
Abstract
Focus of this research work is optimizing the deduplication system by adjusting the pertinent factors in content defined chunking (CDC) to identify as the key ingredients by declaring chunk cut-points and efficient fingerprint lookup using bucket based index partitioning. For efficient chunking, proposed Differential Evolution (DE) algorithm based approach is optimized Two Thresholds Two Divisors (TTTD-P) CDC algorithm where significantly it reduces the number of computing operations by using single dynamic optimal parameter divisor D with optimal threshold value exploiting the multi-operations nature of TTTD. Therefore, proposed DE based TTTD-P optimize chunking to maximize chunking throughput with increased deduplication ratio (DR); and bucket indexing approach reduces hash values judgment time to identify and declare redundant chunk about 16 times faster than Rabin CDC, 5 times than Asymmetric Extremum (AE) CDC, 1.6 times than FAST CDC. Experimental results comparative analysis reveal that TTTD-P using fast BUZ rolling hash function with bucket indexing on Hadoop Distributed File System (HDFS) provide a comparatively maximum redundancy detection with higher throughput, higher deduplication ratio, lesser computation time and very low hash values comparison time as being best distributed deduplication for big data storage systems.
Introduction
In the recent year the exponential growth in Big Data make it next big thing in the IT world. Big data is similar to smaller data but bigger in size that includes large dataset made-up of a variety of structured, semi-structured and unstructured data. Structured data is highly organized and easily searchable data that resides within a relational database SQL format. Semi-structured data has a self-describing structured that includes CSV, XML, JSON and NoSQL formatted data. Unstructured data is difficult to analyze and search often includes text and multimedia content. Example of unstructured data includes message, word processing document, PDF, presentation, photographs, audio files, video files, E-mail message, web page and many more other kind of business documents.
In order to explore the enormous amount of data, big data introduced to the computing world by Roger Magoulas from O’Reilly media in 2005. The challenges of big data include analyzing, searching, transfer, storing and redundancy reduction [1, 2]. The typical software tool ability is not enough to store the vast amount of information so some tools or techniques are required to solve storage problem of big data. The automatically and human generated information [4] has brought greater pressure to traditional techniques. How to store the vast amount of information is the big task. Data deduplication has increased attention in large-scale storage systems to data reduction by eliminating redundant data at chunk-level and identify duplicate contents by cryptographically secure hash signatures like SHA-1 fingerprint. Summary of recently published analyses on redundant data reduction ratios of large-scale real-world datasets by industry like IBM, Microsoft and EMC [1, 48] indicates that content-defined chunking detects much more redundancy with data reduction ratios of about 69% ∼97%, and 42% ∼68%, in secondary storage, and primary storage respectively as shown in Table 1.
Published analyses on data reduction ratios
Published analyses on data reduction ratios
According to a report from International Data Corporation (IDC) the amount of digital information created and copied in the whole world is about 1.8 ZB (∼1021 Bytes) in 2012 and the volume will reach 40 ZB in 2020 [5, 6]. By observing the problem, there are some techniques required that efficiently process and store all types of data.
Cloud storage [7, 12–18] is one of the solutions but the management of various storage nodes is difficult in the cloud network. As a result, the complexity of network increases and the performance of cloud network degrades. Deduplication is another most important technology in storage that used by various users. Deduplication is the process of eliminating duplicate copies of data through a deduplication scanning process so that unique copy is stored and will then serve all authorized user. Categorization of deduplication is shown in Fig. 1 and basic deduplication system architecture in Fig. 2.

Categories of deduplication based on location, granularity and ownership.
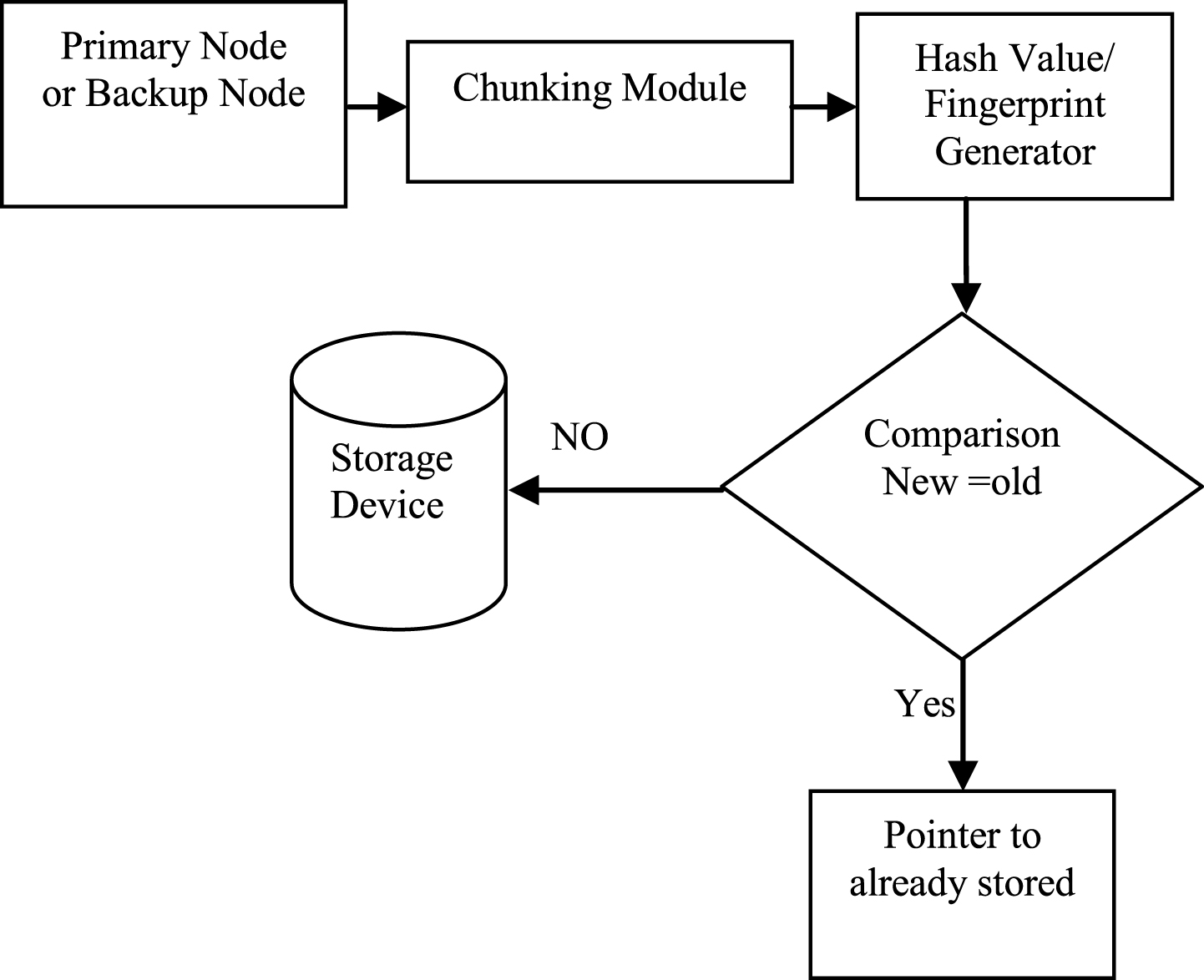
Traditional deduplication system architecture.
Based on the location, deduplication can be performed on client side (source side) where the redundancy removed from the file at the source side before transmission to the backup. It reduces the bandwidth utilization but it is slower than target based deduplication especially for large files. Target based deduplication perform the redundancy removal from backup server upon which the backup software resides. It reduces the amount of storage requirement but does not reduces the amount of data that must be send across local area network during the process of backup. Another categorization of deduplication is based on the ownership. In single user the process of deduplication is applied on single user, the compression techniques are applied to reduce the data size. The redundant data is not removed in this, so the cross client is the better option in which the client and server match the duplicity and then remove the redundant data.
Third categorization is based on the granularity, deduplication can be performed over the whole file where the complete file is taken as single chunk and hash value is computed using the hash function. Hash function is a part of cryptography but does not require any special key for coding. It is a function that maps any value into a fixed size hash value called a hash code. A single bit change in the value generates the different hash code. If the file hash value is matched with the previously stored hash value then only reference pointer is given, otherwise, the file hash value is stored in the storage device. Chunk level deduplication is performed within a file where the file content is firstly broken into smaller chunks. The chunk may be of fixed size or variable size. Experimental results have been performed with analysis on Hadoop Distributed File System. Hadoop is an open source framework for storing data and running applications. It includes the HDFS, Hadoop common, Hadoop YARN and Hadoop map-reduce. The main components of Hadoop are HDFS and map-reduce. HDFS is a master slave architecture in which master contains information of name node and job tracker. The slave contains the data node, task tracker and map-reduce information.
The contribution of this paper is to present an optimized TTTD-P variable size data deduplication scheme for HDFS environment, in order to achieve higher deduplication ratio with low deduplication time. The rest of this paper is organized as follow: Section 2 present related review and background concept in deduplication. Section 3 describes the proposed variable size TTTD-P algorithm with optimal parameters. Section 4 describes the experimental results with bucket indexing. Finally, Section 5 has discussion with Section 6 concludes this paper.
A low bandwidth network file system (LBFS) was proposed by Athicha Muthitacharoen [8] to exploit the inter file and cross file similarity. It avoids transmitting the redundant data over the network so that the less bandwidth consume in the transmission. LBFS break the file into variable size chunk based on the content and then index each chunk by using hash value. Hash value of chunk was computed by hashing function like MD5 or SHA1. The hash functions are combination of cryptographic application like digital signature, random value generator, one-way function and integrity protection. It maps arbitrary input into fixed size output bit - the hash value. Message Digest 5 (MD5) is most widely used algorithm in the list of hashing function [9]. It process the variable length message into fixed size 128-bit output. The process of MD5 includes five steps: appending, padding bits, appending length, initialize MD5 buffer, process message in 16-words and output. SHA-1 is another most commonly used hash function that process the input 512-bit block and produce 160-bit message digest [10]. The algorithm of SHA-1 includes padding, appending length, initializing the SHA-1 buffer, process message in 16-word block and final output.
Deduplication algorithms detect the duplicate content by using the hashing function. The duplication can be finds at file level or at the block level. In 2009 Deepavali et al. [11] proposed a scalable deduplication technique for the backup storage that works at file level. It detects the duplicate chunk with high accuracy by breaking the chunk into two tiers. One resides in the primary index (RAM) and another resides in secondary index (BIN). When deduplication is performed at block level, the data-stream is partition into blocks that may be of fixed size or variable size. For backup application and large scale file systems, many of organizations use fixed size blocks. In fixed size chunking, a data stream is splitted into fixed size blocks easy to implement. It is advantageous due to its fast speed, simple, and computationally with very low cost. So backup applications Venti [49], OceanStore [50], and large-scale file systems [51] have adopted fixed-size chunking. Zhang et al. proposed to use distributed systems for deduplication [52] by partitioning the incoming data stream using fixed size chunking and transferring the data blocks to storage nodes. But there is a limitation in this method; for every insertion or deletion in the original file may generate a set of chunks that are entirely different from the original ones. The boundary of newly formed chunk is totally different from the previous chunks. It creates lots of metadata with some minor changes that increase the storage data and also increase the CPU overhead. Frequency based chunking, byte-index and multi-byte index are some examples of fixed size chunking. Frequency based chunking is a two stage algorithm [19] that identifies the high frequent chunk. At first stage, it identifies the fixed size high frequency chunk. Then at second stage, it consists of coarse grained and fine grained based chunking. In coarse grained chunking, content defined chunking algorithm is used to partition the data stream into large size chunks and then fine grained chunking scan each coarse grained chunk to find the frequent fix size chunk.
Byte index chunking [20] finds the duplicity at byte level by searching the high probability duplicate chunk byte by byte in the file. Index matrix of size 256×256 is used to find the high probable duplicate chunk in less time. After that hash function is applied to confirm that the chunk is definitely duplicate or not. After that multi-byte index chunking [21] was proposed that use two index matrix. First 32 KB index matrix is used for files whose size less than 5GB. If file size is more than 5GB then second 4 MB index matrix will be used.
Variable size chunking solves the problem of “boundary shift problem” that come in fixed size chunking. It partitions the file according to the contents. Some of variable size chunking algorithms are leap based chunking, bimodal chunking, multi-modal chunking and basic sliding window CDC. Leap-based CDC algorithm [22] improves the deduplication performance by adding another judgment function. The pseudo-random transformation is used to define whether a window is qualified or not. This is the replacement of rolling hash function that is used in the sliding window CDC. Bimodal chunking [23] introduced as opposed to the unimodal baseline CDC approach. This is the improved version of CDC that mixes different average size chunks together. The algorithm first chunks the data stream into large chunks and then split parts of them into small chunks. A Multimodal Content Defined Chunking (MCDC) was proposed as a new enhancement in Bimodal Content Defined Chunking. MCDC [24] determines the optimal chunk size according to data size and compressibility.
A new content defined chunking algorithm Asymmetric Extremum (AE) was presented that mainly focus to improve the chunking throughput and the chunk size variance. The Rabin fingerprint based CDC and MAXP CDC algorithm limitations are removed by AE algorithm [25]. A variable size window is used that find maximum value without going in reverse direction as opposed to fixed size window in Rabin based CDC and MAXP. The AE algorithm requires one comparison and two conditional branch operations per byte. Basic sliding window (BSW) algorithm is used in variable size chunking. A signature is created for each chunk, if signature matches the predefined bit pattern; the algorithm set the chunk boundary at the end of window. After each comparison, the window slides one byte position and compute hash function. To find the duplicated data, the content defined chunking proposed a low bandwidth network file system (LBFS) that determines the file similarity and saves bandwidth. Content defined chunking [26] breaks the input data stream into variable sized chunks according to data contents.
The BSW algorithm establishes a window of byte stream starting from the first content to last content of a file as shown in Fig. 3. It performs file chunking, fingerprint generation and redundancy detection. It avoids the boundary shift problem by making chunk boundaries depend on the local content of the file. There are three parameters in BSW: a fixed size sliding window W, an integer divisor D and an integer remainder R, where R<D. The parameter R must lie between 0 and D-1, and usually taken as D-1. The state-of-the-art approaches to CDC for data deduplication are shown in Table 2.

Design of basic sliding window (BSW).
State-of-the-art to CDC for data deduplication
There are two problems in BSW algorithm. Firstly, it may determine the breakpoint in each shift if the file contains lot of continuous repeating string like ‘aaaaaaaa’. Due to this, the metadata size is equal to or larger than original file. The second problem is that after scanning complete file if no breakpoint detected then whole file as a chunk will be treated.
To resolve these problems Two Thresholds Two Divisors (TTTD) algorithm [27] was introduced that takes second divisor D’, where D’<D. It has greater chance of searching the chunk boundary. In this the entire stream is to be scanned and at every position the primary and secondary divisor both compute the chunk boundary. If chunk boundary found by primary divisor D before going up to the Tmax (Maximum Threshold) then it declare a breakpoint, otherwise, the breakpoint is determined by secondary divisor D’.
Some of the CDC algorithms help to find the more redundant data in less time. Ddelta [28] is one of the approaches that based on the Gear based CDC technique to eliminate the redundancy among identical data chunks. Merging the Spooking based fingerprint and Gear based chunking, it accelerate and improve the delta encoding and decoding processes. It also utilize content locality of redundant data to search more duplicate. The wide research is the field acknowledges that 60% CPU overhead used during fingerprinting. Samplebyte [29] is another solution to eliminate the redundant data in the end system services. With equivalent gain it gives fast fingerprinting. To synchronize the commercial system services the novel approach Quick synchronization [30] is presented to shorten the synchronization time.
A fast and efficient approach is developed by Wen Xia et al. [31] to implement the gear based content defined chunking. Fast CDC is approximately 10 times faster than Rabin CDC (BSW) and 3times faster than AE, but deduplication ratio of fast CDC is same as of Rabin [32] CDC means redundant data detection in both fast CDC and Rabin CDC is same; only computation overhead decreases in fast CDC. This new approach is the combination of fast gear CDC and the cut point skipping CDC. The first step is to perform the hash judgment by finding the hash value and then compare with previously stored value to find out the chunk cut point. After finding the sub minimum chunk next step is to accelerate the speed of Gear based CDC by skipping the sub minimum chunk. The final step is to normalize the chunk size distribution to a specified region that is larger than the minimum chunk size. Rabin CDC is time consuming because it computes and judge the Rabin fingerprint [33–35] of the data byte by byte.
In order to speedup the CDC process, other hash algorithms had been proposed to replace the Rabin algorithm for CDC such as sample Byte, Gear and AE. But gear based CDC and AE CDC deduplication has potential problem of low deduplication ratio means data redundancy detection is less, therefore, differential evolution based optimization using bucket indexing has been proposed to speed up hash judgment by reducing computing operations time with increasing deduplication ratio and throughput. So differential evolution based data deduplication using bucket indexing will be 16 times faster than Rabin CDC, 5 times faster than AE and 1.6 times faster than Fast CDC. Even more, DE based approach have higher deduplication ratio by detecting maximum redundancy from data streams. Whereas fast CDC and AE have approximately same deduplication ratio as of Rabin CDC (BSW).So the proposed DE based data deduplication approach is faster as well as with more DR and throughput when analyzed with existing deduplication techniques.
In this work, an Optimized Two Thresholds, Two Divisors (TTTD-P) algorithm with optimal parameter values using the “Differential Evolution” function has been proposed. The main function of this algorithm is to detect more duplicate content in the DataStream. The TTTD algorithm uses the minimum and maximum threshold values to detect the duplicate content. An enhancement in TTTD is TTTD-S, it has a switch value that takes the average of minimum and maximum threshold so that the duplicity detected more efficiently. Based on TTTD and TTTD-S algorithm, an improvement in the TTTD algorithm has been proposed that detects the more duplicity than the TTTD and TTTD-S. In this paper the comparative analysis of Rabin CDC, TTTD, AE, FAST CDC and TTTD-P in the HDFS environment have been done. The variable size chunk hash value is computed by SHA-1 [10].
A. Two Thresholds, Two Divisors (TTTD) Algorithm: In BSW and TD algorithm, the maximum threshold value cause chunk to vary greatly in size. The small sized chunks increase the quantity of chunks that results to be memory overhead. Two Thresholds Two Divisors is combination of Small Chunk Merge (SCM) and Two Divisors (TD) algorithm. The TTTD algorithm [26] uses four parameters D (Primary Divisor), D’ (Second Divisor), Tmax(Maximum Threshold), Tmin(Minimum Threshold) as depicted in Fig. 4. To control the variance in chunk size, minimum and maximum threshold is to be set. The second divisor is half of the primary divisor.

Rolling hash computation in TTTD.
B. Two Thresholds, Two Divisors with Switch (TTTD-S) Algorithm: An improvement in TTTD algorithm is TTTD-S that eliminates the disadvantage of TTTD algorithm [27]. A new parameter switch is added that takes average of minimum and maximum threshold. It switches the value at specific position. The new parameter is known as average parameter. When the algorithm points to average position, the value of main and second divisor is halved. After that it points to original value once the breakpoint is found. It reduces the computation time and avoids unnecessary comparisons and calculations.
C. Two Thresholds, Two Divisors with Optimal Parameter (TTTD-P) Algorithm: To detect more duplicity in the data we have proposed an improved of TTTD and TTTD-S algorithms. It maximally detects the duplicate content by using the optimal parameter. Procedure for TTTD-P algorithm is shown in Fig. 5. The optimal parameters are found by differential evolution. Differential Evolution (DE) is proposed by Rainer Storn and Kenneth Price for optimization problem [36]. It is considered as one of the most powerful evolutionary algorithm for the real number function optimization nowadays.

Procedure for the TTTD-P algorithm.
An initial mutant parameter vector
Where, F is a positive scale factor, effective values for which are typically less than one. The difference between two population members (a, b) is added to a third population member (c). The result (Z) is subject to mutate with the candidate for replacement to obtain a proposal. The basic algorithm of ‘Differential Evolution’ contains the following procedure:
To optimize the function with D parameter, the size of population is initially declared. The step by step procedure of differential evolution is shown in Fig. 6. Differential evolution [37, 38] is four step procedures using Equations 1 to 8.
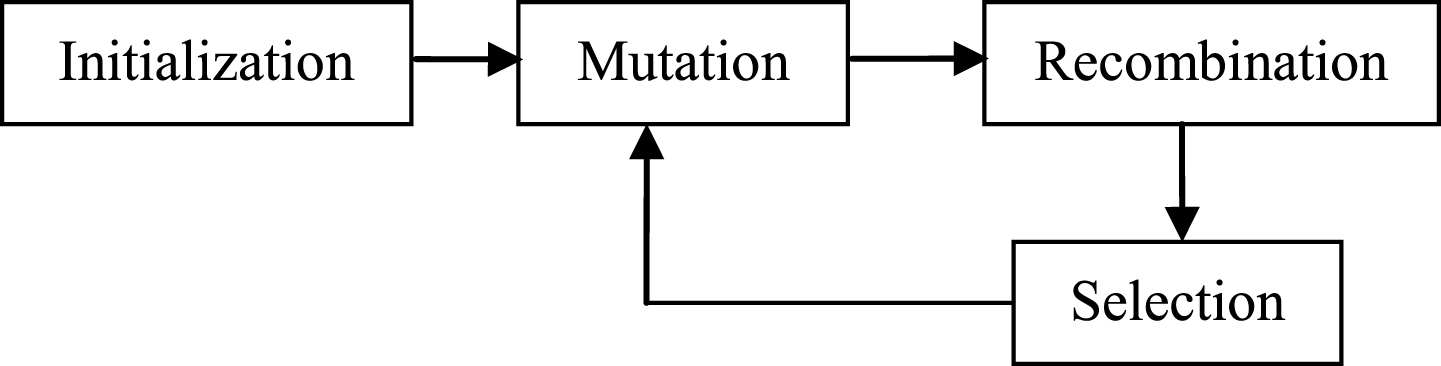
1) Initialization: A random vector is generated in the initialization phase in the interval
Where Xr1,G, Xr2,G and Xr3,G are three distinct candidate solution picked randomly among population.
2) Mutation: Elaborate the search space for the given parameter vector Xi,G by adding three vector Xr1,G, Xr2,G, and Xr3,G such that the indices I, r1, r2, and r3 are distinct. Add the difference of weight of two vectors to the third vector.
Where Vi,G+1 is called donor vector.
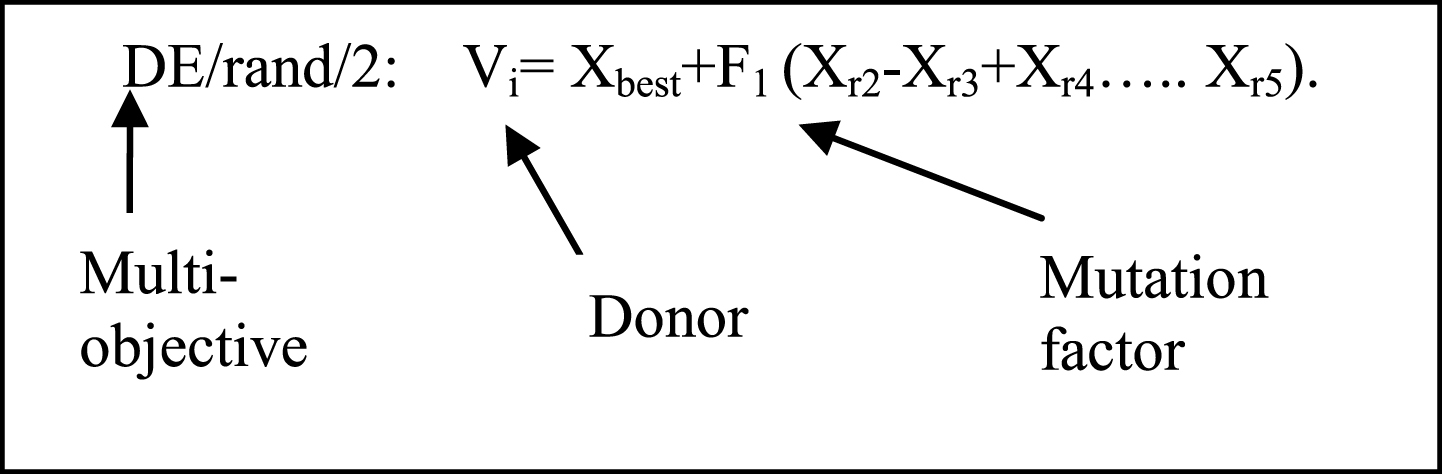
3) Recombination: It pursuit successful solution from the previous generation with current donor. The Vi,G+1 finds from the target vector, Xi,G and the element of donor vector Vi,G+1 with the probability CR.
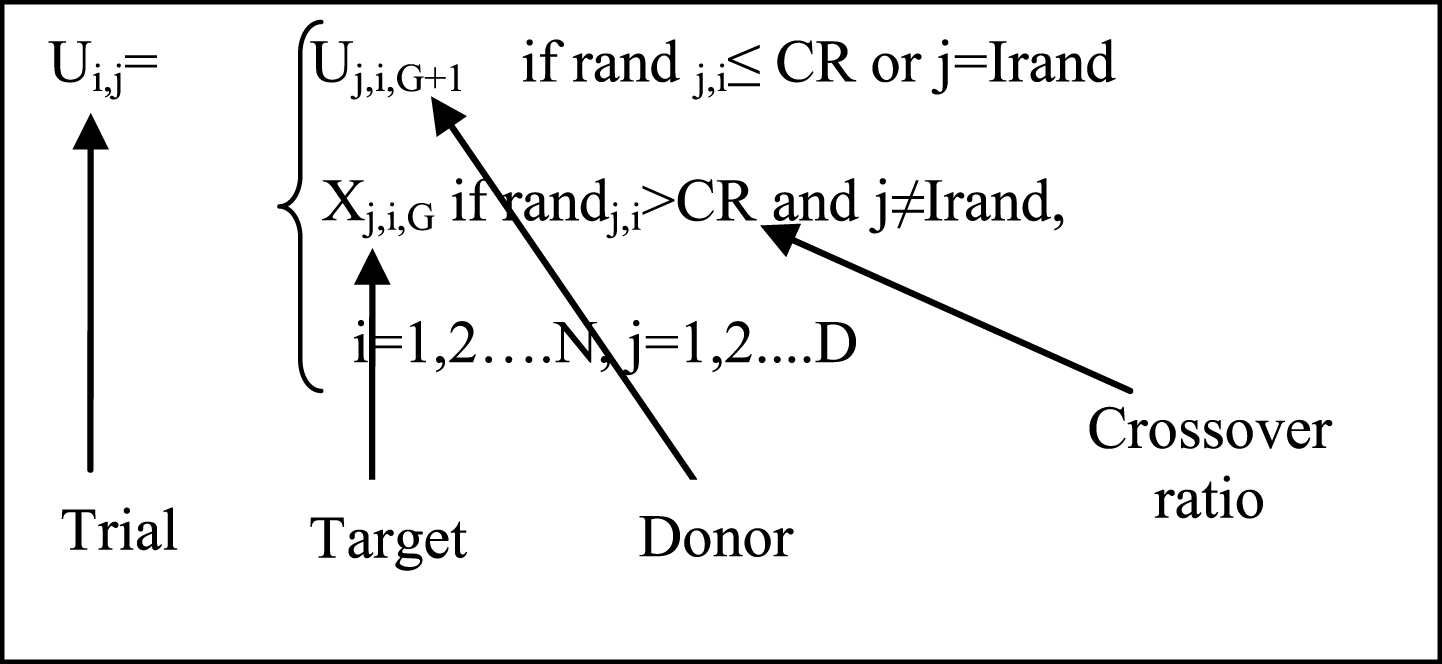
4) Selection: In the selection phase the target vector Xi,G is compare with the trial vector Vi,G+1 and the one with the lowest function value is permit to the next generation. Greedy approach is key idea for fast convergence of DE. Mutation, recombination and selection continue until some stopping criterion is reached.

The differential evolution algorithm [39] involves loops. The outer loop mentions the stop criteria and the inner cycle point out the each individual in a generation with probability CR.
The basic framework of proposed work is shown in Fig. 7 and differential evolution pseudo code is given in Fig. 8. The input data is given to the deduplication system. The working of whole process is divided into following steps:

Framework of proposed work in HDFS environment.

Differential evolution pseudo code [44].
1) Chunking: The input file is divided into variable size chunks using the two threshold two divisor with optimal parameters. These parameters are searched by the differential evolution. With differential evolution the values of divisor and threshold is carried out as optimized values.
2) Hash Value Generation: SHA-1 is used to calculate the hash value of each chunk. In some cases the MD5 generates the same hash value of different chunks that creates the confusion and affects the performance. SHA-1 is used to create secure collision-free unique hash values of data chunks.
3) Redundancy Detection and Elimination: Generated hash values are stored into corresponding bucket from bucket 0 to bucket 9 and bucket A to bucket F by measuring left most digit of hash value i.e. 9aca34 ... .ef, 4ade923 ... cf, b23a3ce ... cd1 hash value in bucket 9, bucket 4, bucket B respectively based on bucket indexing [46]. Duplicate hash values are to be detected and then eliminated by Map and Reduce function. During a MapReduce [40] job, Hadoop sends Map and Reduce tasks to appropriate servers in the cluster.
Input data stream is read by mapping function. With the help of “Two Thresholds, Two divisors” with Optimal Parameters (TTTD-P) the input data stream is broken into variable size chunks in chunking stage using fast BUZ rolling hash function [44] due to its lighter CPU overhead than Rabin hash in sliding window based CDC. Store the chunks and generate the hash values of each chunk by using SHA-1 hash values generator.
Read the hash values of all chunks. Identify unique hash values which give non redundant chunks and store all hash values of complete Big Data streams chunks in 16 buckets based on left most bit of hash value (0 to 9 and A to F). Eliminate duplicate chunks by comparing the new hash values with the previously stored hash values in buckets just by comparing with concerned bucket on basis of left most bit of hash value of a chunk. Store only non-redundant data in the distributed storage systems.
In this section, the experiments are performed to evaluate the performance of Rabin CDC,TTTD,AE, FAST CDC and TTTD-P as per experimental setup given in appendix-A. Proposed algorithm DE based Bucket Indexed data deduplication is implemented in Python [47] and Java [51] language to reduce computing operations in less time. Three big datasets from freedb [41] have been taken to perform the experimental evolution. Tables 3 and 4 show experimental results of CDC with three Big Datasets. The experiments are tested on HDFS environments with following configuration:
Minimum chunk size, maximum chunk size and optimal parameter for big datasets by TTTD-P
Minimum chunk size, maximum chunk size and optimal parameter for big datasets by TTTD-P
Big datasets (Text, PDF, Audio, Video, TAR, LNX, WEB) three real-world datasets
Matrices are used to evaluate the performance for data size after deduplication, duplicate data size, deduplication ratio, hash judgment time and throughput as shown from Figs. 10 to 14.

Bucket indexed data deduplication.
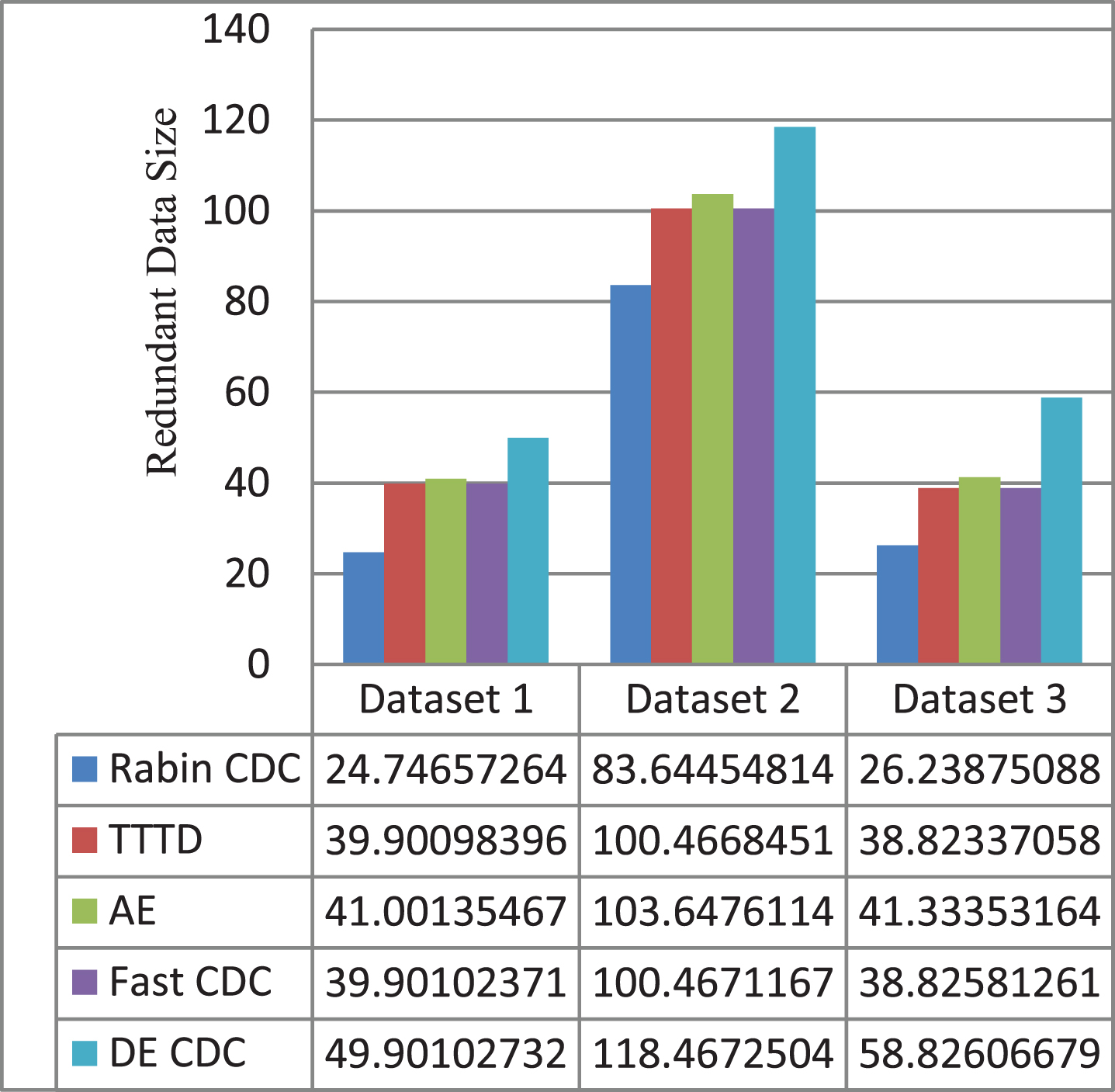
Redundant data detected in five CDC algorithms for different datasets.

Data size after deduplication of five CDC algorithms for different datasets.
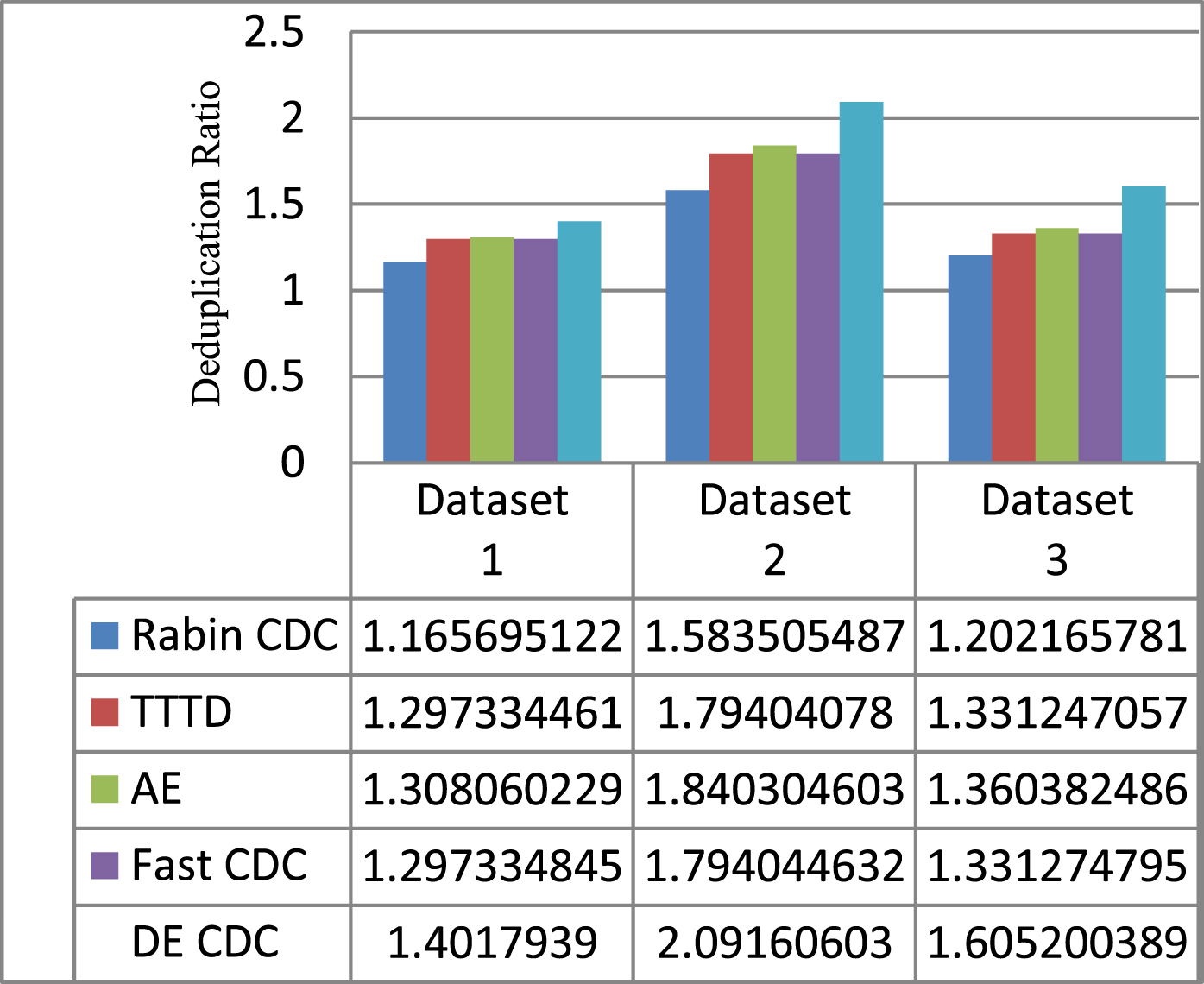
Deduplication ratio of five CDC algorithms for different datasets.
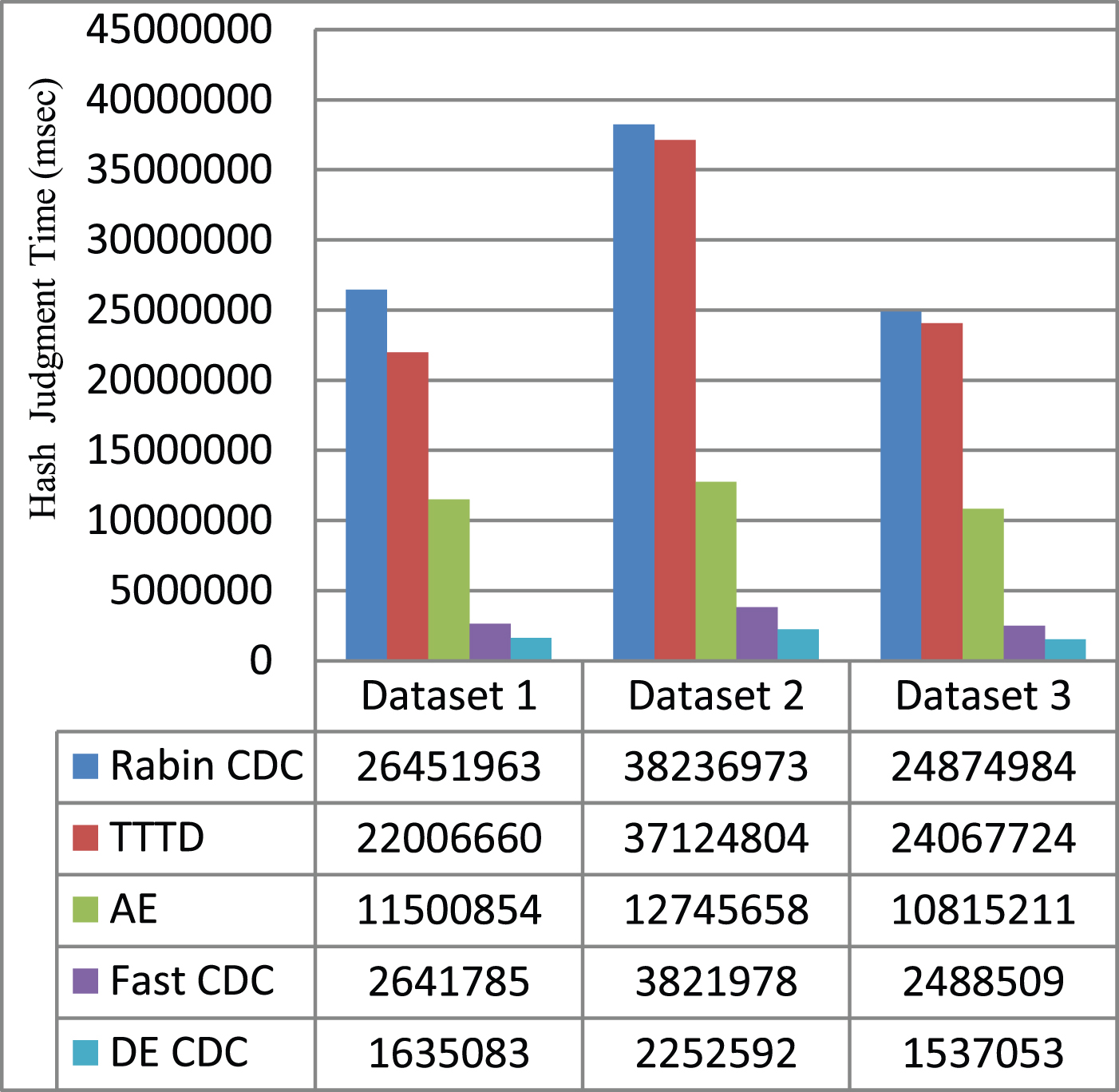
Hash judgment time (milli seconds) of five CDC algorithms for different datasets.
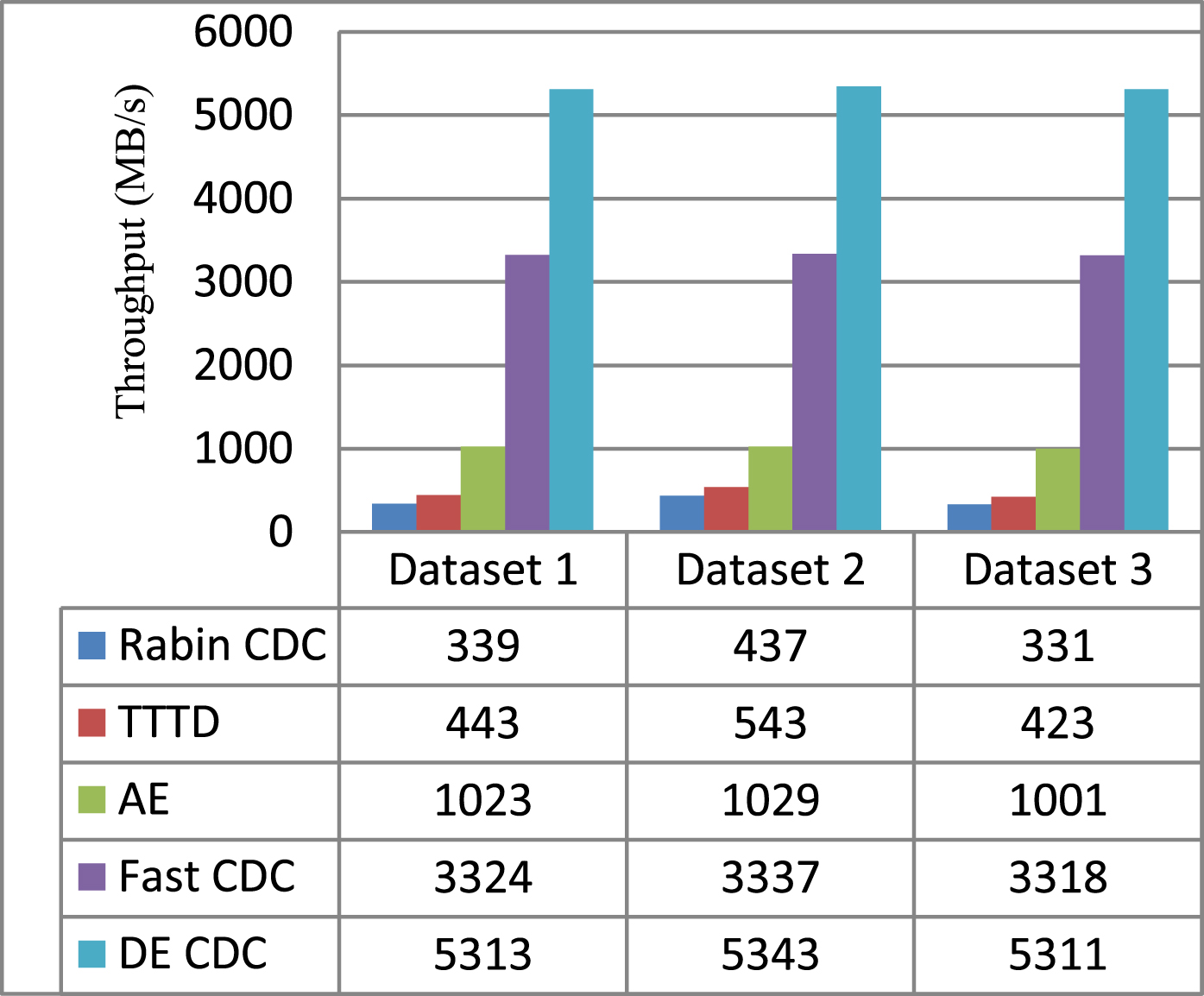
Throughput of five CDC algorithms for different datasets.
A. Deduplication Elimination Ratio (DER) or Deduplication Ratio (DR): The overall deduplication ratio is defined as input data size before deduplication divided by output data size after deduplication.
B. Deduplication Time: Deduplication time is the time required by deduplication technique to give output response. Firstly, chunking step – (1) Hashing in which fingerprints of the data contents are generated using BUZ fast rolling hash function instead of heavier CPU overhead of Rabin hash. (2) hash judgment in which fingerprints are compared against a given value to identify and declare chunk cut-points. Secondly, chunks hash values -Bucket Indexing in which SHA-1 hash values of chunks stored bucket wise in 16 buckets based on left most digit of hash values. Thirdly, data redundancy elimination – new data chunk hash value is compared based on left most digit of hash value with stored hashes in corresponding bucket (Bucket 0 to Bucket 9 and Bucket A to Bucket F). If it is found in bucket then declared as redundant chunk; otherwise store data chunks in storage systems.
C. Throughput: Throughput is a measure of how many units of information a system can process in a given amount of time. In data deduplication, throughput is the amount of data deduplicated in a given period and typically measure in bits per second (bps), megabits per second (Mbps) or gigabits per seconds (Gbps).
A good hash function BUZ [43] have a uniform distribution of hash values regardless of the hashed content best for bucket indexing by providing probably equal chance to all hash values with left most digit from 0 to 9 and A to F and uses far fewer calculation operations than Rabin, Adler, Gear and Fast CDC [31].
Table 4 shows the datasets used by our experiments. Dataset 1, Dataset 2 and Dataset 3 are real datasets [41], whose sources are the web servers and mail servers.
TTTD-P: DE Based Bucket Indexed Data Deduplication
Chunk Number -Chunk Size(Bytes) – Chunk Hash Value
87c: 1 - 676 -3ae22186413cc736b4c420223de515b2e1252b26
88c: 2 -1636 -f59430417084ef91008299282263fc50a3966d46
87c: 3 - 886 - f26e3062370dc0fa30cb50a7ab5ea9e201b9f2f7
87c: 4 - 474 - 5793b177475e878572825c1f3f9f84118ea1d744
88c: 5 - 1021 - 100794ef4f5cffb6b6728dacfa7061b534585f02
87c: 6 - 486 -099b7728385941fd456d87c9769acd0b037d387b
87c: 7 - 521 - e8a34d33e84275f5e709a6ee52e5e3924f58a37f
88c: 8 - 2800 -90652fe41310a8f0127efb2a9a4cd29550557597
88c: 9- 2043 -a10689dd73c3bee45ee830cd23e6fdd3810b2cd7
89c: 10-2386-aade71a6140077e7a2ba91dcbb5e57b00d59a078
89c: 11- 2298 -999fa5343b5b6995b72a00ffc2d084d27adb24fe
89c: 12-2286 -172ab3c7b6d2c5123a414009ca0530e4c8cc6e07
89c: 13-2178 -be4efaa094ea7cca03996c9d63ab4715370252e3
and so on.
Bucket Indexing: The deduplication technology is mainly on disk-based permanent storage to enhance space efficiency. But traditional approaches are facing two major problems. First technical challenge is the duplicate-lookup disk bottleneck and second major challenge is storage node island effect. Traditional approaches store a complete index of data chunks. Therefore, the index becomes too large to store entire hash values while big data volume is increasing. In this scenario, it is very difficult by deduplicate process to lookup fingerprints in an on-disk index and hence degrades the overall performance of the system. The second issue is of storage node island effect to remove duplicates within primary or backup storage but not in distributed multiple storage nodes. Two recent famous papers on indexing issues for data deduplication DDFS [48] and Sparse Indexing [49], proposed novel strategies to eradicate the duplicate-lookup disk bottleneck by exploiting hash values localities in disk-to-disk I/O operations. However, traditional approaches are not in speedup, scale up and size up performance. To overcome the drawbacks of the traditional deduplication indexing approaches, a scalable very high throughput bucket indexing approach for distributed storage systems has been proposed as shown in Fig. 9. Suppose there are 96 hash values generated for 96 chunks of a given DataStream. A good hash function must have a uniform distribution of hash values regardless of the hashed content. Bucket indexing approach has scalable 16 buckets i.e. B-0 to B-9 and B-a to B-f which store hash values by measuring left most digit of hash value to corresponding bucket such as bucket B-a will store only hash values whose left most digit is ‘a’. During hash judgment hash values are compared against stored hash values to identify and declare redundant chunks. So a new chunk hash value will be compared only with stored hash values in a particular bucket instead of with all stored hash values. For example, a hash function generates uniformly equally distributed 96 hash values for 96 variable-size chunks means approximately 6 values for each having left most digit ‘0’ to ‘9’ and ‘a’ to ‘f’. During bucket indexing, a new chunk hash value will be compared only with stored approximately 6 hash values in a particular bucket instead of with all 96 hash values as in earlier techniques of hash judgment to identify and declare redundant chunk. Thus, it reduces hash judgment comparison 16 times approximately than previous Rabin CDC resolves the issues efficiently for big data storage systems.
Proposed bucket indexing logic requires same storage space without extra cost as earlier by all generated hash values without bucket-wise; but drastically reduces hash judgment time 16 times significantly to identify and detect redundant chunks. The results are shown in Table 5.
Index and locality reads
It is clear from Table 5, the Summary Vector, Locality Preserved Caching and Bucket Indexing have an astounding reduction in disk reads. Summary Vector (SV) [48] has disk I/Os reduction approximately 16.51% for 328,613,502 data chunk segments. The Locality Preserved Caching (LPC) [49] has disk I/Os reduction nearby 82.43% for 328,613,502 data segments. Proposed Scalable Bucket Indexing (BI) with high throughput alone reduces about 93.75% of the index lookup disk I/Os for distributed storage nodes for 328,613,502 data segments as shown in Fig. 15.
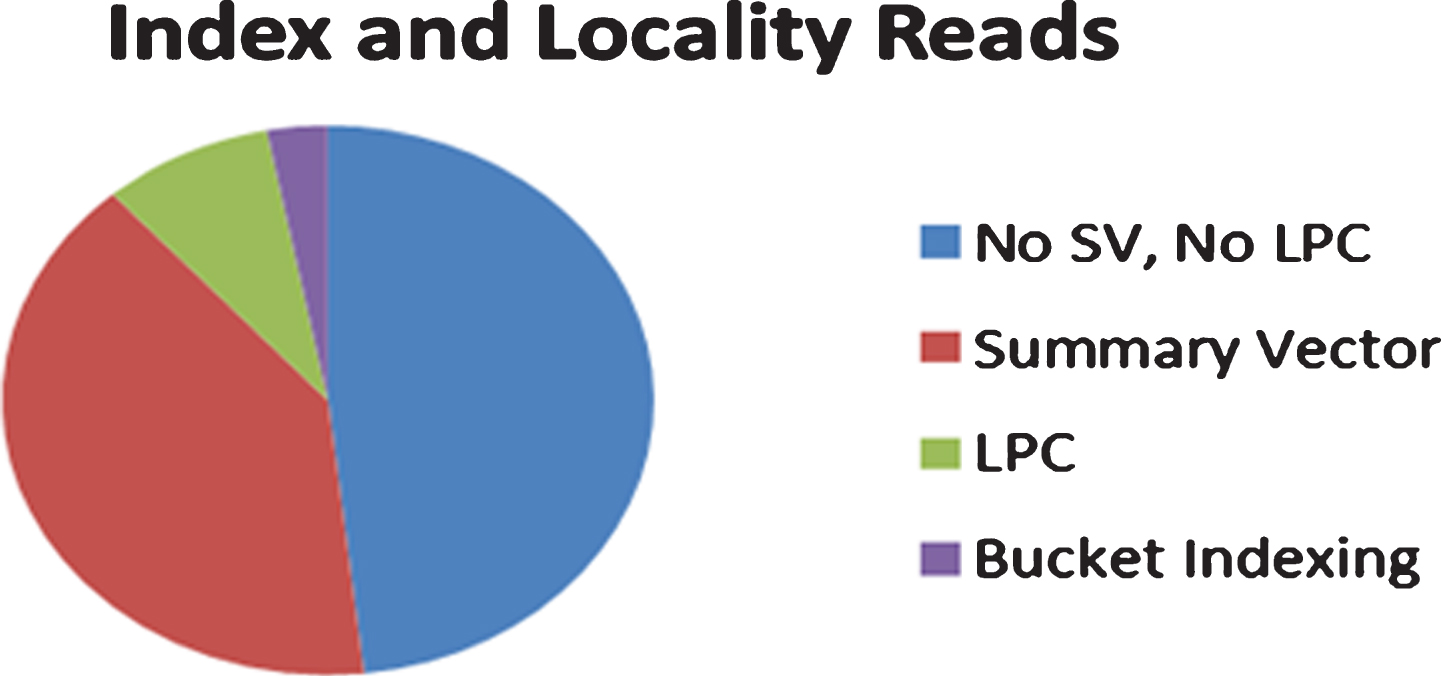
Disk reads for index lookups for SV, LPC and BI.
Significance: The main goal of this research is redundant data reduction to increase storage space with fast indexing for big data storage systems using optimization. Main contribution of this research is: redundant data reduction at chunk-level deduplication solves boundary-shift problem of fixed-size chunking fast indexing to reduce disk reads I/Os operations maximum elimination of duplicate data higher deduplication ratio and chunking throughput reduce computation overheads.
Application: Data deduplication is mainly to eliminate the extra unwanted copy of data that are not required but occupied the space. In this process, the data is to be analyzed to identify the redundant chunk and then eliminate the redundant data from the datasets. Consider an email server that contains 100 instances of the same 1 MB file attachment, say, a sales presentation with graphics that was sent to sales staff. Without data duplication, if everyone backs up email inbox, all 100 instances of the presentation are saved, requiring 100 MB storage space. With data deduplication, only one instance of the attachment is actually stored; each subsequent instance is just referenced back to the one saved copy, reducing storage and bandwidth demand to only 1 MB.
Deduplication workflow in chunking stage renders the performance bottleneck due to high computational overheads of existing CDC algorithms. Execution of judgment function on every byte by slow Rabin sliding window-based CDC algorithms carries heavy computing overhead and duplicate-lookup disk bottleneck due to large size of data index motivated for this research for further optimization using differential evolution optimization with BUZ as fast hash function and bucket indexing to reduce computational overheads of existing CDC algorithms. In this paper, differential evolution based bucket indexed data deduplication for big data storage systems has been proposed, a much faster CDC algorithm achieving higher deduplication ratio with increased chunking throughput in very less time with minimum disk I/Os operations than the state-of-the-art algorithms. To strengthen the superiority of DE based bucket indexed data deduplication, we present two optimizations - one with DE based optimization offering higher deduplication ratio with increased chunking throughput in very short time to provide more storage space for incoming big data streams, and second with bucket indexing based optimization with high throughput alone reduces about 93.75% of the index lookup disk I/Os for distributed storage nodes. As it has been verified and illustrated through experiments on three real-world datasets, DE based bucket indexed data deduplication significantly reduce the computing overhead with increased DR in less time. To resolve the issue of slow Rabin rolling hash in the proposed algorithm, the slow speed role has been replaced by fast BUZ rolling hash. The analysis and the experiments show the authenticity as an appropriate replacement. Furthermore, experimental results show that bucket based fingerprint indexing approach reduces computation hash judgment time about 16 times than Rabin CDC, 5 times than AE CDC, 1.6 times than FAST CDC. DE based bucket indexing TTTD-P algorithm, not only successfully achieves the significant improvements in data deduplication and average chunk-size; but also obtains the better controls on the variations of chunk-size by reducing the large-sized chunks in less computation time. The experimental results substantiate our analysis that is able to shift the performance bottleneck from chunking stage to indexing stage improve the system performance.
Conclusion and future work
This paper presents optimization of chunking and indexing stages of deduplication technique to substantially reduce disk I/Os in high-throughput deduplication storage systems while achieving a comparable high deduplication ratio. The main idea behind DE based bucket indexed data deduplication is the combined use of optimizing chunking with fast hash judgment and fast indexing for minimizing disk I/Os to achieve good deduplication performance efficiently. The experimental evaluation demonstrates that DE based bucket indexed optimized data deduplication obtains a chunking speed 16 times faster than Rabin based CDC, 5 times faster than AE CDC and 1.6 times faster than FAST CDC with an astounding reduction in disk reads with higher throughput alone reduces about 93.75% of the index lookup disk I/Os for distributed storage systems.
This research work has focused on the chunking and indexing stages of data deduplication. There are still many related problems that need further investigations. For instance, the hash-based data deduplication systems have a major issue of hash collision problem. Another interesting research topic is about fast indexing the metadata to speed up the lookup table of big data. Finally, the security challenge of hash-based deduplication cannot be avoided. In our future work, we plan to incorporate DE based bucket indexing architecture for big data storage systems on fast Spark Distributed File System (SDFS) platform to explore the potentials and benefits of fast DE based optimized data deduplication.
Footnotes
Appendix – A
Experimental Setup
| Chunking | Main Divisor D | Backup Divisor D’ | Fingerprinting fp mod D = R | Speed |
| BSW | 1000 | No | Rabin | Slow |
| BFS | 1000 | No | Rabin | Slow |
| TD | 1200 | 600 | Rabin | Slow |
| SCM | 540 | No | Rabin | Slow |
| TTTD | 540 | 270 | Rabin 16-bit Incremental | Slow |
| TTTD-S | 1600 | 800 | Rabin 16-bit Incremental | Slow |
| TTTD-P | Optimal DE (D,T) | No | BUZ 32-bit Rolling Hash | Very Fast |
Acknowledgments
We are grateful to the anonymous reviewers of this paper. For this research, we would like to show gratitude to Prof. Rohitashwa Shringi (and specially his wife Dr. Pramila) Mechanical Engineering department of Rajasthan Technical University, KOTA for their support, valuable advice, motivation and encouragement. We would also like to thank Prof. S.C Jain Rajasthan Technical University, Kota for guiding this research work with valuable suggestions time to time.