
Abstract
Generally, several IoT (Internet of Things) applications employ cloud data centre for processing the data generated by edge devices like smartphones and tablets. Due to the increasing use of the IoT devices, the demand for higher computational and communication capabilities are also increasing. With the advent of Edge Computing and given the fact that computational capabilities are currently untapped, a part of the computational load can be offloaded to the edge nodes. In this paper, a Grefenstette bias based Genetic Algorithm for MultiSite Offloading (GGA-MSO) is proposed. This algorithm decides the schedule of the application that could be offloaded. The proposed algorithm provides a solution which has convergence in lesser time by employing diversification of initial population using the Grefenstette’s Bias method. Besides, the container based lightweight virtualization is analyzed for offloading code and data to the nearby devices. The evaluation of the proposed work on random graphs shows that the proposed method starts to converge with significantly lesser iterations than its counterpart with undiversified population. The test bed results on Single Board Computers (SBC) like Raspberry Pi setup indicates that by adapting container virtualization in the edge environment, the performance of the IoT devices is improved and the communication overhead is reduced.
Keywords
Introduction
Today’s world is filled with mobile devices, and are connected to the internet for creating smarter environment. Such devices are commonly referred to as Internet of Things (IoT). In the past decade, cloud computing technology helped to create a smarter environment by leveraging the processing and the storage needs of mobile devices. Augmented reality, natural language processing, gaming, face recognition and image processing are some typical IoT applications [1–3]. These applications are computation intensive and devices are often resource constrained. In spite of many efforts like incorporating multi-core processors the resources requirement still continues to grow. Computation offloading as a framework is useful in such a scenario. It offloads the computationally intensive part to resource rich systems that are referred to as Mobile Cloud Computing (MCC) or cyber foraging or surrogate computing [4]. Several offloading cloud infrastructure frameworks [5, 6] have been proposed by researchers that use the cloud infrastructure for executing computation-intensive applications on mobile devices like smartphones.
However, with the unprecedented proliferation of IoT devices, cloud computing faced serious challenges in the areas of bandwidth requirement and latency response. Many IoT applications require a response time of a few milliseconds. In order to meet this requirement, a new technology called Edge or Fog or Cloudlet computing [7, 8] was introduced as a supplement to cloud computing technology. Edge computing is a technology that brings in the computation and storage capabilities proximate to the end devices, thereby addressing the bandwidth and latency response issues [9]. A roadside traffic unit may be an edge device wherein there is an edge between a vehicle’s OBU and cloud. Similarly, Cloudlet or Clonecloud acts as an edge between smartphones and cloud. The edge computing framework is in its infancy stage but it still offers many benefits. It offloads the computation intensive part to the edge or nearby devices [10, 11].
In a MCC offloading framework environment, the mobile devices are connected to a high performance server that supports efficient computation offloading. Most of the previous works done in the area; focus on finding an optimal partitioning solution for a single site offloading involving the end device and the cloud. However, the multisite offloading solution will be feasible for edge environments to share computation resources between the surrogates and may lead to significant improvement in terms of performance and energy consumption of mobile devices as shown in Fig. 1.

Offloading Scenarios.
Therefore, in this work multi-site offloading optimization strategy model is considered, and the decisions are made by analyzing parameters like bandwidth, surrogates speed, available memory, loads on the surrogates, and the amount of data exchanged between surrogates and mobile systems. Due to NP-complete decision nature of the problem, it is difficult to design the multisite offloading problem and solve it in polynomial time. In order to resolve this, a Genetic Algorithm (GA) based multisite application partitioning algorithm is proposed, which automatically decides the part of the application to be offloaded to a particular site. Besides most of the existing computational offloading mechanisms [12] depend on virtualization technologies like application level virtualization, hardware virtualization or code migration techniques [13–15]. Adapting such techniques in an edge offloading environment is a cumbersome process because the edge or nearby surrogates are resource limited environments. An alternate lightweight virtualization called OS level virtualization like Docker container is used in this work for offloading the computation part to the nearby surrogates. Other such similar containers include LXC, Open VZ and Imctfy [16–18].
The main contributions of this work are: Offloading decision algorithm for edge environment using Grefenstette’s Bias in GA to achieve optimal partitioning and faster convergence A test bed set-up to evaluate the offloading decisions by adopting Docker container virtualization
The rest of the paper is organized as follows: Section 2 outlines the existing studies that are closely related with the present work. The preliminaries necessary for the offloading algorithm is discussed in section 3. Sections 4 and 5 present the proposed GGA-MSO algorithm and discuss the results obtained. The concluding chapter presents some useful insights on the topic and suggests possible future enhancements.
Many computation intensive applications are benefitted from computation offloading. Most of the articles produced on this subject focus on mobile applications and demonstrate better performance, efficient power consumption and minimization in execution time with the help of offloading. Some of such key articles and their details are tabulated in Table 1.
Related works based on offloading
Related works based on offloading
From the related studies, it transpires that many works focus on single site offloading, i.e. they execute either on a local device or a cloud data centre. Additionally, many offloading frameworks depend on system virtualization, application virtualization or code migration to execute the offloaded code on to the cloud server. These works are proposed for the MCC environment but they may not be suitable for the edge environment as the application’s part can also be offloaded to multiple devices, i.e. multisite offloading need to be considered. A few research works have focused on multisite offloading but still in its undeveloped stage. Considering all these, the proposed study uses GGA-MSO to perform multisite offloading and the results obtained are evaluated in an edge environment using a light weight virtualization technology called Docker container virtualization for offloading the computation intensive part to the nearby devices.
System architecture
A decision algorithm is designed to schedule, the offloadable and non-off loadable components in an application such that the total energy consumption of the mobile device and execution time of an application is reduced. Certain components cannot be offloaded due to security issues or due to their interaction with the hardware devices like cameras, sensors and GPS and some components have to be executed locally or by the remote system.
Figure 2 shows the system flow of the proposed work. It can be seen that the application running on any mobile device can be modelled as Task Interaction Graph (TIG) with the help of a profiler (hardware and software tools) [36]. The TIG is formulated as a weighted graph as shown in Fig. 3. Each node in a graph represents the computational task and the edges represent the control dependences between the tasks. The weighted graph is fed as an input to the decision making engine that will decide which part of the application’s module has to be offloaded to which nearby device. Based on the decisions, the offloadable task and its data are sent as Docker images to the nearby devices by adopting Docker container virtualization.
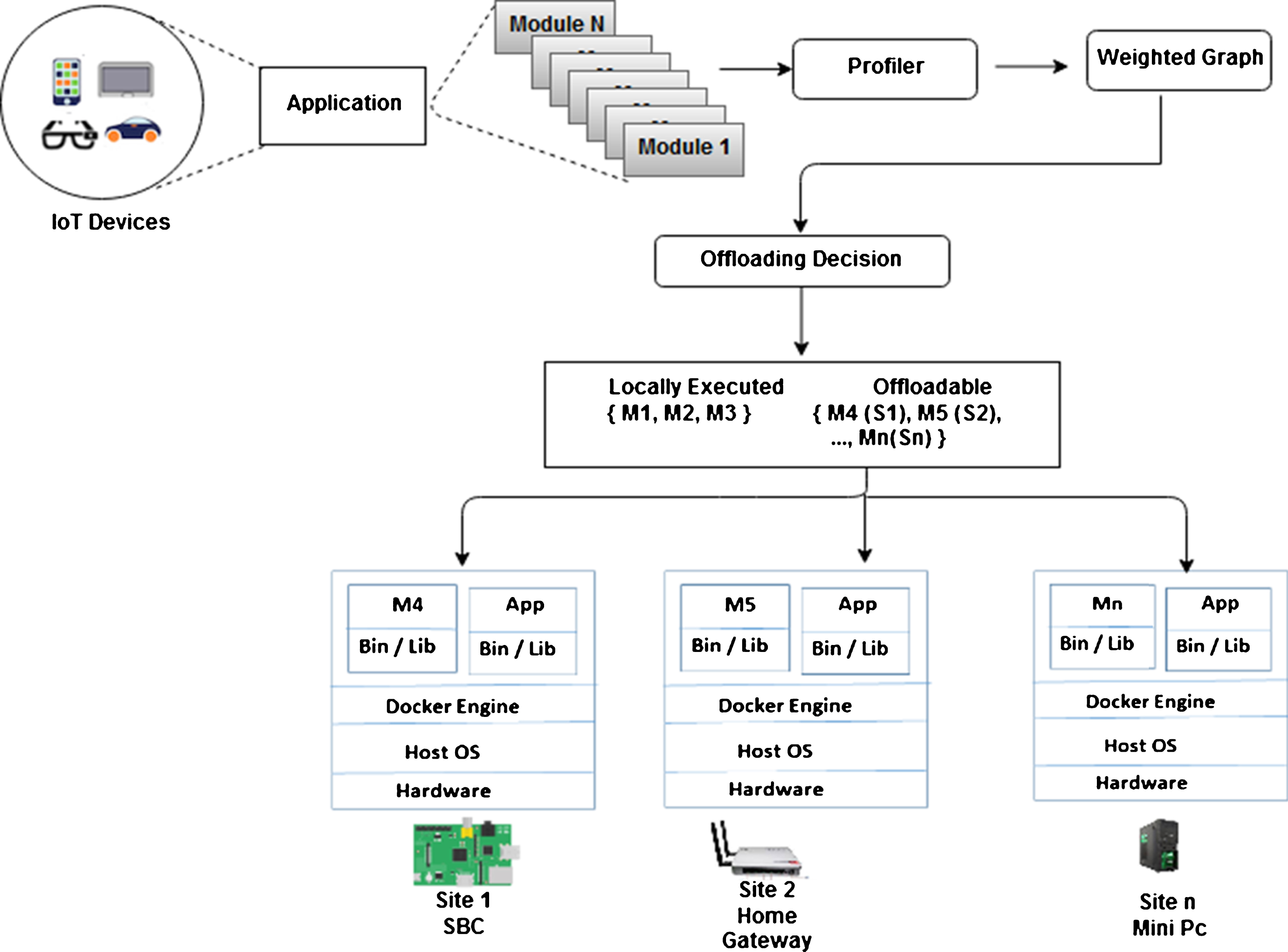
Offloading Framework.
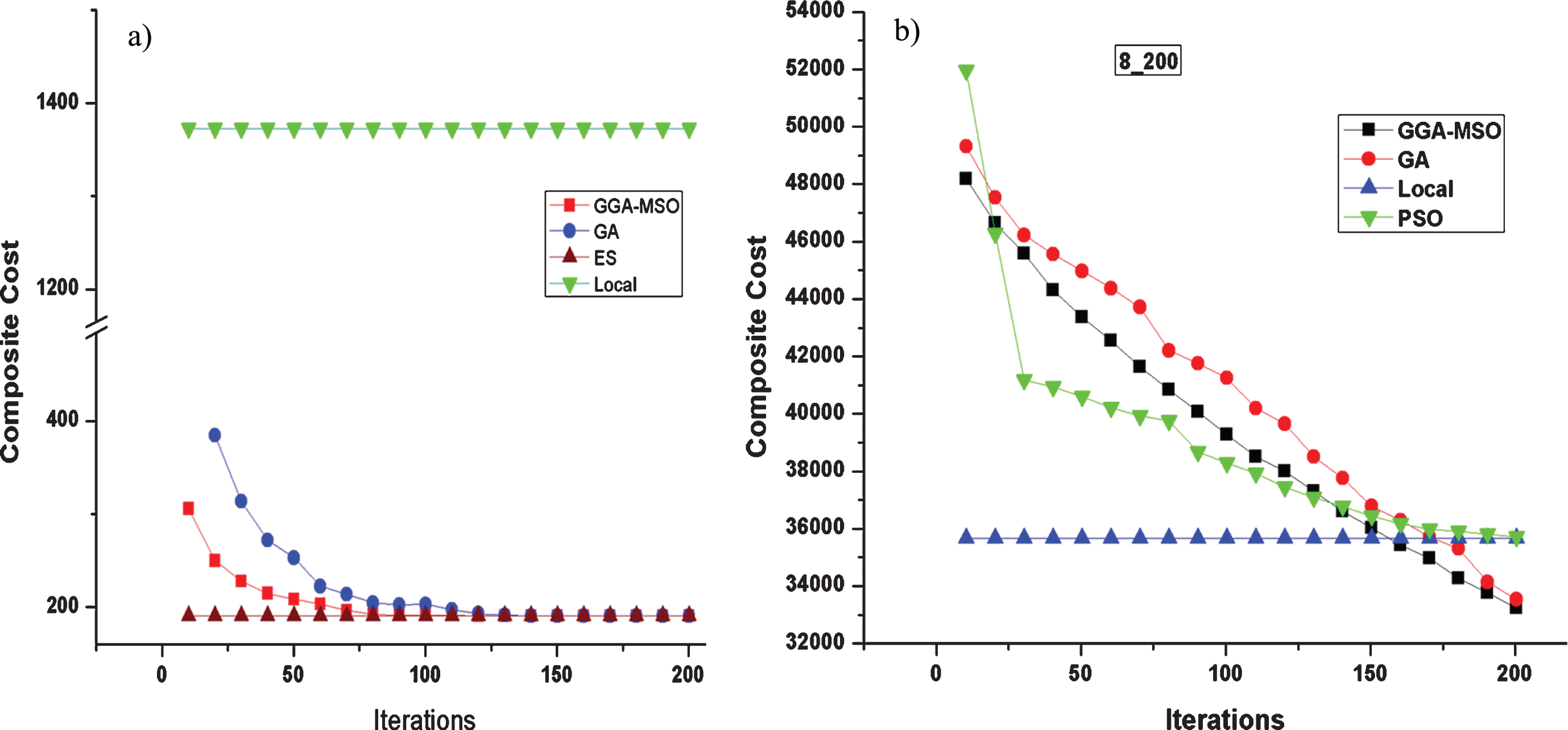
a) Comparison of Composite Cost of Different Model with 10 Modules and 8 Sites. b) Comparison of Composite Cost of the Proposed work with PSO.
To guarantee that the offloading will be profitable, a suitable offloading optimization strategy is adopted for the reduction of execution time and power consumption. If T
d
is the time taken by a task to transmit the data, T
S
is the time taken by a task to execute on remote site and T
m
is the time taken to execute on the mobile device then offloading will be beneficial if T
d
+ T
s
> T
m
. Similarly, for efficient energy consumption, the task can be offloaded if the energy required on mobile is greater than offloading, i.e. E
offload
< E
Loc
, where E
offload
= E
Net
+ E
idle
, E
Net
– Energy required to transmit a data, E
idle
– Energy required to be in idle till response from a server. The parameters that are essential to make the offloading decision are: The execution time of task i on a mobile device j can be represented as shown in Equation (1)
T
CPUcycle
- Number of instructions freq
j
- represents the frequency at which device j run By adopting Dynamic Voltage and Frequency Scaling (DVFS) [37, 38], an appropriate frequency can be used to balance the power consumption and reduction in execution time. Similarly, memory availability, current CPU load and battery discharge are the other essential parameters to be considered while making a decision. To avoid the computational complexity for each vertex, a composite weight is assigned as expressed in Equation 2. Each vertex has multiple weights as To compute the communication cost, the edge weight can be denoted as B
link
- Bandwidth The energy consumption required to execute a task j on mobile device i can be represented as Ei,j as in Equation (4)
P
cpu
-Power required for executing single instruction cycle
With these input parameters the offloading algorithm aims at finding the optimal partitioning by minimizing the execution cost and the power consumption of a device and it formulated as,
The optimization execution model (T) can be calculated as shown in Equation (6) by considering the composite weight and communication cost as,
Where
Similarly the energy consumption model E can be calculated as shown in Equation (7) as,
Where x ≠ y, j ∈ adj (i) and
Where
GGA-MSO is used to find the offloadable and non-off loadable components in an IoT application. In order to obtain an optimal solution, the characteristics and selection of genetic algorithm have to be fine-tuned and this is a difficult task. When using the genetic algorithm characteristics such as initial population, selection criteria, mutation probability, crossover probability, stopping criteria and fitness function are commonly addressed.
With the intent of meeting the requirements at hand, the proposed algorithm is divided into two phases as initialization and execution phases. During the initialization phase, the input values for the random graph and population generation will be carried out. In the execution phase, the genetic operators are applied after evaluating the fitness value. The overview of the proposed GGA-MSO is explained in algorithm 1.
Initialization phase
Random graph generation and the input data
The proposed work is evaluated using directed random graphs. The associated cost related with random graphs such as composite weight (CW (v)), bandwidth and adjacency matrix to show the relation between nodes is generated randomly.
Algorithm 1 - Overview of the Proposed Algorithm
iteration_count = 0 population = GENERATE-POPULATION(nos, nom, sop) loop fit = [0…population.length] for i = 0 to population.length fit [i] = FITNESS (individual, adjacency, cost, bandwidth) new_population = SELECT (fit, population) for x, y randomly chosen in new population CROSSOVER (x, y) population = MUTATE (population, nos) iteration_count = iterationcount+1 until iteration_count <threshold or global_fitness> = fitness_threshold
Initial population generation
The initial random population is an important characteristic because it is related to all the other parameters and operators, i.e. if the initial population of the genetic algorithm is diversified [39], then the algorithm has the best possibility of finding a global solution. In order to achieve this, the diversity can be done at the gene level, chromosome level or at the population level [40]. To determine the diversity, Grefenstette biased method is chosen. The bias measures suggested by Grefenstette to find the diversity at gene-level is expressed in Equation (8) as,
l – chromosome’s length
n – Population Size, and NPop ij is the normalized Jth-gene of the ith- chromosome. i.e., NPop ij ∈ [0, 1].
In the proposed work, with the intent of ensuring the diversity a threshold value is taken. Whenever the diversity measure is less than or equal to the threshold value, then the population is considered as diversified. The criteria for choosing the threshold is stated as shown in Equation (9)
When the population is uniformly distributed, the above equation becomes
Where, Pop ij denotes ith chromosome’s jth gene. Pop ij ∈ [0, nos - 1]
nos: the number of sites
l: length of the chromosome.
n: population size.
The above result is an approximated value that is obtained by assuming that the number of sites is always a divisor of a number of chromosomes. However, this is not always true. Hence, the threshold value is taken as 0.5+ ∈. For example, if the size of the population is 8 then the number of sites is 4 and length of the chromosome is 8 4. An instance of the diversified population can be stated as, {(0,1,2,3) (1,2,3,0) (2,3,0,1) (3,0,1,2) (0,1,2,3) (1,2,3,0) (2,3,0,1) (3,0,1,2)} and the threshold for the population is obtained using Equation (9) as,
In this way, the initial population is generated based on this diversified value. The time taken for generating the diversity in an initial population is negligible as the time expected in determining the diversity of initial population will be compensated with the number of iterations and the optimality of the solution.
The fitness function for the population is calculated using Equation (6). At each step, the GGA-MSO algorithm tries to find a partitioning with a minimum composite weight than the previous iterations. Once the fitness functions are evaluated, the best chromosome is updated. The next set of the population is chosen by tournament selection method. During crossover, the selected chromosomes are combined to generate offspring. In the mutation step, the genes of the chromosomes are mutated using a predefined mutation rate of 0.2. The GGA-MSO is completed with predefined iterations or until it satisfies the prescribed threshold value.
Results and discussion
Random graph evaluation
Simulation experiments were done on random graphs with nodes as modules to evaluate the performance of the proposed GGA-MSO algorithm. The specification of the random graph and the parameters used are presented in Table 2. In order to ensure uniform results, each graph with different nodes such as 10, 50, 100, 200 are tested under two different sites, i.e. a graph with 10 nodes executes on 4 or 8 sites. At each step, the number of iterations is increased from 10 to 200 and a single iteration is run for an average of 20 runs. The following algorithms are compared with the proposed work to make an effective comparison:
Specification of Random Graph and Parameters Used
Specification of Random Graph and Parameters Used
Case 1: Exhaustive Search (ES) Case 2: Application executes on local sites Case 3: General Genetic Algorithm (GA) Case 4: Proposed GGA-MSO algorithm Case 5: Particle Swarm Optimization (PSO)
The obtained results are analyzed by varying the number of iterations, population size and bandwidth.
a. By Varying Iterations
Figure 3a shows that by diversifying the initial population, each iteration produces an optimal partitioning result when compared with the initial population that is not diversified. In most of the test cases, the proposed work starts to converge after 60th iteration onwards and produces optimal partitioning.
The results obtained are compared with the Exhaustive search (with all possible combinations). On an average, 95% accuracy is obtained using the proposed GGA-MSO method. Exhaustive search fails if the input size grows beyond ten modules as the number of iterations to be done is n m (n - sites, m - modules). From the graph, it can be seen that the offloading will be beneficial than executing on a local device. From Fig. 3b the convergence rate of PSO is comparatively high compared to GA and GGA-MSO but it suffers from the fact that its exploration ability is not as high as Genetic and GGA-MSO because particles share information only with help of Global best value. It has a fast convergence towards local optimal solution but lacks in attaining global optimal solution. In Fig. 4, the results are normalized using the min-max normalization method and the results reveal that the proposed work starts to convergence earlier to find the global optimal solution when compared to the results that are not diversified.
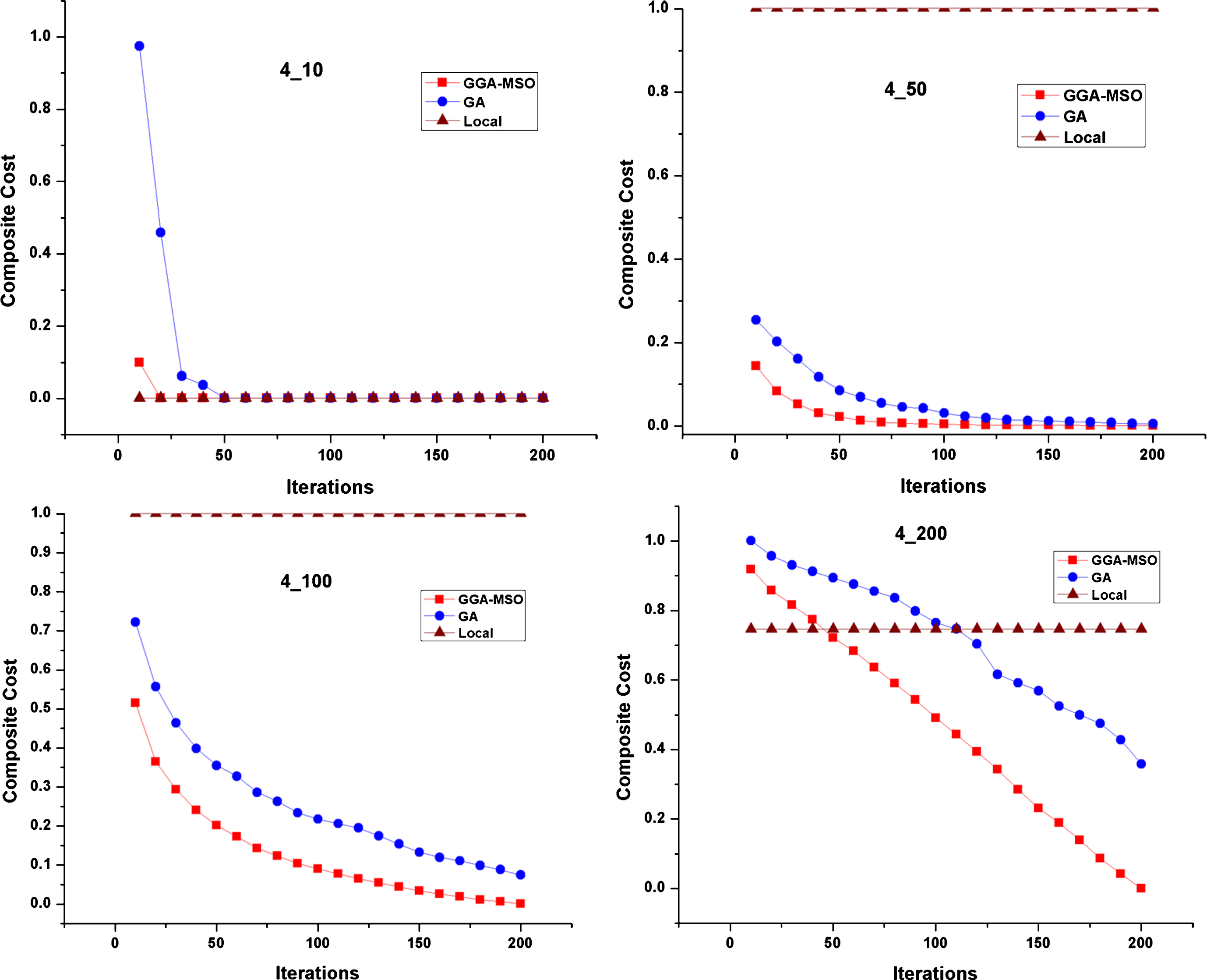
Varying Iterations for Module 10, 50, 100 & 200 with 4 Sites.
b. By Varying Population Size and bandwidth Cost
Figure 5a presents the results obtained by changing the initial population size. It shows that the results are converged early to find the optimal solution when the size of the population increases. Figure 5b shows the results obtained by varying the bandwidth between the sites. It shows the results for the graph with 50 modules and 8 sites. When the bits transferred rate is lower, the composite cost increases. So it is better to offload whenever there is the availability of required bandwidth.
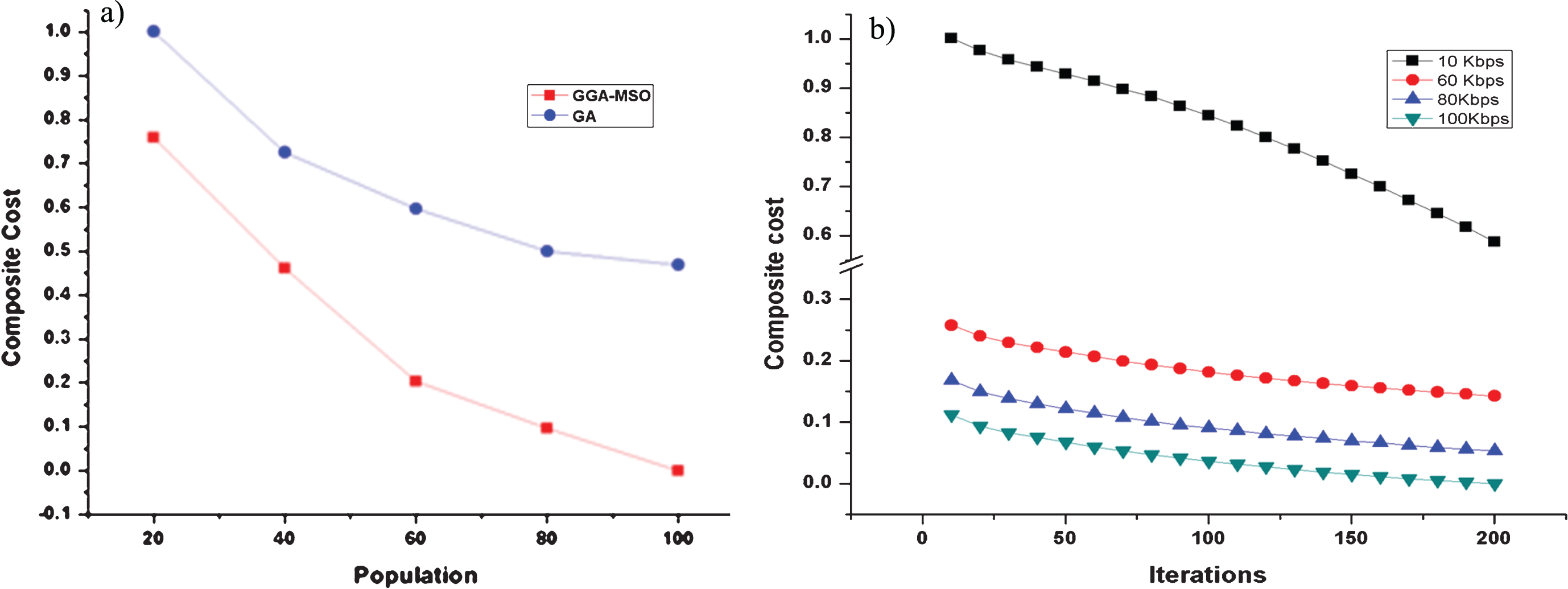
a) Varying Bandwidth Cost for 200 Modules on 8 Sites. b) Varying Bandwidth Cost 200 Modules on 8 Sites.
In order to analyse the importance of Docker migration in an offloading framework, a test bed for video analytics application is created and the different scenarios are presented in Table 3. The offloaded application size is 22.1 MB and the input sample video (Frame size = 1280×720 and Bitrate = 2604kbps) size is 6.5 MB. The computation intensive part and its data are offloaded to edge & cloud and the results are analyzed using Docker containerization in an edge computing environment.
Test bed for video analytics application
Test bed for video analytics application
The end devices chosen are Raspberry Pi2 and Raspberry Pi3, Intel i5 edge device and Amazon EC2 free-tier instance (t2.micro) as a cloud resource.
The results show server copy (offloading data and application as Docker image) power consumption, average power consumption after server copy and total execution time. Figure 6(b) represents the results of an application executed directly on the systems Pi2, Pi3, and intel_i5. Part of the video and video processing application is migrated as Docker image and the results in Fig. 6(a) show that 1-Edge prove to be a viable candidate for video analytics in terms of power and time. 1-Cloud is executed over the link (speed Test: ping = 38ms, download speed = 12.19 Mbps, upload Speed = 8.62 Mbps) and the results show the overall measure fails to overcome the performance of 1-Edge scenario.
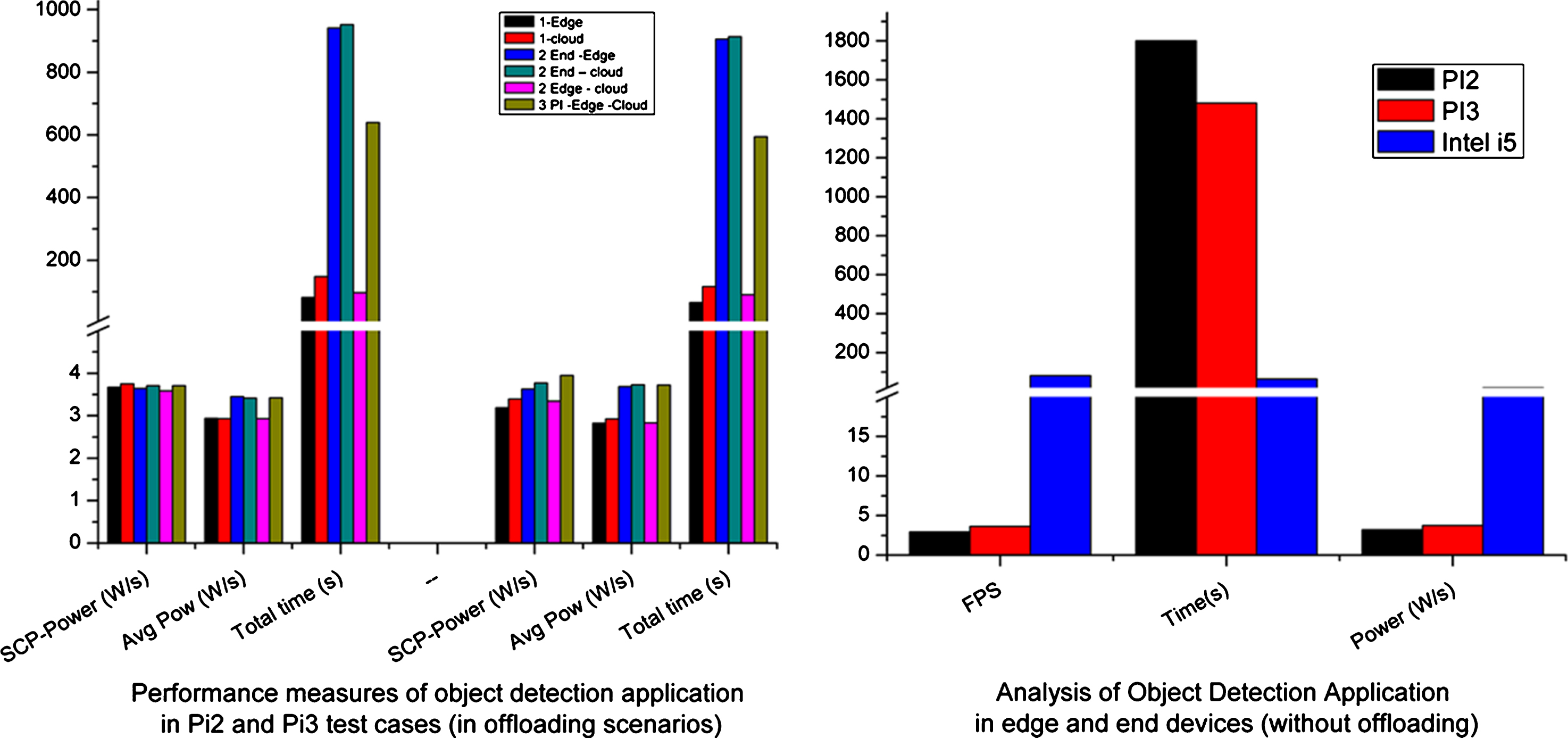
(a, b) Results of Video Analytics (Object Detection) with & without Offloading.
All other variances, using end device as a part of the execution produces an acceptable result. Thus, in overall test beds, 1-Edge scenarios show reliable performance over the others. Thus, the use of Docker containerization as an offloading framework improves the lifetime of the end device and reduces the communication overhead that is created by system virtualization.
The present study deals with the crucial issue of offloading of applications over multiple sites. The measure of diversity plays a significant role in the proposed GGA-MSO algorithm that uses Grefenstette’s bias for strengthening the initial population. The proposed GGA-MSO algorithm is evaluated using random graphs with a different number of nodes and sites. The proposed work obtains a global optimal partitioning solution and the convergence rate is also faster. The results prove that the offloading is beneficial than executing on the local site. Additionally, this research work demonstrates the use of lightweight container technology in offloading frameworks by offloading the video analytics application and its data as a Docker image migration. The results show that the edge environment provides optimal results with regard to latency response than the cloud environment and it also reduces the overhead incurred by virtual machine migration and code migrations. As a future enhancement, a new algorithm which can facilitate in better exploration and has less time complexity has to be generated so that computation complexity will still get reduced.
Footnotes
Acknowledgments
The authors wish to express their sincere thanks to the Department of Science & Technology, New Delhi, India project-ID:SR/FST/ETI-371/2014) and SASTRA University, Thanjavur, India for extending the infrastructural support to carry out this work.