
Abstract
This paper presents a technique to detect the six affective states of individual using audio cues. Bi-spectral features extracted from entire speech signal and voiced part of speech are used to create feature vectors. For classification K-Nearest Neighbor (KNN) and Simple Logistic Classifiers (SL) are used. eNTERFACE audio-visual emotional speech corpus that consists of six archetypal affective states: Fear, Anger, Disgust, Sad, Happy, and Surprise is considered. The performance of the system is analyzed based on features obtained from voiced part of speech and features obtained from the entire speech signal. The work proposed is first of its kind in affect computation, where a compact 13-dimensional Bi-spectral features extracted from the voiced speech segments is able to yield promising performance. A considerable improvement of 8.46% – 27.6% recognition rate is achieved with the proposed methodology compared to the existing approaches using emotion samples from the same speech corpus adding novelty to the proposed work.
Introduction
Affect is a physiological term used to describe feeling or emotion. Affective state of a human is characterized by the change in the feeling tone and by physiologic change in behavior. The factors that are responsible for change in affective state are self-esteem, confidence, abuse, physical ill health, family loss or breakup etc. [1]. There are different modalities that can be used to recognize the affective state of a human. They are speech, facial expressions, blood volume pulse, facial electromyography, galvanic skin response, visual aesthetics and their amalgamations can be used [2, 3]. Among these modalities speech is widely used since it provides information about human’s affective state as well as his demands and intentions. The applications of our proposed work include medicine, e-learning, monitoring, entertainment, law, marketing etc. In medicine, it can be used in analyzing the patient’s feelings about the treatment and understanding the client’s affective state during the counseling and based on that analysis better treatment and counselling can be provided.
There are four main units in speech emotion realized system viz. Speech Corpus, Pre-processing, Feature Extraction and Classification. The first unit is the Speech Corpus that consists of a collection of speech samples of different emotions viz. anger, disgust, fear, happiness, sad, surprise etc. There are many speech corpus available on human’s affective state such as AFEW speech corpus, SAVEE speech corpus and eNTERFACE [4]. Preprocessing unit consists of windowing, framing and pre-emphasis [3]. We use Pre-emphasis to enhance the high frequencies in the signal. Feature extraction unit involves extraction of various speech features such as wavelet features, spectral features and temporal features. Features like pitch, short-time energy, Zero crossing Rate (ZCR) etc. are time domain features. Mel Frequency Cepstral Coefficients (MFCC), Bi-spectral, spectral roll off etc. are frequency domain features [5, 6]. Classification is the final unit. The input to the classifier are the extracted features, which determine the affective state of the speech signal. Few examples of classifiers are Simple Logistic, K-Nearest Neighbors (KNN), and Sequential Minimal Optimization (SMO) [7]. Usage of compensation technique’s like Cepstral Mean Normalization, Speaker and stressed information based compensation leads to improvement in the recognition rate [8].
Various methods are proposed in literature to extract the affective state of human. H. Hermansky and N. Morgan studied the affective state recognition and extracted the relative spectral features (RASTA) based upon the perceptual linear prediction (PLP) using Hidden Markov Model (HMM) based Gaussian Mixture Model [9]. M. Swain et al. presented a method on extracting various prosodic features like pitch, Zero crossing, Teager Energy Operator, Jitter, Shimmer, log energy and MFCC features using Hidden Markov Model (HMM) and Support Vector Machine (SVM) [10]. Schuller, B. et al. [11] suggested an approach to extract Low-Level Descriptors combinations using Support Vector Regressor (SVR) for further empirical analysis. Metallinou et al. [12] presented an approach to extract Mel-Frequency Cepstral Coefficients, Mel-Frequency bank Coefficients, pitch, energy and first derivatives using Hidden Markov Model (HMM) for further practical analysis. Eyben et al. [13] did further pragmatic analysis and proposed an approach to extract acoustic LLD’s using Long Short Term Memory-Recurrent Neural Network (LSTM-RNN). Sayedelahl et al. [14] recommended an approach to extract Short-time energy, MFCC and Fundamental Frequencies using SVR using radial basis function kernel for better analysis. Rosas et al. [15] suggested an approach to extract Pause duration, pitch, intensity and loudness using SVM with Linear Kernel for further analysis.
This work aims to recognize the affective state of a person using Bi-spectral features from the entire speech and from voiced part of speech. Simple Logistic and K-Nearest Neighbor classifiers are used for classification. An insights into the system performance with the use of each classifier on the Bi-spectral feature set is analyzed.
The paper has been organized in following manner: Section 2 discuses about the proposed algorithm, Section 3 gives the experimental background, Section 4 explains the experimental results and analysis, Section 5 provides the Comparison with the existing works and Section 6 gives conclusion and future directions.
Proposed framework for affective computing using audio cues
Proposed model consists of three stages viz. Preprocessing, Extraction of Features and Classification. The illustration of proposed work using features determined from the entire speech and from voiced part of the speech signal is shown in Fig. 1.
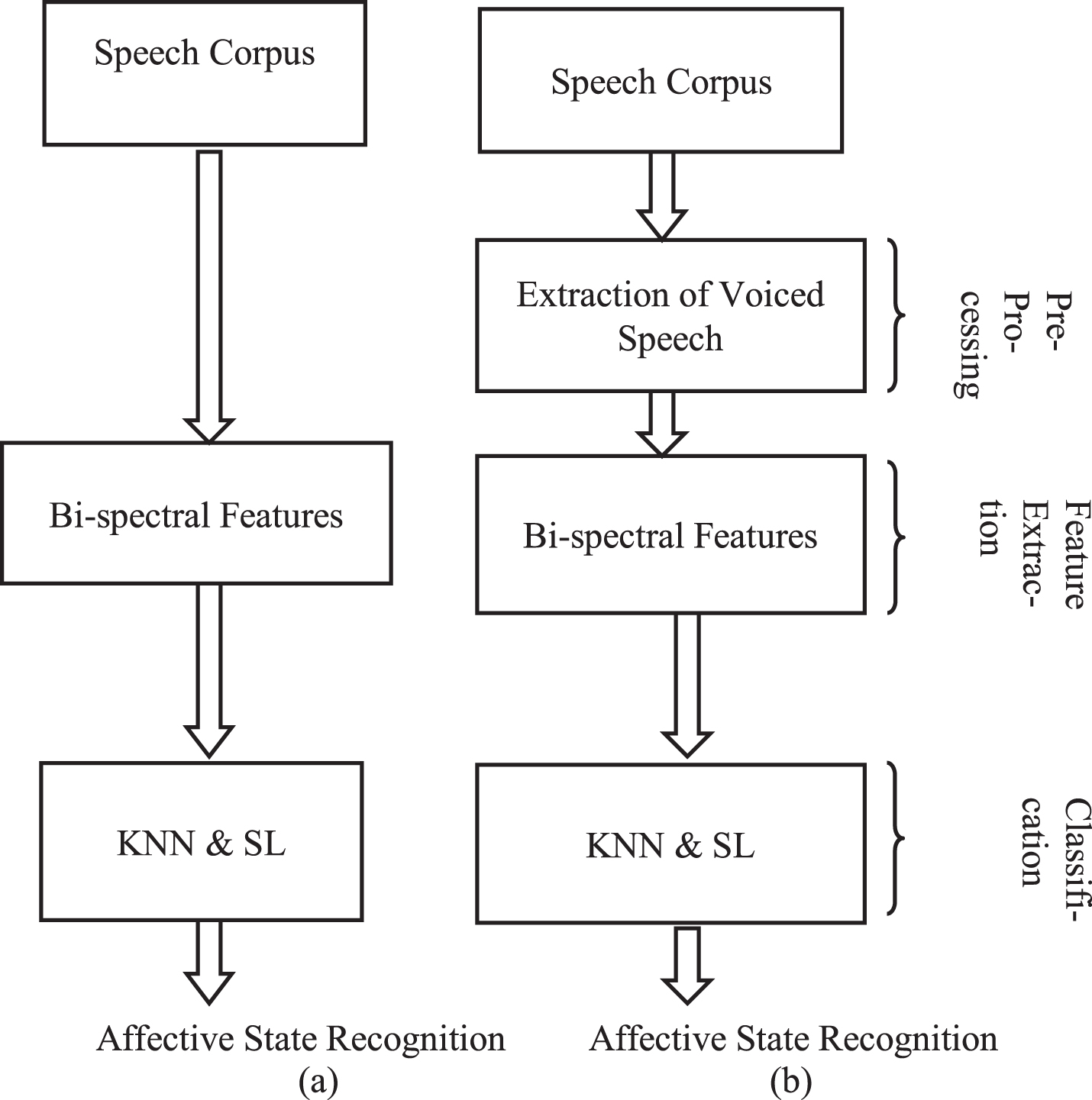
Block diagram of proposed model (a) Using Entire Speech signal (b) Using Voiced Speech.
In order to create a new document, do the following: eNTERFACE is the corpus considered in this work. It is an audio-visual corpus with emotion samples from six affective states viz. anger, disgust, fear, happy, sad and surprise. The speech corpus consists of emotion samples recorded from forty two subjects from fourteen different countries. Here, audio samples are extracted from the video. It consists of 1293 audio samples. The affective states anger, disgust, fear, sad and surprise contains 216 audio samples and happy state contains 213 audio samples. These recording are done with 44.1 kHz sampling frequency [16].
Pre-processing
Voiced sections from the speech signal are extracted in the pre-processing stage. The vibration of vocal cords produces the voiced speech. As observed in Fig. 2, voiced part of speech will have periodic nature.
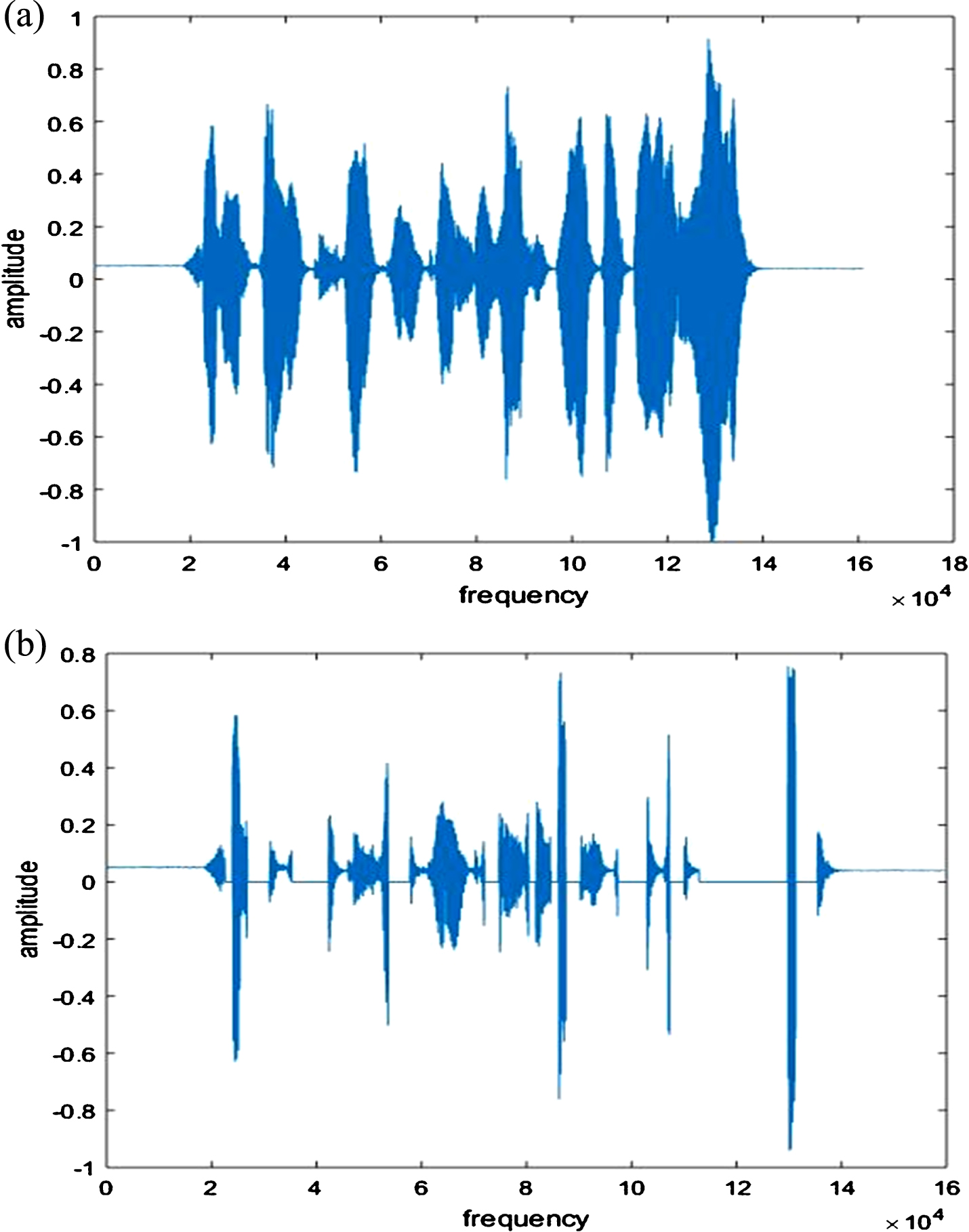
(a) Entire speech signal (b) Voiced speech.
Pitch parameter is used to extract the voiced speech. Pitch determines the sound quality controlled by the vibrations causing it and plays a prominent role in the detection of voiced section in speech. If pitch can be determined from a speech segment, it indicates that the segment is voiced. The voiced part of the speech signal is identified by finding the endpoints using Zero Crossing Rate and Energy. Zero-crossing rate plays a prominent role in voiced/unvoiced classification. It indicates the rate of change of signals from positive to negative and vice versa. Zero crossing rate is less for voiced speech whereas high for unvoiced. Energy calculated from speech is capable of determining the voiced/unvoiced portions in speech. The voiced speech has high energy whereas the unvoiced speech has low energy. The speech signal is divided into segments using framing. Then, the signal is multiplied with a hamming window to reduce the discontinuities present in each ends of the segments. Next, the average power of each frame is computed to find the Short time Energy (STE). A high Short Time Energy and a low Zero Crossing Rate indicates that the segment of speech is voiced [17].
The flow process for extracting the voiced speech segments is depicted in Fig. 3. Initially, framing is done to divide the speech signal into several segments. Hamming window with size 32 ms is applied to smoothen edges of each frame, while the sampling frequency is 44.1 kHz. Thus, each frame consists of 1411 samples. Next, to find the voiced part of the speech, endpoints are detected. The endpoint detection is performed to obtain the beginning and end of relevant partitions and it is accomplished by calculating the Zero-Crossing Rate and Energy from the signal.
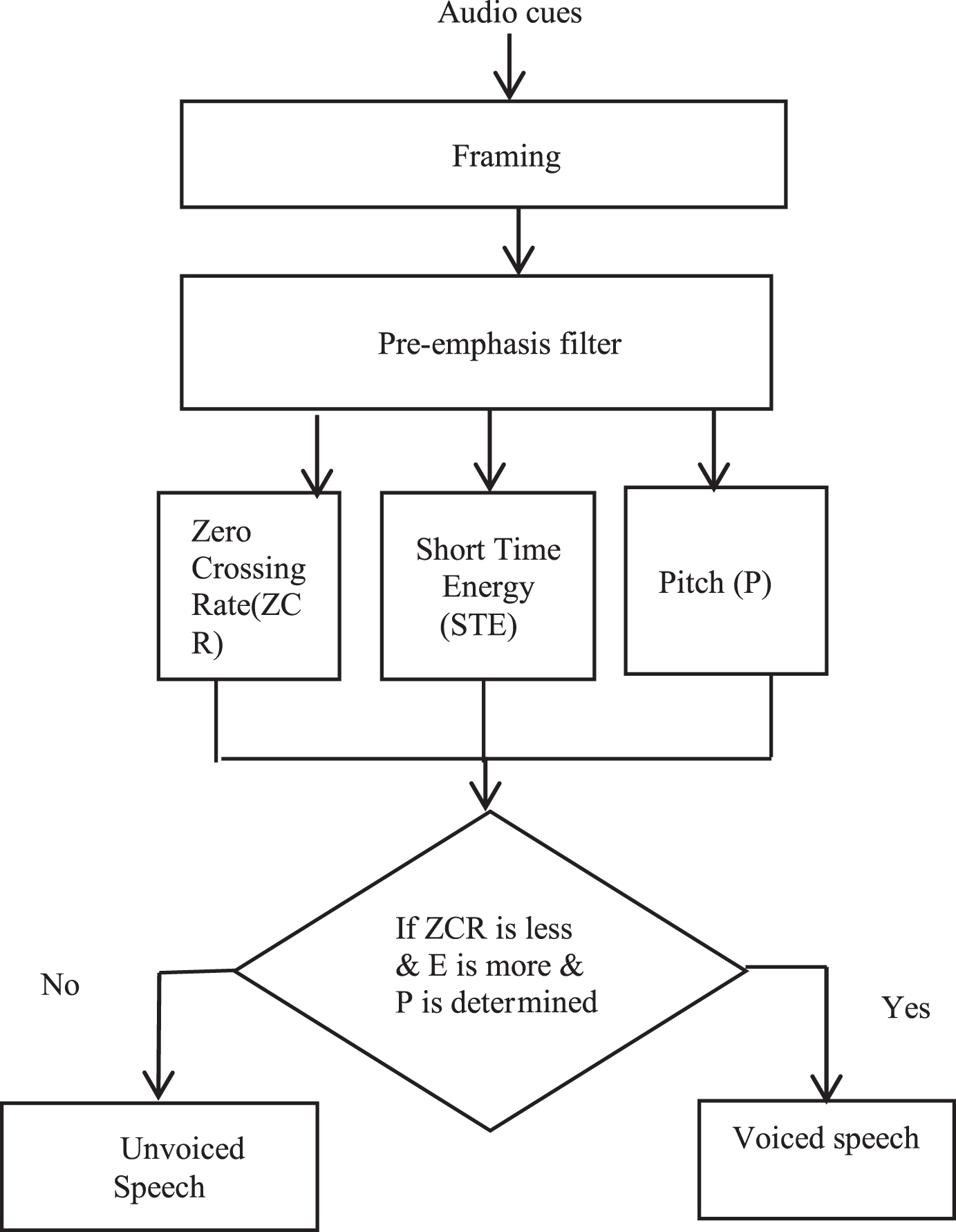
Block diagram for extracting voiced part of speech.
The bi-spectrum is a two-dimensional Fourier transform of the cumulant function of order three.
Frequencies shown in Fig. 4 are normalized by the Nyquist frequency. Equations (2 to 14) represents the procedure to derive Bi-spectral features.
Non-redundant region.
Mean magnitude of Bi-spectrum is given by Equation (2)
Entropy denotes the irregularity or the regularities in the signal. In this study, the entropy features are computed using Equations (7–9) [20].
The summation of log of amplitudes of Bi-spectrum is derived by:
The summation obtained for the log of amplitudes of diagonal elements in Bi-spectrum is derived by:
The diagonal elements amplitude for the spectral moments of order one and two is derived by:
Bi-spectral features are obtained from the entire speech and from voiced part of speech signal. Thirteen features are extracted from the entire speech signal and thirteen features are extracted from the voiced part of the speech signal from the each recording in the corpus and results are compared. The objective behind extracting only 13 features is to increase the affective state recognition with minimum features.
The classification is performed using Simple Logistic and K-Nearest Neighbor classifier.
Simple logistic
Logistic classifiers are non-symmetric models. Simple Logistic classifier yields better result when signal to noise ratio is less. The Simple Logistic regression models has numerical input variables and Gaussian distribution. Simple Logistic classifier performs regularization using a ridge estimator. Simple Logistic classifier merge the coefficients into a regression function and transforms it using logistic function and those coefficients are used to understand the model during training and then are minimized in order to reduce its size. Simple Logistic classifiers are multi nominal logistic regression models and are symmetric. Simple Logistic classifier have a built in attribute selection technique [5].
K-Nearest Neighbors (KNN)
KNN classifier classifies instances based upon similarity between the instances and easily interprets the output while consuming less computational time. It is a widely used algorithm to recognize patterns. It is a Lazy learning algorithm where the local approximation of the function is done [21].
KNN algorithm can be used to estimate continuous variables. The weighted average of inverse distance of KNN is used for one of the implementation. The algorithm is as follows. KNN classifier computes the Euclidean distance between the target plot and samples. KNN orders sample based on the calculated distances. KNN chooses its heuristically optimal K nearest neighbor based upon the calculation of root mean square. KNN calculates weighted average of the inverse distance using k-nearest multivariate neighbor.
Experimental setup and evaluation metrics
Thirteen Bi-spectral features are derived from Voiced speech and entire speech signal. The thirteen features form the feature vector. The total dimension of the input given to classifier is 1293*13. Recall, Precision, False Positive rate (FP), F-measure, True Positive rate (TP) and Receiver Operating Characteristics are the performance metrics considered for evaluating the performance of the system.
Recall conveys information about the number of instances which are pertinent, retrieved among the complete set of pertinent instances. It indicates recognition rate of classification.
Precision is also called as Positive predictive value (PPV).Precision is a ratio between TP and predicted positive.
Harmonic average of recall and precision is called as F-measure.
FP rate determines the probability of falsely rejected instances. TP rate determines the probability of truly predicted instances. Receiver Operating Characteristic (ROC) curve is a plot of FP and TP rate at various thresholds.
The ROC curve for disgust state is given in Fig. 5. Since the curve is aligned towards the upper left corner, it indicates that the classifier have better predicting capability.
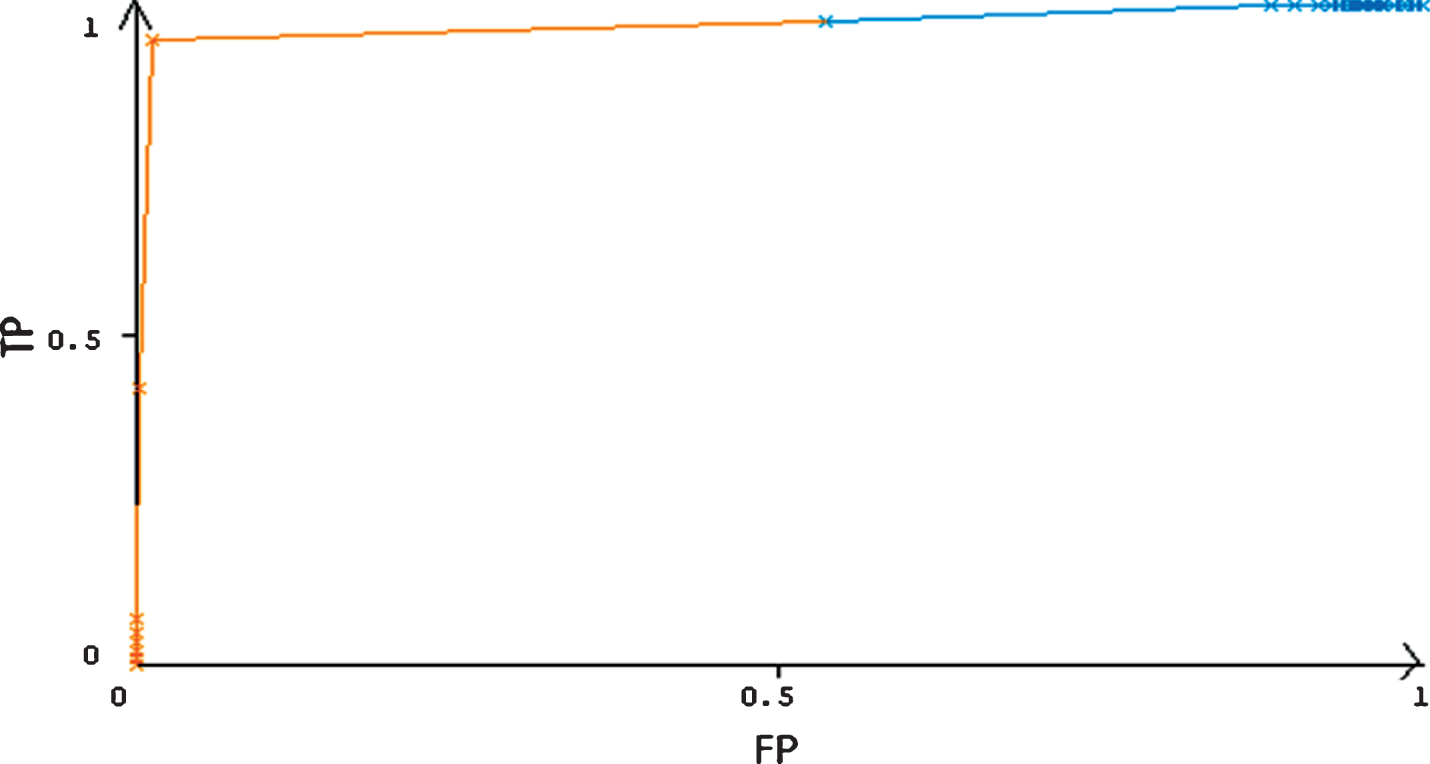
Example of ROC curve.
Classification is performed using weka tool kit. The analysis is done with five-fold cross validation. The feature vectors computed for voiced part of speech are labeled as Feature Set-1 and the feature vectors computed for the entire speech signal is labelled as Feature Set-2 respectively.
Firstly, the affective state of human is obtained with Feature Set-1 classified with Simple Logistic and K-Nearest Neighbor. The performance achieved by each classifier is evaluated using six performance metrics discussed in the earlier section. In order to understand the effect of voiced part of speech, Bi-spectral features are extracted from the entire speech signal i.e. without separating the voiced part of speech signal (Feature Set-2). Results for Feature Set-1 and Feature Set-2 are computed individually and tabulated in Table 1.
Performance Evaluation using proposed algorithm
Performance Evaluation using proposed algorithm
An improvement of 56.5% in Recognition rate / Recall is achieved using Feature Set-1 compared to Feature Set-2. Also, KNN gives better performance with Feature Set-1 and Simple Logistic is suitable for Feature Set-2.
To understand distribution and confusion between each affective state, confusion matrix for the best results obtained with Feature Set-1 is tabulated in Table 2 and with Feature Set-2 in Table 3.
Confusion matrix for Feature Set-1 using KNN Classifier
Confusion matrix for Feature Set-2 for Simple Logistic Classifier
Table 2 states that out of the six basic affective states, surprise state has achieved higher recognition rate of 94.4% and disgust being the least recognized affective state with a recognition rate of 76.9%.
Table 3 states that out of the six basic affective states, sad state achieved higher recognition rate and disgust is the least recognized affective state. Results obtained using Feature Set-1 showed a phenomenal improvement when compared with Feature Set-2. The change observed in the recognition rate of each affective state using Feature Set-1 and Feature Set-2 is shown in Fig. 6.
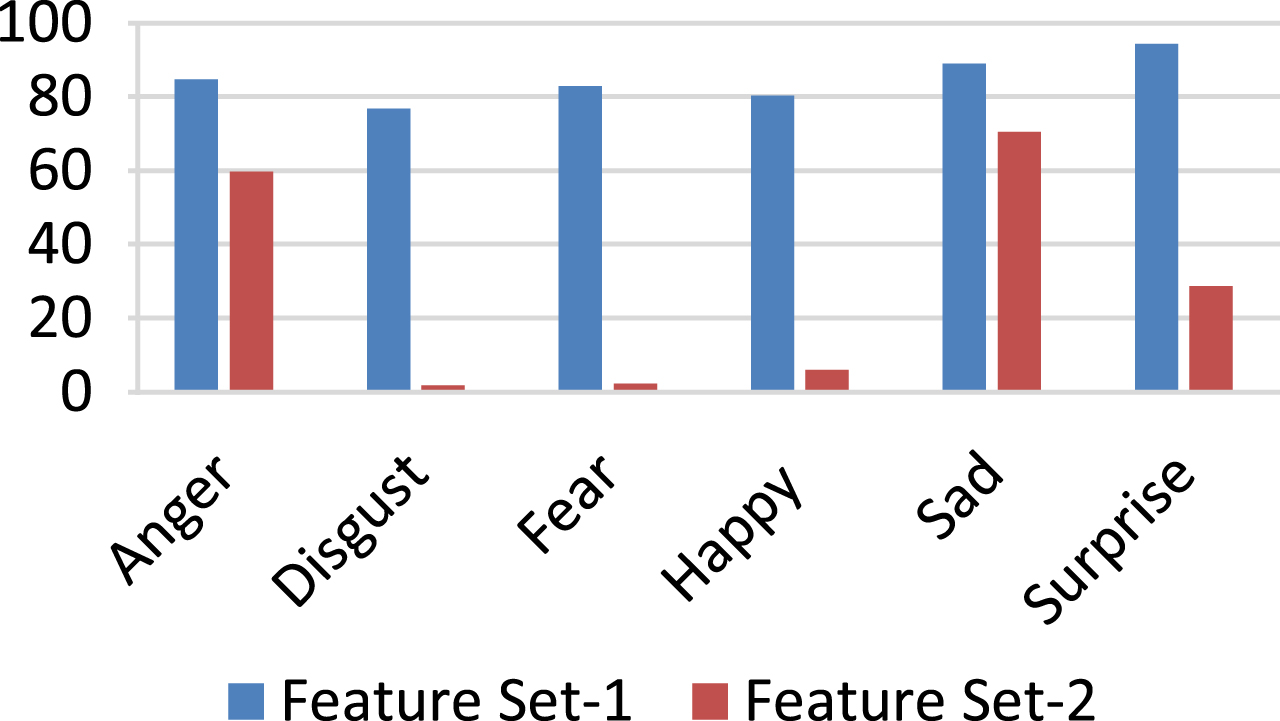
Bar graph showing performance comparison of affective states.
Recognition rate of each affective state using Feature Set-1 is better compared to Feature Set-2. This implies that the Bi-spectral features extracted from voiced part of speech is more capable of detecting the affecting states when compared with the features obtained from the entire speech.
The comparison between proposed model and various affective state recognition techniques using the same speech corpus is presented in Table 4.
Comparison of proposed work with previous works
Comparison of proposed work with previous works
It is observed that the proposed method shows an improvement in the recognition rate of 8.46% – 27.6% in comparison with the existing works. Also, the work by J. Yan et al. [24] achieved promising rate of recognition comparatively.
Thus, the performance obtained for each affective state using proposed model and model proposed by J. Yan et al. [24] are compared in Fig. 7. There has been a change in rate of recognition for disgust, happy, fear and surprise states. Higher order statistics (HOS) reveal more information about Gaussian and non-linearity which cannot be obtained using second order techniques. Thus, the proposed system can be used to achieve an improvement in the recognition rate of disgust, happy, fear and surprise states.

Bar graph showing recognition rate comparison of each affective state for proposed model and J. Yan et al. [24].
An investigation on affective state detection using the eNTERFACE speech corpus using Bi-spectral features from entire speech signal and voiced speech segments with KNN and Simple Logistic Classifier are presented. Five-fold cross validation is used for classification. Voiced speech using KNN classifier obtained high recognition rate compared to Simple Logistic. The classification results for proposed model using features derived from voiced segments is 84.7% showing an improvement of 8.46% – 27.6% compared to the previous works on the same speech corpus. Thus, the method under consideration achieved better recognition rate even with the compact set of features proving the robustness of the Bi-spectral features.
This work can be applied to analyze the patient’s response to the treatment and to understand the client’s affective state during counseling. Based on this analysis, better treatment and counselling can be provided to the patients.
In future, the speech can be combined with other modalities like facial expression, galvanic skin response and skin temperature to detect the affective state. The addition of Bi-coherence features and extraction of Bi-spectral and Bi-coherence features from glottal signals can be used to increase the system performance. Deep learning architectures can be applied for classification. Finally, this work can be analyzed using other speech corpus comprising other affective states like boredom, trust, anticipation etc.