
Abstract
This paper addresses the problem of Face Recognition based on Image Set (FRIS) by kernel learning and proposed an extended kernel discriminant analysis framework for FRIS. By support vector machine learning, an image set from the original input space is mapped into the model space and described with Support Vector Domain Description (SVDD) to handle the underlying non-linearity in data space. In model space, a hyper-sphere encloses most of the mapped data, and the outliers lie outside the hyper-sphere. By exploring an efficient metric for the data domains in model space, we derive a kernel function maps the data from the model space to a high-dimensional feature space, to which many Euclidean algorithms can be generalized. The proposed method is evaluated on face recognition tasks. Comparisons with several state-of-the-art FRIS methods are performed on ChokePoint and CMU MoBo video database. The proposed methods have demonstrated promising performance.
Keywords
Introduction
Recently, Face Recognition based on Image Set (FRIS) attracted increasing attention in the field of pattern recognition [9, 29]. FRIS methods take the entire image collection as a whole to make a global unified model, namely, line subspace, affine hull [4] or manifold [10] etc. Hence, they can fully utilize the information provided by multiple images to obtain better recognition accuracy.
Modelling image sets by linear subspaces has been shown to deliver improved performance in the presence of practical issues such as misalignment as well as variations in pose and illumination [9]. A convenient way of dealing with subspace is to represent them as points on Riemannian manifolds [9–11, 24]. However, classifiers based on discriminative approaches are not directly applicable to features that lie on Riemannian manifolds. Hence, classification is often performed in an extrinsic manner by first mapping the manifold to an Euclidean space using kernels, and then learning classifiers in the new space [19]. One such popularly approach mappings the manifold to a reproducing kernel Hilbert space (RKHS) by kernels.
The key technology of FRIS include obtaining a suitable data description model to represent an image set and measuring the similarity between pairwise models. Generally, a subspace, Gaussian Mixture Model, or covariance matrix may be a suitable model. As discussed in a previous work [31], by mapping the data points from the input data space to a high dimensional feature space, Support Vector Domain Description (SVDD) [18] finds a smallest sphere enclosing most of the mapped data points in the feature space. However, SVDD is mainly utilized to describe the data set, and it emphasizes on data description ability without considering the discriminant ability.
In general, the success of kernel-based methods is often determined by the choice of kernel [19]. Hence, we address the issue of kernel learning from an image set and propose a kernel based learning framework for face recognition. With support vector machine learning, image set is mapped into high dimension model space, and a new representation model is established. To obtain a better separability between hyper-spheres, we define a novel kernel based on the distance between two domains to map samples into a feature space. Through this kernel function, a measure in the domain space is converted into distance metric in Euclidean space, and the kernel matrix is computed based on a similarity measure and embedded into the graph embedding discriminant analysis framework to enhance the classification performance.
The major contributions of the paper are as follow:
Kernel learning in feature space is discussed and a new kernel based on SVDD is proposed. By mapping the data points from the input data space to a high dimensional model space, it finds the minimal sphere enclosing most of the mapped data points in the model space, and it can generate an arbitrary shape of class boundary, and gives rise to an enhanced classification performance. Classifiers based on discriminative approaches are not directly applicable to features that lie on model space. After mapping the model to an feature space using kernels, a graph embedding discriminant analysis framework is used to unify different discriminant analysis methods in the feature space.
The remainder of this paper is organized as follows. Section 2 briefly reviews some kernel function on the Grassmann and Riemannian manifold. Section 3 introduces how to model an image set with SVDD, and a new kernel based on SVDD is discussed. Section 4.1 introduced the graph embedding discriminant analysis for FRIS. Section 4.2 integrated Section 2, 3 and 4.1 into a kernel based learning framework for FRIS tasks. Section 5 reports the experimental results on two video based face databases. In this section, we compare the computational complexity of different methods and report the time cost for each method. Section 6 concludes this paper.
Image set modeling and kernel learning
Let
In
A differentiable manifold
For
SVDD is a sphere shaped data description originally proposed for outlier detection. By mapping the data point from the input data space to a high dimensional feature space, it finds the smallest sphere enclosing most of the mapped data points in the feature space. SVDD is mainly used to describe the data set, and it emphasis on data description ability, without considering the discriminant ability.
In this paper, we discuss the face recognition problem from image set by kernel learning approach. Firstly, by support vector machine learning, image set are mapped into high dimension model space, and a new representation model is established, in which most positive samples are enclosed by a sphere of radius R. Then in the model space, we define a new measurement method to characterize the similarity between the two spheres. To obtain a better separability between hyper-spheres, based on this metric function, we derive a SVDD based kernel function on the data domain. Through this kernel function, a measure of the domain space is converted into distance metric in Euclidean space, and the kernel matrix is computed based on a similarity measure and embedded into the graph embedding discriminant analysis framework to achieve the purposes of classification. Since the definition of the kernel matrix is not a semi-positive definite kernel, this paper further discusses how to convert the general function to a semi-positive definite kernel function.
Support vector domain description
Let X = [x1, x2, . . ., x
N
] be a data matrix of an image set with N samples, where x
i
∈
According to the values of Lagrange multipliers β i (i = 1, . . . , N), the data points in the input space are classified into three types: (1) Inner points (IPs): β i = 0, the data points locate inside the sphere. (2) Support vectors (SVs): 0 < β i < J, the data points locate on the surface of the sphere, which can be used to describe the cluster contour in the original data space. (3) Bounded support vectors (BSVs): β i = J, the data points locate outside the feature space, it is also defined as the external points.
Note that if constant J ≥ 1, no external points will exist. Hence the value of J can be used to control the existence external points.
In this study, the Gaussian kernel
1
with width parameter q is adopted. The Gaussian kernel function is defined as κ (x
i
, x
j
) = exp(- q||x
i
- x
j
||2), where φ (x
i
) is the mapped image of x
i
in high dimension feature space, and q is the Gaussian kernel width parameter. The trained Gaussian kernel support function, which is defined by the squared radial distance of the image of x from the sphere center μ, is given by
Let X = [x1, x2, . . . , x
N
] be a data matrix of an image set with N samples, where x
i
∈
Let SV and BSV denote the collection of all support vectors and bounded support vectors respectively. The SVDD of this set is defined as follows,
Let domain
Let
It is easy to check that k
dd
is a symmetric real-valued function, i.e., κ
dd
(
The spectral flip transformation (SFT) flips the sign of negative eigenvalues of a symmetric matrix K to form a positive semidefinite kernel matrix
The flip method can be explained from the perspective of singular value decomposition (SVD) [27]. Given a symmetric matrix K, the spectral decomposition is K = U T ΛU, and the singular value decomposition is K = Udiag (σ1, . . . , σ N ) V T , where U T U = I and V T V = I.
The matrix U in SVD of K is the same in spectral decomposition of K = U
T
ΛU. In the other hand, from spectral decomposition of K, K = U
T
ΛU, we have KK
T
= UΛU
T
UΛU
T
= UΛ2U
T
, where
Consider a test sample X
t
that is the same as a training sample X
i
from input space. Then if one uses a classifier trained with modified kernel
Graph embedding discriminant analysis for image set
Graph embedding discriminant analysis
A graph G = (V, W) represents a set of vertices V, and a set of edges that connect pairs of vertices, where W = [W (i, j)] N×N is the adjacent matrix represent the similarity between pairs of vertices. The corresponding diagonal matrix D and the Laplacian matrix L of a graph are defined as,
Given N points
Combination the two non-linear function as one description as follows,
Now, we obtain N models
Let α
l
= (a1l, a2l, . . . , a
Nl
)
T
, and K
i
= (κ1i, . . . , κ
Ni
)
T
. Generally, the kernel function in the model space can be defined by inner product as follows,
According to the representer theorem [17], the solution can be expressed as a linear combination of data points, i.e.
The Equation (18) can be simplified to:
The optimal A
opt
are given by the largest eigenvectors of the eigen-problem: KWK
T
A = λKDK
T
A. Grouping the maximum r eigenvectors α
i
, (i = 1, 2, . . . , r) corresponding to the maximum r eigenvalue, we obtain A
opt
= [α1, α2, . . . , α
r
]. Given a test image set X
t
∈
For the convenience of description, the graph embedding framework is denoted as KGE (W, D). By choosing different W and D, the Kernel Fisher Discriminant (KFD) analysis, Kernel Locality Preserving Projection (KLPP) and Kernel Margin Fisher Analysis (KMFA) can be embedded into this framework.
Kernel Fisher’s Discriminant Analysis (KFD) is equivalent to KGE (W, I), where I is an identity matrix. KFD can be solved the eigen-value problem, KWK
T
A = λKK
T
A, where graph W is defined as,
The purpose of locality preserving projections is to minimize an objective function that incurs a heavy penalty if neighbouring points in the original space are mapped far apart in the transformed space [12]. KLPP is equivalent to KGE (W, D), which can be solved through a generalised eigenvalue problem KWK
T
A = λKDK
T
A. The local geometrical structure of
Let N
w
(X
i
) be the KNN of X
i
sharing the same label as l
i
, within-class similarity graph W
w
is defined as,
Let N
b
(X
i
) be the KNN of X
i
, having different labels l
j
(j ≠ i), between-class similarity graph W
b
is defined as,
Our aim is to maximize the discriminatory power while simultaneously preserve the geometry structure, by mapping the points on model space
Add the following normalising constraint tr (A
T
KD
w
K
T
A) =1 to the problem. This constraint enables us to convert the minimisation problem in to a maximisation one as follows:
The maximisation problem of Equation (29) can be simplified as:
Combined the two maximisation problem into one maximisation problem as following,
KMFA is equivalent to KGE (L b + βW w , D w ). It should note that the Grassmann Graph embedding Discriminant Analysis (GGDA)[10, 11] and KMFA [30] are equivalent in nature.
If we define W
w
and W
b
as follows,
Then Grassmann Discriminant Analysis (GDA) [9] is a special case of GGDA [10, 11].
In computer vision applications, the multi-view facial images are non-linearly distributed [6]. The popular learning algorithms such as discriminant analysis and support vector machines, etc., are not directly applicable to such features due to the non-Euclidean nature of the underlying spaces [19]. To overcome this limitation, each image set is mapped into a high-dimensional feature space [6, 14], e.g. a high dimensional Reproducing Kernel Hilbert Space (RKHS), using a nonlinear mapping function, to which many Euclidean algorithms can be generalized [14]. In The workflow of proposed FRIS system. The left dashed Box is the learning procedure, and the right is the testing procedure.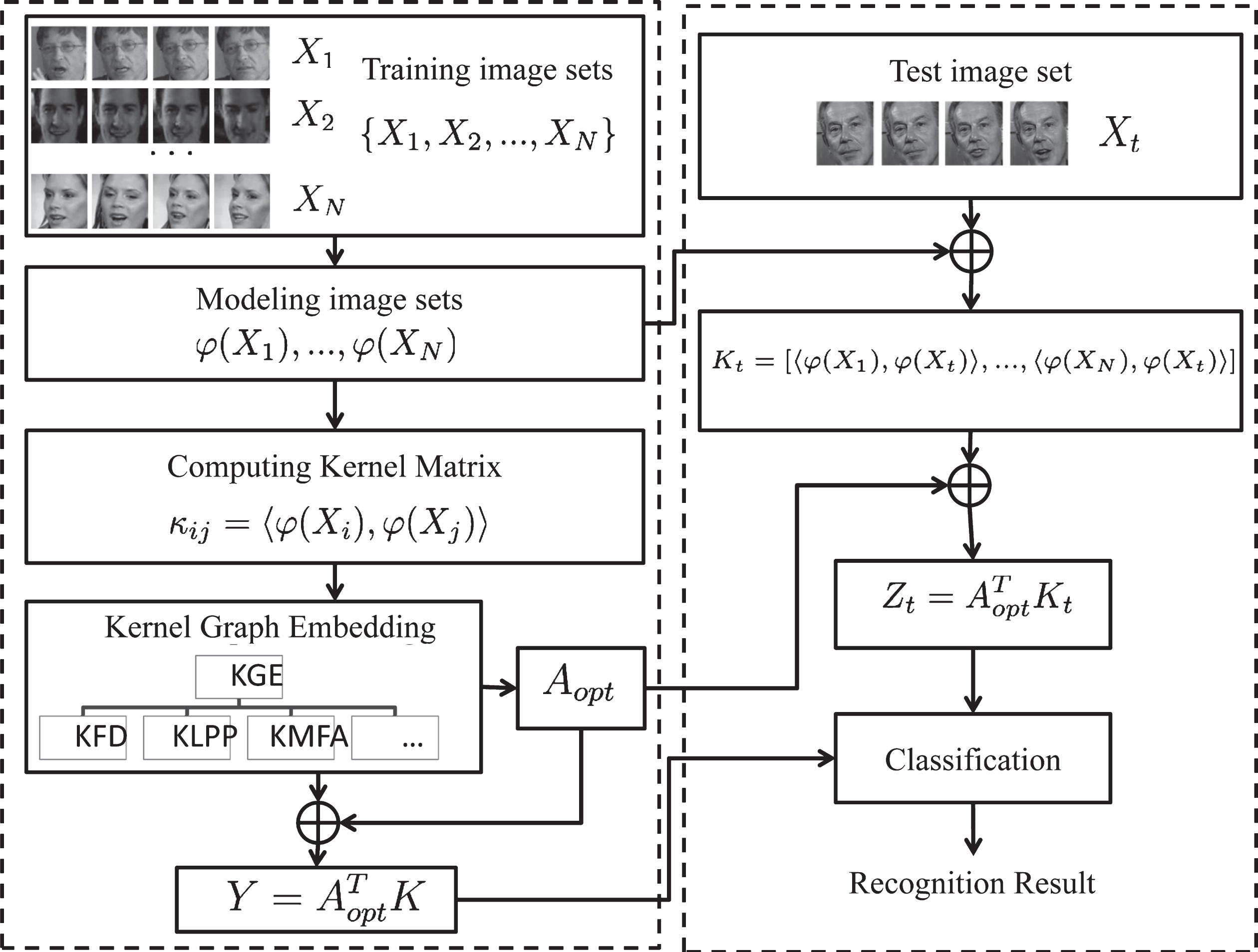
Algorithm 1 summarizes the main scheme of the proposed kernel learning framework for image set-based classification. Given a training set
By exploring an efficient metric for the data in the model space, a kernel function is used to map each model to a high-dimensional feature space
A kernel learning framework for FRIS
In the proposed kernel learning framework, a few things to note are: (1) We need to learn a suitable nonlinear function φ to map the image set from the input space to model space
The proposed approach was compared and contrasted to previous state-of-the-art methods on two public video based face databases: ChokePoint [26] and CMU MoBo [8] in order to ensure an extensive evaluation of different methods against databases changes including images resolutions, facial expressions and illumination variations. In the following sections, we will first briefly overview the databases used in the experiments, followed by a description and discussion of the experiments.
Experimental settings
The first dataset, ChokePoint, is a video data set for the purposed of academic study in video-based face matching. The data set consists of 25 subjects (19 male and 6 female) in portal 1 and 29 subjects (23 male and 6 female) in portal 2. The recording of portal 1 and portal 2 is one month apart. In total, the data set consists of 54 video sequences and 64204 labeled face images. In all sequences, only one subject is presented in the image at a time.
In this paper, we use videos from camera 1 and camera 2 at entering portal 1. There are 8 videos for each person, in these experiments, we randomly partition 8 videos into two sets of four videos for train and the rest for testing. The experiments are repeated 5 times. Histogram equalization is employed to eliminate the lighting effects, and all images are resized to 32 × 32 pixels to reduce the computation time in our experiments.
Comparative methods and settings
We compared the proposed SVDD based kernel combining different discriminant analysis method in this paper with several image set classification methods lately proposed in the literatures. They included Mutual Subspace Method (MSM) [29], Manifold-Manifold Distance (MMD) [24], Sparse Approximated Nearest Points between image sets (SANP) [13], Affine Hull based Image Set Distance (AHISD) [4], Grassmann discriminant analysis (GDA) [9], Graph embedding discriminant analysis on Grassmann manifolds (GGDA) [10], Covariance discriminative learning (CDL) [23], and Multi-local model image set matching based on domain description [31]. The standard implementations of all methods from the original authors were used. To allow comparison with the literature we followed the simple protocol of [24]: the detected face images were histogram equalized but no further preprocessing such as alignment or background removal was performed on them, and the image features were simple pixel (gray level) values for ChokePoint, and Local Binary Pattern (LBP) [1, 2] feature for CMU MoBo.
Note that for comparison we have chosen the GDA [9] as the top performing method in the comparative experiment of [9], where GDA has been compared with DCC [15], MSM [29]. Nearest neighbor (NN) classifier was used for all methods.
Identification results and analysis
Average recognition result and standard deviation in ChokePoint database with SVDD kernel (SVDD), projection kernel (Proj), canonical correlation kernel(CC) and logarithms kernel (LOG)
Average recognition result and standard deviation in ChokePoint database with SVDD kernel (SVDD), projection kernel (Proj), canonical correlation kernel(CC) and logarithms kernel (LOG)
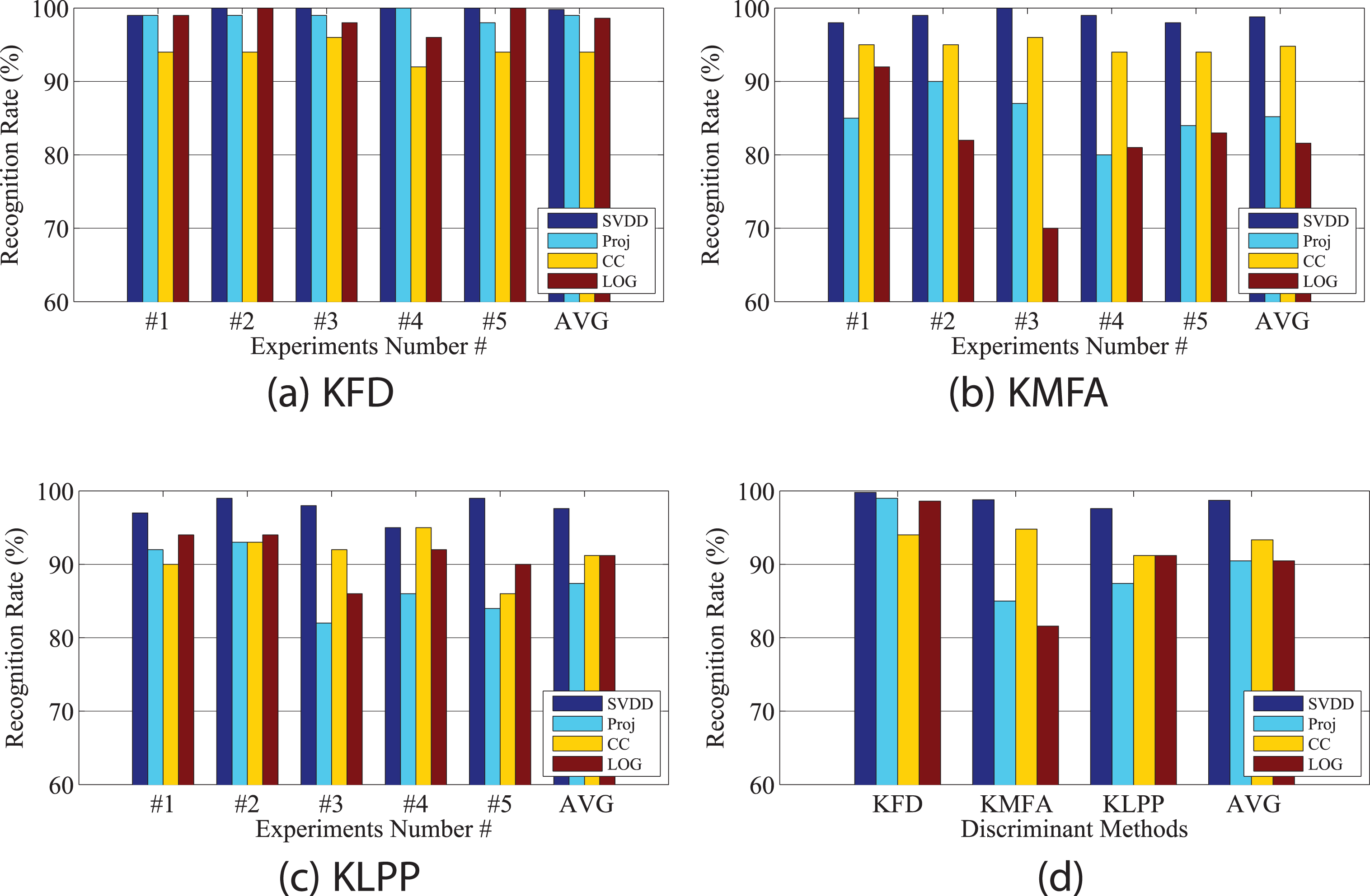
Average recognition result with projection kernel (Proj), canonical correlation kernel(CC), logarithms kernel (LOG) and SVDD kernel (SVDD) on ChokePoint database. In (a-c), the last column is the average recognition rate of 5 experiments, and in (d), the last column show the average recognition rate wile choose different discriminant method. (a) KFD,(b) KMFA,(c) KLPP,(d) different algorithms with different kernels.
As shown in Table 1, the proposed framework using SVDD kernel with KFD discriminant analysis method obtains the best performance, and SVDD kernel obtains the best performance than other kernel function for all discriminant analysis method. From Table 1 and Figure 2(a-c), the recognition rate of KFD is relatively stable with different kernels than KMFA and KLPP. As shown in 2(c), when KLPP is used, the projection kernel obtains the worst performance. Figure 2(d) indicates that SVDD obtains slightly better performance than other methods. In this experiment, the proposed methods have demonstrated promising performance. The proposed method with SVDD kernel in feature space has shown the best recognition rate among all the methods compared.
The Recognition rate(RR), standard deviation(STD), kernel type, discriminant analysis method (DA) in the proposed framework and image set model on ChokePoint dataset
Face recognition rates (RR) standard deviation (STD) (%), average computation time (seconds) on the ChokePoint and CMU MoBo dataset
We also compare with our previous study [31], and the result show that performance of the proposed method in this paper beyond the previous study. All in a word, the proposed method can solve the set based face recognition problem efficiently.
The success of kernel-based methods is often determined by the choice of kernel. This paper addressed the issue of kernel learning for the image set-based classification tasks, and use SVDD to model the image set. After modeling the image set, we define a new kernel based on the distance between two support vector domains to map the domains to an Euclidean space. In this paper, the classic kernel based FRIS methods in recent years are consolidated into a unified framework, and FDA, LPP and MFA are integrated into this framework, which will improve the discriminant ability in feature space. The proposed methods are tested on face recognition task, and the comparisons with several state-of-the-art methods are performed. For the two databases, ChokePoint and CMU MoBo, the proposed methods have demonstrated promising performance.
Footnotes
Acknowledgments
This work is partially supported by the Funds for University Innovation and Entrepreneurship Education of Guangzhou City(No. 2019PT204), the Special Funds for Welfare Research and Capacity Building Project of Guangdong Province (No. 2015A030402003), and the Funds for Science and Technology Project of Guangdong Province(No.2017ZC0117).
Any kernel, e.g. Polynomial kernel, Sigmoid kernel or Gaussian kernel, works here, however, as discussed in [3, ![]() ], Gaussian kernels can provide more tight contour representations, and are used in most SVDD-based approaches.
], Gaussian kernels can provide more tight contour representations, and are used in most SVDD-based approaches.