
Abstract
The current resource integration algorithm lacks the consideration of users’ needs, which can cause high violation of service-level agreement and poor data quality after integration. It affects the energy consumption and service quality of data center. To address this problem, a financial resource integration algorithm of virtual enterprise based on improved artificial bee colony in big data environment is proposed in this paper. The improved PageRank algorithm is used to extract the financial resource of virtual enterprise. The extracted resource is transformed. From the unified data resource centralization after transformation, service resources that satisfy users’ needs and constraints are selected and combined. An improved artificial bee colony algorithm is applied to dynamically integrate service resources for different needs. Experimental results show that the proposed algorithm can effectively reduce the energy consumption of the data center, improve the data quality and user service satisfaction. The advantages and feasibility of the proposed algorithm in the integration of virtual enterprise financial resources under the big data environment are verified.
Keywords
Introduction
With the rapid development of social network, mobile Internet, Internet of things and so on, data is growing at an unprecedented speed. How to manage and utilize these data resources has become a hot issue in the present research [1]. In big data environment, a large number of Internet users will use cloud services to generate a lot of virtual data. These data reflect the activities of the daily operation of the virtual enterprise, record a large number of business interaction and financial data, and form a pool of data resources with unlimited potential for development [2]. In the era of big data information, the status of data resource is as important as material resource and energy resource, and has become an important strategic resource of modern enterprises. As the key element of modern enterprise management, data resource is a new understanding and high generalization of the state of data from the point of view of resource [3]. How to integrate and reorganize massive data resources becomes the key to the successful utilization and sharing of data resources. Building a complete financial resource integration mechanism for virtual enterprise has important theoretical and practical significance to enhance the decision-making ability and overall competitiveness of enterprise [4].
For resource integration in large data environment, a virtual resource integration algorithm based on virtual cluster online migration is proposed in the literature [5]. In this algorithm, first the system is modeled, and the integration of virtualization resources under the big data environment is described. The area division method is used to classify heterogeneous resources to initially reduce the scale and difficulty of solving problems. Based on that, an FFD_grp algorithm for virtual cluster migration in isomorphic subdomain is proposed. In the literature [6], a resource integration algorithm based on phase space reconstruction is proposed. According to mutual information method and Cao method, phase delay time and embedding dimension are calculated, separately. Based on information entropy, an adaptive weighted fusion estimation method is proposed to improve the fusion of objective function. And the social cognition optimization algorithm is used to determine the weight coefficient of each information source and achieve massive data integration. In the literature [6], a resource integration algorithm based on deep learning model is proposed. In this algorithm, the feature extraction model CNNM is trained based at the sink node. Each terminal node extracts raw data features through CNNM, and sends the fused data to sink nodes. These algorithms lack consideration of users’ needs, easily cause high service level violation and poor quality of the integrated data, and affect the energy consumption and service quality of the data center.
For the above problems, a financial resource integration algorithm of virtual enterprise based on improved artificial bee colony in big data environment is proposed in this paper. The structure of the proposed algorithm is as follows.
The financial resource acquisition mechanism of virtual enterprise is divided into data resource extraction mechanism, transformation mechanism, and clustering mechanism respectively. It aims to bring together a large number of chaotic, disordered, heterogeneous financial resources of virtual enterprise, in order to orderly store financial resources in a virtual enterprise financial platform.
The relationship between financial resources of virtual enterprise is mined and analyzed. The improved artificial bee colony algorithm is proposed to dynamically integrate the financial resources of virtual enterprises to meet the dynamic needs of resource users in real-time.
Experimental results and analysis. Experiments verify the superiority and feasibility of the proposed algorithm in the financial resource integration of virtual enterprises in big data environment. The improvement of the current algorithms is also discussed.
Material and methods
Resource extraction
For the massive and noise characteristics of the virtual enterprise financial resources and its origin from different platforms, the data resource extraction mechanism of virtual enterprise is designed to provide data sources for financial resource transformation.
Assume D = {d1, …, d
n
} is the original dataset of virtual enterprise financial resources. Representation coefficient λ is the degree of mutual representation of two data in D. Whether data d
i
can represent data d
j
depends on the similarity and the given representation coefficient λ. The similarity of data d
i
and data d
j
is calculated by using
If sim (d
i
, d
j
) ≥ λ, d
i
can represent d
j
on the λ degree, denoted as rep
λ
(d
i
, d
j
) =1. If sim (d
i
, d
j
) < λ, d
i
cannot represent d
j
on the λ degree, denoted as rep
λ
(d
i
, d
j
) =0. Representation set is the dataset which can represent the data d
i
in the original dataset D under the given representation coefficient. For given d
i
and λ, representation set is
In big data environment, representative data resources extracted from virtual enterprise financial data need to reflect the vast majority of the original data set, and the content redundancy of the dataset itself is as small as possible. Original dataset and representative dataset meet the following relationship. The representative data set R covers the content of the original dataset D, and the similarity of R with D is the largest. The information redundancy in the representative dataset R is minimal, that is, the similarity between the information in the R is small enough. The extraction process of representative data resources is described as
In finding the optimal representative dataset of virtual enterprise financial resources under the big data environment, the global optimal solution is needed to be obtained. The traditional greedy algorithm [8] cannot consider the overall optimization, which is for the local optimal solution, and the result is not good. In this paper, a heuristic algorithm based on PageRank algorithm [9] is proposed to find representative dataset. The idea of this algorithm is as follows.
An initial weight is assigned to each node, that is, PageRank value. The PageRank value of the node is denoted as P (i). Assume there is a directed edge from the node v
i
to v
j
, which is considered that the node v
i
cast a vote for the node v
j
. C (i) represents the number of directed edges from the node i, then the contribution of the node v
i
to the node v
j
is P (i)/C (i). In each round, the data in the original dataset D votes for all the representative sets corresponding to the data and the highest number of votes is added to the representative data set R. The steps of representative information extraction based on PageRank are as follows.
Calculating representation set. According to the original dataset D = {d1, …, d
n
}, the similarity matrix M is calculated. Then with the representation coefficient λ, the similarity larger than and equal to λ in M is set to 1 and that smaller than λ is set to 0 to obtain the similarity matrix M
λ
. The representation set Counting the votes of the representative set. Define the initial PageRank of each data d in D is 1. If d
j
is in
The above method is less effective in calculating the processing speed and energy efficiency for the case of a large number of representation sets. To address this problem, the MapReduce model is introduced to improve the speed of the algorithm. Redundancy optimization. According to the votes of each representation set, the best votes of representation sets in Remove the d
j
added into R and its representation data to obtain the new dataset D and the representation set
The virtual enterprise financial resource transformation refers to the unification of the original heterogeneous data the process of data transformation. The financial resources of virtual enterprises are distributed in different storage centers, and the storage types and formats of each central data are different. In order to achieve data interaction and sharing, the financial resource format of virtual enterprise is unified. By using the ontology description language RDF, a data transformation mechanism for virtual enterprise financial resources is constructed [10]. Then users are provided with a transparent and unified resource service pool. The transformation of virtual enterprise financial resources is described as the following relationship.
The data transformation and mapping technology [11] is used to build data sources of financial members of virtual enterprises. From the local model to the mapping rule library of the global model, the data aggregation of financial members in virtual enterprises is realized. It is convenient for management while providing users with unified data interface services.
The above process is mainly aimed at the collection and transformation of virtual enterprise financial resources under the big data environment, which is the first problem to solve the integration of virtual enterprise financial resources. The next research content is to classify and combine the financial resources of various virtual enterprises gathered in the network platform to achieve the integration of financial resources for virtual enterprises.
The similarity matrix W is constructed with the similarity equation, and then the construction matrix L is obtained. The eigenvectors corresponding to the largest κ eigenvalues of the construction matrix L are selected and normalized. In the κ-dimensional space, it forms the expression corresponding to the original data, and achieves the purpose of column dimension reduction.
Construct the similarity matrix W. The calculation of similarity is given by
The construction matrix L = D-1/2WD-1/2, where D is the diagonal matrix, given by
Select eigenvectors corresponding to the first κ maximum eigenvalues x1, …, xn′ to construct the matrix X = [X1, …, Xn′] ∈ Rn′×κ. Normalize the line vector of the matrix X to obtain
The fuzzy clustering algorithm [12] needs to specify the number of clusters in advance, and it cannot automatically determine the number of clusters based on the data itself. In the fuzzy clustering, the base of clustering fuzzy membership is introduced, and the optimal number of clusters is determined through deleting and combining the cluster centers by membership base. The fuzzy membership base is given by
Parameter initialization. Initial the cluster number C is the maximum cluster number Cmax, ɛ is the iteration threshold, ɛ1 is the clustering fuzzy membership base threshold. Initial fuzzy membership matrix U0 and the cluster center V0, t = 0 is the number of iterations. Calculate the clustering fuzzy membership base N
ι
. If N
ι
< ɛ1, delete this cluster v
ι
(ι = 1, 2, …, C) and update the clusternumber C. If C < Cmax, Cmax = C.
According to the fuzzy threshold of clustering fuzzy membership, the cluster is deleted and clustering number is decreased. When reaching the iterative threshold, it indicates that the number of optimal clusters has been found, and the number of clusters is automatically determined, so as to prepare for fast automatic clustering. When the iterative threshold is reached, it indicates that the optimal number of clusters has been found, and the number of clusters is automatically determined.
In fuzzy clustering algorithm, the weighted index m′ has great influence on the process and result of clustering. The larger the value of m′, the smaller the objective function value and the lower the noise. However, the larger the value of m′, The more fuzzy the clustering results. It usually takes many experiments or experiences to obtain m′. m′ is added to particle encoding. By giving a certain speed change, it can follow the particle swarm evolution [13] to find the right value.
Assume in the D′-dimensional search space, there is a population with w particles. A function corresponding to each big data information feature vector X
ι
is expressed as.
Set the threshold N
th
. When N
eff
< N
th
, the probability of the movement of the ηth particle is xk′+1 = sin(a/xk′), -1 ≤ xk′ ≤ 1, where xk′ is the k′th dynamic inertia weight, a is the control parameter of cluster center. Probability density function of optimal clustering solution is
The particle swarm optimization algorithm is prone to premature and slow convergence. The chaos mapping method is used to optimize the particle swarm optimization, to lead the particle to escape the local optimal solution and to accelerate the convergence. In the chaos method, first a chaotic sequence is generated with Logistic mapping, which is expressed as
In order to improve the convergence speed and global optimization ability of particle swarm, the generated chaotic sequence is used to disturb the global optimal particle. For the above w particles, each dimension is mapped to the range (0, 1) to obtain D = (d1, …, d
w
), where d
φ
is the φth dimension of the particle, expressed as
The chaos perturbation [15–17] is used to do iterative computation and obtain new sequence Z1 = (Z11, …, Z1w). The obtained new sequence Z1 is taken as new particle and its fitness is calculated. If the fitness of Z1 is higher than the optimal solution obtained by previous search, Z1 is taken as the current optimal solution.
Assume there are
Service confidence C is expressed as
Service upgrading of resource provider is given by
After the static integration, the data resource service system can provide many service packages to the customers, but the system needs to dynamically analyze and process the customer’s request for service resources when the existing system cannot meet the demand. This dynamic process of integration service resource is called resource dynamic integration process. In the process of dynamic integration, when service resource is provided, data resource provider must meet the hard constraints of service demander. For soft constraints, if there is no fully matched service resource, it can be recommended to the highest matching resource service. The constraints of enterprise service resources are as follows.
The price reflects the quality of service to a certain extent. The price of personal service demand is the detailed restriction of service demander to data resource service or service resource. In the demand of group data resource service, the price constraint reflects the interests and requirements of the whole enterprise financial data resource service demand group. There is a functional relationship between the deviation of price constraint and the satisfaction of customers’ satisfaction. The relationship between lowest price and customer satisfaction is approximately consistent with exponential function, given by
Financial data resource service demand requests for service resource include service time constraint and service quantity constraint. Service time constraint refers to the how much service time of the service provider satisfying the required service time of the customer. The satisfaction of service demand time constraint with service demand is calculated by using
Service quantity constraint refers to the number of service resources allocated by the service meet the demand of the users, which is given by Eq. (22). The ratio is larger than 1, the satisfaction of service number constraint is 1.
The constraint of service provider’s quality of service and credibility of service institution refer to the quality rating of service providers’ service quality and credibility rating. The calculation is given by
In the financial data resource service, the constraints of the service mode, service domain, resource category, resource subcategory, service resource provider, and service nature are hard constraints. The constraint satisfaction is calculated by using
In the process of selection and combination of service resources, how can we not only satisfy the service needs of resource demander, but also make the overall utilization rate of service resources reach the highest? For this problem, an improved artificial bee colony based virtual enterprise financial resource dynamic integration algorithm is proposed to dynamically achieve the integration of different needs.
After similarity calculation, similar service needs are merged. Assume service demand set is SD = {d1, ⋯, d cn }, where d ξ (ξ = 1, 2, …, cn) is the demand of the ξth service demander.
Assume there are
Satisfaction of the service provider to resources is calculated by using
According to the service property of virtual enterprise financial resource, resources are divided into continuous service resource and intermittent service resource. For different types of financial data resources, resource utilization rate is given by
Static service resource integration is the optimal financial service resource solution to meet specific service needs. Based on the static integration process of service resources, according to the priori nature of financial services, these service resource combinations may soon be reused. Priori scheme set of financial data resource service is defined as
In the financial data resource service system, the service resources with more customer requests and higher service quality are integrated into the prior set of virtual financial service resources, which is defined as
According to the similarity between service resources, the category of service resources can be continued to narrow on the basis of subclass resources. The definition is given by
A dynamic integration algorithm based on artificial bee colony is proposed to solve the problem of dynamic selection, combination and rapid establishment of service supply and demand relationship of financial data resources during serviceprocess.
The solution of combined service resources is to provide services for the complex resources of the service provider in real-time after the service demand requested by the service demander. According to the resource constraint of financial service demand, the subclass service resource is determined. The food source in artificial bee colony algorithm is introduced. The encoding mode is given by
When initializing combined service resource solution, the first part is generated in a priori solution of financial data resource service. The second part initializes the solution in a priori concentration. The third part is from the initialization of similar centralization of financial data resources. The fourth part is from the centralized generation of general service resources. Assume the size of the initial combined financial data resources is SN, the proportions of the first, second, third and fourth parts of the initial solution are α′, β′, χ′, δ′ (α′ + β′ + χ′ + δ′ = 1). The initialization steps of the combined financial data resource solution are asfollows.
Calculate the priori value VPS and user satisfaction SVPS of the prior financial data resource service scheme in PSS. According to the size of the service priori value, VPS is sorted in descending order. Select the priori service scheme with SVPS ≥ TSV, TSV is the user satisfaction threshold. Repeat the step (3) until obtain α′ × SN combined service resources. Random select a subclass resource s∂ in the priori set PS. A candidate service resource is randomly selected from the service resource set until the candidate service resources of all subclass resources are traversed to select. Until obtain α′ × SN combined service resources. A candidate service resource in each subclass resource s∂ is randomly selected from the financial service resource similarity set SimS until the candidate service resources of all subclass resources are traversed to select. Repeat the step (7) until obtain χ × SN combined service resources. A subclass resource is randomly selected from the general set GenS of financial data service resource s∂, and a candidate service resource is selected randomly from the candidate service resource set until the candidate service resources of all subclass resources are traversed to select. Repeat the step (7) until obtain δ′ × SN combined service resources.
Artificial bee colony algorithm is based on the best fitness of food source to evaluate the quality of food source. The selection of fitness function directly affects the convergence speed of artificial bee colony algorithm and the ability to find the optimal solution. According to the characteristics of financial data service resource composition problem, the fitness function of the combined financial data service resource solution is designed. A combined financial data service resource solution is expressed as X
τ
= {sl1, …, s
lη
}, where s
l
is the ηth candidate service resource of the τth subclass service resource in the food resource X
τ
, then the fitness function of the combined service resource solution X
τ
= {sl1, …, s
lη
} is given by
There is a certain partial sequence relationship between financial data services. Based on the knowledge of this domain, a dynamic adaptive neighborhood search strategy with direction for the priori scheme set of financial data resources service, the priori set of service resource, and resource similarity set is proposed. The search process first determines the direction of search and the search step, then searches and generates new food sources in theneighborhood.
In the experiment, four original enterprise information data is used with the types of My sql, Xml, Txt, and Excel. My SQL data is from application platform, and other data sources are from manual collection and network collection. All data in these 4 data sources are integrated by the above mode. The configuration of the integration environment is: CPU Intel(R) Core(TM)3 i3 M370 2.40 GHz, 2GB memory, and 500 GB hard disk. The performance comparison of energy consumption, service-level protocol violation rate, and service customer satisfaction between resource integration algorithm based on improved artificial bee colony, resource integration algorithm based on phase space reconstruction, resource integration algorithm based on depth learning model, and resource integration algorithm based on virtual cluster online migration are carried out.
For the requirements of low energy consumption and high service quality by virtual enterprise financial resource data center, comprehensive evaluation index of service quality and energy consumption ESV is set, which is given by
The lower the value of ESV, the less energy consumption and high service quality of resource integration.
Figures 1 and 2 show the comparison results of energy consumption and service-level protocol violation rate between different algorithms, respectively.

Comparison of energy consumption between different algorithms.
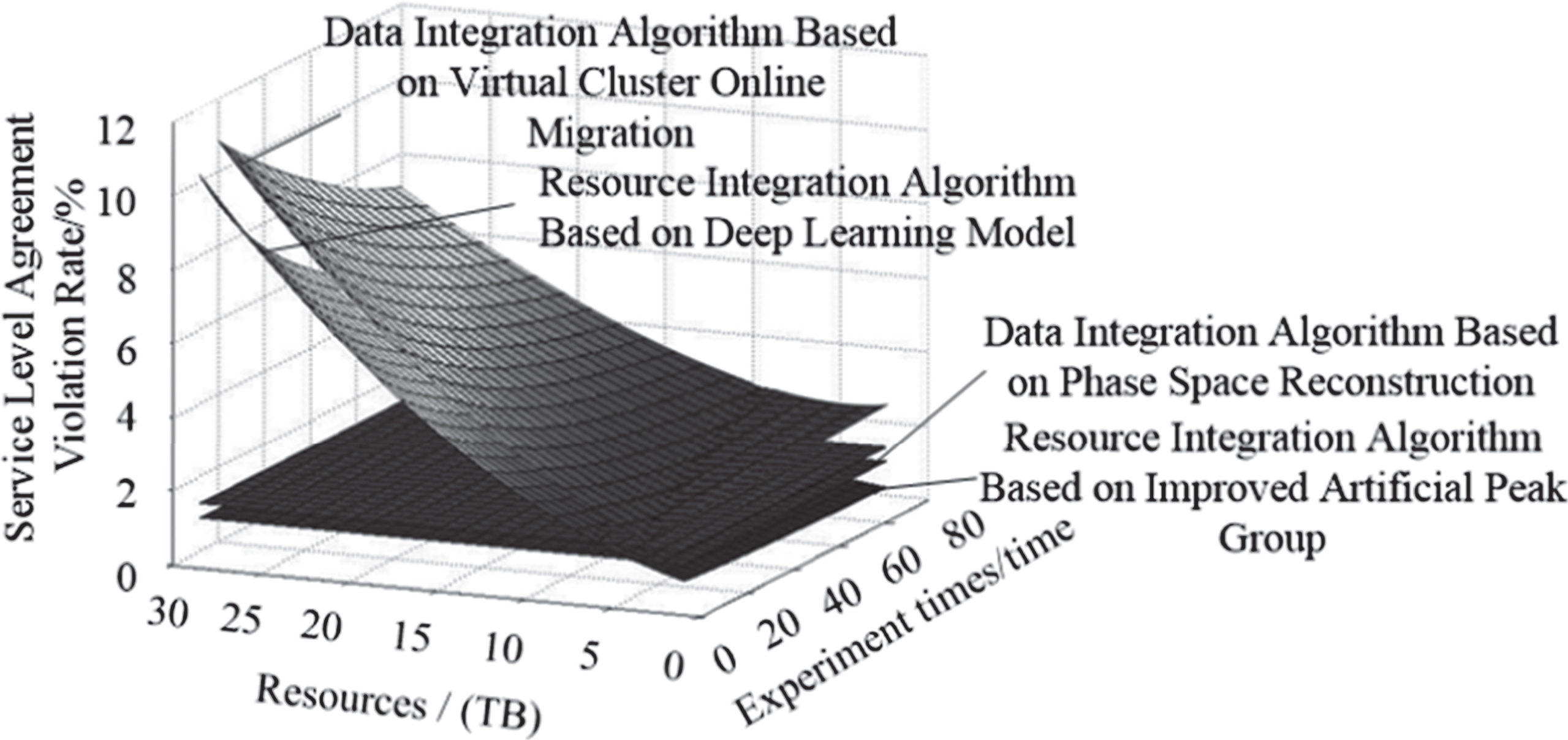
Comparison of service-level protocol violation rate between different algorithms.
From Fig. 1, it can be seen that, with the increase of data volume, the energy consumption of the 4 algorithms is changing little. The energy consumption and the service-level protocol violation rate of the proposed algorithm are always lower than those of the other 3 algorithms. From Fig. 2, it can be seen that, when the amount of financial data of virtual enterprise is 25TB, the resource integration algorithm based on virtual cluster online migration achieves the maximum service-level protocol violation rate. This algorithm transfers the virtual cluster in the isomorphic subdomain without taking into account the customer needs. The optimality of the resource integration result depends entirely on the migration quality of the virtual cluster, which makes the service protocol violation rate higher. For the resource integration algorithm based on phase space reconstruction, the integration of objective demand is continuously improved in the process of resource integration. Therefore, service protocol violation rate is lower than the resource integration algorithm based on deep learning model and integration algorithm based on virtual cluster online migration, but higher than the proposed algorithm.
Figure 3 shows the comparison results of service customer satisfaction between the proposed algorithm, resource integration algorithm based on phase space reconstruction, resource integration algorithm based on depth learning model, and resource integration algorithm based on virtual cluster online migration within the same time. The satisfaction is quantized as a constant C and the optimal satisfaction is 1. From Fig. 3, it can be seen that, with the scale of resources increases, the optimality of the 4 resource integration algorithms reaches a peak value and then decreases. In the resource integration algorithm based on depth learning model and resource integration algorithm based on virtual cluster online migration, the user demand is not considered. The optimality of the results depends entirely on the quality of the resources. In the proposed algorithm, the extracted resources are extracted and the service resources that satisfy the requirements of the user service requirements are selected and combined from the unified data resource after the transformation. It takes into account the service requirements of the different needs and make the corresponding customer satisfaction higher.

Comparison of the service customer satisfaction between different algorithms within the same time.
Data matching method is used to verify the improvement of data quality in the process of virtual enterprise financial resources integration. The integrated data obtained after experiment is verified by manual experiments, and the real financial resources of enterprises are obtained as an accurate contrast data. The experimental data is compared with the accurate data.
Comparing the original data, the integrated target data, and the real data, the accuracy is obtained. The following simple equations are used to estimate the accuracy of data. The first is to calculate the similarity of each attribute. The second is to calculate the weighted similarity of data in the dataset, which id the accuracy of the dataset.
Set the accurate of real data is 100%. Comparison between the original dataset and the integrated data is carried out to obtain the data accuracy. The results are shown in Table 1.
Comparison of data accuracy before and after integration
From Table 1, it can be seen that, after integration, the accuracy of the virtual enterprise financial data set increased by 17%, 32.85%, 28.11% and 41.89%, with an average increase of 29.96%. Compared with the original data, the quality of the original data is obviously improved. After the extraction, transformation and classification of enterprise financial resources, the quality of the original data is improved automatically, and it can provide data services for the enterprise platform more effectively.
In this paper, the current research status of big data environment and virtual enterprise financial resources integration is summarized. The financial resources integration mechanism of virtual enterprise is designed. Finally, taking a company’s financial data as an example, the proposed virtual enterprise financial resource integration mechanism is verified.
Innovative research results are as follows. The data integration mechanism of virtual enterprise financial resource extraction, transformation, and combination is revealed; The integration technology of virtual enterprise financial resource is researched. In order to better serve the financial service demander, the virtual enterprise financial resource integration is realized. It includes static integration of enterprise financial resources and dynamic integration of real-time response. Association rule mining algorithm and artificial bee colony algorithm are applied to the integration process of enterprise financial resources, which effectively improves customer satisfaction and resource utilization.
In the big data environment, the virtual enterprise financial resource integration algorithm needs to be constantly refined and perfected. We need to consider the extraction of real-time dynamic data resources, and design a better financial resource extraction mechanism. The effective combination of data resources under the condition of limited financial resources of virtual enterprise needs further research.