
Abstract
The traditional data query algorithm based on clustering strategy library ignores the association features of social network data, characteristic data acquisition exist a large number of redundant features and frequent relationship among features is low, resulting in the social network data query efficiency and the accuracy is poor, so a fast query algorithm for social network data based on fuzzy degree function based on association features is proposed, it is based on Apriori algorithm for data association feature mining of social network to obtain the maximum frequent association feature set; for association feature preprocessing, it reduce the maximum frequent association feature set by feature dimension reduction and de redundancy algorithm, to obtain better social network maximal frequent associated feature set; when using fuzzy function to query social network data quickly, it uses data of a single gene ambiguity function to build a fast data query diagram, input the best frequent feature set of social network, and output the query results of social network data with the highest priority. The experimental results show that the proposed algorithm has the advantages of high efficiency and high accuracy in social network data query.
Keywords
Introduction
With the development of science and technology, social network is playing an increasingly important role in people’s daily life. People increasingly use social networking as the main way to get information, share information and communicate with each other [1]. In recent years, the large social network platforms emerge in endlessly. In the daily life work, the users’ data are concentrated in the social network platform space. How to effectively utilize the data resources of the social network platform in the Internet space has become a research topic in the field of network data mining research. Database is as the underlying data carrier of social network, with the development and growth of social network, the amount of data has increased rapidly, making massive data search and query become the bottleneck problem of system design [2].
The existing data query algorithm in social network is widely used to retrieve resources of the major social networking platform resources in the intercom space, and is logically classified by data encapsulation categories [3]. Then, data mining is carried out by different data mining algorithms. Through most of the social network data mining technology analysis, it found that the traditional data mining technology used in social network data mining has a lack of logical sequence, when mining data nodes sequence columns coupling arrangement, part of the algorithm logic appears in data mining, data overflow, and the return rate of sudden drop phenomenon [4]. It affects the efficiency of network social data query and the accuracy of the overall data.
This study presents a fast query algorithm for social network data with fuzzy degree function based on association features, it is based on the characteristics of social network mining association data set, and uses fuzziness function for quick query of social network, which was with high efficiency to obtain high-precision social network data query results.
Fast query algorithm for social network data with fuzzy degree function based on association features
Overall framework of algorithm
The fast query algorithm for social network data with fuzzy degree function based on association features makes full use of the requirement of ambiguity function data query to feature independence [5]. The traditional data query algorithm ignores the relationship between the complexity of social network data and the combination of permissions, and considers that the classification ability of each feature is the same. Therefore, the training assembly generated by machine learning causes misjudgments. This feature processing algorithm based on associating feature mining and associating redundancy is used to bind the associated feature combination, which truly realizes the independence between features, and meets the requirement of ambiguity function for query [6]. Based on association feature, fuzzy degree function social network data query algorithm contains three parts: association feature mining, association feature preprocessing, and ambiguity function dataquery.
Association feature mining based on Apriori algorithm
Set W as a set of data on a social network, and any no-empty subset of it is called an associated feature. The support σ (x) of the social network data fast query project x contains the number of project x for all transaction centralization, assuming min _ sup as the minimum support, if σ (x) is greater than or equal to min _ sup, then x is called frequent itemsets. The characteristics of frequent co occurrence relations mean that they have greater probability of appearing in the same document, which may correspond to some specific phrases in the document, such as “data mining”, “computer science” and so on. There are many fast query algorithms for frequent itemsets, which can be easily applied to fast query of frequent features of social network data.
In this study, we choose the simplest Apriori algorithm, and use the Apriori algorithm of mining association rules to mine the correlation between the permissions of the same type application, and build the privilege relation feature library [7]. In order to solve the efficiency mining of high frequency events, we reduce the number of database scanning and the number of candidate data sets, and propose an improved Apriori algorithm based on the classical Apriori algorithm. The basic idea is to generate frequent sets with iterative algorithms, produce rule sets and outputs that can meet the minimum confidence rules. The Apriori algorithm used here is based on the concept of Android permissions. The Apriori algorithm is to excavate frequent itemsets of permissions, and construct the permissions associated feature library. In this study, the rights of 1000 random selected social network data samples are extracted, the permission feature database is formed, and other unrelated data are deleted. Then, the privileges that most of the target data rarely used are deleted. In the end, the Apriori algorithm is used to process this privilege feature database to produce a maximum frequent permissions feature set.
The Apriori algorithm has two main properties: connection and pruning, as well as two steps to generate frequent itemsets. The algorithm is finally output to the maximum frequent permissions database, and the whole process is as follows:
Connection: the set l1 and l2 are the set of items in Lk-1, and the collection of the k-item sets is generated by the Lk-1 connection with itself, and the set of the candidate sets is C
k
. Then the Lk-1 connection is executed, and the Lk-1 is connectable, if
Feature dimensionality reduction
First consider the removal of all has nothing to do with the social network data sets category features, which can be achieved by calculating the correlation measure Si,c between the feature F i and the class C of the social network data set. If Si,c is greater than a certain threshold of δ, then F i has strong separability, the related feature subset is temporarily stored in the category of F′. For ∀F i , F j ∈ F′, although they are all directly related to category C, this does not mean that there is no redundancy between them. It is therefore necessary to further analyze the correlation between F i and F j . The correlation measure Si,j between the association features is easily calculated by the formula (2), and the comparison between Si,j and Si,c can determine who is more dominant in the two related measures. To this end, the main correlations that define the social network data set feature F i are as follows:
For F
i
and class C, if Si,c ≥ δ and no ∀F
i
∈ F′ (j ≠ i) have Sj,j ≥ Si,c, then the correlation between F
i
and category C is the main correlation. Conversely, it is called a redundant peer. Given F
i
, SF,i is defined as a redundant peer-to-peer feature set, and it is divided into two subsets:
If the correlation between the association feature and the class is the main correlation or the deletion of all redundant peers has a major correlation, the association feature is the main association feature.
According to the above description, the process of reducing the dimension of the associated features is the process of analyzing and selecting all the main associated features. But if the N association features are analyzed directly, the time complexity of the algorithm is at least O (N2). 3 heuristic rules are given to reduce the number of correlation analysis.
The heuristic rule 1: if
The heuristic rule 2: if
The heuristic rule 3: The correlation feature of the maximum Si,c value must be the main feature. According to the heuristic rules mentioned above, the association feature reduction algorithm EFFS-select is given.
The algorithm starts:
For i = 1, to N do
Calculating Si,c for each F i
If (Si,c, ≥ δ)
Add Si,c to S list ;
End for
All associated features in
Do
If (Sp,q, ≥ Sq,c)
Delete
The latter association feature of
Else
The latter association feature of F
q
is taken from
End until F q is empty
Take out the latter association feature of F
p
from
End until F p is empty
Algorithm end
The time complexity of the algorithm is mainly composed of multi cycle half decision, ideally, set
Through the above analysis, the possibility of the implementation of related characteristics of maximum frequent high-dimensional data sets with social network still has the redundant features, for quick access to the social network data query results, redundant removal operations are carried out for the maximum frequent association feature set of the social network data after the dimensionality reduction [8].
Redundancy
The maximal frequent associated features obtained after dimensionality reduction of social network data sets for redundant processing. If their contribution to the classification ability is thought to be equal, it is handled as independent permissions association features, and it is clear that the classification is misjudged [9]. In order to improve the effectiveness of the association features in the classification, it is necessary to remove the redundant features in the set of associated features obtained earlier. The whole algorithm step is shown in Fig. 1.

De redundancy algorithm.
After redundant processing, the feature set of social network data association is clear, excluding some uncertain factors, and the best frequent feature set of social network is obtained [10], which reduces difficulty for data query.
Based on the best frequent association feature set of social networks obtained from the upper section, the fuzzy function is used to quickly query the social network data.
Single gene ambiguity function query for social network data
In this study, a single gene ambiguity function is used to construct a data query graph [11]. The ambiguity function of single gene data query is mainly used for query and analysis of large database data. After analyzing the data with this function, we can get the functional parameters of the data and evaluate the functional goals of the data [12]. It is assumed that the fuzzy function of the data u (t) ∈ L2 (R) can be described as Formula (1) and Formula (2):
φ ws (s, τ) is used to represent the fuzzy function of single gene data.
Transportation scale and ambiguity function is not the same as the scale factor corresponding to the single gene, the scaling of single gene factors will change the consequences of data [13]. a large number of studies have shown that the ambiguity function of the maximum transmission value in (0, 1) coordinates, its corresponding query results coincide with the panoramic output.
This study uses the fuzzy degree to analyze the data query of the maximum frequent association feature set of the superior social network. In the fuzziness function, its maximum value and the last full number of data query are correspond to the corresponding delivery [14]. In the process of querying data in the most frequent association feature set of social network, the maximum value of ambiguity function plays a key role, and it can be applied to data detection and parameter estimation, etc [15]. The filter banks are calculated, and the bandwidth of the arbitrary space distance filter can be calculated by the Formula (3).
Among them, min BW is the smallest broadband, EarQ is the quality factor of the interval expected to filter, an interval is expected to represent a filter bandwidth, but the frequency distance between the channel and the channel bandwidth is not the same because of the non-stop change, therefore, in this study, the step length factor is added to the repetition level of the adjacent filter [16]. For repeated levels, the range of values is between 0 and 1. If the step factor is 0, it feels that 100% overlaps; otherwise, it thinks that 0 overlaps. The number of channels in any frequency band can be obtained by Formula (4)
Among them, f n is used to describe the frequency segment of the frequency band, and f m is used to describe the low frequency segment of the band channel.
Then the center frequency is defined, and the center frequency of any frequency band of the space distance estimation filter group can be calculated by the Formula (5).
Space interval is the root of data query of the largest frequent association feature set in social network. The data of the maximum frequent association feature set is finalized by the interval of digital frequency modulation space [17]. If the data u (t), s (t) ∈ L2 (R), then the wide-band ambiguity function of u (t) and s (t) can be obtained by Formula (6) and (7):
Among them,
Through the analysis of the above formula, we can get the distance estimation value for data query in the maximal frequent association feature set of social network [18]. We use Formula 8 to describe it:
According to the results of the above ambiguity function analysis, we design the optimal data query graph, as shown in Fig. 2. The maximal frequent association feature set of social network is A ={ a1, a2, …, a8 }, and the collection of target objects is B ={ b1, b2, …, b8 }. The rectangle represents the query area R, and the critical distance d is 2. Two independent trees are used to index the maximum frequent association feature set A of social network and the target object set B.

Optimal data query results.
The design idea of a social network data query graph based on the fuzziness function is as follows [19]: firstly, using the optimal data query method based on the ambiguity function of single gene data to query the maximum frequent association features of social networks, the overall data target in A is located in R of query area, to keep it in the queue in S A ; then, through the single gene data query ambiguity degree function, the optimal social network data query algorithm is querying the collection of target objects. The shortest interval between B and query area R is smaller than that of the whole target object, the reservation to queue in S B ; for all the target queue in S B , through the heuristic rule calendar queue S A , its priority set is obtained, and the priority of target object is calculated.
If the most frequent association feature set of social network is A ={ a1, a2, …, a n }, the set of target directions is B ={ b1, b2, …, b m }, the range of query is R and the critical interval is d. The optimal set OS (b j ) of target object b j can be described as {a i |a i ∈ A ∧ a i ∈ R ∧ dist t (a i , b j ) ≤ d }.
If the two target objects have the same elements as the optimal set of social network data, then the target object goes to the sum of the elements in the social network data optimal set and determines its priority [20–22]. The cumulative distance of each a i from b j to its optimal set OS (b j ) can be described as AD (b j ) = ∑a i ∈OS(b j )dist t (a i , b j ). The smaller the cumulative distance AD (b j ) of the target object b j is, the higher the priority of the target objects b j is.
The priority of the target object b
j
can be described as a formula (9):
After completing the processing operation, S A ={ a6, a3, a2, a7 }, S B ={ b5, b2, b1, b3 }. The data objects in the S A are in the maximum range of coordinate values on the X axis, so that all the elements in the S A and S B are arranged in ascending order of the X axis coordinate values. Then the first set of the target object b in S B is set up by scanning the data image of the X coordinates in the [b. x - d, b. x + d] range in the S A . Finally, the target object b1, with the highest priority, is output as the result of the social network data query.
Experiment 1
Experimental data setting
In order to verify the validity of the proposed data query algorithm, relevant experimental analysis is needed to carry out. The experimental conditions are as follows: Inter (R) Core (TM) 2 Duo 2.93 GHz, RAM 2 GB, and hard disk 500 GB. The experimental data set is: the Smily Sarm is a community class application on the Facebook platform (4 million users), the average monthly active users 6 million, daily processing of data requests reach 200 million people. In order to achieve effective query algorithm in this study for the entire database, the proposed algorithm is used on the experimental analysis of the data set.
Analysis of characteristic event data query results of different algorithms
The reading events of the official activity Event is selected as a feature event, the specific steps are as follows: first query from the official activities of Library Reply table 10 replies a Event record query, and then go to the library to find the mapping certification according to the record of user_ID DB, and then go to the corresponding user information query target DB. The X axis is set to select an official activity sequence, and the Y axis is the specific time consumption of the details of the people who query the latest 10 replies of a certain activity. Through the comparison strategy of the proposed algorithm and the clustering data pool query algorithm, the results is obtained as shown in Fig. 3, which describes the time consuming status of different algorithms for reading event data.
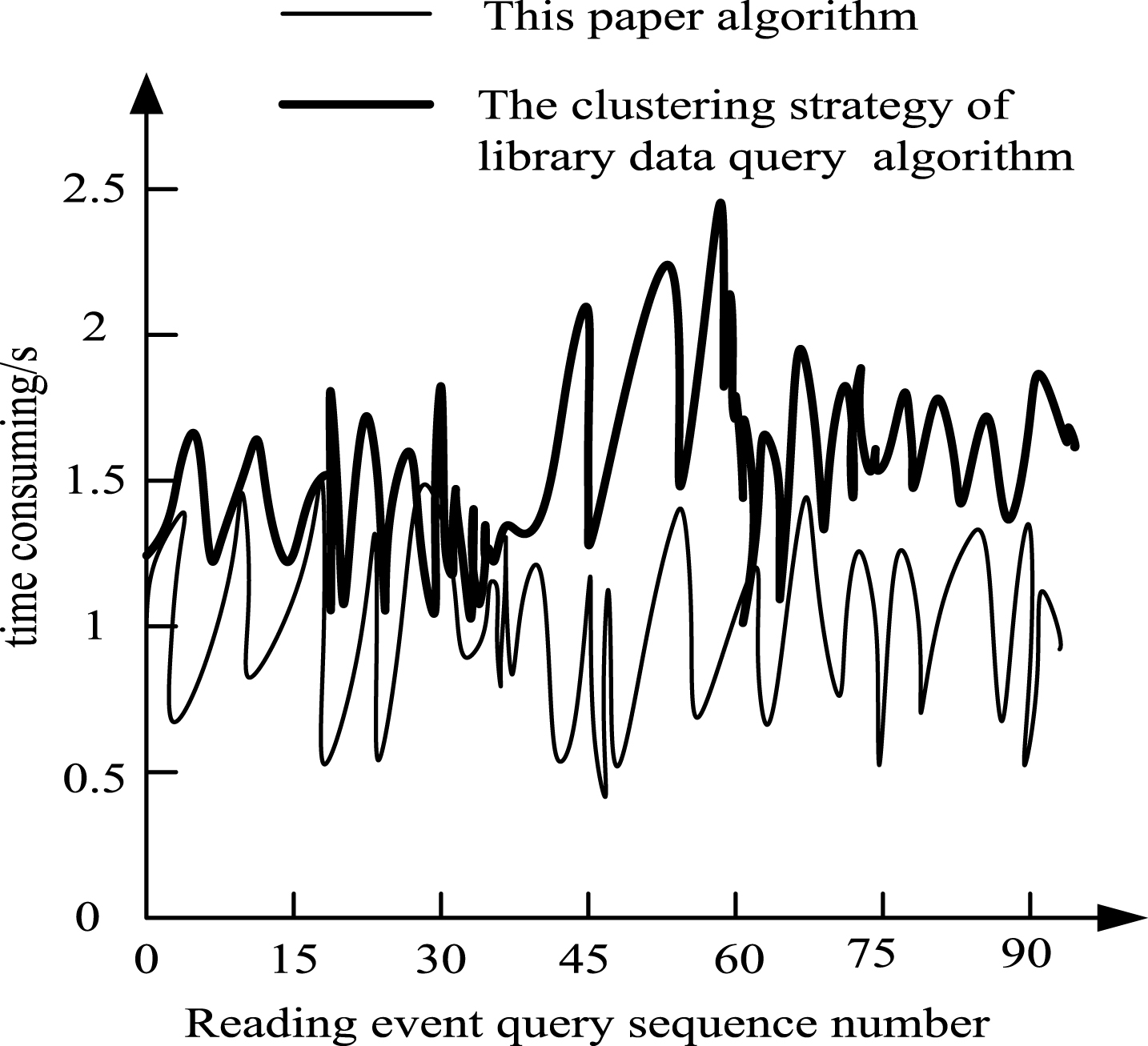
The time consuming status of reading event data query in different algorithm.
Analysis of Fig. 3 showed that the time of initial stage is maintained at 1.5 s, during the 45–60 serial number reading event data query, the peak occurs, which is up to 2.5 s, the data query later stability in the 1.7 s; by using this algorithm reading event data query process, the overall time overall time below the query algorithm in clustering data bank strategy, which slight float on the 1 s, with no obvious peak and good stability. The experimental results show that the query time of this algorithm is less, and the efficiency is higher.
Based on the experimental data, we get the distribution of access efficiency under the two algorithms based on popular reading events, and calculate the average efficiency based on the experimental data, as shown in Fig. 4.
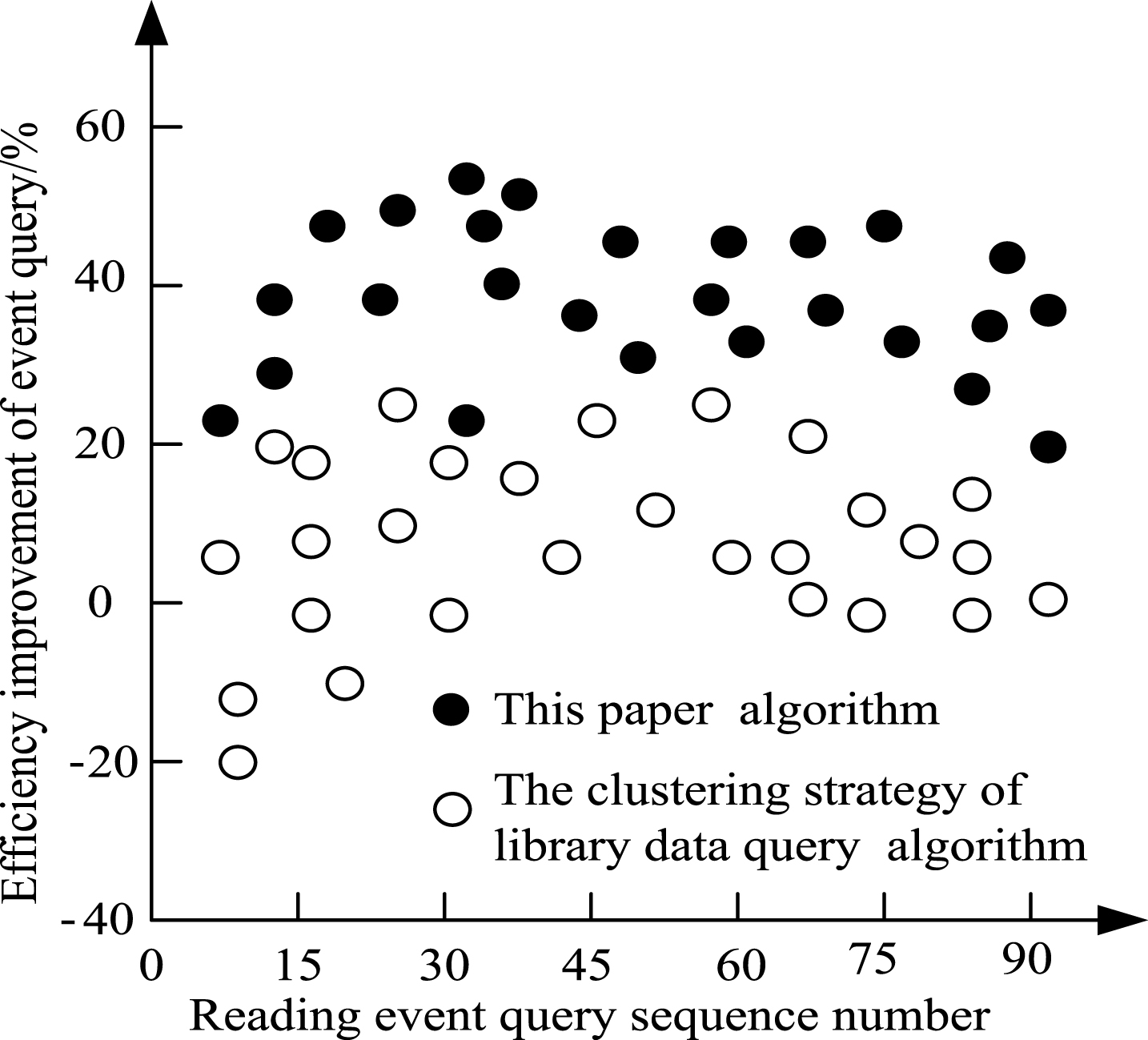
The efficiency improvement of reading event data query in different algorithm.
Figure 4 showed that the clustering strategy library data query algorithm for reading event data query efficiency increase in 10%, in the initial stage of data query, negative growth of efficiency appeared, which was down to –20%, the data query later rebounded, basically stable at around 10%; using this algorithm, the reading event data query efficiency is better, which was more than 20%, stable at around 40%, and up to 58%. The experimental results show that the algorithm improves the efficiency of the social network data query, and the performance of data query is good.
In order to further verify the superiority of the algorithm in improving data query efficiency, based on the above algorithm, experiments are carried out to improve the efficiency of data query in Family Farm, which are more important in the exchange behavior events, recharge events, and user login events. The experimental results obtained are shown in Figs. 5, 6 and 7. Figure 5 describes the efficiency of data collection and distribution of integral exchange events. Figure 6 describes the data query efficiency improvement and distribution status of recharge events. Figure 7 describes the efficiency of user login event query and the distribution status.

Integral convertibility data query efficiency promotion distribution map.

Recharge event data query efficiency enhancement distribution map.
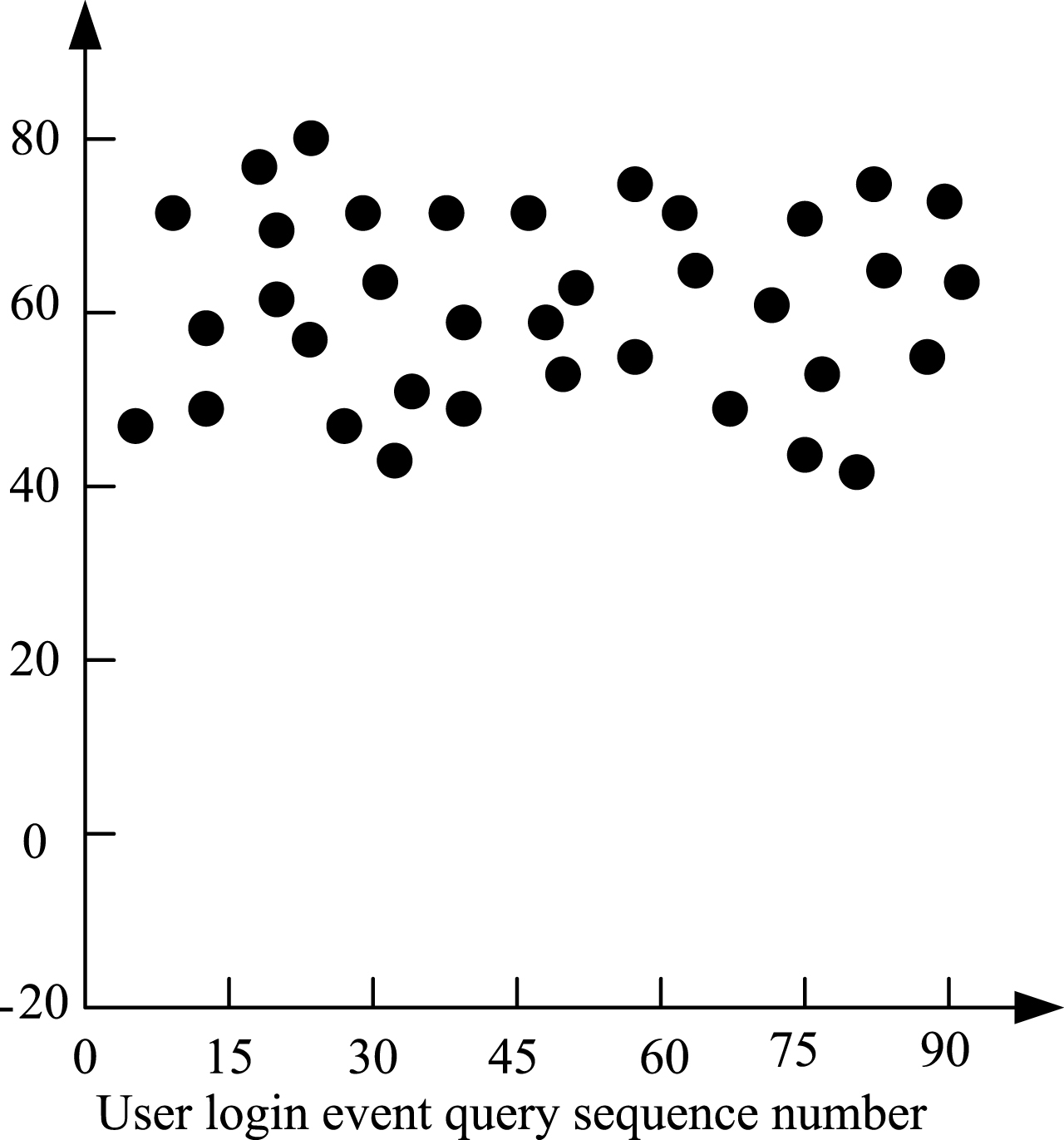
User login event data query efficiency promotion distribution map.
Figures 5, 6 and 7 showed that our algorithm has achieved excellent results in 3 aspects of integral exchange events, recharge events and user login events, and the efficiency has increased by more than 20%. The increase in the efficiency of the convertibility event query is about 40%, the increase in the efficiency of the recharge event query is about 50%, the increase in the efficiency of user login event query is about 60%, and the efficiency improvement of each data query is improved. The experimental results showed that the efficiency of the query data is constantly improved with the transformation of different events, and the ability of data query is very strong.
Experimental data setting
In order to verify the effectiveness of this algorithm in the fast query of social network data, the experimental analysis on the relevant data is carried out, specific data sets is: Internet users sign in real data provided by the Stanford Network Analysis Project Gowalla Austin in the real sign in data set by network users in the city, the data set contains a total of 7219 users, the friend relationship between users is 77589 pairs, a total check-in locations of 16326, and all users have 291161 entries in all locations. The whole data set is run by the algorithm in this study, and the experiment of 10 target data is carried out quickly. The experimental results are described in Table 1.
The proposed algorithm performs fast query results for 10 social network target data
The proposed algorithm performs fast query results for 10 social network target data
Table 1 analysis showed that each query time is maintained at around 21 s, the data query time varies little and tends to be stable every time. The average running time is 20.75 s, and the time taken is shorter. The accuracy rate of the 10 data query experiments was high, both at 95%, the average value reached 96.44%, and the hit rate was high. To sum up, the performance of this algorithm is stable and the accuracy is high.
In order to further verify the superiority of the algorithm in running time and query accuracy, we compare the algorithm with IR-tree data query algorithm and XML data query algorithm. The experimental setup is as follows: three algorithms are used to query target data for different numbers of users, the time spent on different algorithms and the accuracy of the query data is recorded. A broken line diagram is made from the results obtained, as shown in Figs. 8 and 9, Fig. 8 describes the time consuming comparison of query target data in different algorithms, Fig. 9 describes the comparison of the accuracy of the query target data in different algorithms.

Comparison of time consuming conditions for query target data in different algorithms.

Comparison of target data accuracy in different algorithms.
Figure 8 showed that with the increase number of the users, the cost of time in three algorithms has increased, using the XML data query algorithm takes the fastest growth rate, the number of users is 600, time consuming more than 10 s; the time consuming speed of IR-tree data query algorithm is slightly slower, when the number of users is 600, it takes more than 8 s; the time increase of the data query by this algorithm is minimal, it can be obviously seen that in the number of users is 300–600, the algorithm time tends to be stable in 4 s, which is far lower than the other two algorithms.
Analysis of Fig. 9 can be seen that the query accuracy of this algorithm is located at the top of the line graph with different number of users, the accuracy of target data query were above 95%, up to 98%, the latter tends to smooth; the accurate rate by using the IR-tree data query algorithm is relatively low, which was at about 90%; the query using XML data query algorithm has the lowest accuracy, which was below 85%, and the lowest reach 78%. The experimental results showed that the accuracy of the target data obtained by this algorithm is the highest, and with the least time and high overall performance.
This study proposed a fast query algorithm for social network data based on fuzzy degree function based on correlation features, considering the correlation between social network data and frequent relevance, its dimension reduction and redundant processing are carried out, which makes the results of the obtained social network data query more accurate and saves the time of data query.
Footnotes
Acknowledgments
Domestic visiting scholars project support (GF2017); Shaanxi provincial science and Technology Department of natural science basic research project (2017JM6086).