
Abstract
Scholarly search engines, reference management tools, and academic social networks enable modern researchers to organize their scientific libraries. Moreover, they often provide recommendations for scientific publications that might be of interest to researchers. Because of the exponentially increasing volume of publications, effective citation recommendation is of great importance to researchers, as it reduces the time and effort spent on retrieving, understanding, and selecting research papers. In this context, we address the problem of citation recommendation, i.e., the task of recommending citations for a new paper. Current research investigates this task in different settings, including cases where rich user metadata is available (e.g., user profile, publications, citations). This work focus on a setting where the user provides only the abstract of a new paper as input. Our proposed approach is to expand the semantic features of the given abstract using knowledge graphs – and, combine them with other features (e.g., indegree, recency) to fit a learning to rank model. This model is used to generate the citation recommendations. By evaluating on real data, we show that the expanded semantic features lead to improving the quality of the recommendations measured by nDCG@10.
Introduction
Finding relevant bibliography is time-consuming for modern researchers – and it is easy to miss existing related work due to the large volume of scientific literature. Over recent decades, the number of scientific articles has exhibited exponential increase, and this trend is not expected to change soon [1, 2]. Lately, new publication channels such as conference proceedings and open archives have added to the volume of publications and are also growing at a fast pace. This growth is exciting but challenging, as it increases the time that researchers must spend on finding relevant papers to their specific research projects.
To help with this problem, several digital tools such as reference management software, digital libraries, and search engines offer research paper recommendations to their users. Following [3], we highlight two types of research paper recommendations. The first is Global Recommendations, where the task is to find relevant articles related to a given corpus as a whole. The second is Local Recommendations, where the task is to detect local contexts (e.g., sentences, paragraphs in a paper) for which there exist related papers in the literature.
Recommender systems have found application in many different domains, including movies, music, videos, news, books, and products in general. Depending on the context, they produce a list of recommended items using a variety of techniques (e.g., collaborative or content-based filtering [4]). The literature in the field of research paper recommendation is extensive, and content-based recommendations are the most common solution to the global citation recommendation task [5].
In this paper, we research a particular variant of the global recommendations task: we aim to find papers that are relevant to a short description (abstract) of a new paper, provided as input. Addressing this task will be beneficial to researchers who find themselves working on a new paper, with an accurate idea about the problem they wish to solve and their approach, but little knowledge of related work in the literature. For such cases, which are very common among professional researchers, we envision recommender systems that allow the researchers to put together a short text (an abstract) that describes the problem and approach they consider, submit it to the system, and receive a set of related papers.
An essential contribution of our proposed approach is to add semantic features by mapping the given abstract to knowledge graphs. Knowledge graphs represent structured and detailed knowledge about a topic via labeled-nodes and labeled-edges, usually following the Resource Description Framework (RDF)1. One of the most extensive knowledge graphs is DBpedia [6]. It contains topics and facts from Wikipedia, ‘the largest and most popular general reference work on the Internet’2. We map the terms in the abstract to DBpedia using DBpedia Spotlight [7]. In doing so, we generate two types of semantic features: Set of Entities, which contains DBpedia entities, and Set of Properties, which contains the set of properties for the mapped entities.
Our approach for producing recommendations for a given abstract has two phases: training and recommendation. The goal of the training phase is to fit a ‘learning to rank’ model on a ground-truth dataset compiled from CiteSeerX and the Microsoft Academic Graph, where we have the paper’s abstract and its citation. The recommendation phase takes the abstract of a new paper as input and builds recommendations based on the previously fit model. For both training and recommending, we generate a candidate set for the given abstract using Lucene’s More Like This3 on the relevant terms and semantic features of the abstract. We evaluate our recommendations by holding a testing dataset from the ground-truth data. For each of the abstracts in the testing set, we build a Top-10 recommendation and compute nDCG@10 to measure that relevant (cited) papers appear higher in the rank.
Expanding the semantic features with knowledge graphs, using Lucene for candidate generation, and learning to rank on abstract-candidate features, distinguish our work from existing approaches.
The rest of the paper is organized as follows. Section 2 presents a summary of the related research work in the global citation recommendation task. Section 3 presents the working dataset, data cleaning, and exploration, our setting for building Top K Recommendations. Section 4 explains the evaluation methodology, data split, metrics, and baselines. Section 5 presents the experimental results, followed by discussions, and conclusions in Section 6.
Related work
The literature on research-paper recommender systems is extensive Ref. [5] presents a recent survey on the field. The authors summarize different approaches in the literature and open problems for this task. Close to our work are the content-based filtering methods. 70% of the surveyed methods used tf-idf [8] as weighting scheme for terms. Other approaches consider different aspects of the paper’s content. For instance, authors in [3] define context vectors (e.g., weighted terms in the abstract) and score candidate papers by computing the average dot product of these context vectors. In a follow-up work [9], the authors use Cite-PLSA-LDA [10]. This approach builds an LDA model from the CiteSeerX [11] word-topic and topic-citation distributions. Another content-based recommender is using keyqueries to represent the body of the paper corpus. These keyqueries are then used to get similar papers [12].
Enriching the content of the paper is done in [13] with a hybrid recommender system called Quickstep. The authors combine collaborative filtering with content. As a first step, they classify the topic of the paper using multi-class classifiers. Then, a profiling algorithm computes the user interests to the topic from the predicted paper topics and the user’s browsing logs. The final recommendation is the product of the topic classification confidence and the user topic interest. The authors extend the topics with the taxonomy of computer science in the dmoz ontology4. Combining semantic databases to enrich the user interface is proposed in [14], where the authors design a system that tags an input corpus based on a semantic database defined by the user. These tags are then used to build a user interface that allows exploring related papers based on how similar their text is. In the Docear research paper recommender system [15], mind maps are used to enable users to navigate research recommendations based on content-based filtering methods.
Graph based research paper recommender systems build a graph and then compute research paper rankings to find the most central or popular papers either using a citation graph [16–18] or using the author’s graph [19–21]. The authors in [3, 22] present evidence that Katz is a good centrality measure for finding the global relevance of scientific papers. However, [23] mentions that using the citations count (i.e., indegree) is good enough.
Current research on using knowledge graphs to expand the semantic features of the research papers is scarce. Authors in [24] research the extraction of semantic entities from the text using Wikifier [25, 26]. Their results show that Wikifier annotates general terms rather than domain specific terms and they did not research the recommendation task. The usage of knowledge graphs for building Top K recommendations is presented in SPrank [27]. SPrank builds features that represent the connection between users and items using paths between the items and the knowledge graph. Their results show that SPrank outperforms popularity and biased Matrix Factorization [28] baselines while SLIM [29] reached similar performance. Authors in [30] propose a model that computes pairwise features between users and papers, and then train a learning to rank model. This model learns the user preference over the candidate papers. Their experiments show that learning to rank models help in the paper recommendation task when user profiles and explicit feedback (i.e., users mark papers as relevant) is known.
Our work is complementary to the previously mentioned literature in several aspects. Our recommender system aims to satisfy the information needs expressed in a given abstract only. That is, we do not require building a profile for the user for recommending papers. This strict requirement forces us to leverage new methods for expanding the semantic features of the given abstract. We research the added value of knowledge graphs used as content to build global citation recommendations and propose an approach that uses this new set of features. In particular, we complement current literature as follows. First, by using DBpedia Spotlight, we map the terms in the text to DBpedia, a knowledge graph. This process identifies DBpedia entities URIs, and from DBpedia, we extract the entities properties. Second, to reduce the complexity of training and recommending we propose generating a candidate set using Lucene’s More Like This method. This method uses the terms in the abstract and the DBpedia entities to query for relevant papers. By doing this, we show that the quality of the candidate set improves. Third, our proposed approach builds abstract-candidate pairwise features from a ground-truth dataset and mark the pairs with candidates cited as relevant. We input these pairwise features to LambdaMART [31], a learning to rank model that uses the pair-wise features to predict the labeled relevance.
To measure the quality of our proposed approach, we apply our proposed solution year-by-year evaluating on the next year. For each paper published in the year following the training, we take the abstract and calculate the candidate set, compute the abstract-candidate pairwise features, and apply the fit LambdaMART model to rank the pairs according to the predicted relevance. Then, we measure the quality of the ranking (i.e., if the candidates are on the top) by computing nDCG@10. Our results show that the proposed approach outperforms traditional text-based baselines and semantic features improve recommendation quality. The code used for data collection, analysis, and experimentation is available for academic purposes5.
Setting
To show how we build the research-paper recommendations we start by presenting the working dataset, the data cleaning steps and an exploration on the data characteristics. Then, we present our approach for generating a candidate set and discuss how we build the training dataset for the learning-to-rank task. Finally, we provide our definitions and notations, and we present the prediction task. Figure 1 presents an overview of our approach for building Top K recommendations.
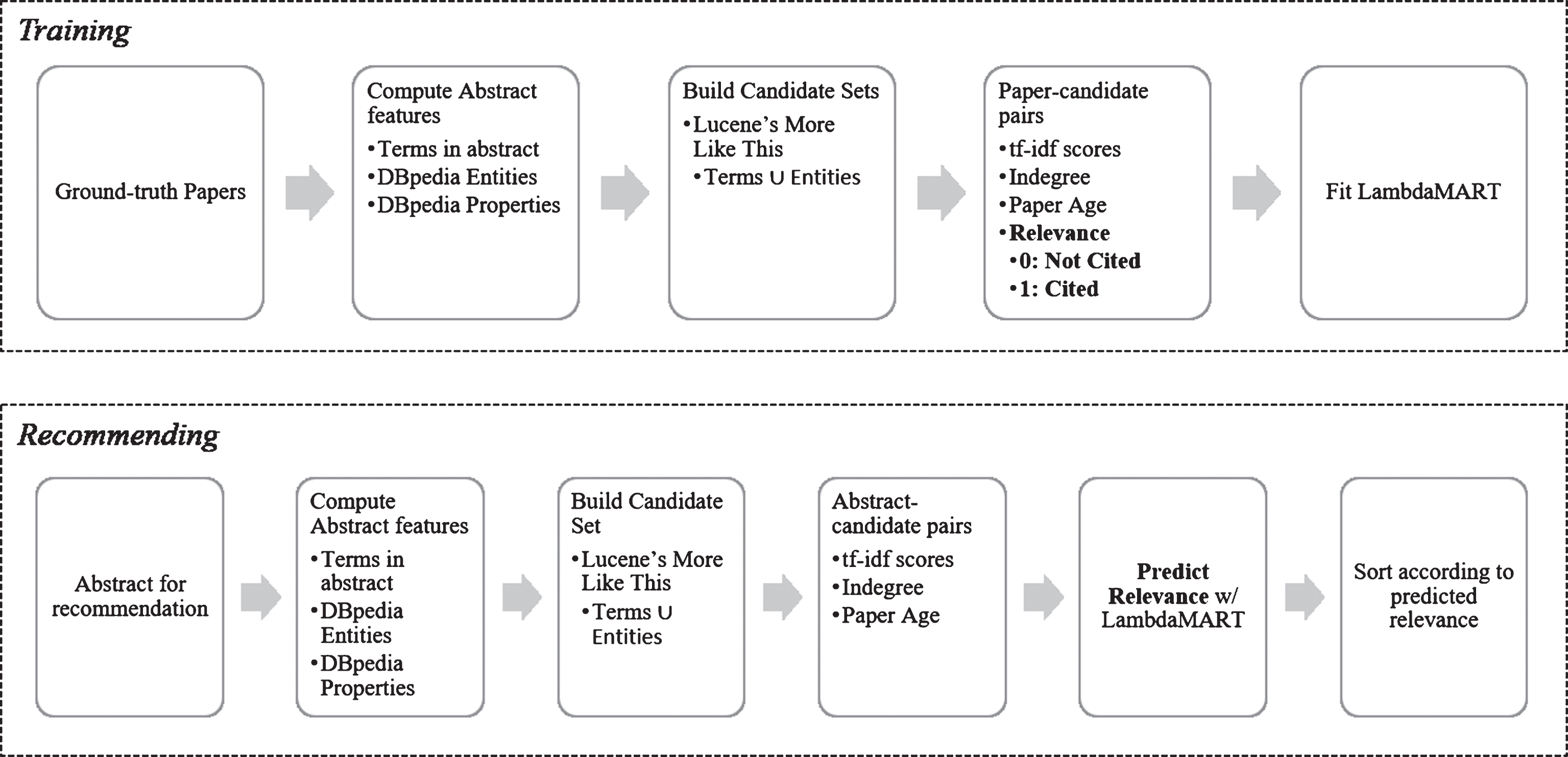
An overview of our proposed approach for building global citation recommendations. The input of the training phase (top), is the ground-truth dataset, and the output is a LambdaMART model fit to predict the candidate’s relevance for the paper. For building recommendations (bottom), we require an abstract that is used to compute content features, build a candidate set, calculate the paper-candidate features, and finally, the trained LambdaMART model is used to predict the relevance of the candidates for the abstract. The recommendations are the set of candidate papers sorted by the predicted relevance.
We compile a working dataset (i.e., ground-truth dataset) of papers, on which we train a model to predict citations6 and generate recommendations. We proceed in two steps. In the first step, we combine data from two large, publicly available datasets. The first is CiteSeerX [11], an open-access repository of about 10 million papers. From this dataset, we use the title and abstract – however, the reference lists (citations) are not included7. The second dataset is the Microsoft Academic Graph (MAG) [32], a publicly available set of 127 million scientific papers, related metadata, and the list of its references (i.e., cited papers). To merge the CiteSeerX and MAG datasets, we match the papers by the edit distance of their lower-case title8. This merge leads to a collection of approximately 2.2 million research papers, 6.7 million authors, and 24 million citations. However, we consider only citations to papers in our dataset. These are 4.7 million citations. Finally, we clean this data as described in Subsection 3.2.
In the second step, we extract semantic features for each paper in the collection. Towards this end, we use DBpedia [6], a large knowledge graph that represents information contained in Wikipedia. Specifically, DBpedia contains facts about entities, expressed as RDF triplets of the form (subject, predicate, object) – for example, (Brooklyn, is_in_city, New York City). For each of the papers output from the first step above, we identify the set of RDF subjects that are mentioned within its title and abstract – and refer to them as the paper’s

An example of two papers and their relation via the http://purl.org/dc/terms/subject predicate. Large text (orange) is the paper title. The small text (blue) are the entities (i.e., E i ). Smaller text (black) are the entities properties (i.e., P i ). In this example, new knowledge is discovered by the link between Dominating_Set and Path_(graph_theory).
In total, we extracted approximately 270 thousand distinct entities, which account for 25 million annotations, and 1.7 million distinct properties.
To summarize, each paper in the resulting working dataset is associated with the following features: title, abstract, set of citations, set of entities, and set of properties.
In Tables 1 and 2 we present descriptive statistics of the working dataset. We include a cleaning phase to remove outliers (e.g., papers with more than 2.9 K authors, 9.6 K citations). The cleaning is done in three steps.
Description of the uncleaned working dataset regarding the total number of entities, citations, and authors in the papers
Description of the uncleaned working dataset regarding the total number of entities, citations, and authors in the papers
Statistics for the Entities and Authors frequency in the uncleaned dataset
First, since the dataset contains papers from year 1800, we compute the quartiles of the total of papers per year and filter in the 75% percentile (i.e.years with at least 1000 papers). The first year that satisfies this condition is 1973. Figure 3 presents a histogram of papers per year. Second, we remove papers with more than 20 authors and 100 citations. Third, we consider entities with a frequency above the median (i.e., entities that appear at least four times). After cleaning, the total number of papers is 385 K. Table 3 presents statistics of the clean dataset. Tables 4 and 5 present the top 10 authors, entities, and properties. Figure 4 shows popular co-occurrences for the top 10 entities of Table 4 (i.e., entities mentioned in the same abstract).

Histogram of papers per year.
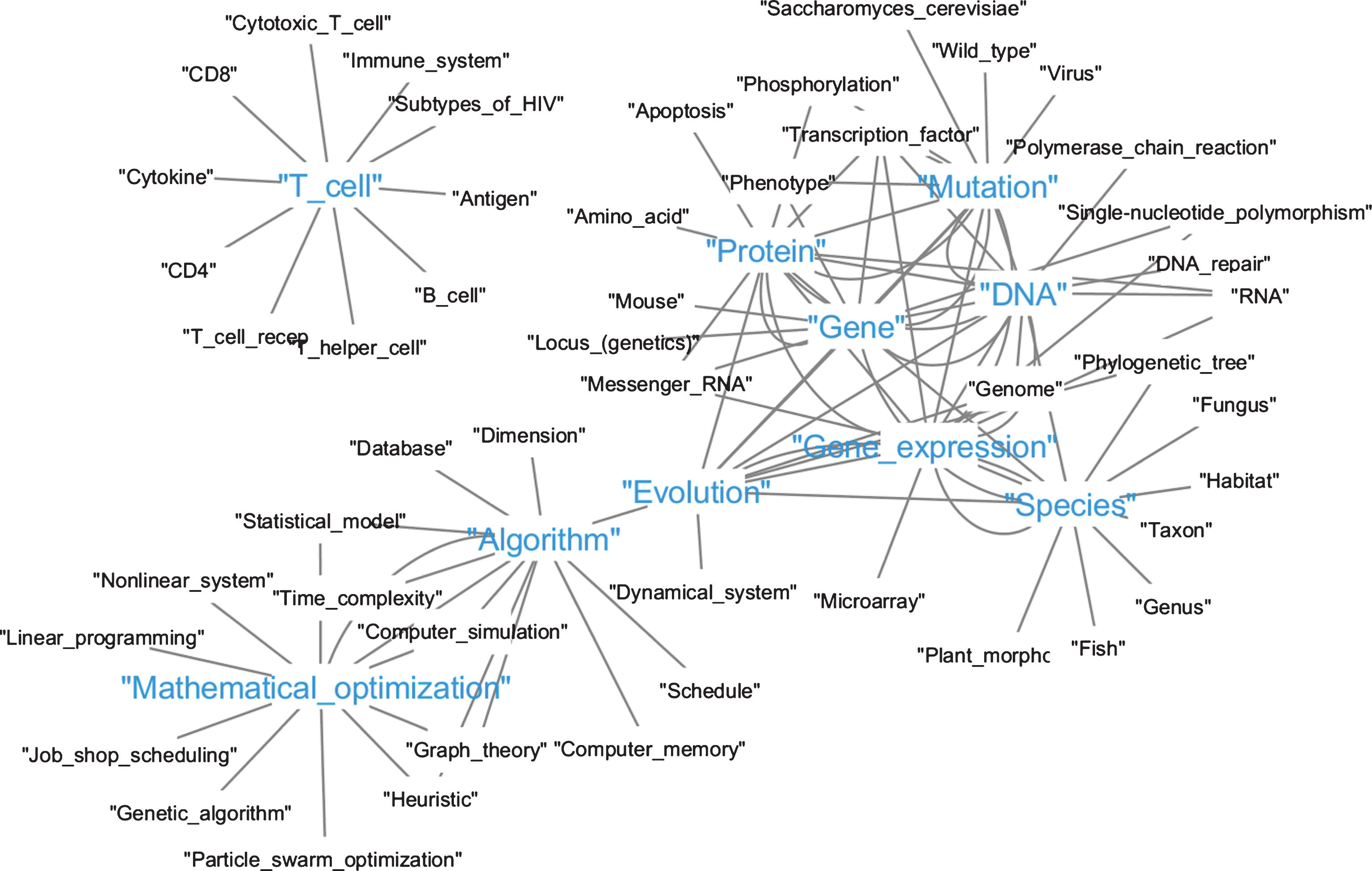
Larger text (blue) are the top 10 entities. Smaller text (black) are entities co-occurrences (i.e., papers mentioning both entities). For simplicity, we show just 10 co-occurrences for each of the top entities.
Statistics of the cleaned dataset. The abstract length is in characters
Most of the authors and entities are related to the fields of computer science, mathematics, and bio-informatics. Note that in this table the authors and entities are not related per row
DBpedia also links to other knowledge graphs like YAGO and other resources (e.g., purl – permanent URLs)
When researchers are creating a new paper, they can potentially cite any paper previously published. Theoretically, then, citation recommendations for a new paper should consider all past papers. To speed-up training, as well as the generation of recommendations, it is important to reduce the set of candidate papers to a relatively limited set of papers that include comparable proportions of true positives (i.e., cited papers) and true negatives (papers not cited).
We achieve this by considering papers similar to the one for which recommendations are produced. Specifically, we use Lucene to retrieve the K papers with abstracts that contain similar terms and entities according to standard tf-idf weighting scheme. We experiment with various values for K, and tune it to a moderate value that offers good recall levels. An alternative approach would include as candidates the cited papers of the K similar papers (as in [3]). However, we found empirically that this approach leads to large candidate sets, which render it impractical.
Training set
Training is set to build a model that answers the question: “given a list of pairs of papers i and candidates c i , is c i more likely to be cited by i than other candidates?”. Textual and semantic features from abstracts, their candidate sets, and their citations are used to create a training set (Fig. 5). Specifically, each entry of the training set corresponds to a pair i, c i of a paper i and its candidate citation c i . The pairs are associated to item i so the model can learn the relevance of c i in the list of candidates for i. The predicted variable is binary and encodes whether paper i cites paper c i . The predictor variables capture the similarity of i and c i regarding their textual and semantic features, as explained below.
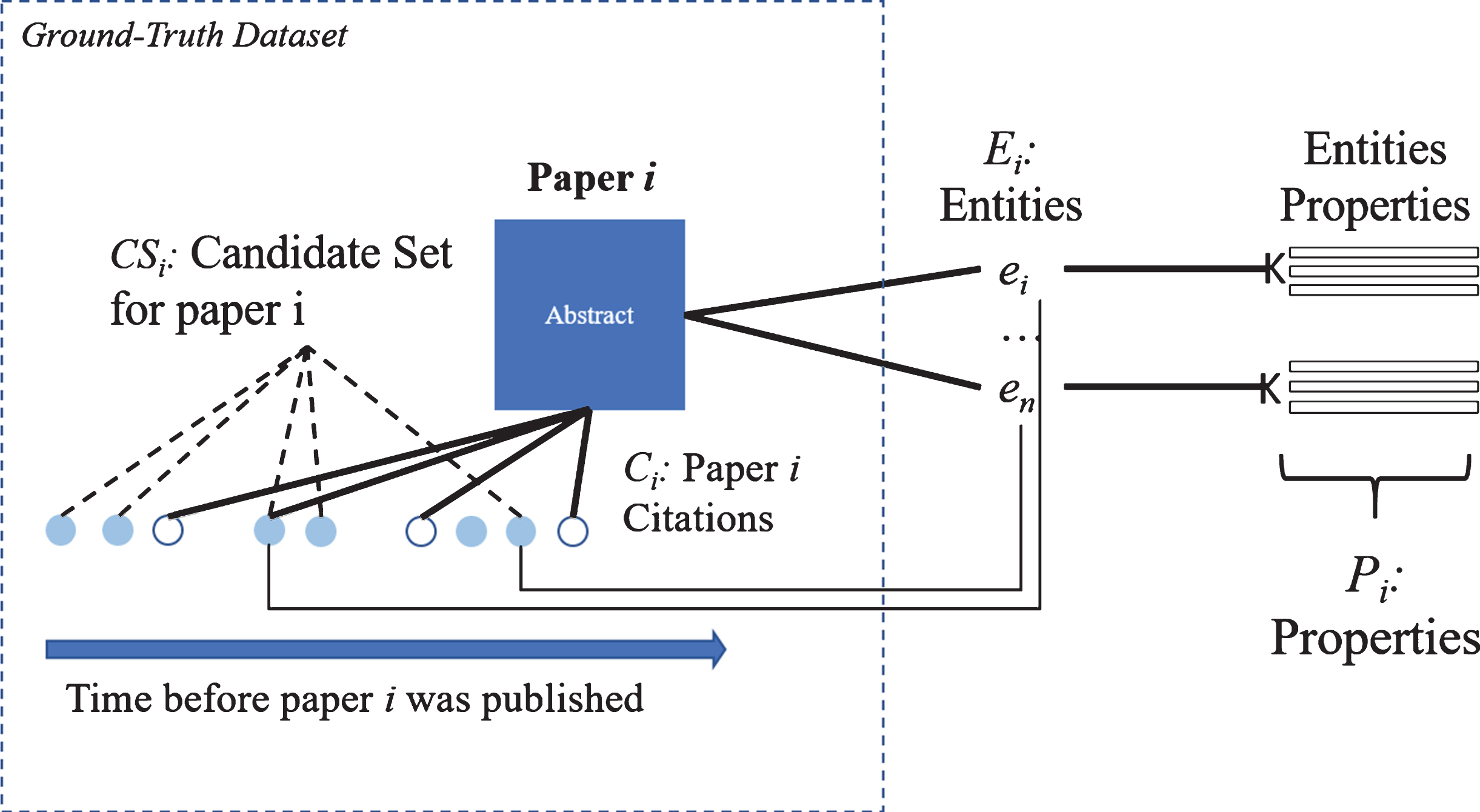
Expanding the papers abstract with knowledge graphs creates a relation between the paper i and entities from DBpedia. These entities relate paper i to papers that share common entities. In our approach, we use these entities together with the abstract terms to generate a candidate paper CS that are likely to be cited by i. In a second step, we rank these candidate papers to build the Top-K recommendations.
We build pairs between the papers I and the candidates c i ∈ CS. We build the same features for the given abstract to predict.
MLT Score. The score returned by Lucene based on the similarity of the most relevant terms and entities.
Entities tf-idf. The sum of common entities in the candidate weighted by tf-idf using Equation 2.
Properties tf-idf. The sum of common entity properties in the candidate weighted by tf-idf using Equation 2.
Abstract tf-idf. The sum of common terms in the candidate weighted by tf-idf using Equation 2.
Combined tf-id. The sum of the entities tf-idf, properties tf-idf, and abstract tf-idf.
Highest tf-idf. Categorical feature with the label of the highest tf-idf score (i.e., entities tf-idf, properties tf-idf, and abstract tf-idf).
Lowest idf-idf. Categorical feature with the label of the lowest tf-idf score (i.e., entities tf-idf, properties tf-idf, and abstract tf-idf).
Candidate Age. The years that have passed since the candidate paper was published. For example, if we are training in a paper from 2015 and the candidate is from 2005, the candidate’s age is 10 years.
Indegree. The total number of papers citing the candidate as of the year of training or recommendation.
Indegree w/Decay. The indegree with a decay according to the candidate age
Equation 1 defines the relevance of c i for paper i.
Learning to rank
Gradient boosting [34], boosted trees [35] and especially some variants of gradient boosted trees [36] are widely used methods for both classification and regression. LambdaMART is a gradient boosted tree based list-wise learning-to-rank algorithm which is a special version of RankNet. The model uses boosted trees optimized for nDCG instead of pairwise errors [31]. Since the occurring term and entity feature space is high dimensional and highly sparse the model needs high number of “weak” learners (shallow trees).
Prediction task
Given these notations and data, the problem of global citation recommendation is defined as follows. Let X be the training set of all triplets in our ground-truth dataset defined as
The goal is to learn a scoring function f that approximates the relevance
Dataset split
We use two approaches for measuring the quality of the global citations recommendations produced by our approach. The first is random split per year. The motivation for this is to train a model using the papers published in a year, hold part of the papers as testing data and then evaluate the recommendations on papers written in the same year. For this purpose, we split the data into three parts. 80% of the papers are used as training set, 20% as testing set, and from the testing set, we take 10% as a validation set. The second approach is evaluating on the next year. The motivation for this is that we want to know how good is the approach for recommending on the next year. Table 6 presents the numbers of papers per year, number of papers, and pairs used for training, testing, and validating. For the evaluating on the next year, we take all of its pairs to build and evaluate the recommendations.
For building the pairs, we consider papers with at least 3 citations. Then, we split the total number of papers in three datasets: training, testing and validation. For each of these papers we build pairs of abstract-candidate and compute their features
For building the pairs, we consider papers with at least 3 citations. Then, we split the total number of papers in three datasets: training, testing and validation. For each of these papers we build pairs of abstract-candidate and compute their features
As performance metric we use nDCG@10 defined as
Baselines
Weighted tf-idf score
For this baseline, we compute the weighted tf-idf of the terms in the candidate’s abstract. Then, we sum the tf-idf of the common terms between the candidate and the given abstract. The weighted tf-idf [37] is defined as
This baseline is the proposed approach for candidate sampling. That is, we rank the candidates according to the Lucene’s More Like This score on terms in the abstract and entities.
Experimental results
Experimental setting
We used Microsoft’s LightGBM9 implementation of LambdaMART. In the validation set, we fine-tune the parameters using Bayesian Optimization [38]. We found the following parameters to perform consistently well: 1000 trees, 30 leaves, and high minimum number of objects in a leaf (100). For Lucene’s More Like we used grid search to fine-tune its parameters. We used ElasticSearch 9 as an interface to Lucene. The code for generating the candidate sets, pairwise features, model training, and predictions was executed on a single machine with 224GB of RAM, 48 cores, and run for a day.
Table 7 presents the different variants of the baselines and LambdaMART used in our experiments.
The LambdaMART models follow our proposed approach. For the ATF and MLT baselines we sort the papers in the candidate set according to this metric without using LambdaMART
The LambdaMART models follow our proposed approach. For the ATF and MLT baselines we sort the papers in the candidate set according to this metric without using LambdaMART
Table 8 presents the coverage of the proposed candidate set sampling method at different set sizes.
Features used for building the candidate sets
Features used for building the candidate sets
Table 9 presents the results for the evaluation on random split per year. And, Table 10 the results for evaluation on the next year.
nDCG@10 for the models evaluated on the year random split. The numbers in parenthesis indicate the gain of the LM-all in comparison to the baseline
The feature importance for the models is presented in Fig. 6.
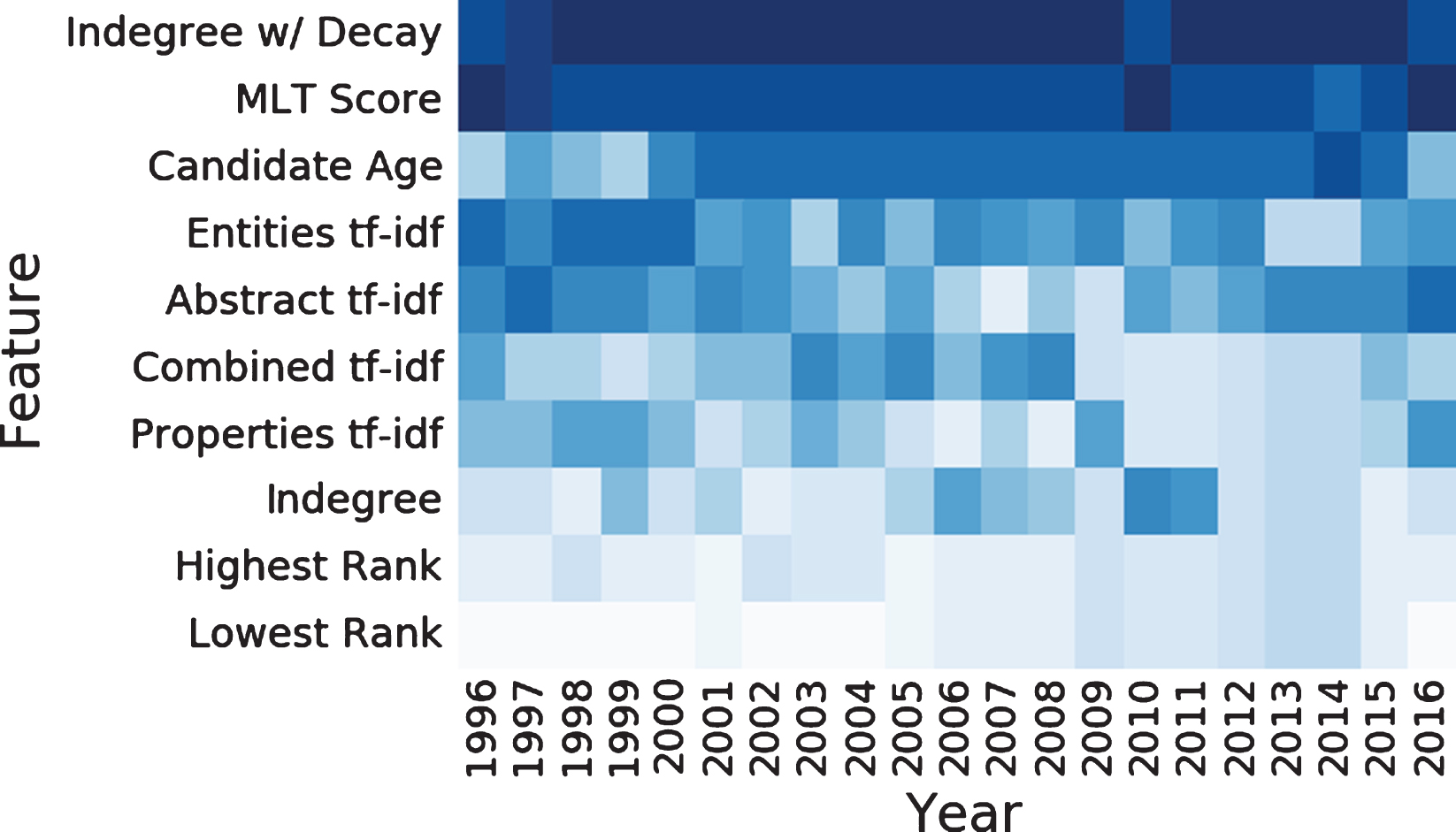
The feature importance per year. The features are sorted by the times they appear in the LambdaMART model. The features are sorted from top to bottom, and stronger color means a greater contribution to the model.
The following findings summarize the main outcomes of our research work based on the presented experimental results.
nDCG@10 for the models evaluated on the following year of the training. The numbers in parenthesis indicate the gain of the LM-all in comparison to the baseline
nDCG@10 for the models evaluated on the following year of the training. The numbers in parenthesis indicate the gain of the LM-all in comparison to the baseline
When modern researchers are searching for the literature of a new paper, they could save time by receiving a list of recommended papers.
Our research work presents empirical findings on using knowledge graphs to build global citation recommendations. To the best of our knowledge, this is the first study that involves semantic features of knowledge graphs in building the candidate set and training the ranking model for this task. Our experiments show that these semantic features contribute significantly and help outperform text-based baseline.
Given the importance of semantic features, an obvious direction of future work is to incorporate them in recommender systems tailored to different settings (e.g., for local recommendations). Moreover, as seen in the Section 3.2, most of the papers are related to areas of computer science, mathematics, and natural sciences. Therefore, another direction of future work would be to build ‘vertical’ recommender systems, that are fit to the semantics of different fields (e.g., dblp, PubMed). Finally, trying different weighting methods (e.g., Okapi BM25) could help diminish the effect of incorrectly annotated entities.
Footnotes
6In what follows, citations are the entries in the Bibliography of a paper. That is, those papers used as supporting literature. We use the word citation and reference equally.
The data was collected from CiteSeerx OAI collection endpoint, which does not provide the citations.
Acknowledgments
Frederick Ayala-Gómez was supported by the Mexican National Council for Science and Technology (Consejo Nacional de Ciencia y Tecnología–CONACYT), and by the European Institute of Innovation and Technology (EIT) Digital Doctoral School. This publication was also supported from the EU H2020 research and innovation program under grant agreement Streamline No 688191 and the “Big Data—Momentum” grant of the Hungarian Academy of Sciences. Aristides Gionis is supported by the Academy of Finland project “Nestor” (286211) and the EC H2020 RIA project “SoBigData” (654024).