
Abstract
Bearings are one of the most omnipresent and vulnerable components in rotary machinery such as motors, generators, gearboxes, or wind turbines. The consequences of a bearing fault range from production losses to critical safety issues. To mitigate these consequences condition based maintenance is gaining momentum. This is based on a variety of fault diagnosis techniques where fuzzy clustering plays an important role as it can be used in fault detection, classification, and prognosis. A variety of clustering algorithms have been proposed and applied in this context. However, when the extensive literature on this topic is investigated, it is not clear which clustering algorithm is the most suitable, if any. In an attempt to bridge this gap, in this study four representative fuzzy clustering algorithms are compared under the same experimental realistic conditions: fuzzy c-means (FCM), the Gustafson-Kessel algorithm, FN-DBSCAN, and FCMFP. The study considers only real-world bearing vibration data coming from both a benchmark data set (CWRU) and from a lab setup where interference between bearing faults can be studied. The comparison takes into account the quality of the generated partitions measured by the external quality (Rand and Adjusted Rand) indexes. The conclusions of the study are grounded in statistical tests of hypotheses.
Keywords
Introduction
Bearings are critical elements in rotating machinery as they are both essential elements and especially prone to faults given the environments in which they usually work. To recognize the importance of such mechanical elements, it is enough to recall that most of world energy production, consumption, and transformation relies on rotating machinery such as alternators, compressors or (wind) turbines and all of these use bearings.
The health degradation of a bearing is a continuous irreversible process. Once the bearing is installed it should enjoy a long-term healthy working period. Eventually, minor incipient faults start appearing gradually at first and then acceleratedly grow with operation time leading to a complete failure. Therefore, to allow for suitable maintenance fault diagnosis, i.e., health condition assessment becomes a fundamental activity.
Generally speaking, bearing fault diagnosis consists of the following data pipeline: data acquisition and conditioning, feature generation, feature selection, and classification. The literature on bearing fault diagnosis is extensive. This paper focus on the employment of fuzzy clustering. Clustering is a fundamental data analysis tool aiming at segmenting a finite, unlabeled, multivariate data set into a set of homogeneous groups, categories or clusters [1]. In a recent review [2], fuzzy clustering has been identified as the second most applied fuzzy formalism for fault diagnosis. Fuzzy clustering has been used as i) an unsupervised fault classification tool, e.g., [3–7]; ii) to estimate data membership values in fuzzy support vector machines, e.g., [8]; iii) for identifying the centers of radial basis functions neural networks acting as bearing fault classifiers [9, 10], and iv) for identifying the antecedent of the rule in fault classifier probablistic fuzzy systems [11]. In [12] FCM was used as the first step in a sparse component analysis procedure for feature extraction for fault detection.
A variety of clustering algorithms have been proposed and applied in the context of bearing fault diagnosis. As noticed in [2], when the extensive literature on this topic is investigated, it is not clear which clustering algorithm is the most suitable, if any. In an attempt to bridge this gap, in this study four representative fuzzy clustering algorithms are compared under the same experimental realistic conditions. The algorithms are: i) The Fuzzy C-Means (FCM) clustering algorithm. In this study FCM acts as the reference clustering algorithm – actually FCM is used in more than 77% of the works on fuzzy clustering for bearing fault diagnosis [2]; ii) The Gustafson-Kessel algorithm (GK) [13]. GK can be viewed as a variant of FCM that employs an adaptive Mahalanobis norm and a clustering covariance matrix which enables the algorithm to deal with ellipsoidal clusters with independent orientations and volumes; iii) FCMFP [14, 15] where a regularization term based on a focal point representing the position of a data observer is embodied into the cost functional of FCM. By changing the regularization hyper-parameters, different regions of the feature space are analyzed with different levels of detail; and iv) FN-DBSCAN [16, 17], a density based, cluster shape independent algorithm.
To ensure operating conditions as realistic as possible, only real-world bearing vibration data coming from mechanical experimental setups are used. The first setup is the well-known Case Western Reserve University (CWRU) setup [18]. The second setup is a more realistic experimental apparatus developed by our research group where fault interferences, different loading conditions, and high levels of noise can be studied.
The paper is structured as follows. Section 2 describes the selected clustering algorithms. Section 3 describes the materials and methods used. The results and discussion are presented in Section 4. A section on conclusions ends the paper.
Background: The clustering methods
Clustering is a tool of exploratory data analysis aiming at segmenting a finite, unlabeled, multivariate data set into a set of homogeneous groups, categories or clusters. Alternatively, clustering can be seen as the process of identifying groups in data so that data in one group are similar to each other, and are as different as possible from data in other groups [1].
FCM
FCM aims at minimizing the objective function (1) for a specified number of cluster c and a given set of observations (data points)
The elements of the partition matrix, u
ij
, i.e., the membership degrees are computed as follows:
Although well-known FCM is presented in Algorithm 1 for easy reference and completeness.
update uij using (3);
update
The algorithm proposed by Gustafson-Kessel (GK) [13] can be viewed as a FCM variant employing an adaptive norm distance to find ellipsoidal shaped clusters. In (1) the distance D
ij
between the centroid of the i-th cluster,
From the necessary conditions for optimizing the above functional, one can obtain the updating expression for each type of hyper-parameter, i.e.,
Similartly, the updating expression for the partition matrix elements is:
Initialize the clusters’ prototypes
Compute Fi using (7);
Compute Mi using (6);
Compute Dij using (4);
Update uij using (8);
update
The Fuzzy C-Means with Focal Point algorithm (FCMFP) [14, 15] is a new clustering algorithm that was recently applied to bearing fault diagnosis [6] and is inspired in the following metaphor. An observer perception of a group of objects depends, among other things, on the observer position. The closer the observer is to a set of objects the clearer the set is perceived. Inversely, the farthest the observer is from the objects less details are visualized. When close enough each object is clearly visible, when too far all objects are visualized as a single entity. This metaphor is substantiated as follows.
The observer position is modeled by a (focal) point
The regularization coefficient is ζ ≥ 0 and allows one to adjust between the unbiased algorithm (FCM) for ζ = 0 and a biased one. Notice that
Consider for instance an unconstrained setup with as many prototypes as data points (Cmax = N). We can think of ζ = 0 as the case where the observer is so close to data that each datum is regarded as a cluster; as ζ increases some prototypes are subsumed by
Once again we can resort to alternating optimization to minimize (9). The optimization problem can then be converted into an unconstrained one using Lagrange multipliers, yielding the updating expressions:
According to [15], no restrictions apply to the point
The number of clusters c is one of the most important parameters of a partitioning clustering algorithm. Only if c equals the (usually unknown) number of subgroups in the data there is a possibility that the clustering process effectively reveals the existent structure of the data. Often, the merit of selecting a given c is evaluated by a cluster validity analysis. One possibility consists in running the clustering algorithm several times for a sequence of c values. The number c which optimizes the validity measure is elected as the best one.
Initialize the clusters’ prototypes
update uij using (10);
update
Project the prototypes into the original feature space
In order to find a number of reasonable clusters we employ an iterative algorithm which consists of successive runs of FCMFP with increasing values of ζ given that
(1 < c′ < Cmax; ζ ≥ 0, and Δζ > 0
Apply Algorithm 3;
Remove neglectable clusters (clusters without any typical datum);
Compute the validity measure for the remaining candidate clusters using (12);
Update ζ ← ζ + Δζ.
The fuzzy neighborhood density-based spatial clustering of applications with noise algorithm (FN-DBSCAN) [16, 17] is a density based, cluster shape independent algorithm that does not require an initial guess for the number of the clusters nor their initial parameters; it has its own set of hyper-parameters though. The algorithm belongs to the family of DBSCAN algorithms whose inductive bias is that a cluster center has a high density of nearby data samples and is relatively distant from other cluster centers.
A central notion in the DBSCAN family of algorithms is that of a core data point. Informally, a core point has a minimum number of other data samples within a given neighborhood. Two closed enough core points are clustered together. In FN-DBSCAN the degree to which
c = 0; % current cluster number;
P ← 0;
neighbours = FN
c = c + 1;
P(c) ←
nn = FN
neighbours ← nn;
Find the centers of each cluster by averaging its members;
FN-DBSCAN was applied recently to a bearing fault diagnosis problem [21].
Vibration analysis is by far the most used and cost-effective technique for bearing fault diagnosis. Consequently, it will be used in this study. In brief, vibration analysis consists of three major steps: i) vibration signals acquisition using accelerometers, ii) feature extraction; and iii) fault diagnosis based on the selected features. This section presents the material and methods used in theses steps.
Experimental apparatus
Two experimental setups are used. The first one is a simple but widely used benchmark setup from the Case Western Reserve University (CWRU) Bearing Data Centre [18]. The second is a more realistic experimental apparatus developed by our group where fault interferences, different working conditions, and high levels of noise can be studied. These are briefly described next.
The CWRU setup
In the CWRU setup [18] the 6202-2RS JEM SKF deep groove ball bearing is employed to support the motor shaft at the fan end side. Vibration signals acquired by accelerometers placed at 12 o’clock on the bearing housing, sampled at 12 KHz, were measured under 0-load at four successive rotation speeds, i.e., 1730, 1750, 1772, and 1797 rpm. Four health conditions were observed: 0,1778 single fault in i) inner race, ii) outer race, iii) ball, and iv) no fault. For each of the above operating conditions, 20 data acquisition experiments were performed. The vibration signal data set includes 320 samples of 2000 points each.
The GIDTEC setup
The GIDTEC setup was developed by our research group and has been used in a series of studies dealing with different aspects of the bearing fault diagnosis problem [2, 22– 25].
In brief, the GIDTEC experimental setup consists of the following. Two SKF 1207 Ektn9/C3 bearings are installed in a ø 30 mm shaft and mounted in their SKF Snl 507-606 housings. One accelerometer PCB Icp 353c03 is installed in each bearing housing for measuring the vibration signals that are collected by the data acquisition card NI Cdaq-9234. The shaft is driven by a Siemens 1LA7 090-4YA60 2Hp motor that is controlled by a Danfoss VLT 1.5 kw driver inverter. Flywheels are mounted on the shaft when load is required. See the above references for photos and schemes of this setup.
A total of 63 × 5 =315 experiments were performed. Each experiment is characterized by a tuple 〈speed, load, bs〉 where speed is the shaft speed, load is the total load on the shaft, and bs stands for the bearing status. Given the low variability of the results, each experiment is only repeated 5 times. Three discrete speeds are tested: 8, 10, and 15 Hz. Also, three different types of loads are essayed: zero, one, and two flywheels. The essayed bearing status are described in Table 1. The sampling frequency is 50 kHz being determined considering the following. High frequency band signals, between 1 to 20 kHz, are indicators of faults in bearings. According to the Nyquist-Shannon theorem the sampling frequency should be at least twice the signal highest frequency (20 kHz). Therefore we choose 50 kHz for securely meeting this requirement. The duration of each sample (measurement time) is 20 s.
Health states of the essayed bearings for the GIDTEC setup
Health states of the essayed bearings for the GIDTEC setup
From the vibration signals time, frequency, and time-frequency domain features are computed. A total of 1634 features are computed as follows. Seven time domain features (including root mean square, variance, kurtosis, skewness, crest factor), 730 frequency domain, and 80 time-frequency features. The vibration signals are converted to frequency signals using Fast Fourier Transform (FFT). The frequency signals were divided in 80 bands of 20 KHz each. Afterwards features are computed for each one of these bands. A band is identified by a number between 1 to 80. Also, Wavelet Packet Transform (WPT) are used to extract time-frequency features. More concretely five mother wavelets are used: Coifier (coif4), Symlet (sym), Biorthogonal (bior6.8), Reverse Biorthogonal (rbior6.8), and Daubechies (db7). For each mother wavelet, wavelet decomposition has been performed up to four levels. Thereafter 24 coefficients are obtained for each mother wavelet. See [6] for further details.
Features selection
Feature selection or dimensionality reduction is a critical step for optimizing efficiency, accuracy and for mitigating overtraining. After all and in a first observation, one can notice that generated features can be redundant and highly correlated. See [26] for a comprehensive comparison of the main available methods for feature selection in rotating machinery fault diagnosis.
In this study, a decision tree-like entropy based criterion is used. In brief, a feature x
j
is selected so that it yields the maximum information gain on the data set
Results and discussion
In this section, the results of the four selected clustering algorithms are compared. The comparison measures the quality of the resulting partitions using the external quality Rand and Adjusted Rand indices presented in the Apprendix. For each scenario each algorithm is ran 30 times under the same initial conditions, including the same random generator seed. Afterwards the quality of the resulting partitions were statistically evaluated using non-parametric statistical Friedman and Wilcoxon signed-rank tests [27]. The significance level considered was α = 0.05 corresponding to a confidence interval of 95% , i.e., if p-value <0.05 it is considered that there is a statistical significant difference among the results being analyzed (rejection of the null hypothesis). There is no statistical significant difference among results, otherwise.
For each algorithm and each experimental setup, two cases are worth study. The case with 2 clusters corresponding to the fault/no fault scenario, and the case with the number of clusters equal to the number of truth health conditions. These are the cases presented below.
Results for the CWRU setup
When the proposed methodology is applied to the data set acquired with the CWRU setup only 2 out of 805 features are selected as the most relevant ones: the time domain rms, and the linear amplitude rms of the FFT band 4. Figure 1 shows ground truth partitions represented in this reduced feature space for (a) 2 clusters, i.e., fault/no fault case, and (b) for 4 clusters corresponding to the 4 health conditions.
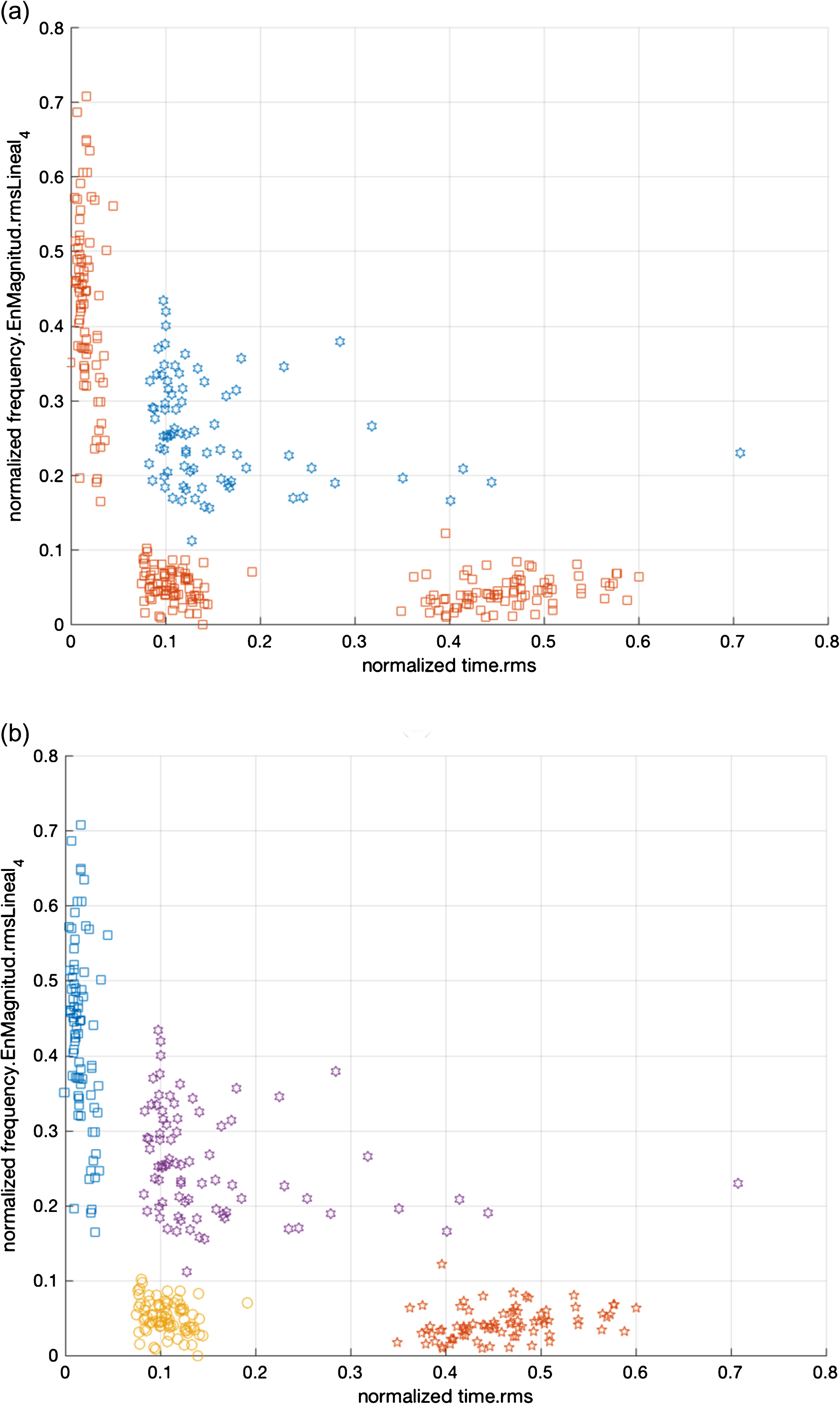
Ground truth partitions for (a) 2 clusters, i.e., fault/no fault case, and (b) for 4 clusters corresponding to the 4 health conditions of the CWRU setup. Data points represented with the same graphical symbol belong to the same cluster.

Boxplots showing the dispersion of the Rand Index values obtained by the algorithms over 30 independent runs for (a) 2 and (b) 4 clusters – CWRU setup.
The hyper-parameters used in the algorithm comparison for the CWRU setup.
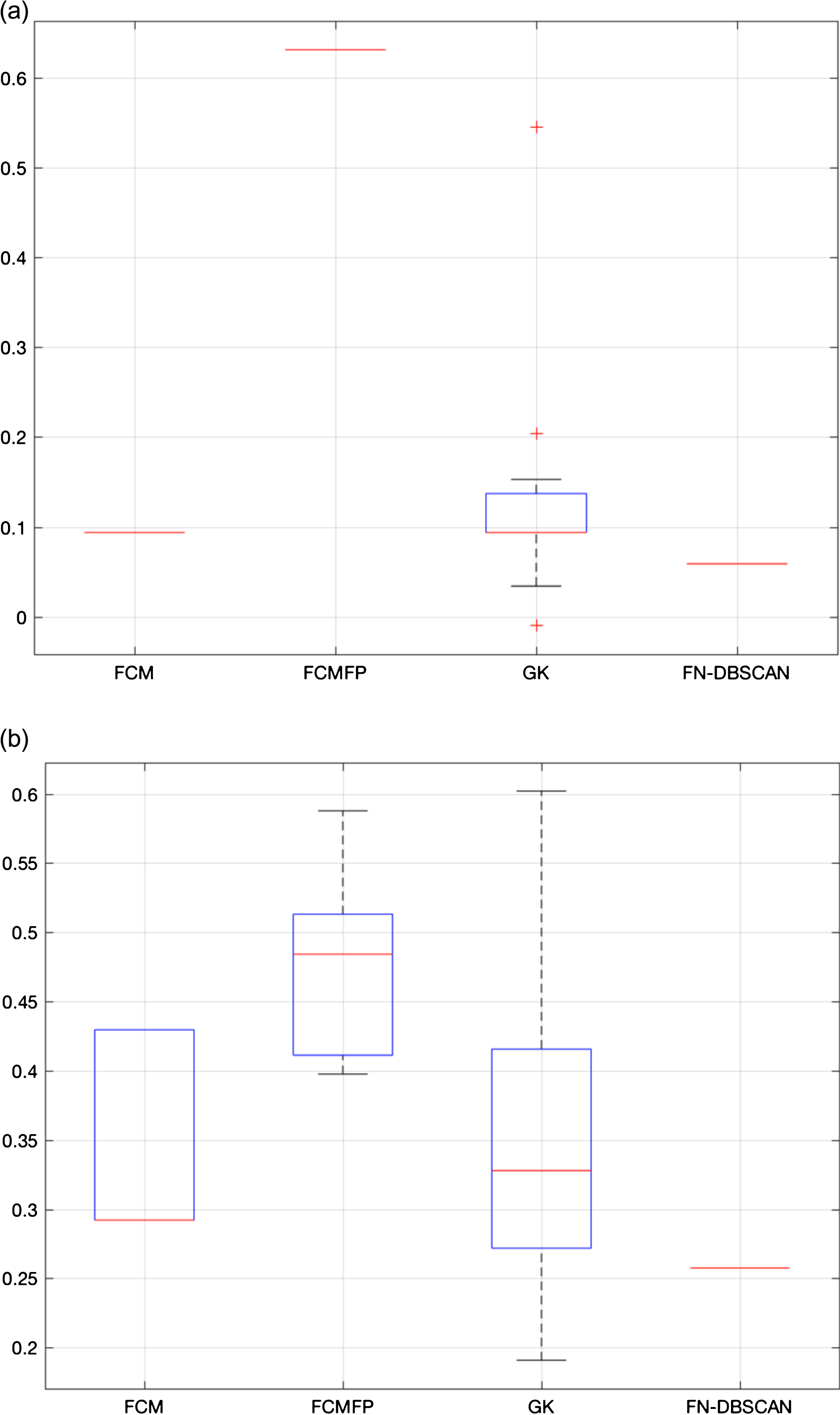
The four algorithms were compared against external validation and the observed dispersion of Rand Index values are displayed in Fig. 4. A pf = 1.7e - 17 and pf = 1.2e - 18 were obtained for (a) 2 and (b) 4 clusters, respectively, meaning that there is a statistical significant difference among the results of the algorithms in both cases. Further analysis reveals that for (a) the best performance was due to FN-DBSCAN and the worst to FCM. For (b) the best was GK while the worst was FN-DBSCAN. The hyper-parameters used by the algorithms in the comparison are presented in Table 3. FCM and GK were the easiest algorithms to configured while the other two were the hardest. As no systematic method was available for tuning the algorithms, no claim can be made on the optimality of used hyper-parameters is made. The FN-DBSCAN algorithm is the only one the ability to detect outliers in the dataset and is immune to initial conditions.
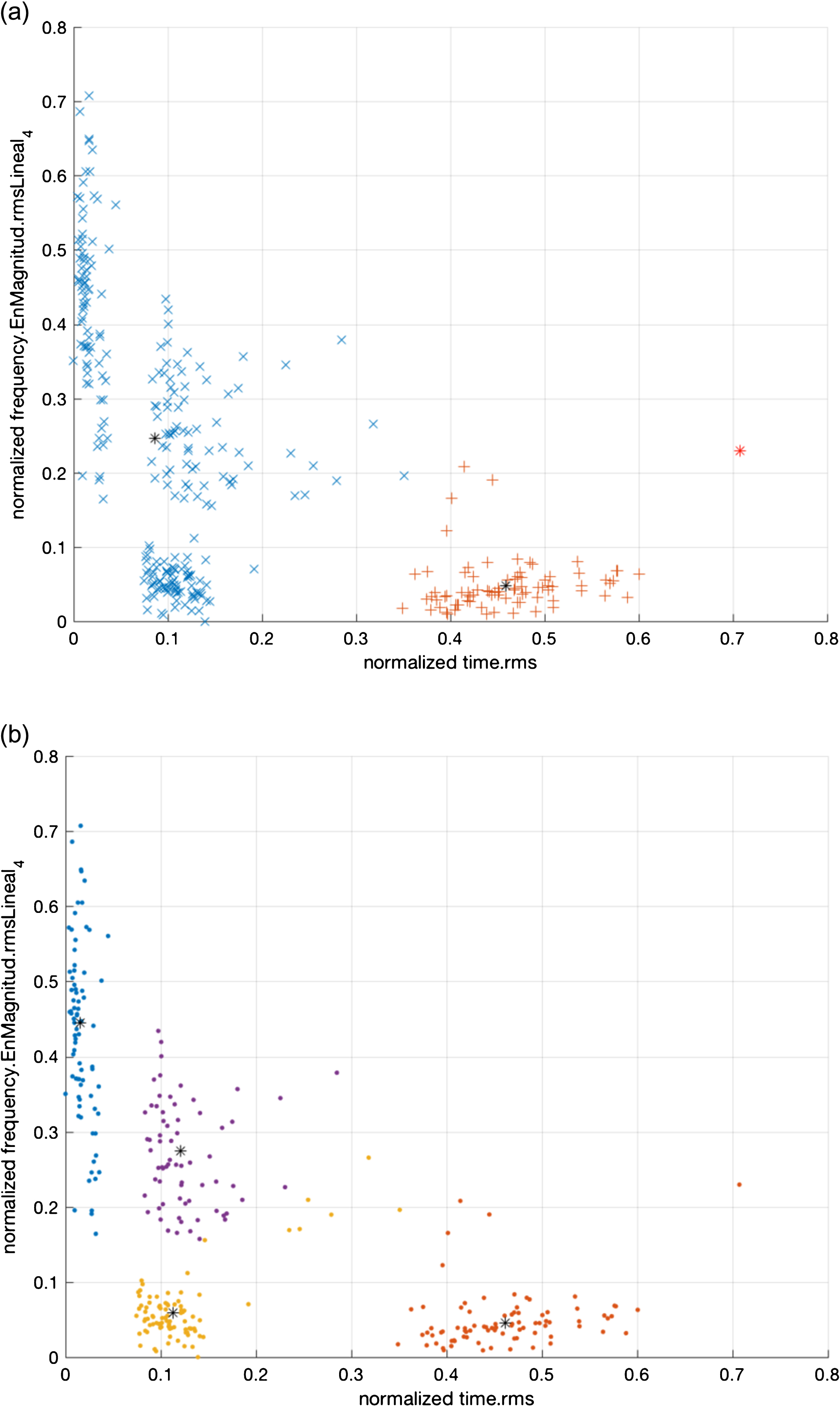
Best clustering results as evaluated by the Rand Index for the CWRU setup: (a) FN-DBSCAN 2 clusters and (b) GK with 4 clusters. Cluster centers are identified by the symbol * and outliers by *. Otherwise, each cluster is identified by data points represented by the same graphical symbol.
Figure 3 shows the best clustering results obtained for (a) 2 clusters (FN-DBSCAN) and (b) 4 clusters (GK).
Boxplots showing the dispersion of the Adjusted Rand Index values obtained by the algorithms over 30 independent runs for (a) 2 and (b) 7 clusters – GIDTEC stepup.
The hyper-parameters used in the algorithm comparison for the GIDTEC setup.
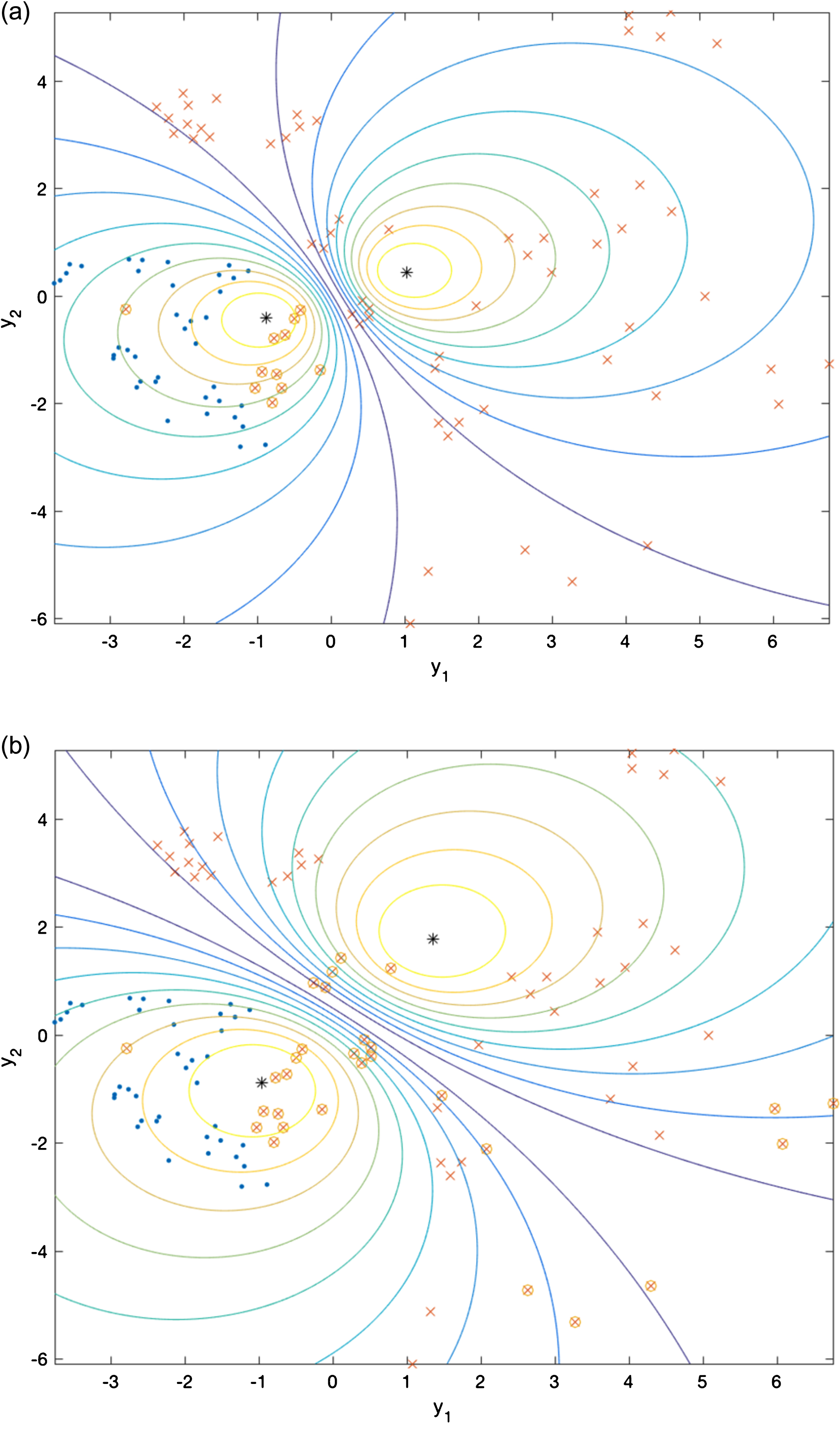
Sammon projections of the 12 dimensions feature space into the plane showing the best clustering results for the GIDTEC setup with 2 clusters obtained by (a) FCMFP and (b) GK. Cluster centers are identified by the symbol *. Otherwise, each cluster is identified by the same graphical symbol.
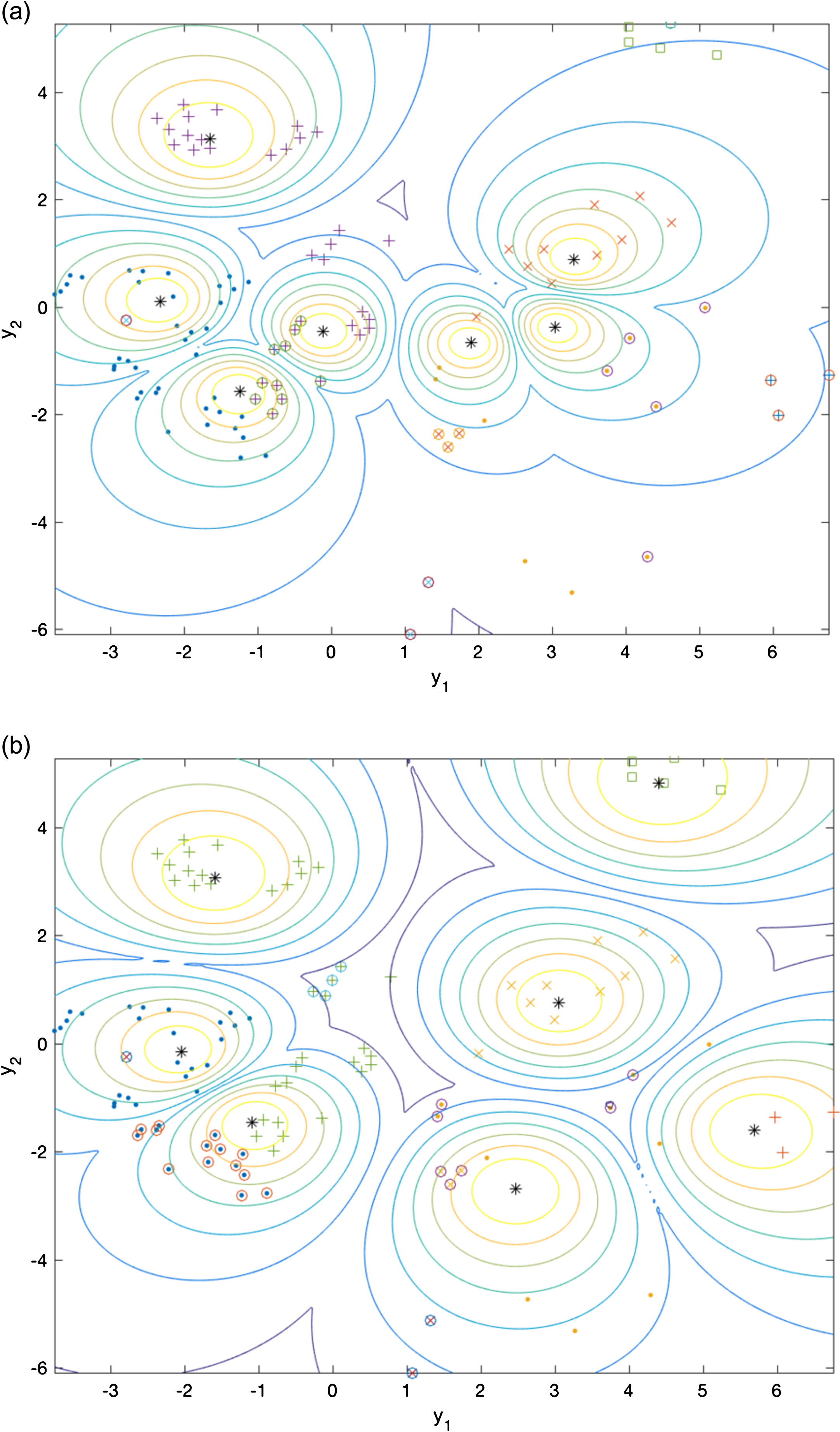
Sammon projections of the 12 dimensions feature space into the plane showing typical clustering results obtained by FCMFP for the GIDTEC setup with 7 clusters. Cluster centers are identified by the symbol *. Otherwise, each cluster is identified by the same graphical symbol. The focal point is located in (a) the baricenter of the data and (b) over the point where features are maximal. Different levels of detail are observed depending on the position of the focal point.
When the proposed methodology is applied to the data set acquired with this setup only 12 relevant features out of 1634 are selected as the most relevant. Other methods such as those based on genetic algorithms selected a number of features one order of magnitude higher typically. From the selected features one can see that Accelerometer 1 is responsible for capturing 9 out of the 12 selected features. Wavelets, i.e., time-frequency domain features correspond to 5 of the total number of selected features; In addition, five time domain and three frequency domain features have been selected. See [6, 11] for details. The four algorithms were compared against external validation and the observed dispersion of Adjusted Rand Index values are displayed in Fig. 4. A pf = 1.35e - 16 and pf = 1.8e - 12 were obtained for (a) 2 and (b) 7 clusters, respectively, meaning that there is a statistical significant difference among the results of the algorithms in both cases. Further analysis reveals that for both (a) and (b) the best performance was due to FCMFP.
The hyper-parameters used are presented in Table 3. As before, FCM and GK were the easiest to configured algorithms while the FCMFP and FN-DBSCAN were the hardest. Again, no claim on the optimality of used hyper-parameters can be made.
Figure 5 shows Sammon projections of the 12-dimensional feature space into the plane. In this figure, the centers of each cluster are denoted by the symbol *. Around each cluster center there are ten solid line curves with different colors ranging from yellow to dark blue, each one of them representing a contour of equal membership value; the farthest the curve from the center the lower the membership value (the darker the blue the lower the membership). Each one of the other colored symbols represents to the truth classification of a sample. Samples in the same class are represented by the same color and symbol. In this figure one can see the best partition produced by (a) FCMFP and (b) by GK for 2 clusters.
Figure 6 shows typical clustering results obtained by FCMFP for 7 clusters. In (a) the focal point is located in over the data baricenter and in (b) it is located over the point where all features attain their maximum values. As it can be seen by changing the focal point it is possible to obtain different levels of detail in different regions of the feature space.
It seems than the shrinkage technique based on which FCMFP is designed plays an important role in multi-dimensional features spaces as is the case of this setup. Curiously enough, this type of performance improvement was not the primary goal beyond FCMFP but appears as a convenient side-effect [15].
It is likely that the relative poor performance of FN-DBSCAN is due to the difficulty of finding a convenient parametrization of the algorithm for this particular data set. It is well-known that the algorithm is highly sensitive to the employed membership function (13) as well as to the thresholds ε and ν.
Bearing fault diagnosis is recognized as both an economically relevant and technical challenging problem. Fuzzy clustering has been extensively exploited in the bearing fault diagnosis literature, especially by resorting to the well-known FCM algorithm. However, up to now no study on the comparison of the rich variety of clustering algorithms has been conducted in bearing diagnosis. In order to bridge this gap, this paper has presented a first-time comparison of four representative algorithms: FCM, GK, FCMFP, and FN-DBSCAN.
To ensure operating conditions as realistic as possible, the studied considered only real-world bearing vibration data coming from both the CWRU benchmark data set and from a more challenging GIDTEC setup specially developed by our research group where fault interferences, different loading conditions, and high levels of noise can be studied.
The comparison takes into account the quality of the generated partitions measured by the external quality Rand and Adjusted Rand indexes. Statistical tests of hypothesis revealed that for the CWRU setup where only two features were used to characterize the bearing healthy state, FN-DBSCAN and GK exhibit the best performance for 2 clusters (fault/no fault case) and for 4 clusters, respectively.
In the GIDTEC setup 12 features were used to identify seven different bearings states. In this case, FCMFP outperformed all the other for both the fault/no fault case and for 7 clusters. The design principle beyond this algorithm is to allows the user to select a suitable level of granularity in a given region of the feature space. However results shown that FCMFP produces partitions exhibiting better external validity index values than the corresponding unbiased algorithm (FCM) for any number of clusters. The improvement is viewed as a convenient side effect of the shrinkage technique employed in the design of the algorithm. From this perspective, one can claim that works currently employing FCM in bearing fault diagnosis would benefit from the use of FCMFP. This also suggests that extension of GK and FN-DBSCAN algorithms with the same design principle and shrinkage technique could also improve the performance of that algorithms in this type of problem.
Footnotes
Acknowledgments
The work was sponsored in part by the Prometeo Project of the Secretariat for Higher Education, Science, Technology and Innovation (SENESCYT) of the Republic of Ecuador, the National Key Research & Development Program of China (2016YFE0132200), and by Fundação para a Ciência e Tecnologia (FCT), Portugal. The experimental work was developed at the GIDTEC research group lab of UPS, Cuenca, Ecuador.