
Abstract
Academic writing is a complex task which requires the author to be skilled in argumentation. The goal of the academic author is to communicate clear ideas and to convince the reader of the presented claims. However, few students are good arguers, and this is a skill difficult to master. Aiming to contribute to develop this skill, we present a freely available annotated corpus to support research in argumentation in Spanish. To build it, we elaborated an annotation guide to identify argumentation in paragraphs. The guide also specified how to determine segments of sentences as a claim or premise, and to indicate relations (support or attack) between such segments. Then, an annotated corpus of 300 sections was created. After its construction, the corpus was used to perform an exploratory analysis which aimed to identify and present the amount of argumentation in each section, as well as resulting patterns for argument identification. Hence, we also report an exploration of lexical features used to model automatic detection of argumentative paragraphs using machine learning techniques. The results of the experiments to evaluate argumentative paragraph detection were encouraging. In addition, we discuss a web-based prototype for argument detection in paragraphs to reach the broader academic community of students, instructors and researchers.
Keywords
Introduction
Academic writing is a complex task which involves mastering a good argumentation skill. This skill is required to support presented claims with solid arguments. For scientific texts, in particular, evidence has to be presented in the form of reasoned arguments so that the reader is led to an appropriate conclusion [25].
In recent years, researchers have studied the task of automatic processing of arguments. This task is addressed interdisciplinarily with a combination of artificial intelligence techniques and theories of argumentation, to improve the information extraction. In the legal field, the aim is to facilitate access to jurisprudence that supports a case [28, 29]. Automatic argument analysis has been studied in political documents for classification of arguments into concepts and modes such as policy, fact, and value [13]. In scientific articles, particularly in biomedicine, automatic processing of arguments can be used to identify rapidly arguments for or against a hypothesis under investigation [18]. Argumentation analysis is also applied in social networks to identify the overall stance of comments (for or against) in a debate [7]. There have been also studies focused on the assessment of argumentation in essays [33].
The act of writing is a challenging process that involves several stages such as planning, editing, and review. In the academic field, the instructor usually performs the review, analyzing the writing to identify errors and point them out to the learner. This is a task that can be greatly assisted by computational tools. During editing, such tools can provide indications for the student, to achieve a good quality writing, before the draft is submitted to the instructor. Examples of tools currently available are Criterion [5], Writing Pal W-Pal [35] and SWoRD [10]. The tools are used to provide general support in several linguistic dimensions. For argument analysis, tools such as MARGOT [26] can identify argument components. Argrewrite [43] extracts and analyzes revisions considering the argumentation component. For annotation of fallacious arguments, Argotario [20] employs a serious game approach to facilitate data creation and annotation. Still, there remains an absence of systems aimed to analyze automatically textual argumentation in large and complex academic works such as theses, in particular in the Spanish language. Academic theses are often written at the end of college and constitute one of the major intellectual academic requirements for graduation, being in consequence important for students success. For this reason, an annotated corpus and a model to automatically detect paragraphs with an argument is a first step aimed to support students in this challenging task.
In this paper, we present a freely available annotated corpus to support research in argumentation in Spanish as our first contribution. We discuss the annotation guide developed for the corpus creation. The built corpus has 300 sections with annotated argumentative paragraphs, argumentative components, and relations. We focused on the following sections of a thesis or proposal: problem statement, justification, and conclusions. From the annotated corpus, we performed an exploratory analysis to identify the amount of argumentation in each section, and the resulting patterns for argument identification. A second contribution is a first model on this corpus for automatic detection of argumentative paragraphs from lexical features, using machine learning techniques. An experiment to evaluate argumentative paragraph detection was conducted and its results detailed. Additionally, we present a web-based prototype which can be used to perform argument detection in paragraphs, to support students.
The paper is structured as follows. In Section 2, we present argumentation concepts, structures and examples. Section 3 details related work for building annotation schemes and argument identification. In Section 4, an explanation of our methodology for corpus creation is provided. We also present the corpus analysis and discriminative patterns in argumentative paragraphs. In Section 5, we report the results of our model for automatic argument detection. In Section 6, we present the prototype implementation. Finally, we conclude with some final remarks and work in progress.
Argument structure
An argument is a set of assertions, that individually or as a whole support another statement [8]. The assertion supported is called a conclusion. There is only one conclusion for each argument; however, each conclusion can be based on a series of supporting assertions. Assertions that provide support are called premises. Among argumentation theories [15, 42], the consensus is that the structure of an argument consists of several argumentative components. In this work, we adhere to the conclusion-premise model [15] since introduces structures used in argument mining [19].
A graphical representation of an argument structure helps to understand how argument components are interacting. This technique is referred as argument diagramming which aids the students in formulating their arguments. In this, we mark each premise and conclusion with a letter associated to a node of a graph. Then, directed arcs (arrows) are used to indicate relations between the components. A simple argument has only one premise that is used to support a conclusion [41].
[Today educational institutions have a greater number of computers with Internet.]/
As we can observe in example 1, the first sentence is a premise (in square brackets /P1) supporting a conclusion in the second sentence (in square brackets /C2). In a simple argument, a premise provides elements to sustain the veracity of the associated conclusion. Figure 1 illustrates a simple argument structure where the premise P1 supports the conclusion C2.

Simple argument diagram.
As we can notice in the argument example 1, the word "therefore" plays an essential role in the identification of a possible conclusion; these patterns of words are called argumentative markers and can help with the detection of elements in an argument.
Arguments can have more than one premise as support, as mentioned previously. In Figure 2, we observe four types of structures for arguments. A convergent structure has several supporting premises, where is possible to eliminate either one of the premises and the conclusion is still supported [41]. A linked structure has two premises which together are used to provide support for a conclusion. A divergent structure has a unique premise to support several conclusions. A serial structure has arguments deployed in successive order, where the conclusion of one component acts as a premise for another element [15]. All these structures can be combined in a more complex one.
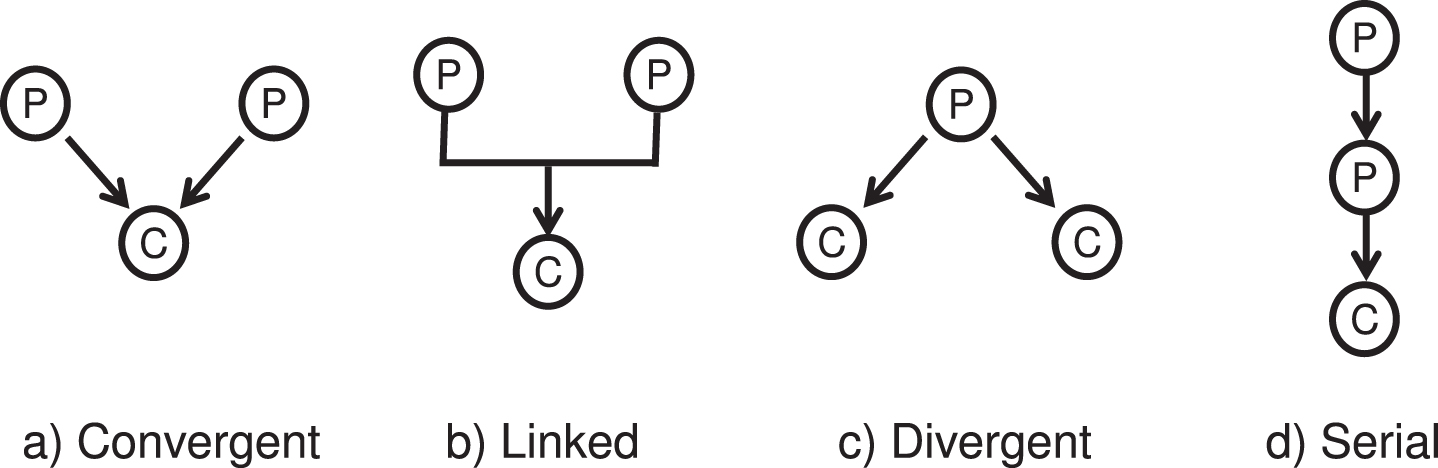
Structures of arguments.
In recent years, argument mining has been intensely studied. Here, we concentrate in two particular tasks, i.e. corpus creation and argument detection. We require these tasks to develop our model. Argument mining involves the automatic extraction of arguments from unstructured text. The first task is the corpus creation to validate the efficacy of the proposed method. As found in the literature, most of the researchers in the field of argument analysis create their annotated corpus, using certain argumentative scheme. We identified a number of annotated corpora available. One of the corpora most used among researchers to detect the presence of arguments in English is Araucaria [22]. The corpus has several types of documents with annotated premises, conclusions, and the argument scheme utilised. However, it lacks of the level of agreement between annotators, which turns it unreliable for this study.
Corpus creation has been done in different types of text, as well as in various domains. In [28], a corpus was built with ten legal documents from the European Court of Human Rights (ECHR) corpus, with annotated premises and conclusions. In this corpus, the level of agreement between the two annotators was a Kappa of 0.80. In a further study [29], the authors expanded the number of annotators to three and the amount of documents in the corpus to 47, where the level of agreement among annotators decreased to a Kappa of 0.75. It is important to note that dealing with legal texts with a clear structure facilitates the annotation process and increases the level of agreement. In other research [38], 90 persuasive essays on randomly-chosen topics were annotated by three persons. They annotated argumentative components with a level of Krippendorff’s alpha agreement for the component of major claims of 0.83 (stance of the author), premises with 0.70 and claims with 0.65. In a more recent work [39], the corpus was increased to 402 essays and 80 essays were analyzed by three annotators. They reported an inter-rate agreement of Fleiss Kappa of 0.877 for major claims, 0.635 for claims and 0.833 for premises. [23] created a corpus with 24 scientific articles in education for the sections of introduction and discussion. Four participants annotated argument components of premises and conclusions, as well as four relationships between the argumentative components of support, attack, sequence and detail, with an average in the level of agreement of Fleiss Kappa of 0.41. We observed that obtaining acceptable levels of annotation agreement in scientific texts is a difficult task, which depends on an appropriate annotation guide and regularly monitoring annotators during the corpus construction. For our research, the closest kind of document is scientific articles since academic theses typically share a similar structure but are longer.
Once we built the corpus, we performed the task of detecting the presence of arguments either in paragraphs, sentences or clauses. In [30], an automatic identification of argumentative and non-argumentative sentences in Araucaria corpus was performed. They represented sentences with features such as combinations of pairs of words, verbs and text statistics, using a naive Bayes classifier, and achieving a 73.75% of accuracy. In the research with legal texts in ECHR corpus [29], an accuracy of 80% was reached. Another approach for argument detection was reported by [14], who employed a set of discourse markers and features based on mood and tense of verbs. They achieved an F1-measure of 0.764 using a decision tree classifier. In [17], they performed identification of argumentative sentences, employing structural, lexical, contextual and grammatical features to represent each sentence. With a logistic regression classifier, they obtained an F1-measure of 0.771 on a corpus of 204 documents collected from social media written in Greek. They also performed identification of argument components (claim and premise). For the task, they applied a Conditional Random Fields (CRF) classifier to obtain an F1-measure of 0.4237. Also, [37] presented a similar approach with CRF and distributed representations of words to identify segments that correspond to argument components. For this task, they reported an F1-measure of 0.3221. The segmentation of argumentative units is also tackled in [1] using algorithms such as SVM, CRF, and Bi-LTSM (bi-directional long short-term memory) with semantic, syntactic, structural and pragmatic features. With all the features and Bi-LTSM, they reached 0.885 in F-measure, identifying segments with argumentation in academic essays.
A more fine-grained analysis of argument detection involves identifying components and relations. The tasks have been tackled separately and jointly by different researchers. For component identification [17, 38], researchers carried out a segmentation of the argumentative text and then classified each segment into its respective argumentative component (e.g., premise or conclusion).
We now detail the annotated corpus and the argument identification method that is compared against a pair of previous techniques. The two tasks are employed in our model to perform the automatic argument identification and a prototype implementation.
Corpus construction
Annotation process
For the annotation process, we have designed first a guide for argument annotation. We consider two argument components: premises and conclusions, as well as two types of relations between components: support and attack. In our annotation guide, we described different argumentative structures with their argument components (conclusion/premise) and their relations (attack/support). We also included types of arguments and a rank to establish the level of argumentation found. Moreover, a set of examples taken from academic theses was included to support the annotator. Finally, at the end of the 29-pages guide, we presented the annotation procedure.
The procedure of the annotation guide includes the following steps. First, the annotator is required to read the title and objective of the thesis or proposal. Then he has to identify if the text includes a conclusion. Next, the annotator has to determine the ideas that support the conclusion and mark them as supporting premises. Also, we advised the annotator to mark complete sentences or clauses as a conclusion or premise. The premises were indicated using square brackets and adding at the end /P, that is: [text of premise]/P. For the case of conclusions, in a similar way, the text was enclosed in square brackets ending with /C, i.e.: [text of conclusion]/C. Additionally, the annotator was asked to indicate the type of argument found in the paragraph, where the types most commonly used by students in academic texts are authority, example, causal, analogy, and comparison. Finally, the annotator assesses paragraphs according to their level of argumentation, based on the score detailed in Table 1.
Argument assessment score
Argument assessment score
As shown in Table 1, texts without any argumentation have a score of zero; this is the case for descriptions or definitions. If the annotator found at least one conclusion, i.e. if there is only one conclusion with no premises, the annotator assigned the score of one to the paragraph. If a conclusion and at least one premise are located in the paragraph, a score of two is assigned. That is, the medium rank is used to indicate paragraphs with a simple structure. If we found a conclusion and two or more premises in the paragraph, the highest score is assigned (3) that indicate the presence of strong argumentation. Arguments with structures such as: convergent, divergent, linked, serial or more complexly joined, are considered in this highest rank. In this way, the annotators assessed the paragraphs of the corpus.
Professionals with experience in the revision of academic and opinion writings were in charge of the annotation. The annotators have a background in philosophy and in political science. The logic of argumentation is of interest in Philosophy, and the analysis of arguments of political discourse is studied in political science. These skills allowed the annotators to identify the structure of the arguments in research proposals and theses. With the guide, we showed to the annotator how to identify the conclusions, premises, and relations, and also, how to evaluate arguments in paragraphs.
The corpus was organized as a structure consisting of a set of academic theses or research proposals. Each item has associated a title, academic level and a set of sections, such as: problem statement, justification, and conclusion. Each section has a type, filename and a set of paragraphs. For each paragraph, there is an argument level, argument type, relation type and a set of argumentative components (premises or conclusions). The paragraphs with no arguments lack of an argumentative component. In Figure 3, we show a diagram of the structure of the corpus with one thesis, to illustrate the elements in the corpus. There, Thesis 1 contains the title and level (e.g. undergraduate, master or doctoral). Thesis 1 also includes Section 1 which has section type and filename. Section 1 has two paragraphs. The paragraphs have argument level (e.g. none, weak, medium or strong), argument type and relations (support or attack). Paragraphs annotation 1 has two components and Paragraphs annotation 2 has three components annotated.
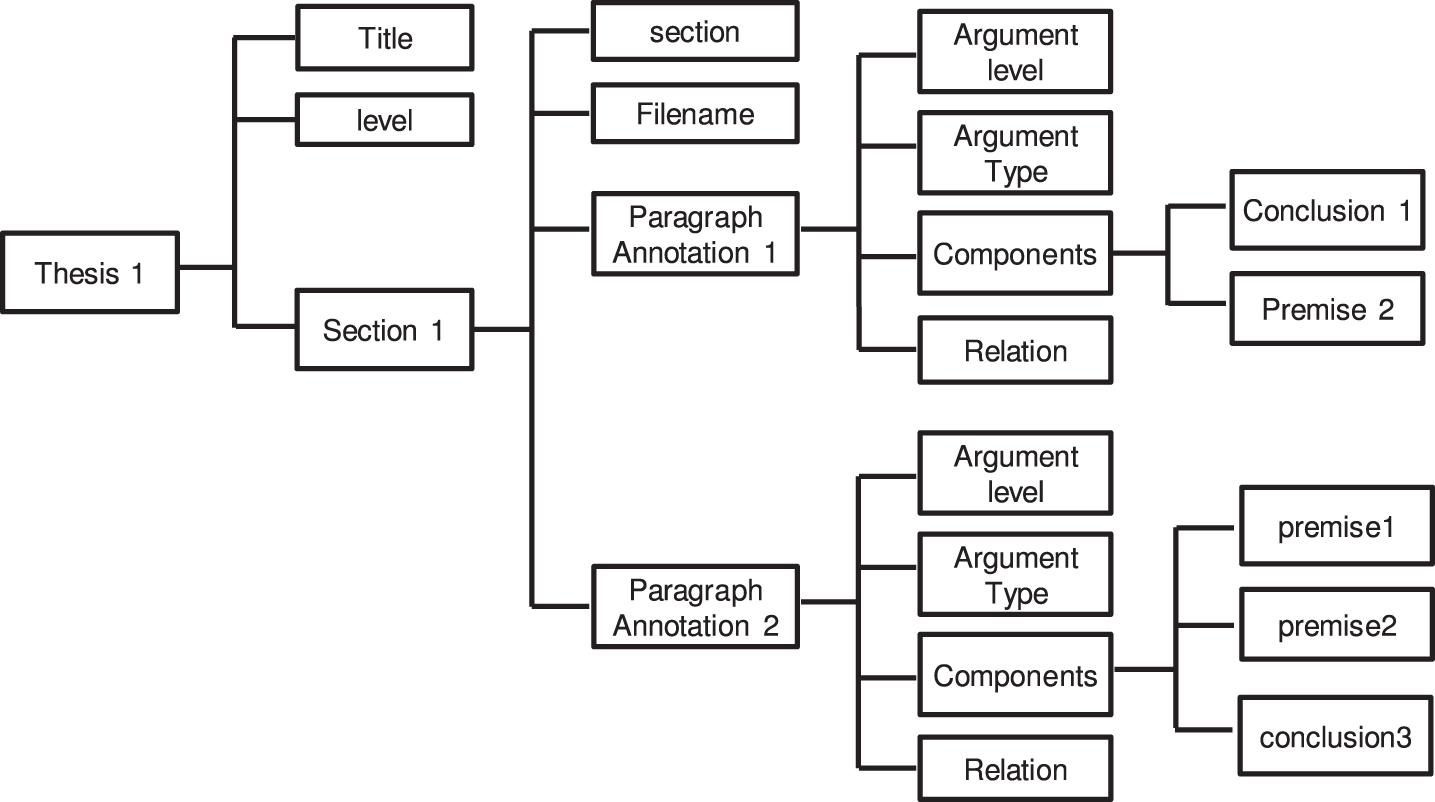
Example of a structure of a record of the corpus.
We employ XML markup to preserve the document structure existing in the original layout. We followed TEI p5 markup (the Text Encoding Initiative format) [12], and chose a subset of structural elements to convert the original annotation text and create the corpus. We adopted TEI elements in the final corpus. Element "desc" with the attribute "type" is used to indicate, at the paragraph subdivision, the argument level, type, and relation. The attribute "type" is also employed to include the section type name (e.g. justification) and the filename of the section at the section subdivision. At theses subdivision, the attribute "type" is utilised to include the academic level (e.g. master). The "seg" element is used to indicate a segment of premises and conclusions using the attribute "type". The exact or partial agreement in text boundaries between annotators is pointed with the "function" attribute. The rendering (rend) attribute is used to display conclusion in bold and premise in italics.
In Figure 4, we present a thesis sample in TEI XML format. In this example, we include a thesis of master level with a justification section which has one paragraph. These segments are defined using the <div> element in lines 38, 44 and 50. In the paragraph, we observed the use of <p> element to indicate paragraphs with the annotation of argumentative components with <seg> element. This paragraph has annotated three premises and one conclusion. In lines 54 to 56 we notice the argument level to 3, type of argument as causal and there are support relations in the paragraph.

Screenshot of a thesis sample of the corpus in TEI XML format.
In addition to the corpus in TEI format, we also provide access to the original annotation texts. Besides we transform the annotations to brat rapid annotation tool (BRAT) format to provide a graphical representation of the annotations through the BRAT system, since this annotation system is widely used in the community. The corpus is shared for academic purposes under a Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International License. The corpus in TEI format, the annotation guide, the original annotation documents in TXT and BRAT format can be downloaded at the corpus site 1 .
We analyzed the corpus created to identify the argumentative characteristics in academic writings of undergraduate and graduate level. The writings come from Coltypi collection of theses [16]. The collection has 468 theses and research proposals in the computer and information technologies domain, in Spanish. The texts are from undergraduate (TSU and Bachelor Degree) and graduate level (M. Sc. and Ph.D.). In particular, our study focuses on the sections of the problem statement, justification, and conclusions. These sections are considered highly argumentative [27].
After analyzing the collection, we observed that each section contains an average of 11 sentences. Each sentence consists of 35 words on average with a total of 398 words per section. The size of sentences for the undergraduate level is 38 words per sentence which turn it harder to read, in contrast to the doctoral level, having an average of 30 words. Based on these findings, we consider that doctoral writing is more concise and of a higher quality than undergraduate level, and we can take it as a reference.
We performed the corpus annotation of 300 sections with the two annotators, following the annotation guide detailed in Section 4.1. The annotation process had a duration of five months from May to September 2016. This was a challenging task for the annotators since varied computer complex concepts were discussed in the theses. The analysis of inter-annotator agreement (IAA) for the annotations considers the paragraphs with observed agreement by two annotators (i.e. different of zero) in the identification of argumentative components (e.g. premises or conclusions). A total of 901 paragraphs were analyzed to compute the IAA with Cohen Kappa [11]. The IAA for the different sections was: 0.867 for Problem Statement; 0.935 for Justification; and 0.866 for Conclusion, that correspond to “Almost perfect” agreement [24]. Also, we notice that the section of justification was easier to annotate, we suppose that this is due to the fact that it has few paragraphs (from 1 to 4) and the purpose of the section is to provide elements of the importance of the research.
As shown in Table 2, most sections have more than half of the paragraphs with arguments. We selected only the paragraphs where the two annotators agreed. This restriction reduces the number of paragraphs to 856 with 1,913 sentences and 76,841 words. From 856 paragraphs analyzed, we found that 584 are argumentative with a proportion of 68.2%. From the analysis, we observed that a significant amount of paragraphs in academic theses have arguments. One characteristic of the corpus is that the conclusion section includes more paragraphs per section, compared to the sections of problem statement or justification. Moreover, we found a higher number of paragraphs with arguments in the conclusion section.
Distribution of argumentative paragraphs per sections
Distribution of argumentative paragraphs per sections
The distribution of paragraphs among academic levels is: 63.3% of undergraduate (542 paragraphs), 27.7% of master (237 paragraphs) and 9% (77 paragraphs) of doctoral level. The section with more paragraphs is that of undergraduate level, our main focus for analysis to help students at college. Also, we observed more the 65% of argumentative paragraphs per level. The IAA per academic level produced a Kappa of 0.899 for undergraduate, 0.894 for master and 0.770 for doctoral. The results indicate an "Almost perfect" agreement for master and undergraduate level. Since the undergraduate level represents the majority of our corpus, these texts were easily annotated by the experts. In addition, we obtained an overall Kappa of 0.886 for the complete set. In Figure 5, we depict the frequency of paragraphs with an argument in sections. There are 63 sections without argumentative paragraphs, and 62.6% of the sections have one to three paragraphs with an argument (i.e. 188 sections).

Frequency of paragraphs with an argument in sections.
We performed the analysis of IAA of two annotators at a more fine-grain level, considering argument components within the paragraphs, that is, the premises or conclusions. A total of 2,862 segments were used to analyze the IAA with Cohen Kappa [11]. The IAA Kappa found for Justification section was 0.598, Problem Statement section was 0.581 and Conclusion section was 0.563. The three sections had a Kappa measure above 0.563, that corresponds to a "moderate" level [24].
In Table 3, we summarize the number of segments labeled by two annotators as conclusion, premises or without any label (none), per section. We only selected segments where the two annotators agreed. This restriction reduced the number of segments to 2,104. We found a total of 1060 premises and 562 conclusions, almost the double of premises compared to conclusions.
Distribution of argument components per section
In total, we obtained 1,622 argumentative components (premise or conclusion). The distribution of argument components among academic levels was 62.8% for undergraduate (1018 components), 27.5% for master (446 components) and 9.7% for doctoral (158 components). We found an IAA Kappa for the doctoral level of 0.607, the undergraduate of 0.585 and master of 0.554. We got a moderate level of IAA for the three academic levels. The general agreement for academic theses levels is an observed agreement of 73.5% and a Kappa agreement of 0.578 with a moderate level.
In Figure 6, we can notice that 43.3% of paragraphs with an argument (232) only have one premise and there are 175 paragraphs with two premises (32.7%). The majority of paragraphs with an argument (96%) have from one to four premises, but can have as many as eight. In Figure 7, we detailed the frequency of conclusions per paragraph. Most of paragraphs with an argument 87.7% (i.e. 435) only have one conclusion, only a few have two or three.

Frequency of premises in paragraphs.
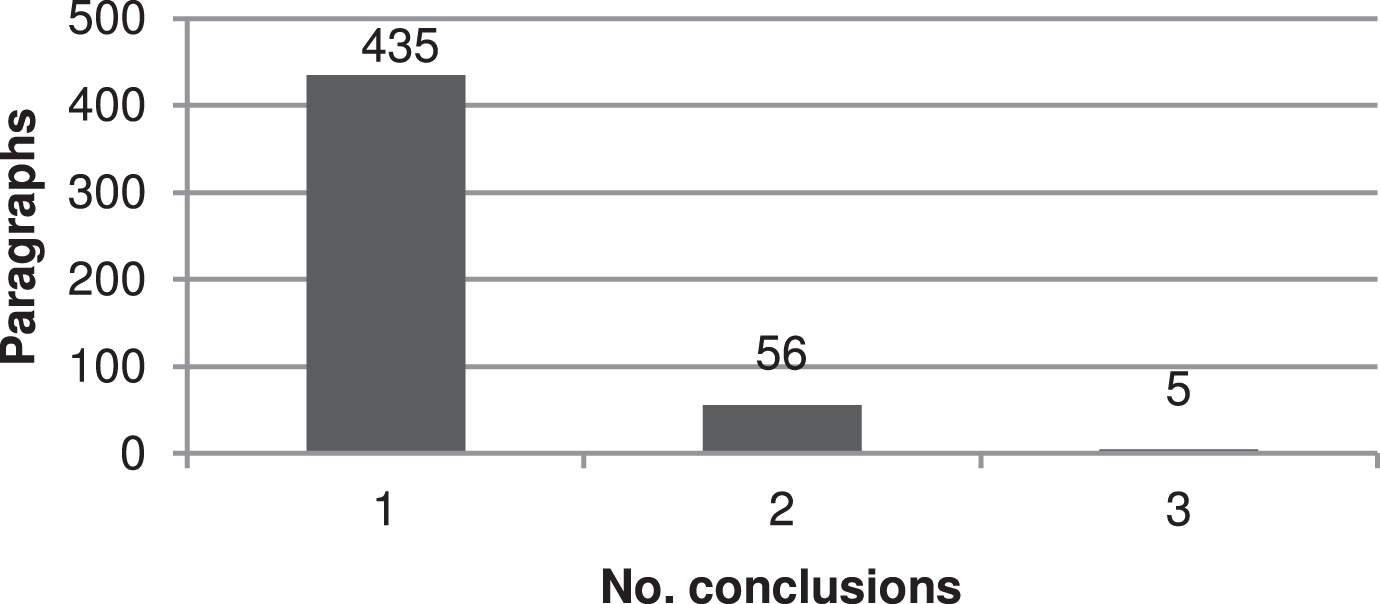
Frequency of conclusions in paragraphs.
For relation agreement, we calculated the possible combinations of pairs of argument components for each paragraph. The paragraphs taken into account have at least one conclusion and one premise. We also consider the direction in the relation, from a source component to a destination component, for instance, a relation from a premise that supports a conclusion. We found 447 paragraphs under these considerations, leading to 3,692 pairs. In total, the relations with agreement taken into account are 3,255 pairs of which 15.9% are support relations, 1.2% as attack relations and 82.9% non-linked pairs. We found an IAA Kappa of 0.654 for support relation and 0.632 for attack relation, corresponding to a “substantial” level for attack and support relations.
We found that most of the relations are of support, accounting for 517 and only 38 attack relations, where the support relations are mainly established between a premise to a conclusion with 506 relations. The attack relation is found in the corpus mainly between a premise to another premise component, totaling 32.
Computing IAA Kappa per section, we found that Conclusion section had 0.696, Justification section got 0.630 and Problem Statement section obtained 0.590. The three sections produced a Kappa value corresponding to a "moderate" level. The highest IAA observed was for the Conclusion section, indicating that this section is easier to annotate than the other. Regarding relations, the Conclusion section has 277, Problem Statement 150, and Justification included 128 annotated relations.
According to academic level, we observed an IAA for argument relations with a moderate level. The IAA Kappa for undergraduate was 0.675, master was 0.609 and doctoral level was 0.601. We found 363 annotated relations at the undergraduate level, master level included 137, and doctoral level showed 55 relations. We noticed that undergraduate level got the highest IAA Kappa of 0.675, which indicates that this type of theses can be more reliably annotated than the other.
We also analyzed the sequence of argument components in these 447 paragraphs. The top five combinations are shown in Table 4. The combination of CP (conclusion, premise) is the most frequent, appearing in 23.9% of the paragraphs.
Frequent combinations of argument components per paragraph
Finally, we found a majority of paragraphs with the type of causal argumentation from these 447 paragraphs. In total, 414 paragraphs included a causal type, nine paragraphs with example type, three with authority type. The types of argumentation of analogy and comparison did not appear in any paragraph.
We detected 372 paragraphs with agreement in relations structures from the 447 paragraphs selected. The different structures occurring in the set were 15 graphs. We got 238 graphs with simple argument structure and 76 graphs with convergent argument structure. Most of argumentative graphs found present a simple argumentative structure, from a premise component to a conclusion component. The convergent argument structure was composed of two premises that support a conclusion.
We analyzed the created corpus and found patterns for identification of argumentative paragraphs using information gain to identify the discriminative patterns. Information gain measures the amount of information attained by knowing the value of the attribute or pattern. The fifteen unigrams (single words or tokens) with more information gain were: "ya, es, que, ’,’, por, lo, no, sin, de, el, en, esto, debido, ello, ’.’ " (in English "as, is, what, ’,’, for, the, no, without, of, he, in, this, due, it, ’.’ ").
For bigrams of terms (pairs of consecutive terms), we obtained the following list of the twenty more informative: "ya-que", ",-ya", "por-lo", ",-por", "por-ello", "es-por", "a-que", "lo-cual", "lo-tanto", ".-es", "debido-a", "el-caso", ".-por", "del-software", "sin-embargo", "tipo-de", ".-para", "por-ejemplo", ",-en", "de-recursos". In this list of bigrams, we identified parts of argumentative markers such as "ya-que", "por-lo", "lo-cual", "lo-tanto", "sin-embargo" and "por-ejemplo" (in English "since, for-the, which, so, however, for example").
We also analyzed the part-of-speech (POS) tags, which indicates the type of role a token is playing in a sentence e.g. nouns, verbs, adjectives, adverbs, etc. We use the FreeLing language analysis tool [31] for POS tagging. We took advantage of this POS tag information to detect the ten main verbs with higher information gain, and these were: "tener, alcanzar, deber, poder, ayudar, aumentar, ocurrir, usar, utilizar, involucrar" (in English "to have, to achieve, to due, to be able, to help, to increase, to occur, to use, to utilise, to involve"). Here, we found verbs like "deber" (in English "due") which is part of the argumentative marker "debido a" (in English "due to").
In addition, we examined the five unigrams and bigrams of POS tags with more information gain. The POS tag unigram with more information gain is VSIP3S0 which is a verb in present tense third person singular (e.g. "es"; in English "is"). In second place appeared the PD00S00 tag indicating a demonstrative pronoun like "this". Third was a subordinate conjunction "CS" (e.g. "que"; in English "since"). Fourth place was the article DA00S0 like "the" and finally the POS tag AQ0CS00 which is an adjective.
In Table 5, we list the POS tag bigrams, being that with highest information gain the pair RG-CS consisting of an adverb and a conjunction (e.g. "ya-que"; in English "since") which is an argument marker.
Bigrams of POS tags with information gain
Bigrams of POS tags with information gain
The five POS trigrams (three consecutive tags) with higher information gain were: "Fc-RG-CS (", -ya-que"), Fp-SP-NCMS000 (", -por-ejemplo"), VSIP3S0-SP-PD00S00 ("es-por-ello"), SP-NCMS000-Fc ("sin-embargo-,"), AQ0CS00-NCFS000-SP ("mayor- cantidad -de"). For the first trigram Fc-RG-CS, we found again that the bigram RG-CS with Fc which is the comma punctuation mark (","), that is comma-adverb- conjunction (e.g. ", -ya-que"; in English ", since").
Finally, the argumentative markers with some information gain were: "ya-que, que, deber-a, por-ello, por-el-que, para, por-el-tanto, sin-embargo, por-ejemplo, pues, por-ese, pero, aunque, ser-por-ese-que, por-tanto, como - consecuencia, por-consiguiente" (corresponding in English to "since, what, due to, thus, so that, for, therefore, however, for example, as, because, but, although, that is why, so, as consequence, consequently"). The most informative marker was "ya-que" (In English "since") which is widely used in academic texts to indicate a premise.
For our experiments, we used the annotated corpus described in the previous section. For argumentative paragraph detection, we utilised the annotations of 856 paragraphs, annotated as argumentative or not argumentative. We found a proportion of 68.2% paragraphs with arguments and for paragraphs without arguments the remaining 31.8% (Table 6). For processing the corpus, we employed the NLTK toolkit for tokenization and feature extraction [3].
Class distribution among instances
Class distribution among instances
The features extracted for our vector representation to identify paragraphs with arguments were lexical and indicators. The lexical features considered were: unigrams for all terms in the paragraph including some punctuation symbols (.;:,) and bigrams, i.e. consecutive pairs of terms in the paragraph including also some punctuation. The indicator feature corresponds to five sets of word patterns (argumentative markers) that were taken to obtain the occurrence frequency of each of the following categories: justification, explanation, deduction, refutation, and conditional. We created the sets of patterns based on the review of different sources of argumentative markers in the Spanish language [4, 36].
The task was approached as a binary classification for each paragraph, i.e. identifying whether it contains arguments. For validation, we employed a stratified 10-fold cross-validation using Scikit-learn Toolkit [32]. To perform the classification, we utilised the algorithms implemented in Weka machine learning toolkit [21]. We applied Support Vector Machine (SVM) [38], Naive Bayes [30], J48 implementation of C4.5 Decision Tree (DT) [14] and Random Forest (RF) [9] classifiers, since they have been previously tested in argument mining.
Vector representations were used to identify paragraphs with arguments. Five representations were built and tested to compare the efficacy on the task. The first representation is a baseline consisting of unigrams, i.e. all terms in the paragraph. For the second representation, we used word embeddings, specifically those of Polyglot [2] trained with Spanish Wikipedia. Polyglot contains words with vectors which represent the meaning of the word. Word embeddings map the index of a word in a dictionary to a feature vector in a high-dimension space. This vector is learned with a neural network by back-propagating the error in the model to update the initialized embeddings. The model utilised is CBOW (continuous bag of words), since this used the context to train the vector of each word. The context is a set of word vectors randomly initialized, which are the previous and following terms of the trained word. The number of word embeddings contained in Polyglot for Spanish is 100,004. The word embedding vector has a size of 64 features. For each paragraph, we calculate the average of word embeddings. The third representation is feature set proposed by [14] consisting of categories of discourse markers and features based on mood and tense of verbs. The fourth representation is proposed by [30] consisting of combinations of all possible pairs of words, main verbs and text statistics.
The fifth representation is our proposal consisting of a Document Occurrence Representation (DOR), from unigrams and bigrams. This representation is based on the “latent” semantics of a term, that can be revealed by the statistical distribution of occurrence over the documents in the corpus. A term is represented as a vector of weights associated with documents in the collection. The weights represent the contribution of a document to the semantics of a term [6]. The term vector size for a DOR representation is equal to the number of documents (769 paragraphs/dimensions) in the training set. We associated a vector to each term (unigrams and bigrams). The representation for each instance is calculated adding all the unique term vectors in a given paragraph. Subsequently, we merged the DOR representation with the categories of argumentative markers, which are the number of argumentative markers in each category found in the paragraph, as detailed previously in the indicator feature.
We built the five representations which included words and some punctuation symbols. Then we trained the classifiers with the data set for training and applied them to the test data set. In Table 7 we report the accuracy achieved by the classifiers. We noticed that the SVM and RF classifiers reached the best levels. Table 8 shows the macro F-measure and accuracy of each representation for their ten folds for the best classifier for each representation. As we can notice, the baseline was quite competitive in terms of F-measure and accuracy when compared with the representations previously proposed by Florou and by Moens. However, our representation achieved the best F-measure with 0.815 (computed from a 0.805 of recall and precision of 0.826) and 84.22 of accuracy to identify paragraphs with arguments using SVM classifier. With these results, we reached enough support for the use of the proposed representation to perform the identification of argumentative paragraphs in academic texts.
Accuracy of classification of argumentative paragraphs
Classification of argumentative paragraphs results
With the aim of eventually providing online evaluation and feedback to students, we have already implemented a prototype at a website 2 . The prototype is available as a web server, where users can submit their plain text drafts (no format required). Figure 8 shows the input interface. Once the user clicks the Analyze button ("analizar" in Spanish), the system processes the text and performs a validation, requiring a minimum length of 12 words for the submitted text.

Input web interface of prototype for evaluation.
In the input interface illustrated in Figure 8, the user has available several examples of academic text for sections such as problem statement, justification, and conclusion, intended to test initially how the prototype works. The first step to analyze the submitted text is to find the paragraphs (text ending with a period "." and followed by a new line character). From each paragraph, we extract the features for our representation as unigrams, bigrams and argumentative markers using the NLTK toolkit. Then unigrams and bigrams terms are used to create a DOR representation with the five categories of argumentative markers. The SVM classifier used the representation to predict the class for each paragraph. Finally, a result HTML page is presented to the user.
In Figure 9, the output of the analysis is shown, where the detected argumentative paragraphs are in blue and paragraphs without detected arguments in red. We also report the percentage of argumentative paragraphs (50% in Figure 9) in the evaluated text and the number of paragraphs with argumentation (one paragraph in the example).

Prototype output interface: result of paragraph analysis.
There is a significant amount of paragraphs with arguments in academic work (research proposals and theses). With the analysis of the corpus, we realized that more than half of the paragraphs written by undergrad students include arguments mostly with causal argumentation. Argumentative components consisted of almost twice the number of premises than conclusions. The most common order for components found in paragraphs is one conclusion and one premise with a support relation, i.e. the simple argument structure is the most common in our corpus. The paragraph and component annotation agreement for Justification section achieved the best inter annotator agreement which indicated that was easier to annotate, we suppose that this is due to the fact that such section commonly has few paragraphs (1 to 4) and its purpose is clearly to provide elements of the importance of the research.
In our analysis of discriminative features, we observed the existence of several relevant markers, specific for supporting premises, attack premises, and conclusions. So, argumentative markers indeed provide information to detect paragraphs with arguments.
According to the reported results, the best accuracy was observed in our representation to identify paragraphs with arguments by the SVM classifier using DOR representation with lexical features and categories of argumentative markers. In future work, we plan to explore the use of structural and syntactical features to advance the classification task and we expect to achieve an adequate representation and classifier for argument components and relations in the texts.
The prototype described in this paper aims to include a model for argument detection in academic texts for students, instructors, and researchers. The final goal is to provide a tool capable of analyzing argumentative components (e.g. premises, conclusions) of academic theses sections, to indicate precisely to students where deficiencies, such as a paragraph with a conclusion but with no premises, are detected.