
Abstract
Existing popular web search engines have been widely used for retrieving information of interests by their users and offer query suggestions (QS) to assist them in exploring the wealth of information online. These search tools, however, are designed without any specific group of users in mind and thus are not tailored towards the specific needs of children, which can diminish their usability and design objectives when they are employed by children. Given the increasing use of the Web for educational and entertainment purposes by children, there is an urgent need to help them search the Web effectively. In this paper, we present a QS module, denoted CQS, which assists children in finding appropriate query keywords to capture their information needs by (i) analyzing content written for/by children, (ii) examining phrases and other metadata extracted from reputable (children’s) websites, and (iii) using a supervised learning approach to rank suggestions that are appealing to children. CQS offers suggestions with vocabulary that can be comprehended by children and with topics of interest to them. We conducted a number of empirical studies using keyword queries initiated by children, besides gathering feedback on the usefulness of CQS-generated suggestions through crowdsourcing. The performance evaluation of CQS revealed the effectiveness of the methodology of CQS. In addition, it demonstrated that CQS-generated suggestions were preferred over suggestions provided by Bing and Yahoo! and at least as comparable to queries suggested by Google.
Introduction
Children regularly use search engines as the starting point in their quest for online information [29]. Unfortunately, their search experiences can be negatively influenced by their lack of skill in formulating adequate search queries. While query suggestion (QS) modules designed for widely-used search engines facilitate query creation for a general audience, they were never designed from a child’s perspective. (The query suggestions generated by known web search engines for two sample queries created by Utah’s elementary school children, as shown in Table 4, illustrate that suggestions made by known search engines do not necessarily target children’s interests and/or information needs.) A survey conducted by McAfee, a software security company, in 2013 shows that children spend an average of 6.5 hours a day online,1
Query suggestions made by existing general-purpose QS modules may require advanced reading level on complex topics which children have difficulty understanding and appreciating them [5]. The discrepancies between children’s and adults’ search behaviors/interests were further verified by the study conducted by Bilal & Kirby [4] and another one by Torres et al. [27] who analyzed AOL query logs and the DMOZ kids/teens directory and have identified significant differences between the set of commonly-created queries for a general audience and queries that seek information on children’s content, such as average length of queries (3.2 words for children versus 2.5 for regular users). Even though search engines designed specially for children, such as Safesearchkids.com, Kidsclick.org, and Kidrex.org, exist, majority of them are not equipped with a QS module. To aid children with their quest for information that satisfy their needs, we have developed CQS,3
An earlier version of CQS, which includes the initial design and assessment of CQS, was published in [26].
Existing query recommendation/transformation techniques attempt to improve a submitted keyword query through word replacements, insertions, and deletions [7]. CQS, on the other hand, minimizes the effort required by a child in specifying his/her search intent by providing query recommendations, which are N-gram suggestions, that yield the suffix to the user’s initial keyword query. Note that suggestions made by CQS for a child’s query Q, which include Q as prefix, follow the common design methodology of existing web search engines, such as Google, Yahoo!, and Bing. Instead of reformulating Q, all of these popular engines offer suggestions by appending keywords to the end of Q.4
We examined hundreds of suggestions made by Google, Yahoo!, and Bing, and all of them were generated by a completion-based approach.
CQS relies on bigrams extracted from multiple reputable websites (as discussed in Section 3) that include content written for or by children, and is different from existing QS modules targeting children [28,29] which rely on tags assigned by adults to describe children/teenager’s websites for making query suggestions. CQS also considers bigrams extracted from Simple.Wikipedia.com, denoted SimpWiki, which is a small, evolving archived collection of documents written in basic English. SimpWiki targets young readers and adults learning English as a second language. Based on the content, which includes simple vocabulary and is written so that children can understand, CQS can suggest meaningful and useful phrases as queries to children.
Query Suggestion in itself is a non-trivial task for web search engine designers, since it requires disambiguating user’s search intent using very few query keywords, i.e., 2.8 words on the average [14]. If a QS module is designed for addressing children’s information needs, as opposed to a general, i.e., more mature, audience, then it has to analyze children’s search intents and behaviors, which are different from those of adults [9]. In fact, children struggle with limited vocabulary to pose their queries to search engines and have difficulty in issuing appropriate search keywords [8].
While research on QS systems targeting children is limited, research work on QS systems for a general audience is rich and well-documented. Existing QS approaches for a general audience [23] either adopt probabilistic methodologies, examine query logs, apply strategies based on random walks, consider concepts/categories, i.e., subject areas of interest, or rely on ontologies, to name a few.
In suggesting queries for young audiences, Torres et al. [28] introduce a QS module based on tags created at Delicious.com. The team constructs a bipartite graph using tags and their corresponding URLs, and suggests queries as a result of a random walk on the bipartite graph that is biased towards children’s content. Later research [29] presents further enhancements based on topical and language modeling features, such as topic-sensitive Page Rank and children-related vocabulary distribution, to more effectively suggest queries for children. Similar to the approaches described above, CQS does not rely on query logs to generate suggestions. CQS, however, differs from these QS modules for children, since, instead of using a bipartite graph, CQS considers diverse features that aim to precisely capture children’s intents. More importantly, CQS relies on content written for/by children to suggest queries as opposed to relying on tags that are often provided by adults and may be poorly defined due to the lack of quality control on user tags and thus can be inherently noisy [7].
Eickhoff et al. [10] present a two-step query expansion strategy for children. Given a query Q, it retrieves top-n results in response to Q from various search engines and uses tags assigned to each retrieved web page at Delicious as keywords to expand Q. In addition, the name of high-level semantic categories (inferred from Wikipedia and the DMOZ.org taxonomy) associated with these tags are treated as expansion terms as well, which are non-stop keywords that can be preceded by a sequence of connection words.5
A connection word [2] is either a preposition, a conjunction, or an article, which is treated as a stopword and is not counted as words in a suggestion but is retained to capture the precise meaning of a suggestion.
To improve children’s web searches, Gyllstrom et al. [13] develop a link-based algorithm which finds web pages for children. The algorithm suggests web pages that include simple vocabulary terms using SimpWiki. While CQS is not designed to search for web pages for children, we share a similar design methodology, i.e., providing simple suggestions that are suitable for kids. Inspired by using SimpWiki, we also extract some of the keywords for suggestions from SimpWiki.
Karimi et al. [17] also focus on facilitating information discovery tasks for children by offering query suggestions. Similar to their proposed strategy, CQS also considers specific children vocabulary and popularity of terms among children texts. However, the QS strategy in [17] depends on Ubersuggest6
to identify candidate suggestions, which limits the type of suggestions that can be generated. CQS, on the other hand, relies on n-grams to generate suggestions on-the-fly.Vidinly and Ozcan [30] adopt a query-log based strategy to provide QS for K-12 students. Their approach examines query logs to identify potentials suggestions, which are then re-ranked based on a score computed by aggregating information pertaining to educational features, grade similarity, log session information, and path frequency algorithms. CQS, unlike its counterpart presented on [30] is not constrained by the existence of query logs created by children.
An initial assessment on children search engines that specifically target children was conducted by us. A number of these search engines do not offer query suggestions, which include Cyber Sleuth Kids7
Instead of considering simple bigram and n-gram phrases for query suggestions as CQS does, Li et al. [20] and Zhong et al. [31] apply text mining approaches to identify useful features and discover effective patterns in text documents, respectively. Relevance features are extracted from text documents in [20] using both positive and negative patterns, whereas effective patterns are mined from text documents in [31] by discovering specificities of patterns based on term distributions in the extracted patterns. Both of these approaches can be adopted by CQS for phrase construction during the children query suggestion process. The tradeoff between using simple n-gram frequencies adopted by CQS instead of discovering text patterns is that the former is simple and yet effective to accomplish the task of suggesting children queries, whereas the latter is more sophisticated but requires the adoption of more complicated text mining techniques.
Websites used by CQS for generating query suggestions for children
Using bigrams extracted from readerviewskids.com, dogonews.com, stonesoup.com, timeforkids, and cmlibrary.org, etc. which are children’s websites, and well-established probabilistic/information retrieval models, CQS identifies each candidate suggestion for a user query Q and the closest categories to which Q belong. Table 1 shows the list of categories defined at well-known children’s websites and considered by CQS, which include stonesoup.com, dogonews.com, and kids.nationalgeographic.com. All the websites, from where various types of information extracted by CQS for generating query suggestions, are shown in Table 2.
Categories defined and used by CQS based on information available at children websites, such as Dogonews.com and Kids.nationalgeographic.com
Categories defined and used by CQS based on information available at children websites, such as Dogonews.com and Kids.nationalgeographic.com
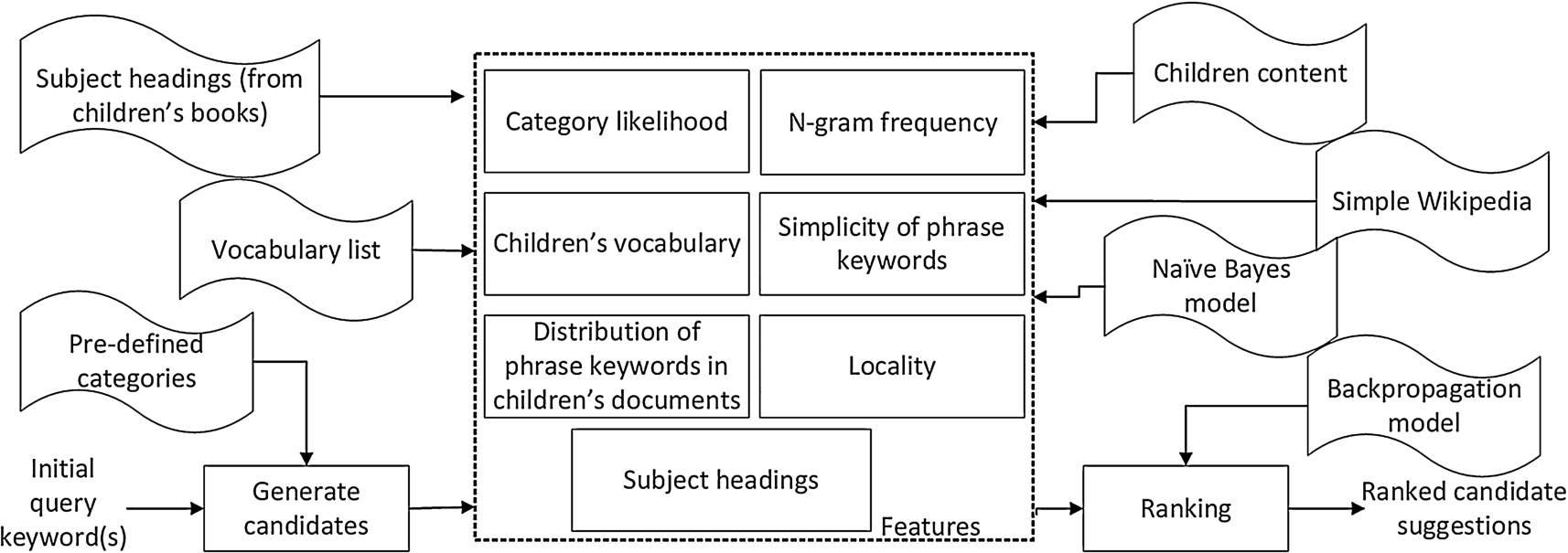
The query suggestion process of CQS.
For each candidate suggestion
The overall process in making query suggestions by CQS for any child’s query is shown in Fig. 1.
To determine the candidate suggestions for query Q with m (
To obtain the frequency distribution of bigrams that are used in generating candidate suggestions, CQS examines the consecutive word occurrences in the 82,000 documents belonged to the 16 categories extracted from children’s websites (see Table 2). Using word occurrences, CQS considers
Category likelihood
Given a query Q, CQS computes the likelihood of keyword(s) in Q matching the contents of different categories. To determine the category likelihood of Q, CQS employs the multinomial model, along with the well-known Bayes’ rule,12
A detailed description on how to apply the popular Baye’s rule for category likelihood’s estimations can be found in [7].
CQS treats the likelihood value computed in Equation (1) as one of the measures to determine the significance of
If the probability of keywords in Q belonged to category c is high, then a candidate suggestion originated from c is treated as a more promising suggestion for Q. CQS offers diverse query suggestions by considering various categories to which a given ambiguous query13
A query is ambiguous if it has several possible meanings or interpretations. For example, the user who creates the keyword query “apple” may ask for information about Apple computers or the fruit apple.
CQS relies on frequency distribution of bigrams within categorized documents to provide statistics of consecutive term occurrences in different categories, i.e., categories shown in Table 1. Recall that we define a term as a non-stopword keyword, which can be preceded by a sequence of connection words. For example, if a user enters the query keyword “information,” a suggestion “information about animals” makes more sense than the suggestion “information animals,” since in the latter case the relationship between the two keywords is missing. To obtain the frequency distribution of bigrams, CQS examines the consecutive term occurrences in the aforementioned 82,000 children’s documents (including SimpWiki documents), which are distributed across 16 categories.
We consider bigram frequency distribution of terms so that searching for related terms to a user query becomes more efficient than examining the frequencies of occurrence of sequences of more than two terms which increases the database size [2] for the document collection and significantly impacts the search time for terms related to a given query.
For a given query Q with the only keyword A, CQS generates candidate suggestions for Q by considering phrases, which are N-grams that includes A, such as
Given a
We consider a special case
Technically, EOS is not a term according to its definition. However, we consider the frequence of
CQS applies N-gram frequency to determine which candidate suggestions should be considered favorable.
CQS determines the “children-friendliness” of the vocabulary used in a candidate suggestion by consulting a vocabulary dictionary comprised of words appropriate for children that were downloaded from children’s word lists posted at a number of children’s websites, including, but not limited to Reading Rockets, Big IQ Kids, Game Gal (see Table 2 for details), as well as Library of Congress (Children’s Subheading). If a term in a suggestion is found in the dictionary, it is assigned the value of 1; otherwise, it is given the value of 0. For a candidate suggestion
Simplicity of phrase keywords
As indicated earlier, one of the design goals of CQS is to offer query suggestions that children can understand, i.e., providing simple query suggestions. To determine the simplicity of a candidate suggestion
A highly-ranked candidate suggestion
Simplicity vocabulary SV generated from SimpWiki differs from the children’s vocabulary CV introduced in Section 3.4. First, words in CV are not extracted from a collection of text documents. Instead, they are words that a child is expected to know. Second, a word in SV is simple but may be absent in CV. In SV, we include words, such as “Nintendo” (a video game console), “Transformer” (the name of a toy), or “Anna” (a character in a Disney movie), which are common terms of children’s folk culture, or terms that children are exposed to on a regular basis through mass-media, i.e., pop-culture. (See [22] for a detailed discussion on children’s exposure to terms/concepts addressing children’s folk, mass-media, and commercial cultures.) Terms in SV are simple based on their frequency of exposure to children. However, they are not commonly-occurred words in children’s literature, and hence are not part of, i.e., included in, CV. Quite often to distinguish which one of the two candidate suggestions with all the words included in CV is more appealing to a kid, CQS must rely on their simplicity scores.
Distribution of phrase keywords in children’s documents
While simplicity of phrase keywords indicates how often keywords in a candidate suggestion
Locality
By concatenating different bigrams in a category into an N-gram phrase, some undesirable phrases, such as “greek language french cyclist” which consists of frequent bigrams ‘greek language’, ‘language french’, and ‘french cyclist’, can be created and should be avoided. To eliminate their creations, CQS determines the locality score for each candidate suggestion
Subject headings
It has been shown [11] that searching information on the Web can be facilitated by searching for the topics of the desired information. With that in mind, we have designed CQS to examine the topics of information addressed in candidate suggestions and penalize suggestions that are associated with topics/themes that are not commonly associated with children content. To accomplish this task, CQS relies on Library of Congress Subject Headings (LCSH), which is a de facto universal controlled vocabulary and constitutes the largest general indexing vocabulary in the English language. LCSH, which are keywords or phrases that denote concepts, events, or names, are employed by librarians to categorize and index books according to their themes, i.e., topics. Examples of LCSH include “Fairy tales” and “Fear of the dark-Fiction”.
To identify, among the large number of LCSH, the subject headings that address topics of interest to children, we (i) examined LCSH assigned to 30,000 randomly selected books known to be suitable for children, which are with readability levels between the K-6 grades defined by publishers and (ii) generated a list of 10,749 children’s LCSH, denoted
In examining the topical information of a candidate suggestion
While the list of subject headings is created by indexers and librarians, each of the headings in cLCSH addresses a topic/theme of interest to children. Using the word-correlation factors, we measure the degree to which a candidate suggestion
The Min function in Equation (6) imposes a constraint on summing up the correlation factors of words in the description of
A candidate suggestion Consider a candidate suggestion “british movies”, which is generated by CQS in response to the user query “british.” In comparing against the subject headings digestion, finance person, television, and films using word-correlation factors, the corresponding degrees of resemblance with respect to “british movies” are assigned the SHScore of 0, 0, Now consider the four subject headings again for another candidate suggestion “british pancakes”, which is assigned the value 0 as its SHScore, indicating that there is no suitable topic description for the suggestion based on the set of subject headings. Furthermore, in considering the two suggestions “british movies” and “british sitcoms” against the subject heading television, CQS assigns higher SHScore to “british sitcoms” than “british movies”, i.e.,
Using the individual scores of the features introduced earlier, which are computed for each candidate suggestion
K in top-k suggestions is determined by the software developer who implements CQS and is recommended to be in the range of 4 and 10.
In training the BP model for CQS, 138,579 training instances were used. Each training instance includes a given noun-phrase, in lieu of a query, and is associated with the seven different feature scores computed for the corresponding noun-phrase and a label, which is either 1 or 0, to designate whether the noun-phrase is a children or generic query, respectively. In gathering the training instances of children queries, noun-phrases from a number of children websites, including spaghettibookclub.org, motherdaughterbookreviews.com, and best-kids-books.com,18
These sources include diverse content for creating sample children queries addressing multiple topics.
In this section, we present the results of the empirical studies conducted to assess the design of CQS and compare its performance with well-known QS modules.
Dataset and metrics
Due to the lack of benchmark datasets to evaluate the design methodology and performance of QS modules for children, we turned to a number of 7- to 12-year-old children who are 1st- to 6th-grade students at a local school. During the month of April 2014, we asked the students to first create keyword queries that they would like to use to conduct their searches. We collected 127 children queries. Children were then provided with a number of CQS-, Google-, Yahoo!-, and Bing-generated suggestions to evaluate. We selected these popular search engines for baseline purposes, as opposed to search engines specifically targeting children, since it has been reported that children rank Google, Yahoo!, and Bing as their three most favored engines for conducting their daily information discovery tasks [3].
Sample queries created by children
Sample queries created by children
Two sample queries and suggestions recommended by Google, Yahoo!, Bing, and CQS, respectively. Highlighted queries are among the top-4 gold standard suggestions for the respective query
We used eight, five unigram and three bigram, queries randomly chosen out of the (keywords in) 127 unique queries provided by 127 elementary school students, who are 3rd to 6th graders, to evaluate the performance of CQS. (Table 3 shows a few of the 127 queries offered by the children.) Altogether, 25 students in 3rd grade, 36 in 4th grade, 26 in 5th grade, and 40 in 6th grade participated in the empirical study. For each query Q, we applied CQS to generate the top-4 query suggestions, which were mixed with the top-4 suggestions of Q offered by Google, Yahoo!, and Bing. Note that we assessed the performance of CQS against Google, Yahoo!, and Bing, since the latter are widely-used search engines. Furthermore, the top-4 suggestions of CQS were used, since Google offers four suggestions per query, the least number of generated suggestions among the QS modules considered for comparison purpose.
Each child who participated in the study was asked to choose four useful suggestions for each test query. Table 4 shows two of the test queries and their corresponding suggestions used in the evaluation, and the remaining queries are arctic circle, chocolate chip, football, greek, information, and snow. The top-4 most frequently chosen suggestions for each test query Q, among the choices provided by the 43 children who participated in the evaluation, were treated as the gold standard of Q.
We acknowledge that the number of queries considered for the evaluation of CQS by school children is relatively small. However, given that (i) evaluations involving children are difficult to conduct due to privacy constraints [28] and (ii) we only had access to students for a limited amount of time—each student involved in the assessment was given 15 minutes to complete the evaluation, which was imposed by their school administrators—we were forced to limit the number of queries to be assessed to eight which allowed each student to spend an average of at most 2 minutes on evaluating suggestions for a query. Had we been given access to more students at the school and/or more time to conduct our evaluation, we would have compiled the results based on more than eight queries.
We applied a simple counting scheme to evaluate the query suggestions made by CQS. For each CQS-offered query suggestion that was chosen by a child (as a useful suggestion), a point is rewarded for the suggestion. Using this counting strategy, we consider the top-4 counts of suggestions for each one of the eight test queries, which yields the gold standard for our evaluation. A total of 43 children participated in the evaluation.
To determine the effectiveness of CQS and existing QS modules (considered for comparison purpose) in making useful suggestions to children, we have computed the Normalized Discounted Cumulative Gain (nDCG) value [15] on their corresponding top-4 suggestions for each test query. nDCG penalizes relevant suggestions that are ranked lower in the list of suggested queries.
To verify the correctness of the design of CQS we conducted a number of studies using the dataset and metrics introduced in the previous section. We first validated the correctness of selecting Backpropagation as a combination strategy. Thereafter, we evaluated the effectiveness of each individual feature (as discussed in Sections 3.2 through 3.8) in making good query suggestions to children, which validates its usefulness. Lastly, we assessed the overall performance of CQS based on combining individual features as a whole (as defined in Section 3.9), which we compared with the performance of a number of existing QS modules adopted by popular search engines. As previously stated, we also used the nDCG metric to quantify the performance of CQS in making suggestions suitable for children against Google, Yahoo!, and Bing, being used these days.20
In computing nDCG scores, a candidate suggestion
CQS considers the BP model, a supervised learning-to-rank approach as presented in Section 3.9. To demonstrate the correctness of selecting such a strategy to combine the seven different scores generated by CQS for each candidate suggestion into a single ranking score, we compared the use of BP with two other combination strategies: (i) CombMNZ [18], which is a linear combination measure frequently used in fusion experiments [6] and (ii) Reciprocal Rank Fusion (RRF) [6]. C̱ombMNZ, as defined in Equation (7), is applied to consider multiple existing lists of rankings on
Prior to computing the ranking score of
Ṟeciprocal Rank Fusion (RRF) [6] first sorts the score list of each feature of all the candidate suggestions, which yields a ranked list of candidate suggestions corresponding to every feature in descending order. Given a list of M candidate suggestions, RRF in Equation (9) is applied to generate a single rank score for
It has been empirically verified that BP is significantly better than CombMNZ and RRF in terms of combining different features of a candidate suggestion as shown in Fig. 2. The figure shows the performance of using different combination strategies on the eight queries that were evaluated by CQS. While the unsupervised combination strategies of CombMNZ and RRF are simple, their overall nDCG values are significantly lower than the overall nDCG value achieved by BP. Although BP requires training to learn the feature weights, the training process is one-time.
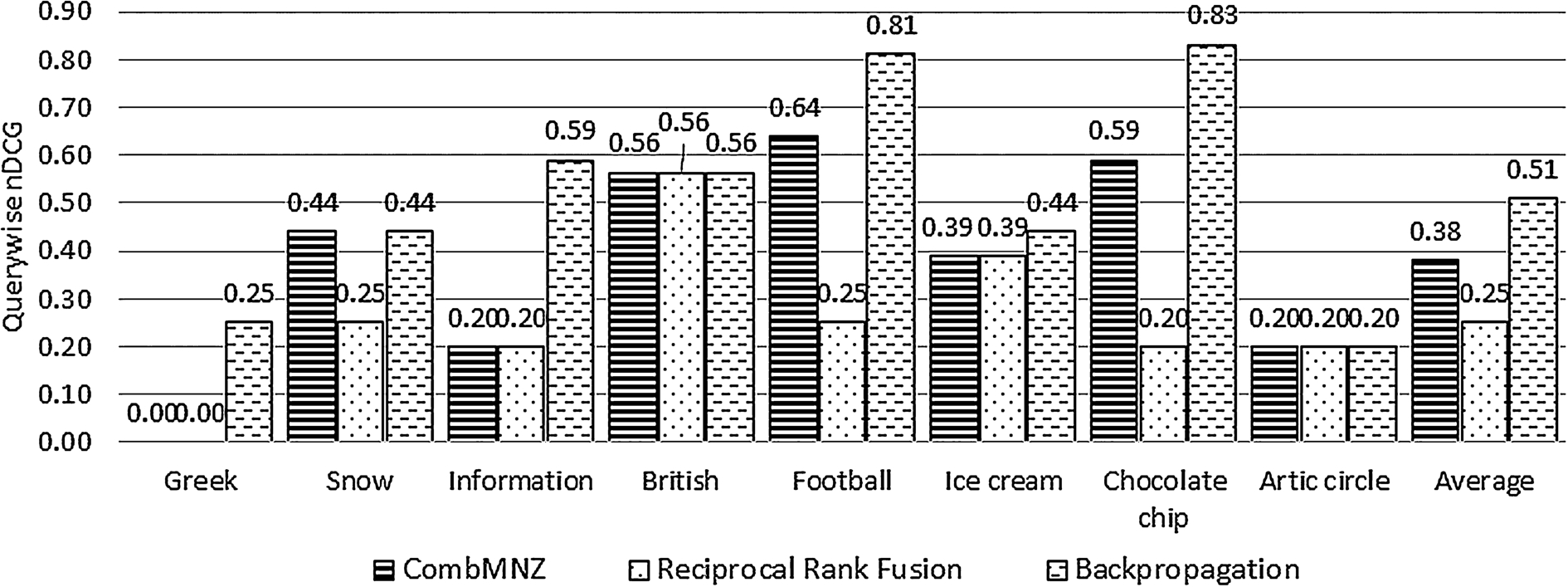
Performance evaluation of three feature combination strategies in generating query suggestions for children based on the eight test queries.

Performance evaluation of (each of the features of) CQS.
To determine which feature(s) of CQS, as presented Sections 3.2 through 3.8, contribute(s) the most in making children suggestions, we relied on a test dataset, denoted TestData. TestData consists of 12,000 labeled instances, which include phrases and their corresponding scores computed for each of CQS features. These phrases are uniformly distributed among children/non-children categories and are disjoint from the instances presented in Section 3.9. Each instance in TestData comes with the scores computed based on each of the aforementioned features. We analyzed the capability of each (group of) feature(s) in distinguishing (non-)children phrases, which are potential candidate queries.
We computed the nDCG score of each feature using the TestData dataset in addition to the overall nDCG score of CQS computed using backpropagation as a combination strategy (as discussed in Section 3.9). As reflected by the nDCG scores in Fig. 3, each individual feature underperforms the combined features used by CQS. By combining all the features, CQS takes the advantage of their individual strengths and greatly improves the degree of relevance and suitability of its generated query suggestions for children. The overall nDCG of CQS as shown in Fig. 3, which is 0.51, is a statistically significant improvement (
CQS versus QS modules
We compared CQS with the QS modules employed by Google, Yahoo!, and Bing in terms of nDCG, which is an evaluation framework similar to the one adopted by the authors of [28,29]. One of the strengths of our evaluation strategy lies on the fact that we rely on children’s assessments, and there is no room for adult-based bias. This is because we use keyword queries initiated by children as test queries and the top-4 suggestions selected as the gold standard are the ones chosen by children.
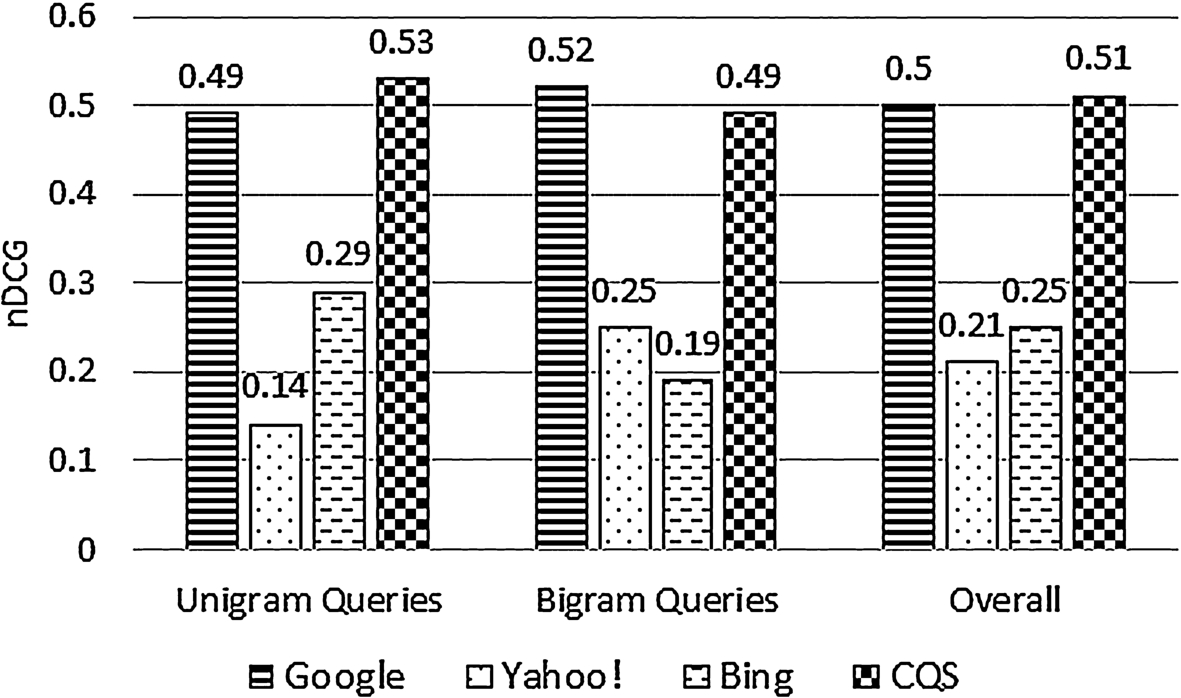
The nDCG scores for Google, Yahoo!, Bing, and CQS respectively determined using their top-4 suggestions against the gold standards.
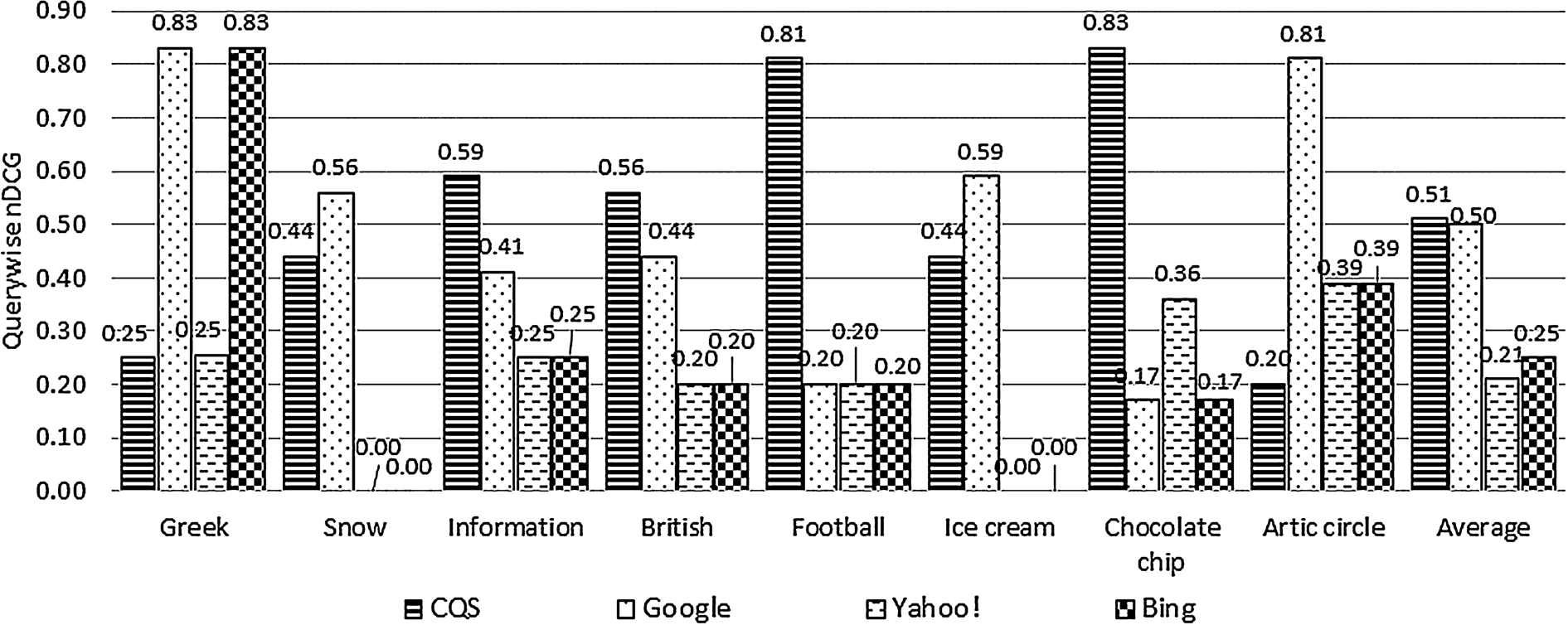
Per-query distribution of nDCG scores for CQS, Google, Yahoo!, and Bing, respectively.
In seven out of eight queries, CQS provides a suggestion that made it either to the first or second position in the gold standard, whereas Google achieves only six out of the eight queries. Figure 4 shows the performance of Google, Yahoo!, Bing, and CQS using the nDCG measure. The results have verified that suggestions made by CQS are more appealing to children than the ones offered by Google, Yahoo!, and Bing. Although the results of CQS are not statistically significant (
Besides analyzing the overall performance of CQS, Google, Yahoo!, and Bing using nDCG, we also examined their performance at the query level. As shown in Fig. 5, CQS outperforms Google in making suggestions in four out of the 8 test queries based on the gold standard. More importantly, CQS-offered suggestions are placed at higher ranking positions compared to Google. In fact, among all the test queries, while CQS and Google both have equal number of suggestions posted at rank position 1, the former has more suggestions placed at positions 2 and 3. Similar to the overall performance, CQS and Google distance themselves from Yahoo! and Bing in terms of achieving higher nDCG values at the query level.
We attempted to compare CQS against other children QS modules [10,28,29]. Unfortunately, implementing these modules requires setting up different parameters which are not explicitly articulated in [10,28,29]. For example, the authors of [28,29] create the random walk graphs, which include a foreground and background model, based on tags and URLs. Given that the (i) specific URLs considered for creating such graphs were not made available, and (ii) authors’ cleaned tags and URLs to a large extent using tag normalization and tag filtering are not described in details in the respective paper, it is not possible to regenerate the foreground and the background model for comparison purpose. Furthermore, datasets presented in [10,28,29] are not available to the research community. For this reason, fair comparisons between CQS and these children QS modules are not possible.
As previously stated, there are no benchmark datasets that can be used to assess the performance of QS modules for children. For this reason, we turned to Mechanical Turk21
to conduct empirical studies that allow us to further evaluate the performance of CQS. We relied on Amazon’s Mechanical Turk, since it is a “marketplace for work that requires human intelligence”, which allows individuals or businesses to programmatically access thousands of diverse, on-demand workers and has been used in the past to collect user feedback on various information retrieval tasks. The performance evaluation of CQS based on independent appraisers are presented in Sections 4.3.1 through 4.3.3.
An evaluation conducted by Mechanical Turk appraisers who assessed the relevance of the suggestions generated by CQS.
We conducted a survey on Mechanical Turk in which we asked appraisers to examine a set of ten test queries and their corresponding suggestions created by CQS. For each query Q, appraisers were required to identify, among a provided set of four suggestions generated by CQS for Q, the ones (if any) that were suitable and relevant for children.22
Note that the responses identified as relevant provided by an appraiser are treated as the gold standard for accuracy and reciprocal rank assessment, and the reported overall accuracy and MRR are based on the average of the corresponding accuracy and MRR calculated according to each appraiser’s response. In other words, the suggested queries treated as “suitable and relevant” by each appraiser were not combined into a single gold standard for evaluation purpose, since we would like to preserve varied opinions on relevance in evaluating the performance of CQS.
While the ten test queries (with five queries in each evaluation form) included in the survey, which are “Disney”, “Lego”, “Pet”, “Transformers”, “National football”, “Art”, “Dog”, “Minecraft”, “Video”, and “Basketball player”, were selected among the query set introduced in Section 4.1 that address varied topics of interests for children at diverse school grade levels, the corresponding suggestions were generated using CQS. The goal of this survey is to quantify the degree to which queries suggested by CQS are appealing to children (from the adults’ points of view). We collected 90 responses during the month of July 2014. Based on the feedback collected through Mechanical Turk, we have observed that, on the average, (close to) 50% of the recommendations generated by CQS were deemed suitable for children. (For the evaluation of the performance of CQS on each test query, see Fig. 7.)
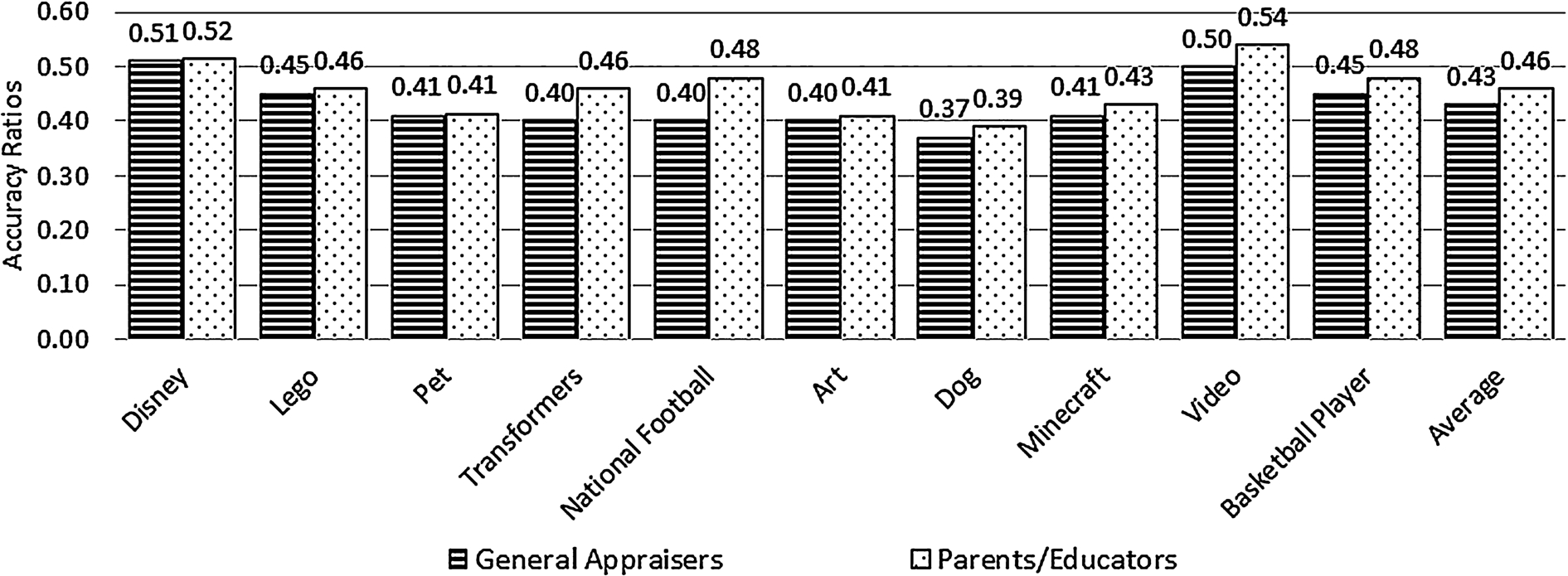
Performance evaluation of CQS based on the responses of Mechanical Turk appraisers.
We are aware that each Mechanical Turk appraiser must be over 18 years old. We solicited appraisers of all walks of life and assessed the performance of CQS by separating the opinions of appraisers known to be educators or parents of young children,23
Mechanical Turk appraisers were asked to voluntarily answer a question which inquired whether they were parents/educators. Overall, 57% of the 90 appraisers who assessed the performance of CQS were parents/educators.
We also turned to Mechanical Turk to validate our claim that queries suggested by CQS for children are more favorable than the ones generated by Google, Yahoo!, and Bing. To verify this claim, we conducted another survey on Mechanical Turk (see a sample evaluation form designed for this empirical study in Fig. 8). The survey requested the appraisers to identify for each test query the two suggestions that, to the best of their knowledge, were most suitable for children. The test queries in this survey are the same queries as presented in Section 4.3.1, and the corresponding suggestions are the top-2 suggestions generated by CQS, Bing, Google, and Yahoo!. (Note that due to overlapped suggestions offered by the four QS modules, there are less than eight suggestions for each of the test queries.) We treated the two suggestions chosen for each test query Q by each appraiser as the gold standard for Q. Based on the chosen suggestions, we computed the accuracy ratio and Mean Reciprocal Rank (MRR). While the former quantifies the proportion of relevant suggestions generated by a QS module, the latter computes the average ranking position of the first relevant suggestion provided by the corresponding QS module.

The Mechanical Turk evaluation form for performance comparison of CQS and other QS modules.
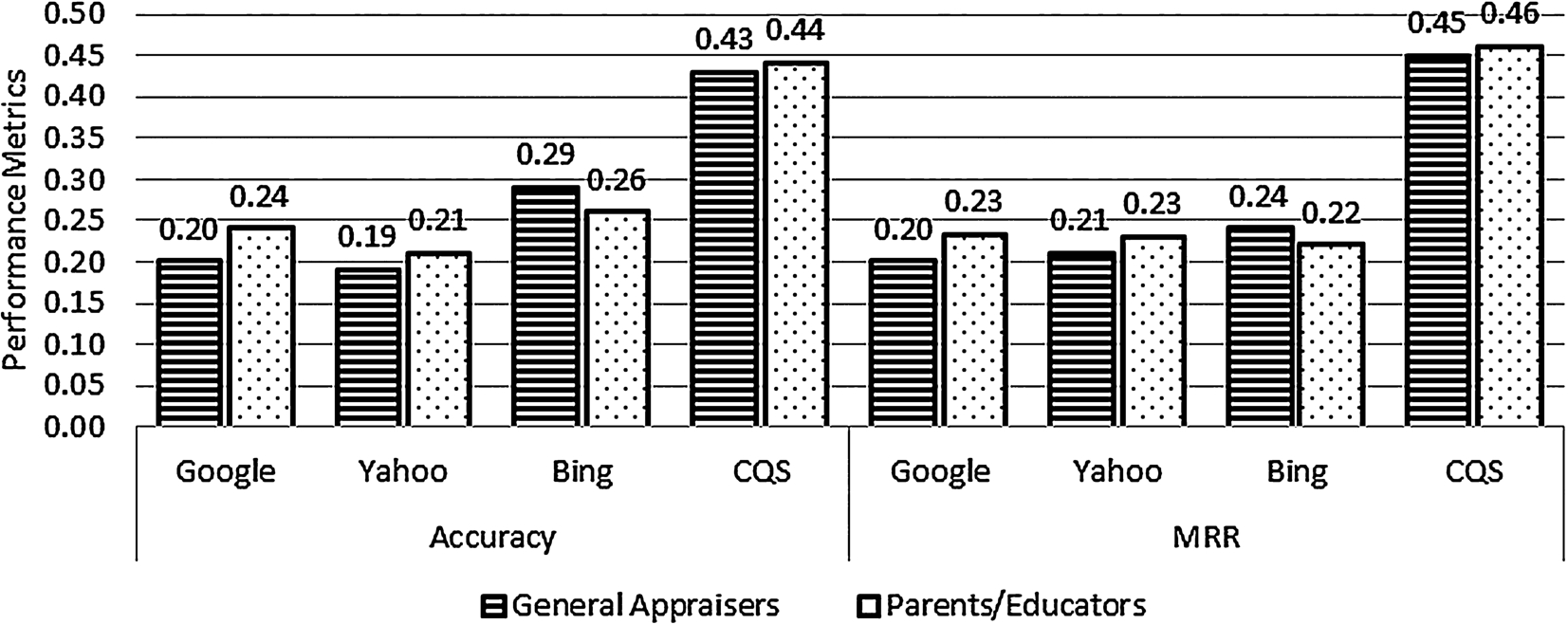
Evaluations of CQS and other QS modules based on Mechanical Turk appraisers’ responses.
The accuracy and MRR scores computed according to the 90 responses collected during the month of July of 2014 are shown in Fig. 9. The results, which are statistically significant with
To further validate the performance of CQS, Google, Yahoo!, and Bing, in terms of their ability to generate suggestions appealing to younger audiences, we conducted another survey to gather feedback through Mechanical Turk. Using the same experimental framework described earlier in this section, we created new HITs using 28 new queries (see the new queries, along with the 10 test queries used in the July 2014 survey, in Table 5), which are selected among the ones described in Section 4.1, and vary in terms of length.
Children queries and their top suggestions provided by CQS and other web search engines

Evaluations of CQS and other QS modules based on Mechanical Turk appraisers’ responses collected during 2017.
We collected 657 responses on the new HITs during the months of January and February of 2017. Based on these responses, we computed the accuracy ratio and MRR of CQS, Google, Yahoo!, and Bing, respectively. As shown in Fig. 10, query suggestions generated by CQS continued to be favored by appraisers over those generated by Google, Yahoo!, or Bing, and CQS performs significantly better than Google, Yahoo!, and Bing (with
Note that Table 5 shows the child-formulated queries used in all of the Mechanical Turk experiments discussed in this section. For each test query, we also include the top suggestion generated by CQS and each of the web search engines considered for comparison purpose.
As we previously stated in Section 4.1, the objective of our empirical assessment is to demonstrate the need for query suggestion modules, alike to CQS, that can be used to complement search engines favored by children, such as Google. In order to further illustrate the suitability of CQS in generating query suggestions to meet the information needs of younger audiences, we conducted another experiment. In the new online study, we examined the performance of CQS and Kidzsearch, a leading kids search engine as discussed earlier.
Following the framework discussed Section 4.3, we created HITs in which we included suggestions generated by both Kidzsearch and CQS for diverse sets of unigram, brigram, and trigram queries, with a total of 28 queries (see the queries in Table 5). We asked Mechanical Turk appraisers to select, according to their interpreted intent of each query Q, the top-2 suggestions most relevant to Q. We collected 687 responses, out of which 344 were provided by appraisers who reported being either parents of young children or educators.
Based on the responses collected on Mechanical Turk, we computed the MRR and accuracy ratios. As shown in Fig. 11, Kidzsearch and CQS achieve comparable performance in terms of MRR, i.e., the difference between their MRR ratios are not significant. The reported results are also consistent among appraisers that are parents or educators. Even though the overall differences in the accuracy ratios between Kidzsearch and CQS are statistically significant (

Performance assessment in terms of MRR for CQS and Kidzsearch, based on Mechanical Turk appraisers’ responses.
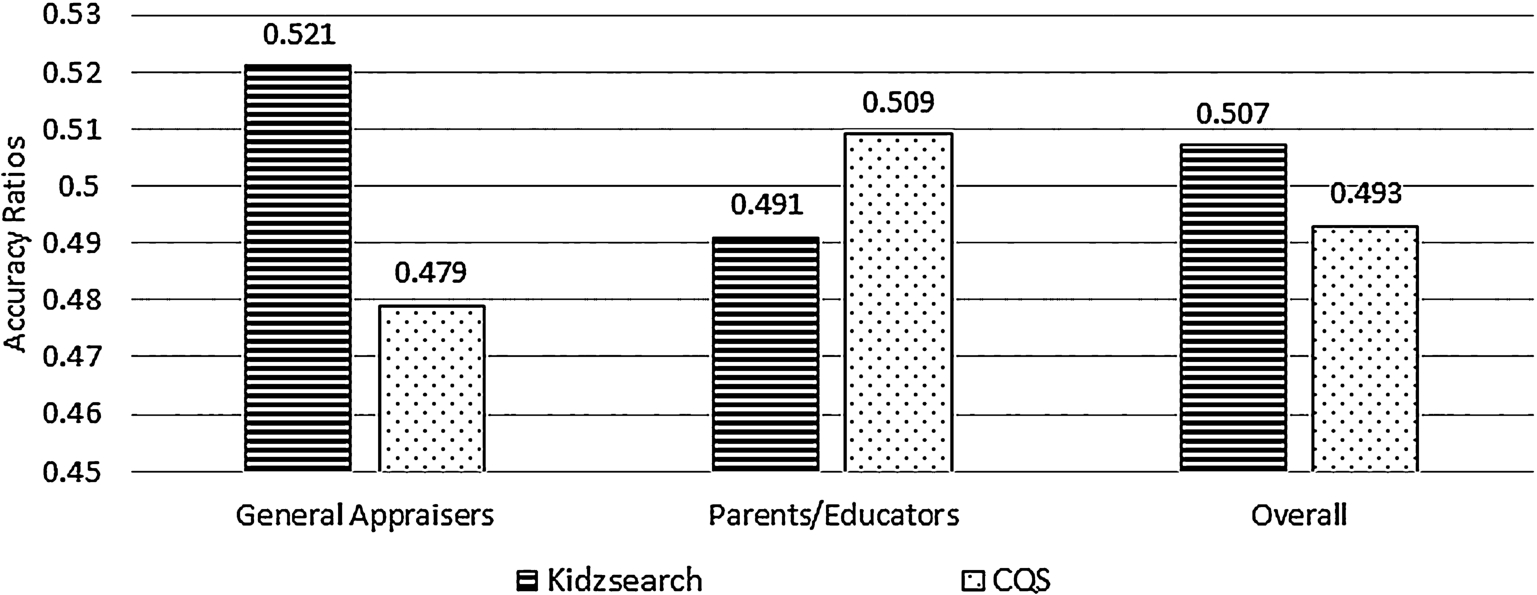
Accuracy ratios for CQS and Kidzsearch based on Mechanical Turk appraisers’ responses.
In Section 4.2 and Sections 4.3.1 through 4.3.3, we presented the results of the different experiments conducted to validate the design strategy of CQS as well as its overall performance. We demonstrated that suggestions generated using CQS are often favored over those provided by Google, a search engine preferred by children. This is promising, given the fact that CQS does not depend on query logs, which are rarely, if at all, publicly available. Instead, CQS relies on public data sources, which are accessible through the Internet, to train probabilistic models that can be updated over time, allowing CQS to offer timely suggestions. Moreover, CQS generates suggestions on the fly, as opposed to the suggestions provided by many of the suggestion modules examined in our experiments, which are based on queries previously formulated by other users. Furthermore, children are familiar and accustomed to the keywords specified in suggestions offered by CQS, since they are extracted from children’s vocabulary and children web pages. Due to of its design methodology, CQS is tailored to serve groups of children of different ages.
Conclusions
A statistical report published in 2012 shows that 76% of children searched information on the Internet [16], which is a significant number back to those days and in today’s standard. To enhance the children’s web search experience, it is critical to design a query suggestion module that tailored towards children’s information needs. In this paper, we have proposed a query suggestion module, called CQS, to suggest queries for children. Instead of following existing query suggestion approaches that rely on frequently-used queries in query logs or children’s query suggestion approaches that count on snippets and titles given by search engines to (obtain tags that can be used to) generate candidate suggestions, CQS considers sentences in children’s writing, children’s vocabulary/phrases, simplicity of words, children’s subject headings, and children’s categories (i.e., subject areas) extracted from various children’s websites, to generate simple and comprehensible phrases as query suggestions. The novelty of CQS is its reliance on freely and easily accessible online content/documents written by or for children. These resources not only allow CQS to make age-appropriate suggestions, but they also offer different children-likelihood features to be considered for capturing children’s information needs, creating cohesiveness and simplicity of keywords in suggestions, and enriching the coverage of various topics in suggestions. Experiments conducted to evaluate the performance of CQS demonstrate the correctness of the design methodology of CQS and show that (i) children prefer suggestions offered by CQS over Yahoo! and Bing’s, and (ii) the suggestions made by CQS are as popular as the ones recommended by Google.