
Abstract
Image segmentation, which becomes more and more prevalent in computer vision, plays a requisite part in the fields of object detection, tracking and even virtual or augmented reality. Early segmentation methods that relied on hand-crafted features have fast been superseded by deep learning algorithms. Nonetheless, deep learning algorithms are hardly applied in real object segmentation because of a lack of ground truth labels. This work introduces the use of 3D models to generate segmentation training dataset. This system projects 3D models to the 2D plane and merges 2D images with different backgrounds to obtain training images. In this process, the ground truth labels would be allowed to obtain automatically without manual annotation, since the position of objects is known in the picture. Experimental results indicate that synthetic images can be used to train on existed networks such as FCNs and DeepLab and trained models achieve relatively accurate segmentation results on real images. Moreover, the modified model based on DeepLab-CRF-LargeFOV achieves more precise segmentation results by strengthening its localization and edge performance.
Introduction
Segmentation techniques could facilitate a large number of applications such as object detection, auto driving, and scene understanding. In the past few decades, traditional approaches such as Active Contour Models [26], Watersheds [23], GrabCut [6] have achieved substantial improvements on segmentation tasks. Recently, Convolutional Neural Networks(CNNs) [37] has surpassed traditional segmentation approaches in terms of accuracy on segmentation tasks, and they are trained more easily in comparison with traditional methods that relied on hand-crafted features. However, deep learning approaches require lots of annotation images and their performance has a close relationship with the amount of training images. All benchmarks such as PASCAL VOC [25], SDB [4], Microsoft COCO [35], Cityscapes [24] require community to annotate based on handwork which is both a waste of time and costly. The problem of data unavailability will become more serious when some specific objects are segmented since training images are hard to collect. There are several approaches in reducing dependency on pixel-level image labeling. The main methods deploy semi-supervised models, which learns segmentation model from existing manual annotations such as bounding boxes or image tags [9]. D lin et al. [10] exploited scribbles, one on each object to learn segmentation models. [1] needed a point on the specific object and then trained to obtain segmentation results. While these semi-supervised approches are not as good as fully supervised methods and even not competitive with traditional segmentation methods yet. Other works have several attempts at taking advantage of easier-to-obtain image bounding boxes to populate objects with the same dye. According to [19], given a ground-truth bounding box, this method uses polygon-RNN to outline the edge of the object through some clicks on this object and further gets the instance segmentation. [6] utilized existing bounding boxes to obtain labels with an iterative GrabCut method. Though segmentation results have improved a lot, they cannot be used as ground-truth because of low accuracy. In this paper, one goal is to obtain the training data and labeling images faster and more accuracy. Another goal is to provide a method to segment object automatically and precisely.
Our method can synthetize images and obtain ground-truth automatically without manual annotations. 3D models are used to complete this task. It is not the first time that researcheres have generated synthetic training data from 3D models. [12] synthetized training data with 3D models to recognize human actions. In [14], authors proposed a pipeline that synthesized RGB-D data of indoor scenes to train their models. But in human eyes, this is the first time to synthetize segmentation data using 3D models. This system firstly scans the object or takes photos in different viewpoint with the object and exploits three dimensional reconstruction technology to acquire a 3D model, and then projects the 3D model with different angels and scales to 2D images with diverse backgrounds to obtain synthetic training data. During this process, the location of the projection in this picture is easily to be acquired, which means the ground-truth labels would be acquired automatically. Though these synthetic images are not realistic enough, the segmentation model trained on these synthetic pictures has strong generalization ability on real images. Synthetic images are fed into existed segmentation network FCN-8s [13] and DeepLab-CRF-LargeFOV [20] and trained models finally obtain relatively accurate segmentation result on real images, which proves that it is credible to train segmentation networks using synthetic dataset. In order to learn more details of the images, a improved network is proposed by us and it reaches 81.7% mIOU on test set(real image), which exceeds the results of DeepLab-CRF-LargeFOV.
Our main contributions are as follows:
(1) A new method is proposed by using 3D models to synthetize segmentation training dataset.
(2) A improved network is proposed that combines existing Fully Convolutional Networks(FCNs), dilated convolution and Conditional Random Filed(CRF) and achieves automatic object segmentation with a remarkable degree of accuracy in real scenes.
Related work
In the past few decades, segmentation systems mainly relied on hand-crafted features such as Random Forests [16], Boosting [15], or Support Vector Machines [3]. These systems have achieved substantial improvements but the segmentation result has always limited by expressive power of the features. In recent years, with the development of the computing ability of GPUs, CNNs have made breakthroughs in image classification, object detection, and segmentation. Currently, the Fully Convolutional Networks(FCNs) proposed by Long et al. [13] is the most successful deep learning techniques for segmentation tasks and many modified networks are stemed from it. Since this object segmentation task can be resolved by deep learning methods, a central questions is how to obtain large annotated image datasets. Some approaches such as using annotation tools, semi-automatic annotation methods and synthetic data methods are proposed to solve the problem of data deficiency.
Generating synthetic training data
A pipeline(See Fig. 1) for synthesizing training datasets is proposed. For a specific object, 3D reconstruction techniques are applied to acquire a 3D model and then a 3D model is projected to the image plane. As proposed by [34], an image can be synthesized by foreground and background. Our method is able to synthesize a image by merging foreground which is provided by rendered datasets with suitable background. Moreover, in order to promote the degree of realism of synthetic images, shading is drawn to synthetic images. For more details, each step is given as below and some synthetic images are shown in Fig. 2.
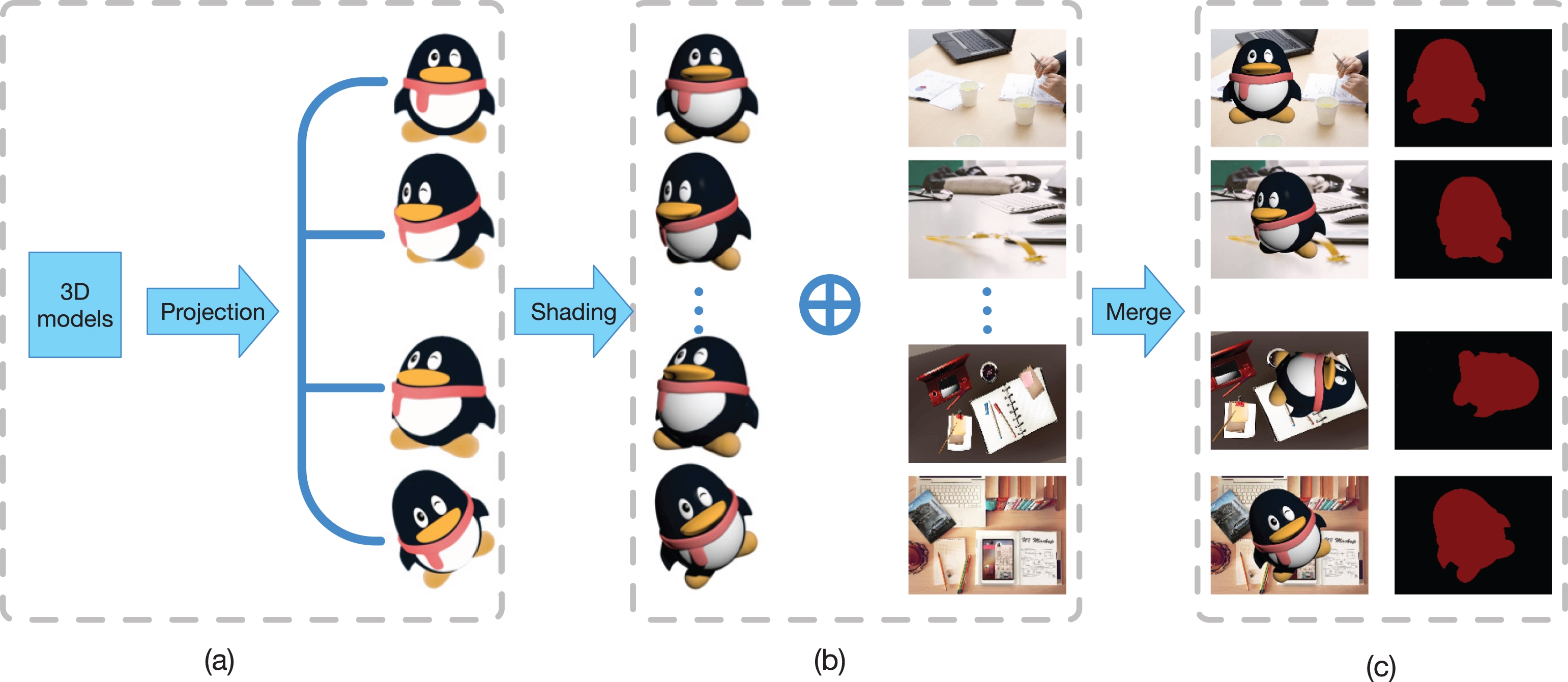
A proposed pipeline for synthesizing segmentation train images and ground truth. (a) For a given object, this system firstly use 3D reconstruction to acquire a 3D model. (b) Then, projecting the 3D model to 2D plane to obtain images and merge 2D images with various backgrounds. (c) Synthetic images and ground-truth can be acquired automatically.

Examples images of synthetic images and ground truth generated by our method.
Given an object, a 3D model would be acquired through reconstructing and further it is projected to 2D plane to synthetize training images. A camera is firstly used to collect some images of this object, and then software such as VisualSFM [7] or laser scanner will be used to acquire dense point clouds. Next, using MeshLab [28] to put point clouds into a surface and recover colors, texture and finally acquires a 3D model. Furthermore, with the intention of obtaining a realistic model, softwares such as Blender, 3DsMax and Maya are exploited to render the reconstruction model.
In order to learn general features of a object, various 3D models about a object are essential. That is means, we provide strategies for improving generalization ability of the network using mutiple different shapes, textures, and colors of 3D models about objects.
Rendering the geometries
After the above step, 3D model is achieved, which contains 3D point clouds, texture, color and other detailed information of the object. In order to convert the 3D model to image plane, which means a point in space of 3D model (P
x
, P
y
, P
z
) projects to a 2D image and gets the point (x
i
, x
j
), the conversion formula of the world coordinate system to the image coordinate system is essential. Additionally, the model of translation and rotaion can increase the diversity of images that can enhance the generalization ability of neural networks. The conversion expression was introduced, which projects 3D model onto image plane, as
In this section, existing technology is utilized to improve the quality of generated images as close to real images as possible. Instead of displaying the object appeared in reality, Our method promotes the degree of realism of the synthetic images.
Shading is drawn to synthetic images, according to [5]. As the 3D model has no shadow, but in real images one object always contains the brightness area and dark region, so the shading is modeled by us. The shading function model can display as
Furthermore, due to prominent edge around the object when objects are merged into the background, which means the edge of the objects is too obvious in synthetic images, Laplacian Pyramid Blending [29] is employed to solve this problem. Before fusing the object and background, our method builds Laplacian pyramids for the object, background and the projected region, and form a combined pyramid using Eq. (2), eventually collapse and fuse these pyramids to obtain the final blend images. The final blend expression is shown
This section talk about our network which is used to train on our synthetic images. This proposed network is based on VGG-16 [17], which won ILSVRC 2014 competition with GoogLeNet [8]. The Fully Convolutional Networks(FCNs) [13] are employed to solve the segmentation problem and the convolution operations have already been placed by atrous convolution. Our model derives from DeepLab-CRF-LarFOV which is stems from FCNs but further efforts are made to improve the segmentation results by adding Conditional Random Field layer to the end of network rather than a post-processing stage and sets greater dilated rates. More details are shown in Fig. 3.
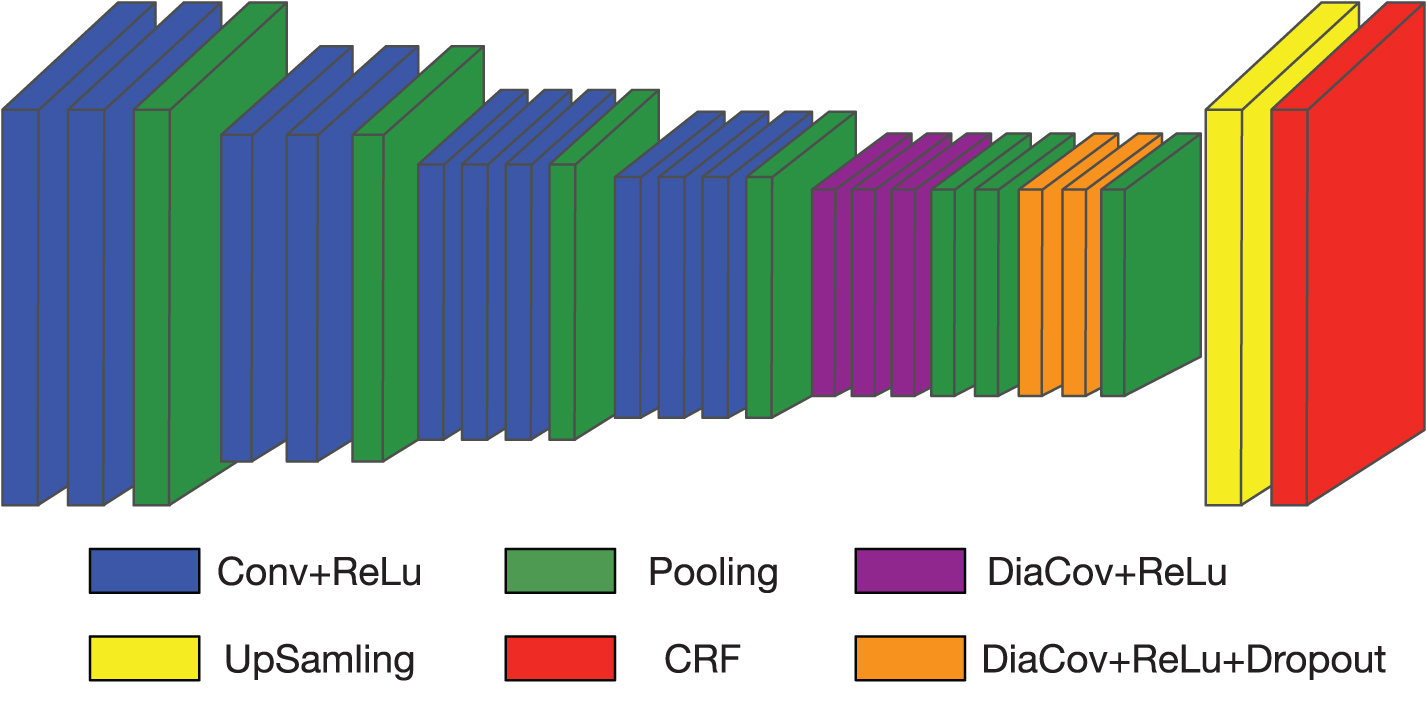
An illustration of our pixel-wise prediction network architecture. The last few convolution layers and fully connected layers are placed by dilated convolution layer. Subsequently, an efficient up-sampling filtering acts on the feature map and followed by a dense CRF layer to obtain dense prediction results.
Long el al. [13] proposed the most successful method for pixel-level segmentation tasks, Fully Convolution Networks(FCNs), which is the forerunner in CNNs, whereafter, many efforts based on this system have been made to improve its accuracy. The biggest contribution of this system is that it replaces convolutional layer with fully connected layer of traditional classification networks and trains end-to-end to solve segmentation tasks.
However, there are some challenges in FCNs. The biggest issue is reduced features caused by applying multiple pooling operations to down-sampling the images. In order to get an output image which is the same size with the input picture rather than a probability value in classification networks for a picture, FCNs exploit deconvolution layer to up-sampling the last convolution layer’s feature map. Thus, some detailed information has dropped during down-sampling and up-sampling stage and segmentation results are rough in FCNs.
To further improve the segmentation accuracy and capture long-range information, atrous convolution and Conditional Random Field (CRF) are integrated into our network.
One challenge for segmentation using CNNs is the problem of reducing spatial resolution of feature maps, causing the dense prediction results is coarse. Due to the limitation of classification nets such as VGG-16 net, it frequently uses pooling and in all a stride of 32 in 5 pooling layers and results in this problem. The representative solutions deploy deconvolution layers such as in [13] or decoder variants in [36], however, these methods require additional memory and higher computational power.
Recently, annother effective approach is to employ atrous convolution, also named dilated convolution, which originates from kronecker layer [33] proposed by S.zhou el al. Deeplab [20–22] successfully deploy dilated convolution to do dense prediction problems and achieves the-state-of-art. Using atrous convolution can not only obtain wider receptive fields without extra computation cost and excessive reduction in feature responses but also adjust to arbitrary resolution at any layer of CNNs. For two-dimensioanl features, the output of dilated convolutions y can be expressed by a weight w [k] and input value x [i] using equation:
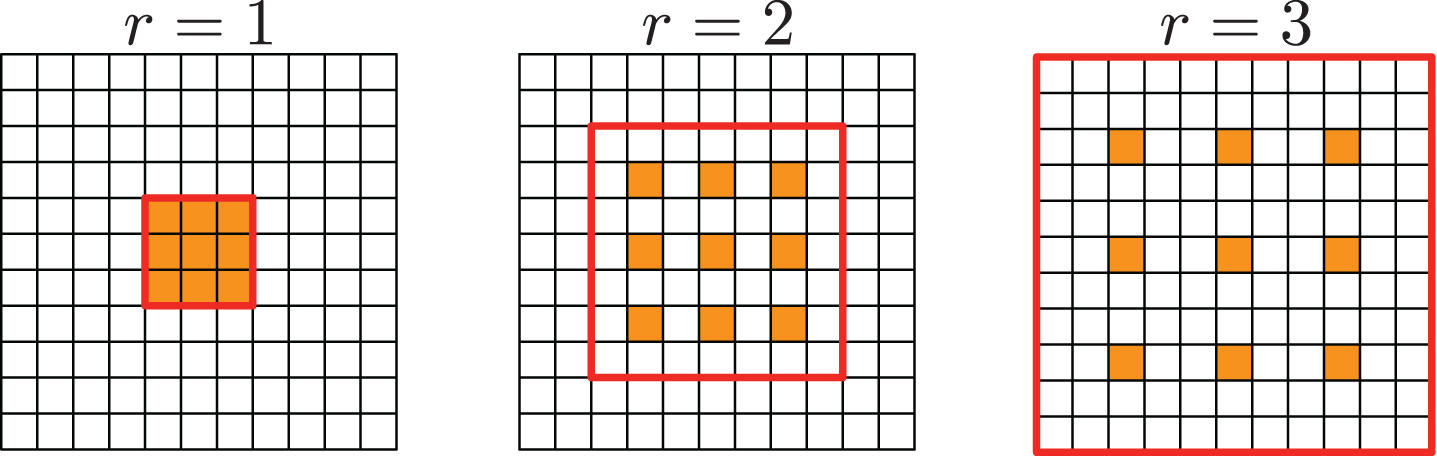
3 × 3 filters(orange) while using multiple different dilated rates, from left to right r = 1, 2, 3. The red rectangel regions are corresponding to the receptive fields, the left ones with 3 × 3 recptive fileds, the middle has a 7 × 7 recptive fileds, and the right one with 11 × 11 receptive fileds.
Additionally, the structure of CNNs is inherent invariant, which means the size of output responses in CNNs is fixed, causing limits the accuracy for dense pixel prediction tasks. One approach to improve the ability of recovering the details of segmentation results especially localizing segment boundaries is to employ a Conditional Random Field(CRF) proposed by P. Krhenbhl et al. [30]. CRF enables combination of adjacent pixels and edges or superpixels to compute class scores and captures long-range information, while CNNs failed to harness this problem and fine edge details.
One successful example that makes use of fully connnected pairwise CRF is DeepLab system [20, 21]. This model views every pixel as a CRF node and directly optimizes a energy function based on each pair of pixels. The energy function is given by:
In this section, common setting is presented for all the experiment and experimental steps and the parameters are elaborated. Synthetic images are used as training set and real images of this object are viewed as test set. Existed network architectures, including FCN-8s, DeepLab-CRF-LargeFOV are firstly used to demonstrate the effectiveness of this synthetic datasets. The experimental results demonstrate that our synthetic images can be used to train and obtain roughly accurate segmentation results in real scenes. Furthermore, To obtain finer segmentation results on real images, a improved network based on DeepLab-CRF-LargeFOV is proposed by us.
Improvement over DeepLab
Our network is based on DeepLab-CRF-LargeFOV. An additional dilated convolution layer is added since we modified network architecture to a larger dilated rate. Compared to origin model, our dilated rate is greater. Because we hopothesize segmentation is aimed at objects which general with greater size in a image. The last few convolution layer is placed by dilated convolution layer and last two fully connected layers are also replaced by dilated convolution. Dilated rate is set to {2,2,2,16,2} separately in 5 dilated convolution layer whose architecture is shown in Fig. 3. Similar to [20], the VGG 16-layer network is modified to a smaller receptive field(128 pixels) and in convolutional layer stride is set to 8 to get intricate segementation results. At the same time, initial weights of VGG16 pretrained on imagenet are avaliable due to ’atrous convolution’ allow us accept any size of receptive filed. In this model, there is another change is that max pooling size is changed in the first 4 layers from 2 to 3 and the filter size from 4096 to 1024 in the layers of fc6 and fc7, leading to fewer parameters and lighter weight trained model(about only 79M instead of 140M). Our model obtains finer results compared to DeepLab-CRF-LargeFOV(see Fig. 6). Additionally, images are cropped at input layer and learning policy is changedto "inv".
Results
In order to verify the validity of synthetic data, different number of synthetic training images are fed into FCN-8s and DeepLab-CRF-LargFOV networks and test on real images. It was not until the loss value is convergence and stable that iterative training stopped. Fig. 5 shows that with the increase of training images, segmentation results on test set are better and better. That indicates our synthetic images are able to used for training. When the number of training images for per object reaches 2000, the performance on test set almost reaches the top. A smooth curve is observed when training images start from 2000 to 5000.
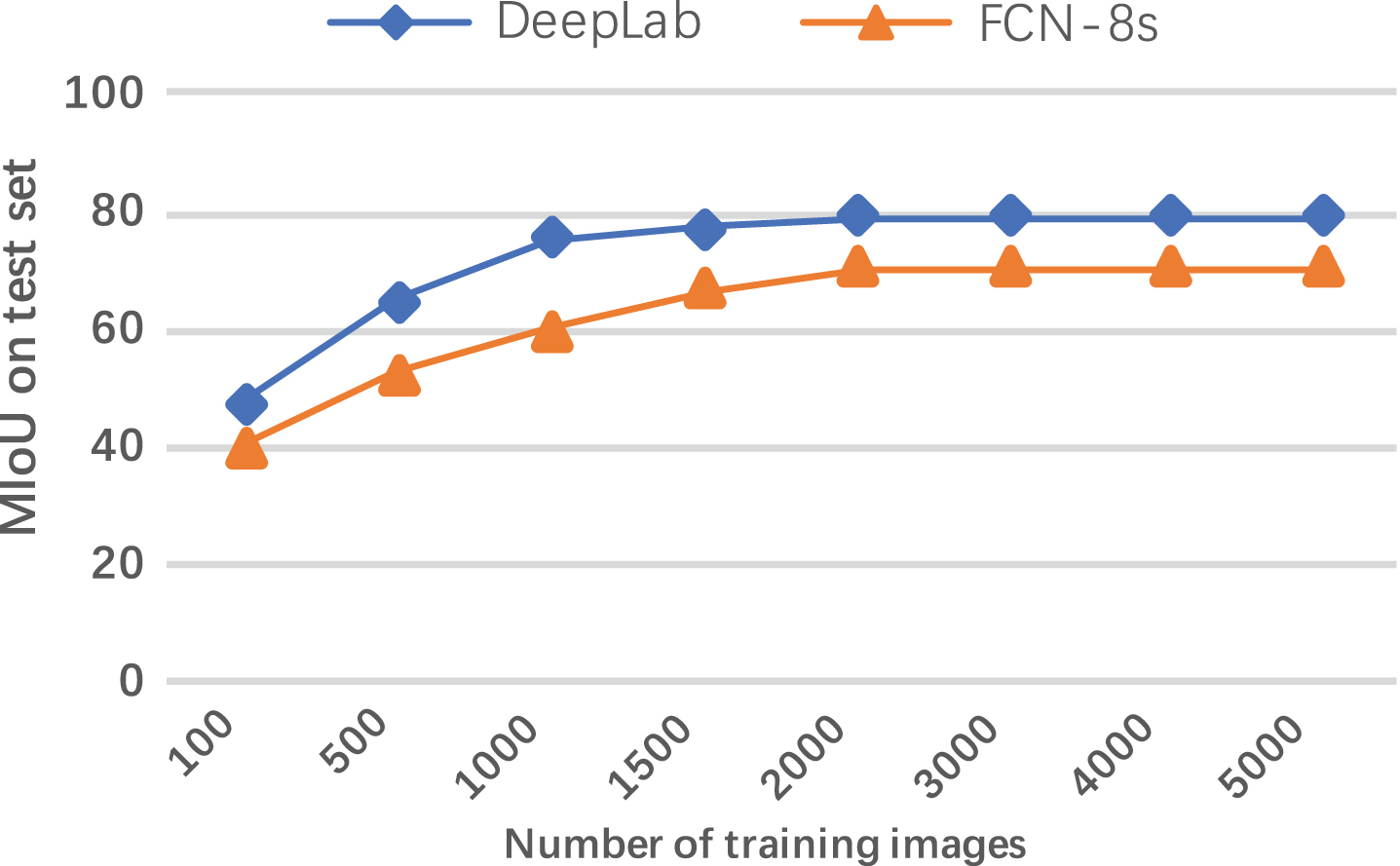
Performance on test set when providing different numbers of training images.
Since the performance almost reaches the top when the number of training images reaches 2000, the same number of synthetic images of each object are randomly choosen for training. Segmentation results on real images are shown in Fig. 7 (Compared with FCNs, Deeplab and Ours). Experiemtal results indicate that our models has strong generalization ability on test dataset. The modified network obtain finer segementation results compared to DeepLab (See Fig. 6). In the end, the improved model achieves the performance of 81.7% on test set which outperforms deeplab-CRF-LargeFOV about 2.5%, as shown in Table 1.
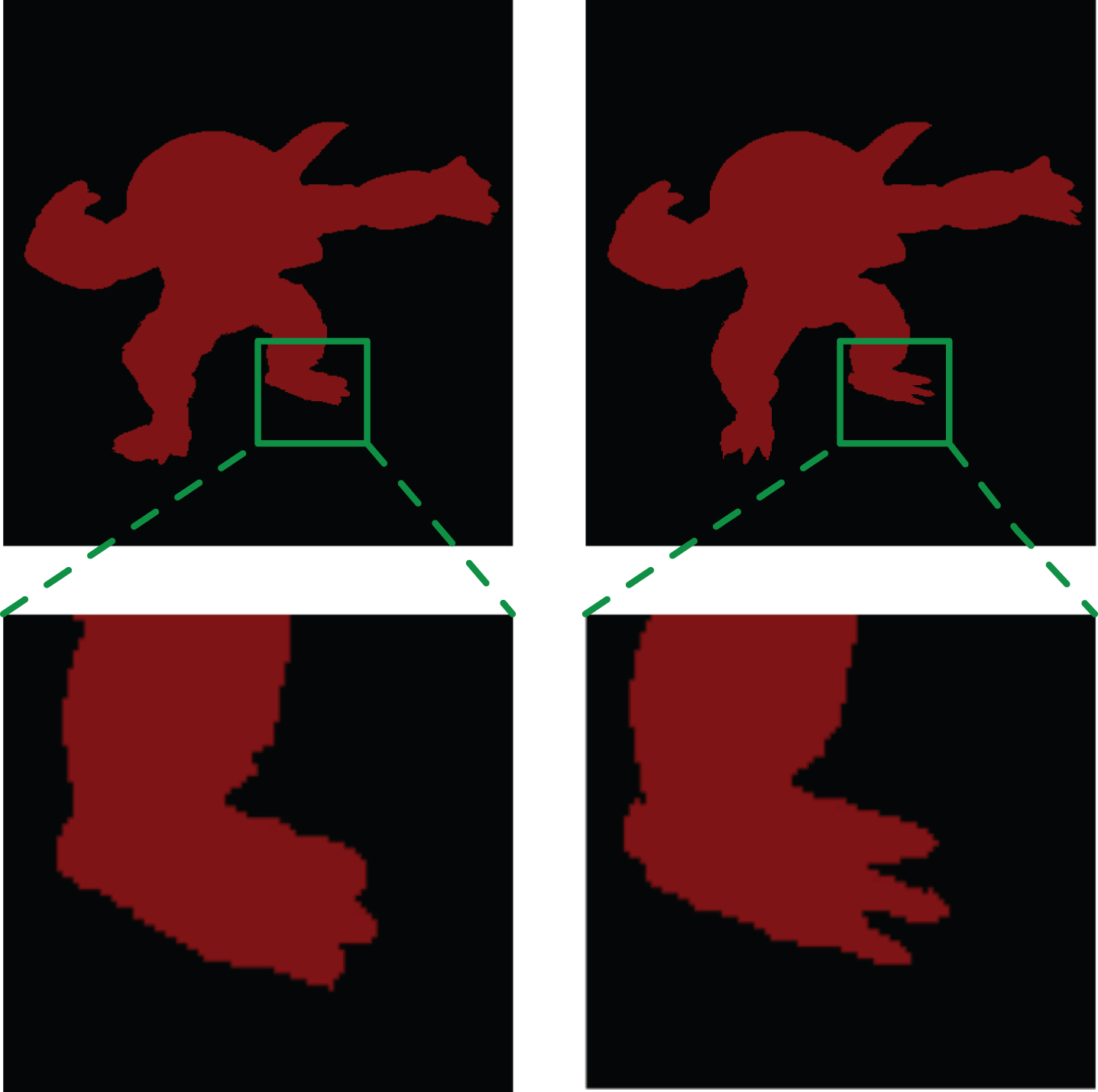
An example image of DeepLab-CRF-LargeFOV segmentation result(left) and ours(right).

Visualization results on test set(real images). Input images, ground-truth, FCN-8s results, Deeplab-CRF-LargeFOV results and ours.
Experimental results indicate that our system can generate images and obtain ground-truth images automatically by 3D models. Training improved networks with synthetic images by this approach, a relatively accurate segmentation result would be obtained on real images. Meanwhile, the future work is to improve the reality of synthetic images and further improve the segmentation result using fully convolutional networks. Additionally, reducing the consume memory and improve the efficiency of computation are our goals.
Footnotes
Acknowledgments
This work is supported by the National Natural Science Foundation of China (No. 61502060), National Natural Science Foundation of China (No. 61701051) and Research project of graduate students in Chongqing (No. CYS188).