
Abstract
The airfoil noise problem is highly nonlinear, but its prediction is very important to broadband helicopter rotors, wind turbines, and airframe noise. Thus, this paper presents a novel strategy whereby the minimum-of-maximum relative error support vector machine (RE-SVM) is used to improve the approximation ability of a fuzzy airfoil noise prediction system. In the preliminary design stage, the antecedents of the fuzzy rule base are used to cluster the fuzzy rules. Then, those fuzzy rules with the same antecedent are clustered. Next, in each cluster, the fuzzy rule that has the highest degree of confidence is regarded as the cluster center, which becomes the final fuzzy rule. Finally, the consequents of the fuzzy rules are obtained using RE-SVM models. The prediction of airfoil noise demonstrates that the proposed method has high prediction accuracy.
Keywords
Introduction
In many practical scenarios such as real-world control or signal processing applications, there are many uncertain effects in complex industrial processes [3, 28], such as strong nonlinearity, uncertainty, multiple variables, strong coupling, and frequent change of working conditions [34, 35]. Hence, it is difficult for traditional methods to describe the dynamic characteristics of those processes. Zadeh [18] advanced fuzzy theory in 1965. Since then, fuzzy theory has been gradually improved and applied to these problems because of its good interpretability. Furthermore, fuzzy systems’ universal approximation ability has already been demonstrated in theory [4, 20]. Recently, the Wang–Mendal (WM) algorithm has become an effective way to extract fuzzy rules [21]. Extracting fuzzy rules from samples is the key to building a fuzzy system. Hence, the WM algorithm has been commonly used in this field because it is simple and practical but does not require prior knowledge [34]. Using a look-up table, the WM algorithm discovers fuzzy rules simply and effectively. However, extracting fuzzy rules from samples leads to a high dependency on the samples. The quality and scale of the sample data affects the result heavily [35].
The Takagi–Sugeno (TS) algorithm [27] was first described in 1985. After the generation of fuzzy rules, although each rule is described as a linear function, the whole fuzzy system can solve complex problems [10]. The TS algorithm has been used in numerous practical applications [7, 33] because it can deal with highly nonlinear applications. Zhao et al. [36] applied the TS algorithm with intermittent measurements to detect faults. Wu et al. [19] used the discrete-time TS fuzzy systems to solve time-varying state delay problems. Zhao et al. [23] introduced the stability and stabilization for the uncertain TS approach to approximate time-varying delay.
Support vector machines (SVMs) were first developed by Vapnik and Lerner [31] in 1963. SVMs were developed using statistical learning theory [29, 30] and Vapnik–Chervonenkis (VC) theory [6]. Further, SVMs use a regularization parameter and kernel trick that are suitable for solving highly nonlinear problems with small-scale data [16]. There are many variants of SVMs, such as least-squares SVMs (LS-SVMs) [12, 13], particle swarm optimization for the minimum-of-maximum relative error SVM [16, 37], and ε-intensive SVMs [2].
Inspired by the above studies, we use our previous work in SVM called the minimum-of-maximum relative error SVM (RE-SVM) [16] to propose a fuzzy model identification (FMI) algorithm called the RE-SVM-FMI algorithm. We combine the high interpretability of fuzzy systems and high approximation ability of RE-SVMs to deal with airfoil noise prediction. Namely, with the high prediction accuracy using the proposed algorithm, it is more appropriate to solve the airfoil noise problem.
The rest of the paper is organized as follows. Section 2 presents the related work. In Section 3, the RE-SVM-FMI algorithm is described. The experimental results and analyses for RE-SVM-FMI are given in Section 4. The conclusion is provided in Section 5.
Related work
WM algorithm
In this section, a brief introduction to the WM algorithm is presented. Given an m-input one-output dataset, the extracted IF-THEN rules in the WM algorithm are of the form
The construction of the WM algorithm consists of the following steps: Partition the fuzzy regions. Transform the sample set into an initial fuzzy rule base. Eliminate the conflict fuzzy rules. Generate the final fuzzy rule base. Generate the fuzzy system.
Given m-input one-output training samples
where g (
Briefly, the procedure of the TS algorithm is as follows: Choose the premise variables. Identify the premise parameters. Identify the consequent parameters.
Given m-input one-output training samples
where C is a penalty parameter,
Applying a Lagrangian function, Equation (3) can be written as
The Karush–Kuhn–Tucker (KKT) conditions [1, 9] are then used here to solve Equation (4) by taking the derivative of α
i
, b, e
i
, and
Hence, the parameters are obtained by the matrix solution
where
The optimization problem of LS-SVMs with n training samples
where γ is the penalty parameter, e
i
is the ith sample’s error, φ (
Using a Lagrangian function and the KKT conditions, the following solution is acquired.
where
The subtractive clustering method (SCM) [24] based on data density is a very efficient and effective way to obtain cluster centers. Thus, to reduce the human disturbance [15], the SCM algorithm is used to determine the number fuzzy regions and the variance of the Gaussian membership function of the fuzzy rules. Calculate the density of each data point as follows:
Obtain the data point with the largest density. Subtract the density obtained in last step for every data point.
Repeat Steps 2 and 3 until the following stop condition is reached:
where σ is a predefined constant.
Reasons for using RE-SVM to improve the WM algorithm
The RE-SVM model is suitable for small-scale datasets. Because the fuzzy rules are clustered, the dataset is divided into N clusters, namely, N parts of sub-dataset. Hence, in some clusters, the number of samples is small. Therefore, the use of RE-SVM can improve the accuracy of the WM algorithm. The RE-SVM model is suitable for highly nonlinear applications. Thus, RE-SVM is very useful for improving the approximation ability of the fuzzy system. The RE-SVM model is suitable for high-dimensional applications. In these applications, the fuzzy rule base is obviously not complete. Hence, the RE-SVM model compensates for the lost accuracy caused by the incomplete fuzzy rule base.
Given the high interpretability of the fuzzy system and its high approximation ability, the RE-SVM-FMI algorithm is useful for solving complex practical applications.
RE-SVM-FMI algorithm
Inspired by the WM algorithm in Section 2.1 and the TS algorithm in Section 2.2, the proposed algorithm uses more sophisticated consequents to improve the approximation ability of the fuzzy system. Here, the RE-SVM models are used as the consequents because the fitting ability of the RE-SVM is better than that of a linear function. The IF-THEN rules of the proposed algorithm are represented as follows:
where
The steps of RE-SVM-FMI are given as follows: Determine the number of fuzzy partitions and standard deviations of the Gaussian membership function. To reduce the human interference in the process, the SCM algorithm [24] is used to obtain the parameters for each variable. The Gaussian membership function is
Generate the fuzzy rules from data samples using Equation (1) and calculate the weight of each fuzzy rule using
Determine the degree of confidence for each fuzzy rule as
Determine the clusters for the generated fuzzy rules. Here, the fuzzy rules with the same antecedent are clustered together. In each cluster, the fuzzy rule with the highest doc is regarded as the cluster center, and only cluster centers are retained in the fuzzy rule base. The number of final fuzzy rules is N. Train the RE-SVM model for each cluster using Equation (7). In each cluster, the corresponding samples are used to train the RE-SVM model, and the trained RE-SVM models are used as the consequents of the fuzzy rules. Build the prediction model. To reduce the effect of the fuzzy rules generated from the noise samples and the influence of over-fitting of the RE-SVM model, the output of the fuzzy system is calculated by the weighted average operation because the number of samples for some RE-SVM models is too small to have high generalization ability. The obtained fuzzy system is
A flowchart of the RE-SVM-FMI algorithm is as shown in Fig. 1.

Flowchart of the RE-SVM-FMI algorithm.
The applicable scope and conditions for the proposed algorithm are as follows: Because of the limitations of RE-SVM, the prediction value cannot be zero. Because the number of RE-SVM models is equal to the number of fuzzy rules, the scale of the dataset should not be too large and the dimensions should not be too high, or the efficiency will be low. The proposed algorithm is suitable for nonlinear, uncertain, and strong coupling problems. Some consequents of the fuzzy rules can be over-fitted because the sample used to train the RE-SVM models is too small.
Experiments and analysis
Evaluation index
In this section, the mean absolute error (MAE) and root mean square error (RMSE) are used as evaluation indexes. These indexes are respectively calculated as follows.
In addition, the experimental results are evaluated by leave-one-out cross validation.
The airfoil self-noise data set was obtained from the UCI Airfoil Self-Noise Data Set [26], which includes 1,503 data samples with six input variables (frequency, angle of attack, chord length, free-stream velocity, and suction side displacement thickness), and one output variable (scaled sound pressurelevel).
Table 1 lists some statistical properties of the airfoil self-noise data set: minimum value, maximum value, mean, and standard deviation.
Statistical properties of airfoil self-noise data set
Statistical properties of airfoil self-noise data set
Parameter setting for the WM algorithm
To reduce the human interference in parameter selection for the number of fuzzy regions and the variance in the Gaussian function, the SCM algorithm was used. The size of the cluster in the SCM algorithm was set to 0.1 for all variables [15].
Parameter setting for the FCAWM algorithm
The SCM algorithm was used to determine the number of fuzzy regions and the variance in the Gaussian function. The size of the cluster in the SCM algorithm was set to 0.1 for all variables. The number of cluster was set to 9 in the fuzzy C-means clustering algorithm [14, 15].
Parameter setting for the TS algorithm
The SCM algorithm was used to determine the number of fuzzy regions and the variance in the Gaussian function. The size of the cluster in the SCM algorithm was set to 0.1 for all variables [15].
Parameter setting for LS-SVM
For the parameter setting of LS-SVM [16], the kernel function used here was the RBF kernel. Parameter γ was set to 0.01, 0.1, 1, 10, 100, 1,000, 10,000, and 100,000 successively and parameter σ was set to 0.01, 0.1, 1, 10, 100, 1,000, 10,000, and 100,000, successively. The best of these sixty-four results was chosen.
Parameter setting for RE-SVM-FMI
In the fuzzy rule generation phase, the parameters for the number of fuzzy regions and the variance in the Gaussian function were set using the SCM algorithm. The size of the cluster in the SCM algorithm was set to 0.1 for all variables [15]. In training RE-SVM phase, according to [16], penalty parameter C and variance σ2 should be large in order to obtain better performance. Thus, C was set to 1, 10, 100, 1,000, 10,000, 100,000, 1,000,000, and 10,000,000 successively and σ2 was set to 1, 10, 100, 1,000, 10,000, 100,000, 1,000,000, and 10,000,000, successively. The RBF kernel was used here. The best result was chosen from these sixty-four results.
Experimental results for predicting the airfoil self-noise data set
Table 2 describes the performance of the WM, FCAWM, LS-SVM, and RE-SVM-FMI in terms of MAE and RMSE. Moreover, Fig. 2 presents the target values and predicted values of each comparison algorithm.
Comparisan of the experimental results for the WM algorithm, FCAWM algorithm, TS algorithm, LS-SVM, and RE-SVM-FMI using airfoil self-noise data set
Comparisan of the experimental results for the WM algorithm, FCAWM algorithm, TS algorithm, LS-SVM, and RE-SVM-FMI using airfoil self-noise data set
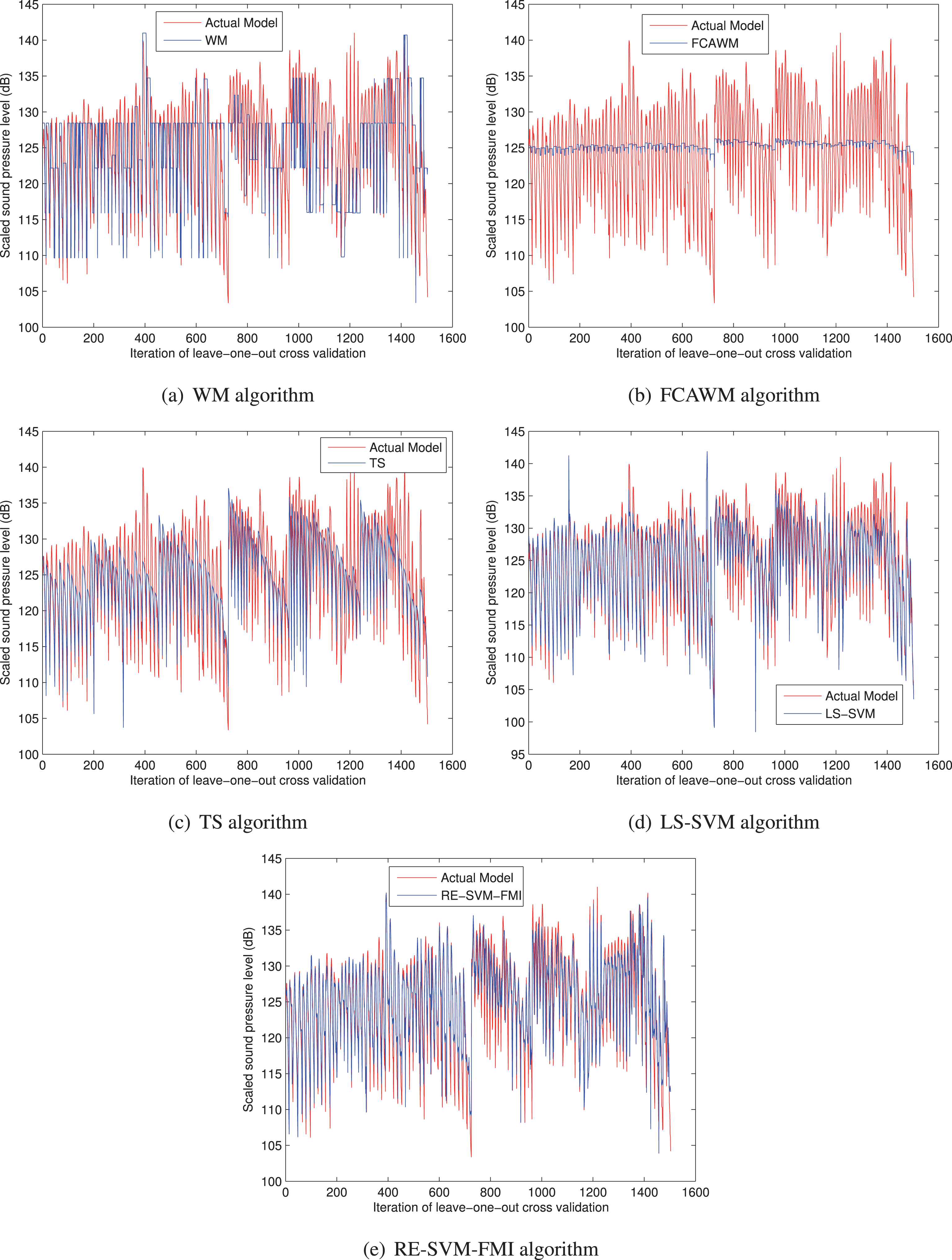
Comparison of the experimental results of the (a) WM algorithm, (b) FCAWM algorithm, (c) TS algorithm, (d) LS-SVM, and (e) RE-SVM-FMI with the actual model.
As shown in Table 2, the performance of RE-SVM-FMI is better than that of the other four algorithms in terms of MAE and RMSE, which demonstrates the effectiveness of the proposed algorithm in practical applications. As the fuzzy rules of the proposed algorithm show, the complex problem is divided into several less-complicated ones. In addition, the RE-SVM model is capable of solving highly nonlinear applications since SVMs are based on the theory of VC dimension and structural risk minimization [32]. Moreover, the weighted average operation is used to reduce the effect of noise data [25] because bad fuzzy rules could be extracted from noise data. Namely, applying weighted average operation could improve the robustness of the fuzzy system [14]. Thus, the performance of the proposed algorithm is greatly improved.
Moreover, Fig. 2 indicates that the approximation ability of RE-SVM-FMI is better than that of the WM, FCAWM, TS, and LS-SVM algorithms. The clustering of the fuzzy rules divides the dataset into groups in terms of the fuzzy rule antecedents, which, to some extent, reduces the complexity of the original problem. The use of the RE-SVM model improves the approximation ability of the proposed algorithm because this model uses more samples to describe each fuzzy rule than the WM, FCAWM and TS algorithms. The experimental results demonstrate that the proposed algorithm is useful and suitable for solving complex engineering problems.
Conclusion
Because the fuzzy rule base plays an important role in constructing fuzzy systems, the generation of each fuzzy rule should be powerful enough to obtain good performance. The approximation ability of the proposed algorithm is better than that of the WM, FCAWM and TS algorithms because the proposed algorithm uses the RE-SVM model as the consequent to enhance the performance of the fuzzy system, while the TS algorithm uses a linear function as the consequent, and the WM and FCAWM algorithms use a single variable as the consequent. For highly complex problems, the fuzzy-rule clustering reduces the complexity of the original problem because it is divided into many sub-problems that are less difficult. Moreover, the novel strategy of using RE-SVMs as the consequents of fuzzy rules could greatly enhance the approximationability.
In future work, a better algorithm and novel strategies to generate fuzzy rules could first be used. Second, different membership functions according to practical applications could be applied. Finally, more up-to-date methods could be tried as consequents of the fuzzy rules to obtain better results in complex applications.
Footnotes
Acknowledgements
This work was supported by National Natural Science Foundation of China under Grant 61572204, and Subsidized Project for Cultivating Postgraduates’ Innovative Ability in Scientific Research of Huaqiao University under Grant 1400414002.