
Abstract
Smartphone has been used for recognizing the different motion activities. However, current studies focus on either improving algorithm factor or adjusting neural network structure factor rather than on time cost factor and actual application factor. A novel method to consider these four factors comprehensively enhancing recognition of motion state accuracy is proposed. An architecture of the Bi-LSTM neural network and the TensorFlow machine learning system are used to classify the motion state and evaluate its experimental results. In addition, the Bi-LSTM neural network is compared with other neural network structures. Meanwhile, using the data captured by the accelerometer sensor and gyroscope sensor of the smartphone tests the Bi-LSTM neural network model. Experimental results show that using Bi-LSTM neural network and TensorFlow machine learning system to extract motion state characteristics, this method makes the motion state identification achieve 86.7% accuracy and the Bi-LSTM neural network model is better than other neural network models considering above four factors. The model of Bi-LSTM neural network can be used for other time-series fields such as signal recognition, action analysis, etc. This study provides a new method, which considers the four factors, to enhance the accuracy of the motion state classification.
Introduction
Motion state recognition is an important research fields that have been used or have the potential to make use of a wide range of applications, including human activity recognition, traffic state recognition, military training, location-based services, health condition monitoring, animal’s behaviors learning, weather service, and mobile networks service [1, 2]. To obtain the data onto motion state, a set of dedicated sensors are used. Nevertheless, these special sensors are expensive, and have to be assembled in a circuit board; the entire data acquisition process is complicated. In order to deal with this problem, the smartphone is included as the device with many sensors to take the place of these dedicated sensors.
Due to the development of mobile computing, especially the rapid increase of the smartphones. Smartphone has been our portable office equipment and become a super assistant for us that can deal with amount of things, which can be defined as a microcomputer. And as a portable and smart device, there are not only many traditional sensors embedded in smartphone such as GPS module, wireless module and Bluetooth module also some latest micro-sensors like Light, Magnetometer, Pressure, Acceleration and Gyroscope module included. Owing to the popularity of smartphone, tons of data that can be dug out potentially and significant information is obtained from these sensors. So the smartphone can be used to collect the data of motion state.
Artificial intelligence (AI) has been slow to develop for a long time in the past, but the past two years with the development of the Internet, based on three main ingredients for AI have been in place: big data, software-hardware advances and cloud business models, the ingredients play a great role in promoting the development of AI. Owing to the development of AI, there are many deep learning architectures like Caffe, Theano, Thorch and TensorFlow. TensorFlow is Google’s second-generation artificial intelligence learning system based on DistBelief, which is derived from its own operating principles [3]. Due to Google designs TensorFlow, the neural network model could be transplanted to Android smartphone easily, which provides JAVA interface, and there are many kinds of neural network models, which are built by deep learning techniques, such as auto-encoder, restricted Boltzmann machine, deep belief networks, convolutional neural networks (CNN) and recurrent neural networks (RNN).
Motion recognition has been a research field since 1990s [4]. However, most studies have to face the key issues: recognition accuracy, time cost and actual application. So many studies have to propose new methods and improve existed algorithms to resolve the critical issues. Gjoreski [5] applied machine learning skills to extract features for motion state identification and collected the data from different parts of the body, subsequently, that compared several machine learning algorithms such as Decision Tree (J48), Random Forest, Naive Bayes, Support Vector Machines, and K-Nearest. Nevertheless, the latter and another work by Guiry [6] compared a series of motion recognition algorithms, including various classifiers, to recognize activities. Trabelsi [7] made use of an unsupervised approach to identify activity state with three accelerometer sensors, and placed sensors at the breast, thigh, and ankle.
Zeng [8] proposed an approach to extract automatically state features for activity recognition, and this approach based on CNN which captured local dependency and scale invariance of a signal as it has been shown in speech recognition and image recognition domains. Jiang [9] proposed a new method which transformed time series signal of accelerometer sensor and gyroscope sensor into an activity image, and adopted deep convolutional neural networks (DCNN) to capture main features from the activity image. Most studies have utilized CNN, and the accuracy of CNN is little higher than other neural network models on motion state recognition. However, CNN model is not suit for being transplanted to Android smartphone, due to CNN needs a large number of computing resources, but general smartphone does not have the ability to offer a many computing resources, which results in considering other neural network model instead.
Lefebvre [10] gave a new way for micro-electromechanical systems (MEM) gestures recognition, and built a system based on bidirectional long short term memory (Bi-LSTM) neural network to extract features for gesture classification, nevertheless, a shallow Bi-LSTM gave to explore long-range temporal dependencies. Zhu [11] employed an end-to-end fully connected deep long short term memory (LSTM) neural network to perform automatic feature learning and motion modeling, in which LSTM could learn feature representations and model long-term temporal dependencies automatically. Hammerla [12] explored deep, convolutional, and recurrent approaches across three representative datasets that were captured by wearable sensors and exploited the temporal dependencies within the movement data. Zhu [13] proposed a novel method that utilized to collect activities data and GPS information, and then constructed two different neural networks to extract features and classify activities.
Yang [14] used Bi-LSTM neural networks and mean-pooling to extract features, and that is a good method, but the data were collected by sensors which is very hard because every action needs to collect 15 parts data of body in a time, especially the collection method is hard used for big data collection.
Singh [15] adopted deep learning techniques that extract features and recognize activities using any prior knowledge and LSTM neural networks, and monitor human activities of smart house, however, it didn’t refer to a detail of activities and also refer to the structure of LSTM neural networks.
Song [16] proposed an end-to-end spatial and temporal attention model for human action recognition using skeleton data, however, the data also were very hard to collect without Kinect.
According to literatures above, it is a trend for the deep learning techniques to become the dominant tool for motion state recognition. However, it is obvious that most of these researches focus on either the improving algorithm or adjusting neural network structure rather than on time cost and real-world application. Based on the above analysis, this study proposes the use of Bi-LSTM neural network, which is a kind of Recurrent Neural Network (RNN) on time-series, raw sensor data from the acceleration and the gyroscope, and extracts data characteristics and relevant information. Furthermore, owing to deep learning techniques that can automatically learn the features from a particular dataset which includes training set and test set [17], the TensorFlow system is used to construct the model, train and test neural network architecture. In the meantime, the model is transplanted to Android smartphone to validate the model, and the process optimizes model structure and collects more information, which could improve the accuracy of experimental results. Meanwhile, this work examines some core problems in selecting neural network structure and deep learning techniques (including optimization algorithm). Subsequently, time cost (spending time on building the neural network model) and real-world application (applying the neural network model to resolve real-world problems) are also considered.
Methods
Motion state has similar characteristics where different people do the same behavior in diverse ways, and a kind of activities can show different points in time [18]. When making use of sensor signals to discriminate motion state, it is vital to consider the temporal dependence of nearby reading. LSTM neural network researches the data properties that compute a mixture of nearby sensor readings. Discriminating motion state can be deemed to a classification, where the input data set is time series signals and the output set is motion state label. Figure 1 shows the motion state recognition process, consisting of training phase and test phase. The features are extracted from time series sequences data set and then utilized to train a perfect classification model until the stopping criteria are achieved during the training phase. In the test phase, features are extracted from test set and the trained classification model is used to predict a motion state label.

Training and validation procedures.
Various neural network structures can classify the motion state. Based on this point, the accuracy and cost time are judged as standards for every neural network structure. In this study, four neural network models are analyzed and compared such as classical neural network, LSTM, Bi-LSTM and CNN to validate why Bi-LSTM is thebetter one.
Classical neural network is feedforward neural network. This means the information is always fed forward, never fed back. Figure 2 shows the network architecture. The output is defined as Equation (1).
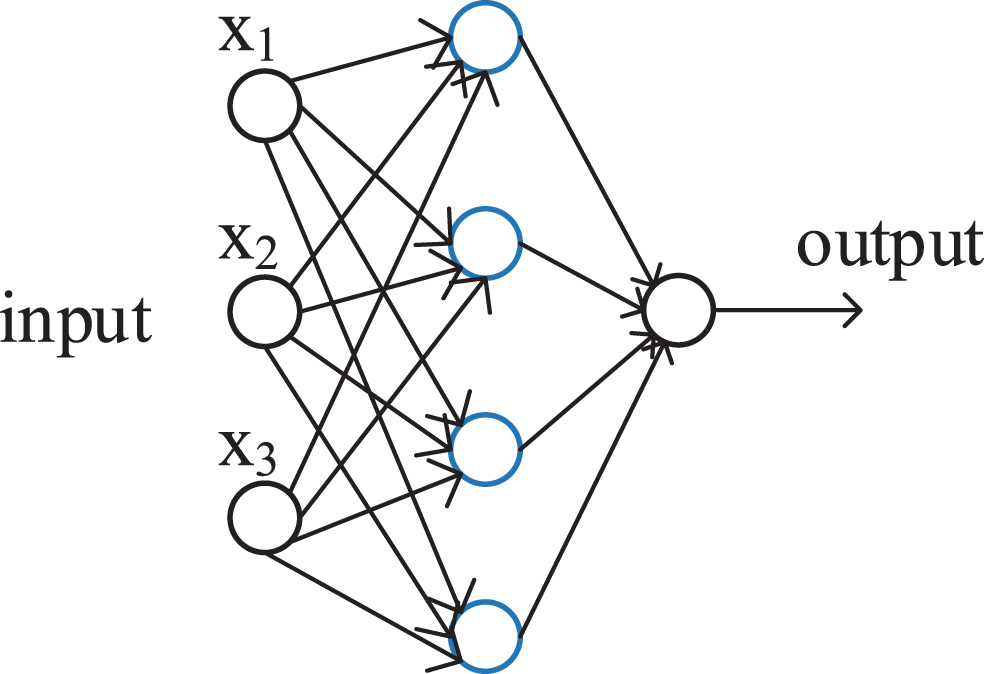
Basic classical neural network architecture.
where x i is ith sensor data input data, w i is the weight for the ith sensor data input vector, σ is the activation function, b is the bias term for the ith sensor data input vector. However, owing to time-series data is not only relevant to its previous information but relevant to its next information; this neural network structure is not suit for dealing with the time-series data.
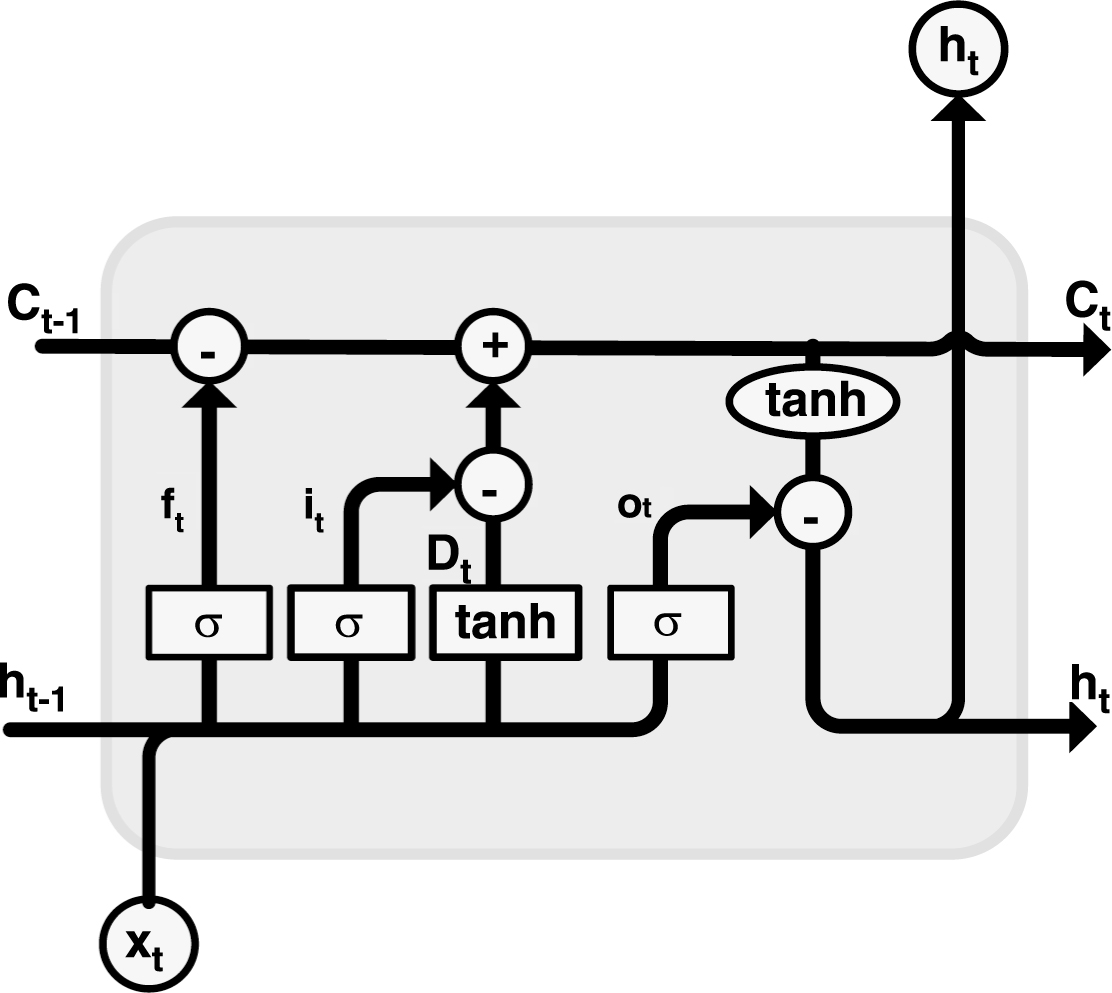
It is known that RNN cannot record the information where an input message is too spaced apart. Therefore, the long-term dependencies are a fatal injury to the traditional RNN. Then the LSTM, which is a variant of RNN, is proposed by Schmidhuber in 1997 [19]. The LSTM is designed for the long-term dependencies. It does not need to adjust the complex hyper-parameters and the long-term information is remembered by default. The structure of LSTM is shown in Fig. 3.
LSTM neural network unit architecture.
LSTM network has this chain like structure, but the repeating module has a different structure that compares with standard RNN in Fig. 3. The update of an LSTM layer is defined as Equations (2–6).
where i, f, o and C are the input gate, forget gate, output gate and cell state, h is hidden value, σ is the activation function, w is weight matrix, and b is the bias term.
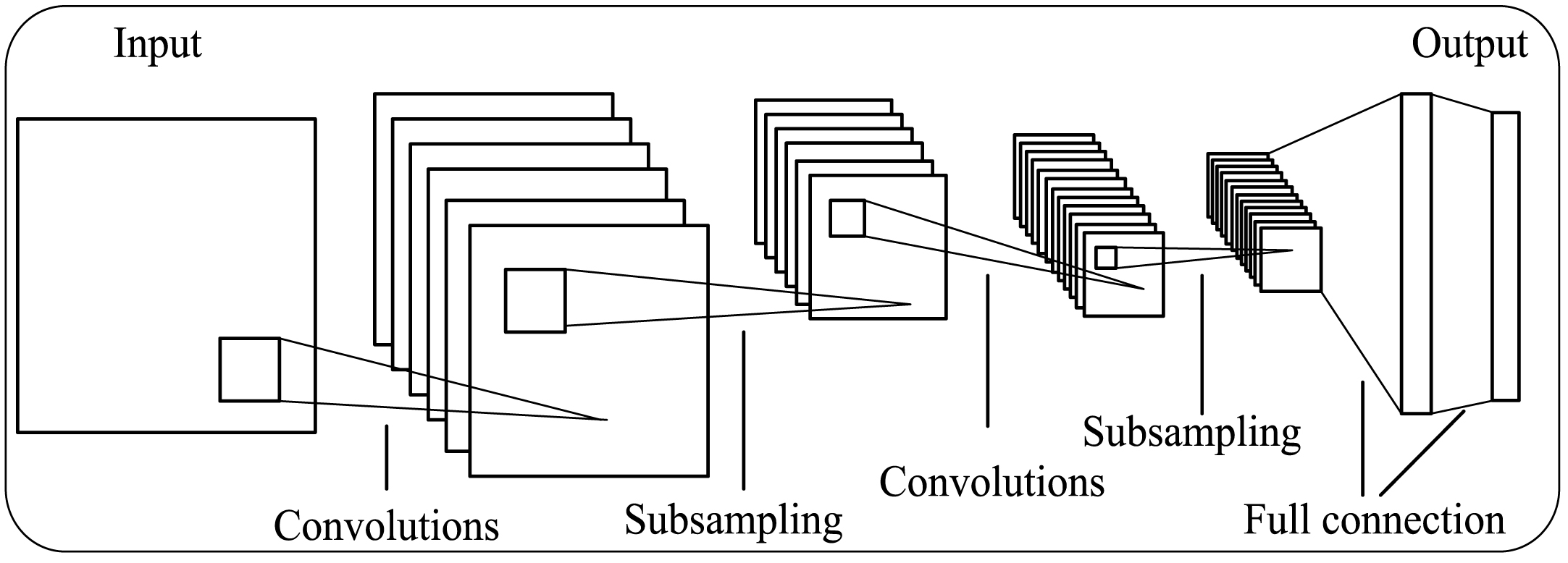
CNN has been a hot neural network model. It can extra more features and get higher accuracy. Meanwhile, due to involving amount of matrix operations, it means computer possesses the power to compute at high speed. Figure 4 shows the CNN architecture. The computation process of CNN is defined as Equations (7) and (8). Equation (7) expresses convolution process and Equation (8) shows the pooling process.
The architecture of CNN.
where w i is shared weight for ith layer, b is shared bias for ith layer, σ is the activation function, and max() is a function that can determine the maximum value in c i vector. However, in most cases, although the general computer can deal with the complex computation, the speed of computation is much lower for the experiment. When a parameter is adjusted, it means the training process can start with a clean slate and the training process spends lots of time, which is not the most effective for application. Moreover, it is difficult to design CNN structure, especially, where the location of convolutional layer and pooling layer are hard to arrange.
Bidirectional RNN (Bidirectional Recurrent Neural Networks) is also a variant of RNN, which is proposed by Schuster and Paliwal in 1997 [20], and in the same year, LSTM is proposed as well. In the classical RNN, the transmission of state is one-way, transmits from front to back, which limits the direction of propagation. However, in this study, the output of the current moment is not only related to the previous state, but also the state after it. So the bidirectional RNN is necessitated to deal with this condition. One of primary purpose of the Bi-RNN is to increase its available information. The implementation principle of Bi-RNN is very simple. The structure of Bi-RNN is illustrated in Fig. 5. Bi-RNN has the two directions which have no intersection, but output is coming from their common synthesis, so the contribution to the current time node’s output is calculated in the training phase, and parameters will be optimized according to the gradient to the appropriate value. The computation process of Bi-LSTM is defined as Equations (9), (10) and (11).
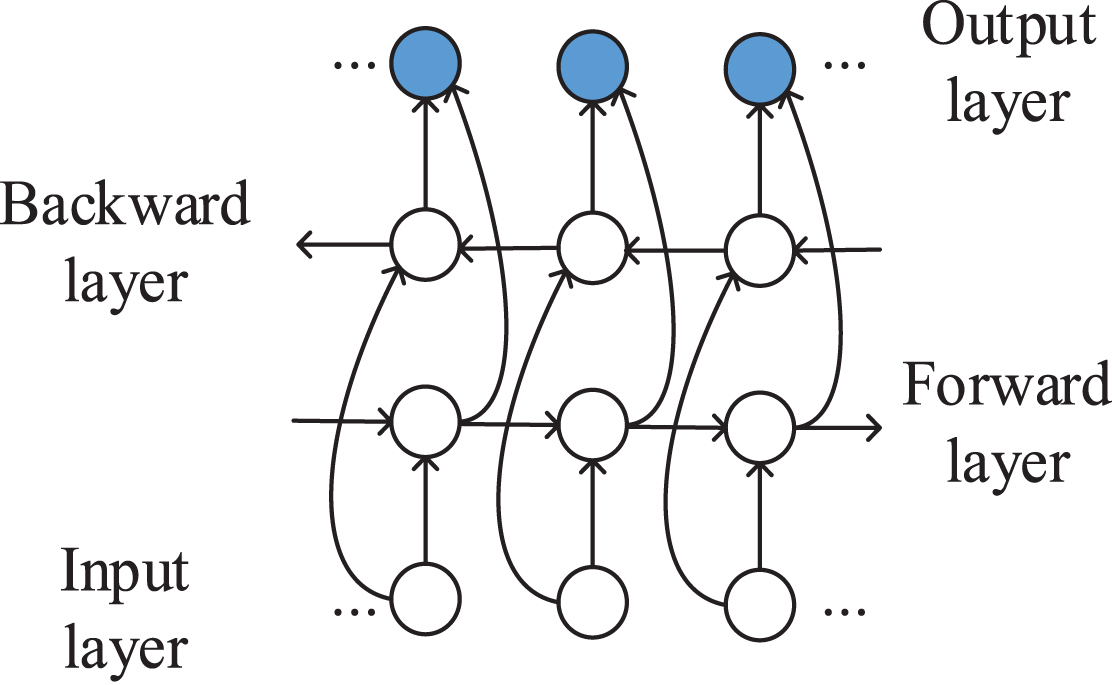
The structure of Bi-RNN.
where W is weight matrix, b is the bias term, and h is hidden value. The final classification result, output t , is generated through combining the score results produced by both RNN hidden layers. Equations (9) and (10) show the mathematical formulation behind building the Bi-RNN hidden layer. The difference between these two relationships is in the direction of recurring through the data.
The classical neural network, convolutional neural network, LSMT and Bi-LSTM are used for this study. However, the final results are not the outputs of the neural network, and the next step is classifier. A softmax classifier is used to classify activities, which is placed at the top of the neural network. The result is a probability value. The probability is defined as (12).
where c is a class label, x are all features of sample, y is label variable, K is the number of classes, o t is same value of neural network outputs.
The experiments used the HAR smartphone dataset from the UCI repository [21]. The dataset contains accelerometer sensor data and gyroscope sensor data which produces from 30 persons performing six different activities, consisting of walking (WK), walking upstairs (WU), walking downstairs (WD), sitting (ST), standing (SD) and laying (LY). There are 21 subjects that are used for training phase to learning features, and the others are used for testing. The amount of train set is 7352*128*6, and the test set is 2947*128*6.
To increase the accuracy of Bi-LSTM networks classification, different hyper-parameters were set. In this experiment, two layers of Bi-LSTM neural network were used. Figure 6 shows the structure of experimental Bi-LSTM neural network. The accelerometer and gyroscope data that performs 3-channel (3-axes) for each were used in this experiment. Moreover, the size of input vector was in line with the accelerometer and gyroscope data that contained 6*128 data in a line.
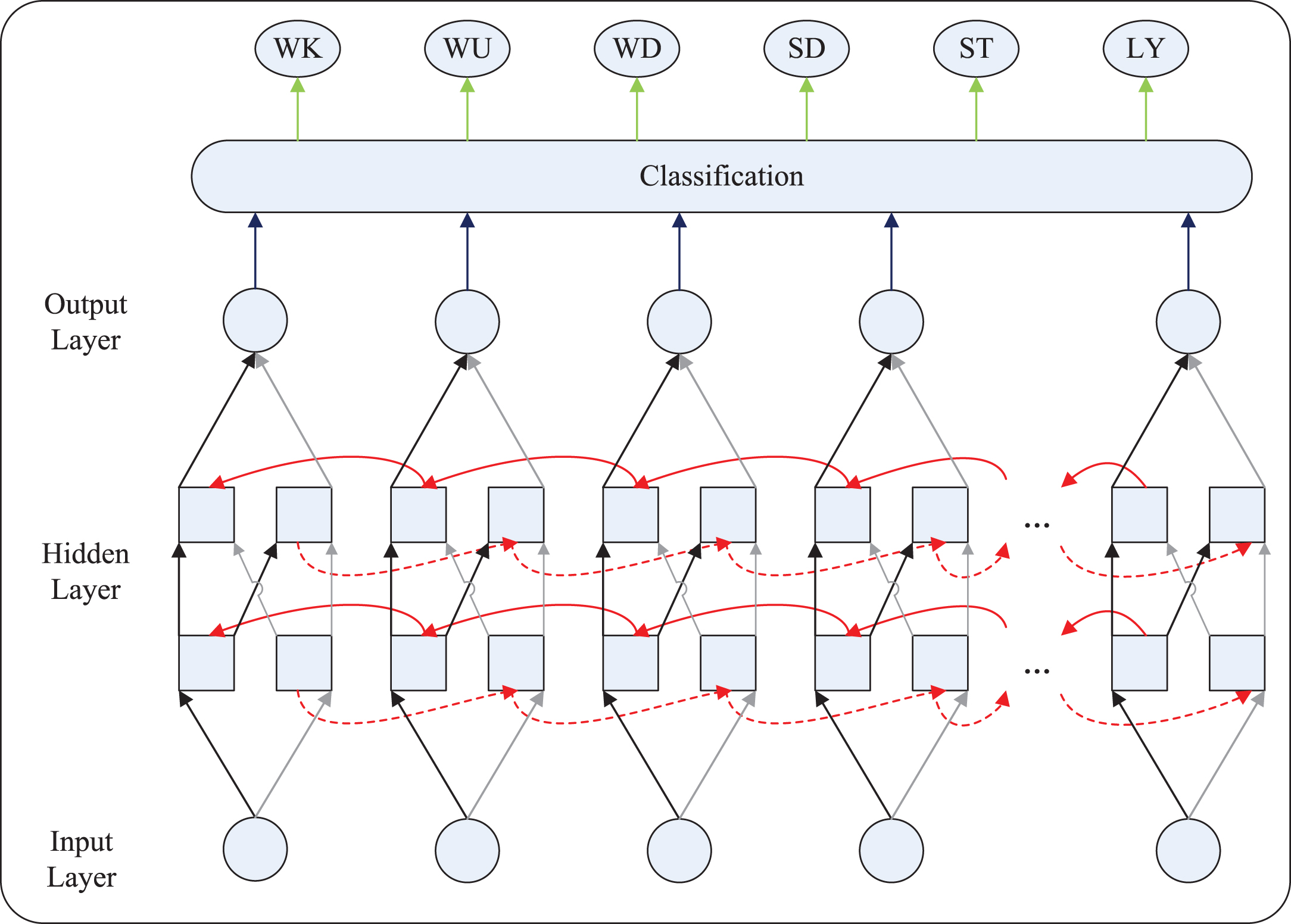
The structure of Bi-RNN.
The experimental configuration is shown in Table 1. The size of batch expresses the size of data for every run. The LRB (Learning rate base) expressed basic learning rate and is set from 0.5 to 0.005. The LRD (Learning rate decay) expresses the decay rate. To get a better solution and adjust the learning rate, the high learning rate is used in the beginning. Then the DLR (Decayed learning rate) is defined as Equation (13).
Experiment configuration
where DLR is the learning rate that is used in each round of optimization, decaySteps is the speed of decay rate and globalStep is the global stepscounter.
The moving mean model is put to use making the model more robust. The MAD (Moving average decay) which is a kind of decay determined the Bi-LSTM neural network model updating speed. When the value of the MAD is greater, where the reasonable values for decay is close to 1.0, the network model updated faster. It was through the experiment that this study attained that the training epochs should be set for from 1000 to 1400, which could be as a stopping criterion of halting training, where the loss of network model trended to be steady. In this experiment, these hyper-parameters are used to train the model, adjust different parameters until the model that reaches the stable accuracy score on the test set is saved.
The part of experiment results is shown in Table 2. In order to estimate the influence of each hyper-parameter across all experiments, the process was recorded. It derived that the accuracy of experiment results was very sensitive to the hyper-parameters. For example, when LRE was 0.03, altering the value of RE, the accuracy became low. Therefore, a suitable value of parameter that meant trial and error is inevitable until the preferable results came up. Meanwhile, it determined that there were three main factors affected the accuracy of the experimental results. The first was learning rate that decided the speed of learning process. The second was regularization that could avoid overfitting and overtraining. Moreover, the last was structure that was affected by hyper-parameters.
Parts of experiment results
The accuracy of experiment is shown in Fig. 7. The blue curve expresses the accuracy of the training data. And the other one shows the accuracy of the test phase. In most cases, the accuracy of the training phase is little higher than test date, which can improve the generalization ability of the model. Moreover, the red curve converges quickly, and the results are relatively stable, which it turned out that the proposed model is robust and stable. For the sake of better evaluating the experimental results, the confusion matrix was utilized to illustrate the results, as seen in Fig. 8. Simultaneously, it is known that the accuracy of classification is important for evaluate the classifier ability. So this paper used precision, recall and F Score to evaluate the accuracy, and they are defined as Equations (14–16).
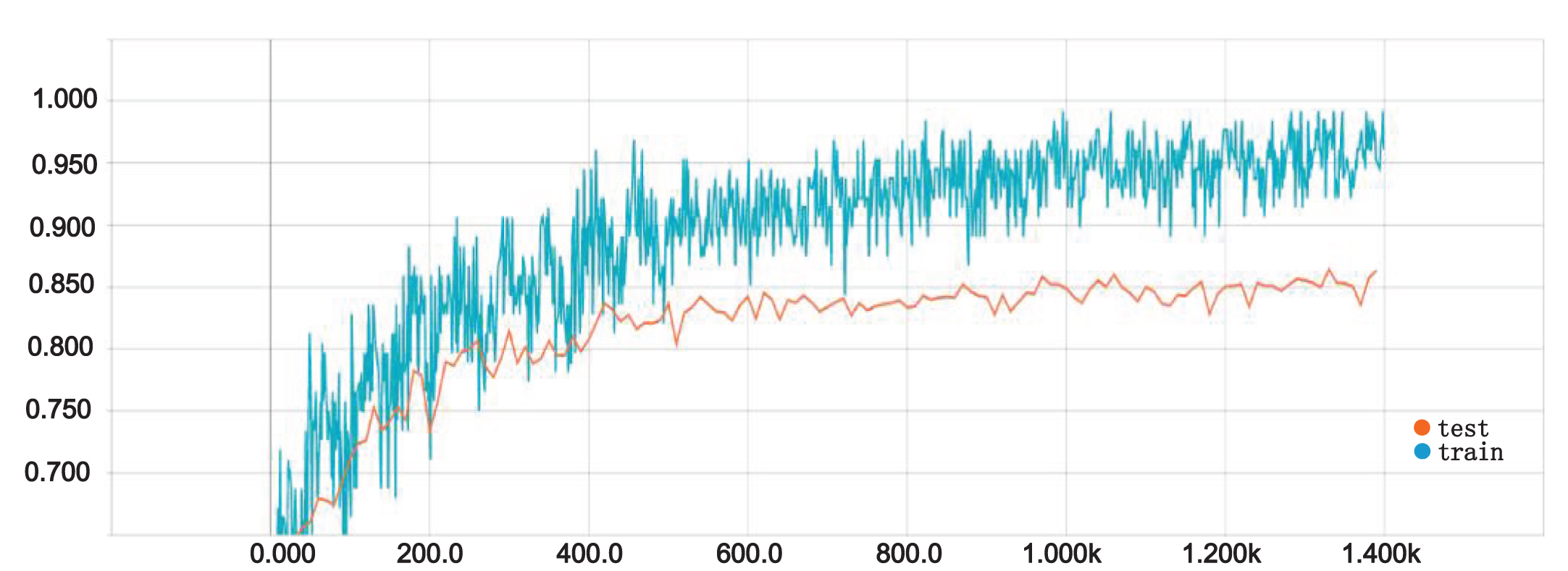
Performance of Bi-LSTM neural network.
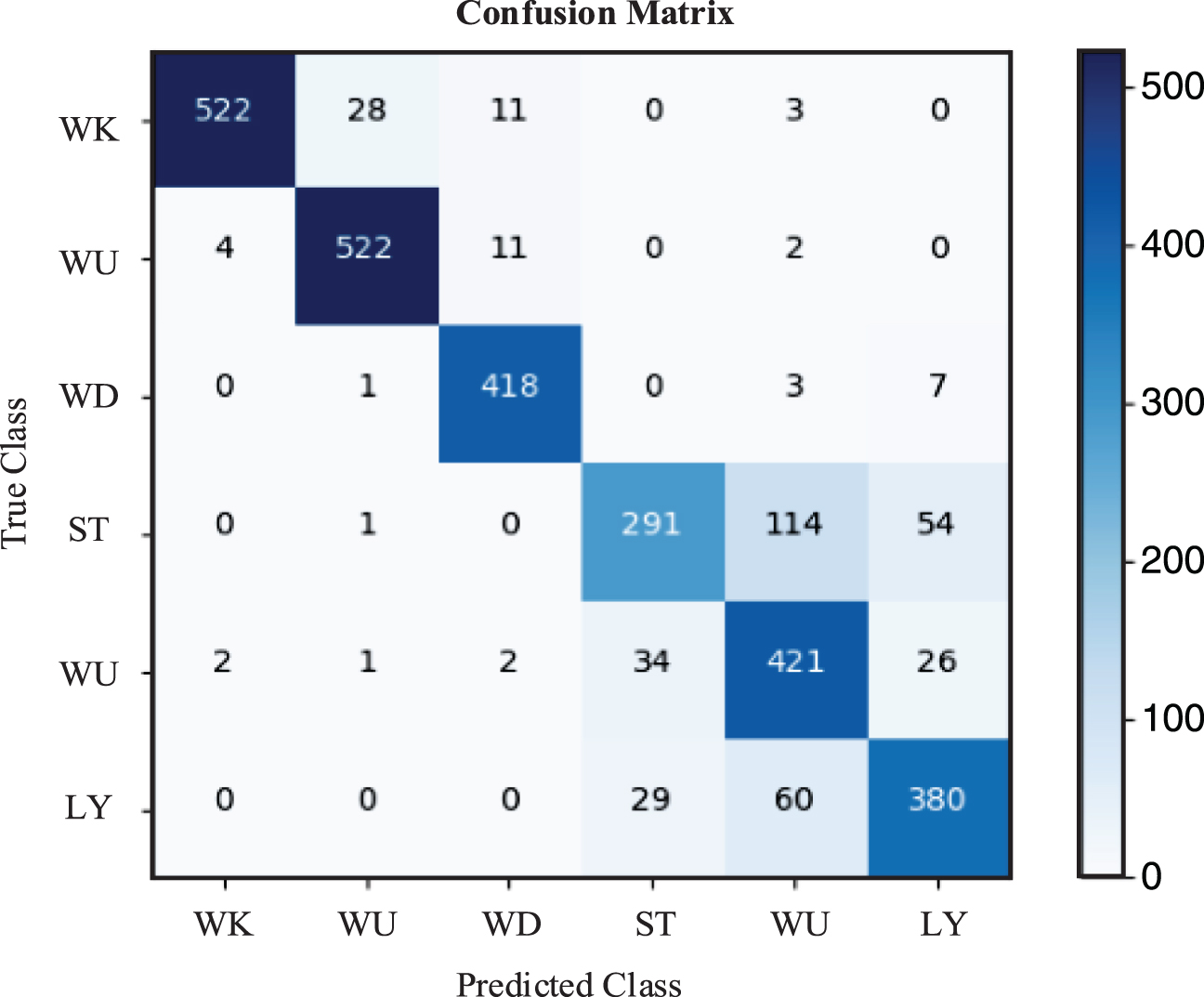
Confusion matrix of Bi-LSTM neural network.
where tp is true positives, fp is false positives, and fn is false negatives. Recall represents currently divided into positive sample categories, the proportion of true positive samples to all positive samples. Precision represents currently divided into positive sample categories, the proportion of the correct classification. F score is average of precision and recall.
The train model gave the best Bi-LSTM neural network performance of 0.867, as seen in Table 3. Comparing the confusion matrix of Bi-LSTM neural networks, this neural network is suit for discriminating the motion state such as WK, WU, WD, however, but not for others. Owing to the others has features that are more similar in dataset, it accounts for why the Bi-LSTM neural network cannot discriminate them accurately, and it depresses the overall accuracy.
Results of experiments
This study compared the Bi-LSTM with other algorithms, as seen in Table 4. Results showed that Bi-LSTM outperforms other neural network models. For using general performance personal computer to training the neural network model, the Bi-LSTM neural network was recommended to training model.
Compared with other models
To enhance accuracy and adjust model, the other method that transplanted the model to the smartphone was adopt. When the network model was constructed well, the model was transplanted to Android Smartphone to validate the model. According to the accuracy of actual test results, the next phase was to optimize model structure and collect more information, which can improve the accuracy of experimental results, and the whole phase was a loop process until the model achieved the reasonable stop criteria. Figure 9 reveals detail process of training model.
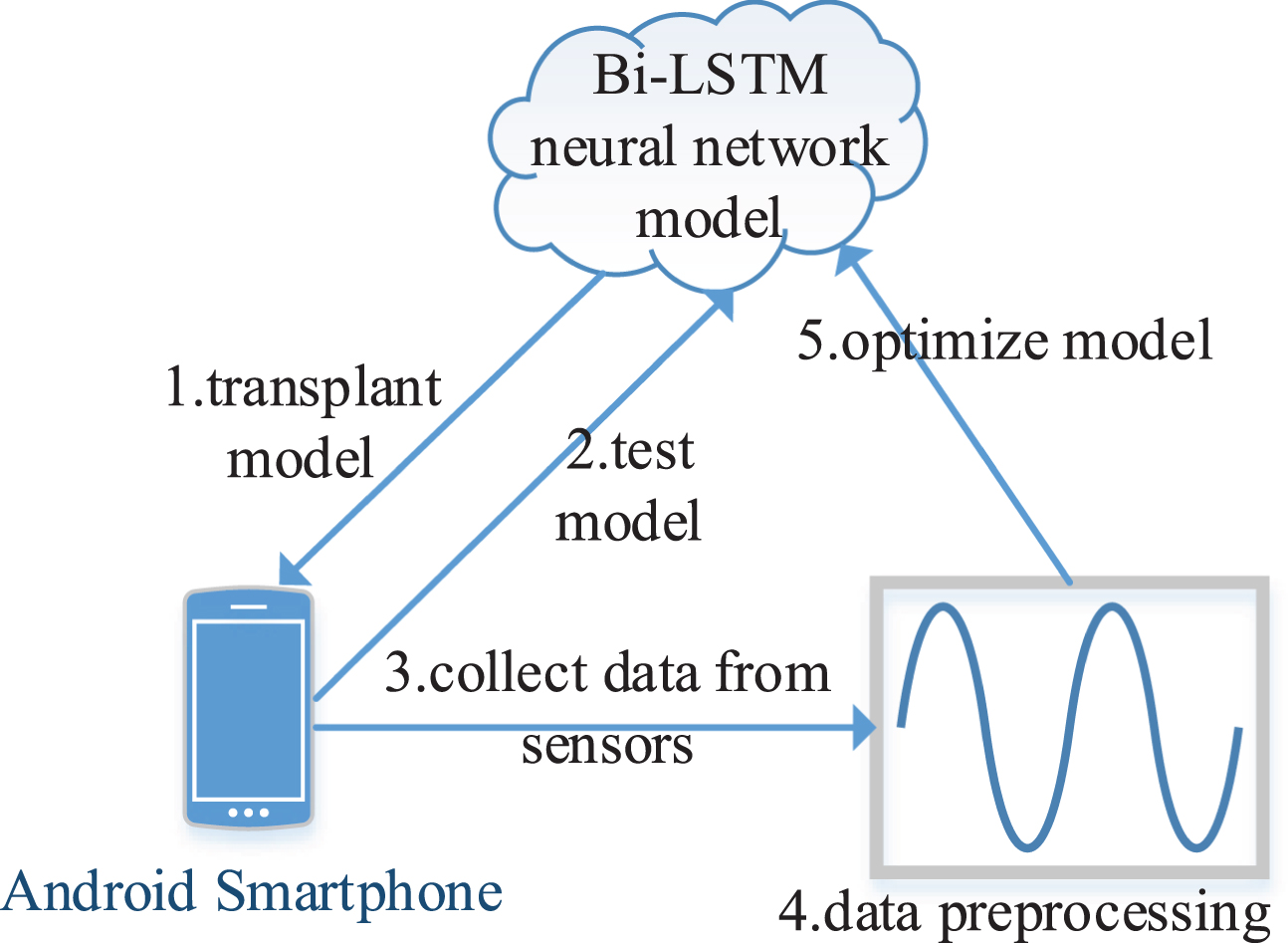
Management processing of constructing mode.
In order to show the application, this study developed an application of Android smartphone to show the recognition of the model. The model was transplanted to the smartphone. The Fig. 10 shows the processing of recognition. Firstly, the SD was selected, and clicked the ‘recognize’ button in Fig. 10(a), then the results were shown in Fig. 10(b), and the results were probability value. The two kinds of filters were used for this application. They were average filtering algorithm and median filtering algorithm. In order to get better final results, the application compared the values of two algorithms, only both are highest of all and the results can be shown. It was found that the highest value of the Pro-avg algorithm is SD and so did the Pro – med in Fig. 10(b). Due to different smartphones have same kinds of sensors, but the same sensor, different manufacturers of precision is not the same, which has an effect on the recognition accuracy.
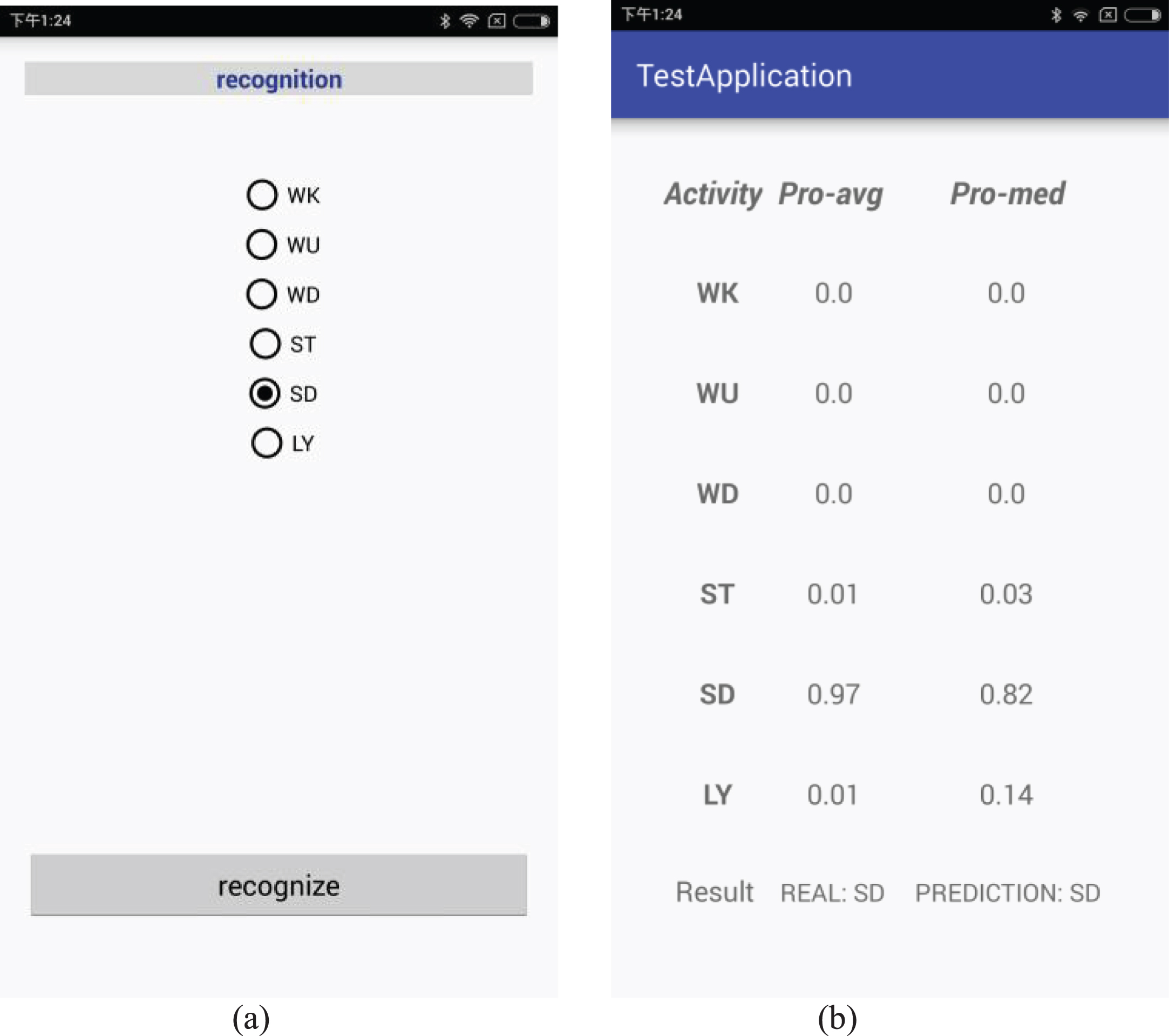
Processing of recognition.
To enhance accuracy of the motion state recognition, a novel method based on the Bi-LSTM neural network architecture was developed to construct a better neural network architecture. A case study was analyzed to compare the various neural network structures, algorithm, time cost and real-world application. The following conclusions could bedrawn:
Neural network Structure. Classical neural network, LSTM and Bi-LSTM were simple in structure, except the CNN that required many parameters and many network layers, possessed complex neural network structure and necessitated a many computing resources was not suit for general computer. Algorithm. Except the structure is different, the algorithms were same in this study. Some optimization algorithms to avoid overfitting or overtraining restriction were used such as optimization learning rate and the moving mean model. Cost Time and Application. During the model constructing process, especially, the performance of hardware in general, the cost time has to be considered as first. Owing to CNN requiring a lot of computing resources, this was main reason for discarding this neural network. In application, Google designs TensorFlow, the Bi-LSTM neural network model could be transplanted to Android smartphone easily, which provides JAVA interface.
Thus, neural network structure, algorithm, time cost and actual application were considered in the proposed method to construct a better performance neural network model.
In future studies, we plan to adjust neural network model architecture to enhance accuracy, and comprise with other neural network to get a better model. The APP is not perfect, we will add some new content such as recording the every activity lasting time in one day, analyzing the amount of exercise and giving some good advice to users.
Footnotes
Acknowledgments
This work was supported by the Natural Science Foundation of China under Grant Nos. 51668043 and 61262016 and the CERNET Innovation Project under Grant Nos. NGII20160311 and NGII20160112.