
Abstract
Automatic recognition of human affective state using speech has been the focus of the research world for more than two decades. In the present day, with multi-lingual countries like India and Europe, population are communicating in various languages. However, majority of the existing works have put forth different strategies to recognize affect from various databases, with each comprising single language recordings. There exists a great demand for affective systems to serve the context of mixed-language scenario. Hence, this work focusses on an effective methodology to recognize human affective state using speech samples from a mixed language framework. A unique cepstral and bi-spectral speech features derived from the speech samples classified using random forest (RF) are applied for the task. This work is first of its kind with the proposed approach validated and found to be effective on a self-recorded database with speech samples comprising from eleven various diverse Indian languages. Six different affective states of angry, fear, sad, neutral, surprise and happy are considered. Three affective models have been investigated in the work. The experimental results demonstrate the proposed feature combination in addition to data augmentation show enhanced affect recognition.
Introduction
Affect is regarded as a physiological term that describes an emotion or state of mind of an individual. Human affective state is featured with a change of tone and usually followed by physiological behavior change. Various factors responsible for this condition is confidence, health related issues, loss in family, break up in personal relations, self-esteem etc. [1]. Various modalities such as speech, facial expressions, heart rate, blood flow, body temperature can be used to recognize the human affective state. Of all these methods, the modality using speech is more popular as recording the data and storage is easier [2] [3]. In this work, various speech patterns are used to recognize the affective (also referred to be para-linguistic / emotional) state of the individual. The applications of the proposed work comprise call center applications, on-line tutoring, robotics, e-learning, marketing, entertainment, law etc. [4][5].
The important modules in any speech emotion recognition system are database, pre-processing, feature extraction and classification. The first module.ie database consist of a collection of speech sample recordings of a specific language with different emotions. Berlin (German language recordings)[6], eNTERFACE (English language recordings)[7], Savee (British English recordings) [8] have been the pioneering databases on which there have been many published works. Recently Baum-1a (Turkish language recordings) [9], MELD (English language recordings) [10] databases have been released. The second module of pre-processing involves mainly framing and windowing as speech is a non-stationary signal. Various normalization techniques and sometimes noise reduction mechanisms have been part of this module [11][12]. Various speech features or patterns are derived from the third module. Various prosodic, spectral, teager energy operated and voice quality features have been applied till date for affect recognition [13][14][15]. The extracted speech patterns are the input to the last stage i.e. Classifier that does the recognition task. Classical classifiers such as Gaussian Mixture model (GMM), Hidden Markov Model (HMM), Support Vector Machines (SVM) etc., deep learning classifiers such as convolutional neural networks (CNN), Recur-rent Neural Networks (RNN) etc and deep learning based classifier ensemble such as auto encoders, adversarial training, attention mechanism have been part of the final module of classification [16][17] [18].
This work is focused on speech based affective state recognition in a mixed-lingual environment of Indian background. The key contributions in this work are as follows: Creation of an in house mixed lingual emotional database with twenty four speakers in eleven diverse Indian languages A unique cepstral and bispectral feature combination is proposed for affect recognition in mixed-lingual framework The proposed mixed-lingual system is unique with three different emotion models investigated besides attainment of considerable performance of affect recognition
This article has state of the art discussed in Section 2, database creation explained in Section 3, overflow of work is described in Section 4, evaluation measures and experimental work with analysis put forth in Section 5 and 6. Finally, Section 7 has conclusion with future directions.
State of the Art
Literature reports work on affective state recognition majorly on single and multi-corpus corpus contexts that deals with recognition of emotion samples from one language each time system is analyzed and tested. Mainly, each work is diverse in the type of features and classifiers used. In single corpus affect recognition works, only one language emotion samples are involved. A small set of prosodic features constituting primarily energy, intensity and pitch were popular during the infantry stage of emotion recognition [19][20]. Spectral features of Mel cepstral coefficients (MFCC) and linear prediction coefficients (LPC) contain emotion specific information as investigated by Ayadi et al [21]. In another work by Bang et al., prosodic and cepstral features with data augmentation method proved to be significant to recognize emotions from IEMOCAP speech samples [22]. A combination of Teager-Kaiser energy operator based features and empirical mode decomposition (EMD) were applied by Kerkeni et al [23]. Prominent emotion features for two different databases of English and Spanish independently were selected using recursive feature selection.
In multi-corpus affect recognition works, the system is tested for more than one database / corpus. With more databases involved, researchers explored and applied large sized features for affect recognition. Interspeech 2010 feature set comprising feature vector size of 1582 along with neurogram features were derived from voice samples of Berlin and eNTERFACE databases and classified using SVM to recognize emotions yielding an accuracy performance of 89.2% (Berlin database) and 78.2% (eNTERFACE database) [24]. Deep multitask networks accompanied by shared hidden layers classified affect samples from nine distinct corpora using GeMAPS (83 features) and ComParE (6373 features) feature sets [25]. Two heterogeneous emotion corpus of English and Japanese voice samples were classified using multi-task learning with the aid of Interspeech 2010 features [26].
However, in the recent times affective recognition in speech with databases from mixed-lingual context is witnessed. A combination of MFCC and SDC features of size 124 extracted from samples of IEMOCAP and FAU-AIBO were classified using deep neural networks (DNN) yielding an accuracy of around 51% [23]. In another work, cepstral features of size 151 using Random Forest classifier have been applied to recognize emotions from a mixed-lingual context with number of databases involved from 2 to 5. Accuracy of around higher than 80.0% was demonstrated in the work [27]. An interesting point is that although appreciable results are achieved in the work reported in [27], but databases involve samples recorded in a fixed noise free background conditions.
Summary of state of the art and research gaps:
Existing work on affect emotion detection describes various methodologies. Prosodic and spectral feature combination have been popular for recognizing affect. Among large feature sets, Interspeech 2010 feature set is often applied with affective work involving more than one database. SVM has been effective among the traditional classifier category for classification. Different deep neural networks are applied recently for recognizing emotions. Although lot of work is suggested in speech based affect recognition, mixed-lingual affect recognition is quiet minimal. Especially, in India with so many languages which people communicate, an affect recognition system that performs emotion recognition in a framework of mix of diverse languages is a deficit. This problem is addressed with a suitable methodology in this work.
Insights of database creation
An in house speech emotion database with a diverse Indian language samples is performed in this work. The voice samples were recorded from various hand held mobile devices with each had its own configuration in terms of sampling frequency and default settings. Additionally, few samples were from mono channel re-cording and the others were from stereo recording settings in the mobiles. The speakers were from undergraduate, post graduate and Ph.D. students in the age group of 20–28 years. Each voice sample duration length lasted from 2–4 sec. A total of 32 speakers with 24 male and 12 female students participated in the re-cording. The database created consists of emotion samples with six categories i.e. angry, fear, neutral, sad, happy, and surprise in 11 diverse Indian languages. A total of 675 samples were recorded. A perception test was conducted with 4 members as judges. Each time a voice sample was played and the emotion perceived by each of the member was recorded. A total of 106 samples were dis-carded after the perception test due to the disagreement on the type of emotion perceived by the judges. The number of emotion samples from each language that passed the perception test and included in the database for the proposed work is listed in Table 1.
Frequency of emotion samples of each language in the created database
Frequency of emotion samples of each language in the created database
An overview of the methodology in this work for recognizing affective state in an environment of mixed languages is shown in Fig. 1.
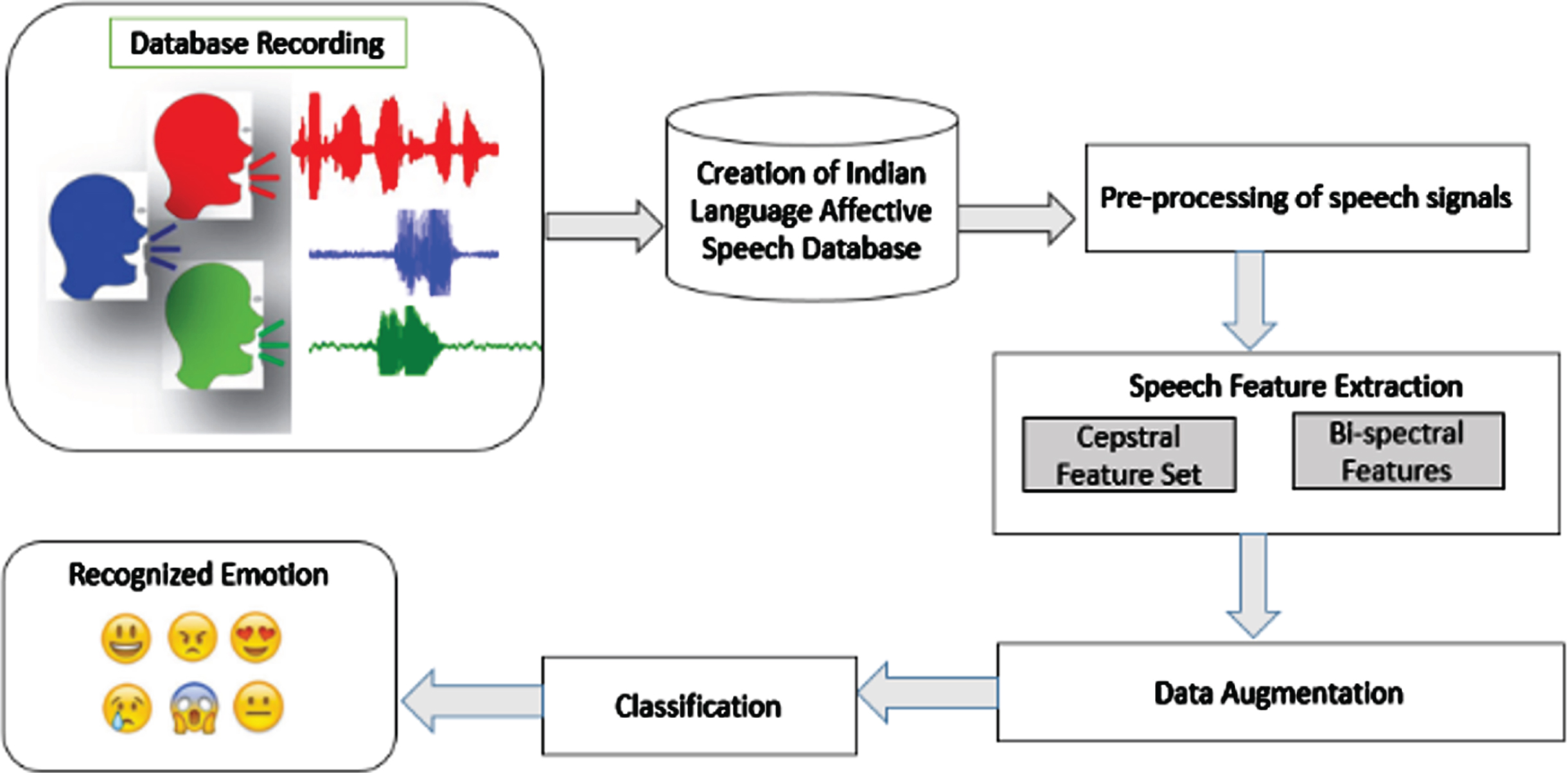
Block diagram of the proposed work.
As depicted in Fig. 1, the proposed system consists of four major phases i.e., pre-processing, acoustic / speech feature extraction, data augmentation and finally classification. Each of these sections are discussed as follows:
This phase involves framing and windowing of voice samples, due to the non-stationary characteristic of the data. A 30 ms length of hamming window is chosen and an overlap of 10 ms is performed.
The window function w(n) is defined in equation (1).
The windowed frame y(n) of the input speech signal x(n) is expressed in equation (2).
The acoustic/speech features considered in this work are composed of two major constituents, i.e. cepstral speech feature functional set and bi-spectral features. The cepstral feature set had majorly features derived from Mel, bark and inverted Mel filter banks besides modified H-Coefficients and additional parameters as shown in Table 2.
Cepstral Feature Set [27]
Cepstral Feature Set [27]
It is composed of a set of 151 sized functional set. The functionals of maximum, minimum, mean, standard deviation, variance and median were considered. These features have found to play a major role for mixed-lingual affective recognition with majority of the speech samples in the corpus belonging to non-Indian languages [27]. From the experimentation performed in this work, it is observed that these stand-alone features of Table 1 were not sufficient to recognize the affective state of mixed-lingual Indian corpus with diverse languages. Hence, it was very much required to add some additional features to the cepstral feature set.
Extraction of Bi-spectral features
Bi-spectrum is basically a Fourier transform which is of two dimension with respect to the cumulant function of third order as represented in equation 3.
Hence, from the non-redundant area (Ω) Bi-spectral features are selected as depicted in Fig. 2.
Frequencies depicted in Fig. 2 are normalized with Nyquist frequency. Equation (4) to (13) characterizes the process to obtain Bi-spectral speech features. Average magnitude of Bi-spectrum is represented in Equation (4).
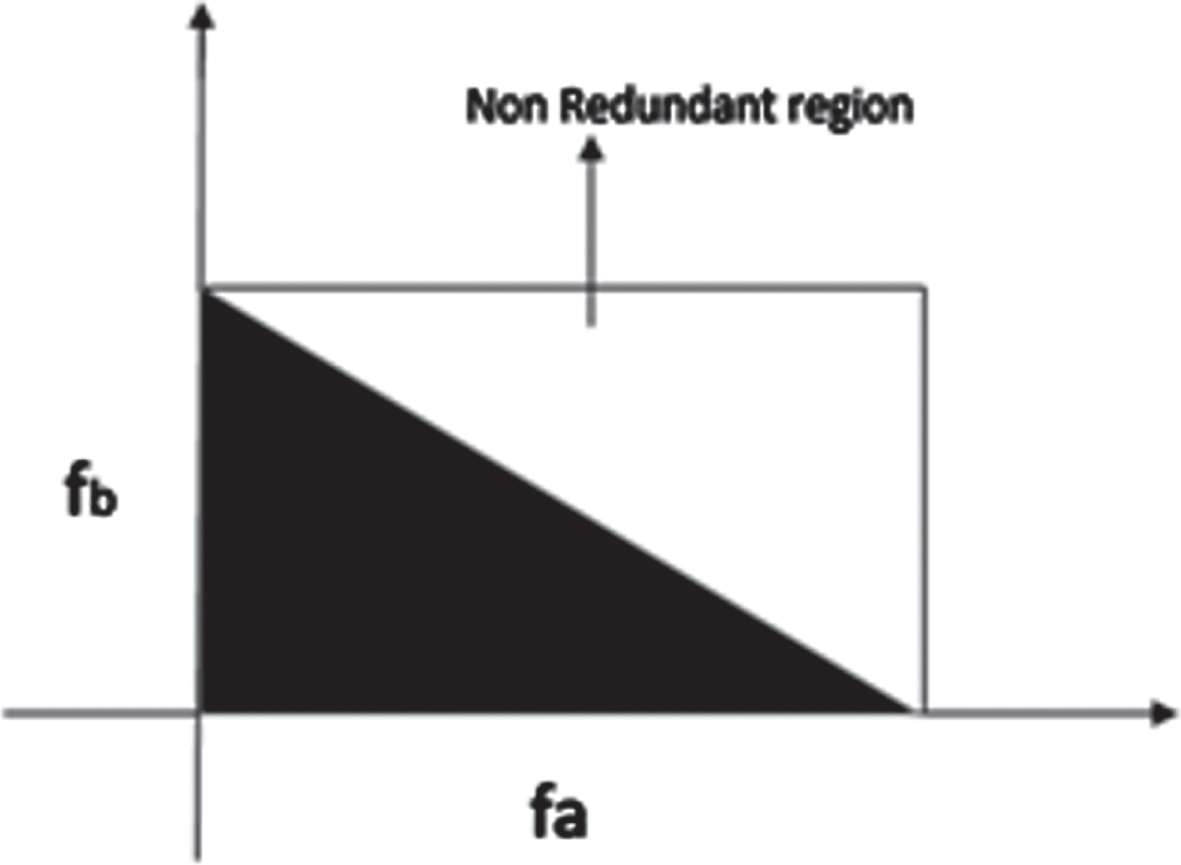
Non-redundant region.
The log amplitude summation (T
a
) of Bi-spectrum is derived by:
The log amplitude summation from diagonal elements (Tb) in the Bi-spectrum are given as:
The diagonal elements amplitude (T
c
, T
d
, T
e
) for the spectral moments of order one and two is derived by:
A total of 6 features that includes average magnitude of bi-spectrum and five features derived from log amplitudes of the bi-spectrum are extracted. Thus, in this work a combination of cepstral features of size 151 and bi-spectral features of size 6 results in a total size of 157 coefficients are extracted for each speech signal.
One of the popular data augmentation method, introduced by Nitesh et al., referred as synthetic minority oversampling technique (SMOTE) is applied in this work [30]. Synthetic samples of the minority classes are created in a feature space using this method. The methodology of sample creation is based on choosing k-nearest neighbours. Here, the value of k is selected to be 5.
Classification
This forms the last phase with recognition of the speech sample affective state performed using random forest (RF) classifier [27]. Multiple decision trees having more similar distributions associate to form RF. Several decision trees are formed during the process of training with the output considered from every individual tree. A subset of data is obtained using bagging method. In this work, a total of ten trees are selected.
Performance measures
To evaluate the performance of the proposed mixed-lingual affective recognition system, recall, precision, F-score and confusion matrix are used in this work [31]. These measures are defined as follows:
Recall refers to the fraction of samples relevant among the total amount of relevant instances.
Precision refers to the sample count relevant among the samples retrieved. It is also referred to be positive predictive value.
F-Score refers to the harmonic average of recall and precision.
Confusion matrix refers to a table which indicates the relevant information of the test samples correctly recognized.
The experimental work was conducted by extracting cepstral and bi-spectral features making a total of 157 coefficients for each speech signal. Data augmentation is applied following classification using various classifiers from python [32]. However, random forest was found to give optimum results for the proposed mixed-lingual work. A fivefold cross validation was applied to analyse the system performance. The work is performed and investigated in two phases as follows: Experimentation and analysis of the proposed mixed-lingual affect recognition system on three emotion models Comparative analysis on the emotions and across the models
Experimental work and result analysis of the proposed mixed-lingual affect recognition system across the emotion models
The proposed mixed-lingual affect recognition system is applied on three different emotions models referred i.e Model 1, Model 2 and Model 3 created from the in-house database recorded in this work and performance of the system is analysed in each case. The insights into these three models are as follows; Model1 comprises of three emotions i.e. happy, sad and neutral. Recognition of emotions in this model are quiet crucial in the investigation of mood swings of an individual. Model 2 consists of four emotions i.e. angry, fear, neutral and sad. Recognition of these emotions are important during investigation of psychological state of an individual. Model 3 has all the six emotion classes i.e. angry, fear, neutral, sad, happy, and surprise. This model serves to recognize most frequent emotions recognized in daily life.
Hence, each model is applicable for different application. The experimentation is carried out to analyse the performance and suitability of the proposed approach for each model.
Proposed system on Model 1
The proposed mixed-lingual affective system is applied on voice samples of Model 1. Performance of emotion recognition on voice samples across the model is shown by the confusion matrix in addition to performance measures depicted in Table 3 and Fig. 3 respectively. It is observed that happy samples are better recognized while neutral and sad are at times misclassified with one another. Happy is recognized with a recall rate of 80.6% while sad and neutral samples exhibit a moderate recognition of around 70%. Performance measures of precision, recall and F-score exhibit performance rates not lesser than 70% across all the three classes of emotions. The average from all the three measures are consistent depicting rates higher than 75%.
Confusion matrix for Model 1
Confusion matrix for Model 1
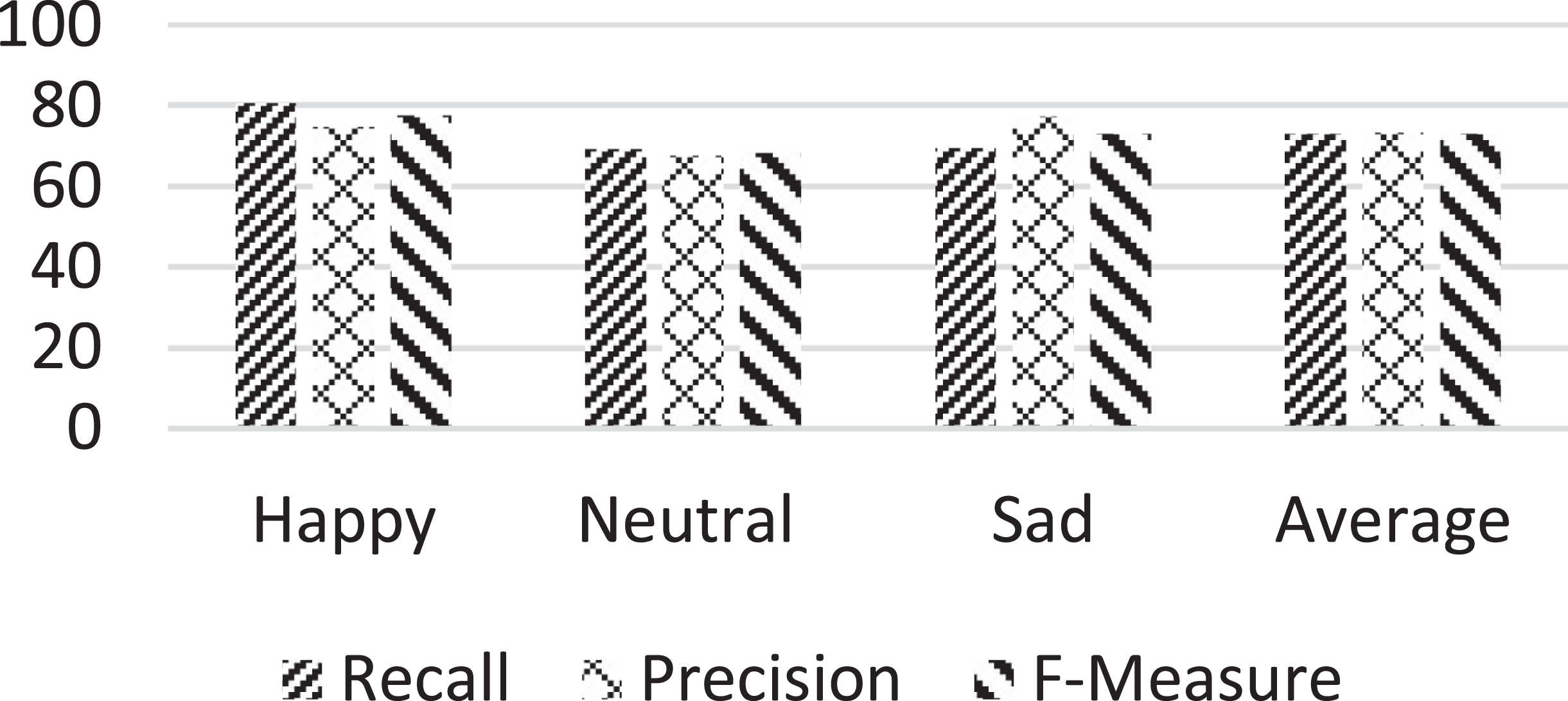
Performance of the proposed mixed-lingual affect recognition system across Model-1.
The proposed mixed-lingual system is applied to recognize emotions from Model-2 with the results reported in confusion matrix of Table 4 and performance measures shown in Fig. 4 respectively. Among the four emotions, angry is recognized across most of the voice samples. Fear is moderately recognized but often misclassified to be angry. Similarly, there exists a small confusion between neutral and sad emotion.
Confusion matrix for Model 2
Confusion matrix for Model 2
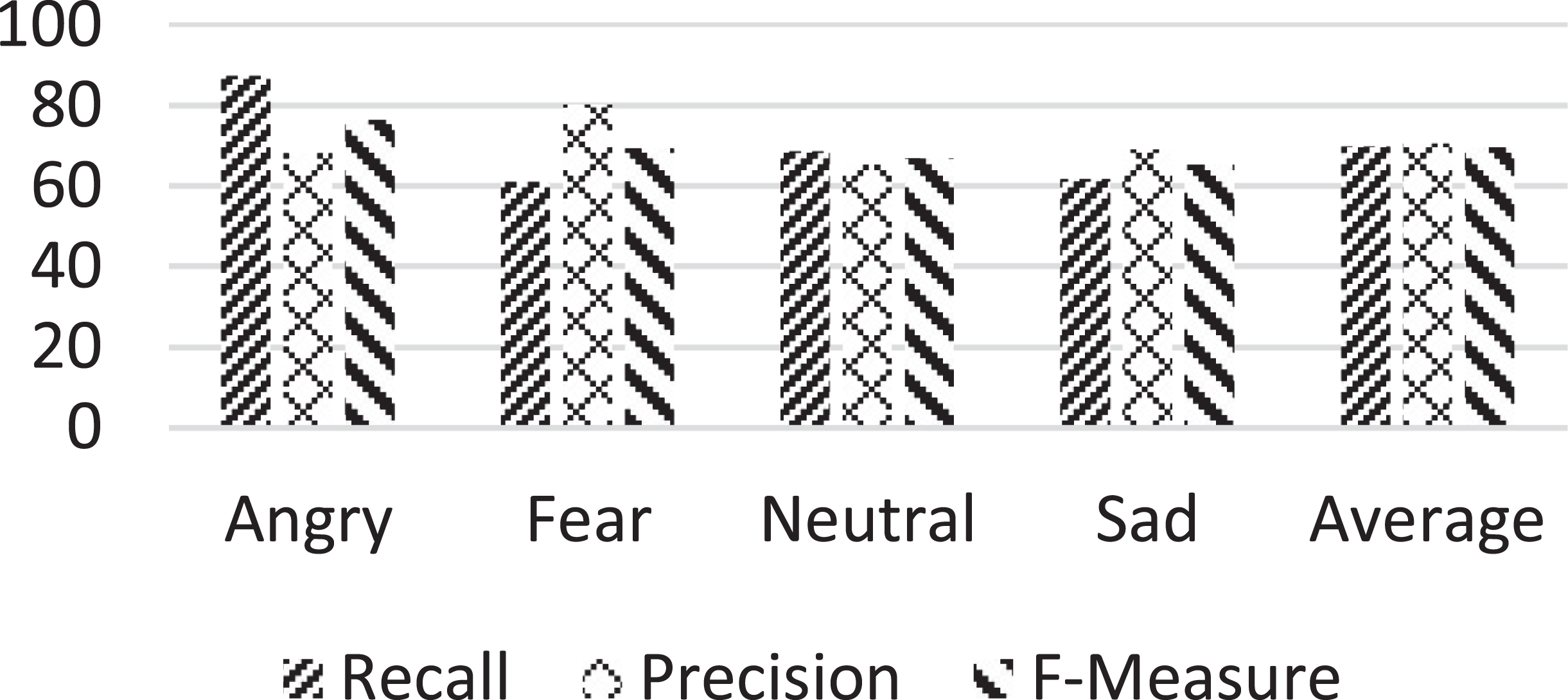
Performance of the proposed mixed-lingual affect recognition system across Model 2.
From the perspective of performance measure from Fig. 4, recall rates are higher for angry with 87.2%, while neutral is the next better recognized emotion around 70%. Precision has been higher with fear, reaching around 80% indicating lesser number of false negatives predicted by the methodology in the context. Lastly, except for sad emotion F-Score, has remained around 70% and higher. The average rates of all the three measures are found to be around 70%.
The proposed system is applied on Model 3 with performance results achieved depicted in confusion matrix of Table 5 and three performance measures shown in Fig. 5.
Confusion matrix for Model 3
Confusion matrix for Model 3

Performance of the proposed mixed-lingual affect recognition system across Model 3.
From the confusion matrix of Table 5, angry is better recognized among the six emotions. Besides, Surprise is the next emotion fairly predicted. However, Neutral and Sad emotions are misclassified with one another while, with few samples, fear is identified as recognized as angry or happy. Recall rates for angry is higher than 75%. Similarly, precision rates of fear is around 75% since the false negatives predicted are lower. For rest of the other emotions all the three performance measures have almost remained around 60.0%.
Further, with eleven diverse languages, the proposed model is able to recognize all the six emotions almost around 60% or higher shows the effectiveness of the proposed method.
This section discusses performance of proposed system in recognizing, the most confusing emotions of sad and neutral across all the three models. These two emotions are often difficult to be classified by humans also. Next, performance measure averages across all the three models in this work are compared.
Comparative performance analysis of Neutral and Sad emotions using the proposed model
The neutral and sad emotions which are usually referred as low emotions are important to be recognized in any application. With three models investigated in this work, the performance measures of both in presence of other emotions across the models is depicted in Fig. 6. With the first model, both emotions are recognized higher than 70% in the presence of the third emotion happy. Next, presence of other two emotions of angry and fear resulted sad to be slightly misclassified higher with neutral in model 2. However, with Model 3, in-spite of presence of another four emotions, both the emotions sad and neutral have been fairly recognized by the proposed model with rates of around 60%.
Comparative performance analysis of the proposed mixed-lingual affect recognition system across all the three models
The average evaluation measures of recall, precision and F-score across all the three models investigated in this work are compared in Fig. 7. Across the models it could be observed all the three evaluation measure average are almost remained same. The best averages of around 73% are achieved using Model 1 with a set of three emotions. However, as the number of emotions increased to four and six with Model 2 and Model 3, confusion increased during classification among the emotion class causing slight reduction in the recognition rates. The key observation is that even with all the six emotions considered in Model 3, averages have resulted around 60% which is still a better performance by the proposed mixed-lingual affect recognition system since diverse Indian languages and speakers are involved in the mixed-sample recordings.
Conclusion and future outlook
This article provides an investigation of mixed-lingual affect recognition system for different Indian languages. Against the huge feature sets applied in literature for affect recognition, in this work a narrow set of 157 co-efficients of cepstral and bi-spectral features have been the key constituents of the speech feature set. With various classifiers applied in the work, random forest classifier is found suitable for the mixed-lingual environment. Diversity in the speakers and language of the speech emotion samples are considered during in house data creation. Experimental results are demonstrated using the performance measures of recall, precision and f-score. All the three metrics have proven to be consistent and shown to be considerable across all the three models investigated. The proposed methodology of proposed feature set and data augmentation has proven to be superior since emotions samples captured with a simple hand held devices were recognized. In future, some additional features could be added to the proposed feature set for enhanced recognition rates. Also, other Indian language emotion samples could be added to the database and the proposed method could be validated further.