
Abstract
This paper proposes a pre-classification based language identification (LID) system for Indian languages. In this system, firstly, languages are pre-classified into tonal and non-tonal categories and then individual languages are identified from the languages of the respective category. In this work, language discriminating ability of various acoustic features like, pitch Chroma, mel-frequency Cepstral coefficients (MFCCs) and their combination has been investigated. The system performance has been analyzed for features extracted using different analysis units, like, syllables and utterances. The effectiveness of deep residual networks (ResNets) model in identification of Indian languages has been studied. Also, the system performance has been compared with the performances of other deep neural network architectures like, Convolutional Neural network (CNN) model, cascade CNN-long short-term memory (LSTM) model and shallow architecture like, ANN. Experiments have been carried out on NIT Silchar language database (NITS-LD) and OGI-Multilingual database (OGI-MLTS). Experimental analysis suggests that proposed ResNets model, based on syllable-level features, outperforms the other models. The pre-classification module provides accuracies of 96.6%, 93.2% and 90.6% for NITS-LD, and 92.1%, 89.3% and 85.4% for OGI-MLTS database, with 30s, 10s and 3s test data respectively. The pre-classification module helps to improve the system performance by 3.8%, 4.1% and 4.3% for 30s, 10s and 3s test data respectively. For OGI-MLTS database, the respective improvements are 6.8%, 6.5% and 5.4%.
Introduction
Language identification (LID) refers to the task of identifying the languages correctly from a given speech sample [1]. Performance of any LID system depends on different factors. An ideal LID system should have the ability to identify large number of target languages with high accuracy. Also in countries, like, India, where most of the languages share a common phoneme set, language identification task becomes more challenging. In order to prepare an LID system for identifying either large number of target languages or closely related languages with higher accuracy, languages either can be pre-classified into different sub language families or into different categories.
In one such case, Jothilakshmi et al. [2] reported a hierarchical LID system for 9 Indian languages using MFCC, MFCC + delta and double delta coefficients (Δ and Δ-Δ) and MFCC + shifted delta coefficient (SDC) features and three different classifiers, namely, Gaussian Mixture model (GMM), Hidden Markov Model (HMM) and ANN. The authors noticed that GMM model and MFCC + Δ-Δ feature provides the highest accuracy of 80.56%. Here, in the first level, languages were divided into two language families, namely, Indo-Aryan and Dravidian and then individual languages were identified from their respective language family. However, it seems that, at the first stage, the categorization of the languages into different language families has been performed manually.
In another work, Ramu Reddy et al. [3] prepared an LID system for 27 Indian languages using spectral and prosodic features. They achieved an accuracy of 62.3% for GMM model and the combination of spectral and prosodic features. This accuracy is much less compared to that of the recently developed LID systems.
Literature study reveals that a vast population (almost half) of world languages is tonal [4, 5]. In a pioneering study, Wang et al. [6] reported a novel system to pre-classify 6 world’s distinct languages into tonal and non-tonal categories using different parameters of pitch contour and duration as features and artificial neural network (ANN) as classifier and achieved an accuracy of 80.6%. They have extended their work further in [7] to show that the performance of the system improves by 4% to 5% when pre-classification of languages into tonal and non-tonal categories is done before performing individual language identification. However the use of phonetically labeled data makes the identification task non-trivial.
Tonality is used to arrange sounds according to pitch relationships of interdependent spatial and temporal structures. The pitch relationship is represented through a pitch helix that places tones on the surfaces of a cylinder [8]. Pitch has both rectilinear and circular dimensions which are referred to as pitch height and pitch Chroma [9]. The angle of pitch rotation as it traverses the pitch helix is represented by Chroma. Chroma features collect all spectral information of a given pitch class into a single coefficient. Chroma feature has become a de facto feature for several tasks like, audio structure analysis, audio matching, music alignment etc. However, for LID task, it alone may not be able to compete with spectral feature but can be used as a complementary feature with different spectral features. Several researchers [2] reported different LID system using MFCC features. Also, MFCC feature has been identified to be quite useful for carrying tone information [10]. However, no such research is reported showing the effectiveness of MFCC feature for pre-classification based LID system.
Development of deep learning methodologies have greatly influenced the performance of LID systems. In recent studies, several neural network structures [11–14] have been proposed, among which CNN is one of the most effective models. CNN has the ability to exploit the time and frequency correlations and to capture the frequency shift in human speech signal [15]. Moreover, it has lesser number of free parameters to be tuned, so that it becomes advantageous to use CNN when available data to train is not as abundant as is required by other deep architectures. Also, LSTM-RNN [16] is another powerful tool used for acoustic modeling in large vocabulary speech recognition. Deep learning techniques mainly aim to study the feature hierarchy in which lower level features are combined to form higher level representations. Better representations require a deeper network for training, and several researchers have analyzed how the system performances change with increased depth of network [17]. However arbitrary increase in depth of the network does not show significant improvement in system performance. Recently, a new network structure has been proposed in computer vision and in speech recognition called residual networks (ResNets) [18, 19] that have several advantages: i) Here, networks of any depth can be trained with stochastic gradient descent algorithm. ii) It does not suffer from vanishing gradient problem. iii) It learns from residual mapping [20] which is more compliant for optimization. iv) ResNets easily converge and also provides better generalization than other network.
In this paper, focus has been laid on Indian languages. Since, the influence of one language on other is very high in India, therefore, distinguishing these languages is difficult as compared to other distinct languages. Very few databases are commercially available which include Indian languages, and therefore it necessitates the preparation of a database for Indian languages.
From the above mentioned studies it can be observed that the performance of an LID system is subject to number of target languages [3–14]. Here, the authors didn’t investigate the impact of a pre-classification module on handling the large number of target languages with higher accuracy. On the other hand, a hierarchical LID system for Indian languages, proposed so far, gives low system performance compared to many latest LID systems [2]. In [7] authors confirmed the effectiveness of pre-classification module for the identification of world’s distinct languages. However this study cannot tell us about the usefulness of the pre-classification module for the identification of closely related Indian languages. In paper [7] features are extracted from whole utterance of the speech signal. However, for tonal languages, either open or sonorant closed syllables are known to be tone bearing units [21], where pitch changes in a regular pattern. Moreover, most of the Indian languages are syllable centric [22], which is why the language specific cues are best evident at syllabic level itself. Therefore, it can be hypothesized that syllable-level analysis may provide better performance for this system. Also, no such literature is available mentioning the effect of powerful models, like, ResNet for pre-classification based closely related Indian language identification. Modeling of syllable-level features using ResNet has not been explored so far. Effect of MFCC and Chroma features individually or their combination for a pre-classification based LID system have not been reported in the existing literatures.
The main focus of this study is given below: Development of a tonal and non-tonal language pre-classification based LID system for closely related Indian languages without using phonetically labeled data. Exploring the effectiveness of ResNets for the task of language identification. Analyzing the system performance for Chroma feature and its combination with MFCC feature. Development of a pre-classification based LID system considering syllables as basic units. Preparation of NITS-LD (studio quality) for twelve Indian languages with data collected from All India Radio news archives. Comparative study of the system performances of NITS-LD and OGI-MLTS database (telephonic) has also been made.
The rest of the paper is organized as follows: Section 2 describes the proposed language identification system. Section 3 describes the databases used in this work. Different features used in this experiment are described in Section 4 and Section 5 outlines different language modeling techniques. Section 6 describes the experimental setup along with experimental results and their analysis. Section 7 concludes the work by mentioning the future works.
Proposed language identification system
In this work, a pre-classification based LID system has been prepared for improving the system performance with respect to the state-of -art system. Here, system performances have been obtained for three different conditions. Condition I, where no pre-classification stage is present and the languages are identified as a conventional (baseline) LID system does. Here, in training stage, a separate model (L1, L2, … L M ) for each of the M number of languages is trained and identification stage determines which of the L languages is most likely to the language models prepared at the training stage. For condition II and condition III, first languages are pre-classified into tonal and non-tonal categories and then individual languages of respective category are to be identified at the second stage. Moreover, for condition II, all languages labeled as tonal or non-tonal at the first stage are processed to the second stage and for condition III, only truly detected tonal or non-tonal languages from the pre-classification stage (separated manually) are processed by the individual language identification stage. Block diagram representations of all the three conditions of the system are shown in Fig. 1. It is evident from the literatures [21] that tonal characteristics in the tonal languages are coded at syllable level rather than the utterance. This paper uses syllable as the basic units for feature extraction which are useful for distinguishing among the languages. The common syllable structures are Vowel (V), vowel consonant (VC), consonant vowel consonant consonant (CVCC) and vowel consonant consonant (VCC) etc. In case of Indian languages most of the syllables are CV types [23]. Syllable boundaries are obtained considering the locations of vowel onset points (VOPs) [24] as end points.
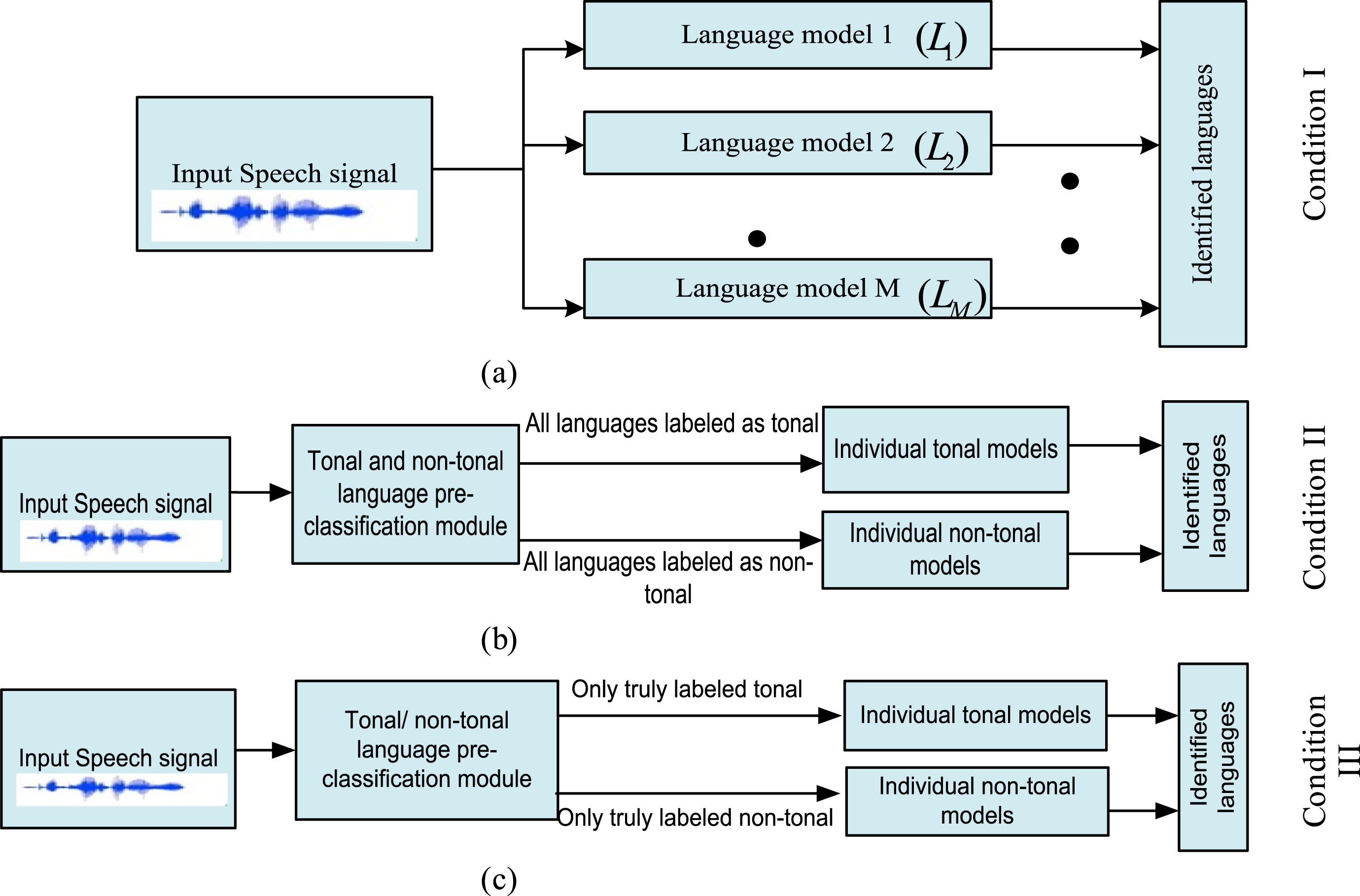
Block diagram representation of the system for (a) condition I (b) condition II and (c) condition III.
NITS-LD comprises of 12 Indian languages and its detailed description is given in Table 1.
Descript ion of NITS-LD
Descript ion of NITS-LD
The two columns of Table 1 under the train and test represent total speech data (in hrs) and total number of speakers present in train and test set of each languages respectively. Data of different languages has been collected from AIR news archives, resampled at 8 kHz and then stored as 32-bit floating point numbers. The speakers of AIR news channels are highly professional and well matured. Hence the speech samples collected from this news archives are well articulated and are standard in terms of pronunciation and speaking rate. Data collected from AIR news archives has some inherent problems, like, (i) the number of speakers for each language are less in number and specially for some languages like Nagamese etc. are noticeably small; (ii) there are the chances to get overlapping speech samples of different speakers and (iii) moreover the news headlines may have the back ground music. Hence, proper care should be taken while preparing the database useful for the experiment. In order to train the models, along with our NITS-LD a subset of Indic database [25] is also used. The details of Indic database are given in [25].
Our proposed language classification system is also tested for OGI-MLTS database. OGI-MLTS database [26] contains spontaneous and fixed-vocabulary utterances of 11 languages: Hindi, Farsi, French, English, German, Korean, Japanese, Spanish, Mandarin Chinese, Tamil and Vietnamese. Japanese language has not been used in this experiment. The utterances were spoken by around 90 individual speakers of each language over telephone line and the speech was sampled at 8 kHz. This set includes two tonal languages (Mandarin, Vietnamese) and nine non-tonal languages.
Existing features for tonal and non-tonal language classification
In the existing system [6], different parameters of prosodic features, namely, mean pitch, pitch changing speed, pitch changing level, voiced duration counts and another parameter, voiced phonemes counts have been used for tonal and non-tonal language classification task. Since in our experiment speech samples are not phonetically labeled, instead of using voiced phoneme counts total number of vowels (vowel counts) of an utterance are used as a parameter. Vowel counts are obtained by counting the number of VOPs present in the utterance. VOPs can be obtained from a spontaneous speech signal by using VOP detection algorithm of [24]. All other parameters are obtained by using the same procedure as explained in [6]. In case of syllable-level analysis, same parameters are extracted from each syllable of the speech signal. Since number of vowels are nothing but the number of VOPs, for a syllable vowel counts would be always equal to 1. Therefore, use of this parameter is insignificant for a syllable.
Proposed features
Chroma features
This paper proposes pitch Chroma spectrogram for analyzing the system performance.
Humans perceive two pitches as similar in “color” if they differ by one or several octaves [27]. Based on this observation a pitch can be split into two components, namely, tone height and Chroma. Chroma is represented through a set pitches separated by an integer number of octaves where one octave is represented by the distance of 12 pitches. Mathematically Chroma is represented as
where, X lf is log-frequency spectrum, z is integer octave index, N is number of octaves, b is integer Chroma index, β represents bins per octave.
In this experiment speech samples are blocked into 20ms frames with a skip rate of 10ms and then from each frames MFCC are obtained. Extraction of MFCC is done using standard algorithm which is explained in [2]. Here, 23 coefficients of Mel spectrogram have been used to perform the classification tasks.
Backend for language modeling
Existing system architectures
In this experiment, system performances have been analyzed for three existing models, namely, ANN, CNN and CNN-LSTM.
Residual neural network architecture
Instead of fitting the desired underlying mapping directly, ResNet layers try to fit a residual mapping. Let H (x) be the mapping to be fit as shown in Fig. 2. where x denotes the input of the first layer of the residual blocks. ResNets layers try to learn H (x) - x mapping and original function H (x) therefore becomes F (x) + x. In each residual units there are two convolutional layers and each layer uses 3×3 filter size.
After each convolution batch normalization is performed and rectified linear unit (ReLU) activation is used after the first convolution and addition operation is performed after the shortcut connections. Generally, several residual units are stacked together to obtain deep residual networks. Use of the combining residual connections and batch processing helps to simplify the training procedure since, computation of residual generates more stable gradient across the network [18].
Experimental results
Experimental setup
In order to analyze the system performance for NITS-LD, whole dataset (described in Table 1) has been split into three parts: NITS-train, NITS-development and NITS-test data set. Around 6hrs data of each of the 12 languages totalling to around 72-hours data forms the NITS-train set for this experiment. Out of the72-hour NITS-train set, 30hrs of data has been obtained from five tonal languages and remaining 42hrs of data has been obtained from seven non-tonal languages. Also, 1hr of data of each of the 12 languages, totalling to around 12-hour makes up the NITS-development set and 1hr data from each of the 12-languages totalling to around 12-hour makes up the NITS-test set. NITS-train, NITS-development and NITS-test set are mutually exclusive. Since the performance of the language classification system varies largely with the varying duration of the test utterances, the performances are analyzed for 30s, 10s and 3s duration of test utterances. To analyze the performance of OGI-MLTS database, 15hrs of training data (9hrs data from non-tonal category and 6hrs data from tonal category), 5hrs of development data and 5hrs of test data (30mints data from each language) of this database are used to perform the experiments.
For utterance level analysis features are extracted of 30s, 10s and 3s test data. 23 MFCC coefficients per frame constitute 3000×23 and 12 Chroma spectrogram coefficients constitute 3000×12 dimensional features for each 30s sample. Similarly, each 10s and 3s sample is represented by 1000×23 dimensional MFCC, 1000×12 dimensional Chroma and 300×23 dimensional MFCC, 300×12 dimensional Chroma respectively. Combinations of these features in a row makes 3000×35, 1000×35 and 300×35 dimensional features for each 30s, 10s and 3s samples respectively.
In case of score combinations at decision level, the output scores corresponds to individual inputs are used as input to train a classifier to stack the MFCC and Chroma models. For this the test set has been split again into two parts-one to train the decision level combiner model and other to test the resultant model. The logistic regression (LR) [28], support vector machine (SVM) [29] and Random forest [30] models have been considered for stacking the models. The % of accuracy calculated from the correctly identified trials making hard decisions (by selecting the top scored language) has been used to assess the system performance.

Residual block used in this study.
For syllable-level analysis, instead of using each utterance, syllables corresponding to the utterances of the above mentioned NITS-train set, NITS-development set and NITS-test set (used in utterance level analysis) have been considered. Generally, duration of different syllables are unequal in length and therefore, to train ResNets model, each syllable duration has been adjusted to 100 frames. Therefore, 100×23 dimensional MFCC and 100×12 dimensional Chroma for each syllable unit have been utilized to conduct the experiment. Here too, combinations of these features in a row makes 100×35, dimensional features for each syllable and for score combination at decision level, stacking of MFCC and Chroma based model has been accomplished by LR, SVM and random forest as in similar way of utterance level analysis. In this case, scores obtained for all the syllables of a test utterance are averaged to compute the score for that utterance. Then the % of accuracy of the system has been calculated in the similar way as calculated at the utterance level analysis. Experiments have been carried out for different network structures of ANN and it can be observed that 5L-8N-1L for existing features and 35L-50N-12N-1L for Chroma + MFCC feature with tan-sigmoid transfer function provides the highest accuracies. Here, CNN model contains 3 convolutional layers each having 256 kernels. Each kernel consists of 5×5 dimension filters. The output of the filter is passed through a rectified linear unit (ReLU) activation followed by max pooling operation layer of 2×2. The network architecture of CNN model is shown in Fig. 3(a). In CNN-LSTM, the CNN model is followed by an LSTM layer with 256 hidden nodes as is shown in Fig. 3(b). In both CNN and CNN-LSTM, outputs have been configured as a single output neuron with sigmoid activation to produce the class probabilities of pre-classification stage. The models have been trained by minimizing cross entropy loss using Adam optimizer and for 100 epochs with a mini batch size of 256.
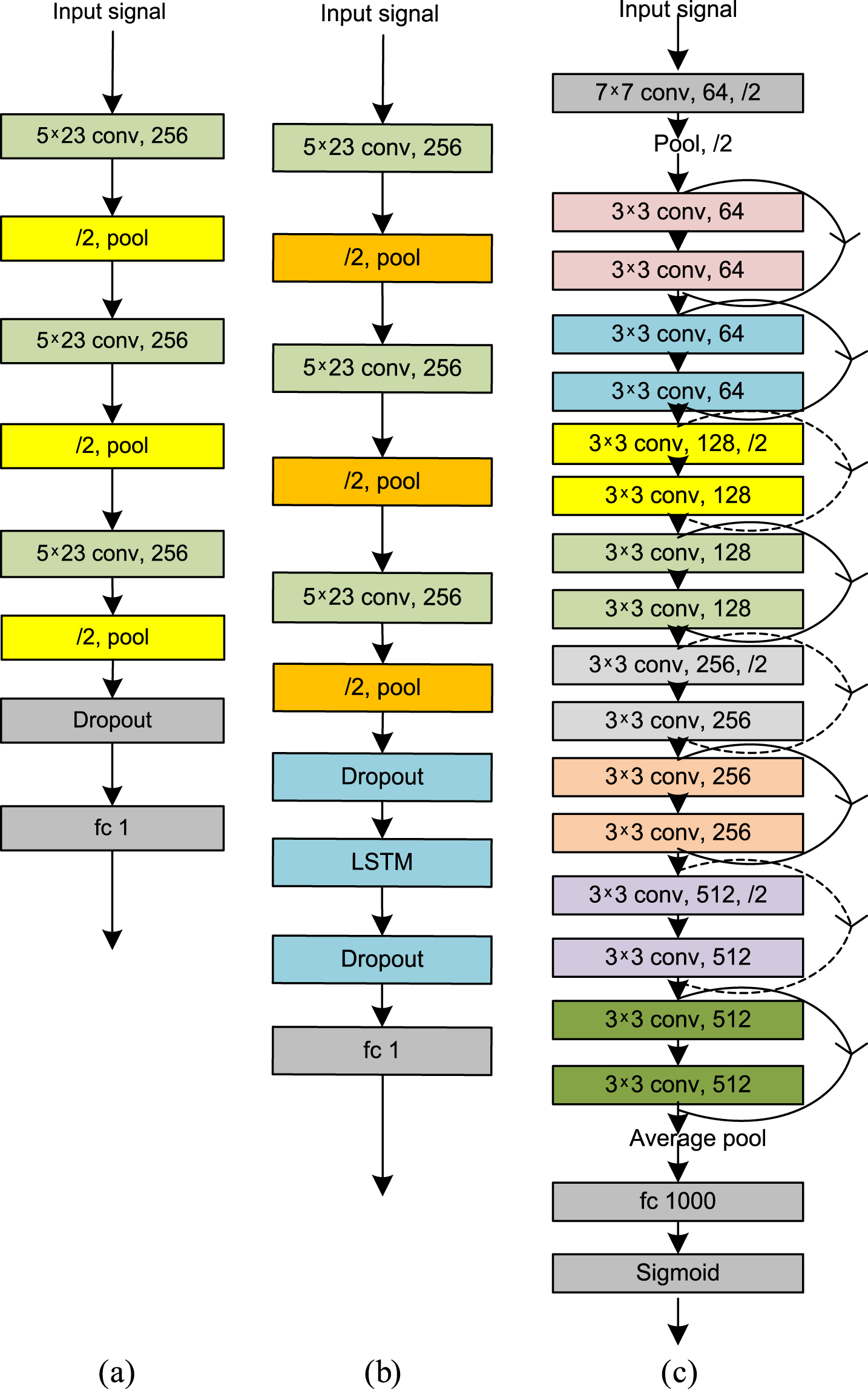
Block diagrams of three different CNN architectures. (a) CNN (for MFCC), (b) CNN-LSTM (for MFCC), (c) ResNets used at pre-classification stage.
Utterance level performance
An attempt has been made to analyze the system performance, built using different features, extracted of the whole utterance of the speech signal. Table 2 shows the performance of NITS-LD for the features extracted of the utterance of a sample and ResNets is used to model the features. Table 3 shows the performances of OGI-MLTS database. Here, pitch Chroma is denoted by F1 and MFCC is denoted by F2. From Tables 2 and 3 following observations can be made: Chroma features shows significant improvements with respect to the existing parameters of prosodic features. MFCC is more effective than Chroma and their Combination provide further improvements. It indicates that they carry complementary information for language pre-classification. The system provides better performance when output scores are combined at decision level Among the three different back-end classifiers, SVM provides the highest accuracy. Overall system performance obtained for NITS-LD is better than the performance for OGI-MLTS database. This is possibly because of differences in channel conditions, language characteristics etc.
Utterance level performance of NITS-LD for ResNets
Utterance level performance of NITS-LD for ResNets
Utterance level performance of OGI-MLTS database for ResNets
Figure 4 shows a comparative performance analysis of different models for both NITS-LD and OGI-MLTS database. It can be observed that ResNet performs the best, followed by CNN-LSTM, CNN and then ANN model. Thus it can be inferred that ResNets is able to model more language specific information than other models. Therefore, for syllable level analysis of the system ResNets are opted.

Comparative performance analysis of different classifiers for (a) NITS-LD, (b) OGI-MLTS database when features extracted from whole utterance.
In this case instead of considering the whole utterance, features are extracted from syllabic units of the speech signal. Table 4 shows the syllable-level performances of the system for two different databases. Following observations are made from Tables 2–4:
Here Chroma features are more effective than existing parameters of prosodic features.
Chroma and MFCC carry complementary information and their combination provide features provide the highest accuracy when they are combined at decision level.
Features extracted at the syllable levels are the most useful cues for discriminating tonal and non-tonal languages. This result reveals that syllables are the most accurate tone bearers.
Therefore, combination (decision level using SVM) of Chroma and MFCC features extracted of syllables are considered for the subsequent experiments.
Accuracies of ResNets for the features extracted of Syllables
Accuracies of ResNets for the features extracted of Syllables
Here, system performance has been analyzed for three different conditions. For condition I, pre-classification module is absent and hence individual languages are identified like a conventional LID system does (baseline). In condition II and condition III, pre-classification module is present at the first stage and the workings of the system in these two conditions are explained in section 2. Scoring is done in a similar way as done in the pre-classification stage. The likelihood scores of all the syllables constituting an utterance are averaged to obtain the scores for that utterance. Experimental results for NITS-LD using combination of Chroma and MFCC features extracted of syllables are given in Table 5. From Table 5 it can be observed that ResNets work well for almost all the languages. System provides highest accuracy for condition III and system performances are 3.8%, 4.1% and 4.3% better than the condition I for 30s, 10s and 3s test data respectively. For condition II, the system performances are 2.5%, 2.7% and 2.2% better than condition I. For condition III, experimental results are obtained considering that a hundred percent accurate pre-classification module is available. Therefore, it can be inferred that that an accurate pre-classification module can boost the performance of the system manifold.
Language wise performance of NITS-LD for three different conditions using combination of Chroma and MFCC feature
Language wise performance of NITS-LD for three different conditions using combination of Chroma and MFCC feature
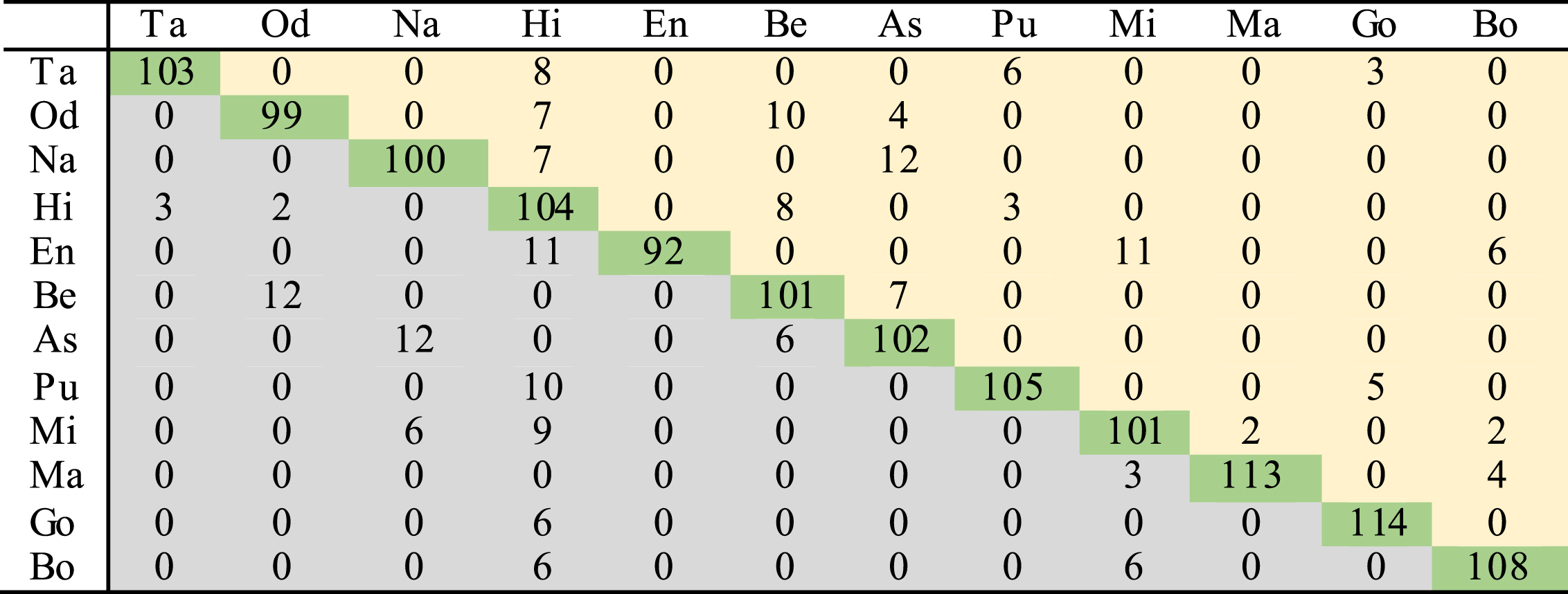
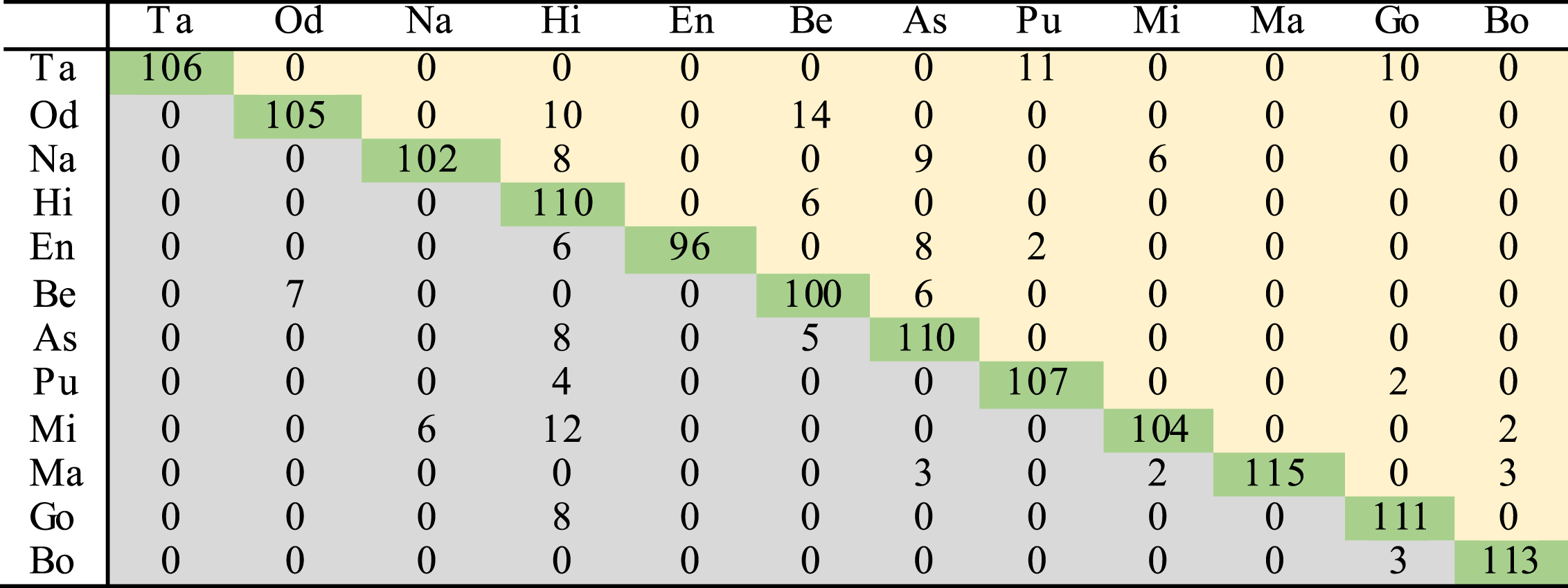
Table 6 shows the confusion matrix for condition I. Here, the performance of Hindi language is good. However, most of the languages are confused with it. Except Hindi, no other language is confused with Tamil. Gojri language shows the highest accuracy in this case. Confusion matrix for condition II is given in Table 7. It can be observed from Tables 6 and 7 that pre-classification module helps boost the overall performance of system. However, the individual accuracies of not all the languages improve. Due to error in the pre-classification stage itself, the accuracies for some of the languages become even lesser. Significant gain in accuracy is observed for languages which are classified correctly at the pre-classification stage, such that the overall accuracy of the system increases. Bodo language shows the highest accuracy in this condition.
Confusion matrix for condition I using 30s test data and combination of Chroma and MFCC feature (Rows correspond to actual class and columns to the assigned class of test data)
Confusion matrix for condition II using 30s test data and combination of Chroma and MFCC feature (Rows correspond to actual class and columns to the assigned class of test data)
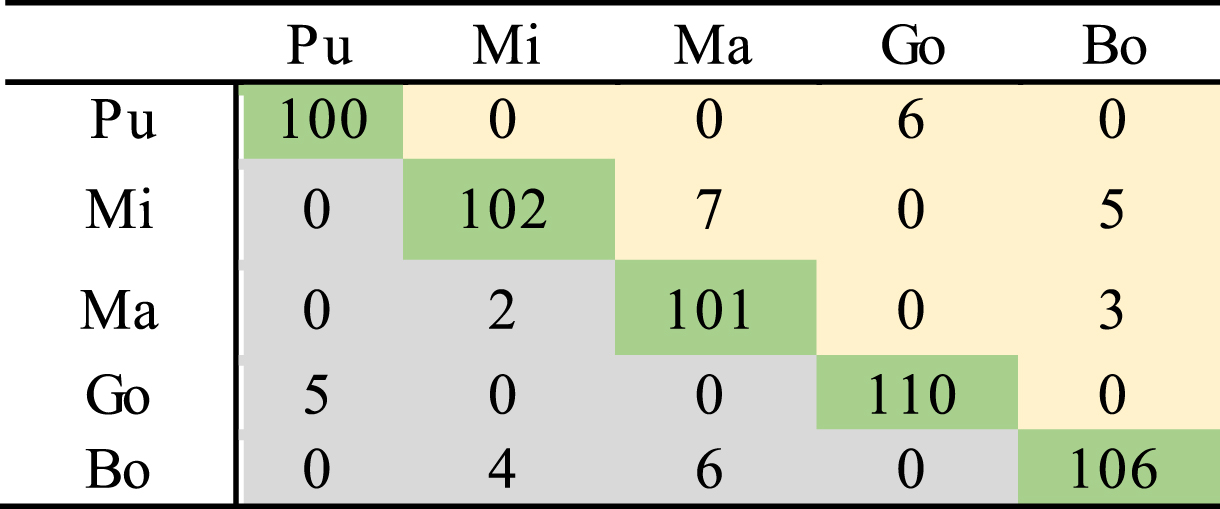
Tables 8 and 9 show the confusion matrices obtained for non-tonal and tonal languages for condition III. In this condition since, only truly detected tonal and non-tonal languages are identified at the second stage, there is no possibility to confuse the languages of tonal category with the languages of non-tonal category. It can also be observed that even though the highest accuracy is achieved by Hindi language, almost all other languages of non-tonal category are confused with it. Confusion of other languages with Tamil is very less. However, it is confused with only Bengali and Hindi languages. Gojri language provides the highest accuracy among the languages of tonal category. It is only confused with Punjabi and vice-versa. It is possibly because both Punjabi and Gojri are offshoot of the group of Indo-Aryan languages.
Confusion matrix for non-tonal languages using combination of Chroma and MFCC feature and 30s test data (condition III)
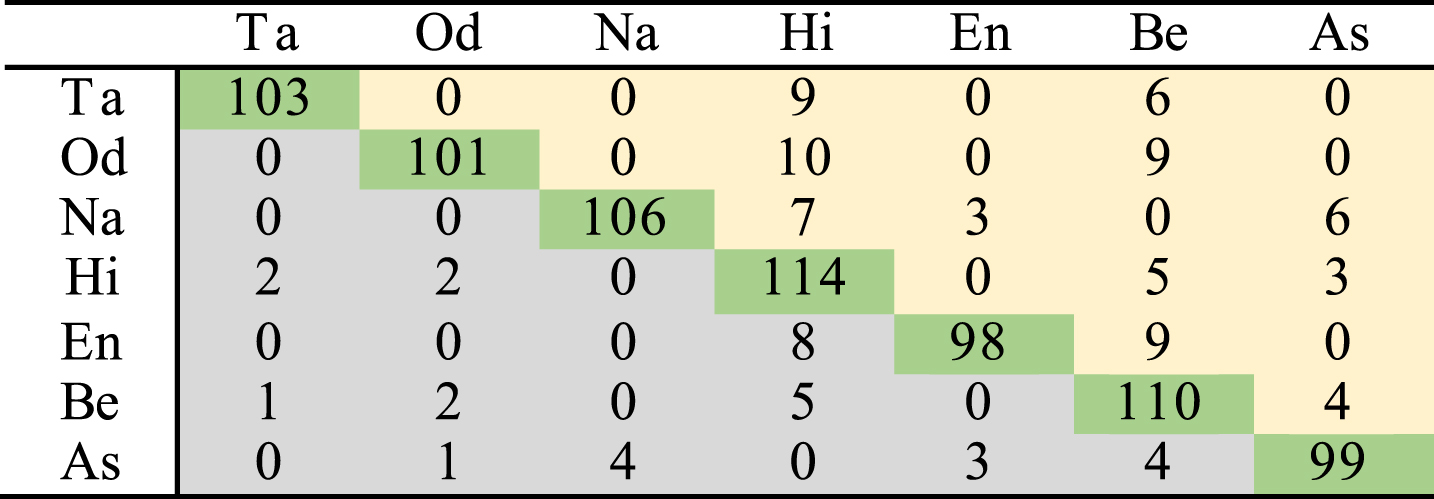
Confusion matrix for tonal languages using combination of Chroma and MFCC feature and 30s test data (condition III)
Performance of OGI-MLTS database for three different conditions are shown in Fig. 5. In this case also, pre-classification module helps to boost the system performance. It may be reasoned that in condition II, use of pre-classification module helps to reduce the confusion among the languages. Also in condition III there is no possibility to confuse the languages of non-tonal category with the languages of tonal category. Therefore, condition III reports the highest accuracy, followed by condition II and then condition I. So, it may be inferred that improving the accuracy of the pre-classification system may help to reduce the confusion and thereby enhance the performance of the individual language identification module.
From Table 5 and Fig. 5 it can also be observed that after introduction of pre-classification module improvements in the system performance for OGI-MLTS database (6.8%, 6.5% and 5.4%) is more significant than NITS-LD (3.8%, 4.1% and 4.3%). This could be because OGI-MLTS database has been prepared using World’s distinct language whereas NITS-LD includes closely related languages of same origin.
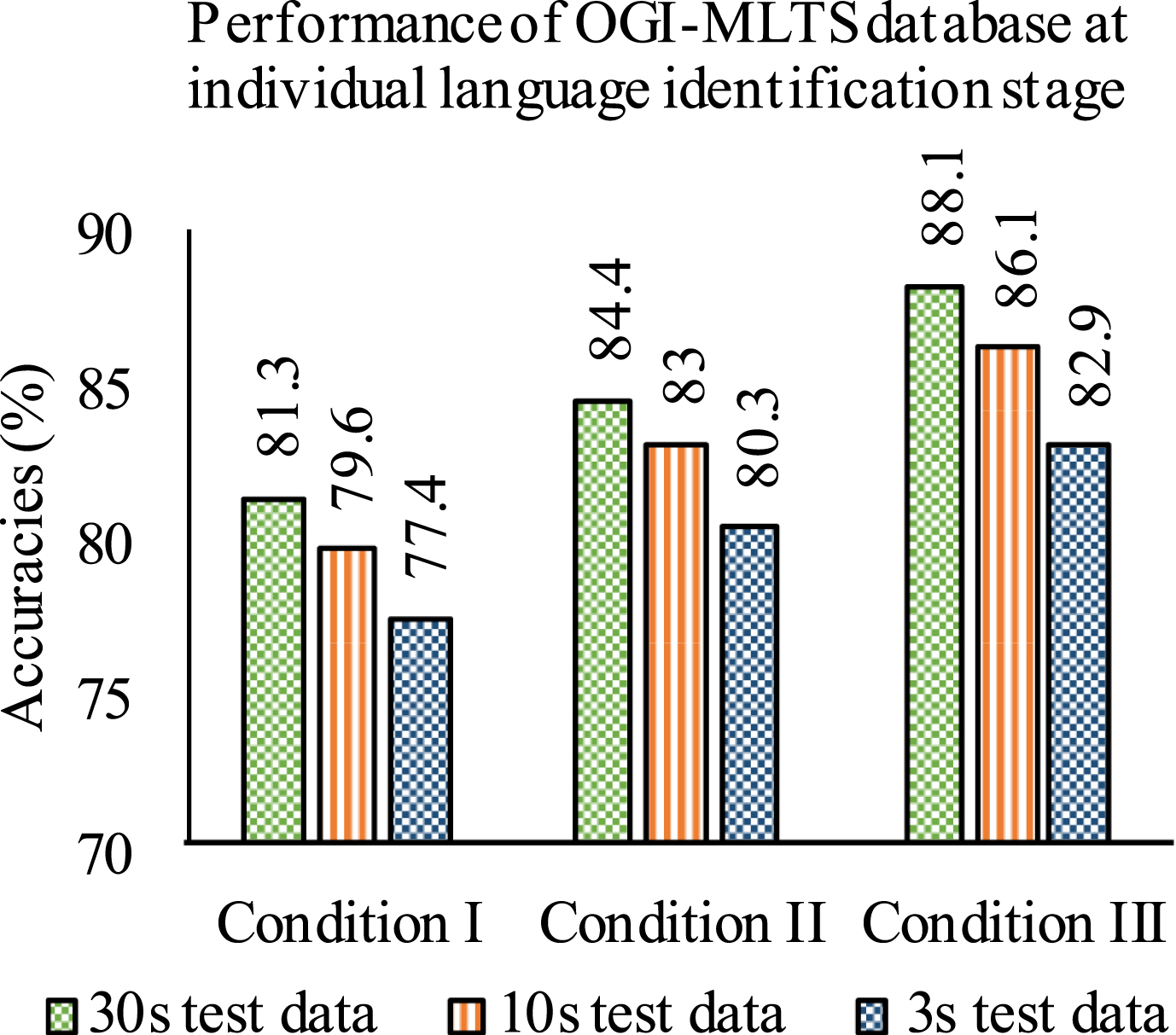
Performance of OG-MLTS database for three different conditions.
This section compares our work on language identification with other related works [2, 14]. Table 10 depicts the performances of different LID system for Indian languages along with our proposed system. Table 10 shows that our system provides better performance as compared to the performance of some of the existing system.
Different LID system for Indian languages
Different LID system for Indian languages
In this paper, pre-classification based LID system has been proposed for Indian languages. This approach firstly identifies the category of the language and then identifies the language from that category in the second stage. Therefore, number of comparisons required to identify a language is lesser. It also shows that both pitch Chroma and MFCC are useful for this system and have complementary information. Experiments have been conducted for twelve languages of NITS-LD and ten languages of OGI-MLTS database using different features extracted at both syllable and utterance levels. Experimental results indicate that the syllables are the most appropriate analysis units to be used for this pre-classification based LID system. Results also confirm that ResNets are well suited for this task and provide better performance than other neural network architectures such as ANN, CNN, and CNN-LSTM. Here, 30s duration test data and ResNets models provide the highest accuracies of 90.1% and 88.1% for NITS-LD and OGI-MLTS respectively. Also experimental results indicate that effectiveness of pre-classification module for the world’s distinct languages of OGI-MLTS database are more prominent than that of the case closely related Indian languages of NITS-LD.
In future, further experiments can be carried out to handle noisy data. Instead of using two-stage identification system, languages can be identified level-by-level to obtain better accuracy of the system.
Footnotes
Acknowledgments
The authors would like to thank the members of Speech and Image Processing Laboratory of ECE Department, NIT Silchar, Assam for providing necessary facilities and support to carry out this work.