
Abstract
Query completion approaches assist searchers in formulating queries with few keystrokes when using an information retrieval system to address their information needs, which help users benefit from avoiding spelling mistakes and from producing clear query formulations, etc. Previous work on query completion algorithms returns a ranked list of queries to the users mostly based on the overall observed search popularity of query candidates in the whole query logs. However, the query search popularity could be changed over time, i.e., it’s time-aware. Thus, these ranking approaches based on the overall search popularity could not work very well and users may fail to find an acceptable query in the returned list, resulting in a limited search satisfaction. Hence, this paper proposes a Learning-based Personalized Query Ranking approach, i.e., LQR, where the features on the observed and predicted search popularity both in the whole logs and the recent period are exploited. Taking a pair-wise learning scenario, this paper presents a method for generating a ranked list of query candidates, and then reranks the candidates by the similarity to current search context. The experimental results show the proposed approach outperforms the baseline in terms of Mean Reciprocal Rank (MRR), reporting an average MRR improvement of 7% against the baseline.
Introduction
Query completion is one of the most significant features provided by common information retrieval systems. It also can be embedded into other search systems such as image retrieval system [1, 2]. As shown in Fig. 1, after typing the prefix “Nepal” in the search box, the search system will automatically provide several query candidates to help you finish formulating your query. The goal of query completion service provided by the search systems is to accurately predict the user’s intended query with only few keystrokes (i.e., typed prefix or a string). By doing so, it helps the user formulate a satisfactory query with less effort and avoid misspelling it as well. It has been shown in Web search applications that query completion is heavily used by searchers and highly influential on search results accuracy when it’s offered [3].

Google query completions of typed prefix “Nepal”. The snapshot was taken on Saturday, May 2, 2015.
Currently, a common and straightforward approach used in previous work on query completion ranking task is to extract the matching queries to the prefix from the query logs, and rank them by their popularity [4–6], which assumes that the current or future popularity of queries will remain the same as previously observed. Although this approach results in good query ranking performance on average, it fails to take strong clues from time, or named search popularity trend, into consideration while such information often influences the queries most likely to be typed. As shown in Fig. 2, these two queries “Nepal” and “Nepal earthquake” are absolutely unpopular before April 2015. However, after the date of April 22, 2015, we can see there is a sharp jump from a low level to a completely high degree, that’s because of an earthquake in Nepal recently. Hence, the query ranking approach solely based on the overall search popularity can not work well for such cases.

Relative query popularity for different queries over time. Query “Nepal” in blue and query “Nepal earthquake” in red. Both queries present a sharp increase from a relatively low level after April 22, 2015. The snapshot was taken on Saturday, May 2, 2015.
In addition, queries issued in the same session often express similar search intents, which could affect the ranking of query candidates for a query completion task. To deal with it, this paper proposes a Learning-based personalized Query Ranking approach, namely LQR, which takes the observed and predicted search popularity in a recent period into consideration as well as the overall popularity in the whole query logs. Moreover, the search intent expressed by previous in session is also taken into account in our model by considering the similarity between queries. Eventually, our proposal can beat the baseline in terms of Mean Reciprocal Rank (MRR) with 7% improvement.
The goal of this paper is that we provide an alternative approach for query completion, which is helpful to search engine designers to improve the satisfaction of web search users. Our contributions in this paper can be summarized as: We propose a Learning-based Personalized Query Ranking approach (LQR), incorporating popularity related features for learning and user’s search history for personalization, which is verified to improve the accuracy of query completion. We analyze the effectiveness of our LQR model and find that it significantly outperforms the state-of-the-art baselines for query completion in terms of Mean Reciprocal Rank (MRR), reporting an MRR improvement of around 7% against a time-sensitive query completion approach.
Next, we briefly summarize the related work on query completion in Section 2, which is followed by a Section 3 of introducing our approach, i.e., learning-based personalized query ranking approach. Section 4 details the experimental setups and Section 5 discusses the results generated by our proposal and compared with those of the baseline. We conclude our findings and point out possible future research directions in Section 6.
Query completion [5, 7–10], a well-known feature of today’s search systems, relies on the query logs to generate query candidates and is among the first services that users interact with a search system as they formulate their queries [11]. In a common query ranking scenario, the most simple approach to rank query candidates is to use Maximum Likelihood Estimation (MLE) approach based on the collected popularity of queries [4], i.e., frequency. It refers to this type of query ranking as the Most Popular Completion (MPC) model as Equation (1):
In essence, the MPC model assumes that the current query popularity distribution will keep the same as what was previously observed, and hence query completions are ranked by their past popularity in order to maximize the effectiveness for all users on average. However, query popularity may change over time, and accordingly, query candidates must be adjusted to account for time-sensitivity. As a consequence, the ranking of query completions should be time-dependent (see Fig. 2). These points have been studied recently in the fields of information retrieval. Next, we summarize some recent query completion approaches from two aspects: search popularity based query completion and search context similarity based query completion.
The basic query ranking approach works well based on the overall search popularity. However, the temporal information, e.g., recency, has not been taken into account in the original ranking model while the query popularity is changing over time. Rather than ranking query candidates by their previously overall popularity, researchers proposed a time series analysis based modeling approach to forecast the query frequency by applying a fixed moving time window [5]. Queries recurring during specific temporal intervals, such as day/night, workday/weekend, summer/winter, etc. are modeled differently to predict the future popularity for query ranking at different time. The forecasts obtained by such models are substantially more reliable, by which good query ranking can be generated. However, a detailed analysis of the performance impact of the time window period selection is lacking.
Moreover, the time information, such as recency, has been studied [12–14] and the seasonality has also been considered [5, 15] for ranking query candidates. These approaches employ time-series analysis techniques to forecast query’s future popularity [5, 15]. In addition, a popularity-based query ranking approach can be combined with other criteria. The hybrid model assigns a final score to each candidate by linearly combining the popularity score and another metric score, e.g., context similarity score. All these discussed models use the search popularity in a straightforward way, ignoring the latent contributions from recent search popularity or the trend. Our proposal will conduct a deep investigation on the impact of search popularity to query ranking performance.
Search context based query completion
In most work mentioned so far, query candidates are computed globally, and for a given prefix, all users are presented with the same list of candidates. However, different users have various search intents. Hence, exploiting user’s personal search context has led to increase the query ranking effectiveness [4, 16–18].
Typically, the user’s recent queries are used as context to find users with shared search activity [4, 19], considering the similarity of query candidates to this context for ranking. Their hybrid model computes a final score of each candidate by linearly combining the MPC score and a context-similarity score. Similarly, the click graph is used [11, 20] to measure the similarity between search context and query candidates, by which the query ranking list can be generated. Moreover, user interactions can play a prominent role in models for ranking queries [3, 21]. In addition, exploiting the context to learn user reformulation behavior is well proposed [21], where a supervised approach for ranking query completions based on term-, query- and session-level features of user reformulation behavior was proposed. These features can capture how users change their queries during search sessions and these interesting findings provide valuable insights for understanding user’s engagement in search systems.
In this paper, we argue that injecting recent search popularity features, from observations and predictions, into a learning to rank framework to query completion tasks will boost the ranking performance. In addition, our personalized query ranking based on semantic query similarity will help generate better ranking of queries.
Approach
In this section, we first describe the search popularity features, then introduce the learning algorithm for query ranking, and finally generate a personalized query ranking by incorporating the query similarity to search context.
Search popularity based features
We propose a learning-based query ranking method, i.e., LQR, that ranks query candidates by both observed and predicted query popularity (i.e., frequency) based on its recent trend. LQR not only inherits the merits of time-series analysis on short-term observations of query popularity, but also considers the overall query counts. Generally, we collect the observed query popularity in the whole query log as well as in recent m day(s), and denote the corresponding features as: fo+w and fo+m, where the former relates to the popularity in the whole query logs and the latter is collected only in the recent m days.
In addition, we predict a query q’s future popularity based on its recent preceding observations. The search popularity prediction
We indicate the features based on the predicted search popularity with fp+n, where n denotes the day from which the prediction is generated.
The problem of learning-based query completion ranking can be formalized as follows. For a prefix p typed by a user and a query candidate set Q consisting of N queries to be ranked, i.e., q1, q2, ⋯ , q
N
, the optimal ranking approach should return a ranked query list L
r
that orders the queries in Q according to a score (or relevance), where the queries can be represented as vectors, e.g., q
i
← {fi1, fi2, ⋯ , f
iu
}, where u is the number of features. Hence, the query ranking approach tries to assign a score s (p, q) to each query candidate q in the set Q using a ranking function as Equation (3):
Typically, the ranking systems can not achieve an optimal ranked list
We are now in a position to define the problem of learning a query ranking function. For a fixed but unknown distribution
However, it has been shown that this problem is NP-hard [22]. Instead, it is possible to approximate the solution by introducing a non-negative variable ξi,j,k and minimizing the upper bound ∑ξi,j,k. Hence, it leads to the following optimization objective in Equation (6):
As queries in the same session always express similar search intents [25], we personalize query completion according to the query similarity to the current search context in session, i.e., the previous queries in session.
We introduce a hybrid model to incorporate the scores of the similarity and the ranking generated by the learning process in §3.2. First, the learning process produces a ranking of query candidates S (p) of prefix p, where each candidate q
c
∈ S (p) is associated with a ranking score LeaScore (q
c
). Then we calculate the similarity score SimScore (q
c
) for q
c
to the previous queries Q
S
in session by the scheme in Equation (8)
Like this work [4], we then define our hybrid model as a combination of two scores in Equation (10):
As LeaScore (q
c
) and SimScore (q
c
) use different units and scales, they need to be standardized before being combined. We standardize LeaScore (q
c
) as follows in Equation (11):
1:
2: Extract the popularity features q i ← {fi1, fi2, ⋯ , f iu };
3: Compute LeaScore (q
c
) using
4: Compute SimScore (q c ) according to Eq. (8);
5: Compute HybScore (q c ) according to Eq. (10);
6:
7: Rerank query q ∈ L based on the hybrid scores to generate L′;
8:
Below, §4.1 describes the datasets and lists some interesting observations; §4.2 provides details about our evaluation metric and baseline; we detail our settings and parameters in §4.3.
Dataset
We use the query log dataset collected from a commercial search engine. It’s sampled between March 1, 2006 and May 31, 2006. In total there are 16,946,938 queries submitted by 657,426 unique users and we partitioned the data into two parts: a training set consisting of 75% of the query log in terms of time period, and a test set consisting of the remaining 25%. Traditional k-fold cross-validation is not applicable to streaming sequence since it would disorder the temporal data [27]. Moreover, we filtered out a large volume of navigational queries containing URL substrings (.com,.net,.org, http,.edu, www.) from the dataset and removed queries starting with special characters such as &, $ and # from both datasets.
Additionally, only queries appearing in both partitions were kept in order to extract the popularity features. A cross-validation based approach cannot be applied in our setting because it will disorder the sequence of queries, resulting in incorrect time-aware query popularity. Table 1 details the statistics of the dataset. One of the most interesting findings from the data is that the phenomenon typified by a number of repeated queries from each user can be seen in both the training and testing phase.
Statistics of the processed dataset. Queries: Qs, Users: Us
Statistics of the processed dataset. Queries: Qs, Users: Us
One baseline used for comparisons with our method was proposed in 2011 [4], namely, the most popular completion method, which sorts the queries by their popularity based on the whole log, referred as MPC in this paper. In addition, we use another baseline for comparison, i.e., MPC-R [12], which ranks query candidates by the popularity collected in recent R days of query logs, where we set R = 7 in our experiments [12].
To evaluate the quality of query rankings, Mean Reciprocal Rank (MRR) is selected as a standard measure. Given a query q with prefix p in the query set Q associated with a list of query candidates S (p) for this prefix p, and the user’s finally completed query q, Reciprocal Rank (RR) is computed as Equation (13):
Then MRR is computed as the mean of RR for all prefixes.
In our learning-based query ranking approach experiments, we are first given a list of top N QAC candidates returned by MPC; we set N = 10 as this is commonly used [4, 11–13] and used by many web search systems. In addition, the cases where the final submitted query is not included in the original list of N candidates by MPC are removed from the dataset, to guarantee the ground truth is returned.
We use the LambdaMART [24] learning algorithm for ranking QAC candidates across all experiments. For the observed query popularity, we set m ∈ {1, 2, 4, 7, 14, 28}, which was often used [12] for the same task and reported a good result. These options are also used for predicting the future popularity. Therefore, we can generate totally 15 popularity features for each query, i.e., 7 features from observations in recent m day(s), 7 features from predictions based on recent m day(s), and 1 feature from observation in the whole query logs. We set the tradeoff γ = 0.5 in (10) to balance the contribution of learning-based ranking and of query similarity. In addition, we compare the models at various lengths of prefix in character, ranging from 1 to 5 characters.
Results and discussions
In section, we will examine the effectiveness of our proposed model, compared to the baseline. Additionally, we zoom in on the feature importance to find the ranking of features used in our model.
Query completion ranking performance
In this section, we compare the query ranking results generated by our model against those of baselines, i.e., MPC and MPC-R. We report the performance of these two models in terms of MRR in Table 2. Clearly, our LQR model can beat the baseline MPC at all prefix lengths, which presents an MRR improvement around 8.10% and 5.31% generated at prefix length 1 and 5, respectively. Additionally, all the MRR scores are larger than 0.5, indicating that for most cases, the final submitted query can be returned early in the top two positions in the query list. One particularly interesting finding from Table 2 is that, the MRR scores are increased and the MRR improvement margins of LQR against MPC are decreased as the prefix length increases. It could be explained by the fact that long prefix can sharply narrow the space of query candidates, resulting in relatively high MRR scores and small MRR gaps when it’s increased.
Performance in terms of MRR of our proposal LQR model and the baselines, tested at various prefix lengths (# p) ranging from 1 to 5 in character. The best performer in each row is boldfaced
Performance in terms of MRR of our proposal LQR model and the baselines, tested at various prefix lengths (# p) ranging from 1 to 5 in character. The best performer in each row is boldfaced
Regarding MPC-R, it performs better than MPC at long prefix, e.g., 4 or 5, however, it loses the comparison with MPC at short prefix, e.g., 1. In contrast, our LQR models again beats MPC-R for at all prefix lengths. From the results shown in Table 2, we can conclude that, our LQR model can benefit not only from the overall popularity of candidates but also from the recent popularity. In addition, the personalization mechanism in our model helps further boost the ranking performance.
Next, we compare the performance of LQR and baselines at the prefix level in terms of reciprocal rank. We report the ratios of prefixes at various lengths for which LQR wins, ties and loses the comparisons against baselines in Table 3.
Per prefix bakeoff, in terms of reciprocal rank: LQR vs. baselines. The ratios (%) of test prefixes at various lengths for which LQR loses against corresponding model listed in columns have a red background, ratios with equal performance have a yellow background, and those of prefixes for which LQR wins have a green background
Per prefix bakeoff, in terms of reciprocal rank: LQR vs. baselines. The ratios (%) of test prefixes at various lengths for which LQR loses against corresponding model listed in columns have a red background, ratios with equal performance have a yellow background, and those of prefixes for which LQR wins have a green background
As shown in Table 3, compared to MPC, LQR shows a majority of draws (more than 50%). These draws actually often happen in these cases where both LQR and MPC return the ground truth (finally submitted query by user) early in the query list, e.g. at position 1 or 2. This could also be used to explain why these two models can receive very high MRR scores reported in Table 2. Another finding from Table 3, the opportunity for MPC of winning the comparisons against LQR is increased when more keystrokes are typed, i.e., when the prefix length becomes long. It means our model can work better for short prefixes than long prefixes.
In particular, LQR wins or ties MPC for most cases at various prefix length. In other words, LQR outperforms MPC frequently. It means these developed features for learning to rank queries used in LQR model do help improve the performance. We can also argue the search popularity in recent period does affect the ranking of query candidates. In order to have a deep look at these developed features, we will conduct an investigation on feature importance analysis in our learning algorithm in Section 5.3.
Regarding the comparison between LQR and MPC-R, similar findings can be observed. For prefix length at 1, MPC-R wins only 5.10% against LQR, less than the ratios of MPC, i.e., 5.38%. However, for longer prefixes, MPC-R wins LQR a bit more than MPC against LQR, indicated by the corresponding ratios at various prefix lengths. These results are consistent with the findings in Table 2, where MPC-R can work better than MPC at longer prefixes, e.g., 4 or 5.
Following previous work [28], we implement a feature ranking investigation to derive the relative importance of features used in our learning approach, according to a χ2 test. We report the top ten important features used in our learning approach in Table 4. We score the most important feature with 1.0000 and assign the relative importance scores of other features against the most important one. By doing so, the scores are all in (0, 1).
Ten most important features used in our LQR model, returned by χ2 test; the character o or p in subfix of feature f in column 2 means observed or predicted popularity, respectively; and the number or the character w means the time period for observation or the preceding day used for prediction, respectively
Ten most important features used in our LQR model, returned by χ2 test; the character o or p in subfix of feature f in column 2 means observed or predicted popularity, respectively; and the number or the character w means the time period for observation or the preceding day used for prediction, respectively
As shown in Table 4, the feature of predicted search popularity based on the observation in 2 days before is the most important feature in our LQR model. Besides that, the observed search popularity in recent 4 days or 2 days are also important, which are ranked in position 3 and 4, respectively. Apparently, the search popularity in recent period either from observations or from predictions plays absolutely important role in query candidate ranking. In contrast, compared to the features in Table 4, the feature of popularity in recent 28 days is less important. However, the overall search popularity in the whole query logs, i.e. feature fo+w, line 5 in Table 4, is relatively important. That’s probably because for some queries, their popularity are not time-sensitive but they are frequently issued by searchers.
Finally, we zoom in on the performance of our LQR model only using these top ten important features reported in Table 4. We denote this model as LQR top and plot the comparisons in Fig. 3. Clearly, both LQR model and LQR top model can beat the baseline MPC as all the MRR margins, i.e., the MRR scores of LQR-MPC and LQR top -MPC are positive. In addition, if we compare the MRR gap between LQR and LQR top , the biggest gap can be found at prefix length 1 and the gap is further shorten as the length of prefix increases. It could be explained by the fact that long prefixes make it difficult to distinguish the results generated by these two models, because both models report good performance in terms of MRR. Moreover, we can see from Fig. 3 that LQR always outperforms LQR top , indicating than our learning-based query ranking approach not only learns from the important features, but also from the less important ones.
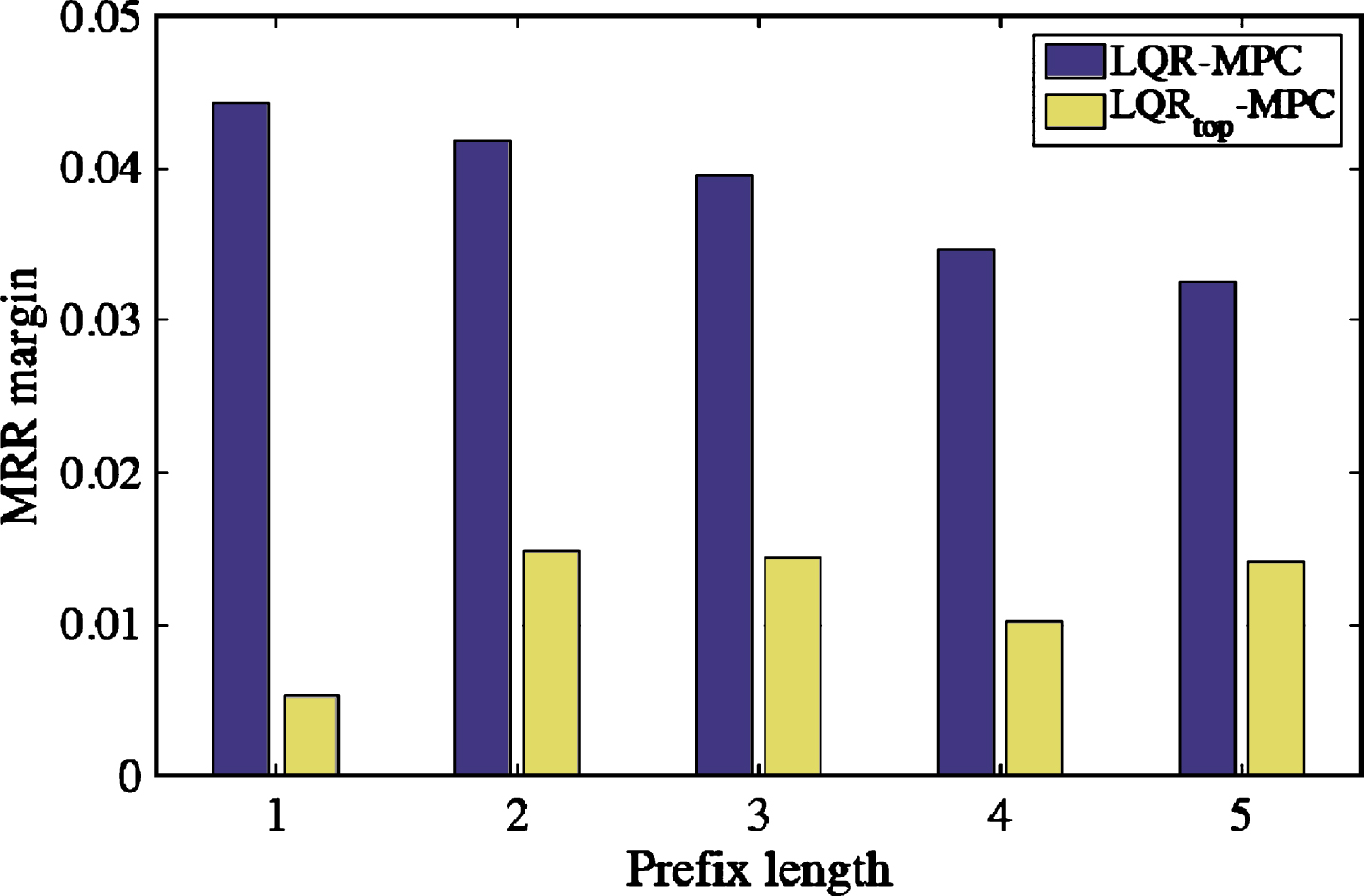
Overall performance of two models, i.e., LQR and LQR top , tested on all prefixes at various lengths in terms of MRR margin, i.e., LQR-MPC and LQR top -MPC.
To examine the relative contribution of learning output and of personalization, we manually vary the value of γ in (10) in LQR and LQR top models form 0.1 to 0.9 with interval 0.1. We plot the results in Fig. 4.
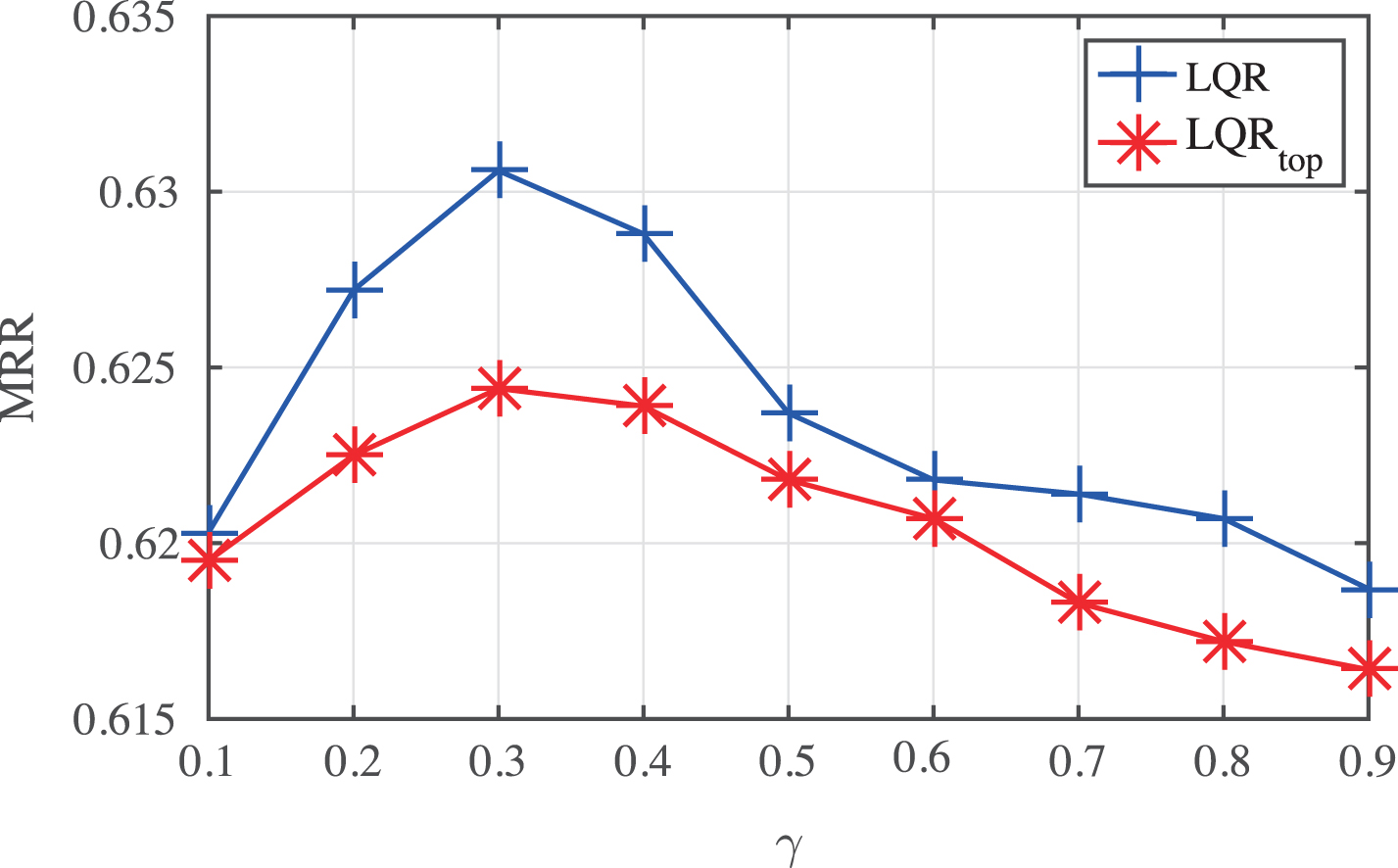
Performance of LQR in terms of MRR at various γ.
As shown in Fig. 4, apparently, our LQR and LQR top models with a relatively small γ < 0.5 can produce better results than those with a large γ > 0.5. It means that in our task, the personalized information of search context similarity contributes much more than the learning output. It’s further confirmed by the finding that both models achieve the best performance when γ = 0.3. In addition, we find LRQ is more sensitive to γ than LQR top as it shows obvious fluctuation when γ varies.
Previous work on query ranking is based on the overall search popularity. However, for some queries, their popularity is time-dependent. Thus, this basic query ranking model can not work well. To deal with it, we propose a learning-based query ranking approach, where the search popularity features based on recent observations and predictions are developed. In addition, we consider the query similarity to rerank the candidates using the preceding queries in session to personalize query completion. Our initial experimental results show our LQR model outperforms the baseline. In addition, we find the predicted popularity is important for query candidate ranking in a search system.
As to future work, we intend to have a closer look at the performance when more query candidates are initially returned by the popularity based candidate ranking method: how much can we gain from the good candidates that previously were ranked at lower ranks and later were pushed up by our model? In addition, we would like to implement our model on some artificial data to gain deep insight into the formulated problem (e.g. user behaviors). Moreover, we aim to transfer our approach to other datasets with long-term query logs. Finally, a further possible step is to extract these features in a parallelized way.
Footnotes
Acknowledgments
This work is supported by the National Advanced Research Project of China under No. 6141B08010101.