
Abstract
The theory of rough sets is an efficient mathematical tool for dealing and reasoning with uncertainty information systems. The measures of traditional rough sets are applicable to discrete-valued information systems, but not suitable to real-valued data sets. In this paper, by introducing a distance matrix to granulate these real-valued data, a granulated fuzzy rough set model is proposed, which combines fuzziness and roughness into a rough set theoretical framework. By constructing a fuzzy similar relation with a distance matrix form, real-valued data sets can be deal with. We also define some operations on the fuzzy relations and fuzzy granules. Furthermore, two kinds of measures of fuzzy granules are proposed, which are information entropy measure and information granularity measure. These measures are calculated by a novel representation with a fuzzy granule matrix. As a result, uniform representations of fuzzy rough sets and their information measures are formed in this work.
Keywords
Introduction
The theory of rough sets [46] proposed by Pawlak in 1982 is a valid mathematical tool for dealing with the imprecise, uncertain and tremendous data in information systems. The basic idea of rough sets uses two approximate sets to describe a vague object set. The two approximate sets, named upper and lower approximation, contain some knowledge granules induced by equivalence relations with respect to some attributes. The theory of rough sets has been widely used in many fields, such as feature selection [27], gene selection [29], attribute reduction [5], big data mining [23], approximate reasoning [17], granular computing [33], image segmentation [26] and classification [43].
In order to tackle the widely existences of vague data, many uncertainty measures are proposed in rough sets. Pawlak [47] presented accuracy and roughness for evaluating a rough set in an information system, and also introduced approximation accuracy and approximation roughness for measuring a rough classification in a decision system. The Pawlak’s uncertainty measures are not meticulous, since there is a case that the two different equivalence class sets probably have the same accuracy or roughness. Therefore, many researchers have proposed other measures to overcome the deficiency from different perspectives, including information quality [25], information entropy [11], rough set entropy, approximate quality [20], knowledge granularity [12], etc. Since these measures target to evaluate equivalence relations and equivalence classes, other authors have presented uncertainty measures and applications for neighborhood rough set models [18, 31, 42, 44], probabilistic rough set models [10, 35], covering rough set models [9, 39], cost-sensitive rough set models [15] and fuzzy rough set models [21, 28, 32].
The theory of Pawlak rough sets is mainly applicable to the information systems with discrete data. As for widely existing continuous data, a discretization should be implemented. However, this preprocessing will result in the loss of information, reducing the classification accuracy. The rough set model is extended to a fuzzy set domain by replacing the equivalence relation with fuzzy equivalence relation. The usefulness of fuzzy rough set model is evident from its applications in feature selection [1, 7, 40], gene selection [30], attribute reduction [8, 13, 37], hybrid data reduction [34], mining stock price [3, 41], rule extraction [2, 16], decision trees [22, 36], cancer classification [38] and image classification [4]. Fuzzy equivalence relation satisfying reflexivity, symmetry and transitivity, is similar to general equivalence relation. In practise, there is a more general and extensive relation only fulfilled with reflexivity and symmetry. It is called as a similarity relation. Actually, distances between objects can describe their similarity. In this paper, we proposed a novel fuzzy similarity relation based on the granulation by a distance matrix. Fuzzy similarity relation categorizes objects in the classes with fuzzy boundaries depended on their similarity according to their distances. The fuzzy similar classes can be seen as fuzzy similar granules that are close to the human decision process. Furthermore, a distance-based fuzzy rough set model is proposed by building upper and lower approximations with fuzzy similar granules. We also tend to granulate data for simplification and memorization of information in our cognition. Since the similarity relation is not the same as an equivalence relation, the classical uncertainty measurement tools and methods are not applicable to the fuzzy knowledge classification systems. Considering the characteristics of vague and fuzzy data, we use the fuzzy rough set model to granulate those data. Moreover, we study the uncertainty measures in the fuzzy rough set model. After introducing several measures in classical rough sets, we propose naturally extensional measures of uncertainty for information systems.
The remainder sections are structured as follows. An introduction to rough sets and several measures are presented in Section 2. In Section 3, a granulated fuzzy rough set model is introduced. Then we propose two uncertainty measures in our proposed fuzzy rough set model, which are information entropy-based and information granularity-based measures. Furthermore, we prove some theorems associated with the proposed measures. In Section 4, for contributing to understand further concepts of information entropy and information granularity, we carry out some experiments in decision systems. Finally, this paper is concluded with some discussions and remarks in Section 5.
Preliminaries
In the following section, some basic concepts in Pawlak rough sets are recalled, which can be found in [46] and [47]. These definitions mainly include equivalence relation, upper and lower approximations. Furthermore, we also introduce some uncertainty measures in Pawlak rough sets.
Pawlak rough sets
The information systems are formalized representations of some practical application systems. Generally, an information system is expressed by a quadruple IS = (U, A, V, f), where U = {x 1, x 2,…, x m } is an m-dimensional sample set; A = {a 1,…, a n } is an n-dimensional attribute or feature set; V = ⋃ a∈A V a is a union of values on attribute a and f : U × A → V is a mapping function.
For any attribute subset P ⊆ A, an equivalence relation is represented by IND (P) in the following:
IND (P) = {(x, y) ∈ U × U| ∀ p ∈ P, f (x, p) = f (y, p)}.
The IND (P) satisfies reflexivity, symmetry and transitivity. A partition of U induced by the IND (P) is denoted by U/IND (P) or U/P. We define the partition by:
U/P = {[x i ] P : x i ∈ U where [x i ] P represents an equivalence class belonging to a sample x i . The elements of an equivalence class are equivalent to each other. Equivalence classes are used to depict arbitrary subsets of U, which are also named as information granules, elementary sets and blocks.
P * (X) = {x i ∈ U| [x i ] P ⊆ X},
P* (X) = {x i ∈ U| [x i ] P ∩ X ≠ ∅},
where [x i ] P represents an equivalence class on P of a sample x i .
The lower approximation consists of samples which equivalence classes are contained in X, while the upper approximation consists of samples which equivalence classes are intersected with X. The tuple <P * (X), P* (X)> is named as a rough set of X, if the lower approximation is not equal to the upper approximation. The rough set degrades into a crisp set, if they are equal.
Uncertainty measures in Pawlak rough sets
In rough sets, there are two aspects uncertainty measures: algebra representation measures and entropy representation measures. On the one aspect, the algebra representation measures include accuracy, approximation accuracy, roughness and approximation roughness. On the other aspect, there are mainly three entropy representation measures which are information entropy, conditional entropy and mutual information.
The accuracy measures the imprecision of a rough set by the ratio of lower approximation to upper approximation. The roughness is an inverse of accuracy by a subtraction.
Approximation roughness measure is calculated by subtracting the approximation accuracy, which is defined as
The measures of accuracy and roughness are used for evaluating uncertainties of information systems, while the approximation accuracy and approximation roughness are used for evaluating uncertainties of decision systems. However, these measures are not enough meticulous. Liang et al. [24] explained that the two different partitions may reach the same accuracy or roughness.
In 1948, Shannon [6] originally proposed the information theory to measure the uncertainty of a channel transmission. Düntsch [19], Yao [45] and Miao [11] developed various entropy measures for evaluating uncertainties of attributes or features of information systems.
A granulated fuzzy rough set and its measures
The traditional rough set theory is used to tackle categorical data in information systems. As for numerical data, a discretization should be implemented before a machine learning task. However, this preprocessing will lead to an information loss. In the follows, a granulated fuzzy rough set model is presented to deal with categorical data in a knowledge representation system. The fuzzy similar relation is founded by a distance matrix, then similar granules are achieved by a granulating method. Furthermore, several uncertainty measurement tools are proposed to meticulously measure fuzzy relations or fuzzy granules.
Fuzzy granulating with a distance matrix
The granulating idea of Pawlak rough sets is founded on equivalence classes and equivalence relations. In this section, we will introduce a distance matrix to describe a similarity between two objects. Then, we construct a fuzzy similar relation from the distance matrix.
An information system.
An information system.
We use the Euclidean distance to granulate these objects in the information system. Three distance matrices of the attribute sets R = {a}, S = {a, b} and T = {a, b, c} are achieved as follows:
D′ (B)=D (B)/max (D (A)), where max (D (A)) is a constant, which is the maximal value of elements of D (A). For simplicity, all the distance matrices in the follows are normalized.
The distance matrix describes how far they are between two objects, while the fuzzy similar relation matrix represents how similar they are between two objects. It means that there is a relation between the two matrices. Consequently, we construct a fuzzy similar relation matrix from a distance matrix by the formula
For two fuzzy similar relations
These operations can be interpreted as extensions of fuzzy-theoretic operations in a framework of fuzzy similar relation computations. Different fuzzy similar relation may be formed by different distance metrics of objects. The above operations may be used for combining fuzzy similar relation. It can be easily verified that these operations satisfy the following properties: 1)Commutativity:
Then, the fuzzy similar granules are listed in the follows:
1)
The tuple
Information entropy is originally proposed by Shannon in literature [6]. It tells how much information there is in an event. In general, the more uncertain or random the event is, the more information it will contain. Information entropy refers to disorder or uncertainty, measuring the uncertainty of an attribute set or an equivalence relation in Pawlak rough sets. In the follows, it is applied for evaluating fuzzy similar relations or fuzzy similar granules. Furthermore, we present its various extensional forms.
Information granularity measures of fuzzy similar granules
The information granularity also called knowledge granularity is firstly proposed in literature [12]. But the measure of information granularity is not suitable for the fuzzy data. In the subsection, a new information granularity is proposed to evaluate the uncertainty of a fuzzy similar relation or fuzzy similar granules.
Experiments
In order to demonstrate the advantages of the uncertainty measures proposed in this paper, some experiments are conducted on two real-life data sets, which are Iris and Wine. The two real-life data sets are used available from UCI repository of machine learning database. The conditional attribute subset is increased from one attribute to all attributes during the experiments.
The measuring results are the information entropy of fuzzy granules, information granularity of fuzzy granules and approximation accuracy method,which are shown in Fig. 1 and Fig. 2. It can be seen from the two Figs. that the values of these measures are increasing with the number of selected attributes becoming bigger. We know that these measures are inversely proportional to the uncertainty. Therefore, that means the uncertainty decreases as the number of attributes we select increases. In other words, the uncertainty decreases when more available knowledge is supplied. They demonstrate the validity of the three measures in decision systems. It follows that the three measures both can be used to measure the uncertainty. It is easy to find that the values of approximation accuracy are the same when the number of attributes increased from 3 to 4 in Iris. Similarly, there is no change as the number of attributes increases from 4 to 5 and from 7 to 13 in Wine. In comparison, the information entropy and information granularity can evaluate the uncertainty more accurately. The results show that measures of information entropy and information granularity can provide more information for evaluating the uncertainty in decision systems. The result of Iris data set. The result of Wine data set.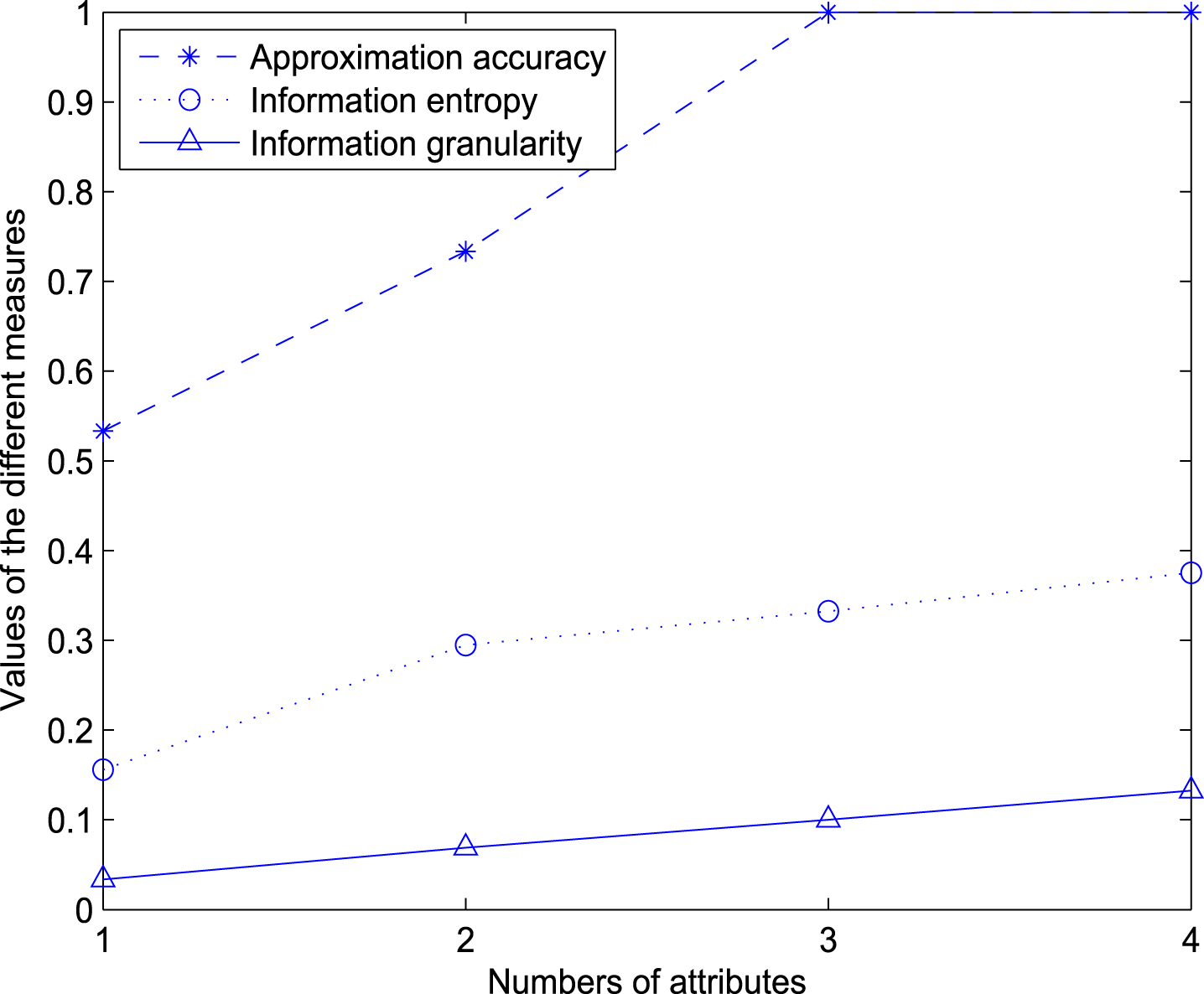

The contribution of our work is two aspects. On one aspect, we construct fuzzy similar relations and fuzzy similar granules by introducing a distance matrix on information systems. Furthermore, we define some operations on these fuzzy similar relation and granules. And we present a fuzzy rough set model which combines roughness and fuzziness, for deal with information systems containing real-value data. On the other aspect, this paper has focused the development of uncertainty measures, tackling the problems of noisy and real-valued data, as well as dealing with mixtures of discrete and continuous value attributes of an information system. We have achieved this by proposing a fuzzy rough set and its some uncertainty measures. The original measures proposed by Pawlak are not suitable for real-value information systems. Consequently, two uncertainty measures are developed to handle the uncertainty of a fuzzy similar relation, which are information entropy and information granularity. Theoretical analyses and experimental results show that these measures are monotonic and valid. These measures will be used to evaluate the significance of attributes or features in an information system. Therefore, some attribute reduction algorithms will be developed based on these measures in the future. They may be potentially applied to fields such as feature selection, gene selection and decision rule extraction.
Footnotes
Acknowledgment
This work is supported by the National Natural Science Foundation of China (Nos. 61573297 and 61672442), the Social Science Planning Project of Fujian Province (No. FJ2017C012), the Natural Science Foundation of Fujian Province (Nos. 2015J05015 and 2016J01325) and the Program for New Century Excellent Talents in Fujian Province University.