
Abstract
Copy-move forgery is one of the famous manipulation technique in digital image. Many block-based techniques have been proposed previously for forgery detection, but most of them have higher computational complexity due to higher number of feature vectors dimension. In this paper, we have tried to reduce the feature vectors dimension. This paper proposes a copy-move forgery detection (CMFD) technique based on circular blocks and discrete cosine transform (DCT) with fewer feature vectors than the prevalent methods. Initially an input image is taken and divided into overlapping blocks. To extract the features from each block, DCT transformation is used on each block. Then, these features are represented using a circle block to reduce the feature vectors dimension. The extracted feature vectors are then used for matching process to locate the manipulated regions. Experimental results depict the performance of the proposed method and robustness against the post-processing operations. The computational complexity of the proposed method is lower than the existing techniques due to fewer feature vectors dimension.
Keywords
Introduction
A number of software applications (e.g., Adobe Photo-shop) are available nowadays to easily edit pictures without leaving noticeable proof of modification. It is thus difficult to determine whether a given image has been altered. This creates various problems in fields as diverse as legal trials, insurance, and pseudo-scientific research. An example is shown in Fig. 1 in which American astronaut Stephen Robinson is shown in front of the Canadarm2 on a space walk. This picture is prompted by several Canadian government websites for Canada’s involvement in the International Space Station. But The Economist pointed out the forgery done in the Canada logo visible on the arm. As it can be seen that the logo clearly did not match with the background color and texture. Originally there was NASA logo which was captured by NASA [1]. Example of Copy-move (a) Original image (b)Tampered image
To ensure the authenticity of an image, researchers have developed several methods. Broadly it has been categorize into two categories: Intrusive (active) and Non-intrusive (passive) methods. In intrusive method, prior information is embedded into the image like watermarking or digital signature. At authentication stage, it is being tested to ensure the authenticity of the image. If there is any tampering done in the image the extracted watermark or digital signature is not same. By this method, the authenticity of an image can be ensured. But in non-intrusive methods, there is no such kind of information is embedded into the image, we have to rely on the intrinsic properties of the image. It is also said as blind technique to detect the image forgery. According to Christlein et al. [2], non-intrusive methods are of two kind: copy-move forgery and splicing detection. In copy-move forgery one region is copied and pasted over other region in the same image to conceal some important information. But in image splicing one region is cut and pasted over other region in different image to create a new image. Based on the above classification, the basic principle of forgery detection is to find the region which have similar feature in copy move or completely different region in spliced image. Although it can manifest itself in many forms, the basic form of image manipulation is known as copy-move forgery in which object is covered by some part of the image. Researchers have proposed many techniques to detect the copy-move forgery and most of them uses block matching method. Fridrich et al. [3] used DCT to extract the features and locate the duplicated region, but the method is not invariant to noise present in the image. Huang et al. [4] reduced the number of dimensions of feature vectors to increase the performance, but their method lacks in detection of multiple copy-move regions. Popescu et al. [5] introduced a new method based on principal component analysis (PCA) for feature extraction. It is invariant to noise but accuracy is not up to the mark. Luo et al. [6] used color features and ratio of block intensity to verify the strength of their method. Mahdian et al. [7] used blur moment invariants to locate forged regions in an image. Bayram et al. [8] applied the Fourier-Mellin transform (FMT) for the extraction of features from each block and project it in one dimension. Pan et al. [9] applied scale invariant feature transform (SIFT) to find the manipulated regions and this method shows better results. The above discussed methods have high computational complexity as they have used quantize square blocks for matching and detecting the duplicated regions. As the efficiency of detection is related to the dimensions of feature vectors, if the feature vectors dimension is greater, the detection efficiency is affected. It affects more when the large-sized high-resolution images are processed.
This paper presents an efficient and robust against post-processing operations for manipulation detection method based on enhanced DCT. After comparative study with the existing state-of-arts, followings are the main advantages of proposed method: The number of dimensions of the feature vectors are reduced. The proposed method can detect forgery with various attacks (such as noise contamination, Gaussian blurring and multiple copy-moves). Low computational complexity is observed for the proposed method.
The remainder of this paper is organized as follows: related work is presented in Section 2. In Section 3, the proposed method is described in detail. The experiments to test our method and a discussion of the results are presented in Section 4, and the conclusions of this paper are offered in Section 5.
In recent years, many methods have been introduced for copy-move manipulation detection, and most of them are block based. A few of them are discussed below, and Table 1 shows an analysis of these techniques based on the length of the feature vectors.
Fridrich et al. [3] proposed a method where blocks are represented by quantized DCT coefficients and collected as a row in a matrix. This matrix consists of (R - B + 1) (C - B + 1) rows and B × B columns. The rows of the matrix are lexicographically sorted. They have used exhaustive search, where every block is compared against others. In this method, each block consists of 64 quantized DCT coefficients. Later on, Alkawaz et al. [10] studied the effect of different block size (4 × 4 and 8 × 8) for copy-move detection. But there method doesn’t consider the post-processing operations. Zhong et al. [11] proposed a method in which auxiliary overlapping circular block is used to divide the image. Discrete Radial Harmonic Fourier Moments (DRHFMs) is used to extract the features from the image. They have applied 2 Nearest Neighbour (2NN), euclidean distance and correlation coefficient to locate the forged regions. Wang et al. [12] proposed a method based on DCT in which matching is done through packages of feature vectors to reduce the time of blocks comparing and avoid lexicographical sort. Packages are formed on the basis of pixel means of the blocks.
Analysis of some popular block-based techniques
Analysis of some popular block-based techniques
Huang et al. [4] proposed a method where DCT coefficients are used, but in improved form, in the sense that only a few values of quantized DCT coefficients are used as feature vectors. DCT have a properties that, most of the energy of the transformed DCT coefficients focus on the first several values (i,e. lower-frequency coefficients). Hence, to reduce the dimension of the feature vectors, higher-frequency coefficients can be pruned. Now DCT coefficients are reshaped into a zigzag order row vector. Truncation can be done by a factor p (0 < p ≤ 1), and only those DCT coefficients are considered for further processing. In this way, Huang et al. [4] considered only 16 DCT coefficients for further matching.
Yanjun et al. [13] introduced a method in which transformed DCT coefficients are represented by a circle block. To reduce the dimension, four feature vectors are considered from each quadrant of the circle as an average of the coefficients. The feature vectors are stored in lexicographical order and matching process is subsequently implemented. Luo et al. [14] proposed a method in which blocks are divided into four sub-blocks and feature vectors are evaluated according to the average value of red, green and blue colors. Their method is robust against Gaussian blurring, additive noise and JPEG compression. Hayat and Qazi [15] proposed a method which depends on the discrete wavelet transform (DWT) as well as DCT for feature reduction. The DCT is applied to individual blocks obtained after dividing the DWTed image. They have used correlation coefficients for the comparison of the blocks and achieve the average accuracy of 73.52% on simple copy-move forgery detection. They didn’t consider any post-processing operations on the forgedimages.
Kang and Wei [16] applied singular value decomposition (SVD) for feature extraction which gives a better representation of features with less dimension. Then lexicographical sort is applied on feature matrix according to the singular values. Their method can detect manipulation even in noise. Bayram et al. [17] used the Fourier-Mellin transform (FMT) and one-dimensional (1D) projection of log-polar values to efficiently detect duplicated regions.
Mahdian and Saic [8] used blur-invariant moments that are relevant to blur degradation, additive noise, and arbitrary contrast change. Li et al. [18] used circular blocks to extract features from an image along with a rotation binary pattern (LBP) that is rotation invariant. Lin et al. [19] proposed a method where blocks are divided into fixed sizes of overlapping blocks with nine average intensities, and are then subjected to radix sorting to obtain the feature vectors. Later on, Yang et al. [20] used LBP to extract the features from image and sorted the feature vectors to estimate the matching block pairs using euclidean distance to locate the forgeryin image.
The summary presented in this section indicates that the above-mentioned methods have high complexity because they have used feature vectors with a large number of dimensions. The feature vectors in the proposed method have fewer dimensions than those in existing techniques, and the proposed method is robust against various attacks such as Gaussian blurring, noise contamination, and multiple copy-move processes.
In CMFD, it is well known that there must be at least two similar regions present in suspicious image. In the exceptional case, if there are large smooth regions then the algorithm fails to locate the actual duplicated regions because of the presence of false matches. Basically the task of forgery detection algorithm is to locate the duplicated regions in an input image. The shape and size of the duplicated region are undetermined. Hence, it is not feasible to check all possible pair of regions of various shapes and sizes. Thus, the input image is divided into overlapping blocks of fixed sizes, and matching is applied to obtain the duplicated region. The matching procedure involves representing the blocks by their features. To make the proposed algorithm effective and robust, there is a need of efficient feature extraction method. After all the blocks are processed and features are represented, then the matching process is conducted between blocks to get the duplicated regions. The matched blocks have identical features and to conduct matching process more effective, features are sorted lexicographically. Due to this, the detection algorithm has less computational complexity.
Algorithm flow
The skeleton of the proposed CMFD algorithm is shown in Fig. 2, and consists of the following steps: Splitting the image into fixed-size blocks. Generating the quantized coefficients using DCT transformation on each block. Representing every quantized block by a circle and extracting the relevant features. Exploring similar block pairs. Extracting the correct block and representing it as output. Algorithm flow of detection method Proposed Algorithm

Circle divided along (a) horizontal and (b) vertical directions.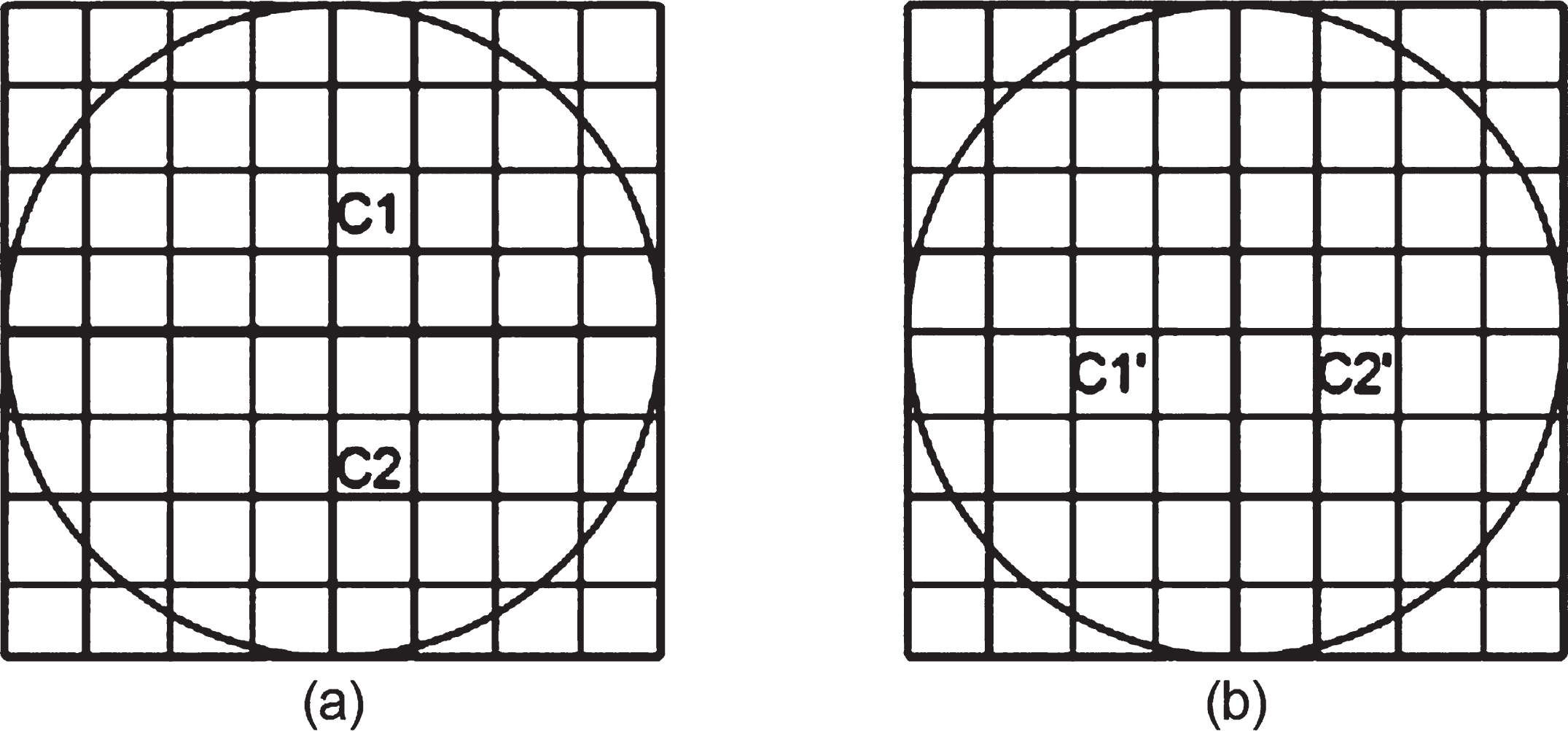
Lets consider r as the circle radius, then the ratio between the circle_area and block_area is given by
Above calculation shows that the circle block can efficiently represent most of the coefficients of the block. This draws the conclusion that by using circle block, computational complexity can be reduced.
For block matching, the feature are extracted from the circle block which is further divided into two semicircles along the horizontal direction (Case 1) and vertical direction (Case 2). The main purpose of dividing the circle into semicircle is to reduce the feature vectors dimension which leads to the less computational time in forgery detection. The detailed discussion about these cases are given below.
This indicates that the dimension reduction is more substantial compared with that in other methods [3–5, 13] and value reduction occurs by using the 1×64, 1×16, 1×32 and 1×4 features vectorsrespectively.
Feature Vectors robustness
The correlation coefficient of the post-processed data is calculated and it is equal to 1.0 as shown in Table 2, which indicates that the feature vectors are well correlated to each others. Hence the calculated vectors are robust enough to perform further detection algorithm for duplicated region detection. It also indicates that the dimension reduction is successfully achieved as shown in Table 1.
For experimental analysis, we have used MATLAB R2013a. Images used in the experiments are of 256 × 256 size in JPG format. We set the threshold by using overlapping blocks, and features are extracted through circle blocks. The threshold parameters are defined by selecting the circle radius. It plays a vital role and it is selected very carefully. For selection of circle radius, different images having tampered regions are used and set the radius of the circle with unit increment ranging from two to six.
By experimentation, the radius of the circle (r) is set to four for RGB images. The parameters b = 8, D similar = 0.0015 and N d = 120 provide the best result for r = 4.
The effectiveness of the proposed scheme has been tested on few images containing regions of a similar size 256 × 256 from database [2] and converted them into gray scale. The detection results are shown in Fig. 4. Detection results (original image, tampered image, detection results). The detection results: original image, tampered image and duplicated region respectively.

The detection method executed on the images did not involve any post-processing operations; each set of tests consisted of the original image, the tampered image, and the detection results. We ran the detection algorithm on images with irregular duplicated regions and, as shown in Fig. 5, all the duplication regions were detected accurately. Detection results: (a) Original image, (b) Tampered image, (c) Duplicated region. Multiple copy-move forgery detection result after post-processing operations: (a) Original image, (b) Tampered image, (c) Duplicated region. Detection results of the forgery images after applying JPEG compression with varying quality factor (from 20-100). (a) original image (b) forged image (c) ground truth and (d)-(l) detected regions. Comparison of different techniques by plotting the DAR and FPR curves: (a)-(b) Gaussian blurring with different SNR levels (w = 5, σ = 0.5, 1, 1.5, 2, 2.5, 3) and (c)-(d) with (SNR = 5, 10, 15, 20, 25, 30 dB).


Many image-editing tools are available to create tampered images in which the changes are barely detectable. The employment of multiple copy-move steps is gradually coming into use for image manipulation, where many duplicated regions are present in an image. None of these problems were previously considered [3–5, 13]. The detection result is shown in Fig. 6.
Fig. 6(a) is the original image of a Christmas tree. In Fig. 6(b), the tree is copy-pasted three times. The image seems to be natural with several Christmas trees. The proposed detection algorithm is able to accurately detect that the Christmas trees had been copied and pasted to alter the image.
In real-life scenarios, people who perform tampering within an image, use post-processing operations to alter these images. They generally use noise addition, blurring, JPEG compression or a combination of different operations. We examined such a scenario as well. Fig. 7(a) shows the original image, Fig. 7(b) the tampered image with the Gaussian blurring operation, with w = 5 and σ = 1. It can be observed from the tampered image that after post-processing, the image is barely discernible. However, Fig. 7(c) shows that the proposed algorithm accurately located the multiple duplication regions. We have also applied JPEG compression having different quality factor (ranging from 20-100) to test the robustness of the proposed method. As it can be observed from the Fig. 8 the forgery can be detected in all JPEG quality factors. In the literature [3–5, 13], these conditions were not considered. For evaluation of the efficiency and robustness of the proposed method, we calculated the detection accuracy rate (DAR) and the false positive rate (FPR) as
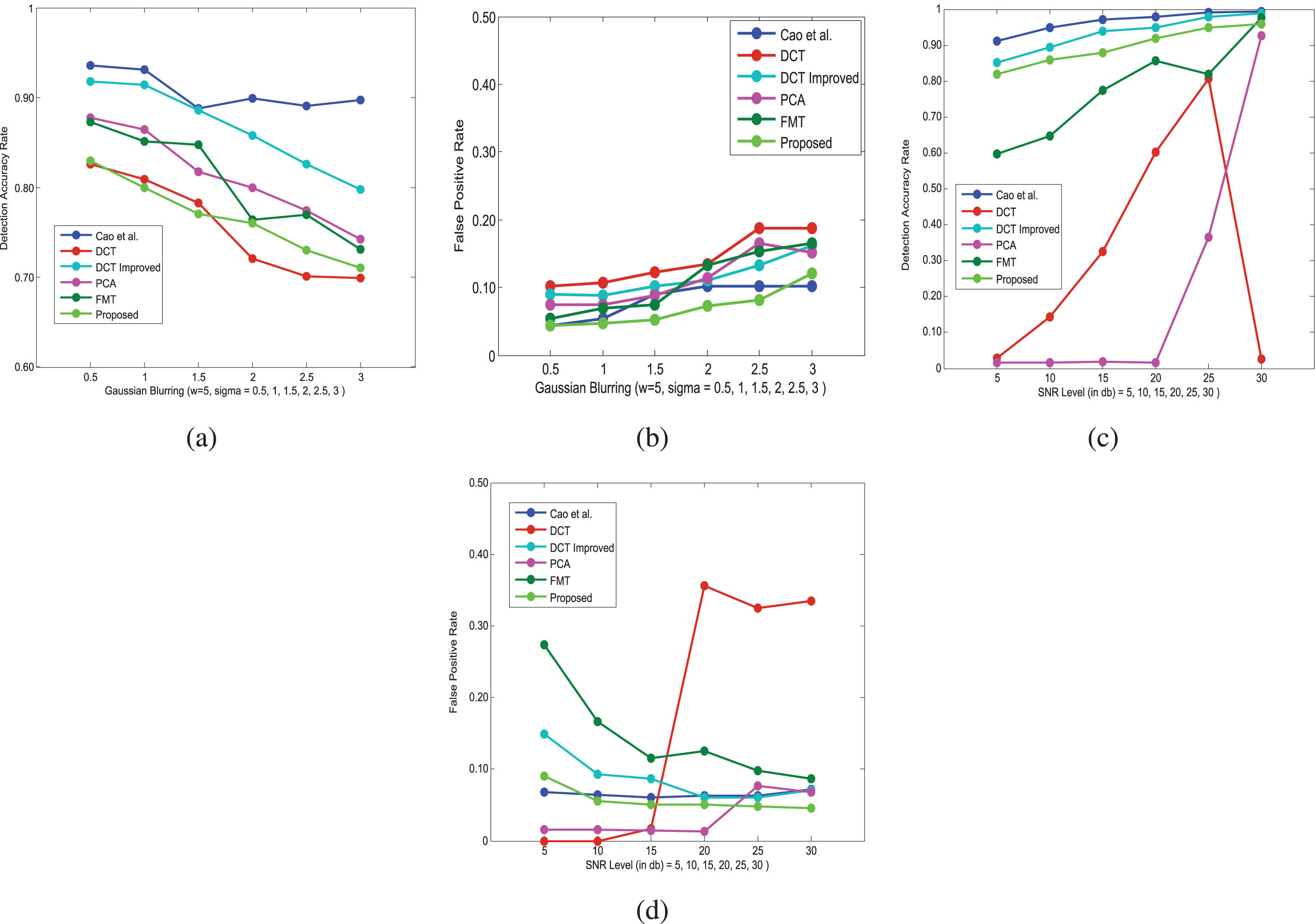
We quantified the sensitivity and efficiency of the proposed algorithm by using images of size 256 × 256 from an existing database [2]. Here, the proposed method is compared with other methods: DCT-based [3], DCT-improved [4], PCA-based [5], FMT-based [8] and Cao et al. [13]. For the comparison, we tampered some images by randomly copying and pasting a square region on a non-overlapping position. The size of the square region was 48 × 48. Then additive white Gaussian noise and Gaussian blurring are applied. We used Gaussian blurring with w = 5, σ = 0.5, 1, 1.5, 2, 2.5, 3 and white Gaussian noise with SNR = 5,10,15,20,25,30 dB. The average DAR and FPR performance after post-processing operations over the database [2] is shown in Fig. 9.
As shown in Fig. 9(a), the DAR performance of the proposed method against Gaussian blurring was comparably robust and, in most cases, over 70% of the area of copy-move regions was detected, even when the image was poor in quality, with w = 5 and σ = 3. The FPR was much lower than those of other techniques, as shown in Fig. 9(b). The DAR performance against Gaussian noise was above 80% with different SNR values (5, 10, 15, 20, 25, 30 dB). The FPR was lower than 10% in all cases, as shown in Fig. 9(c) and Fig. 9(d). In general, we observed that when the image quality was poor, the performance of the detection method degraded drastically; however, the proposed algorithm was able to detect more than 70% of the tampered regions that were easily observed by a human.
Finally, we compared the proposed method with that of K. Hayat & T. Qazi [15] on images from an existing database [2]. The performance of both methods in terms of DAR and FPR is shown in Table Table 3. All images were used without post-processing. Table 3 shows that the performance of the proposed method in terms of DAR was better to that of K. Hayat & T. Qazi [15], but it was sufficiently robust to detect the duplicated regions. As we also successfully reduced the number of dimensions of the feature vector, the efficiency in terms of DAR was acceptable to detect forgery in images. Also Table 3 shows that the FPR performance of the proposed method is superior to that of Hayat & T. Qazi [15].
Here, we have discussed the computational complexity of the proposed scheme. Initially, to obtain the N
blocks
blocks from the input image, it takes
From the above analysis it can be observed that, for a given image of M × N dimension, N
blocks
can be obtained using Equation (2) and the number of blocks increases with a
Conclusion
Comparative performance of the DAR/FPR of proposed approach with K. Hayat & T. Qazi [15]