
Abstract
Automatic text summarization systems are nowadays of great help to extract relevant information from large corpora. Many solutions to the task have been proposed from the perspective of the optimization of a single-objective function, aiming at finding the global optimum. This is an unrealistic goal since when multiple objectives are considered a solution that optimizes one of the objectives may induce the opposite effect on the others. Recently other solutions have been proposed that involve multiple, conflicting objectives, but which eventually are aggregated into a scalar function thus resulting in a single-objective optimization problem. Furthermore, oftentimes a typical bag of words model is used and little effort has been made to include semantic relations between sentences to improve performance. In this paper a novel method for query-oriented summarization is proposed as a multiobjective optimization problem taking into account the Pareto front and based on an embedded representation of sentences. The method is evaluated with the TAC 2009 dataset. Experimental results show that the approach contributes to improve performance significantly. To the authors’ knowledge, the method is the first attempt to include embedded representations of sentences in a multiobjective optimization solution, which applies the Pareto approach to query-oriented summarization.
Keywords
Introduction
Context of research
The speed at which online documents are produced on any subject has increased dramatically in the last decade. Tracking and synthesizing multiple relevant documents is an almost impossible task for a human today. Automatic text summarization systems are an alternative to reduce processing and information extraction times. Automatic text summarization (ATS) is considered one of the most complex problems in Natural Language Processing (NLP), due to the large number of tasks and complexity involved in finding optimal solutions under a set of performance metrics.
Work within ATS can be divided into extractive and abstractive methods of summary generation. The former focus on extracting the most relevant sentences based on a set of criteria in order to build summaries with these sentences as they appear in the original text. The latter seek to approximate the way a human writes, so its implementation entails greater algorithmic complexity and the use of several linguistic resources to achieve a higher level of abstraction.
Solutions to the ATS problem can also be classified as Generic and Query-Oriented. A generic approach summarizes on the basis of the main subject or subtopics that the set of documents deals with; i.e. no particular relevance criteria are considered in selecting sentences from the corpus. In contrast, a query-oriented approach summarizes on the basis of a user input that reflects his information need or interests, thus the output summary is personalized making the inclusion of relevance criteria necessary.
Research objectives and contribution
The present work focuses on a solution proposal to the problem of query-oriented multi-document extractive summarization. The main strategy for extractive summarization consists firstly in obtaining the most relevant sentences by scoring and ranking them according to a number of features. Then the first N sentences are selected to build the summary. However, this strategy does not guarantee that collectively these sentences form the best summary. As a whole, they should comply, with at least the following properties [26]: Coverage: Summaries must contain textual units covering as much relevant information as possible. This property typically applies to generic summaries. Relevance: Summaries must contain units of text (sentences) that are relevant to the user. This property makes sense in the presence of query-oriented summaries. Non-redundancy: Summaries should not contain multiple textual units that convey similar information. Summaries are limited in length.
Clearly, these properties may help in formulating criteria or design objectives of an optimization problem that must be solved with multiple objectives. Finding a solution to this problem amounts to choose the best combination of sentences that meets the aforementioned (possibly conflicting) properties.
Many of the current multiobjective optimization approaches for solving the summarization task are based on the use of evolutionary algorithms [1, 18] like genetic algorithms [28], being the implemented algorithm the most important variation. Nevertheless, most of the proposals are formulated as the problem of finding the best solution, which could be the minimum or maximum value of a single objective function that join all objectives into one. This perspective is useful in that one can eventually obtain a solution to the problem, the global optimum. However this is an unrealistic goal in the scenario described above as the problem is oversimplified. In a real multiobjective optimization problem with conflicting objectives there is no single optimal solution. The interaction between different objectives gives rise to a set of compromised solutions, largely known as the trade-off, nondominated or Pareto-optimal solutions. Complexity increases because when multiple objectives are considered (a Pareto-optimal front) a solution that optimizes one of the objectives may induce the opposite effect on the others. Hence, single-objective methods cannot provide a set of alternative solutions that trade different objectives against each other. Recently other solutions have been proposed that involve multiple, conflicting objectives, but which eventually are aggregated into a scalar function thus resulting in a single-objective optimization problem. This approach will be herein referred to as the linearized multiobjective method.
Another fundamental aspect of the automatic summarization task is the way in which sentences are represented in order to facilitate their processing, but mainly in an attempt to capture syntactic and semantic relations. In these respects, many approaches have been proposed, from graph representations [11] to Latent Semantic Analysis (LSA) representations used in Fuzzy systems [3]. The majority of the works proposed for automatic summarization addressed as a multiobjective optimization problem lack a representation that incorporates semantic elements, since they adopt a vector representation where only the frequency of occurrence of each word is taken into account in the sentence.
In a query-oriented summarization task, one of the principal objectives to optimize would be the relevance to the query, in order to obtain the summary that best responds to the user’s information needs. Previous work has been chiefly dedicated to the production of generic summaries, so they focus on coverage, redundancy and length properties only. The references [14] and [28] include the relevance to the query, but as a part of a single-objective function. The definition of a correct function for relevance to the query should guarantee a summary closer to the user’s needs.
In this context, the contribution of this work is twofold. On the one hand, it is proposed to address the automatic summarization task as a multiobjective optimization (MOO) problem, which consists in finding a set of optimal trade-offs, the so called Pareto optimal set [29]. In this paper the feasibility of this kind of approach is investigated by comparing its performance against a state-of-the-art linearized method. On the other hand, the use of a sentence representation model that exploits semantic relationships between them is proposed, as this could help to improve relevance, coverage and non-redundancy performance. In particular, vector representations of both sentences and words have been widely used in NLP tasks in general. More recently, embedded representations have gained momentum as it has been shown they capture linguistic and semantic regularities in an effective and efficient way [20]. Although multiobjective optimization has been applied over the last decade to a number of problems in data mining [12], to the best of the authors’ knowledge there is no study in the area of query-focused automatic summarization comparing the results obtained with a single-objective optimization approach against a multiobjective optimization method (in the Pareto sense), which in addition uses word embeddings to represent sentences.
The remainder of the paper is structured as follows. Section 2 discusses current approaches to the problem of automatic summarization. Section 3 introduces the multiobjective evolutionary algorithm, the sentence representation method used and the fitness functions for the optimization problem. Section 4 presents and discusses the experimental results. Finally, some conclusions are derived in Section 5.
Related work
The idea to approach text summarization as an optimization problem is not new. Early proposals focused on the optimization of a single objective, suggesting different methods for its resolution. As an example reference [6] proposed an approximate greedy procedure that incrementally includes sentences that maximize the Maximal Marginal Relevance function, which aims to minimize redundancy and to include the sentences more related to the query. McDonald [19] studied several global inference algorithms for multi-document summarization: an approximate greedy method, a dynamic programming approach, and an algorithm that uses Integer Linear Programming. Gillick et al. [13] worked with the assumption that the input documents have a set of concepts, each one having a value, so a collection of concepts will have a total value equal to the sum of the values of the contained concepts. A method is proposed to find the collection of concepts with the maximum value subject to a length restriction. The solution to the problem is framed under a global optimization Integer Linear Programming algorithm based on the knapsack problem.
In the last decade, proposals have arisen addressing the summarization task as a multiobjective optimization problem, but rather with a linearized approach. Huang et al. [14] proposed to optimize 4 functions: information coverage, significance, redundancy and coherence. These functions are defined on the basis of a selection of main terms and their grouping into clusters. The main terms are chosen from the calculation of co-occurrence statistics with respect to the terms of the query. They test with the linearized approach and with the lexicographic algorithm, however they do not take the Pareto approach into account.
Zhao and Tang [28] proposed the resolution of the problem of multiobjective optimization by means of a genetic algorithm. They defined a single fitness function as the weighted average of three factors: query-focused feature, importance feature, and non-redundancy feature. The weighting values in the function must be defined by the user in a range between 0 and 1.
More recent works have focused on the use of different evolutionary algorithms. A telling example is Alguliev et al. [1] who proposed a differential evolutionary algorithm adapted to optimize one single function that is formulated as the coverage divided by diversity. For the definition of these two properties (coverage and diversity) they started from a vector representation of sentences, whose features are all words in the vocabulary and where each feature value represents the weight of the word of the vocabulary calculated by the tf × isf coefficient. The same authors proposed in [2] testing with different measures to establish similarity between sentences by combining symmetric measures like the cosine distance and the Jaccard coefficient as well as asymmetric measures like overlap. They proved that the similarity measure used influences the final results.
Saleh and Kadhim [24] proposed a MOO based model for modeling the multi-document text summarization problem. They used a Multi-Objective Evolutionary Algorithm with Decomposition (MOEA/D) to optimize coverage and redundancy objectives. According to our literature review, this is the first investigation that addresses the task as a real multiobjective problem. They proved the effectiveness of the proposed model based on MOO over other state-of-the-art models. However they applied the model only for generic summaries.
More recently, a combination method was proposed by Mashreghi et al. [18]. They combine text mining and optimization algorithm to reduce redundancy and obtain the most relevant sentence for multi-document summarization. The authors evaluate the sentences based on quantitative criteria (length of sentences, position of sentences and total weight of words) and similarity criteria (sentences cosine similarity with title, sentences overlapping criteria). This evaluation is used for the selection of the best sentences using a Particle Swarm Optimization Algorithm.
Thus, in the present work, a model to address the task of Query-Oriented Summarization is proposed as a Multi-Objective Optmization problem from the Pareto approach including a semantic representation of sentences based on Word Embeddings (QOS-MOO-WE).
Methods
Proposed model
Figure 1 shows the model proposed, in which the process starts with a set of documents about a certain topic to be summarized (Collection). Next, in the Preprocessing stage the segmentation of sentences, tokenization, and stopwords removal are performed. The remaining stages are explained in the following Sections.
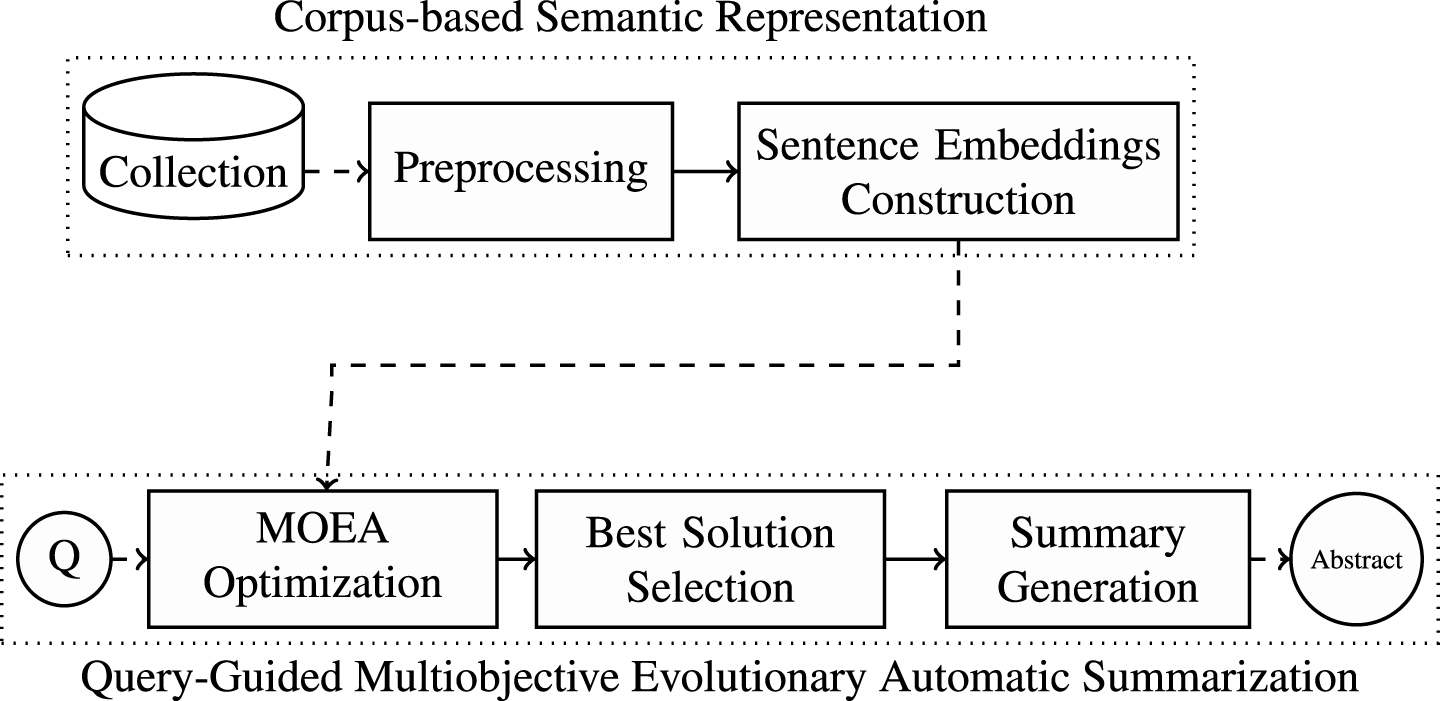
Proposed method for query-guided text summarization based on multiobjective evolutionary algorithms and word embeddings.
As mentioned, a fundamental aspect of the summarization problem is the way in which sentences are represented in order to facilitate their processing, but mainly in an attempt to capture syntactic and semantic relations. Recent research has been reported where word embeddings have been used as a semantic modeling technique in different Natural Language Processing tasks [4, 5].
The computation of word embeddings from text corpora has been an active research field in recent years [20, 22]. Although many such methods now exist, any of these representations is useful for the purposes of the work presented here. The model proposed by Mikolov et al. [20], known as
In
Hence for the
Multiobjective evolutionary optimization
The application of evolutionary algorithms to solve multiobjective optimization problems has been very successful. In fact, it emerged as a new field called evolutionary multiobjective optimization (EMO), wich refers to the use of any sort of evolutionary strategy (i.e., genetic algorithms, evolution strategies, evolutionary programming or genetic programming) to solve multiobjective optimization problems [7].
The Nondominated Sorting Algorithm II (NSGA-II) [9] was chosen because it is a genetic algorithm that has been widely used in solving many multiobjective problems with good performance [29]. This algorithm was proposed as an improvement to the NSGA [25], incorporating the concept of elitism, meaning that the most fit handful of individuals are guaranteed a place in the next generation.
In general, a genetic algorithm works with a population of potential solutions to an optimization problem. Each individual within the population represents a particular solution of the problem, generally codified and known as a chromosome. It also has associated a fitness value that expresses how good the individual is in solving the problem. These algorithms use a set of genetic operators, which operate stochastically on the population. Three basic operations that consist in reproduction, crossover and mutation are applied on the individuals with higher fitness, akin to a biological evolutionary process. The population evolves through generations to produce better solutions to the problem; i.e. individuals with higher fitness values. Unlike simple genetic algorithms that are looking for a single solution, multiobjective genetic algorithms try to find as many elements of the Pareto set as possible.
The NSGA-II algorithm starts with an initial population of N individuals (P
t
), from which N descendants are obtained (Q
t
). With this population of size 2N (R
t
) the algorithm proceeds to classify each of the vector solutions (Pareto-optimal decision vectors) on different fronts (local Pareto-optimal sets).The non-dominated solutions of the set are obtained and included in the first front. This same process is repeated with the remaining decision vectors until all are sorted in some way in different fronts.The main steps of the NSGA-II algorithm are described below: Combining parent and offspring populations to create R
t
= P
t
∪ Q
t
. Perform the non-dominated sorting at R
t
and identify the fronts Fi, i = 1, 2, ..., etc. Make Pt+1 =∅. While |Pt+1| + |F
i
| < Ndo|Pt+1| = |Pt+1| ∪ |F
i
|. Sort by crowding distance2 and include in P
i
the N - |Pt+1| solutions that are more sparse using the crowding distance values associated to the front F
i
. Create offspring population Qi+1 from Pi+1 using binary tournament selection, crossover and mutation.
The main processing stages of the proposed method are described next.
The coverage function is intended to maximize the similarity between each sentence of the abstract to the average vector of the collection, as it has been demonstrated by Radev et al. in [23] that this is the vector that best represents the central content of the collection.
The objective pursued with this function is to minimize the similarity of each sentence of the abstract with respect to the rest.
Three experiments were undertaken to validate current proposal. The first experiment aims at evaluating the performance of the proposed approach for a generic summarization task. The second experiment was designed for a query-oriented summarization task. Finally, a third experiment compares the performance of the selection method used in the current version of the system against the best solution from the Pareto set. The purpose of this third experiment is to show the potential benefits of seeking the best solution in the Pareto set, which is out of the scope of the present paper.
For all experiments, the embedded sentence representation is compared against a standard tf - isf representation showing the advantages of the former over the latter, in both a linearized-MOO (LIN-MOO) system and the approach proposed here (QOS-MOO-WE). The vector space model for sentence retrieval uses the term frequency – inverse sentence frequency method (tf - isf) which is analogous to the traditional term frequency – inverse document frequency method (tf - idf) used for document retrieval [10].
Experimental setup
The tests were developed with the corpus of TAC-2009 [8], which is made up of news from different press agencies such as Agence France Presse, New York Times, etc., in the period from 2004 to 2006. The news are grouped in 44 topics, and there are 20 news papers per topic. In addition, there are 4 summaries per topic written by humans, which are the reference summaries for the evaluation.
ROUGE, which stands for Recall-Oriented Understudy for Gisting Evaluation [16], its an automatic package for text summarization evaluation that uses unigram co-occurrences between summary pairs. Usually, automatically produced summaries are compared against human written ones, using standardized measures to determine the quality of a summary. The evaluation measure used in this work was ROUGE-N, N ∈{1, 2}, where N is number of n-grams used for the metric. According to in-depth studies based on various statistical metrics and comparison to the results of the Document Understanding Conference (DUC) 2002, this evaluation method correlates surprisingly well with human evaluation [17].
ROUGE-N is calculated as follows:
Tables 1 and 3 show the results obtained for this first experiment using ROUGE-1 and ROUGE-2 evaluation respectively. In Tables 2 and 4 the same measures are evaluated but eliminating stop words. The values marked with an asterisk indicate the best of the four systems. These results are statistically better than the others according to the Wilcoxon Signed Rank test [27] with a significance level of 5%.
Rouge-1 Evaluation for Experiment 1
Rouge-1 Evaluation for Experiment 1
Rouge-1 (Stop Words Removal) for Experiment 1
Rouge-2 Evaluation for Experiment 1
Rouge-2 (Stop Words Removal) for Experiment 1
The results obtained in this first assessment show that the embedded representation is better than the tf - isf representation in all cases and that the multiobjective approach is better than the linearized method for ROUGE-1 and ROUGE-2 measurements including stop words.
Moreover, in this case special attention is paid to the solution summary length. In TAC2009 competition, the summary was limited to a maximum of 100 words, so it was analyzed whether the summaries obtained complied to this constraint. Using Equation 4 the L parameter was set to 100 in a first run, however it was noticed that summaries did not have exactly the same number of words that L, so these values were changed for different runs. Results are depict in Fig. 2.
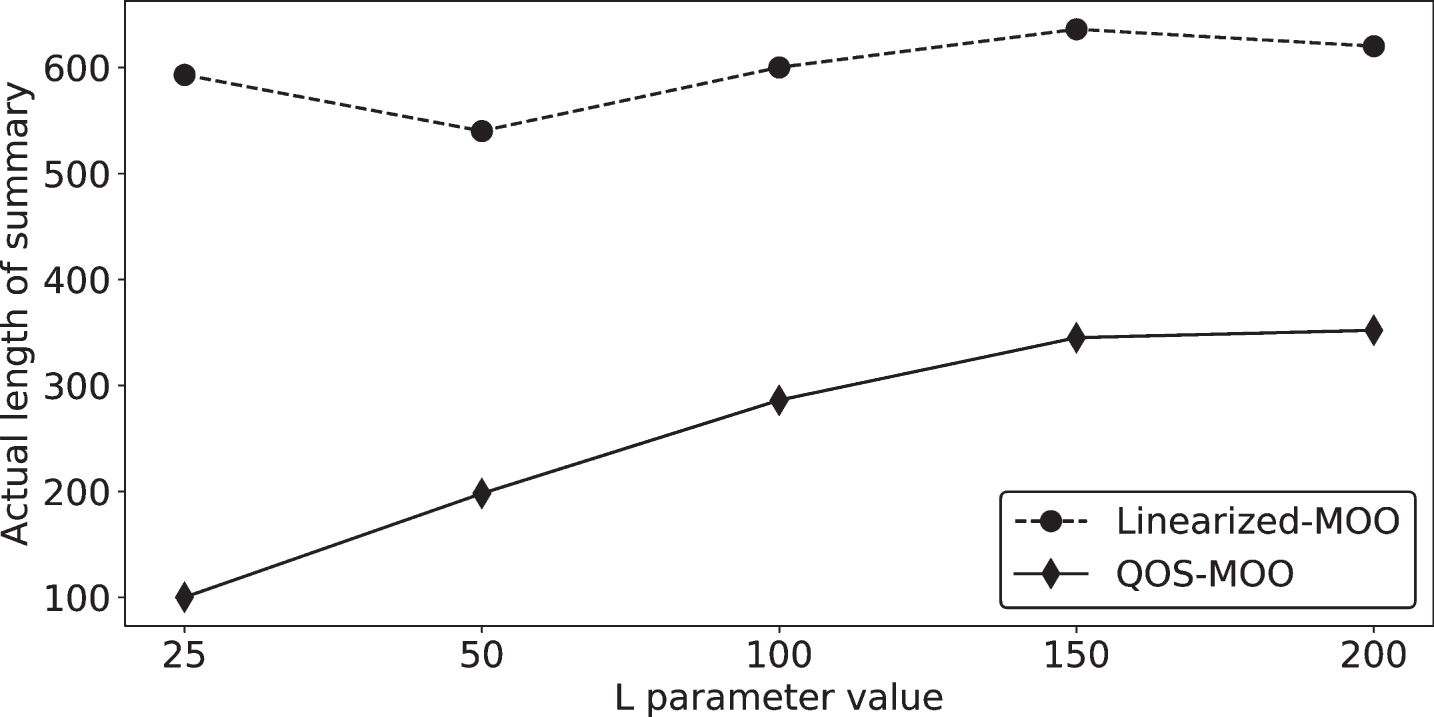
Compliance of optimization methods to the constraint on summary length in function of model parameter L.
As can be appreciated in the Fig. 2, in both cases the number of words obtained from either method is way larger than expected. Nevertheless, compared to its linearized counterpart, the QOS-MOO method produces summaries whose length behaves more linearly. As it was not possible to comply to the exact length constraint, the length criterion was not included in the next experiment.
As previously mentioned this second experiment aims to assess the performance of the proposed approach in a query-focused summarization task. In this case two conflicting objectives appear, namely to minimize redundancy while maximizing relevance. Results are shown in Tables8.
Rouge-1 Evaluation for Experiment 2
Rouge-1 Evaluation for Experiment 2
Rouge-1 (Stop Words Removal) for Experiment 2
Rouge-2 Evaluation for Experiment 2
Rouge-2 (Stop Words Removal) for Experiment 2
For this second experiment the results are similar to the previous test. That is, it is possible to assert that the representation of sentences using word embeddings is better than the classical tf - isf method.
However, the results are not conclusive in favour of the proposed method, since it is not true for all cases that the QOS-MOO-WE approach is better than the MOO-LIN-WE method. The problem stems from the selection procedure of the solution from the Pareto set. This assertion is confirmed with the third experiment which follows next.
The aim of this experiment is to demonstrate that the proposed method has potential benefits against approaches of the kind MOO-LIN. Tables12 show that the best solution coming from the Pareto optimal set performs the better over the whole set of runs.
Rouge-1 Evaluation for Experiment 3
Rouge-1 Evaluation for Experiment 3
Rouge-1 (Stop Words Removal) for Experiment 3
Rouge-2 Evaluation for Experiment 3
Rouge-2 Evaluation for Experiment 3
Finding the best solution is however not obvious as can be observed in Fig. 3. In this figure the Pareto set results were normalized using a typical min-max approach. The best solution from the Pareto set of each topic is plotted in order to locate it in the Pareto’s frontier. In this respect it should be noticed that the objectives represented are conflicting, as the goal is to maximize relevance and minimize redundancy. The figure shows that the space of best solutions is sparse and it is not obvious from the available information to define a pattern of optimality for all cases. This problem requires further analysis and is part of undergoing research.
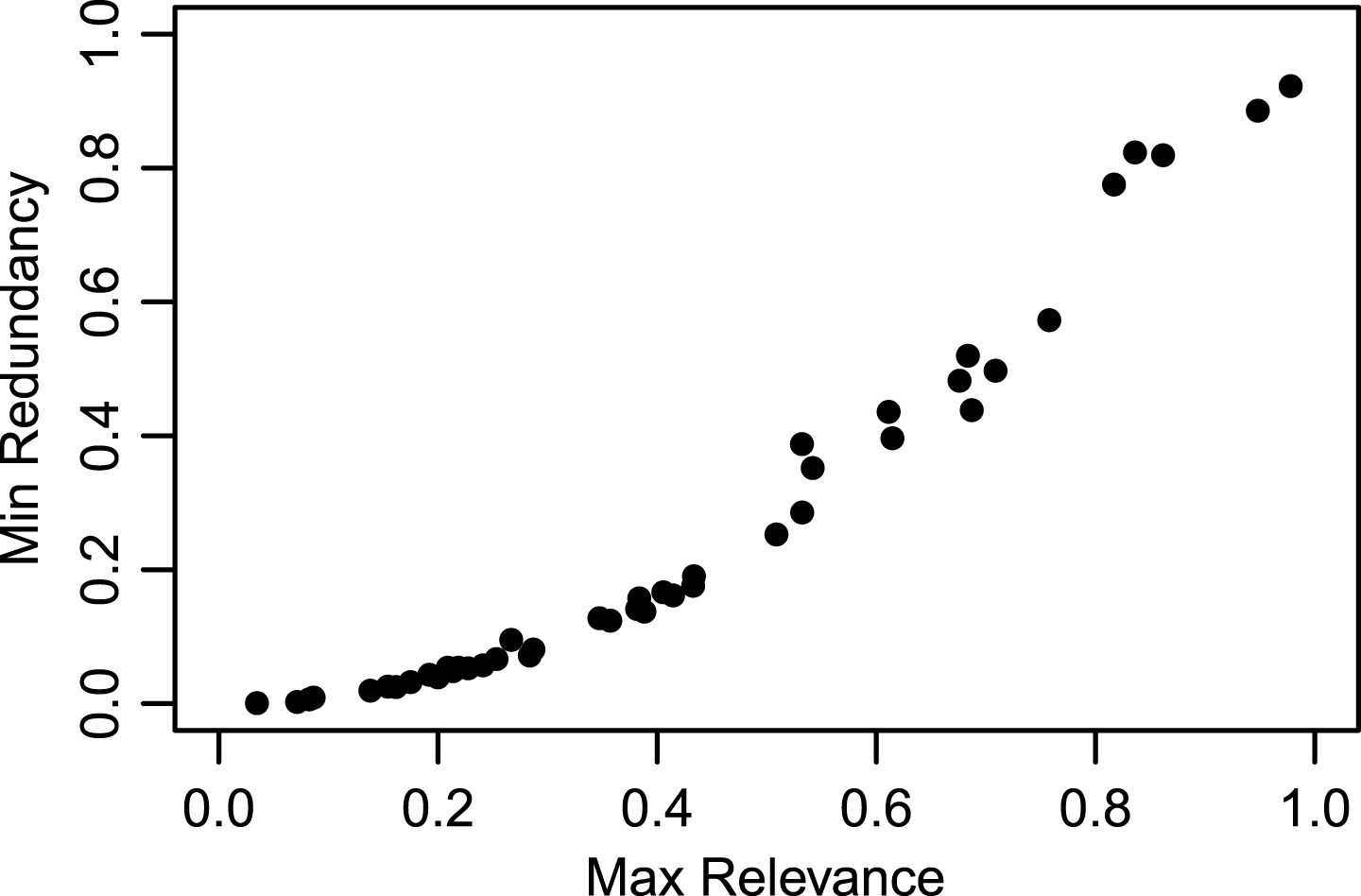
Best solutions for all topics in QOS-MOO-WE.
This paper proposes to address the query-focused automatic summarization task as a multiobjective optimization problem, which consists in finding the Pareto optimal set of solutions. State-of-the-art approaches propose a single-objective function which is unrealistic. At best, solutions have been proposed that involve multiple, conflicting objectives, eventually aggregated into a scalar function thus resulting in a linearized optimization problem.
This work lays evidence on the benefits of word embeddings for sentence representation when defining redundancy, coverage and relevance measures in an optimization problem for a summarization task. In this case, the representation of a sentence was obtained from pretrained word embeddings that were averaged. However it is possible to explore other sentence embeddings that could increase the overall performance of the system.
Despite the fact that the results presented in this work are preliminary, the benefits of the approach were demonstrated by the experiments, which allow us to conclude the following: (1) a sentence semantic representation yields better performance than a tf - isf representation. (2) the query-oriented summarization method based on the Pareto optimal set introduced in this paper performs better than a multiobjective optimization approach with just one function that combines the objectives to optimize. As it was shown, the problem remains as to how to automatically identify the best solution. Both issues are considered of the utmost importance so that further research in this direction is envisaged as part of future work.
An additional advantage of the method proposed in this work is that, depending on the user and application, one could choose different solutions as appropriate summaries. Indeed, on the one hand it may be the case that redundancy is tolerated insofar as all that is relevant is included. On the other hand, another scenario could be a preference for very concise summaries with very little redundancy, although it does not include all the information. The approach presented in this paper has this flexibility as seeking the best solution from the Pareto set allows to model these different scenarios in an intuitive way.
Footnotes
Acknowledgments
This work was partially funded by CONACYT under the Thematic Networks program (Language Technologies Thematic Network project 281795) and through the scholarship No. 574411.