
Abstract
One-class classification is an important problem encountered in a lot of applications. The datasets extracted from the real-world problems are often represented as tensors. The classical support vector domain description (SVDD) for one-class classification problems cannot work directly since its inputs are vectors. This paper develops a linear tensor-based algorithm named as Linear Support Tensor Domain Description (LSTDD) to find a closed hypersphere with the minimal volume in the tensor space which can contain almost entirely of the target samples. LSTDD can keep data topology and make the parameters need to be estimated less, and it is more suitable for learning the high dimensional and small sample size problem. Firstly, we detail the LSTDD model with 2nd-order tensors, and then extend it to the higher order tensors. It has been shown by experiments on the real-world datasets that LSTDD is a promising method for handling one-class classification problems with both 2nd-order and higher order tensor inputs.
Keywords
Introduction
Support tensor machine (STM) [1, 2], proposed by Cai et al. based on the Supervised Tensor Learning (STL) framework [3, 4], has attracted considerable attention. As an extension of support vector machines (SVMs) [5, 6], its inputs are tensors instead of vectors. STM can overcome over-fitting problem that often happens in the traditional SVMs when they deal with the small sample datasets with high dimensionality. In addition, compared with SVMs, STM needs less parameters. For example, SVMs take a vector
With the development of tensor theories, STM has gotten the growing attention in recent years. A lot of tensor-based learning algorithms have been proposed, such as C-STM, ν-STM [4], Twin STM [7], Proximal STM [8], Transductive STM [9, 10], higher rank STM [11], a higher-order STM for classification [12], the hyperplane-based one-class STMs [13–15] and so on.
One-class classification, as an important problem in machine learning and data ming, has wide applications in the areas such as image retrieval, document classification, and fault detection and diagnosis. There are basically three categories of one-class classification solutions: density estimation methods, reconstruction methods, and boundary methods [16]. The effective boundary methods are different from the other two kinds of methods since they find a closed boundary to contain target samples and meanwhile discard outliers without concentrating on the full description of the underlying distribution. Support Vector Domain Description (SVDD) [17] derived from SVM is one of the most classical techniques in this type. It finds the minimum volume enclosing hyperspere to contain almost all the target objects, and has been widely applied [18–25]. Another research topic focuses on the improvement of algorithm [26–29]. All of these algorithms are grounded on vector space and cannot directly take a tensor as input.
It is well known that the original representations of objects are tensors in a lot of applications. It is well known that gray image can be considered as a second order tensor, while color image, grayscale video sequence and gait contour sequence can be considered as third order tensors. Generally speaking, vector-based algorithms learn tensor data by transforming them into vectors. But there are two main disadvantages. The first is that transforming tensors into vectors may result in the loss of data structural information. For instance, the data correlation of the adjacent columns in a matrix may be destroyed when the matrix is converted as a vector. The second is that if a tensor is converted as a high dimensional vector, then a substantial number of training samples are required to overcome the over-fitting problem. However, for some tensor data such as video data stream, it is hard to get plenty of samples.
In this paper, we extend SVDD to the tensor-based model, and present a Linear Support Tensor Domain Description (LSTDD) to find a minimal volume hypersphere in the tensor space to contain target samples. We first detail LSTDD model with 2nd-order tensors, and then generalize it to the higher order tensor space. We present the specific iterative algorithm and analyse its computation complexity. We test LSTDD by experiments on both the 2nd-order tensor datasets and the higher order tensor datasets, which are really high dimensional and small sample size datasets. Experimental results confirm that LSTDD is a promising method for handling one-class classification with tensor inputs.
In the following of the paper, we concisely introduce the tensor algebra involved in the paper, STM, and SVDD in Section 2. Then the new method is described in Section 3. After the detail description of the LSTDD with the 2nd-order tensors, we extend it into the higher order tensor space. The flow chart of specific algorithm arises at the end of this section. The experimental results on real-world datasets including vector datasets and tensor datasets are given in Sections 4 and 5, respectively. Finally, we give the conclusions in Section 6.
Preliminaries
In this section, we briefly review some relevant concepts of tensors, support tensor machine (STM), and support vector domain description (SVDD).
Some basic operations of tensors
Simply, a 1st-order tensor is a vector and a 2nd-order tensor is a matrix. Suppose a q-th order tensor
When
The Frobenius norm of
Suppose the training set
And the corresponding mathematical programming is
Cai et al. [1] presented an iterative method to effectively solve (2-6). Firstly, fix μ and let λ1 = μ 2,
Then one can get μ and ϑ by solving two standard SVMs (2-7) and (2-8) iteratively.
Suppose training data
Then we can get
In this section, we firstly present LSTDD model with 2nd-order tensors, then extend it to the higher order tensor space, and finally give the specific iterative algorithm.
LSTDD with 2nd-order tensors
Suppose the training set
The decision function can be given by the formulation (3-2)
By introducing Lagrange multipliers to optimization problem (3-1), we get the Lagrangian function:
Since
By the Karush-Kuhn-Tucker (KKT) conditions, we have
It can be seen by (3-6) and (3-7) that μ and ϑ are not independent. In the light of the idea proposed by Cai et al. [1], we solve the optimization problem (3-1) iteratively.
Firstly, we fix μ, and denote λ1 = μ 2,
Thus we have
Since the Frobenius norm of a tensor indicates that
It appears that the formulation (3-13) is similar to standard dual problem (2-10) of SVDD. Therefore, we can easily solve it. Solving (3-13) determines the Lagrange multipliers τ
i
*, then we can get
Similarly, let λ2 = ϑ 2 and
And we get a new
Finally, we can get the optimal boundary as follows:
The inputs of LSTDD described above are 2nd-order tensors, namely, matrices. However, we often encounter higher order tensors, for example, color image and gait contour sequence represented as the third order tensors. Therefore, it is necessary to extend the LSTDD into the higher order tensor (>2) algorithm.
Denote
The corresponding decision function is given as follows:
We use the alternating projection algorithm to optimize the variables μ1 ⋯, μ
k
. Firstly, we fix μ2 ⋯, μ
k
, and let λ2 = μ2 2, ⋯, λ
k
= μ
k
2. According to the mode-d product of tensor and vector, we define
Thus, the dual of mathematical programming (3-18) can be derived as follows:
Noticing that (3-20) is a convex quadratic programming, we can easily solve it by the classical optimization algorithms. Once μ1 is obtained, we fix μ1, μ3, ⋯, μ k to calculate μ2. Thus, all the μ i can be calculated in such an iterative way.
Description of 12 vector datasets
Next, we present the general algorithm of LSTDD.
Suppose l training samples with n features, and the computation complexity of SVDD is O (l2n). The computation complexity of LSTDD in the k-th order tensor space is O (l2 (n1 + ⋯ + n k )), where n1 × ⋯ × n k ≈ n. Clearly, compared with SVDD, LSTDD has lower computation complexity. The training time of LSTDD depends upon the iterative number. In the following experiments, we set the maximum iterative number N = 50 and the tolerance θ = 10-4.
Experiment setup
The experiments are performed on 12 publicly available datasets from UCI repository on LIBSVM webpage [30] and David Tax’s homepage [31]. Table 1 gives the description of these datasets. All the features of these datasets were scaled to [-1, 1]. For one-class classification problem, we concentrate on the target classes. Table 1 gives the target classes and the number of target samples. The approach of transforming a vector
As we know, it is difficult to deal with the high dimensional and small sample size classification problems. To test the effectiveness of LSTDD, small training sizes are chosen as in [1, 13]. In one-class classification problems, the training sets are formed by target samples, and the True Positive Rate (TPR) is used as the performance evaluation criterion. We employ 5-fold cross validation to optimize the parameter. The optimal parameter ν are chosen from {0.1, 0.2, 0.3, 0.4, 0.4, 0.6, 0.7, 0.8, 0.9}. For statistical significance, the averaged results over fifty random splits from target class are reported. The implements of all the algorithms are in MATLAB R2011b on a PC, whose system configuration is Intel Core i3 (2.4 GHz) and 6 GB of RAM.
Experiment results and analysis
We compare LSTDD with the standard SVDD on all datasets in Table 1. The training set consists of 10 samples, and Table 2 reports the averaged results. As can be seen, the TPRs of LSTDD have been significantly promoted in comparison with SVDD on all 12 datasets. We calculate the averaged value of TPRs of all 12 datasets, and the results are 0.7403 of LSTDD and 0.6222 of SVDD. Specifically, for COLON, METAS, and LEU datasets, they are the really small sample size data with high dimensionality. And LSTDD obtains the far better TPRs than SVDD. It is shown that although the vector datasets can be directly trained by the vector-based algorithm, if they are trained in the form of tensors, the much better performance can be achieved by the tensor-based algorithm.
Averaged TPRs on various datasets
Averaged TPRs on various datasets
The performance of LSTDD and SVDD with special reference to parameter ν is discussed in this subsection. In the standard SVDD, parameter ν can control the trade-off between the volume and the errors. Noticing that the training sets are pretty small, it is more meaningful to find the regularity corresponding with ν in the tensor space rather than to validate how ν can be used to control the above trade-off.
In particular, there are three datasets in Table 1: COLON, METAS and LEU. As we can see, these three datasets are really high dimensional and small sample size datasets. It makes sense to convert the samples to the higher order tensors. Thus, based on the idea of [1], the third order tensor sizes of the three datasets are selected as 12 × 13 × 13, 17 × 17 × 18, and 19 × 19 × 20, respectively.
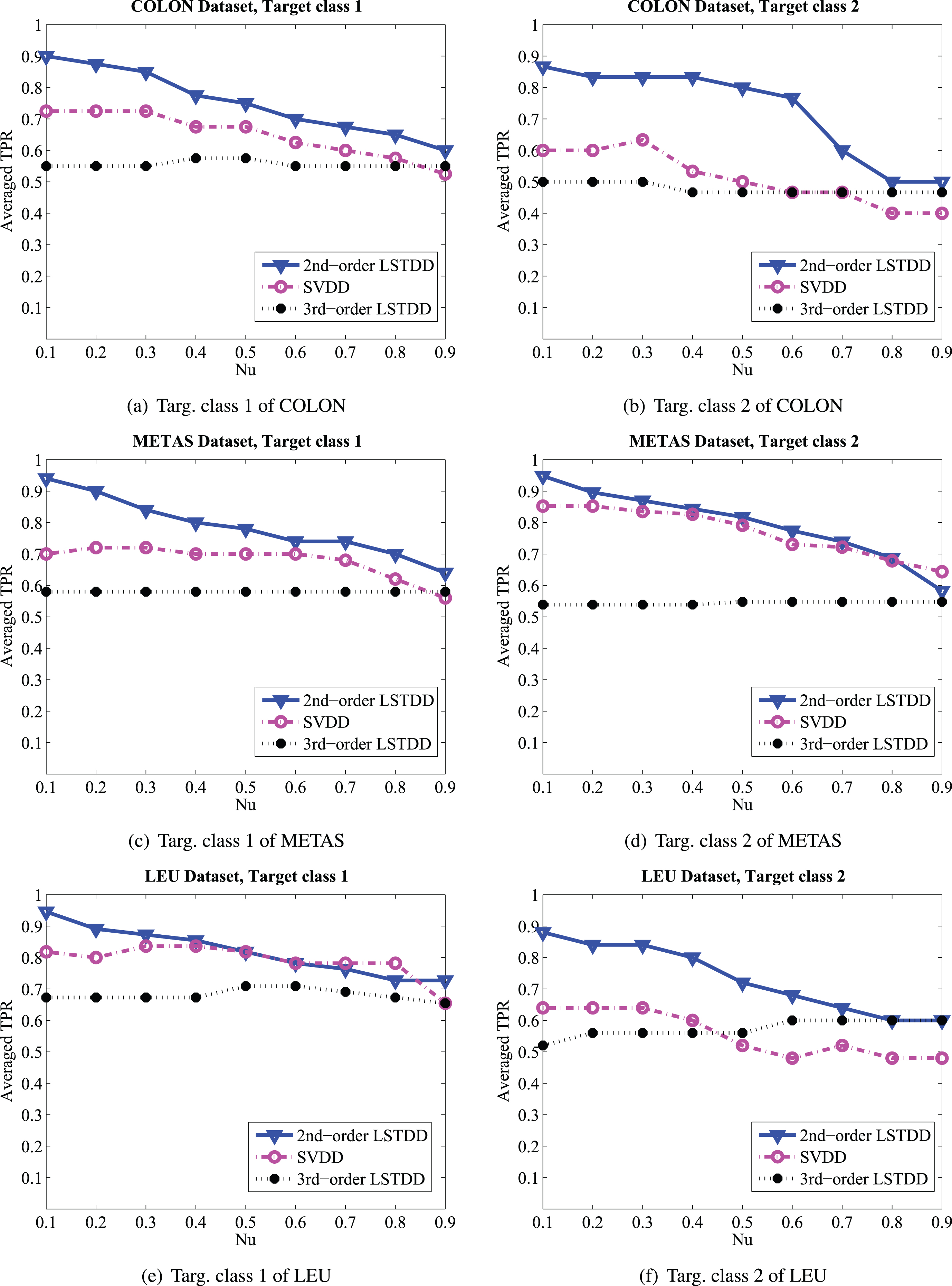
The comparisons of 2nd-order LSTDD, 3rd-order LSTDD and SVDD on averaged TPRs with different values of ν.
We train LSTDD and SVDD with different choices of parameter ν = {0.1, 0.2, ⋯, 0.9}, and evaluate LSTDD with both the 2nd-order tensors and the 3rd-order tensors. We denote them as 2nd-order LSTDD and 3rd-order LSTDD, respectively. To better understand the experimental results, we illustrate the averaged TPRs of the three algorithms for each dataset in Fig. 1. We can see that in all the six target classes, the TPRs of 2nd-order LSTDD are much better than those of SVDD, especially when ν = 0.1. Meanwhile, we can illustrate from Figure 1 that the TPRs of 2nd-order LSTDD and SVDD have significant relevance with parameter ν. The TPRs of 2nd-order LSTDD and SVDD tend to decrease with the increase of parameter ν. Especially for the 2nd-order LSTDD, the tendency of decreasing is more obvious and the best TPR appears when ν = 0.1 in all experiments. We conclude that parameter ν can control the volume of the hypersphere which contains most of target samples in the 2nd-order tensor space.
On the contrary, the TPR of 3rd-order LSTDD has no significant difference with the different values of ν. In addition, it is shown that the performance of 3rd-order LSTDD is worse than that of SVDD and 2nd-order LSTDD. The raise of the tensor order does not make the accuracy of the algorithm improved. As we know, unlike the real tensor-based datasets, there is no structure information retained in the vector-based datasets. Although the vector-based sample can be converted to higher order tensors, 2nd-order tensor is good enough for converting high dimensional and small sample size vector-based datasets to the tensor representation.
Averaged TPRs on 40 target classes in ORL dataset
Averaged TPRs on 15 target classes in YALE dataset
In this section, we focus on real-world tensor datasets: human face datasets and gait silhouette sequence datasets. The human face datasets are the 2nd-order tensor datasets, and gait silhouette sequence datasets are the 3rd-order tensor datasets. The 2nd-order and 3rd-order tensor datasets are the current major datasets for the experiments of tensor-based machine learning algorithms.
Face recognition
There are two 2nd-order tensor datasets we concern about: the ORL [32] and the YALE datasets [33]. The ORL dataset includes 40 individuals’ face images, and each one has 10 different images. Each image is 28 × 23 with 256 grayscale levels per pixel. The YALE dataset includes fifteen persons’ images with eleven size of 100 × 100 images for each one. All the features have been scaled to [0, 1], and we do not carry out cropping or resizing to reduce the feature number of images.
Each person’s face images are considered as a target class. ORL has 40 target classes, and each target class has 10 samples. YALE has 15 target classes, and each target class has 11 samples. We adopt the 5-fold cross validation for optimizing parameters, and report the averaged results. Tables 3 and 4 have summarized the averaged results of TPRs on all target classes of these two datasets, respectively.
As can be seen in Table 3, the TPRs of LSTDD are much better than those of SVDD on the target classes of the ORL dataset. Specifically, the TPRs of LSTDD are better than those of SVDD in 33 out of 40 comparisons, and equal to each other in the rest 7 comparisons. We calculate the averaged TPR of the 40 experiments, and the results are 0.655 of LSTDD and 0.47 of SVDD.
The performance of the LSTDD is also significant on YALE dataset. We can see from Table 4 that the TPRs of LSTDD are better than those of SVDD in 8 out of 15 comparisons, and in 3 out of 15 comparisons they are equal to each other. In the rest 4 comparisons, the TPRs of LSTDD are not as good as those of SVDD. We calculate the averaged TPRs of the 15 experiments, and the results are 0.7778 of LSTDD and 0.7244 of SVDD.
In brief, the tensor-based classifier LSTDD can greatly promote the identification of the target class in comparison with SVDD.
Gait recognition
The aim of gait recognition is to identify people by analyzing the gait patterns extracted from video. In this subsection, we consider three gait recognition datasets: USFGait17_ 32 × 22 × 10, USFGait17_ 64 × 44 × 20, and USFGait17_ 128 × 88 × 20 which are represented as third order tensors. They all come from the USF HumanID Gait Challenge dataset version 1.7 [34].
Averaged TPRs on 3 gait recognition datasets
Averaged TPRs on 3 gait recognition datasets
There are 71 sequences in each dataset, and each sequence from one person who walks in elliptical paths in front of the camera. In our experiments, for simplicity, we randomly choose 10 sequences from each dataset as target classes since there exist too many target classes. Table 5 summarizes the averaged results of 5-fold cross validation on each dataset, respectively. As we can see in Table 5 that the averaged TPRs of LSTDD have been promoted significantly on each considered target class of all the three gait datasets. We calculate the averaged TPR of 10 experiments, the results are 0.6747, 0.6243 and 0.6327 of LSTDD in comparison with 0.3647, 0.3418 and 0.3550 of SVDD in these three datasets, respectively. We conclude that LSTDD outperforms SVDD on the recognition of the target classes.
In this paper, a new data domain description with the tensor input has been proposed, which is termed as Linear Support Tensor Domain Description. We first describe LSTDD based on the second order tensor space, and then extend it into the higher order tensor space. The experiments on both the second order datasets and the higher order tensor datasets show that LSTDD has good generalization capability.
As we know, in a wide spectrum of real world problems, such as handwriting detection, image database retrieval, and face recognition, we often encounter one-class classification problems. The original objects of these fields can be represented as multidimensional arrays, namely tensors. The tensor-based one classification algorithms like LSTDD have potential on the practical applications. In addition, there are some extensions of SVDD, such as Frequency-based SVDD and Write-Related SVDD [35]. Although LSTDD is developed based on SVDD, the idea of constructing the algorithm can provide for reference in establishment of other tensor-based one-class classification algorithms.
However, there is drawback of the proposed method. LSTDD costs more training time due to the iterative manner of solving the optimization problems. Finding the efficient methods to solve the corresponding optimization problem in LSTDD is included in the further research. The proposed LSTDD is a linear algorithm and more research is need to develop the nonlinear algorithm for the higher order tensor.
Footnotes
Acknowledgments
The work is supported by the National Natural Science Foundation of China (Nos. 11171346, 11626186), New Start Academic Research Projects of Beijing Union University No. Zk10201513, and Xi’an Shiyou University Youth Science and Technology Innovation Fund Project No. 2016BS17.