found so far, in master and doctoral theses. So, we restricted to unigram DOR representation with an SVM classifier. In Table 11 we show three configurations of train/test sets to analyze the efficacy in different test sets. We found a better accuracy when we used the undergraduate level components as training set and test in the master level set. We presume the master’s theses have the closest style to the undergraduate theses rather than the doctoral theses which obtain a lower accuracy. However, taking the undergraduate and master level sets together, we observed a loss in accuracy when we classify the doctoral level theses. We suppose that the master theses are quite different from doctoral thesis introducing noise to the model. We obtained an F1-measure for premise classification above 0.70 for the three representations, which indicates that premises are more easily classified than conclusions. These results were also consistent with those given in Table 10.
Classification results of different train and test sets among Academic Levels
In the same direction, we formulated a second experiment to examine the quality of texts according to study levels, under the assumption that higher study level corresponds to a better quality of writings. Hence, we performed three experiments, training with master, doctoral or both levels theses an SVM classifier with DOR unigram representation again. We employed as the test set the undergraduate degree theses. As Table 12 shows, we notice the best accuracy when we employed the master level theses as the training set. We also observed the best classification of premises than conclusions, with practically the same F1-measure as in Table \ref table:resultClassLevels but with a more compact representation of DOR with only 490 instances. These results indicate that the features of master theses are closer to those of undergraduate theses than to doctoral theses. We presume doctoral theses as training set obtained a low accuracy because the set is smaller (177 instances) which produced a limited representation of DOR. However, another reason can be that doctoral theses have a higher number of sophisticated terms than master or undergraduate theses. We can also notice that when training with master and doctoral theses together, the classification of conclusions has a slight improvement, possibly caused by additional examples.
Classification results for training with graduate levels
We analyzed the information gain of n-grams to find out those more discriminative patterns using Weka toolkit. Table 13 shows a list of patterns with their corresponding information gain. The punctuation (e.g..,) obtained a high information gain, as well as words and patterns that are part of argumentative markers. We found argumentative marker “since” (“ya - que” in Spanish) which helps to identify premises. Also parts of markers such as “for the” (“por - lo” in Spanish) appears, that is also part of the marker “therefore” which is used to indicate a conclusion. We noticed stop words with information gain such as articles (e.g. “the”), prepositions (e.g. “to”), and conjunction (e.g. “and”), which can reveal a particular writing style.
N-grams with information gain. Patterns in Spanish
N-grams with information gain. Patterns in Spanish
We presented an annotated argumentative components corpus of theses and research proposals in the computer and information technologies domain, in Spanish. In the corpus, we found that the number of premises doubles that of conclusions. The proportion is observed in academic writings since the students often provide more than one piece of evidence to support their ideas.
We employed the corpus to perform experiments for argumentative component classification. After tackling the problem with language models, we conclude that these models require more instances for training to capture the particularities of the argumentative components. Therefore, we tried an approach employing classification using machine learning algorithms. We analyzed several feature types and found out that the lexical and semantic characteristics achieved the best accuracy. However, after analyzing the DOR representation using unigrams, we found an even better accuracy. We then tried this representation to analyze the efficacy of the model trained only with undergraduate theses and tested in graduate level theses. We found that master’s theses seem to be closer to undergraduate theses than to doctoral theses.
Also after experimenting with DOR representation and the collection divided in academic levels, we found that master level theses were quite descriptive of premises, reaching acceptable efficacy with a smaller training corpus. The classification of conclusions has still a good margin for improvement, in any case.
We also analyzed the information gain of n-grams. We obtained several patterns through the information gain that correspond to parts of argumentative markers. For example, the argumentative marker “since” (“ya - que” in Spanish) provides information to classify argument components. Also, we found that some stop words provided information for the classification of argument components. We presume these patterns also reveal stylistic aspects of academic writings in Spanish.
In future work, we will explore the use of features such as the context of nearby sentences, component location in the paragraph and the syntactic structure of the component for argument component classification. Also, we plan to experiment on relation identification between argument components using semantic similarity and machine learning algorithms. To conduct a complete analysis of new students’ texts, in future experiments, we intend to tackle the segmentation task of texts along the argumentative component classification.
Footnotes
English translation of a justification in Spanish.
We are currently working to make the corpus available to the community. Researcher interested on it can contact the corresponding author.
Acknowledgments
We thank the annotators for the assistance in the corpus creation. The first author was partially supported by CONACYT, México, under scholarship 357381.