
Abstract
Opinion leaders are those users who have great influence in social networks. It is significant to detect opinion leaders for the study on social networks and other applications. According to the key idea of the PageRank algorithm, a novel algorithm called HybridRank is proposed, taking into account topic-sensitive analysis and temporal characteristics. Our two major contributions are twofold: (1) topic-sensitive analysis is conducted to obtain the clusters in social networks; (2) temporal analysis is proposed to investigate the dynamics of the user’s influence over the time. We also provide impressive experimental analysis on a real dataset grabbed from Chinese Sina BBS, showing that the proposed HybridRank Algorithm outperforms various related approaches.
Keywords
Introduction
Social networks, such as blogs, Facebook, Twitter and other social medium, have become increasingly popular for people to express their opinions in recent years. As more and more people prefer to publish their opinions on social networks, it is evident that some very active users who have great influence on other users, called opinion leader, play a crucial role in information propagation. For example, a company can sell their cool product through these influential persons, and thus a large population in the network would adopt the product through the word-of-mouth effect at a small cost. Consequently, the detection of these so-called opinion leader from a large amount of the users becomes a crucial issue. With respect to the spread of information, it is of great significance to detect these relatively more influential users.
Therefore, considerable attention has recently been devoted to detect opinion leaders as an important issue in social networks. At the current stage, numbers of methods for detecting opinion leaders focus on social relations based on Social Network Analysis (SNA). For instance, some researches detect the opinion leaders by using centrality-based metrics such as degree and betweenness [1]. Other studies put PageRank [2] and other modified PageRank algorithms (including LeaderRank [3] and PloarityRank [4]), which rank nodes according to the link structure features. Some other quantitative research is based on text analysis [5–7], whose strongest advantage is to fully utilize the information of users, such as published comments and online time, in order to reconstruct the model of social networks and identify the opinion leaders more efficiently.
According to the previous presentation, we find that many methods rely on single method rather than by combining the methods above, which would not reflect accurately the importance of nodes for information dissemination. For instance, in a PageRank-based algorithm, its PageRank value is averagely distributed to outbound links; thus the algorithm ignores some information including topic information. The exiting of topic-sensitive phenomenon has attracted many scholars attention [4], i.e., a user follows his friend because he get interested in the topics his friend publishes, and his friend also follows back because they share similar topic interest. Moreover, PageRank algorithm has not concentrated on how temporal characteristics affect the published opinion of internet users. Considering users’ general browsing habits, a user likes the latest published opinions. And thus if a comment published earlier, it may has less influence. In summary, if we want to detect opinion leaders more accurately and analyze its characteristics as well as other useful metrics, it is not enough to put attention only on one measurement, but also needs to combine the methods above. This is exactly what we will do in the paper: detecting opinion leaders by taking into account the multiple measurements, which combines PageRank algorithm, topic-sensitive analysis and other useful characteristics such as temporal characteristics.
We address the context problem by proposing a novel approach to detect opinion leaders, called HybridRank Algorithm. The main framework of the proposed approach is illustrated as Fig. 1. In the pretreatment, some preprocessing is firstly conducted on the raw data, providing conditions for the subsequent process. Secondly, We conduct topic-sensitive analysis through the process called topic distillation, and give each node a particular value to express its topic characteristics. Then we use temporal characteristics to further examine the dynamics of influence, and a modified PageRank algorithm is conducted. Finally, focusing on different topics, we apply our HybridRank Algorithm, which combines PageRank algorithm, topic sensitive analysis and temporal characteristics, to rank users’ influence.

Framework of the proposed approach.
In summary, we address the efficiency problem of detection opinion leader from following two directions. In one direction, we propose a new method to further improve PageRank algorithm, and combine the original PageRank together with text analysis for more accurate results. Specially, by fully using of the topic-sensitive phenomenon, we propose our method to measure the topic-sensitive opinion leaders in social networks, which can further accurately detect opinion leaders. In other direction, we take into account temporal characteristics in the process of detecting opinion leaders, and investigate the dynamics of the user’s influence over the time.
The rest of the paper is organized as follows. Section 2 will overview previous works on detect opinion leaders. Section 3 will describe the basic ideas and methods of HybridRank algorithm. Section 4 will show our experiment results and analysis. We will conclude the research and give the future studies in Section 5.
Our work focus on the detection of opinion leaders in online social networks. And thus we give an overview of the related work in two aspects including Social Network Analysis and PageRank-based algorithms.
Social network analysis
Early Social Network Analysis mainly utilize link structures to detect nodes with high centrality including degree centrality value, closeness centrality, and betweenness centrality [1]. In the methods, the users are represented as nodes and the relations between users are represented as edges usually. In a simple social network, centrality theory prove to be theoretical and practical. These centrality measures capture the importance of nodes from different angles.
Degree centrality
The importance of a node is determined by the numbers of nodes link to it. The higher value of degree centrality would indicate a node has a larger number of connections with other nodes. Given a node k, the degree centrality can be defined as
Here, N is the total number of nodes in the networks, and d (k) is the degree value of node k.
The global index measures the path it takes for a node to connect the rest nodes in a network. The shorter the average distance of a node to other nodes, the more direct and efficient is the node’s impact on the other nodes. Given a network having N nodes, the closeness centrality of node k is calculated as
Where d ki is the length of the shortest path from node k to i in the network.
The betweenness of nodes measures the number of shortest paths that will pass a node in the network. Specially, g
ij
denotes the number of these shortest paths between nodes i and j, and g
ij
(k) represents the number of these shortest paths that pass through node k. Therefore, the betweenness centrality of node k can be defined as
However, these centrality methods have a serious drawback, which is its efficiency. To get desired results reflecting the real networks properties, relying on one or more simple centrality methods would be impossible. What’s more, most recent social networks are large-scale and very dynamic, and also have complex link structures, which indicates the approach to the detection of opinion leaders needs to be very efficient and salable.
PageRank algorithm is a sorting algorithm for link analysis and calculation of rank and importance on the Internet.The higher the level of a web page, the more prominent the importance, in the search engine rankings will appear on the front. It has two basic assumptions: (1) If a page is connected by other more pages, and perhaps it has greater importance; (2) If a page is connected by an important Web, it may be important too. Formally, the PageRank algorithm is described below.
It is noted that, PageRank algorithm measures the influence only considering link structure of the network, rather than some other additional information, which does not accurately capture the notion of influence. For example, when using PageRank algorithm, a topic-drift phenomenon often happen. One of the main reasons of this phenomenon is that PageRank has nothing to do with the topic of queries. Therefore, a set of PageRank-based methods has been proposed to efficiently detect opinion leaders [3, 4]. The most similar work with ours is LeaderRank and TwitterRank. LeaderRank algorithm proposed by Xiao et al. [3] identifies opinion leaders in BBS, which contains two crucial steps, namely finding the clusters based on topic analysis and defining the authority value as the weight of the link between users. Weng et al. [4] present a TwitterRank algorithm to measure the topic-sensitive influence on Twitter by using Latent Dirichelet Allocation(LDA) [8, 9]. The experimental results show that both of their work(LeaderRank&&TwitterRank) outperforms the original PageRank and other related algorithms. Meanwhile, their work provide us new angles of addressing the shortcomings of PageRank algorithm by taking into account both link structure and topical information. However, LeaderRank and TwitterRank both neglect temporal characteristics in the networks. Therefore, we have deeper understanding about the influence and carries out extensive experiments to further examine temporal dynamics of influence, which is more in line with the real networks shown as the experimental results in Section 4.
Considering a social network based on comment, users in the network prefer to browse their interested comments and reply them. Therefore, it is obvious that many users likely relate to each other with the same interesting topics. Based on above observation, a social network consists of three levels including topic layer, comment layer, and user layer illustrated as Fig. 2. There exists some relations mappings between different layers. For instance, users generate a comment which may be consist of several topics, and a topic may maps several comments.

Three layers of social networks.
Our final goal is to efficiently detect opinion leader in G
UN
(V, E), which may change over time. To achieve the goal, the paper takes the core ideas of original PageRank algorithm, and proposes a novel algorithm, i.e. HybridRank Algorithm, which is based on topic distillation and temporal analysis. We will do the following work which will be introduced in following section. Modeling G
CN
(V, E) and G
UN
(V, E) based on connections between comments and users. Topic distillation based on some cluster method. Dynamic detection based on temporal analysis. Detection of opinion leader by using exploring PageRank algorithm.
We will introduce our proposed HybridRank algorithm in detail, and analyze the affection factors including topic distillation and temporal characteristics in the section.
Raw data preprocess
After grabbing the related comments on a social network platform, we can construct the reply network among users directly, and identify the major information during a time period. Next, we will analyze the text information and apply ICTCLAS (Chinese Academy of Sciences Chinese Lexical Analysis System) [10] to split the title and body of comments into words. Formally, for two comments C
i
and C
j
in C = {C1, C2, …, C
n
}, we first conduct some preprocessing by removing punctuation and eliminating stopwords from the comments. And then we split C
i
and C
j
into words respectively, and utilize a vector consisting of representative words to describe C
i
and C
j
. The vector C
k
= {kw1, kw2, ⋯ , kw
n
} denotes the comment C
k
in the social networks, and kw
n
means the key words in the comment. After that, we use TF-IDF [11, 12] to compute weighting by document frequency and inverse document frequency respectively, which has gained popularity in information retrieval assuming that the words are manually independent. Given a comment collection C, a word w, and an individual comment c ∈ C, we calculate
Where fw,c is the number of times w appears in comment c, |C| equals the size of the comment corpus, and fw,C denotes the number of documents in which w appears in C.
After above process, we can describe every comment by Vector Space Model(VSM), which provide foundation for the subsequent process.
Following work focus on clustering and classifying the comments according to the topics based on the proceeding definitions.
There exists many clustering algorithms including K-means [13], Hierarchical Clustering [14, 15] and other methods,which capture the clusters of documents in different perspectives. And it is difficult to define which is the “most suitable” algorithm for a problem regardless of the actual data distribution. However, in large-scale networks, most clustering algorithms are so computationally intensive that one may not get the results in a reasonable time except for K-means algorithm. K-means algorithm runs very fast, and doesn’t require calculating all of the distances between each nodes. Therefore, It can be applied to efficiently deal with very large data sets, where other methods may fail. In conclusion, we use K-means clustering algorithm as our topic distillation method rather than other methods.
Suppose that we have n comment vectors, and we know that they fall into K compact clusters, K < n. Moreover, we define the maximum number of iterations is L. The main steps of K-means is shown as following.
The comments from social networks are divided into groups according to different topics after the process of K-means algorithm. In detail, the model has two parameters to be specified, i.e. the cluster number K, and the maximum number of iterations L. The Fig. 3 describes the detail of K-means where K is 3 and L means 3.

The representation of K-means algorithm.
Moreover, we suggest that each comment is accompanied by the representation of topics, and has at least one topic. As an example, when browsing comments we may incline to those comments on the interesting topics. Therefore, we can draw a conclusion that the impact of topic should be account. Therefore, we propose the following formula to further calculate the topic attribute for comment u:
Where C i represents the set of cluster which comment u belongs(from K-means algorithm), and C is the total numbers of comments.
It can be seen that topic (u) express the ratio of the number of comments in the set which contains comment u to all the number of comments. The more the number of the comments in the set (which comment u belongs to) is, the larger the ratio is, which means it is more influential in the network.
Figure 4 demonstrates the trend of public opinion about the rainstorm disaster in Beijing, 2012. With the passage of time, the comments on the incident gradually reduced whether it was news or Weibo. Since July 22nd, the number of relevant Weibos significantly decreased. Similarly, the number of news reports greatly reduced since July 23rd. In the terms of information dissemination, the influence of the comments become more and more weak.
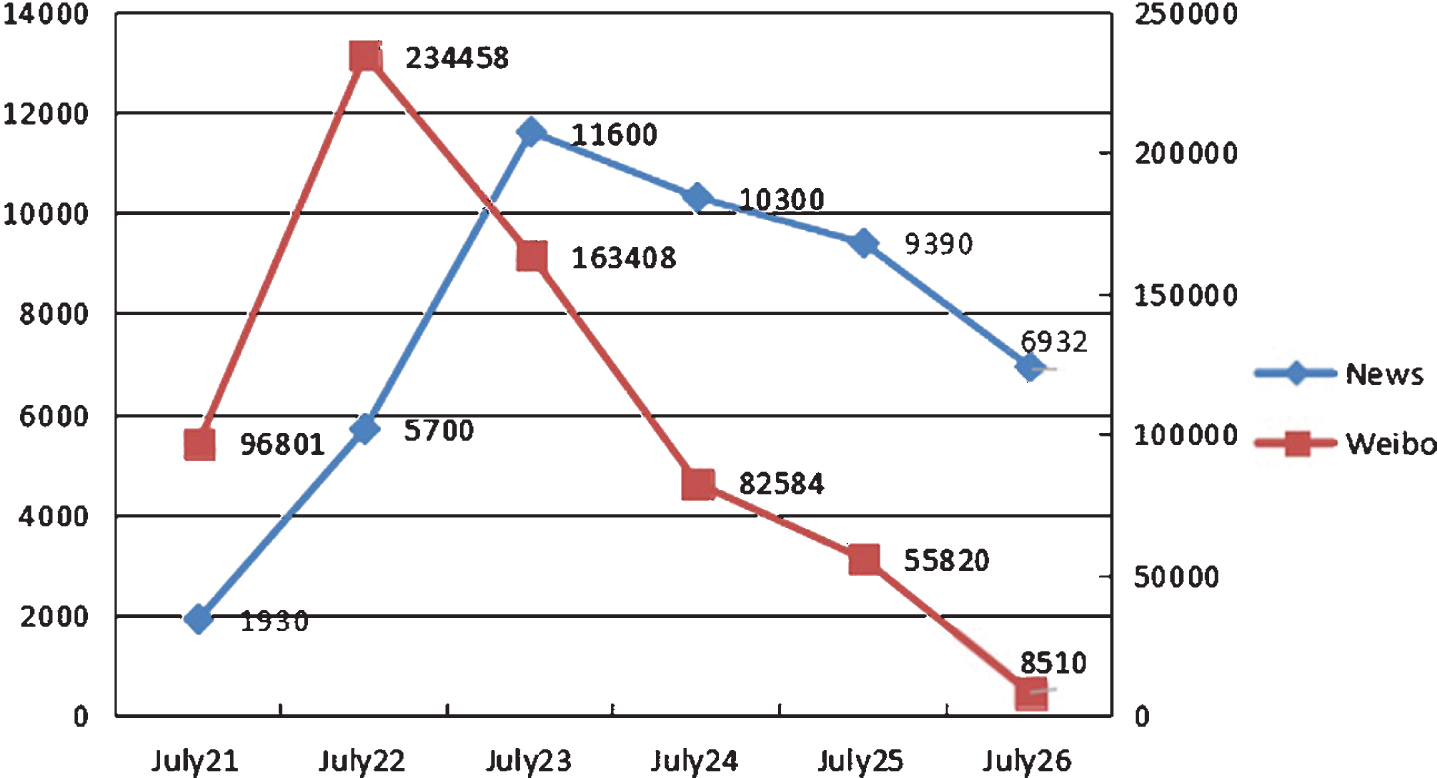
The trend of public opinion about the rainstorm disaster in Beijing.
Therefore, no matter news or Weibo is accompanied by the characteristics oftemporal, such as the time of the comment published. In detail, when reading comments, for instance, we may incline to overview those newly published comments rather than the earlier ones. It is interesting to find that there is a crucial relation between the publishing time of comment and its choice. Therefore, we believe that it is very reasonable to take the impact of time into account.
The paper solves the problem by defining a time reduction function f, which is accompanied by each comment.
Where f is a function relevant to damping coefficient D, time t1 and t2 is published time of the former and latter comment respectively. Therefore, if the latter comment is far from the former one, the probability of be visited is low. Additionally, the damping coefficient D is time- independent, and so we define f as the following formula.
According to the formula above, the larger distance of |t2 - t1|, the smaller value of f (t1, t2, D) is. Moreover, with the increase of |t2 - t1| value, the value of f (t1, t2, D) tends to 1, which satisfies the convergence of the algorithm.
Opinion leaders play an important role in the procedure of information dissemination, who have a great impact on other users in social networks. Therefore, a novel rank method called HybridRank is proposed based on topic distillation and temporal analysis to detect opinion leaders in the paper.
Inspired by the original PageRank algorithm, HybridRank algorithm is presented by considering topic and temporal characteristics. Moreover, we set the topic factors of comments and temporal characteristics as weight of edges between users. For comment u in each topic, the ranking score can be calculated as following.
It can been seen that the above formula is similar to formula 4, i,e, f (t1, t2, D) displaces the originally damp quotient d in formula 4. In addition, we consider each comment is accompanied with a topic factor topic (u). If we conduct the above method, we will finally obtain the score of each comment in a time period. At last we select the user with the highest score as the opinion leader.
HybridRank algorithm is described in detail as Algorithm 1
HybridRank algorithm
In order to verify the correctness, extensive experimental analysis is carried out. The data for the experiment is crawled from Chinese Sina BBS, which exhibit many of the key features of social networks. Through tracking the comments all 2016 year round and splitting the period of time into four time segments, each time segment is analyzed to detect opinion leaders, and also the dynamic change of the opinion leaders is analyzed.
Experimental results
A dataset consisting of 347 users in Sina Sport forum is selected to validate effect of the proposed HybridRank algorithm in the paper. And the start time of the data is from January 1, 2016 to December, 2016. The dataset is grabbed including the authors and their replies from various forum “CBA”, “NBA”, “European Cup”, “Chinese football” and “Chinese volleyball”. And the basic information of the data set is illustrated as Table 1. It is obvious that the forum is a highly sparse network whose average clustering coefficient is only 0.28, with a small amount of nodes that are densely connected among them while being loosely connected to the rest of the graph.
Basic statistics of Sina BBS data sets
Basic statistics of Sina BBS data sets
The datasets is pretreated firstly, splitting by ICTCLAS which is an open-source software in Chinese. Secondly, the comments are clustered by their title and content and formatting different topics by using K-Means algorithm. The distribution of topics for the dataset is shown as Table 2. In order to provide a meaningful description, each topic are associated with 5 keywords that can mostly represent the content in the comments.
The five topics extracted from the comments
The next is to analyze temporal characteristics for each comment. We solve the problem by calculating the value of time reduction function which is defined as formula 10. Each comment is accompanied by a value reflecting the temporal characteristics, which is convenient for our following dynamic analysis. Finally, we conduct our proposed HybridRank algorithm to detect opinion leader for every topic. Table 3 illustrates top-10 opinion leaders with the highest score according to formula 10.
Top-10 opinion leaders for each topic within 2016 full year
From the above table, we can observe that the opinion leaders is sensitive to the topics. Specially, if a user is an opinion leader in one topic, and perhaps it is just a follower in another topic. For example, the user with ID 119561022 is the opinion leader for the topic “CBA”, but ranks outside top-10 in other topics, which means that taking the topic into account is very necessary.
Additionally, we divide one year into four time segments, and each time segment is analyzed to identify opinion leaders, and also the dynamic change of the opinion leaders is analyzed which are shown as Fig. 5.
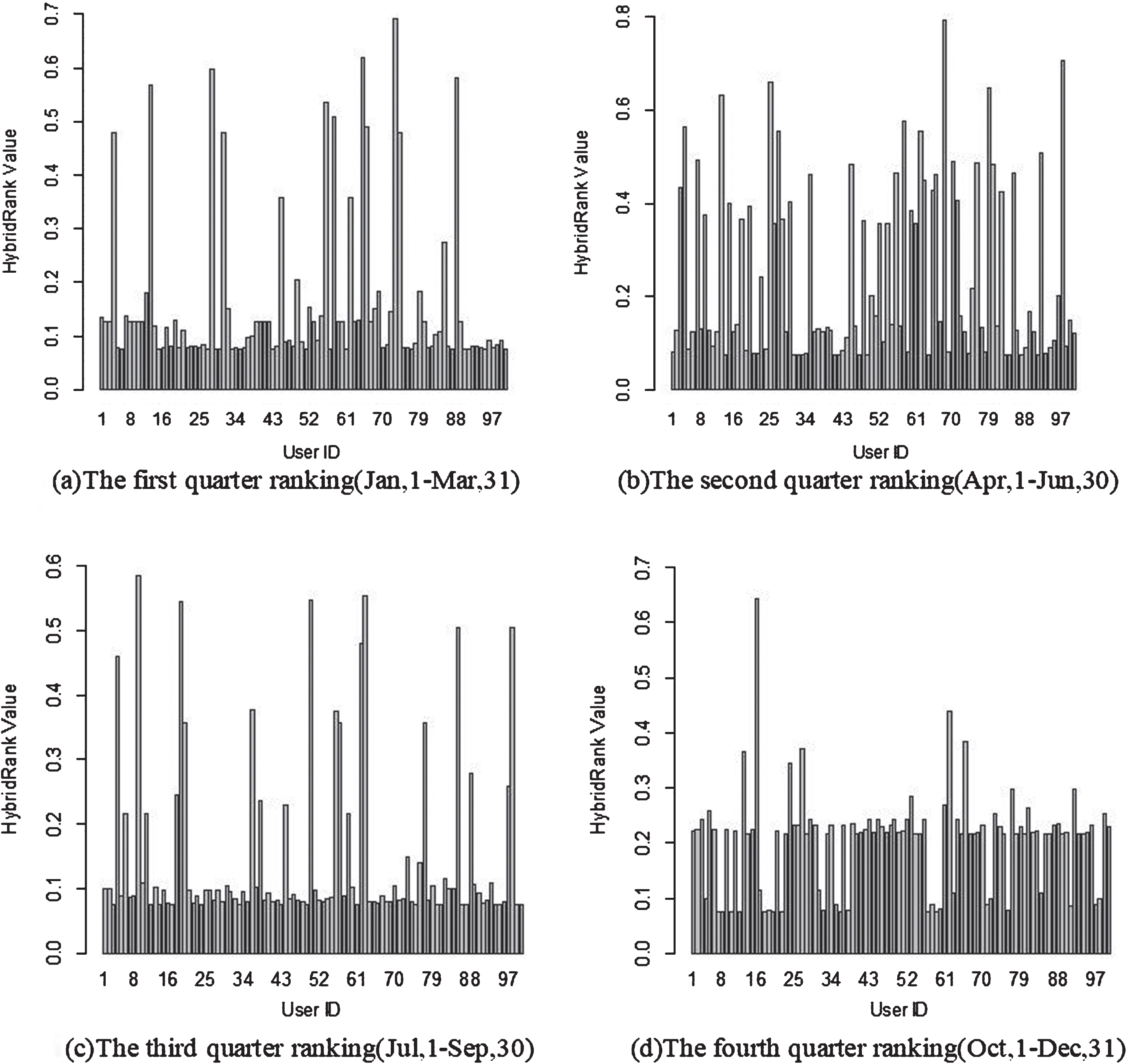
Different time segment ranking in 2016 full year.
From above figure, we find that opinion leaders are really changing over time. In other words, the rank of opinion leaders is also affected by the time. For example, in Fig. 5(a), the user with ID 190438754 had the highest score, meaning that it is the opinion leader in the time segment without question. In comparison with the rest figures, the user got fewer attention in the rest time of 2016 year. Therefore, it is very necessary to consider the time factor when detecting opinion leaders.
To further find the effectiveness of HybridRank algorithm, we first compare the results of our proposed algorithm and PageRank algorithm directly as seen in Table 4.
Comparison of the results of HybridRank algorithmand PageRank algorithm
Comparison of the results of HybridRank algorithmand PageRank algorithm
Table 4 shows top-10 opinion leaders using HybridRank and PageRank respectively. It is clear that the results are very different from each other, with only two repeat users with 323458396 and 436915662. Our proposed HybridRank Algorithm takes into account the multiple measurements, which combines PageRank algorithm, topic-sensitive analysis and temporal characteristics. Therefore, it can be used to enhance the importance of some users, and get reasonable results. For example, since the European Cup is held every four years, it has aroused great concern and more popular comments have been related in June and July, 2016. Therefore, the topic of European Cup has a larger wight. We can find some opinion leaders on the topic such as users “179023165”, “443671098”, “329849037” and “554913373” from Table 3. However, there was less and less attention to the European Cup as time goes on. And more and more people began to focus on important events such as NBA and CBA in November, and some new opinion leaders like users “235611348”, “190438754”, “389042859” and “298472957” were detected. It is worth noting that user “235611348” also pay particular attention to the topic of Chinese football with a relative higher score, and so it is the winner ranking by our proposed method.
Moreover we use Kendall’s coefficient τ [16] to show the degree of difference between them. The value range of τ is from – 1 to +1. The closer the value is to +1 or – 1, the stronger is the likely correlation. Table 5 demonstrates the correlation between HybridRank and degree centrality, closeness centrality, betweenness centrality, or PageRank measure. The lists of top 5 user ranking by HybridRank algorithm have a strong correlation, while a weak correlation with Betweenness centrality. The performance shows the τ value for the best-case scenario is 0.64.
Kendall τ rank correlation coefficients
We address the problem of detecting opinion leaders in social networks, and propose a novel algorithm called HybridRank based on original PageRank method. The algorithm takes into account the multiple measurements, which combines PageRank algorithm, topic-sensitive analysis and temporal characteristics. Focusing on Chinese Sina BBS, we study the dynamics of influence across topics and temporal. Experimental analysis demonstrates that our proposed HybridRank algorithm obtains better results comparing with other related algorithms. However, as an attempt to provide new lights on the research of opinion leaders, HybridRank algorithm still has space for improvement.
As part of future work, we plan to extend our framework in three directions. First, our current experiments only applied on special networks, and we plan to valid the proposed algorithm in a larger dataset. Second, so far we only considered some information including link, topic and temporal characteristics. In many applications, some other information i.e. sentiment characteristics is also very important. We are investigating how to incorporate these information into our method. Last but not least, an incremental approach for fast computation to detect opinion leaders is still a topic deserves further study.
Footnotes
Acknowledgments
This paper is supported by the Nature Science Foundation of China (No. 61502281,71403151).