
Abstract
The choice of attribute significance is the most important step of attribute reduction algorithm. Information entropy is a method of calculating the importance of attributes. Due to the fact that information view only takes the size of knowledge granularity into account rather than measures the importance of attributes objectively and comprehensively this paper begins with putting forward the definition of approximate boundary accuracy based on algebra view. Afterwards, this paper proposes two concepts of relative information entropy and enhanced information entropy based on the definition of relative fuzzy entropy, which has obvious magnification effect. Then, two new methods of attribute reduction are proposed by incorporating approximate boundary precision into relative information entropy and enhanced information entropy, so that the choice of the importance of the attribute is more objective and comprehensive. Finally, it will analyze and compare the classification accuracy of each kind of algorithm by using the SVM classifier and ten-fold crossover method, and analyze the influence of outliers on the effect of the algorithm. Through experimental analysis and comparison, it can be concluded that the attribute reduction based on improved entropy is feasible and effective.
Keywords
Introduction
Rough set theory [1, 2] is a typical mathematical tool to dispose the imprecise, incomplete, and inconsistent information in fuzzy information system. At present, rough set theory has been successfully applied to a number of areas: data mining, machine learning, rule generation, troubleshooting, risk profile and other fields [3–7].
Attribute reduction is one of the core contents in the research of rough set. It aims to remove redundancy attribute and replace original data with fewer attribute to achieve the ideal reduction effectiveness in the case of keeping the same capacity of classification. In recent years the researchers of rough set have proposed lots of measures about attribute importance, based on which many heuristic attribute reduction algorithms are designed. Up till now, there are two views in rough set theory, including algebra view and information view. The former bases on the indiscernibility relations and studies the effect of attribute on certain classfication subset in domain. It defines the attribute importance with algebraic expression and the algorithms mainly contain positive [8–10], discernibility matrix [11, 12]. The latter is to study the effect of attribute on uncertain classfication subset in domain from the view of information granules, which can measure the size of knowledge granularity effectively.
Information entropy was proposed by Shannon to measure the changes of material state in 1948 [13]. Then the concept is introduced to rough set by many researchers to measure uncertainty information and some attribute reduction algorithms based on information entropy emerge accordingly [14–20]. Literature [14] proposes an attribute reduction algorithm based on conditional informattion entropy. Literature [15] proposes approximate reduction based on conditional information entropy. According to the actual application, literature [15] removes some redundant attributes, effectively enhancing its anti-noise and anti-interference ability, and playing a supplementary role in attribute reduction of decision table based on conditional information entropy. And literature [16] proposes the concept of correcting condition entropy and fuzzy relative entropy in decision system based on the characteristic of uncertainty of fuzzy entropy and blurring.
Most of the existing methods of attribute reduction based on entropy mainly calculate the importance of attribute through infromation theory, and seldom do they combine with algebra view. Literature [14] proposes and proves that algebra view is highly complementary to attribute importance defined by information theory. The objectivity of measurement of attribute importance directly influence the results of attribute reduction and time consume of the system. In order to search the most important attribute quickly and precisely, it is necessary to take all associated factors into consideration and propose a more comprehensive attribute importance measurement method by combining the features of algebra view and information theory. In addition, the existing attribute reduction algorithms based on entropy have higher time complexity and need to be imporved.
In view of the above question, literature [17] proposes approximate decision entropy, which combines the approximation quality under algebra view and the conditional entropy under information theory, then an overall attribute importance measurement method is gained. To further investigate the measurement metohd objectively and fully, this paper proposes a new information entropy of approximate boundary precision model based on algebra view. At first, it calculates the effect of the positive region on boundary precision under algebra view. This paper proposes and proves that approximate boundary precision and approximate precision have the same monotonicity, and play a role of modifying approximate precision with magnification. Secondly, the concept of the relative information entropy and the enhanced entropy are proposed on the basis of fuzzy relative entropy in literature [16] from the perestive of information theory. This paper discusses the monotonicity and reasonability of the two information entropy, which has more obvious magnifaction effect than the fuzzy relative entropy. Hence, A new reduction method is proposed on the basis of combinig modified approximate boundary precision with two kinds of entropy. Finally, experimental analysis and comparison with six kinds of similar algorithms on reduction time and attribute redction results will be given.
This paper proposes the reduction algorithm of relative information entropy (ABIE) and enhanced information entropy (ABIE′) based on approximate boundary precision information entropy. In the process of attribute reduction, as the algorithm of ABIE and ABIE′ shows non-strict monotonicity, it provides the basis for the rationality of the algorithm. Meanwhile the new model which measures the importance of attribute has obvious magnifaction effect than the fuzzy relative entropy of paper [16] under the same conditions. It can provide an effective way to select the most important attribute quickly. The new information entropy model is more comprehensive because it considers the effect of determined-classfication and uncertainty fully. And the reduction algorithm shows the feasibility and validity of the new model through the analysis of experimental data. Besides, the advantages of time performance and attribute reduction quality are shown under the new information entropy model where deficiency is great influenced by the outer rate which can provide the reasonable references.
Preliminary
Obviously, if IND (B) denotes as U/B, U/B is an equivalence relation. Supposing U/B includes x, the equivalence relation x is defined as follows:
Supposing that as the α
B
(X) increases and 1 - α
B
(X) decreases, the value of By Definitions 2 and 3, we arrive at the conclusion of 0 ≤ α
B
(X) ≺1. Then the value of β
B
(X) - α
B
(X) is
In a word, both the α B (X) and the β B (X) have the same monotonicity. In order to calculate the unity in scope and confine it between 0 and 1, the amended approximate boundary precision definition is proposed as follows,
Obviously, we can get the result of
From above, we can get the conclusion that
Relative information entropy and enhanced information entropy
Relative fuzzy entropy E (D
B
) is
The equivalent form of the amended condition information entropy is as follows,
Let P (Y
j
|X
i
) be
(2) when
(1) If
We get the results of |X
k
∪ X
l
| = |X
k
| + |X
l
| and | (X
k
∪ X
l
) ∩ Y
j
| = |X
k
∩ Y
j
| + |X
l
∩ Y
j
| because of X
k
∩ X
l
= ∅. Let |X
k
| be x, |X
l
| be y, |X
k
∩ Y
j
| be ax and |X
l
∩ Y
j
| be by. Obviously, x and y are greater than 0, and a and b are greater than equal to 0 and less than
(2) If
Let |X
k
| be x, |X
l
| be y, |X
k
∩ Y
j
| be ax and |X
l
∩ Y
j
| be by. Obviously, x and y are greater than 0, and a and b are greater than equal to
In conclusion, RIE (D B i+1 ) is less than or equal to RIE (D B i ).
As the relative information entropy is calculated, we must judge the range of
The enhanced information entropy is proposed as follows:
Let |X
k
| be x, |X
l
| be y, |X
k
∩ Y
j
| be ax and |X
l
∩ Y
j
| be by. Obviously, x and y are greater than 0, and a and b are greater than equal to 0 and less than or equal to 1. We could get the following conclusion,
In conclusion, RIE′ (D B i+1 ) is less than or equal to RIE′ (D B i ).
Suppose
So RIE′ (D B ) is greater than or equal to E (D B ).
The blended entropy consists of approximate boundary precision and relative information entropy based on D relative to B, the definition will be as follows:
The definition of approximate boundary precision enhanced information entropy will be as follows:
There are algorithms based on algebra view and algorithms based on information view in the fields of attribute reduction. The algorithm of algebra view can measure the completeness of knowledge effectively, but it is not ideal to measure the size of knowledge. On the contrary, information view can measure the size of knowledge effectively, but there is nothing to be done about the completeness of knowledge. Obviously, study on attribute reduction from the sole algebra view or information view is one-sided. As can be seen from Definition 9, the information entropy enhanced by approximate boundary precision effectively combines the characteristics of information view and algebra view. The new model considers both completeness and the size of knowledge compared with the traditional information entropy model. So the new information entropy can measure the uncertainty of the rough set comprehensively and objectively.
(1) According to the definition of U/B and the partial ordering of
So, it can be concluded that the value of is less than or equal to .
(2) Let U/D be {Y1, Y2, ⋯ , Y
m
}. By Theorem 2, we can get the following conclusion:
That is to say, RIE′ (D|B) is greater than or equal to RIE′ (D| (B ∪ a)). Similarly, by Theorem 1, we can get the result of RIE (D|B) ≥ RIE (D| (B ∪ a)).
In summary, Theorem 3 is correct.
By Theorem 3, we can know that both function ABIE′ () and ABIE () have non-strict monotonicity. Therefore, we can use the characteristics of approximate boundary precision enhanced information entropy (or relative information entropy) to measure the importance of attribute, and based on which reduction set can be calculated.
The significance of enhanced information entropy is defined as
There is a large number of calculations of |X i ∩ Y j | in process of getting information entropy. X i is the sub-division of U/B. Y j is the sub-division of U/D. The solution code of X*Y is as follows:
char[ ] intersect(string X, string Y)
{ Char[ ] Z;
int i = 0,j = 0,k=0;
while(i < X.length && j < Y.length)
{ if (X[i] = =y[j])
{ Z[k++] = X[i]; i++; j++; }
else if (X[i] > Y[j])
j++;
else
i++; }
return Z; }
In this paper, the time complexity of computing intersection of two sets is reduced from |X||Y| to|X| + |Y|, among which |X| is the radix of set X, and |Y| is the radix of set Y.
enlargethispage 5pt
Input: Let DT = (U, C, D, V, f) be a decision table, U/B = {X1, X2, ⋯ , X n }, U/D = {Y1, Y2, ⋯, Y m }, and B ⊆ C.
Output: ABIE′ (D|B) and ABIE (D|B).
int ABIE′ = ABIE = 0;
int type;
for (i from 1 to m)//The number of sub-division of U/D is m.
{ int t1 = t2 = t3 = t4 = count = 0;
input type;
for (j from 1 to n)//The number of sub-division of U/B is n.
{count = count + |X j |;
temp = intersect (X j , Y i ).length;//statistics the numbers of lower approximations
if (temp==|X j |) then
t1 = t1+ |X j | ;
else if (temp = =0)
t2 = t2 + |X j |;
else { switch(type) {
Case 1://compute enhanced information entropy
break;
Case 2://compute relative information entropy
if
else
break; } }
t2 = count – t2;//statistics the numbers of upper approximations
Input: DT = (U, C, D, V, f);
Output: R.
{ calculate
Let R = R ∪ b k and C′ = C′ - b k ;
if (ABIE′ (R|C) equal to ABIE′ (D|C))
output the reduction R of enhanced information entropy;
if (ABIE (R|C) equal to ABIE (D|C))
output the reduction R of relative information entropy.}
The main time expense of the algorithm is to find information entropy. If an attribute is added to reduction set R, the approximate boundary precision information entropy should be recalculated. Because of the flexible use of U/B to calculate U/(B ∪ b), the time of calculation A is reduced to O (|U|). In the process of calculating attribute reduction,any one of the most important attributes is added to the reduction set every time, the worst time complexity of the algorithm is O (|C|2|U|).
To further verify the performance of algorithm in this paper and other similar algorithms, we use VS2012 based on Windows7 system as development tool. This is a kind of machines with 4 GB main memory and Intel(R) Coretrademark i7-4712MQ Processor (2 cores in all, each having a clock frequency of 2.3 GHZ. In this paper, six data sets are all downloaded from UCI repository of machine learning databases, as following, (1) Ecoli data set with 336 samples, 8 attributes and 8 classes; (2) Chess King-Rook vs. King-Pawn(Chess) data set with 3196 samples, 37 attributes and 2 classes; (3) Tic-Tac-Toe endgame(Tic) data set with 958 samples,10 attributes and 2 classes; (4) Mushroom(Mush) data set with 8124 samples,23 attributes and 2 classes. (5) Zoo data set with 101 elements, 17 attributes and 7 classes; (6) Lymphography (Lymph) data set, with 148 samples, 19 attributes and 4 classes;
enlargethispage 2pt
This paper is compared with the following several representative algorithms.
(1) Approximation decision entropy based method ( ADEAR ) [17]; (2) Relative fuzzy entropy based method ( RFE ) [16]; (3) Combination conditional entropy based method ( CCE ) [19]. (4) Conditional entropy based method ( CE ) [14].
The experiment was compared on the results of reduction, classification precision and running time. Table 1 shows the reduction of the different algorithms based on the above six data sets, of which RN is the radix of minimum attribute reduction. From it, it can be seen that the three algorithms of CE, RFE and CCE only study information entropy with calculating the significance of attribute, affecting the effect of reduction. However, the algorithm of ADEAR integrates approximate precision into information entropy; ABIE integrates approximation precision into relative information entropy and ABIE′ integrates approximate boundary precision into enhanced information entropy. These algorithms combine the concept of algebra view and information view effectively, which can measure the importance of attribute comprehensively and objectively. There is better reduction effect with the six data sets in Table 1. By comparing Algorithm ABIE with ABIE′, CE, RFE and CCE in running time, the results are shown in Table 1.
Comparison of reduction result (residue number/run time(s))
Comparison of reduction result (residue number/run time(s))
As shown in Table 1, the running time of algorithm ABIE is much less than CE and RFE under the same data reduction. As the algorithms of ADEAR and ABIE utilize efficient methods to save a lot of system time cost overhead. The calculation of attributes importance is computationally equivalent to those algorithms, so there is no significant difference in time performance. Method ABIE′ has less judgment steps than method ABIE. And by using the characteristics of information entropy expansion, the most important attributes can be found quickly and the speed of reduction can be increased, so the time performance is superior.
(2) In order to further verify the algorithm based on information entropy and positive domain (FABS [20]), and the accuracy of the classification of ABIE′ in this paper, the reduction results of each algorithm are used as the input of SVM classifier. In order to improve the classification accuracy of SVM classifier, 25% of the data is for the test and 75% for the training set. The “Radial Basis Function” is used as kernel function to adjusts the Lagrange multiplier upper bound and the radial basis parameters. And the ten fold cross-validation is applied to evaluating all reduction classification accuracy. The results are shown in Fig 1.
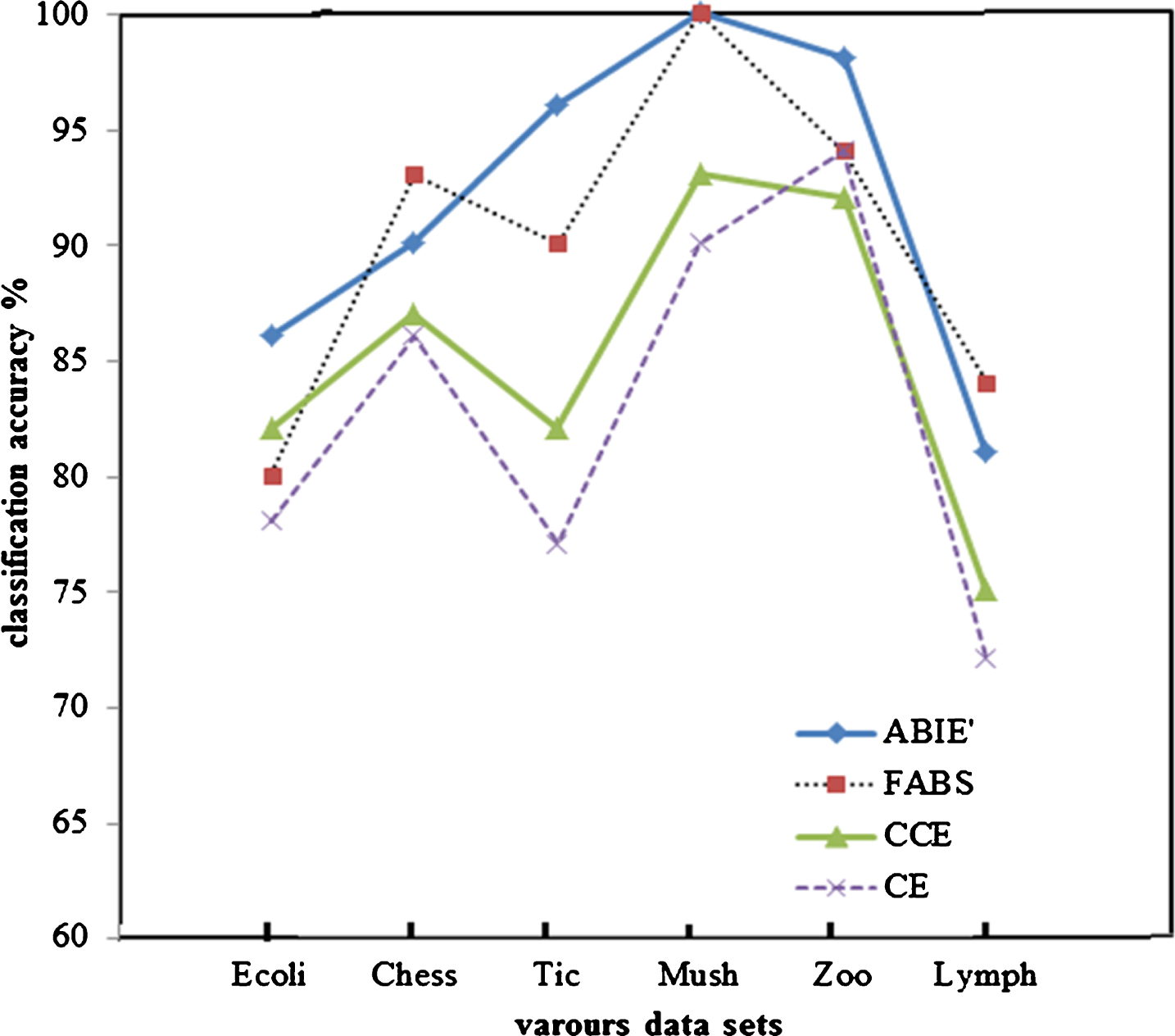
Comparison of classification accuracy.
According to the classification results in Fig.1, the higher classification accuracy of reduction results can be obtained in such data sets as Ecoli, Chess, Tic, Mush, Zoo, and Lymph. The classification accuracy of CE reduction results is not ideal, as it calculates the significance of attribute by considering the information entropy only. The reduction performance of FABS algorithm is relatively stable, but the classification accuracy is lower in most cases, because it only considers the distinguishing ability of positive domain samples in decision table without considering the negative domain samples. Especially, when calculating the importance of attributes using the positive region method, it is often the case where the attribute importance values of multiple condition attributes are the same. Since each calculation of attribute significance is relative, the randomly selected attributes will affect the next attribute selection. By adopting two methods of enlarging entropy of information in this paper and combining with the importance of attributes of approximate boundary accuracy in algebraic view, the subtle differences among samples can be effectively measured. So it shows that the classification effect of the algorithm in this paper has obvious advantage in the subsequent classification work.
(3) In order to study the influence of outliers on the reduction of the algorithm, the Euclidean distance is used to calculate the spatial distance between each sample object, and then the number of outliers is calculated by using Radial criterion. The numbers of outliers in above six data sets are as follows, Ecoli(4), Chess(188), Tic(0), Lymph(5), Zoo(2), Mush(156). If the ratio of the number of outliers to the total samples is defined as rate of outliers, then the rate of outliers of each data set is following, Ecoli(11.9‰), Chess(58.8‰), Tic(0‰), Lymph(33.8‰), Zoo(19.8‰), Mush(19.2‰). Among the above six data sets, the classification accuracy of the algorithm ABIE′ is lower than the algorithm FABS in the data set chess and Lymph. Because the data set Chess or Lymph has a higher the rate of outliers, the classification performance is affected by the rate of outliers. By contrast, the algorithm FABS is less affected by the rate of outlier and its classification accuracy is higher than the ABIE′ algorithm. In order to improve the performance of ABIE′, it is necessary to find out the outliers and minimize the impact before the attribute reduction.
The attribute reduction is one of the cores of Rough Set Theory. Most of the researchers design algorithms of reduction only from the algebraic view or information view. A method to calculate the importance of attribute, which integrates the characteristics of algebraic view and information view, is proposed in this paper, which has higher classification accuracy. In addition, by making the most of results of U/B in the calculation of U/(B ∪ b), the time of calculating equivalent is reduced greatly and system resources are saved.
The next step is to consider how to reduce the computational capacity in the case of maintaining high precision classification to further improve the time performance of algorithm and reduce the time complexity of the algorithm by combining computation with modern multi-core processors.
Footnotes
Acknowledgments
This work is supported by the studying project of visiting home and abroad of Anhui Province of China gxfx2017100, by the natural science foundation of Anhui Province 1308085MF101, by the natural science foundation of Anhui Province, KJZ2013Z231, KJ2016A502.