
Abstract
Fuzzy inference systems have been successfully applied to many real-world applications. Traditional fuzzy inference systems are only applicable to problems with dense rule bases covering the entire problem domains, whilst fuzzy rule interpolation (FRI) works with sparse rule bases that do not cover certain inputs. Thanks to its ability to work with a rule base with less number of rules, FRI approaches have been utilised as a means to reduce system complexity for complex fuzzy models. This is implemented by removing the rules that can be approximated by their neighbours. Most of the existing fuzzy rule base generation and simplification approaches only target dense rule bases for traditional fuzzy inference systems. This paper proposes a new sparse fuzzy rule base generation method to support FRI. In particular, this approach uses curvature values to identify important rules that cannot be accurately approximated by their neighbouring ones for initialising a compact rule base. The initialised rule base is then optimised using an optimisation algorithm by fine-tuning the membership functions of the involved fuzzy sets. Experiments with a simulation model and a real-world application demonstrate the working principle and the actual performance of the proposed system, with results comparable to the traditional methods using rule bases with more rules.
Introduction
Fuzzy sets and fuzzy logic theory provide an efficient way of handling vague information that arises due to the lack of sharp distinctions or boundaries between pieces of information. With the ability to effectively represent and reason human natural language, fuzzy logic theory is considered as an advanced methodology in the field of control systems. The most common fuzzy model is the rule-based fuzzy inference systems, which is mainly composed of two parts: a rule base (or knowledge base) and an inference engine. The inference engines have been defined by different inference approaches, such as the Mamdani model [1] and the TSK model [2]. Although the TSK model is able to generate crisp output, the Mamdani model is more intuitive and suitable for dealing with human natural language. A common feature of all these classical fuzzy inference systems is that they are only applicable to problems with dense rule bases, by which the entire input domain must be fully covered.
Fuzzy rule interpolation (FRI) [3] was initially proposed to address such a limitation due to its ability to work with a spare rule base. When system inputs or observations do not overlap with any rule antecedent values, traditional fuzzy inference systems are not applicable as no rule can be fired. However, fuzzy rule interpolation can still generate a conclusion through a sparse rule base, thereby improving the applicability of fuzzy models. FRI can also be employed to reduce the complexity of complex fuzzy models by excluding those rules that can be approximated by their neighbouring ones. A number of important fuzzy rule interpolation methods have been proposed in the literature, such as [4], which have been successfully applied to deal with real-world problems [8–14].
Fuzzy rule base generation has been intensively studied in the literature. It is usually implemented in one of two ways: data-driven (extracting rules from data) [15] and knowledge-driven (generating rules from human expert knowledge) [16]. Both approaches may suffer from the ‘curse of dimensionality’. In addition, the knowledge-driven method may be further negatively affected by the limited availability of expert knowledge. Data-driven rule base generation was proposed to minimise the involvement of human expertise. The success of data-driven approaches is built upon a large quantity of training data. These approaches usually only target dense rule bases that are used for traditional fuzzy inference approaches. However, redundancy often exists in fuzzy rule-based models that are acquired from numerical data. This results in unnecessary structural complexity and reduces the interpretability of the system. In order to reduce the complexity of such rule bases, various rule base reduction approaches have been developed to minimise the redundancy [17–20]. Most of such approaches are based on certain similarity measures; therefore, they are likely to cause performance deterioration along with the size reduction of the rule base.
This paper presents a data-driven rule base generation approach for FRI based on the initial work reported in [21], which directly generates sparse rule bases from data sets by effectively using curvature values traditionally utilised in geography. Different to the conventional fuzzy rule base generation approaches, the proposed approach discriminates rules by calculating their curvature values. Note that curvature values are only workable in three-dimensional spaces (or a rule with two antecedents and one consequence) and thus cannot be directly used for higher-order problems. As a solution, for any given higher-order problem, the proposed approach firstly decomposes the higher-order space into a number of three-dimensional spaces, and then approximates the importance of the higher-order spaces by aggregating the curvature values of the corresponding decomposed three-dimensional ones. From this, the most important rules are selected to form a raw rule base, which is then optimised using a general optimisation approach, such as the genetic algorithm. The proposed approach is validated and evaluated by two experiments; the results demonstrate that the proposed approach is promising.
The rest of the paper is structured as follows. Section 1 Background introduces the theoretical underpinnings of rule base generation, fuzzy rule interpolation, and curvature calculation methods, upon which this work is built. SparseRuleBaseGeneration presents the proposed approach firstly for a basic case with two inputs and then for a general case with multiple inputs. Experimentation details the experimentation for the purpose of demonstration and validation. Conclusion concludes the paper and suggests probable future developments.
Background
Background
Rule base generation and reduction
RuleBase Generation/Reduction Fuzzy modelling describes systems by establishing relations between the relevant variables in the form of if-then rules. There are mainly two types of fuzzy rule base generations for fuzzy modelling. One is knowledge-driven and the other is data-driven. Although early-stage fuzzy models were built by knowledge-driven methods, recently there has been an increasing interest in data-driven methods that can obtain fuzzy models from measured data. According to the different forms of the consequent parts in the if-then rules, there are two types of fuzzy models, Madamni [1] and TSK [2]. A multi-input and single-output (MISO) fuzzy model is represented as a collection of fuzzy rules in the following form:
Most fuzzy rule base generation methods are based on grid-type fuzzy partition. They divide a given problem space into a number of fuzzy regions, each representing a fuzzy rule that is used to construct the final rule base. From this, the raw rule base is optimised by a general optimisation approach, such as the genetic algorithm. As an important benchmark, the method proposed in [15] provides a fast and non-iterative way to learn linguistic rules from data and has been proven with many successful applications [22]. Another successful method is the ‘cooperative rules’ (COR) strategy as reported in [23], which creates a large pool of possible rule-bases using search heuristics.
All these approaches may suffer from the redundancy problem and the ‘curse of dimensionality’. These issues can be addressed by reducing the constructed fuzzy rules through feature selection and instance selection. Empirical studies show that some variables or features are not sufficiently important to be included in the realisation of the fuzzy model during the fuzzy rule base generation process, as some features may be redundant or barely relevant. Thus, the application of feature selection before fuzzy model construction may reduce the fuzzy rule search space and increase the accuracy of the model [24].
Fuzzy rule interpolation approaches can be mainly categorised into two classes. The first class directly interpolates rules whose antecedent variables are identical to those observed, with the first FRI technique (referred to as the KH approach) being a typical example [3]. This method is based on the decomposition and resolution principles [25]. According to these principles, each fuzzy set can be represented by a series of α-cuts (α ∈ [0, 1]). Given a certain α, the α-cut of the consequent fuzzy set is calculated from the α-cuts of the observation and from all the fuzzy sets involved in the rules used for interpolation. Knowing the α-cuts of the consequent fuzzy set for all α ∈ [0, 1], the consequent fuzzy set can be assembled by applying the resolution principle. The closed form fuzzy interpolation is another example of this class [6], which can not only be represented in a closed form but also guarantees that the interpolated results are valid fuzzy sets. The stabilised-KH approach extends the original KH approach, which is based on a certain interpolation of a family of distances between fuzzy sets in the rules and in the observation [26]. Unlike the original KH approach, it does not consider the two closest neighbouring rules. Instead, it takes all the rules and computes the conclusion based on the consequent parts weighted by the distances.
The second class of the FRI approaches is based on shape discernibility and an analogical reasoning mechanism, known as ‘analogy-based fuzzy interpolation’ [27]. Instead of directly inferring conclusions, this class works by first creating an intermediate rule such that its antecedent is as ‘close’ to the given observation as possible, given a fuzzy distance metric or other measures based on certain similarity principles. Then, a conclusion is derived from the given observation by firing the generated intermediate rule through an analogical reasoning mechanism. That is, the shape differentiation between the resultant fuzzy set and the consequence of the intermediate rule is analogous to the shape differentiation between the observation and the antecedent of the generated intermediate rule. A number of ways to create an intermediate rule and then to infer a conclusion from the given observation by that rule have been developed, such as the weighted fuzzy interpolative reasoning [7], and the HS approach based on scale and move transformation [4] and its extensions [28, 29]. The HS approaches not only guarantee the uniqueness, normality, and convexity of the interpolated fuzzy sets, but can also handle the interpolation of multiple antecedent variables with different types of fuzzy membership function. They have been extended from different directions, such as adaptive fuzzy rule interpolation [5, 31], and dynamic fuzzy rule interpolation [32, 33].
Curvature
CurvatureSection There are two types of methods for curvature calculation. The first type is based on the directional derivative with meshes or curve fitting [34], such as the profile curvature, the streamline curvature, and the planform curvature. The second type is based on a moving least-squares (MLS) surface [35], such as the Gaussian curvature, the mean curvature, the maximum principal curvature, and the minimum principal curvature. The maximum and minimum principal curvatures can be derived from the Gaussian curvature and the mean curvature. The first type is relatively simple and is usually used in meshes or curve fitting situations with more regular data, such as 2D images or maps, and 3D digital elevation models. In comparison, the second type is more complex and is usually used in graphical and engineering applications that contain more irregular discrete data, such as feature recognition, segmentation, and rendering [36].
The first type of curvature calculation methods is based on a directional derivative. A directional derivative represents the steepest downward gradient for a given direction. It refers to the rate at which any given scalar field F(x,y), changes as it moves in the direction of some unit vector,
The profile curvature can also be directly calculated using the partial derivatives with the following formula derived from Equation 2.
The second type of curvature calculation methods is based on a MLS surface. It defines a MLS surface S as the stationary set of a projection operator ψ
p
, i.e., S = {(x ∈ R3| ψ
p
(x) = x} . This type of methods explicitly defines the MLS surface as the local minimal of an energy function e(y,a) along the directions given by a vector field n(x). Here, y is a position vector and a is a direction vector. Following this, the MLS surface S can be implied or implemented by determining the vector field n and the energy function e. Suppose a normal vector v
i
is assigned to each point of q
i
∈ R3 of an input-point set Q, then the vector field n is:
It has been proven in
where n :R3 → R3 is the vector field defined in Equation 5 and e : R3 × R3 → R is the energy function defined in Equation 7. Applying the curvature formulas for implicit surfaces given in
Where is the gradient of g(x), and
SparseRuleBaseGeneration Curvature is an important concept in the field of geography, which is conventionally used to investigate the water flow over a landscape. Therefore, the curvature values are only workable with three-dimensional spaces. For this reason, the inference problems with two inputs and one output (referred to as the basic case) is considered first, followed by the general case with multiple inputs (referred to as the general case).
The basic case with two inputs
TheBasicCase By artificially viewing an inference problem (such as classification, diagnosis or prediction) with two inputs and one output as a geometry object, the curvature values as introduced in CurvatureSection can be used to represent the linearity of the object surface. This then reveals the extents to which the geometric object deviates from being ‘flat’ or ‘straight’. Considering that most of the existing FRI approaches are essentially fuzzy extensions of crisp linear interpolation [31], the ‘flat’ or ‘straight’ parts of the geometry object can be easily approximated by its surroundings, and therefore can be omitted. Given a training dataset with two input features and one output feature, the data instances that represent higher curvature values are more important in summarising and generalising the pattern entailed by the dataset. Therefore, they can be used to construct a sparse rule base or to simplify an existing complex rule base. A sparse rule base generation approach based on this motivation for a problem with two inputs and one output is presented below.
Problem domain partition
DomainPartition The partition approaches used in conventional fuzzy rule base generation methods, such as the partitioning and clustering approaches reported in [38], can also be used in this work. Specifically, if the training dataset is sparse, non-grid partition is applied; otherwise, grid partition is used. Given a dataset with two input features (x1, x2) and one output feature (y), denote the universe of discourse of the inputs to be [
Curvature-based region selection
CurvatureBasedRegionSelection Curvature values represent the ‘straightness’ or ‘flatness’ of a surface, which serves as an important description of intrinsic surface characteristics. Therefore, curvature is intuitively employed as the criterion to select the most important regions and hence to generate the most important rules in the implementation of FRI systems. The curvature value of a region is positively proportional to the importance of the region. A predefined curvature threshold leads to a certain number of rules. Reversely, a predefined rule base size implies a certain curvature threshold. The curvature threshold or the number of rules is problem-specific and usually determined through empirical study.
As discussed in DomainPartition, if the dataset is very sparse, a non-grid partition is applied. The curvature of each partitioned space representing a data instance can be directly calculated using the MLS-based curvature calculation approach as introduced in CurvatureSection. Important data instances can then be selected using either a rule size threshold or curvature value threshold, and the selected important data instances can be directly used for rule base initialisation as introduced in the next subsection.
If a given dataset is dense, grid-partition is used. In order to balance cost and performance, a hierarchical partition and region selection approach is proposed herein to support the rule base generation. The approach is implemented in a recursive manner, and the pseudo-code of the approach is shown in Algorithm 1 hierarchical_partition. In this algorithm, if the curvature value of a region is greater than the activating threshold θ and is less than the ceiling threshold θ * (1 + p), this region will be selected to generate a rule. If the curvature value of the region is less than the threshold θ, the region will be discarded. However, if the curvature value of the region is very large (i.e., larger than θ * (1 + p)), the region cannot accurately be represented by one rule. In this case, this region is further partitioned with the activating threshold θ being updated as θ * (1 + p). Following this, the procedure is recursively applied to each of the further partitioned regions until no region needs to be further partitioned. Note that the curvature threshold is used in this algorithm; the rule size threshold can be applied in a similar and straightforward way, which is thus omitted here.
Rule base initialisation
Each selected region is expressed as a fuzzy rule. If the region is led by the non-grid approach, the corresponding data instance is used to represent the region. Denote the fuzzified value of the representative of each region as (A1, A2, B); the generated corresponding rule for the region can be expressed as:
If the dataset is dense (and accordingly grid-partition is employed), each region usually covers multiple data instances, and a representative data point is required to represent the region for fuzzy rule generation. This is implemented by firstly aggregating all the data instances into one artificially made data instance, and then such an artificially made data instance is fuzzified using the same approach as discussed above.
A number of ways are available in the implementation of the aggregation operator, such as arithmetic averaging and weighted arithmetic averaging (WAA). The most commonly used approach is WAA, which is also applied in this work. This approach first weights all the given arguments, and then aggregates all these weighted arguments into a collective one. For simplicity, as the curvature values of the data instances already imply their importance, the curvature values are intuitively employed as a means to rank their weights in the WAA method. Suppose a given region is formed by n data instances, the artificially made data instance representing the selected region can be calculated as follows:
TheGeneraralCase
The majority of real-world applications consists of more than two inputs. Thus, the approach proposed in the last section needs to be extended. Given that traditional curvature values only work with three-dimensional data, the most challenging part to evaluate the importance of a high-dimensional instance is that there is no exiting approach to be directly applied for calculating the ‘curvature’ value of a high-dimensional instance. However, a higher-dimensional complex problem can be regarded as a collection of three dimensional problems with two inputs and one output (i.e., multiple basic cases). With the curvature-based approach discussed in TheBasicCase, any high-dimensional problems can thus be addressed by applying the basic case solutions multiple times.
Problem domain partition
ProblemDomainPartion3 Suppose that a complex problem Pn+1 (n > 2) contains n input features
If the dataset is dense, grid partition is applied. In this situation, the input domain is evenly partitioned into m1 * m2 * . . . * m n hypercubes, where m i , 1 ≤ i ≤ n, represents the number of partitions in the variable domain of x i . The values of m i are usually empirically determined by experts or statistically calculated by clustering methods such as k-means. Traditional fuzzy partition methods represent each hypercube as a fuzzy rule. Hence, any given complex problem Pn+1 will lead to a rule base with m1 * m2 * . . . * m n fuzzy rules [40].
For simplicity, let h be the number of data instances if the given dataset is sparse, and h = m1 * m2 * . . . * m
n
if the given dataset is dense. Accordingly, the generated hypercubes can be collectively represented as
Representing hypercube in cubes
The traditional curvature value is only applicable in a geometric space with three dimensions. Hence, there is no equation to directly calculate a ‘curvature’ value for a high-dimensional instance, and thus to directly use the value for representing its importance. However, based on the curvature values of its decomposed cubes, the importance of a high dimensional hypercube can still, to some extent, be identified. In order to distinguish important hypercubes, every high-dimensional hypercube H
i
, 1 ≤ i ≤ h, is broken down into
The importance of a hypercube can be collectively determined by its decomposed cubes. That is, the importance of hypercube H
i
can be determined by the curvature values of Ci1, Ci2, ⋯ , C
ic
. The curvature value v
ij
of each artificially created cube C
ij
can be calculated using the approach detailed in CurvatureSection. Collectively denoting the values of all cubes as V, the calculated results of all cubes can then be represented as follows:
The importance of each hypercube can be represented by the summation of the curvature values of its decomposed cubes. In particular, given a set of hypercubes
If the parameter m is given instead of using θ, the hypercube selection process is summarised in Algorithm 3 hypercubeselection. The most significant m instances or hypercubes can be selected simply by taking the first m hypercubes with the highest accumulated curvature values after ranking them in descending order, as expressed in Line 8. The accumulated curvature value regarding a hyper cube H i , represented as H i . weight, can be calculated as the summation of all its related decomposed cubes (as expressed in Line 5).
Feature discrimination
In addition to the fact that some hypercubes are more important than the others, some dimensions in a selected hypercube may also be more significant than the others. Therefore, selective dimensionally reduced hypercubes can be used to generate a more compact rule base with fewer rule antecedents. This is summarised in Algorithm 3 featurediscrimination. It takes the output of HypercubeSelection () as its input, in addition to the number of selected features b and the training data T. The output of the algorithm is a subset of input features
The algorithm artificially generates c set of two-input and one-output fuzzy rule bases to evaluate the importance of the pair of associated features. Recall that since C1j, C2j, ⋯ C
hj
share the same input features in Equation CurvatureRankingofCubes, they jointly form the jth artificial rule base. Every pair of input features is then evaluated by its corresponding rule bases by applying the training dataset to perform FRI with the rule bases. From this, all the artificial rule bases, representing every pair of features, can be ranked. A weight function is designed to convert the ranking to a weight for the pair of features. Note that each input feature appears in
Rule base initialisation
Similar to the basic case, each hypercube with selected features is expressed as a fuzzy rule. Denote the fuzzified values of a data instance or a hypercube with b selected input features and the output feature as (Ak1, Ak2,. . . A
kb
, B
k
); the corresponding fuzzy rule can be expressed as:
Note that the above rule base is a Mamdani-style rule base, as the consequence of each rule is a fuzzy set [41]. However, depending on the real-world application, a TSK-style rule base may also readily be generated using the existing TSK rule base generation approaches [42]. Note that the resultant rule base has only b antecedents, which is a subset of the input features. In an extreme situation, the resultant rule base may only have two input features, which backtracks to the basic case as discussed in TheBasicCase.
Optimisation The initialised rule base can be improved by fine-tuning the involved fuzzy sets, given that the initialised fuzzy sets are specified based on empirical knowledge. This can be implemented using any general optimisation approaches; the genetic algorithm (GA) is particularly employed in this work due to its effectiveness in rule base optimisation [43]. Specifically, a chromosome is designed to represent all the fuzzy sets in the initialised rule base. Given the fixed representative value and isosceles shape of a fuzzy set A, its membership function can be readily constructed from the support of A (denoted as S (A)). Then, each rule with b antecedents and one consequent can be represented by b + 1 parameters: S (Ai1), S (Ai2),…, S (A ib ), and S (B i ). Thus, a chromosome representing all the rules in the rule base has (b + 1) * m genes, where m represents the number of rules in the rule base.
Following this, the initial population can then be generated by creating a number of individuals, i.e.,
Experimentation
The initialised rule base for Experiment 1
The initialised rule base for Experiment 1
The optimised rule base for Experiment 1
The problem presented in [17] is reconsidered here for a comparative study, which models the non-linear function as defined as:
In order to reveal such a mathematical model, the approach first uniformly partitions the problem space into 20 × 20 grid areas, resulting in 400 sub-regions, as illustrated in Fig.1. The input domain of the variable x is divided into 20 equal intervals, with each represented as a fuzzy set. This is also the case for the variable y. Then the degree of flatness or sharpness of each sub-region can be represented by its curvature value. The curvature values of all sub-regions are calculated using the profile curvature from the directional derivative method. For example, regarding the first sub-region (where x is around -9.5 and y is around -9.5), the curvature value is 0.099. This value is relatively high, which means that the sub-region is relatively sharp and cannot be easily approximated by neighbouring sub-regions. This selected sub-region is represented as a fuzzy rule for initialising the rule base, which is optimised using the GA.
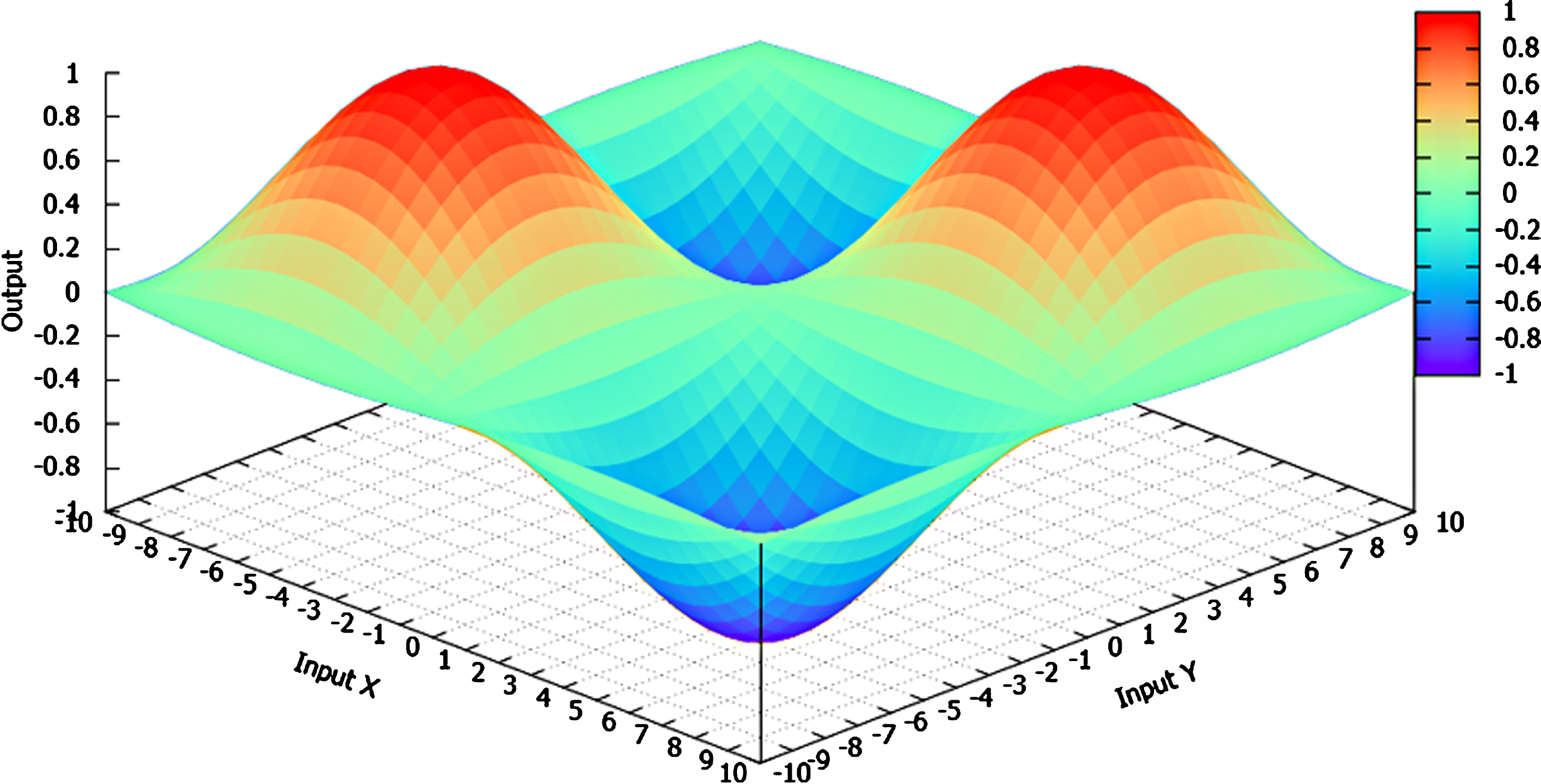
Problem space partition for the illustrative example.
By employing the traditional similarity-based method in [17], if the number of rules is smaller than 23, the sum error of the testing instances is too high to be discussed. However, the proposed curvature-based method can still generate acceptable results, with the optimised sparse rule base using 23 or less rules, as listed in Table 1. This initialised rule base was optimised using GA. In this experiment, the population size was set to 100, the maximum number of generations was set to 1,000, and the probabilities of crossover and mutation were set to 0.8 and 0.01, respectively. The optimised rule base with 23 rules is summarised in Table 2.
To enable a comparative study, the summed errors from 36 random testing data points produced by different approaches based on various sizes of rule bases are illustrated in Fig.2. The black line represents the results generated by the nearest neighbour interpolation approach and the blue line represents the results produced by the piecewise polynomial cubic spline interpolation approach as reported in [17], whilst the red line represents the results generated by the proposed curvature-based sparse rule base generation approach.
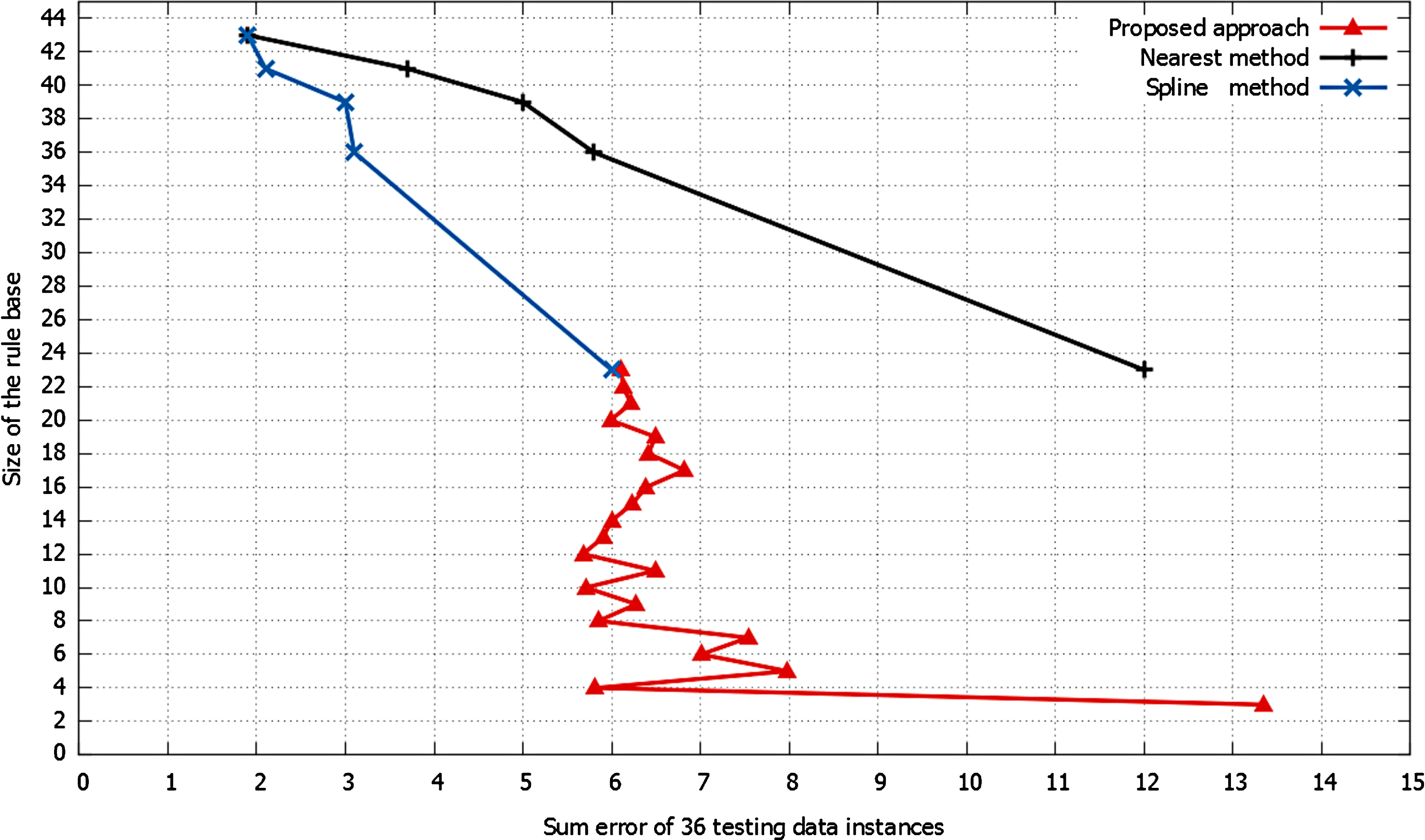
Sum error led by rule bases with different sizes.
Curvature values of the decomposed cubes from the first instance
The indexes of selected important instances
Experimentation results for comparison in Experiment 2 (two to seven features used by the proposed approach and seven features used by other compared approaches)
From Fig.2 ErrorsWithDifferentRules, it is clear that rule bases with fewer rules generally lead to larger summed error and poorer system performance, whilst rule bases with more rules generally result in smaller summed error and better performance. However, it should be noted that this is not always the case. For instance, the sum error produced by the rule base with 12 rules is smaller than that produced by the rule base with 17 rules. In fact, as shown in the figure, the rule bases with 12, 10, 8, and 4 rules in this experiment have demonstrated better performance. This is partly because these selected rules more efficiently represent the intrinsic characteristics of the data.
Detecting users in an indoor environment based on the strength of Wi-Fi signals has a wide application domain. Deployable models have been developed in monitoring and tracking users based on the Wi-Fi signal strength of their personal devices. The applications of such models include locating users in smart-home systems, locating criminals in bounded regions, and obtaining the number of users on an access point. An indoor environment localisation dataset was employed in this experiment to validate and evaluate the proposed approach [44]. The dataset was collected in an indoor space by observing the signal strengths of seven Wi-Fi signals visible on a smart-phone. The dataset includes 2,000 instances, each with seven inputs and one output. Each input attribute is a Wi-Fi signal strength observed on the smart-phone, whilst the output decision class is one of the four locations.
In comparison to the synthetic dataset (where the required data can be obtained from anywhere in the space, thus resulting in a very dense dataset), the collected small dataset is irregular and sparse. In this case, due to the sparseness of the dataset, each data instance in the dataset is regarded as a high-dimensional hypercube and represented as a fuzzy rule if it is selected. In order to distinguish the data instances and to select the important instances, all high-dimensional hypercubes are broken down into
Note that in the rule base generation process for classification problems, each output class should be covered in order to avoid misclassification. Therefore, when selecting instances or hypercubes, the candidates should be considered in tandem with the local higher curvature values, instead of the global higher ones. Otherwise, the candidates with higher curvature values may just belong to one or two output classes in this particular experiment. This dataset has 500 instances in each output class, with a total of 2,000 instances in all four output classes. Thus, in each class, m important instances are chosen to guarantee that all the output classes are covered. In other situations that involve an uneven distribution, the number of selected instances in each class can be adjusted accordingly. Based on their accumulated curvature values, for each output class, the most significant m instances or hypercubes within the output class were selected, simply by taking the first m hypercubes with the highest accumulated curvature values. Finally, the most important 4 * m hypercubes or instances were selected to jointly initialise the rule base.
Empirical study shows that, in this example, m = 7 produces the best performance. The result shows that although there are 2,000 instances, only 4 * 7 =28 important instances were needed to construct a sparse rule base, as summarised in Table 4. The initial rule base was optimised by applying the GA over the training dataset in fine-tuning the membership functions of the fuzzy sets which are involved in the 28 rules. The results produced by the proposed method using two to seven features and other approaches using seven features were compared, as shown in Table 4. The classification accuracy of the proposed method is 99.25%, which outperforms all the existing methods. Furthermore, using the FRI performance of the constructed intermediate rule bases, important features can also be identified; these appear in descending order as [5, 2]. If all the seven input features are used, the accuracy is 99.25%. Instead, if only the most important two to six input features are used, the accuracy still remains good as 96.75%, 98.15%, 98.6%, 98.8%, and 99.15%, respectively. This clearly demonstrates the superior advantage of the proposed approach.
Conclusion
Conclusion This paper proposes a curvature-based sparse rule base generation method to support fuzzy rule interpolation. The approach first either partitions the problem domain into a number of hypercubes for problems with dense datasets, or represents each data point as a hypercube if only a small dataset is available. From this, the hypercubes are discriminated by effectively utilising the curvature values, and each important hypercube is represented as a fuzzy rule. The proposed method has led to very comparative results in the experiments, which demonstrates its potential for a wider range of real-world applications. One possible future direction of improvement is to mathematically extend the traditional curvature value calculation in a more effective way for higher dimensional problems, given that the current approach is combinational and thus requires high computational power. In addition, the approach needs to be further evaluated by large-scale real-world applications.