
Abstract
The adoption of network flow in the domain of Network-based Intrusion Detection System (NIDS) has steadily risen in popularity. Typically, NIDS detects network intrusions by inspecting the contents of every packet. Flow-based approach, however, uses only features derived from aggregated packet headers. In this paper, all publicly accessible and labeled NIDS data sets are explored. Following the advances in deep learning techniques, the performances of Long Short-Term Memory (LSTM) are also presented and compared with various machine learning classifiers. Amongst the reviewed data sets, the models are trained and evaluated on CIDDS-001 flow-based data set.
Introduction
The detection of malicious traffic and network intrusions is typically automated by deploying Intrusion Detection System (IDS). An IDS complements a firewall in a similar way. It analyzes traffic for any possible intrusions, which can originate from either outside or inside an organization. One of the first major division of an IDS depends on the data it analyzes. Network-based IDS (NIDS) is one such variant, it monitors all traversing network traffic for intrusions or anomalies.
Traditional NIDS relies on Deep Packet Inspection (DPI) by extracting the desired information from payloads. Despite yielding beneficial insights on semantic attacks [1], the implementation of DPI can be difficult. Issues such as encrypted payloads and computational costs can render an IDS ineffective in high-speed networks. On this account, one such prominent recourse is to use network flows in detecting network intrusions. A flow-based IDS eliminates the aforementioned weaknesses by having only information from the flow records. Yet, it has not been exploited as much when comparing to the traditional packet-based approach.
In considering the majority of NIDS performances are evaluated on outdated data sets, this paper presents the trends and analysis of various labeled NIDS data sets which can serve as replacements. Furthermore, due to the effectiveness and notability of deep learning, Long Short-Term Memory (LSTM) is explored. The performances of LSTM are compared with different machine learning algorithms. Different multiclass and binary classifications are also experimented on unidirectional flow-based CIDDS-001 data set.
Flow-based intrusion detection system
As defined in [2], A network flow is a set of IP packets flowing through an observation point. IP packets headers are aggregated into a particular flow based on common properties such as IP addresses, port numbers and protocol. The aggregation of flows can be either in unidirectional or bidirectional format. Unidirectional implementation creates two different flows from a single conversation. Bidirectional instead, result in only a single flow, stemming from the host who initiated the conversation.
Figure 1 presents the typical architecture for the generation of flow-based traffic. Accounting flows relies on cooperation of two main components: flow exporter and flow collector [1]. The flow records are first generated by the metering process from the passing packets at observation points. Metering process consists of a set of functions for the proper creation of flow records. Thereafter, flow records are passed to the exporting process either when they are expired or end of connection has been detected (in the case of TCP flow).

General flow architecture.
The flow exporter is responsible for sending flow records to one or more flow collector to be later stored for relevant purposes. Various protocols exist for defining the format of flow records and how they are transported [3], but Cisco NetFlow remains the dominant one. Most flow-based data sets reviewed in this paper are also recorded in NetFlow format.
As traffic are now summarized into aggregated views of packet headers, there are both obvious impacts from the use of network flows [4]. Compared to the traditional DPI, a flow-based IDS is both computational and financially efficient [5]. Flow-based approach is better equipped in handling high-speed links as it does not require the analysis, or even decryption of payloads. However, the complete absence of payload during inspection can also be a double-edged sword. The main drawback of a flow-based IDS is its difficulty in detecting network attacks in which the destructive power resides in the payload [1].
DARPA’98 [6] and DARPA’99 [7] are some of the earliest known data sets designed for the assessment of IDS. Extending from DARPA’98, DARPA’99 has included some of the new attack types and Window NT victim machines. Otherwise, both of them were created using the same approaches and the traffic are simulated in an offline military environment. On top of that, the attacks executed in the simulation are further classified into four classes: Denial of Service, User to Root, Remote to Local, and Probes [8].
Following this, Stolfo et al. [9] created the KDDCup’99 data set. The data set was reconstructed from DARPA’98 tcpdump data. The author processed the data into connection records with three main types of features: basic features of single TCP connection, content features suggested by domain knowledge, and traffic features derived from past two seconds. KDDCup’99 remains to be the most used data set since its creation. However, several problems exist in the aforementioned data sets, and were mentioned in few studies [10–12].
Due to the popularity of KDDCup’99, few studies have been attempted to refine the data set. One of the first attempt was conducted by Perona et al [13]. The data set: gureKDDCup was generated by the same methodology in order to replicate KDDCup’99 as accurate as possible while maintaining added features. gureKDDCup data set carries all the features of KDDCup’99 with extra payload information, IP addresses and port numbers.
NSL-KDD data set proposed by Tavallaee et al. [12] is another attempt to solve some of the inherent weaknesses in KDDCup’99. The author has removed all redundant records in both training and testing set in order to eliminate biases toward the frequent records. Furthermore, the selected subsets of records are inversely proportional to their difficulty level of predictions in the original KDDCup’99 data set. This has made the evaluation results of different machine learning methods to be more efficient and precise. Despite that, NSL-KDD still carries few problems discussed by McHugh [10].
In another spectrum, multiple honeypots have been deployed in Kyoto University for the generation of Kyoto 2006+ data set [14]. As only traffic which are directed to the honeypots are captured, most of the traffic are inherently suspicious. Only normal activities which are simulated to produce DNS and mail traffic are captured. The data set contains 14 non-content features from KDDCup’99. Additional 10 features such as indications of attacks, IDS trigger, and malware are included to assist in investigating the present of attacks.
The first labeled flow-based IDS data set is generated by Sperotto et al. [15] in 2009. Similar to the previous data set, the traffic was captured from a honeypot in University of Twente, resulting in a limited view of the network traffic. Even though monitoring of traffic is limited to one honeypot, labeling process still proved to be a complex task. Services such as SSH, Apache web server, and FTP are executed by the honeypot and their log files collected for labelling task.
The second flow-based data set: CTU-13 was created by Garcia et al. [16]. The author focuses on the captures of botnet traffic, along with normal and background traffic. Normal labels are assigned to known and controlled computers in the network, while background labels are assigned to other unknown traffic. The data set consists of 13 scenarios, each with differing malwares and actions. Originally, unidirectional flows was used in [16], but bidirectional flow is later replaced to include much more detailed labels. The data set is also extended to include pcap files of all traffic [17], albeit being truncated due to privacy concerns.
Shiravi et al. [18] established a set of guidelines to adhere to, and follows a systematic approach in generating the UNB ISCX 2012 data set. Two profiles were devised to aid in simulating desirable events: α-profiles describe a set of attack scenarios, and β-profiles contain distribution models for background traffic. The data set covers a total of four multistage attack scenarios, and each scenario uphold to the following attack lifecycle: reconnaissance, identifying vulnerabilities, acquiring access, maintaining access, and covering tracks. Although various protocols were simulated for the background traffic, the data set does not contain HTTPS traces.
Aiming to solve the absence of modern low footprint attacks in KDDCup’99 data set, Moustafa et al. [19] proposed the UNSW-NB15 data set. The data set consists of synthetic normal and abnormal traffic, generated with the aid of IXIA PerfectStorm tool. The generated attacks consist of nine different categories. A total of two simulations are carried out, with varied frequencies of generated attacks. Each simulation is captured until it reaches the size of 50 GB.
After a few years of gap, the trend of labeled flow-based data sets emerges again. UGR’16 data set by Fernández et al. [20] aims to create a data set which can aid in the evaluation of cyclostationary-based NIDS. Flows are captured at a tier-3 ISP located in Spain over a period of four month. Both synthetics and realistic attacks are also included in the data set. The background traffic which contains realistic attacks are labeled though manual analysis and by employing 3 state-of-the art anomaly detectors. Several sources are also referred to assist in labeling blacklisted public IP addresses.
In 2017, CIDDS-001 flow-based data set is published by Ring et al. [21]. The data set contains two sources of traffic: internal OpenStack traffic, and external server traffic which are exposed to the Internet. Within the controlled OpenStack network, a total of four different subnets are designed to emulate the environment of a small business. Each subnet has its own prescribed behaviors and follows the probability distribution of working hours. At the external server, traffic which are not generated by the OpenStack clients are considered unknown for HTTP or HTTPS requests, or suspicious for remaining traffic.
At the time of writing, the most recent data set is CICIDS2017 by Sharafaldin et al. [32]. The data set covers all eleven criteria of the evaluation framework and uses β-profile proposed in previous work [33]. Six different attack profiles were created to include common and updated attacks. Besides, CICFlowMeter [34] is also utilized to extract 83 statistical features for the data set.
Majority studies on network intrusion detection methods evaluate their performances on KDDCup’99 and NSL-KDD [12]. However, both of them are obsolete and are inferior in reflecting modern real world traffic [35–37], since they are essentially based on a 20 years old DARPA’98 data set. A comparison table of the aforementioned data sets are shown in Table 1.
Comparison table of labeled data set for NIDS
Comparison table of labeled data set for NIDS
Data format: R - tcpdump / pcap; NFU - unidirectional NetFlow; P - payload; NFB - bidirectional NetFlow; C – csv; NFD - NetFlow dump; X - xml; FB - bidirectional flow. f1: features derived from headers. f2: features derived from content or application payload. f3: features derived from previous connections. f4: features do not belong to any of the mentioned categories.
Machine learning techniques have since been used to tackle disparate problems. It has the ability of learning and extracting patterns without any explicit programming. However, the performances of traditional machine learning techniques are greatly dependent on the representation of data [38]. Often, it requires domain expertise in order to craft and obtain a fitting representation from raw data.
Deep learning can solve such problem by discovering the suitable representations. It has shown the capability of beating machine learning techniques in many applications with outstanding results [39]. The ongoing wave of interest in deep networks research can be traced back to 2006, when Hinton et al. presented an effective strategy for pre-training Deep Belief Network (DBN) [40]. The surge of interests was further motivated by the advances of Graphical Processing Unit (GPU). The efficiency of GPU in training a deep network has made it much more convenient for experimentation.
Deep belief network
Restricted Boltzmann Machine (RBM) is a probabilistic generative model, it is capable of learning the probability distribution of the inputs for reconstruction. RBM consists of two layers, a visible and a hidden layer. By stacking RBMs, where the hidden layer becomes the visible layer for the next RBM, it forms a Deep Belief Network (DBN) and can arrive in higher level representations [41]. One of the earliest implementation of DBN in NIDS is proposed by Salama et al. [42]. From the literature, DBN of two RBM layers is used to reduce 41 features from NSL-KDD to five output features. DBN is trained using backpropagation and is tested with two different configurations: as classifier by itself, or by using it to perform dimension reduction before applying Support Vector Machine (SVM) as a classifier. Results are compared and the DBN-SVM combination outperform both standalone SVM and DBN. In recent years, DBN-based models received much more attention compared to other approaches. Both Gao et al. [43] and Alrawashdeh et al. [44] have demonstrated the performance increase by implementing more hidden layers for DBN. With a total of four hidden layers, they have achieved high performances on KDDCup’99 data set.
Recurrent neural network
Recurrent Neural Network (RNN) approach in the domain of network intrusion detection also received increasing attention. Unlike a feedforward neural network, a RNN is able to perceive and memorize previous sequences with the introduction of feedback loop that is connected to the previous time step. A three layer reduced-size RNN is proposed by Sheikhan [45], in which the nodes are partially connected between layers. The implementation of this structure allows both effective training speed and improved classification rate on KDDCup’99 data set. Yin et al. [46] also propose the use of RNN in detecting network intrusions. Unlike previous literature, nodes in the hidden layers are now “fully connected”. The author has studied the performance on both binary and multiclass classification. The experimental results show that the performance is of more superior. In another study, Kim et al. [47] adopt Hessian-free optimization algorithm to address the difficulty of handling complex long-term dependencies in RNN. Hessian-free optimization allows faster convergence without computation of Hessian matrix.
The study of deep learning approach in NIDS has received growing attention in recent years. Most of the existing deep learning methods for NIDS are centered around KDDCup’99 and NSL-KDD data sets. In the case of flow-based NIDS, the exploit of deep learning study is lacking.
Long Short-Term Memory
Long Short-Term Memory (LSTM) is a variant of RNN proposed by Hochreiter et al. [48] to solve the long existing problems of exploding and vanishing gradient in RNN. There exist many proposed variants of LSTM architecture. Most modern vanilla LSTM has since comprised of modifications including forget gate [49] and peephole connections [50]. Other notable variants also include a lesser complex Gated Recurrent Unit (GRU) architecture. Results obtained in [51] has shown the dominance of vanilla LSTM in handling various data sets when comparing to other variants of it. Figure 2 illustrate the unfolded version of a 2-layer LSTM network.
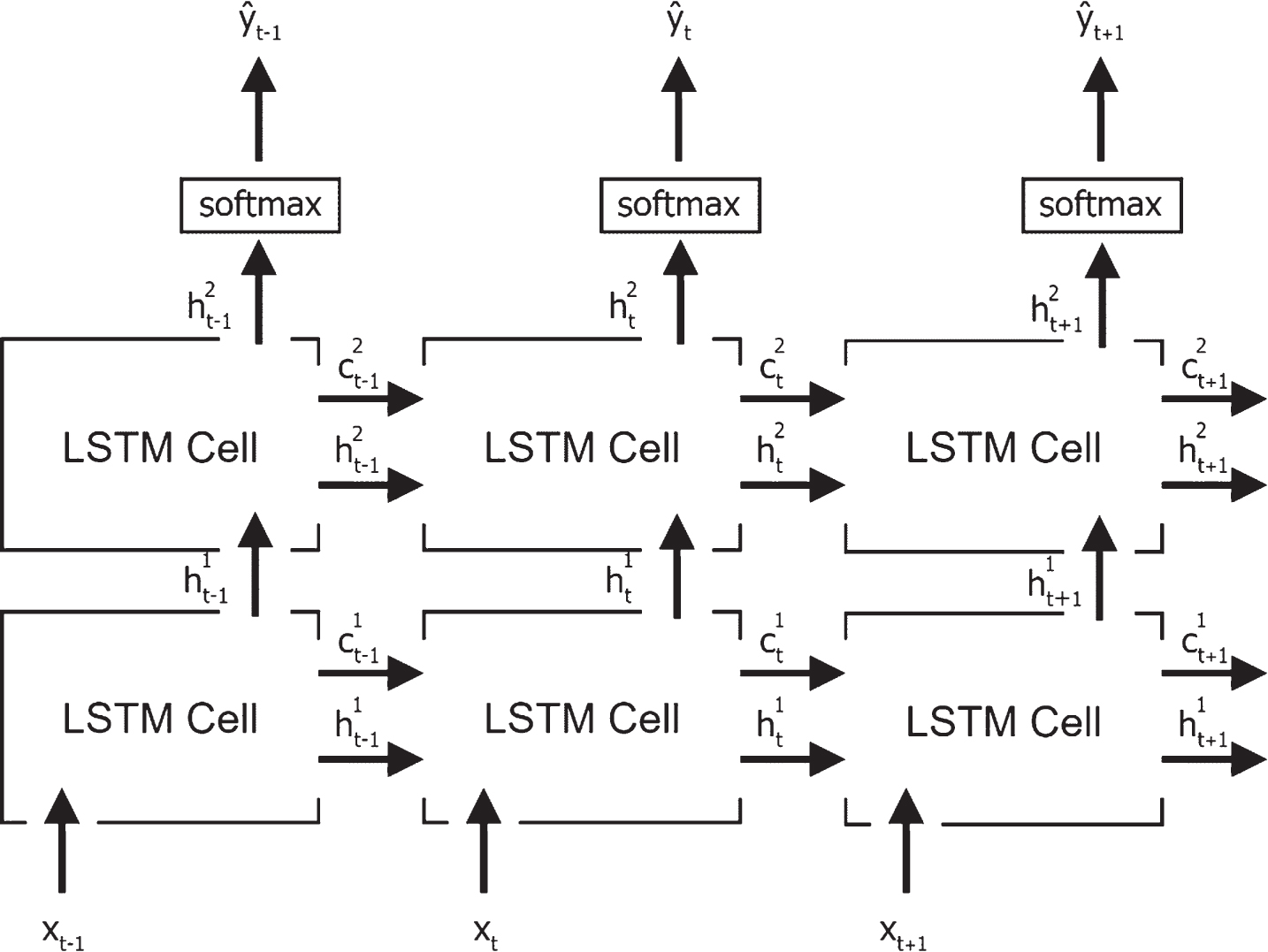
Stacked long short-term memory network.
Formulas below denote the forward-pass of a non-peephole vanilla implementation:
Inside each of the LSTM cells are regulated by three main gates: input gate i t , forget gate f t , and output gate o t at a certain time step t. The gates activation uses element-wise logistic sigmoid function and is denoted by σ. The weights and biases are W and b, for the respective gates or state (4). x t is the input, and ht-1 is the hidden state from previous time step. The updated cell state served as a memory, and is represented using h t . Finally, ⊙ is an element-wise multiplication of two vectors.
The forget gate (1) outputs a value between 0 to 1 to control the decision of either keeping or forgetting the previous states. This is essential in processing unreasonably long and complex tasks, as it allows an LSTM cell to learn when to reset the memory contents.
The CIDDS-001 data set is a flow-based data set that contains two different sections organized based on the location of the traffic captured. In this paper, the traffic recorded in the OpenStack environment is used to evaluate the performance of the models. The first week of the data set is used in training the models, while the performance of the models are evaluated by the second week of the data set. The attributes of the data set consist of more common properties found in a NetFlow record as can be seen in Table 2. Due to privacy concerns, the author has anonymized the first three bytes of the public addresses, as well as replacing the addresses of both DNS and external server.
NetFlow features of CIDDS-001 dataset
NetFlow features of CIDDS-001 dataset
The data set are captured at the OpenStack router over a period of four weeks. In the first two weeks, a total of four different attacks are deployed intermittently alongside other benign activities. The attacks are automated and the characteristic of each attack follows the behavior presented in Table 3. Since unidirectional NetFlow format are captured, class victim is supplied as well, in contrast to the conventional binary normal and anomaly labels. The additional victim label is given to the flow if the Dst IP Addr is the source of an attack. Table 4 shows the number and type of flows captured in the OpenStack environment.
Attacks executed in OpenStack environment
Classes of CIDDS-001 OpenStack dataset
Preprocessing stage
In this stage, all features are preprocessed before employing them to train the models. The start time of the flow is first converted into two dimensions. The two dimensions represent sine and cosine wave which spans for one week.
Protocol, flags, and type of service attributes are then transformed into binary vectors representations. Binary encoding is used to represent protocol fields, while one-hot encoding is performed on the latter two. The resulting attributes are encoded into dimensions of five for protocol attribute, and four for both flags and type of service.
The flows attribute is also removed from the data set, as the value remains identical for all instances throughout the weeks.
In the case of IP addresses, binary encoding results in poor performances and one-hot encoding is not applied due to their sizeable distinct elements. Instead, IP addresses are bucketized into seven different categories based on the identity and locality available on the hosts. IP addresses which originated from the OpenStack network are mapped into respective subnets of either “server”, “management”, “office”, or “developer”. As for the hosts residing outside the network: DNS server, external server, and public addresses are each given a category to represent them.
In this experiment, port addresses are treated as numerical values, and the performances are compared with the binary encoded ports.
The features of the data set are then normalized into the range of [0,1] using Min-Max normalization technique (6). The parameters of the normalization are calculated on the first week and are applied on both training and testing set. x
i
denotes the value of ith feature, whereas min(x
i
) and max(x
i
) represent the minimum and maximum value of ith feature in training set respectively.
The goal of an IDS is to have minimal False Positives (FPs) and False Negatives (FNs). Sensitivity is prioritized if the protection of an asset is of utmost importance. Specificity otherwise, when efficiency is concerned [37]. The cost of misclassification in this domain is relatively expensive [52], as every false positive on the attacks requires the time of security analyst in investigating the reported incident. Meanwhile, an attack which bypasses the detection of an IDS can results in serious damages.
Some of the more common metrics used in this experiment are as shown below. The first metric is Sensitivity, it also goes by the name of True Positive Rate (TPR) or recall. Sensitivity is used to measure the rate at which all instances of a positive class (anomalous events) are classified as it is.
The next metric used is Precision (PPV). Precision of a particular class is defined as the rate at which all the predicted instances of a class are really true:
TP denotes the number of correct predictions on positive class (anomalous traffic). TN denotes the number of correct predictions on negative class (benign traffic). FP denotes the number of prediction on anomalous instances are not actually anomalous. FN denotes the number of anomalous instances that are not detected.
The number of instances in the data set are skewed towards the normal class much like most of the NIDS data sets. In comparing the performances of multiclass classifications, macro averaged values of the aforementioned metrices (7, 8) are used. Macro averaging allows the treatment of differing classes to have the same weights regardless of the number of instances in each class. The formulas are denoted by:
Where |C| denotes the total number of instances in class λ.
A total of five notable machine learning algorithms: C4.5 (better known as J48 in Weka), Random Forest, Hoeffding Tree, Naïve Bayes, and Support Vector Machine are employed in this experiment. The classifiers are trained and tested in the same manner by using the machine learning software: Weka.
As for the deep learning method, vanilla variant of LSTM (without peephole) is used and its performance is compared as well alongside other classifiers. The experiments for LSTM are designed with the aid of open source framework: TensorFlow 1.4.
All the aforementioned models are evaluated based on four different classifications as shown: 2-class: normal and anomaly. 5-class: normal traffic, with four different types of attacks. 3-class: normal, attacker and victim. 9-class: normal traffic, four different types of attacks including attacker and victim label.
LSTM model is trained with disparate combination of hyperparameters as shown in Table 5, and their results are observed at 50th epoch. The performances of the models do not deteriorate substantially within the specified scope of hyperparameters. To aid in the convergence of the model, both Xavier initialization and Adam optimizer are used. Gradient clipping is also applied to control exploding gradients.
LSTM Models of varied Hyperparameters
LSTM Models of varied Hyperparameters
λ1: Sequence length; λ2: Mini-batch size; λ3: Hidden units; λ4: Hidden layers; λ5: Learning rate; λ6: Dropout rate.
Table 6 shows the results obtained from using the hyperparameters mentioned in Table 5. Across four classification tasks, the model: L8 which has the decent trade-off between FPs and FNs is taken to be compared with other machine learning classifiers.
Performance results of LSTM with varied Hyperparameters
Results of vanilla LSTM and various models are summarized in Tables 6 and 7. The abbreviations of different models are used to denote the respective models. Table 7 captures the results when port addresses are treated as numeric values. Meanwhile, Table 8 presented the gain of performance in which the ports are binary-encoded. The amount of change in performance is relative to the results obtained in Table 7. No significant differences are observed in comparing the results of preprocessed ports. In some cases, the binary-encoded modification only performs slightly better than leaving the port numbers untreated.
Performance comparison on numeric-valued ports
Performance gain on binary encoded ports
From Table 7, it can be observed that the vanilla LSTM is able to achieve consistent results while achieving optimal sensitivity and precision trade-off in most classification tasks.
Naïve Bayes algorithm is able to obtain the highest sensitivity in 5-class and 9-class classification tasks. However, it suffers greatly from false positives by having benign traffic predicted as attacks, resulting in lowest precision compared to other models. Whereas in the case of J48 and Hoeffding Tree, the opposite held true. They have comparatively low performances in sensitivity, which are caused by anomalous traffic not being detected (FNs).
In the case of SVM, high performances are achieved in binary and 3-class classification tasks. But the outcome in 5-class and 9-class diminished, as it fails to detect both ping scan and brute force activities.
Another observation is the low performances in both sensitivity and precision. This is caused by the losses in FPs and FNs from each class, since they are evaluated with the same weight without taking number of instances into consideration (9-10). The effect is undermined even further by the failure in detecting brute force attacks by all classifiers.
All things considered, the exceedingly high accuracies of the classifiers are in part due to the use of flow information in detecting probes and DoS attacks [36]. The confusion matrices on the LSTM model: L8 are illustrated in Fig. 3.

Confusion Matrices of LSTM model: L8. The results of all classification tasks: 2-class (top left), 5-class (top right), 3-class (bottom left), and 9-class (bottom right) are taken on 50th epoch. Across each row represents the instances of the actual class, while predictions are represented across each column.
In this paper, all labeled network IDS data sets have been reviewed and compared in view of the widely popular yet outdated DARPA’98 data set. In the application of NIDS, the adoption of network flow in contrast to the conventional DPI approach is also examined. Furthermore, various machine learning algorithms, including a deep learning model: LSTM, are deployed to be evaluated based on a flow-based data set. One of the latest unidirectional NetFlow CIDDS-001 OpenStack data set is prepared to aid in the evaluation. The models are then compared and studied in both binary- and multi-class classification tasks. From the experiment results, the capability of vanilla LSTM in handling flow-based traffic is shown.
Footnotes
Acknowledgments
This research work was supported by a Fundamental Research Grant Schemes (FRGS) under the Ministry of Education and Multimedia University, Malaysia (Project ID: MMUE/160029).