
Abstract
Based on the analysis of campus cloud storage requirements, the paper plans a cloud storage structure model to achieve the goal of breaking the bottleneck of traditional campus network resource utilization. The model established in the thesis fully considers the problems of cluster data security and big data analysis and utilization, and proposes an optimization scheme for cloud storage open platform system design. Plan the HDFS + HBase distributed storage deployment in the Hadoop cluster, elaborate the process of behavior analysis, and find a way to optimize and improve the cloud storage in colleges and universities. HBase technology implements operations on HDFS distributed storage systems in Hadoop clusters, effectively improving the efficiency of resource access and resource analysis. The cloud platform storage platform designed by the thesis solves the problem of integrating the superior resources of colleges and universities.
Keywords
Introduction
With the development of cloud computing technology, the university and major universities have vigorously researched and developed campus cloud application products, and can improve the communication efficiency between teachers and students in the new teacher-student interaction platform. As a digital information resource integration, the cloud storage platform uploads the files to be stored to the network space by a variety of technologies and services [1]. Cloud storage uses the I/O data stream to perform data operations on the distributed storage system [2], which integrates the campus educational management system with the office system, thereby effectively improving data access speed, and is highly scalable and transportable. The characteristics of the rate can meet the requirements of efficient storage of campus data [3].
Hadoop originated from Apache Notch, an open source web search engine, a software framework for distributed processing of large amounts of data [4]. The existing campus cloud storage platform mainly uses the Hadoop Distributed File System (HDFS) to manage the state of the cluster. The campus cloud storage platform is built to provide more personalized services for students, teachers and administrators. Management coordination and sharing [5]. This paper focuses on the characteristics of campus cloud storage requirements, plans a cloud storage structure model, and relies on Hadoop, HBase and other technologies to try to break through the performance bottlenecks, so as to achieve efficient data storage and effective analysis of behavior analysis [12–16].
Demand status of university cloud platform application
At present, some domestic universities have established their own cloud platform data centers or have moved their main services into the cloud, using object storage in their own systems. Some of the university data centers have established personal service platforms for each of their students in the data area, facing a huge user base, massive data storage and processing tasks. The user group’s data needs to be maintained. The user’s personal information, performance, social practice, shared photos, published comments, and shared content need to be stored. User access history needs to be analyzed and processed, and raw data must be extracted and fed back. For students, parents and schools. Similar problems have emerged in the e-commerce platform Amazon, the email platform Yahoo, the search engine Google, and the social platform Facebook, which are the origins of cloud technology. So how do they solve it? We analyze and learn some solutions from Internet companies to find a way to optimize and improve the cloud storage of colleges and universities.
Based on the mission characteristics of key technologies, the paper introduces some characteristics that campus cloud platform must satisfy when storing massive data. (1) The message mechanism, which needs to manage “where the message comes from, to whom it is sent” is the basis of the inbox. Not only must we provide services to users at the same time, but also the need for PB-level data throughput and long-term uninterrupted operation. The main features are high write throughput, incremental storage of data, and data migration. (2) Activity real-time analysis interface, including social network plug-ins, pages and advertisements. Through these anonymous data, you can deepen the understanding of other business users about their own situation, such as impressions, click-through rate, page visits and so on. Through this information, business users such as school departments or training institutions can improve their services. (3) The measurement system, similar to the log, needs to record the statistics of all the hardware in the system. These operations have high requirements on the number of writes, a large number of indexes and sequential write operations coupled with an unpredictable increase in the amount of data, which makes the MySQL database using sharing mode difficult to cope with, and even needs to artificially fragment the database. operating. In addition, most operations involve only the most recent data, with less access to earlier data, but must be guaranteed to be available. For example, mail service, message service, etc. At the same time, these operations also require faster query speeds for recent data. According to the commonality of the university network, combined with the specific technical characteristics, the needs of the campus network task characteristics of the university can be summarized as follows. Agility. Due to the increasing student data and the increasing demand for service diversification, the campus cloud platform requires storage to support incremental capacity expansion of the system capacity, and requires minimal overhead from this operation while avoiding operational downtime. problem. For example, the library system to increase the online access to books and exchange services, you need to quickly increase the capacity of the system, and require the system to automatically handle the load balancing between new and old hardware, and use it efficiently. High write operation. Many applications in college cloud platforms need to store a large amount of data, which requires high write operations. Such as job submission, cloud printing, messaging services, etc. Low latency and consistent data center. The business needs a data store that guarantees consistency. For example, all university data centers across the country can exchange information, and the number of messages displayed in the system should be consistent with the actual number of visitors. However, implementing a distributed, highly consistent storage system is not possible, and it is only possible to provide strong consistent data storage when data is located within the same data center. High efficiency random reading. The business logic of the message system cannot hit the data in the cache, resulting in many random read operations that penetrate the cache layer and access the back-end database system. Range scanning. Some applications need to support efficient retrieval of collections within a certain range. For example, retrieve a student’s recent 100 message records or calculate the data of an employer’s birthday attendance for the internship in the past six months.
MySQL + Memcached and Hadoop + HBase technology comparison
MySQL is an open source database that is widely used for its lightness and simplicity. The cloud platform initially used MySQL + Mem-cached to build the storage layer. Facing the requirements of the storage system in the campus cloud platform, the storage layer of the original MySQL build could not meet the system requirements. Mainly MySQL cluster has the following problems: low random write rate, poor scalability, high management and hardware costs, and unsatisfactory load balancing [6]. These shortcomings are the system requirements brought by the massive data of the campus cloud platform. So large network companies have given up MySQL + Memcached to build storage tiers and turned to Hadoop + HBase. The main reason is that the characteristics of HBase meet the above requirements for storage systems. HBase is now able to provide key-value storage with high consistency and high write operations.
Construction of Campus Network Cloud Storage Open Platform Based on Hadoop + HBase
The paper introduces the design requirements of the cloud platform storage architecture and why Hadoop and HBase are used to implement the storage architecture. Below, we should come to the high school cloud platform to implement Hadoop and HBase applications, starting with the system framework design. To deal with a large amount of relevant data, and this large amount of data necessarily requires the network to contact, and the amount of data is always on the scale of the PB level. To handle such a huge amount of data, it is impossible to use a single server, so it is distributed.
System design
The cluster environment of the cloud storage platform is composed of seven virtual machines and is denoted as wm1, wm2, respectively . . . wm7. Each virtual machine is a node in the cluster. Among them, wm1 runs, becomes the metadata server in the cluster; wm2 runs Second Name Node as the metadata backup server; wm3, wm4, wm5, wm6 all run Data Node as the data server; deploy the campus cloud storage development platform service system on wm7. A typical user logs in to the cloud storage system through a browser or a mobile phone to perform daily operations. The cloud cluster administrator monitors the operation of the server cluster through the system monitoring dashboard. The database stores the basic information of the school, the information of the school management departments at all levels, Meta Data, etc., and other data is stored in the distributed file system. The space that ordinary users see is set by the system according to the capacity value in the database. In fact, there is no fixed space size. Users can get more capacity with upgrade privileges. The main reason for using HDFS is its highly fault-tolerant system, which is suitable for deployment on inexpensive machines. The internal mechanism is to split a file into one or more blocks that are stored in a set of data nodes. The name node implements backup to multiple nodes through the replication block, reducing the possibility of data loss.
The main task of the user layer of HDFS is to process and accept the requests sent by the client, and provide services of different interfaces according to different requirements of the application [7]. The HDFS user layer is mainly responsible for the four steps: effective management of users, management of access requests sent by the client, logical control of services stored in the campus cloud, and data filtering and processing. Handling and logically controlling the business of campus cloud storage is the communication link between the UI layer and the HDFS storage layer, and it is also the research focus of this research. The main function of the campus cloud database is to establish a data protection backup barrier to save the private information of the users in the system, the attributes of the files and the permissions. The database in the HDFS-based campus cloud storage platform will be combined with the HDFS user information. Placed in the same server, the campus network in the same area will save the application data of all users in the network (such as the files backed up by the visitors, audio and video files, etc.) and set them in the HDFS cluster. System architecture as shown in Fig. 1.

Cloud storage open platform architecture.
According to Fig. 2, the computer or server actually stored in different departments can be set as Task Tracker. The main thing he does is to monitor the resources of his own machine. Set up a set of Job Tracker as the center of the cloud platform framework in the cloud platform data center. An HDFS cluster consists of a Name Node and multiple Data-Nodes. The management, monitoring, and heartbeat detection functions of the Name Node can be placed in the cloud platform data center; while the Data Node mainly performs functions such as reading and writing data blocks, reporting status to the Name Node, and performing pipeline copying of the data blocks, and can be placed in different departments.
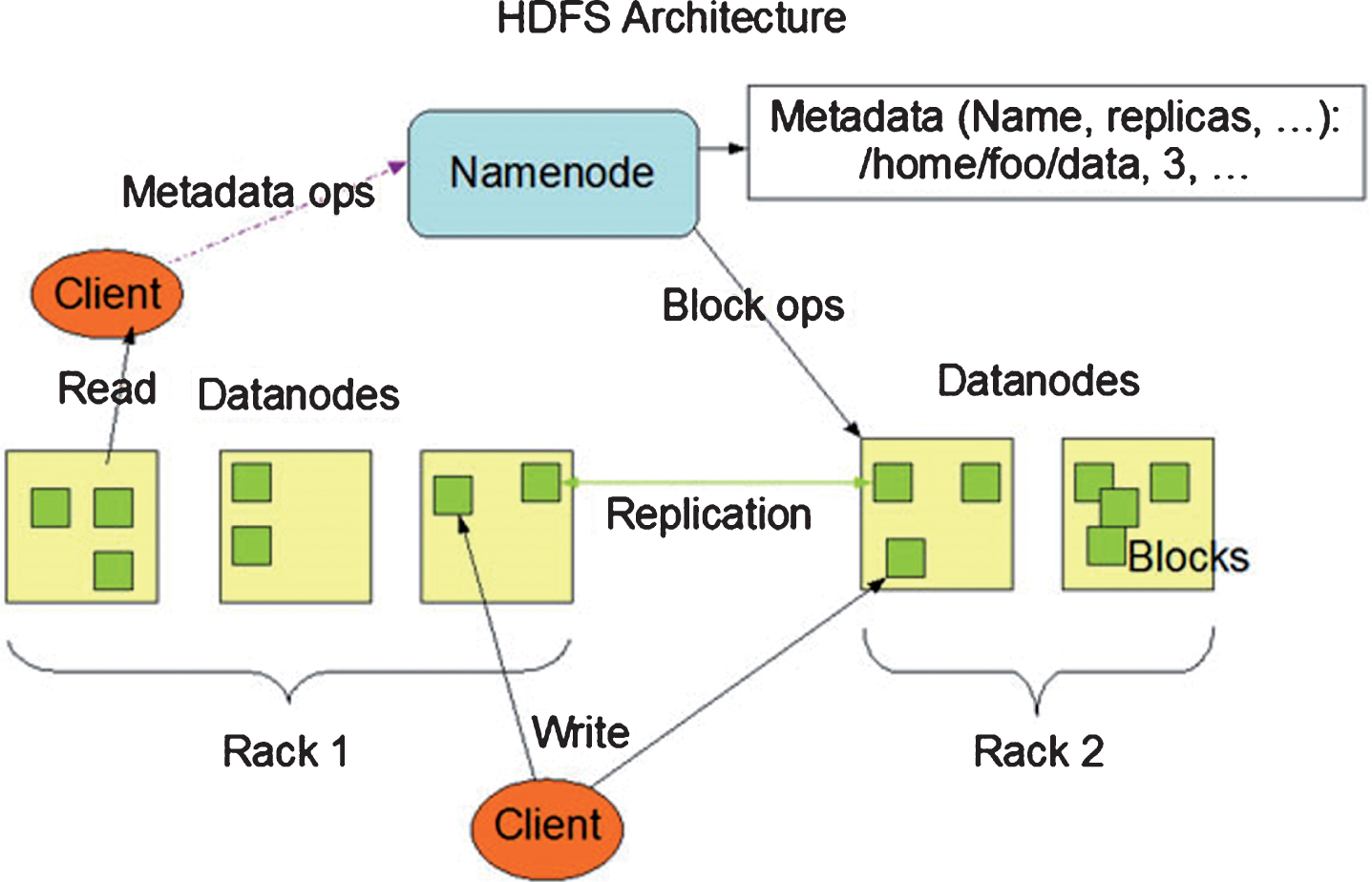
HDFS architecture.
The HDFS-based campus cloud storage system is different from the traditional e-commerce network. It can be divided into two categories according to the nature of the storage: the first category includes personal information including users, user access roles, permissions, user access logs, etc. User data within; the second type is user-uploaded documents and audio and video data information. The data stored in the HDFS-based campus cloud storage system is mainly data that is not related to the user access account, and generally includes access point number information table, advertisement delivery data table, student achievement data table, etc., all data tables. There is no cross-term between services, and the relationships between them are independent of each other. It is such natural attributes that enable vertical division of the business of these data tables. In general, most of the network type storage data devices store huge amounts of data between each other, and their relationship tables are numerous and complex [8], so the first problem to be solved in the process of designing the campus cloud storage platform of this paper is the sub-library. Faced with different horizontal distribution tables, different partitioning schemes can be designed according to actual conditions. For example, for a unique data table, there may be different hashing methods, such as single-database multi-table, single-table multi-partition, and multi-database multi-table. Wait.
Module design
In the campus cloud storage system, the HDFS user layer mainly includes two parts: logical control of the cloud storage business on the campus, data filtering and processing [9], and can be divided into campus user access and campus user access management according to the content processed by the campus. 4 modules for campus access department authority control and HDFS user cluster data information management. The modules accessed by campus users are mainly responsible for ID login of campus access users, modification and change of personal information, backup, download, sharing, and document archiving and management of campus users’ daily files. The functions of the campus user access management module are mainly responsible for the personal information management of the campus users, the online status management of the logged-in users, and the assignment of campus user home management. The functions of the campus access department authority control module are mainly responsible for the basic information setting and management between the various departments of the campus, the user and department authority management of the campus network system, and the coordination authority allocation management between the various departments. The HDFS user cluster data information management module is mainly used for campus network maintenance personnel information setting and management of slave nodes, master and slave nodes IP and quantity in the cluster, and can edit the status and tasks of users and personnel in the cluster at any time. In addition, the module has the function of alarm management [10]. The detailed hierarchical division and module functions of the background management of the campus cloud storage system are shown in Fig. 3.
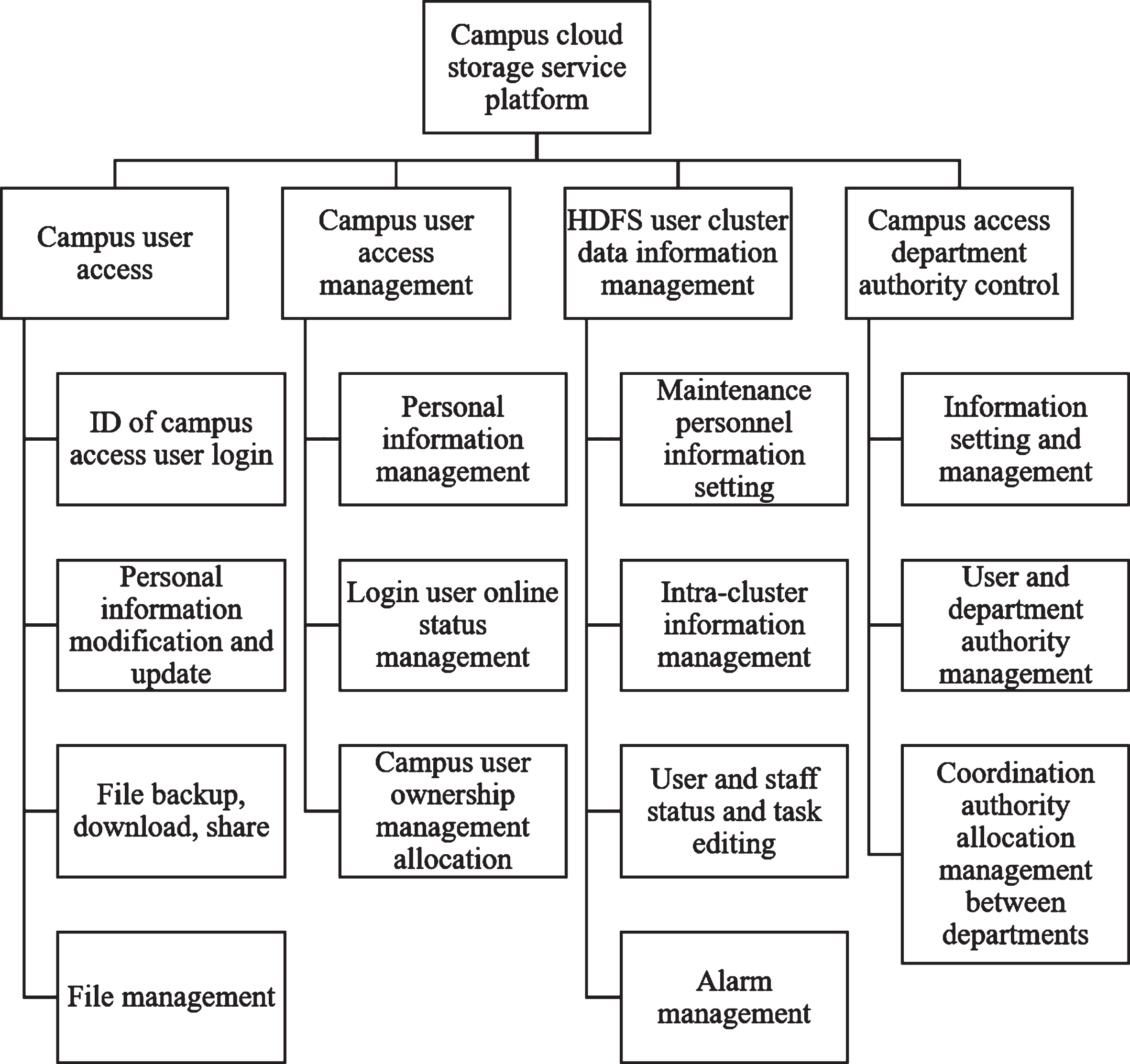
System module.
Database design is an important part of the system. After comparing MySQL, MongoDB, and HBase mainstream databases, we need HBase, which is important for Hadoop. The product, because the underlying layer relies on HDFS, has its own horizontal scalability. System database E-R model, as shown in Fig. 4. Relational databases are easier to reflect the direct connection of transactions, and the analysis data can be obtained directly from the database, but the structure stored in HBase to improve efficiency is different from the traditional relational database. For example, when doing the analysis recommendation function, user table, department table, permission table, file table, shared file table, and device table should be established. The user table has two column families: the user attribute column family and the user behavior column family, and the file table contains a column family. USER: User ip role, user ip department, user name ID. USER: access share; file number; click time. FILE: The subject to which the file belongs, the file authority, and the file belongs to the department. The file Property of the file table inserts a row health data: Put ‘FILE”, file03140566’, ‘file Property: subject’, ‘computer programming’ Put ‘FILE”, file03140566’, ‘file Property: authoritative’, ‘expert level’ Put ‘FILE”, file03140566’, ‘file Property: authoritative’, ‘Software Teaching and Research Office’

Comparison of campus cloud storage file system memory before and after optimization.
Analyze users accessing shared files and creating data: Firstly, the user first accesses the files shared by the software teaching and research section, and the platform obtains the user’s identity and IP. Then, the platform queries the operation record of the IP from the action Property from the USER table according to the user IP. If not, create a new record and save it in the two column families of USER. Save user attributes: Put ‘USER’, ’151.121.11.21’, ‘user Property: ip Role’, ‘Student’ put ‘USER’, ’151.121.11.21’, ‘user Property: ip Department’, ‘Software Technology’ Put ‘USER’, ’151.121.11.21’, ‘user Property: user Id’, ’100001213’ Save user behavior: Put ‘USER’, ’151.121.11.21’, ‘action Property: share,’/rjjys/...’ Put ‘USER’, ’151.121.11.21’, ‘action Property: file Id’, ‘file03140566’ Put ‘USER’, ’151.121.11.21’, ‘action Property: time’, ’20161030084200’
When the user enters the platform again using the same IP, the platform will get the ID of the advertisement according to the data found in the user Property column family of the user table, and then use IP to find the user’s operation record in the action Property of USER. Explain that during this time the user is interested in this software programming class file, and then find all the files of this category to push to the user. Administrators and software lab teachers can view the file visits and the distribution of visitor groups from the data platform. In the platform management console, graphically demonstrate the health of the Name Node and the number of block backups for the Data Node. The data analysis display uses D3.js to draw beautiful data analysis charts. Through the above case cloud platform, the useful data is pushed to the relevant users in the first time.
Core function implementation code: The configuration in HBase Configuration is as follows: Configuration config=HBase Configuration. create(); Config. Set (‘base. zookeeper. quorum’, master, slave1, slave2); HBase operation tool class HBaseHelper.java key code: / / Create HBase database table file Public static void creates (String table name, String column) {if (admin. Table Exists (table name)) {System. out. Print ln (‘table Exists!’)} Else {Table Descriptor table Desc=new Table Descriptor (table name); Table Desc. Add Family (new Column Descriptor (column-Family)); ... } }
In the previous cloud platform implementation example, HDFS was adopted as the Hadoop distributed file storage system, and there was only one unique Master, Name Node. The system will be unavailable when the Name Node is down. For some services in colleges and universities, we must hope to obtain stable services. Then you need to extend this part to ensure its usability. In the optimized HDFS cluster, there are two Node nodes, the primary Node (Name Node) and the backup Node, which store the HDFS file system image and the transaction log backup in a separate server FS File. After each primary Node updates the log stored in FS, the standby Node reads the update at the same time and then applies the updated transaction to its own file system image and log. The standby node is responsible for generating the detection points of the primary node, and it is necessary to periodically merge the transaction logs and create file mirrors. So, there is no Secondary Name Node in the system. The Data Node in the cluster not only communicates with the primary node, but also communicates with the backup node, so that when a failure occurs, the backup node can immediately become the active node, and the original primary node that is started later becomes the new standby node. When the file is closed or synchronized, HDFS stores the ID corresponding to the block in the transaction log. In order to minimize the time, the system simultaneously writes the block allocation operation to the log, and writes the length, ID, and school of the transaction.
The above improvements effectively prevent the impact of downtime on HDFS. There is only one Master in HBase, and there is also the possibility of data loss when a failure occurs. To avoid this, you can store the data in Zookeeper because Zookeeper uses a majority of the policies and the data is stored on multiple nodes. Set compression to interrupted operation, reducing downtime to a few seconds or so. In addition, the size of the compressed block is limited to avoid the generation of large blocks of data, thereby improving the efficiency of the network IO.
Experimental preparation
In order to optimize the design of the campus cloud storage solution proposed in this paper, the test experiment is arranged as follows: The experiment will operate the HDFS system on a physical machine and select the physical machine as the data space server of the campus operation user, mainly because of the optimization of this paper. The experiment is only for the Name Node and does not involve the Data Node. The physical machine configuration selected during the experiment is as follows: Name Node server uses six-core AMD Opteron II CPU 3.2 GHz, Kingston Beast 16GB DDR3 2400 memory, and space metadata (Meta date) server uses 16-core Intel Core i7 4770 CPU 3.4 GHz, GALAXY HOF 16GB DDR4 4000 memory. The experiment has a user-scaled step size of 50, and simulates 100 to 500 nine sets of experiments, respectively, in which each user creates 100 files and does not read and write files after creation, that is, the file size interval of each set of experiments is 10 000 to 50,000.
Memory test
In order to facilitate the comparison of the system before and after optimization, we have done several experiments, and recorded the size of the memory changes in the nodes and processes in the Name Node. The specific experimental results are shown in Fig. 4.
In this paper, the size range of the file is defined as 0∼5 W, and the metadata size is also an order of magnitude. As the file size of HDFS expands, the information of the metadata occupies a certain memory space, so the memory of the Name Node in the experiment will continue to be occupied in a linear growth. After the system optimization, the number of data sizes of the Name Node in the experiment corresponds to the number of campus users, so the number of files in this experiment has decreased by 100 times. This experiment will expand the number of memory users occupied by the data owned by the Name Node process. However, the results show that the memory loss after such expansion is not significant. The results of this experiment show that the HDFS scheme proposed in this paper can effectively reduce the loss of Name Node memory and also expand the namespace of HDFS cluster.
Read and write test
We tested the read time of the file, tested the actual file stream and metadata information, and tested the HDFS system and the HDFS creation file added to the My baits optimization solution. The result is shown in Fig. 5. It is not difficult to find from Fig. 5. When the optimized scheme is used to read and write metadata in the Name Node, the speed of reading and writing metadata information is greatly improved. From the perspective of the actual data block write, we found that the optimized solution reduces the read and write speed when reading and writing metadata in the Name Node. This may be because the HDFS system cannot provide sufficient support for file operations. From the perspective of the speed of reading metadata information, we can find that the optimization of the scheme is realized by introducing the framework of My baits, and the speed of reading metadata information of HDFS can be effectively improved.

Read and write test comparison.
Cloud storage technology has brought significant changes to the construction model of data platforms in domestic universities. Universities will no longer need to purchase hardware facilities separately. Just customize the corresponding storage management solution from the cloud computing data center according to their own conditions, and they can get stable data services from the cloud storage platform. HBase technology implements operations on HDFS distributed storage systems in Hadoop clusters, effectively improving the efficiency of resource access and resource analysis. It is predictable that with the continuous development of cloud computing, big data technology and cloud storage technology, the campus network of colleges and universities will also develop and improve rapidly. The realization of cloud platform storage solves the problem of integrating the superior resources of colleges and universities, and better serves the campus and society.
Footnotes
Acknowledgments
[1] Scientific Research Platform of Chongqing University of Education, Big Data practice platform for sports and health based on Campus IOT, NO.2017XJPT07.
[2] Chongqing Key Research Base of Humanities and Social Sciences ‘Chongqing Research Center of Overall Development of Urban-Rural Teachers Education’, Research on Post-service Training Management and Programme for Primary and Secondary School Teachers in Chongqing Based on Big Data, NO.18JDZDWT04.
[3] Project supported by the key issue of Chongqing Education Science “13th Five-Year” Plan in 2018, Research and Practice of Intelligent Classroom Construction Based on Internet of Things and Big Data, NO.2018-GX-017.