
Abstract
A set-valued information system is the generalization of a single-valued information system and its information structures reflect the internal features of this kind of information system. This paper investigates information structures in a set-valued information system from granular computing viewpoint, i.e., information structures are viewed as granular structures. The distance between two objects in a set-valued information system is first introduced. Then, the fuzzy T cos -equivalence relation, induced by this kind of information system by using Gaussian kernel method, is obtained, where Gaussian kernel is based on this distance. Next, information structures of this kind of information system are described by set vectors. Moreover, relationships between information structures are studied from two sides of dependence and separation. Finally, as a simple application for the proposed information structures, granularity measure of uncertainty for a set-valued information system is investigated. These results will be helpful for establishing a framework of granular computing in an information system.
Keywords
Introduction
Granular computing, presented by Zadeh [63–66], is an important tool in artificial intelligence and information processing Its purpose is to seek for an approximation scheme, which allows us to view a phenomenon with different levels of granularity and then can effectively solve a complex problem. Information granulation, organization and causation are basic notions of granular computing. Information granule is a family of objects that are drawn together by some constraints, such as indistinguishability, similarity or functionality. The process of constructing information granules is called information granulation. It granulates a universe into a family of disjoint or overlapping information granules. Granular structure is the family of information granules where the internal structure of each information granule is visible as a sub-structure. Naturally, granular structure can be depicted as a vector consisting of information granules. Lin [21, 22] and Yao [57–59] explained the importance of granular computing, this aroused people’s interest in it. Until now, the study on granular computing mainly has four methods, i.e., rough set theory [36], fuzzy set theory [62], concept lattice [34, 52] and quotient space theory [71].
Rough set theory is an effective tool to deal with uncertainty. An information system based on rough set theory was presented by Pawlak [36–40]. Most applications of rough sets, such as uncertainty modeling [6, 49], reasoning with uncertainty [12, 59], rule extraction [5, 53], classification and feature selection [14, 50] are related to information systems.
In granular computing in information systems, information granular and information structures are two important concepts. An equivalence relation is a special kind of similarities among objects from a data set. In an information system, an attribute subset determines an equivalence relation. This equivalence relation partitions the universe into some disjoint classes, these classes are called equivalence class or information granules. If two objects of the universe belong to the same equivalence class, then we may say that they cannot be distinguished under this equivalence relation. Thus, every equivalence class is an information granule consisting of indistinguishable objects [21, 41]. All these equivalence classes or information granules constitutes a vector, this vector is called an information structures in the information system induced by this attribute subset. Obviously, an information structure in this information system is namely a granular structure in the meaning of granular computing. Li et al. [27] gave information structure in distributed fc-decision information systems.
It is known that an unknown target concept can be characterized approximately by existing knowledge structures in a knowledge base, which is one of the strengths of rough set theory. In granular computing in knowledge bases, Qian et al. [41] studied knowledge structures in a knowledge base. Li et al. [26, 28] investigated knowledge structures in a knowledge base and relationships between knowledge bases. Their results have been shown to be very helpful for knowledge discovery from knowledge bases and significant for establishing a framework of granular computing in knowledge bases [45]. Similarly, knowledge structure in a knowledge base are namely granular structures in the meaning of granular computing.
Uncertainty, including randomness, fuzziness, vagueness, incompleteness and inconsistency, nearly exists in everywhere of the real world. Uncertainty measurement is an important issue in the research of many fields, such as machine learning [55], pattern recognition [7, 13], image processing [35], medical diagnosis [15], information retrieval and data mining [10]. Some scholars have done some exploration in this aspect and many excellent research contributions have been made. For example, Yao et al. [58] gave a granularity measure from the angle of granulation; Wierman [51] presented measures of uncertainty and granularity in rough set theory; Bianucci et al. [1, 2] explored entropy and co-entropy approaches for uncertainty measurements of coverings; Beaubouef et al. [4] proposed a method for measuring the uncertainty of rough sets. Liang et al. [29, 30] investigated information granulation in complete and incomplete information systems; Dai et al. [11] researched entropy measures and granularity measures for set-valued information systems; Qian et al. [43, 44] presented the axiomatic definition of information granulation in a knowledge base and studied information granularity of a fuzzy relation by using its fuzzy granular structure; Yao [56] studied several types of information-theoretical measures for attribute importance in rough set theory. Xie et al. [54] gave new measures of uncertainty for an interval-valued information system; Zhang et al. [69] considered uncertainty measures for a fully fuzzy information system.
So far, information structures in a set-valued information system has not been reported. Considering that a set vector is better than a set family in displaying the image of information structures in a set-valued information system, the purpose of this paper to investigate information structures in a set-valued information system by means of set vectors.
The remaining part of this paper is organized as follows. In Section 2, we recall some basic concepts about fuzzy sets, fuzzy relations and set-valued information systems. In Section 3, we introduce the distance between two objects in a set-valued information system. In Section 4, we give the fuzzy T cos -equivalence relation induced by a set-valued information system by using Gaussian kernel method. In Section 5, we investigate information structures in a set-valued information system and study relationships between information structures from two sides of dependence and separation. In Section 6, we give a simple application for the proposed information structures by obtaining granularity measure of uncertainty for a set-valued information system. Section 7 summarizes this paper.
Preliminaries
We first review some basic concepts about fuzzy sets, fuzzy relations and set-valued information systems.
Throughout this paper, U denotes a finite set called the universe, 2 U denotes the family of all subsets of U, I denotes the unit interval [0, 1] and |X| denotes the cardinality of X ∈ 2 U .
Put
Fuzzy sets and fuzzy relations
Fuzzy sets are extensions of ordinary sets [62]. A fuzzy set P in U is defined as a function assigning to each element x of U a value P (x) ∈ I and P (x) is called the membership degree of x to the fuzzyset P.
In this paper, I
U
denotes the set of all fuzzy sets in U. The cardinality of P ∈ I
U
can be calculated with
If R is a fuzzy set in U × U, then R is called a fuzzy relation on U. In this paper, IU×U denotes the set of all fuzzy relations on U.
Let R ∈ IU×U. Then R may be represented by M (R) = (r ij ) n×n, where r ij = R (x i , x j ) ∈ I means the similarity between two objects x i and x j .
If M (R) = E, then R is said to be a fuzzy identity relation, and we write as R =▵; if r ij = 1, i, j ≤ n, then R is said to be a fuzzy universal relation, and we write as R = ω.
Let R ∈ IU×U. For each x ∈ U, we define a fuzzy set S
R
(x):
(1) Commutativity: T (a, b) = T (b, a) ,
(2) Associativity: T (T (a, b) , c) = T (a, T (b, c)) ,
(3) Monotonicity: a ≤ c, b ⩽ d = T (a, b) ⩽ T (c, d) ,
(4) Boundary condition: T (a, 1) = a .
Then T cos is a t-norm.
(1) Reflexivity: R (x, x) =1,
(2) Symmetry: R (x, y) = R (y, x) ,
(3) T-transitivity: T (R (x, y) , R (y, z)) ⩽ R (x, z) .
Set-valued information systems
If P ⊆ A, then (U, P) is called a subsystem of (U, A).
If P ⊆ A, then (U, P) is called a subsystem of (U, A).
A set-valued information system
A set-valued information system
According to the above definition, the distance between two objects in a set-valued information system is defined as follows.
Then
Thus
By Definition 3.1, we have
Then
The fuzzy T cos -equivalence relation induced by a set-valued information system
In this section, we give the fuzzy T cos -equivalence relation induced by a set-valued information system by means of Gaussian kernel method.
Gaussian kernel method is an important methodology in machine learning and pattern recognition. For making data linear and simplifying classification tasks, it maps data into a higher dimensional feature space [47, 61]. Hu et al. [16, 17] found that there are some relationships between rough sets and Gaussian kernel method, so Gaussian kernel is used to obtain fuzzy relations. In this section, we use Gaussian kernel to extract a fuzzy T cos -equivalence relation on the object set of a given set-valued information system.
Gaussian kernel
Obviously, G (x, y) satisfies:
(1) G (x, y) ∈ [0, 1];
(2) G (x, y) = G (y, x);
(3) G (x, x) =1.
Then
Information structures in a set-valued information system
In this section, we investigate information structures in a set-valued information system.
Some concepts of information structures in a set-valued information system.
Given R ∈ IU×U. Then for each i, S
R
(x
i
) can be viewed as the fuzzy neighborhood or the information granule of the point x
i
[44]. According to this view, Qian et al. [44] defined the fuzzy granular structure of R as follows:
Let (U, A) be a set-valued information system. Given P ⊆ A and θ ∈ (0, 1]. Then, by Theorem 4.2,
Then S θ (P) is called the information structure of the subsystem (U, P) with respect to θ or θ-information structure of the subsystem (U, P).
Below, we propose dependence between information structures.
(1) S
θ
2
(Q) is called to depend on S
θ
1
(P), if for each i,
(2) S
θ
2
(Q) is called to depend partially on S
θ
1
(P), if there exists i,
(3) S
θ
2
(Q) is called to be independent on S
θ
1
(P), if for each i,
Obviously,
S θ 1 (P) = S θ 2 (Q)
⇔ S
θ
1
(P) ⪯ S
θ
2
(Q), S
θ
2
(Q) ⪯ S
θ
1
(P) ,
Properties of information structures in a set-valued information system
In this subsection, we give properties of information structures in a set-valued information system.
Proof. Obviously. □
Proof. Clearly. □
Proof. This follows from Theorems 5.6 and 5.7. □
(1) If 0 < θ1 ≤ θ2 ≤ 1, then for any P ⊆ A, S θ 1 (P) ⪯ S θ 2 (P);
(2) If P ⊆ Q ⊆ A, then for any θ ∈ (0, 1], S
θ
(Q) ⪯ S
θ
(P). Proof.(1) For any i, j, it is clear that
Then
So
By Theorem 5.7,
(2)
Then
So
Thus, by Theorem 5.7, S θ (Q) ⪯ S θ (P) . □
S θ 1 (Q) ⪯ S θ 2 (Q) ⪯ S θ 2 (P), S θ 1 (Q) ⪯ S θ 1 (P) ⪯ S θ 2 (P).
(1) 0 ≤ D (S θ (Q)/S θ (P)) ≤1;
(2) S θ (P) ⪯ S θ (Q) implies D (S θ (Q)/S θ (P)) =1;
(3) S θ (P) ⊑ S θ (Q) ⊑ S θ (L) implies D (S θ (P)/S θ (L)) ≤ D (S θ (P)/S θ (Q)).
D (S θ (B)/S θ (C))
= 0. D (S θ (C)/S θ (B))
= 0.
Thus
The following theorem shows the fact that relationships between information structures in a set-valued information system can be quantitatively described by the inclusion degree.
(1) S θ (P) ⪯ S θ (Q) ⇔ D (S θ (Q)/S θ (P)) =1 .
(2) S θ (P) ⋈ S θ (Q) ⇔ D (S θ (Q)/S θ (P)) =0 .
(3) S θ (P) ⊑ S θ (Q) ⇔0 < D (S θ (Q)/S θ (P)) ≤1 .
It follows that ∀ l,
Hence S θ (P) ⪯ S θ (Q).
(2) “⇒". Since S
θ
(P) ⋈ S
θ
(Q), we have
Thus D (S θ (Q)/S θ (P)) =0.
“⟸". Since D (S
θ
(Q)/S
θ
(P)) =0, we obtain that ∀ l,
Then ∀ l,
(3) This follows from (1) and (2).
Information distance between two information structures
Considering separation between information structures, in this subsection, we propose the concept of information distance to differentiate two information structures in the same incomplete real-valued information system and give some of its properties.
For A, B ∈ I
U
, denote
If A ⊆ B, then |A ⊕ B| = |B - A| = |B| - |A| .
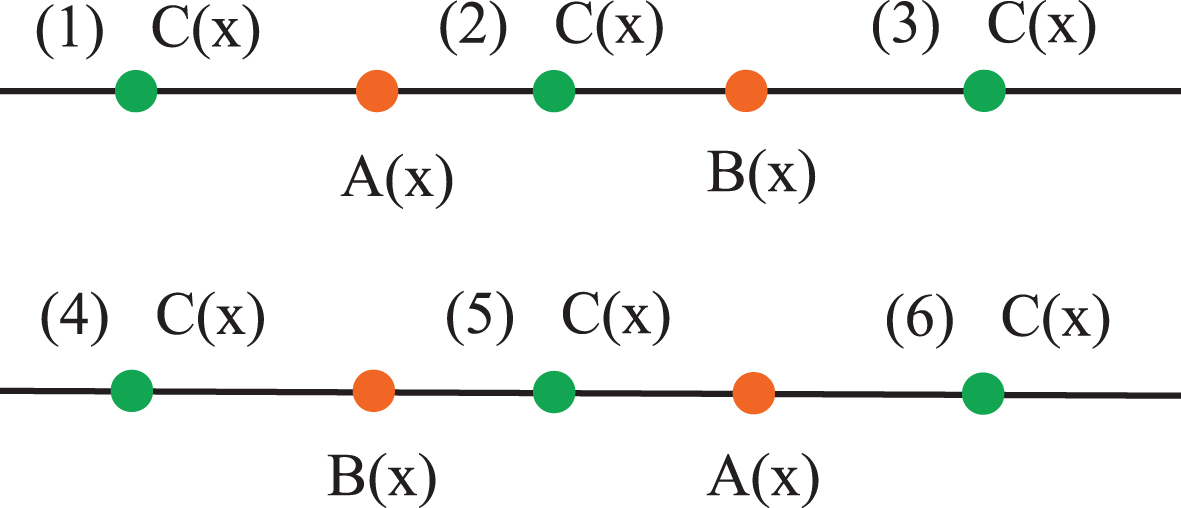
The sizes of A (x), B (x) and C (x).
We only prove case (1).
Given x ∈ U, since C (x) ≤ A (x) ≤ B (x), we have
|A ⊕ B| + |B ⊕ C| - |A ⊕ C|
= (|B| - |A|) + (|B| - |C|) - (|A| - |C|)
= 2 (|B| - |A|) ≥0.
Thus
If A ⊆ B ⊆ C, then |A ⊕ B| + |B ⊕ C| = (|B| - |A|) + (|C| - |B|) = |C| - |A| = |A ⊕ C|.
If C ⊆ B ⊆ A, then |A ⊕ B| + |B ⊕ C| = (|A| - |B|) + (|B| - |C|) = |A| - |C| = |A ⊕ C|.
ρ (S θ (P) , S θ (Q)) ≥0,
ρ (S θ (P) , S θ (Q)) = ρ (S θ (Q) , S θ (P)).
By Lemma 5.3,
ρ (S
θ
(P) , S
θ
(Q)) =0 ⇔ ∀ i,
By Lemma 5.3, we have
ρ (S θ (P) , S θ (Q)) + ρ (S θ (Q) , S θ (L))
= ρ (S θ (P) , S θ (L)).
Thus (
(1)
(2) If S
θ
(P) ⪯ S
θ
(Q) and
(3) If S
θ
(P) ⪯ S
θ
(Q), then
Then
Thus
Hence
(2) Since S
θ
(P) ⪯ S
θ
(Q), ∀ i, we have
Thus
ρ (S θ (P) , S θ (P*))
= ρ (S θ (Q) , S θ (P*)) .
(3) Note that S
θ
(P) ⪯ S
θ
(Q). Then, ∀ i,
Thus
ρ (S θ (P) , S θ (∅))
= ρ (S θ (Q) , S θ (∅)) . □
Uncertainty measurement for an information system was investigated and relationships between these measures were discussed [30]. These measures include granulation measure, information entropy, rough entropy, and knowledge granulation. They have become an effective mechanism for evaluating the uncertainty of an information system. In this section, as a simple application for information structures in a covering information system, granulation measures for a set-valued information system are investigated.
We first give the axiom definition of information granulation in a set-valued information system.
(1) Non-negativity: ∀ P ⊆ A, G θ (P) ≥0;
(2) Invariability: ∀ P, Q ⊆ A, if S θ (P) = S θ (Q), then G θ (P) = G θ (Q);
(3) Monotonicity: ∀ P, Q ⊆ A, if S θ (P) ≺ S θ (Q), then G θ (P) < G θ (Q).
Here, G θ (P) is called θ-information granulation of the subsystem (U, P).
Similar to Definition 5 in [44], θ-information granulation of a set-valued information system is given in the following definition.
If
If
(1) If S θ 1 (P) ⪯ S θ 2 (Q), then G θ 1 (P) ≤ G θ 2 (Q);
(2) If S θ 1 (P) ≺ S θ 2 (Q), then G θ 1 (P) < G θ 2 (Q).
Thus G θ 1 (P) ≤ G θ 2 (Q) . (2) Since S θ 1 (P) ≺ S θ 2 (Q), we have S θ 1 (P) ⪯ S θ 2 (Q) and S θ 1 (P) ≠ S θ 2 (Q).
Then, ∀ i,
So, ∀ i,
Hence G θ 1 (P) < G θ 2 (Q). □
This proposition illustrates the fact that θ-information granulation increases when the available information becomes coarser, and it decreases when the available information becomes finer. In other words, the more uncertain the available information is, the bigger θ-information granulation value becomes. Thus, we can conclude that θ-information granulation introduced in Definition 6.2 can be used to evaluate the uncertainty of a set-valued information system.
(1) If 0 < θ1 ≤ θ2 ≤ 1, then for any P ⊆ A, G θ 1 (P) ≤ G θ 2 (P).
(2) If P ⊆ Q ⊆ A, then for any θ ∈ (0, 1], G θ (Q) ≤ G θ (P).
We have
Thus G θ 1 (A) < G θ 2 (A) .
(1) Obviously, “non-negativity" holds.
(2) Given θ ∈ (0, 1] and P, Q ⊆ A. If S
θ
(P) = S
θ
(Q), then ∀ i,
By Definition 6.2, G θ (P) = G θ (Q).
(3) “Monotonicity” follows from Theorem 6.5. □
Conclusions
In this paper, information structures in a set-valued information system have been described as set vectors. Relationships between information structures have been investigated from two sides of dependence and separation. As a simple application for the proposed information structures, granularity measures for a set-valued information system have been investigated. In future work, In the future, we will consider the other applications of the proposed results.