
Abstract
Counting the number of words and lines that a user reads is important for many educational purposes – e.g., the reading speed is a key factor to improve learning, intelligent systems can suggest text that must be read to achieve a determined learning objective. The eye tracking technology is commonly used to analyze the user reading habits. Counting the number of read words could be hard when the readings are obtained from imprecise eye tracking data – e.g., eye tracking calibration difficulties. Approaches that find patterns from saccades and fixations usually fail to solve the problem in such conditions. This paper introduces the
Introduction
The significant progress made in designing a robust, low-cost, mobile eye-tracking system allows analyzing what the user is seeing. Two common techniques for eyetracking are electrooculography (EOG) and optical tracking. The technical principle of EOG is based on the fact that the eye acts as an electrical dipole between the cornea (positive) and retina (negative). This approach is cheap to implement and requires little processing compared to optical tracking; however, it only gives relative eyemovements.
Alternatively, some commercial systems – e.g., Eye tribe or Tobii – estimate the gaze point by reflecting infrared light into the user’s eyes. The precision and accuracy of these systems are not always satisfactory; for example, Ooms et al. [12] reported that measurements obtained by the “Eye Tribe” optical tracking system have an offset of 34px (25px standard deviation) for non-border measurements, but high deviations – offset and standard deviation – at the edge of the screen. Some factors – e.g., lighting, set-up and calibration – can render the recordings useless.
The main contribution of this paper is a method to estimate the number of lines and words effectively read by the user. The idea relies on two observations: (i) fixations are usually not located on words due to sensor inaccuracies (Fig. 1a), and (ii) to read a text, user’s gazes must fall on the same text line several times (Fig. 1e). The outline of the proposed approach is shown in Fig. 1. First, fixations and character centroids are obtained from the eye tracking data and image, respectively. In order to better determine the number of read words, the proposed approach associates a cluster of the closest characters to each fixation (Fig. 1c). These small point clusters are analyzed to find lines (Fig. 1d). Finally, noisy fixations are corrected by a Bayes factor test for merging lines (Fig. 1e).
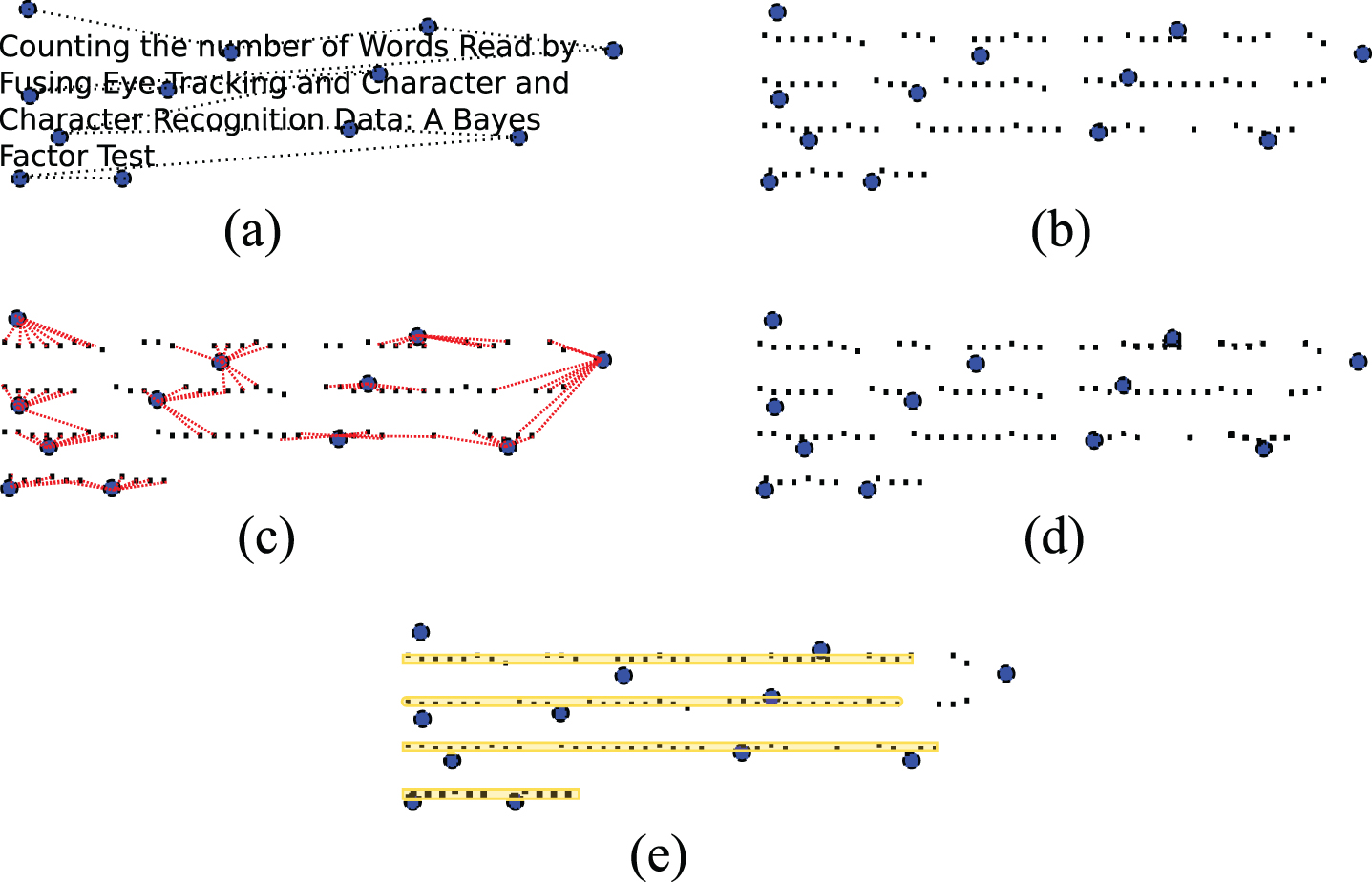
As shown in the experimental results section, the precision-recall rates are high for the proposed algorithm, even from corrupted eye-tracking data. Furthermore, it can recognize reading for any text direction; i.e., it is not restricted to recognize reading of a left-to-right text.
The rest of the paper is organized as follows: Section 2 reviews the related work, Section 3 reviews the Bayes Factor used to choose the right model between two competitive models (of one and two lines, respectively), Section 4 explains the proposed algorithm, Section 5 describes the empirical study; Section 6 discusses its findings; finally, Section 7 presents the conclusions of this work.
While reading, the eye follows a distinctive pattern – e.g. moving from left to right for English –, many approaches seek to identify such pattern for detecting the reading activity. For example, Huda et al. [6] propose to use the derivative of the Horizontal EOG (h–EOG) signal. Points that correspond to reading activity are found by applying an empirical threshold between peaks. In their approach, the number of selected points corresponds to the number of lines read, and the separation between them resembles the time taken to read the corresponding line.
For recognizing reading activity in daily life scenarios, Bulling et al. [4] use a head-mounted accelerometer to detect “head down” periods. They report an average precision of 87.7% with a recall of 87.9% for a pattern recognition approach based on strings – saccades are translated into strings of the alphabet Σ ={‘L’: long left, ‘l’: left, ‘R’: long right, and ‘r’: right}. As well, they report a precision of 88.9% with a recall of 72.3% for a Support Vector Machine (SVM) classifier that analyzes saccades, fixations, and blinks.
For reading detection, Kunze et al. [9] uses an SVM classifier with a radial basis function on a vector of features from the eye tracking data within a frame sliding window. The vector includes features from fixations (the number, sum of duration and average time), saccades (average and minimum length, horizontal, and vertical components), and average amplitude of wavelets. Unfortunately, some of these features are user-dependent – e.g., fast readers produce fewer fixations, fixations of shorter duration, larger saccades, and fewer regressions [8].
Yamaya et al. [15] consider the problem of fixation-to-text alignment and solve it by a two–step approach: (a) the gaze data is analyzed to find a set of sequential reading segments, these segments are found by a threshold test of the horizontal backward distance, (b) the second step searches for a minimum cost alignment between the reading segments and text lines using dynamic programming. The cost of the alignment uses a similarity based on the segment length. The main drawbacks of this approach are: gaze segmentation fails in some cases (e.g., for small text lines, or regressions in reading), and it only detects reading for horizontal text.
Biedert et al. [2] propose a linear classifier that uses the relation between consecutive saccades – v.g., angles and lengths – to discern between reading and skimming. Such classification problem is different to the one of counting words. An interesting strategy implemented by Biedert et al. is the normalization of features by using an estimation of the character size.
For detecting lines, Kunze et al. [10] project each saccade vector on the horizontal axis and create a histogram of distances. By considering the histogram as a mixture of two Gaussians (with means μ1 and μ2), they suggest to use (μ1 + μ2)/2 as threshold for line-break detection. For word count, they propose to estimate the number of words per line by using statistics obtained from the whole document. The works of [2, 15] are related to the proposed approach in the sense that they associate eye tracking withwords.
Table 1 summarizes the approaches that quantify the text read by the user. Summing up, to the authors’ knowledge, this paper offers the first effort to detect readings for text in any direction. This is an important advantage because some languages do not follow the left-to-right reading direction, other documents (e.g., diagrams) do not have complete text lines. Even more, the proposed approach can better estimate the text read for different reading strategies (e.g.,skimming).
Comparison of approaches for detection of reading activity
Comparison of approaches for detection of reading activity
† Can detect reading activity in a mobile setting (e.g. while walking) by detecting head-down position.
‡ Estimated as (average word count of the document read) × (estimated number of lines).
For completeness, this section reviews the Bayes factor for merging lines proposed in [11]. The Bayes factor [13, 14], a quantity for comparing models in the Bayesian framework, has played a major role in assessing the goodness of fitting competing models. Here, the Bayes factor is used to detect whether two point clusters follow the same linear model. An example of this problem is shown in Fig. 2, by using the measurement model of points, the Bayes factor can decide that clusters D a and D c follow the same linear model, but D a and D b do not.

Errors from point to lines. Given a set of n independent Gaussian data points D = {z
i
= 〈x
i
, y
i
〉|i = 1, …, n}, the sum of squares of the normalized orthogonal directed distances from points in D to the line ℓ : 〈r, φ〉 is defined as
Bayes Factor Test to Simplify Point Clusters. Suppose there are two point clusters, each of them following a linear model. Let D
a
and D
b
be the two point clusters of size a
n
and b
n
, respectively. The model M0 considers that both data sets were extracted from the same line in
Lara-Alvarez et al. [11] propose that the Bayes Factor between models M0 and M1 is
The proposed approach, named
The following paragraphs provide some implementation details that are specific to the current development:
Proposed Algorithm (cowl )
Proposed Algorithm (
The goal of the experiment is to evaluate the performance of algorithms that count the number of lines and words read by users using a low cost eye tracking device. A qualitative comparison of approaches that estimate the number of lines and words is shown in Table 1. These approaches use different settings and therefore cannot directly be compared to the proposed approach; for instance, use the EOG sensor, and not the optical eye tracking. Some approaches do require specific preconditions; e.g., Kunze et al. [10] can only be used for text of the same font size. Specifically, we are interested in comparing the proposed COWL approach against another approach from those that count lines/words by aligning eye tracking data to text [10, 15]. The approach proposed by Yamaya et al. [15], hereinafter referred as DP, was selected because it also deals with eye tracking errors. To ensure a fair comparison, the position-variance method [1] was used to find fixations, and the parameters of the DP algorithm were configured as suggested in [15].
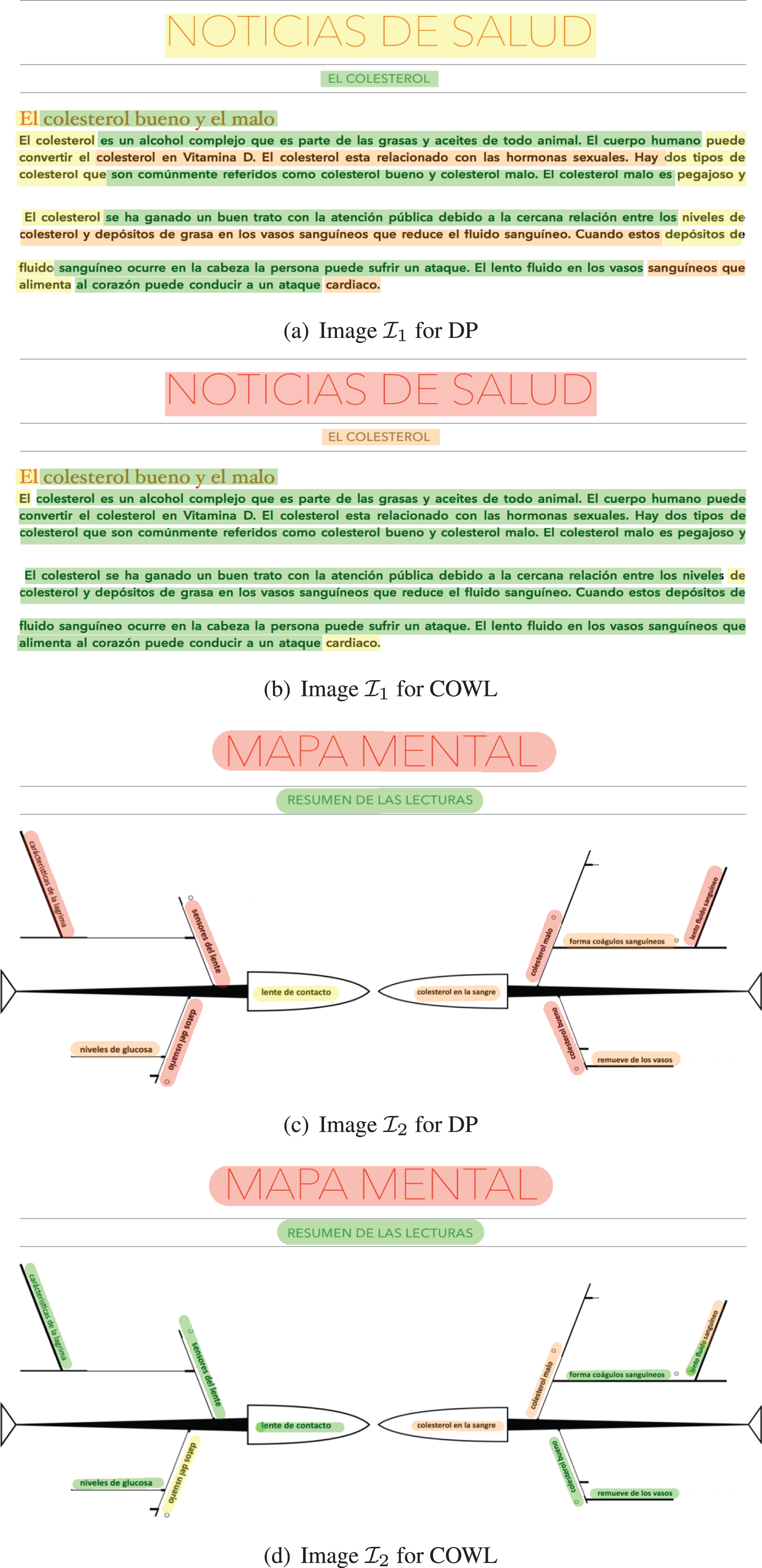
These two images were sequentially presented to the user for reading purposes and the gaze data was obtained from each image. Elements (words and lines) truly read by the user – ground truth dataset – were obtained by an expert that carefully analyzed the gaze data; henceforth, these elements are represented by Θ (gt). Analogously, elements obtained by algorithms (COWL, DP) are represented as Θ (alg).
Study participants were men and women (n = 14) aged 25 to 45 years, all of them native Spanish speakers with bachelor’s degree. At the time the experiment was conducted, only one participant was wearing glasses (two diopters).
For each participant, the eye tracker was calibrated with the OGAMA software tool (using 12 calibration points) and it was set at a distance of about 50 cm from the subject’s head. Participants were instructed to read – according to their usual reading habits – the images. No time limit was imposed for any trial, and the users were asked to change the image (by giving a click) once they read completely the actual reading material.
Results and discussion
Table 2 shows the results for the number of lines and words. The F–scores (
The DP approach has good performance for image
Results for images
and
shown in Table 1 (n = 14). Best values are in bold
Results for images
Skimming is the process of reading only main ideas within a passage to get an overall impression of the content of a reading selection – Biedert et al. [2] suggest a reading classification algorithm. Regression is the process of re-reading text already read. These two habits difficult to obtain a complete reading path in those approaches that use a return sweep detection.
As shown in Table 2, the recall of words for
On the other hand, it is evident from Fig. 3 that text lines with few words – e.g., the titles or some branches of the mind map – are hardly detected by
This paper introduces the
The strength of the