
Abstract
Emotion recognition is one of the most important components of human-computer interaction, and it is something that can be performed with the use of voice signals. It is not possible to optimise the process of feature extraction as well as the classification process at the same time while utilising conventional approaches. Research is increasingly focusing on many different types of “deep learning” in an effort to discover a solution to these difficulties. In today’s modern world, the practise of applying deep learning algorithms to categorization problems is becoming increasingly important. However, the advantages available in one model is not available in another model. This limits the practical feasibility of such approaches. The main objective of this work is to explore the possibility of hybrid deep learning models for speech signal-based emotion identification. Two methods are explored in this work: CNN and CNN-LSTM. The first model is the conventional one and the second is the hybrid model. TESS database is used for the experiments and the results are analysed in terms of various accuracy measures. An average accuracy of 97% for CNN and 98% for CNN-LSTM is achieved with these models.
Introduction
The ability to comprehend and respond to human feelings is essential to successful human-machine interaction. Humans can hide their expressions in faces easily at that time it is difficult to find accurate emotions in such cases speech signals are very helpful and it is difficult to hide their voices compared to the face. Speech is the most straightforward and effective method of communication available to humans. Emotion identification through the analysis of speech signals has many potential uses, including in contact centres, classrooms, lie detectors, security systems, healthcare, video games, and more [1]. There are two primary components to any speech emotion detection system: feature extraction from speech signals and classification of those features according to emotional states [2]. A wide variety of speech parameters, including pitch [3], zero crossing rate, formants, signal energy [4], maximum amplitude, Mel Frequency Cepstral Coefficients (MFCC), etc. [5], are employed in speech analysis. After features are extracted, they are fed into a classifier like a Gaussian Mixture Model (GMM) [8, 9], Support Vector Machine (SVM) [6, 7], a Decision Tree [8, 10], a Bayesian Network model [9], or a Nearest Neighbor [10].
Researchers are focusing more of their time and energy on Deep Learning methods currently. When confronted with a problem, deep learning algorithms use a comprehensive learning cycle. In the subject of emotion recognition from audio signals, two of the most current approaches to be employed are convolutional neural networks and long short term memory networks. These two methods are addressed as being among the most recent methods used. Emotional speech can be recognised using either a one-dimensional or a two-dimensional CNN-LSTM model, both of which are described in [11]. The IEMOCAP and Berlin EmoDB public databases served as the experimental platforms. The outcomes demonstrate that 2D CNN-LSTM outperforms its 1D counterpart. Following the high-level feature extraction performed by Convolutional layers, the LSTM model is utilised to hold long-term dependencies, and finally, two dense layers round up the CNN+LSTM architecture suggested in [12]. The SAVEE database was used to conduct the study. Emotional speech identification based on spectrograms is explored in [13]. Here, the Spectrograms are fed into a CNN model. The following chapters constitute the various parts of this investigation. Following an explanation of the database in Section 2, which is followed by explanations of the architectures of Convolutional Neural Networks (CNN’s) and Long Short Term Memory Networks- (LSTM’s) in Sections 3 and 4, Section 5 describes the models used in this work for speech emotion recognition, which are CNN and CNN-LSTM, Section 6 discusses the investigational results, Section 7 is a Comparative analysis, and Section 8 is the Conclusion. Section 1 is an introduction to the database.
Database
Toronto Emotional Speech Set (TESS) was established to study how ageing affects emotion perception. Two female actresses – 60 and 20 – comprise this dataset. Each actor simulated seven emotions for 200 neutral sentences. This dataset includes disgusted, angry, neutral, delighted, astonished, terrified, and sad. 56 undergraduates were asked to label the dataset by recognising emotions from utterances. The dataset comprised utterances with over 66% confidence after the identification exercise. TESS is at
Convolutional Neural Networks (CNN)
CNN: An overview
The Convolutional Neural Network (CNN) is widely regarded as one of the most significant models for deep learning. CNNs have been demonstrated to be useful in a wide variety of contexts, including the categorization of text, the investigation of documents, computer vision, object detection, and the processing of images. The convolution stage, the pooling stage, and the fully connected layer are the three fundamental building layers that are utilised in convolution neural networks, as described in [14]. These stages are respectively the convolution stage, the pooling stage, and the fully connected layer. Figure 1 presents a diagram of the primary CNN’s underlying architecture.
Architecture of Simple CNN.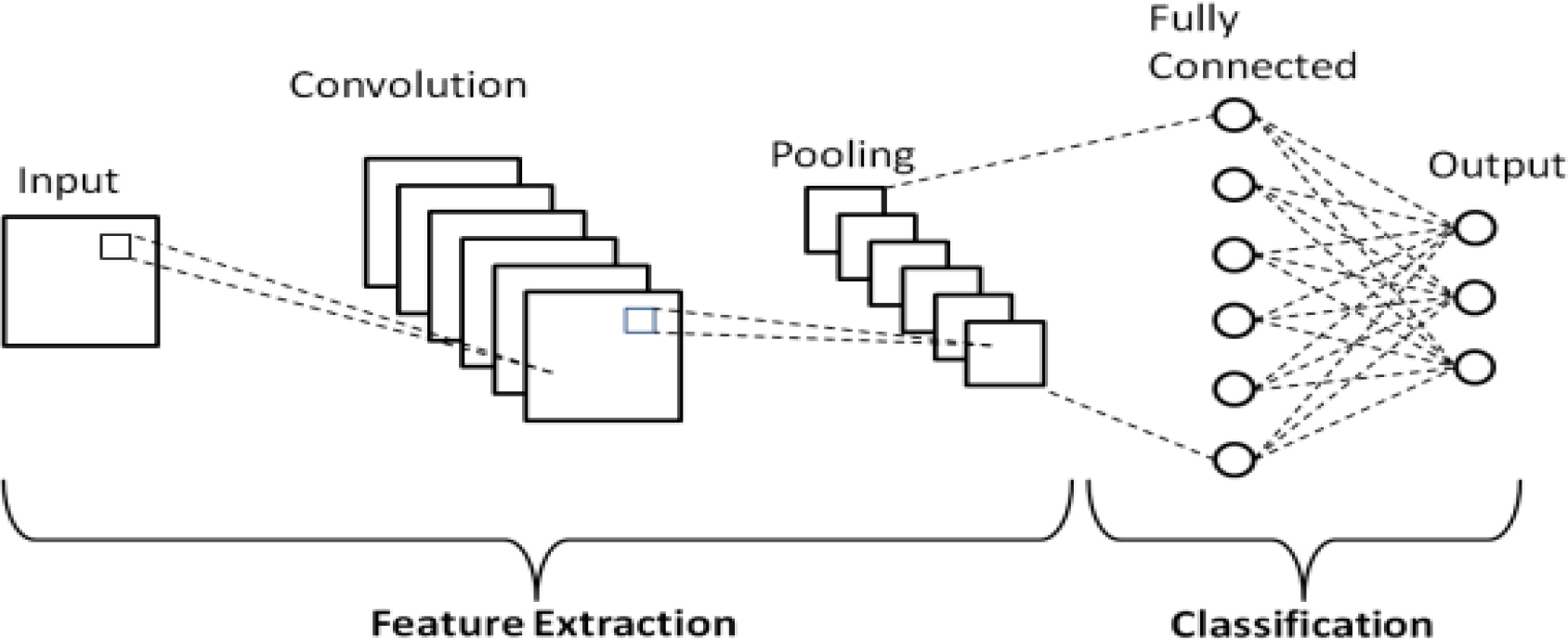
The Convolutional Layer (CL) is an essential component in the construction of neural networks. The function of feature extraction is carried out by the convolution layer in a CNN design. In order to extract, one uses the helpful characteristics that are found in the convolution layer of the inputs. The technique of convolution consists of doing nothing more complicated than applying a filter to the input in order to generate activation. When the same filter is used multiple times, a type of map of activations known as a feature map is produced. The formation of these feature maps is accomplished by passing incoming data through a number of different filters. The 1D and 2D convolution processes are illustrated respectively in Figs 2 and 3, respectively.
1D Convolution operation of n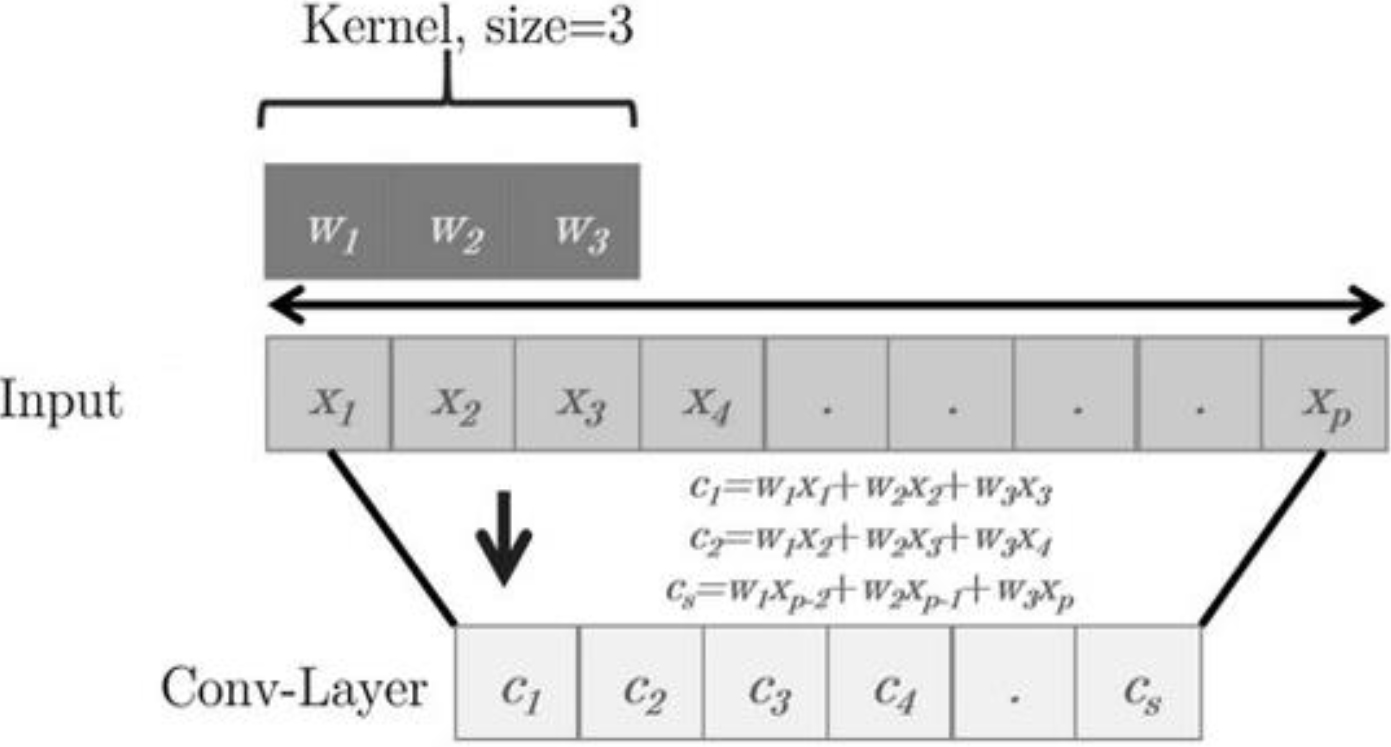
Convolution in two dimensions performed on a 5 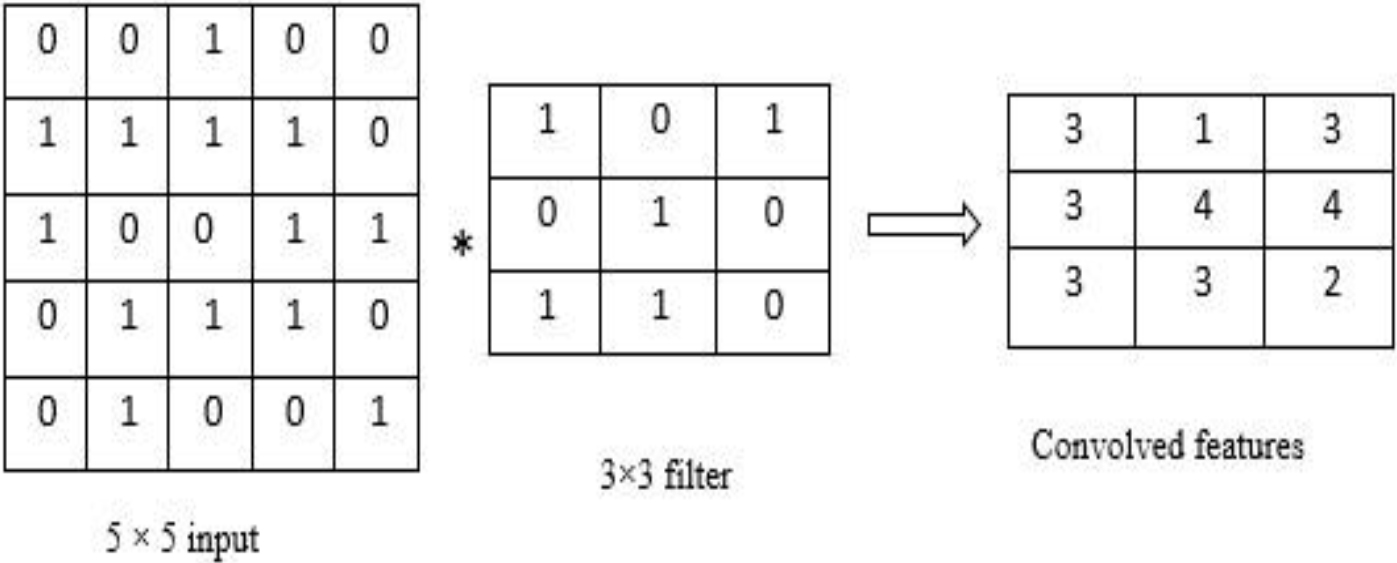
The pooling layer’s purpose is to cut down on the size of the convolved features as much as possible. Just taking into account the information that is most relevant to the problem at hand will cut down on the amount of computation that is required to progress the data. Two common strategies for pooling data are the maximum pooling and the average pooling. The Max pooling method is employed to obtain the segment with the biggest value, and the Average pooling procedure is utilised to acquire the segment with the values that are representative of the segment on average. Figures 4 and 5 illustrate an example of maximum and average pooling in both a one-dimensional and a two-dimensional setting, respectively.
1D max and average pool operations with pooling size 2.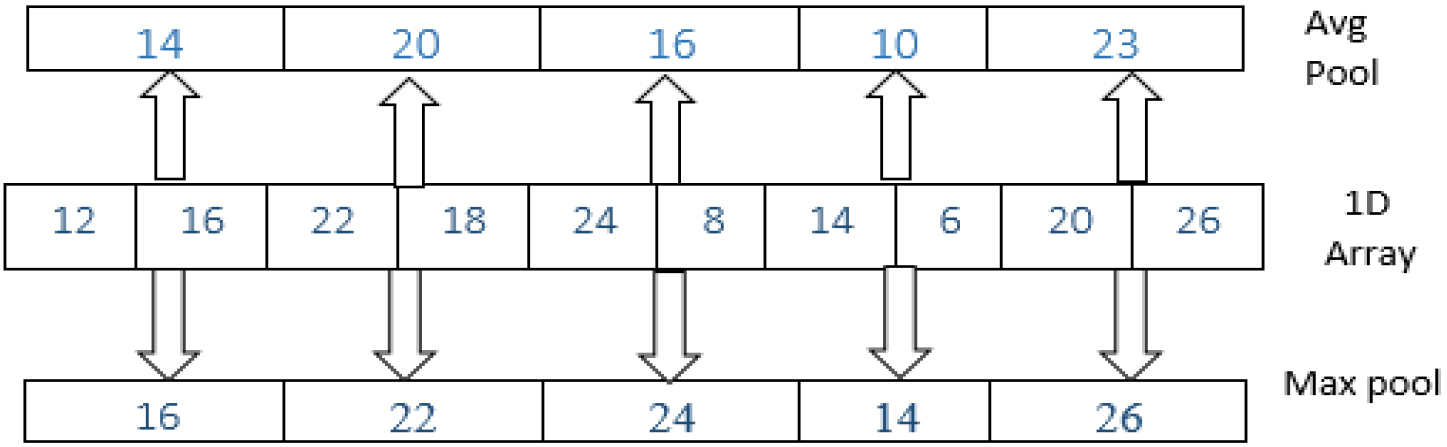
2D pooling with stride 2.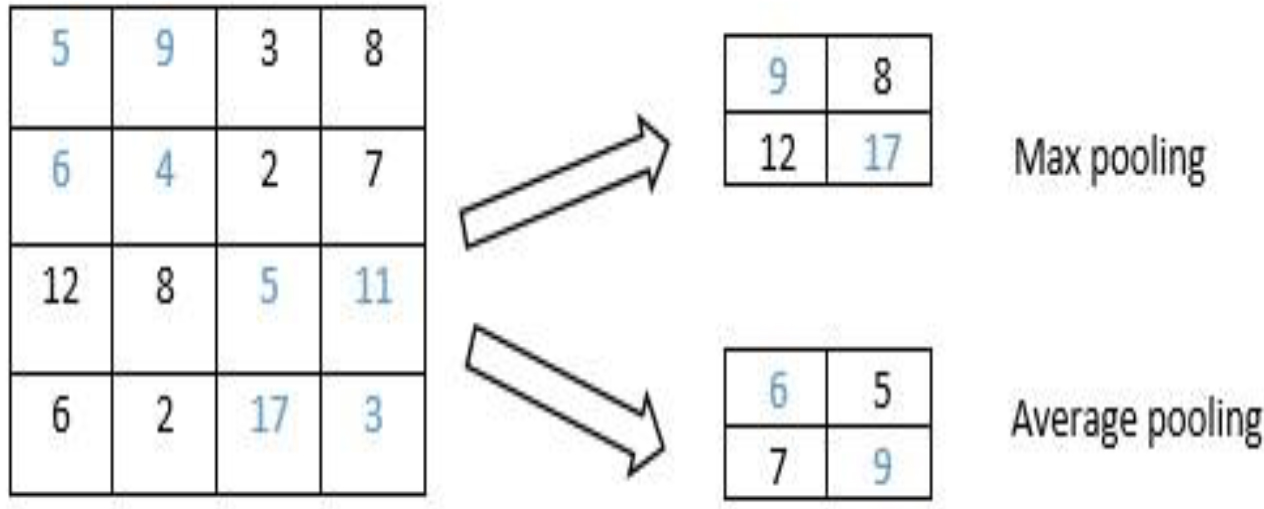
It creates a 1D array by mixing the inputs from the layers that came before it. The number of classes serves as the determinant for the output dimensions. Figure 6 is the example of a small fully-connected layer with four input and eight output neurons.
Fully Connected layer.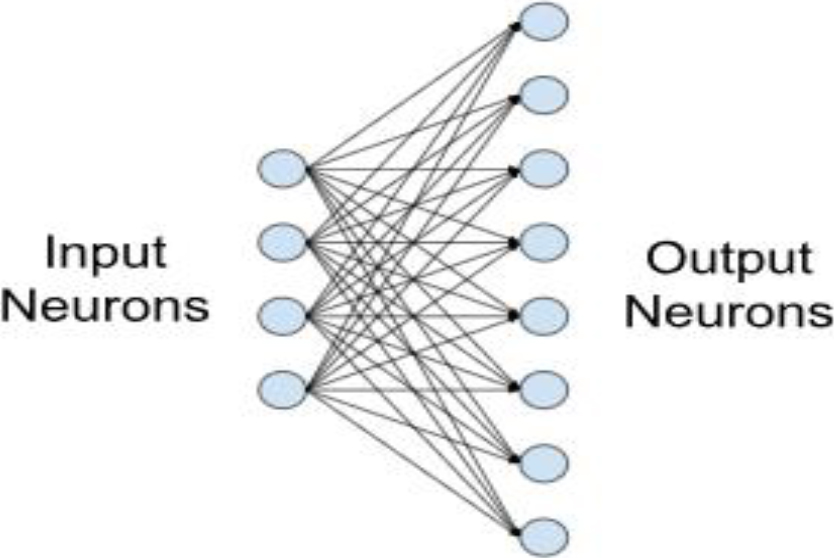
The word that is used is “rectified linear unit,” also written as “ReLU.” Once the feature maps have been collected, they need to be imported into a ReLU layer for further processing. The process of cancelling out all of the negative pixels in an image is carried out by ReLU in a step-by-step manner. As a consequence of the network changing into a non-linear structure, a rectified feature map is generated [15]. The graph of a ReLU function is presented here in Fig. 7.
ReLU function.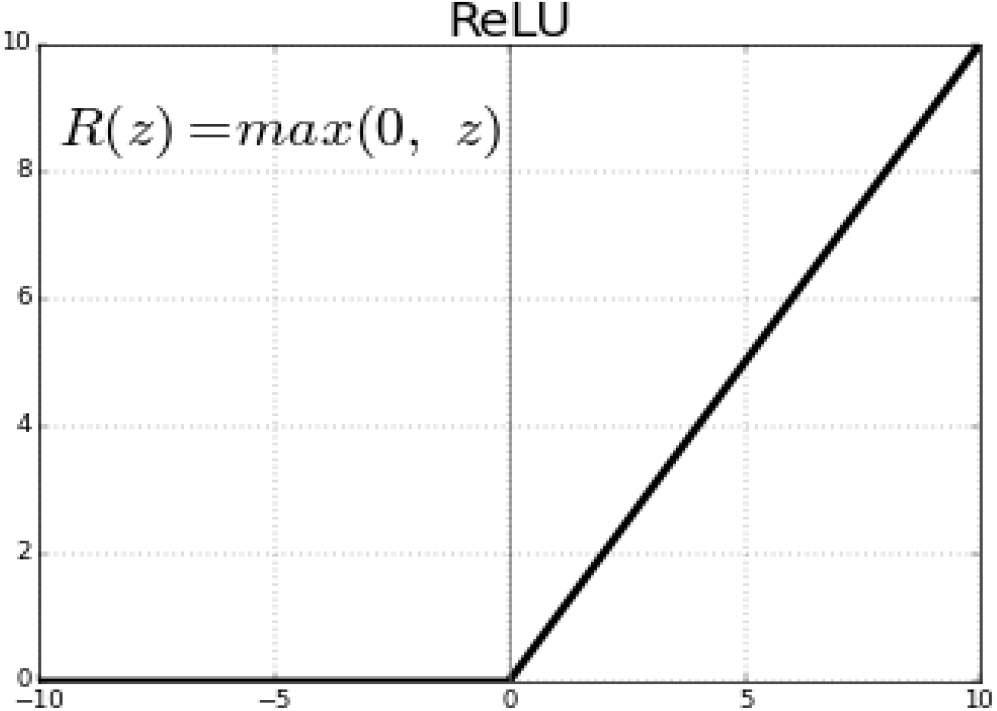
a) Without Dropout; b) With Dropout.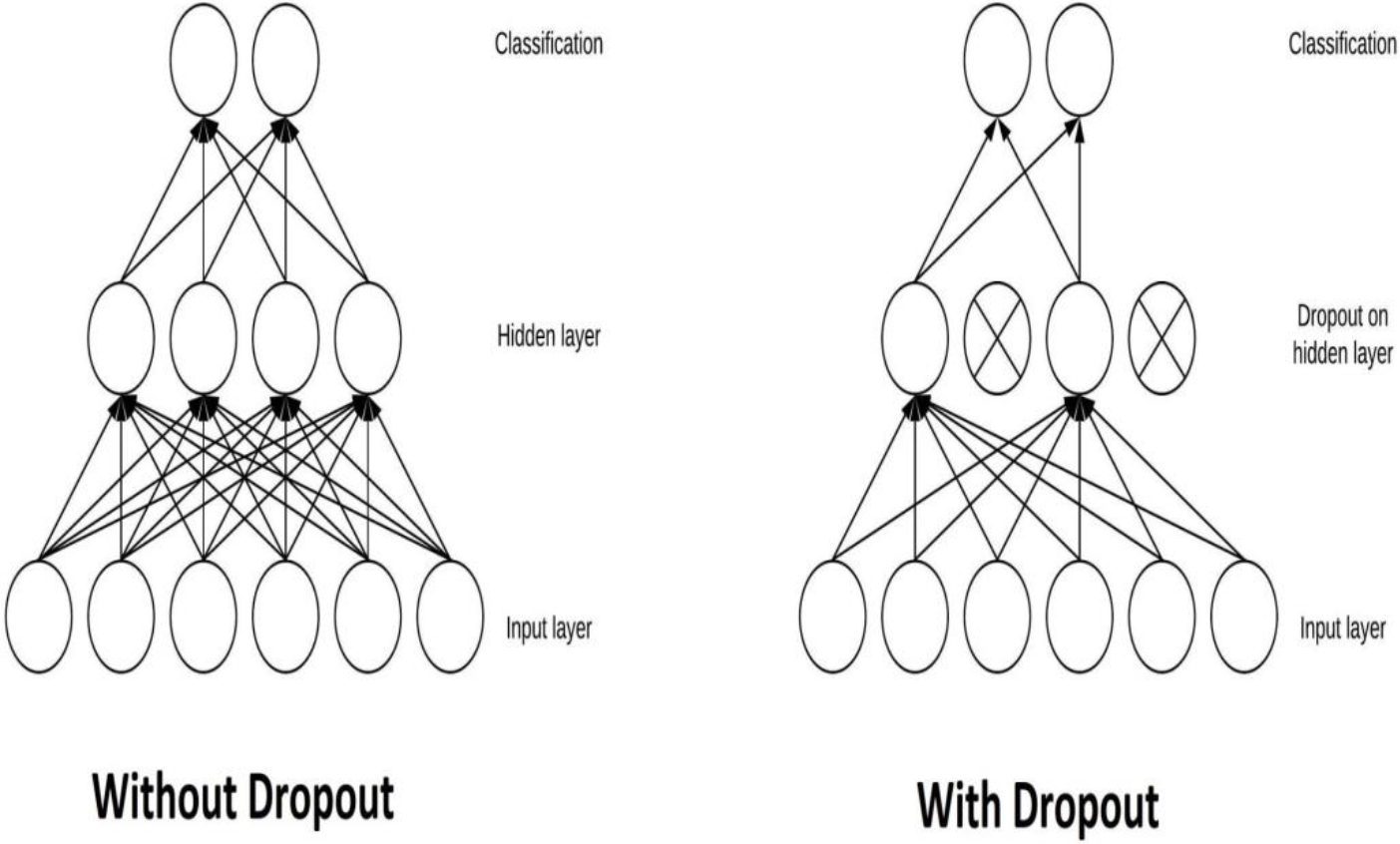
Dropout is a method of regularisation for neural networks that helps to mitigate the effects of overfitting [16]. As shown in Fig. 8, Dropout takes random samples from a Bernoulli distribution and zeroes out part of the connections of the input tensor with a probability
Softmax activation.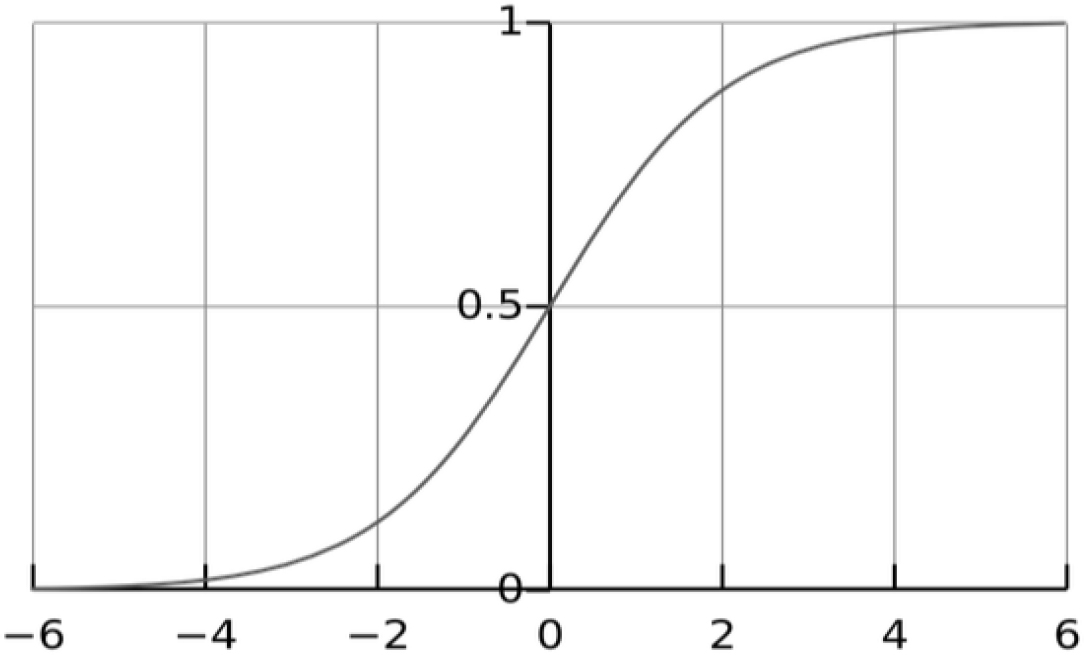
The softmax function can also be referred to by its alternate name, softargmax. This function’s objective is to normalise the output of neural networks so that it falls somewhere in the range of 0 and 1, as specified in [17]. The graphic depiction of the softmax function can be seen in Fig. 9, which can be seen below.
The formula for the SF is given below.
The value of Softmax is calculated by taking the exponent of each individual input vector and dividing that number by the total exponents for all of the inputs.
It measures how well a model fits data. If forecasts differ from goal values, the loss function number will be higher. If not, it will be lower. CNN’s Cross Entropy Loss Function checks the model’s reliability after applying the Softmax Function [18]. This optimises neural network performance. Figure 10 shows that when the expected probability falls, the log loss (entropy loss) increases quickly.
Loss function graphical representation.
The formula for the Loss function is given below.
True and approximated distributions are
Long-term data storage is possible with the complicated RNN LSTM. Data determines whether the network keeps memory. Gating maintains the network’s long-term dependencies [19]. Network gating allows memory release or retention. LSTM cells have three gates. Figure 11 shows that the Forget gate comes first, followed by the Input and Output gates.
Cell of LSTM with gates.
LSTM Cell states.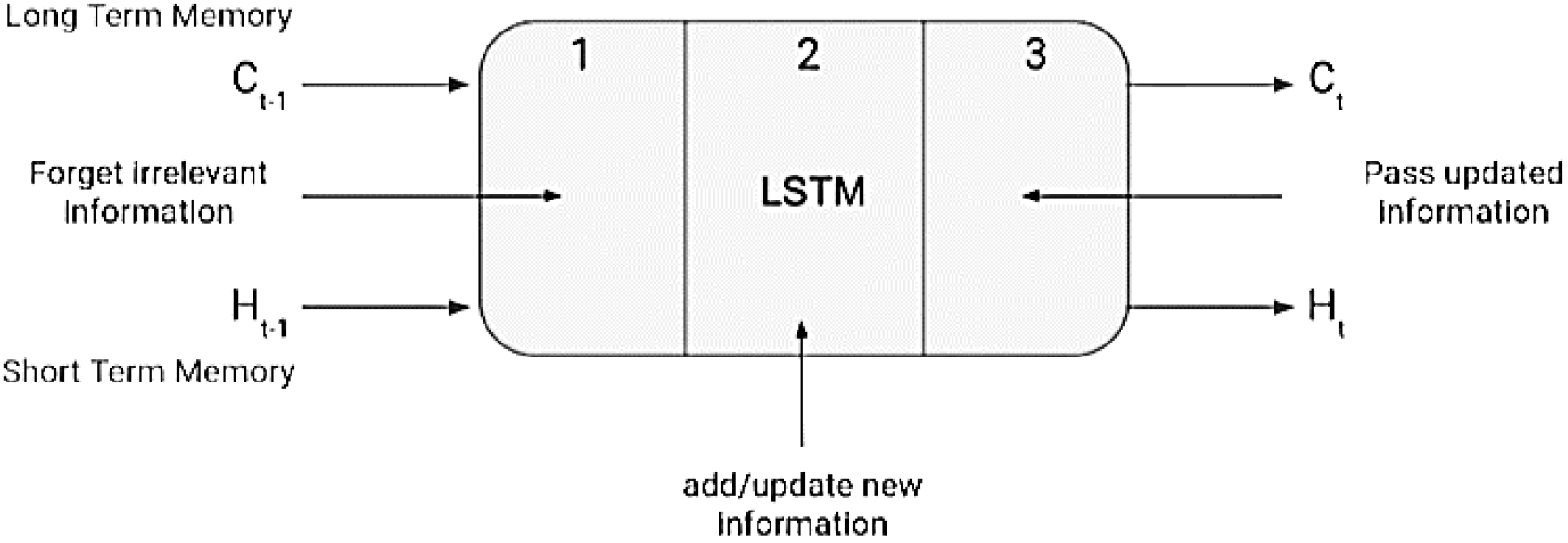
Working of LSTM cell.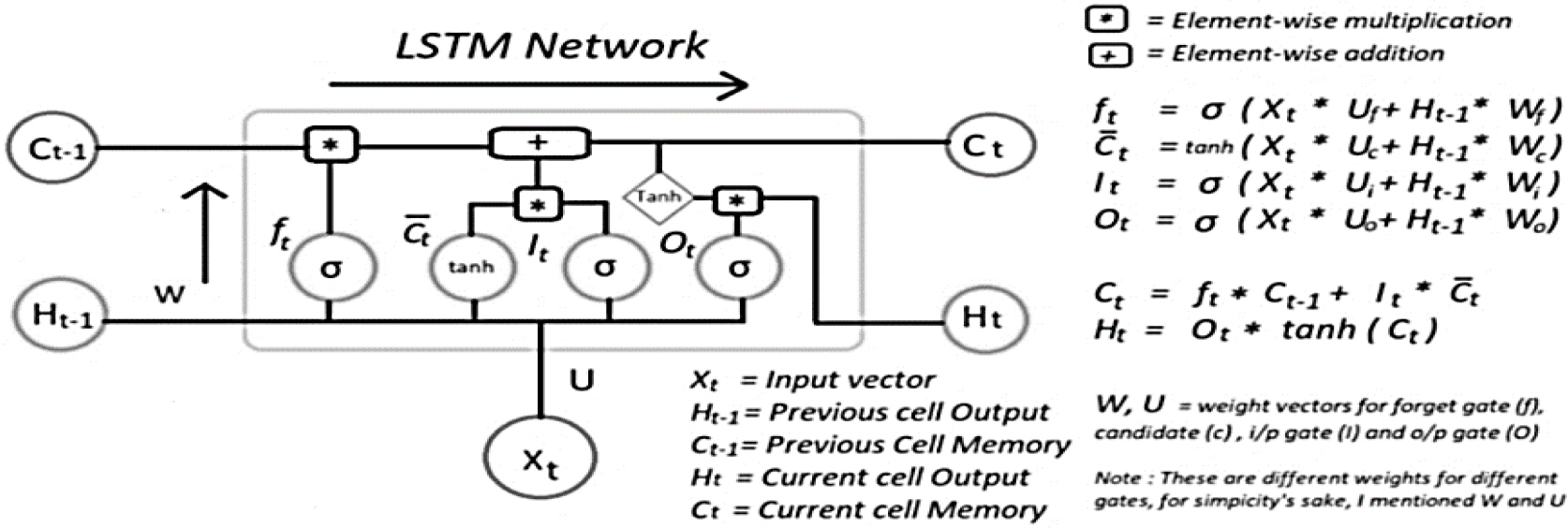
The hidden state of an LSTM, which is identical to a simple RNN, is
Under the parameters of this discussion, both the concealed state and the cell state are associated with short-term memory. The LSTM operation is broken down into its basic steps and depicted in Fig. 13.
When you multiply something by a vector that is somewhat near to zero, you are working towards the goal of erasing the memory of what came before. Adjust the forget gate such that it is set to 1 to let the old memories pass through.
Where
Where
The sigmoid function guarantees a 0 to 1 output value. We’ll utilise the modified cell states in the following equation to find the hidden state. This will reveal the hidden state.
Long-term memory (
Voice emotion recognition is the focus of this study, which employs both the CNN and CNN-LSTM neural network designs in its analysis (Convolution neural network – Long short term memory network). The trials were carried out with the help of the TESS dataset.
CNN architecture
The below is the CNN architecture
1 2 1 1 The ReLU function is used as an activation function in all layers of the network with the exception of the output layer.
Vector shapes with CNN architecture.
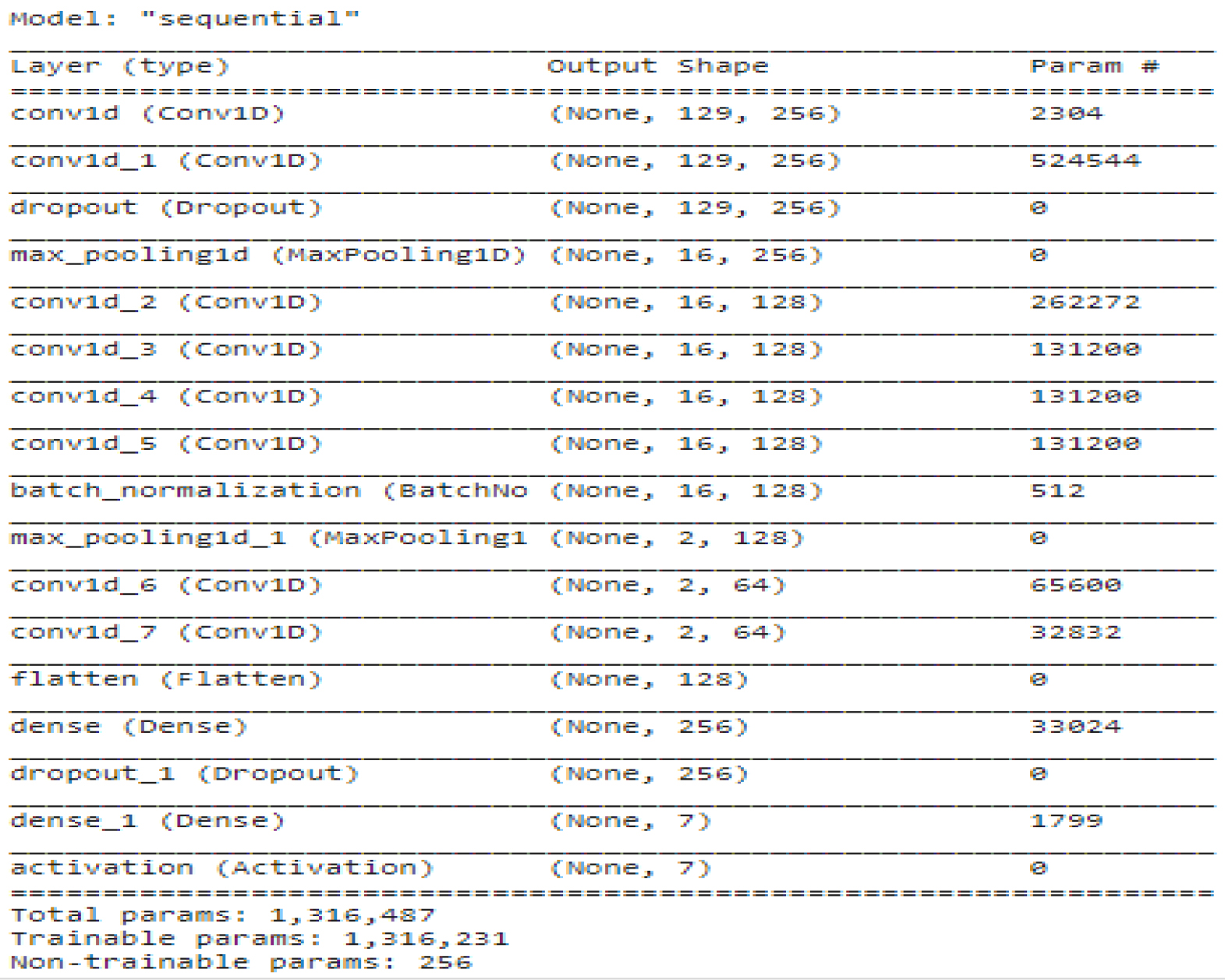
The CNN model’s Keras implementation may be found presented below Table 1 in the following location: This section will provide a deeper dive into the architecture of the CNN, including a discussion of the input and output vector forms that are depicted in Fig. 14.
CNN model based Keras implementation
For optimal results in vocal emotion identification, it is recommended to work with a hybrid Convolution LSTM model. The CNN-LSTM model can be broken down into two distinct components with regard to its architecture. The initial step is the production of time series sequential data from the speech stream, followed by the fusion of CNN and LSTM layers. A recurrent neural network, also known as an LSTM, feeds its data back into itself while a convolutional neural network, on the other hand, processes spatial data. A recurrent neural network can also be referred to as an LSTM. The performance of recurrent neural networks is considerably increased when the data is presented in a sequential order. Long short-term memory (LSTM) is able to recognise patterns across time, but convolutional neural networks are only able to recognise patterns in space. The power of this fusion, which takes the best features of both neural networks and integrates them, is not to be under estimated. Figure 15 presents the CNN-LSTM model for your perusal.
CNN-LSTM ARCHITECHTURE.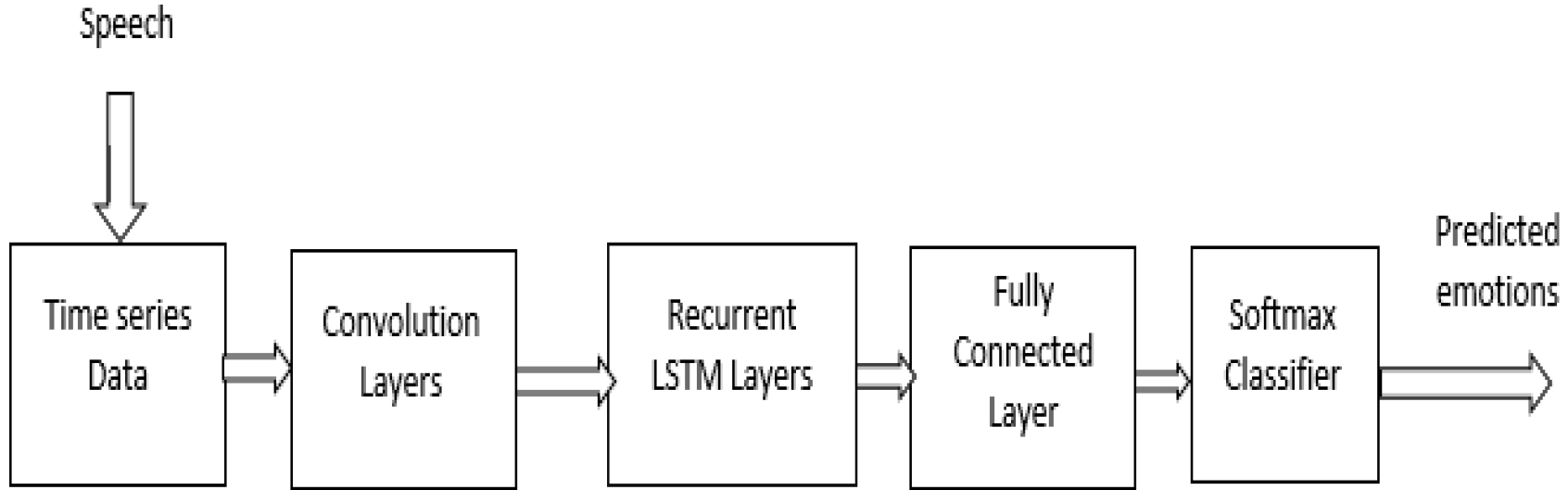
The audio sample is initially converted into a one-dimensional vector, and then it is fed into a one-dimensional network. Convolution layers are utilised in order to discover the regional characteristics of the sample. After being reshaped, the features obtained from the convolution layers are ultimately used as input for an LSTM layer. The characteristics that are derived from the LSTM layer contain both short-term and long-term contextual information that has been incorporated. The completely connected layer (FC) is distinguished by its flattened input, which indicates that each neuron in the layer receives its input from every other neuron in the layer. This is the defining feature of the fully connected layer. In order to prevent over fitting, drop out is inserted after the dense layer. The final layer of this design is referred to as the Softmax classifier, and its function is to classify different emotional states according to the learning properties that they contain. In this particular instance of the model, the categorical cross-entropy serves as the loss function, and the Adam optimizer is the tool that is utilised to locate the best possible answer. Using Google Colaboratory in conjunction with a GPU backend that has 12 gigabytes of Memory was used to carry out the evaluation. The task was accomplished with the help of Google Colaboratory, which included a GPU back end and 12 gigabytes of RAM in its configuration. Using the application programming interfaces provided by Tensorflow and Keras is necessary in order to import the CNN and LSTM layers.
The below is the Structure of the CNN-LSTM model
1 2 4 Two layers of convolution, each with 64 channels of an 8 One layer of maximum pooling, each with an 8 256 LSTM internal units comprising the LSTM layer 1 layer that is dense with 256 units 1 layer that is dense with 7 units of softmax The ReLU activation function can be found throughout the network, with the exception of the output layer, which does not contain this function.
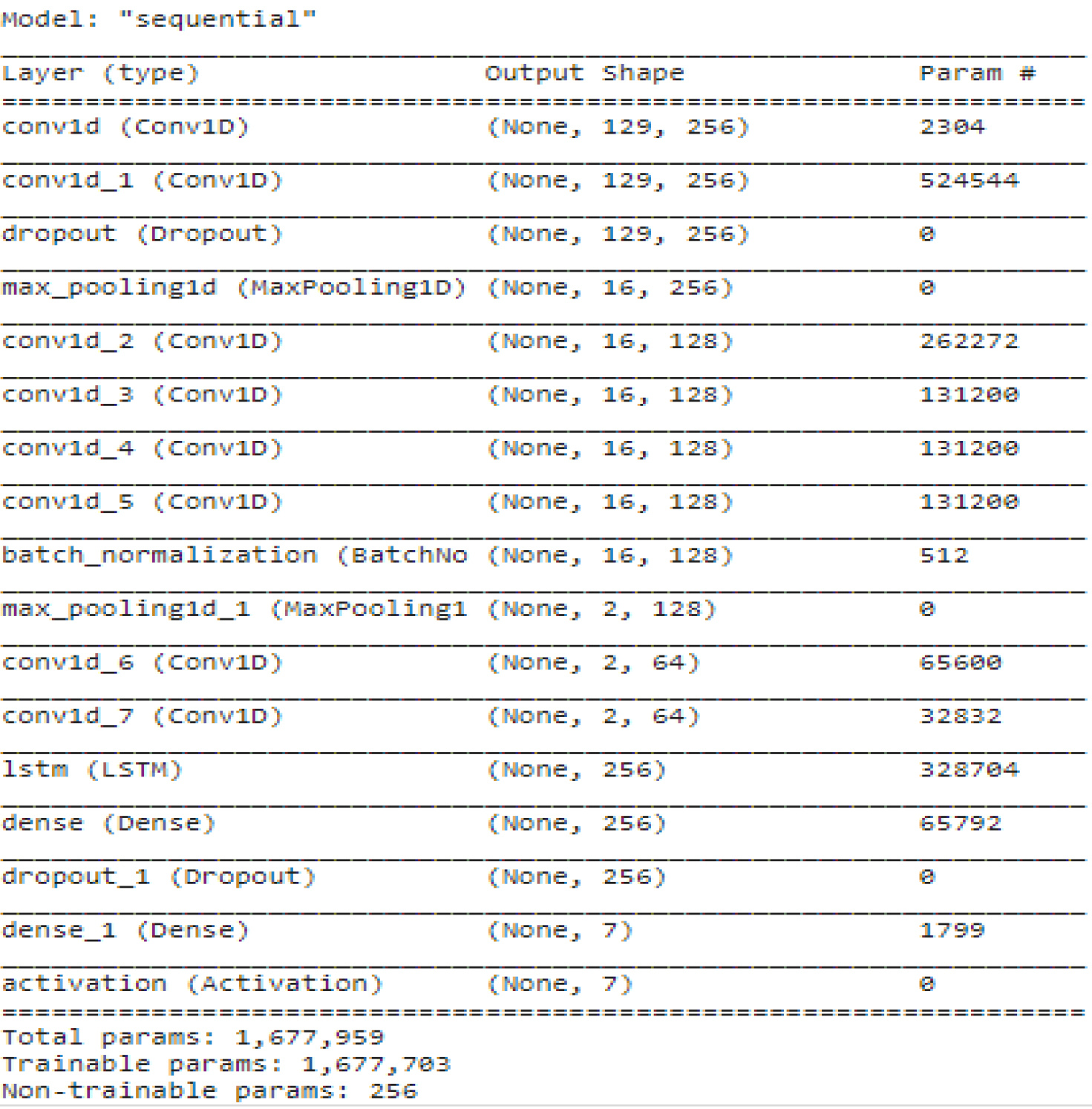
Vector shapes analysis using CNN-LSTM.
Table 2 shows the CNN-LSTM model that is displayed in the Keras implementation, which can be seen further down on this page. This is a deeper dive into the CNN-LSTM architecture, including a discussion of the input and output vector forms that are depicted in Fig. 16.
CNN-LSTM based Keras implementation
The subsequent section presents the results of the tests conducted on the numerous models that were used in this investigation. The F1 score, sensitivity, precision, accuracy, and specificity were the markers of performance that were used for this study [21]. The phrases true positive (TP), false positive (FP), false negative (FN), and true negative (TN) are utilised for the purpose of defining metrics (TN).
Where TP
One method that can be used to evaluate the precision of a measurement is to take the total number of samples and divide it by the number of correct samples.
One definition of sensitivity explains it as the proportion of correct diagnoses that are obtained in comparison to the total number of correct diagnoses and erroneous negative results combined.
As compared to the total number of true negative cases and false positive cases, the ratio of the number of true negative instances to the total number of true negative cases and false positive cases should be high for a test to be considered to have a high level of specificity.
The proportion of precisely anticipated positive occurrences in relation to the total number of expected positive cases is one way to quantify precision.
The
Figure 17 is an illustration of the outcomes of fitting the data, and it is based on the CNN architecture.
Figure 18 depicts a plot of the model’s accuracy vs its loss in terms of accuracy. Both the loss and accuracy values are impacted when the number of epochs in the calculation is altered. In the below graphs
Table 3 contains an illustration of the confusion matrix for the testing data, which includes 280 different samples. In addition, Table 4 presents the performance metrics of the model that were generated making use of the confusion matrix. These metrics may be found in the previous section.
CNN based Confusion Matrix (CM)
CNN based Confusion Matrix (CM)
Analyzing fitting by using CNN.
While determining the accuracy, specificity, and sensitivity of the model, it is necessary to take into account not only true negatives (TN), but also true positives (TP), false positives (FP), and false negatives (FN), in addition to true negatives (TN). True positive is denoted by the letters TP, while false positive is denoted by FP and true negative is shown by TN. The results of the CNN model’s performance evaluations are presented in Table 4.
Performance analysis using CNN
Confusion Matrix (CM) by using CNN-LSTM
Using CNN Accuracy and Loss comparison.
Upon the completion of the aforementioned computations, the
The results of fitting the data are illustrated in Fig. 19, which uses the CNN-LSTM architecture as its foundation.
Figure 20 displays the accuracy and loss curves, which were generated by employing the CNN-LSTM model.
The confusion matrix for the test data is presented in Table 5. It includes 280 samples representing the seven distinct emotions of anger, disgust, fear, happy, neutral, and sad, as well as surprise.
Performance analysis using the CNN-LSTM
Performance analysis using the CNN-LSTM
Performance analysis of CNN and CNN-LSTM
Results of Fitting by using the CNN-LSTM architecture.
Table 6, which can be seen below, provides an evaluation of the CNN-LSTM model’s performance, which was utilised in this research. The evaluation can be found below.
According to the calculations that were presented earlier, the
The TESS dataset is utilised in this work for the purpose of voice emotion identification. There are a total of 2800 samples included in the speech data set, of which only 280 are chosen for testing. The results that were obtained for the CNN and CNN-LSTM networks are presented in Table 7.
CNNs can recognise patterns in space, but LSTMs do better in time. CNN and LSTM are combined in the CNN-LSTM model. This combo is efficient and more accurate than CNN alone. The following table compares deep learning methods for voice emotion identification.
Comparison of proposed study with other existing works
Comparison of proposed study with other existing works
Implementation parameters
Loss &Accuracy by using CNN-LSTM.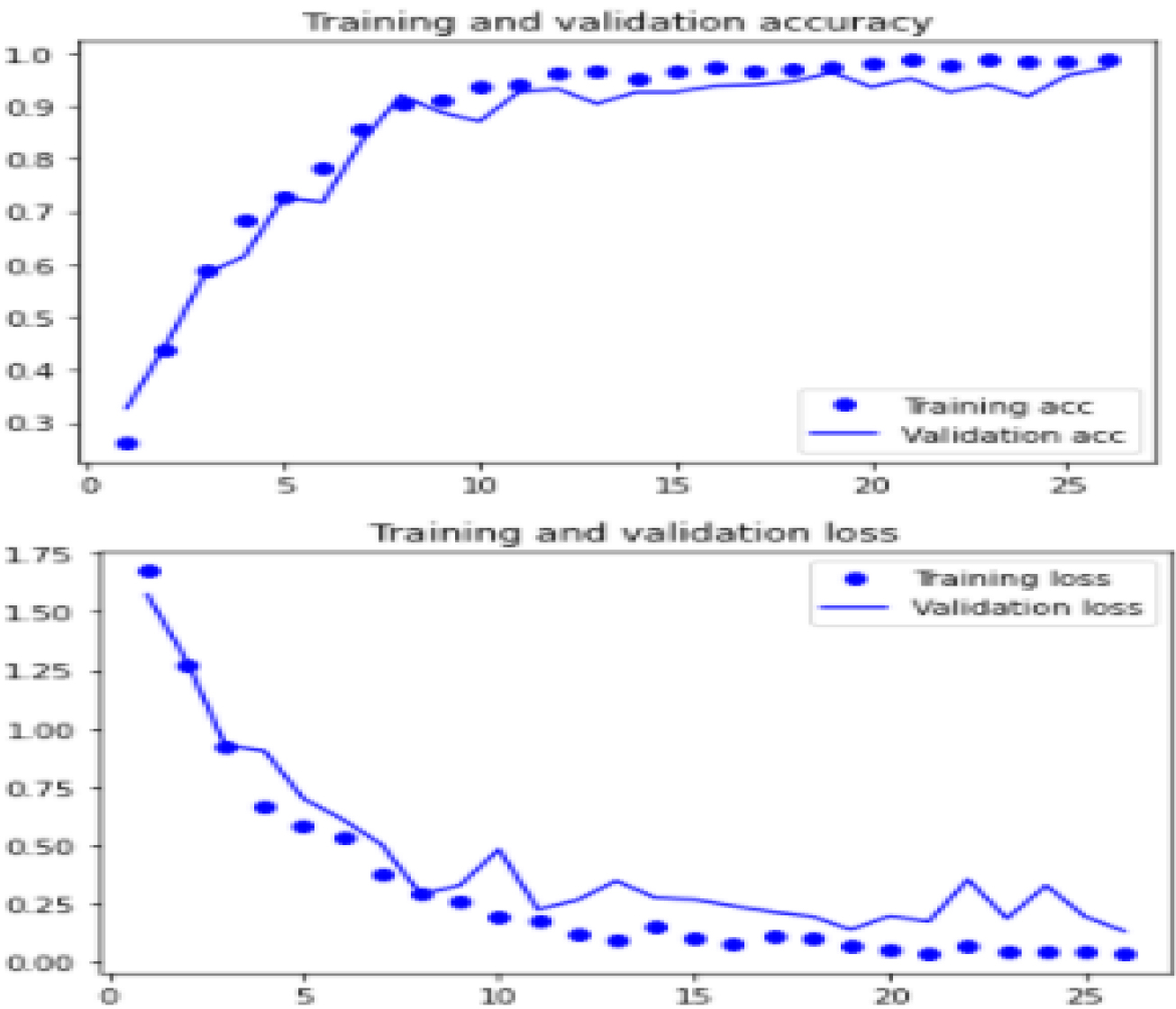
Our CNN-LSTM model achieved the best accuracy, 98%, for the recognition of speech emotions when compared to all of the other research that is currently being carried out.
The below Table 9 shows some of the implementation parameters for all the two models used in this work. The classifier used for the models is the Softmax classifier and the optimizer is the Adam optimizer and the loss function is categorical cross entropy. The Regularization used for all the models is Batch normalization. And some of the parameters like Dropout, Epoch size, and Batch size are the same for all two models.
Conclusions
Both CNN and CNN-LSTM models are utilised in this research for the purpose of speech emotion identification based on the signals produced by the speaker. The architecture used in this work is CNN LSTM. This architecture uses the advantage of both CNN and LSTM. CNNs are powerful for learning local patterns in data, while LSTMs are effective at capturing long-term dependencies in sequential data. Combining these two types of networks can result in improved performance for time series classification tasks. The TESS database served as the testing ground for the experiments. The research were analysed with the help of the TESS database. If you use the CNN model, you will achieve an accuracy of 97%, but if you use the CNN-LSTM model, you will achieve an accuracy of 98%. In contrast to the CNN model, the CNN-LSTM model was successful in achieving a high level of accuracy.
Future Scope: In the present work the CNN-LSTM architecture is tested with speech signals only. In future the model will be developed for EEG and ECG signals also.