
Abstract
Link prediction is the problem of inferring future interactions among existing network members based on available knowledge. Computing similarity between a node pair is a known solution for link prediction. This article proposes some new similarity measures. Some of them use nodes’ recency of activities, some weights of edges and some fusion of both in their calculation. A new definition of recency is provided here. A supervised learning method that applies a range of network properties and nodes similarity measures as its features set is developed here for experiments. The results of the experiments indicate that using proposed similarity measures would improve the performance of the link prediction.
Introduction
Immense real-world social networks exhibit a range of interesting properties [2, 15]. One of the noteworthy approaches in this line of research is to design models that predict the global structure of network [2, 19].
Social networks are highly dynamic; they grow and change quickly through new interactions of the nodes in the network. Therefore, studying these changes at individual edge creation level is intriguing. Identifying the mechanism through which the new individual edges are added to the network is a fundamental research challenge. This challenge is called link prediction problem [9].
The study of networks to predict the upcoming links has beneficial applications in researches and organizational context in a variety of fields. Link prediction can help inferring the missing links from a network [10]. This issue can improve the security of the network by allowing one to assume the unobserved interactions among particular nodes [13]. Another application of link prediction is to predict the friendship or participations of actors in social networks [15].
To solve the link prediction problem, it needs to determine the probability of formation or dissolution of links. Usually, such probability is measured by similarities. There are many generic similarity measures, which use information of nodes and social network topology. Liben-Nowell and Kleinberg have discussed several metrics based on the graph structural features [15], after their work, many topology-based metrics were proposed [23, 36]. These similarity metrics are commonly applicable in online social networks because of their tolerable computation time complexity [34]. Most of the available studies in this field lack of considering time factor in similarity measures computations.
A few studies consider temporality of similarity measures with introductory definitions of recency [27, 35]. The former recency definitions do not discriminate new added nodes and the most recent active nodes. These former definitions do not consider recency of communications received by nodes too.
This article will discuss the impact of applying recency of nodes interactions on link prediction. A new definition of recency of nodes is greatly emphasized in this article, which considers both send and receive communications and includes timestamps of previous interactions. This recency was applied to propose some new similarity measures based on well-known classic similarity measures. The experimental study shows that applying recency of nodes significantly improve prediction capability of models.
Additionally, many improved versions of classic similarity measures are proposed in this article. These improvements focus on considering weights of links in the network and fusing recency and weights in similarity measures computations. Various aspects of applying these similarity measures and their impacts of prediction task are examined in an experimental manner. A supervised learning experiment framework is applied which considers different classifiers. The experiments indicate that applying recency of nodes alongside weights of edges would promote similarity measures too.
The literature review
The issue of link prediction in social network is a general concern consisting of several topics.
Link prediction problem
According to Liben-Nowell and Kleinberg a classical definition of link prediction is: “Given a snapshot of a social network at time t, we seek to accurately predict the edges that will be added to the network during the interval from time t to a given future time ” [15]. This issue can be considered as a problem of supervised learning models, the objective of which is to predict existence of edge between a pair of nodes [11, 16]. Link prediction problem is considered as a supervised learning solution subject of the study on the contributions to various properties of network structure.
There exist various studies on this problem. The link prediction learning method can be divided into two broad categories: a) link prediction based on unsupervised learning methods [1, 26], and b) link prediction based on supervised methods [11, 31]. More studies are conducted on the category (a) and have become restricted due to heavy data load, have their weaknesses. The category (b) provides capabilities to improve link prediction results with more accuracy [16]. In this article, category (b) will be investigated and as a result a new method is proposed for link prediction of evolving online social network.
Most of the real world social networks data are immense and are presented in graph formats. Majority of the link prediction researchers applied classic datasets like co-authorship for their experiments [11, 16]. But real world social networks graphs are sparse and encounter class imbalance problem. In [16], the authors apply some classic methods to overcome the existing class imbalance. An adjustment of a number of samples in dataset is made in this article to have more realistic results.
Different classifiers’ results are investigated on link prediction problem by [11]. Although in [16] studied some factors regarding classification process improvement. Different similarity measures could be applied as the classifiers feature sets. The prediction results of models trained through these feature sets are applied in evaluating similarity measures. Some innovations are proposed in this article to improve classification by applying some innovative parameters as classification feature sets.
Nodes similarity
There exist different approaches to calculate similarity of nodes in several articles. The similarity of nodes is a common parameter to be applied as predictor. Cutting edge methods in similarity calculation are combined and compared in [15] and [19]. Similarity measures are commonly applied method in unsupervised learning studies. The basic idea is sorting the nodes based on similarity measure and selecting more similar nodes as probable ones to make links in future.
Many possible improvements in similarity measures are applicable. Some studies applied weights of edges for this aim. Authors in [23] proposed weighted Common Neighbor and weighted Adamic Adar and applied them in link prediction. De Sá and Prudêncio [31] applied three weighted similarity measures as their classification features Authors in [18] studied the role of weak ties in link prediction and proposed parameter free versions of weighted similarity measures. In this article some new similarity measures are proposed which merge weight of edges and recency of nodes interactions.
Methodology
A supervised learning approach is applied to evaluate the applicability of this article’s proposed measures. The properties for supervised learning method, social network data used in this experiments, preprocessing job that prepare data for supervised learning and final classification job are presented in this section.
Baseline similarity measures
These baseline similarity measures contribute to the classification features of this experiments.
Node neighborhood based similarity measures
The nodes proximities in graph is the basic approach to assign similarity between them. The idea is to assign a connection weight score (x, y) to each pair of the nodes x and y based on their proximity. For a node x, let Γ (x) represent the set of neighbors of x in social network. There are some commonly applied similarity measures that are selected as the baseline measures in this experiment:
Common neighbors
Newman [24] computed score (x, y) in the context of collaboration network, and verified that there is a correlation between the number of neighbors that x and y have in common at time t and the probability of their collaboration in future, presented as follows:
This measure is commonly applied in information retrieval. By considering common neighbors as feature f that either x or y has, Jaccard coefficient can be computed by the probability of both x and y having common neighbors [15], Equation (2).
This measure is a refined version of the common neighbors that take rare neighbors more serious [1]. The Adamic/Adar score can be presented through the following equation:
By considering a pair of nodes, x and y, which are not directly connected, node x can send some resource to node y, where their common neighbors act as transmitters. In the simplest case, it is assumed that each one of the transmitters has a unit of resource, and will distribute it to all of its neighbors on average. The similarity between x and y can be defined as the amount of resource y received from x, which is presented through the following equation [36]:
Where k (z) is the degree of node z.
The findings in experiments of [36] indicate that the three measures of common neighbors (CN), Adamic/Adar (AA) and resource allocation (RA) have the best overall performance in comparison with other neighborhood based similarity measures. In this article these three similarity measures are applied in order to generate their extended versions.
Authors of [32] and [12] studied the effectiveness of the Neumann kernels as a link analysis measure. They revealed that the Neumann kernels could be used as an efficient and powerful mechanism for determining “relatedness” between vertices. The relatedness between vertices is applied as a similarity measure in this article.
The Neumann kernel is defined in terms of an adjacency matrix X that its (i, j)-element is the frequency of i-th node relation with j-th node. From X, destination correlation matrix K = X T X and source correlation matrix M = XX T are first constructed.
The similarity between nodes i and j is given by (i, j)-element of
Hence, when γ < ρ (K) -1 (= ρ (M) -1), the solution exists and is given by
Some new similarity measures, which apply recency of nodes; weights of edges between nodes, and fusing recency with weights of edges are proposed.
Recency based similarity measures
The active users of a social network are determined by time factor. By applying the recency concept, how recently a user acted would be determined. Recency is a metric which was preliminary used for the first time by Potgieter et al. [27]. They applied a very simple definition of recency to investigate temporality in link prediction. To them recency is “One plus the number of time steps elapsed since the node last communicated”. In [35] authors used another definition for recency as “The time elapsed since a node made its last new link”. The second definition does not discriminate between new added nodes and most recent active nodes in the network.
In this article another definition of recency is applied; which consider node recent activities alongside the most recent actions. The definition of recency concept by [22] where the following two equations are effected from is applied in this study:
Where i is the difference between timestamp of current communication and last communication made by u, and j is the difference between timestamp of current communication and the last communication received by u. The value of recency sender (u) is the recency of the node with respect to the last communication made by, whereas recency reciever (u) is the recency value of the node u with respect to the last communication received by.
The values of i and j can be represented in seconds, minutes, hours and days depending on the application. In this article i and j are represented as hours, hence α take the value of 24.
The similarity measures are calculated based on the nodes’ recency to provide better predictions. According to this idea, the temporal versions of common neighbor, Adamic/Adar and resource allocation are presented as TCN, TAA and TRA, respectively:
The effectiveness of applying both the graph similarity measures and the weights of existing links in a social network is studied in [23], where the results indicate that their method outperforms previous approaches. By applying this weights of edges and with respect to common neighbor, Adamic/Adar and resource allocation similarity measures the weighted versions are applied in this study. These similarity measures are presented by WCN, WAA and WRA and can be obtained through:
Where, w (x, y) is the weight of link between nodes x and y, and S (x) = ∑z∈Γ(x)w (x, z).
As described, the recency of nodes and weights of the edges could be applied to propose new similarity measures. Consequently, the weighted temporal versions of common neighbors, Adamic/Adar and resource allocation similarity measures are presented as:
Almost all the previous works have used the co-authorship dataset. This dataset does not contain the creation time of nodes; therefore, another dataset with complete longitudinal information is chosen here as the empirical data. The social network adopted in this experiment is a network created from an online community [25]. This network dataset includes 1899 students at the University of California, Irvine. The observation period is from April to October 2004. This dataset covers every online message the students sent to each other. A total number of 59835 messages between students could be seen in 20296 directed edges among them. Each edge has a weight attribute which presents the number of messages between two nodes. In addition there exist timestamps of nodes creation and interactions, which is applicable in time awareness of the proposed method.
In spite of the excellent contributions on the researchers’ part, they have overlooked the overfitting of prediction model. Social network data are in the format of large graphs that merely contain presence of links. The dataset constructed by these graphs would have plenty of positive instances that can skew prediction results. To solve this problem some negative instances should be added to the dataset. In [11] and [31] authors added few negative instances to the dataset in a random manner to solve the problem. Here a weighted sampling is applied to confront this problem.
Development setting
All the experiments in this study are developed through R language and environment [29]. The igraph package [4] is applied in order to handle graph related functions. And the Caret package [8] is applied for supervised learning functions of the experiments. The pROC package [30] is applied for evaluations. The experiments are run on a windows 32-bit platform.
Evaluation metrics
Usually a classifier labels instances as either positive or negative. These prediction results can be represented in a structure known as a confusion matrix. The confusion matrix has four categories of true positive (TP), false positive (FP), true negative (TN), and false negative (FN). Confusion matrix can be used to construct different evaluation metrics for classifiers.
Accuracy is the ratio between the number of correct predictions and the total number of predictions. This evaluation metric is defined as:
The Kappa statistic is another evaluation metric which is applied in this article [33]. This metric compares an observed accuracy with a random accuracy. The kappa statistic is used not only to evaluate a single classifier, but also to evaluate classifiers amongst themselves. This evaluation metric can be presented through:
The random accuracy of the classification task is defined as the sum of the products of reference likelihood (actual true/false) and result likelihood (predicted true/false) which can be written as:
Sensitivity (a.k.a True Positive Rate and Recall) is the ratio of the number of TP to the total number of positive instances in a given dataset [28].
Specificity (a.k.a True Negative Rate) is the ratio of the number of TN to the total number of negative instances in a given dataset.
Precision (a.k.a Positive Predictive Value) is the ratio of the number of TP to the total number of instances predicted as positive.
Precision is interpreted as the ratio of the number of missing links predicted correctly [19].
Another evaluation metric constructed from confusion matrix is the Receiver Operating Characteristic (ROC) curve [6]. A ROC curve is a two-dimensional representation of the classifier performance which can be used to evaluate 2-class models. A ROC curve represent tradeoffs between TP and FP. Actually ROC curve plots the sensitivity (TPR) by one minus specificity (TNR). The Area Under ROC curve (AUC) could be used as a performance measure of classifiers [3, 6]. Any algorithm that obtains the highest AUC could be labeled as a better classifier.
Any supervised learning algorithm needs a feature set in order to construct its model. All of the candidate similarity measures for feature sets in this experiments are tabulated in Table 1. By considering different combinations of these similarity measures; feature sets of this assessment would be made. To see their impact on link prediction it is best to add these features to feature set incrementally.
The list of all similarity measures used in the experiments
The list of all similarity measures used in the experiments
*Proposed by this article.
Social networks data are in the form of sparse graphs. These graphs only represent existence of edges between the nodes, but there is a need for both positive and negative classes in supervised link prediction. This would lead to overfitting of the results; therefore, creation of negative classes is a major part of preprocessing. In spite of the excellent contributions on the researchers’ part, they have overlooked the overfitting of prediction model. In [11] and [31] authors added few negative instances to the dataset in a random manner. The dataset constructed by these graphs would have plenty of positive instances that can skew prediction results.
A weighted sampling procedure is applied here, to confront this problem with the idea of adding some non-connected pairs of nodes as negative instances. The sampling size is calculated through Equations (23 and 24).
Where, CE is the number of connected edges presented in graph, and NE is the number of non-connected edges.
There exist many classification algorithms for supervised learning. Their performances are different for any given dataset. In this study two six different learning algorithms are applied: Linear Discriminant Analysis (LDA), Stochastic Gradient Boosting (GBM) [7], Boosted Classification Trees (ADA) [5] and C5.0 Decision Trees [14], Logistic Regression (GLM) and Random Forest (RF). In the first step LDA and GBM classification models are applied, and then the other four classifiers are applied in order to compare and study more.
Here 3-fold cross validation is applied for the classification algorithms. The performance of the classifiers are assessed through evaluation metrics Accuracy, Kappa, AUC and Precision.
The prediction results of the two selected classifiers are assessed in this article. In each runs a selection of nodes characteristics is applied as the classifiers’ feature set. The classifiers are trained through feature sets in order to have different prediction models for prediction performances comparison.
The similarity measures in Table 1 are applied by classifiers singly and their prediction results are tabulated in Table 2. Unlike [36], where it is claimed that Resource Allocation outperforms others, the Common Neighbors similarity measure is ranked the first prediction results. It shows that in practical applications, one should choose right similarity measures according to the characteristics of social networks. There is no an absolutely dominating similarity measure for different datasets.
Prediction results of using baseline similarity measures
Prediction results of using baseline similarity measures
The prediction results, where this newly proposed similarity measures are applied, are tabulated in Table 3. These results indicate that applying weighted and temporal versions of similarity measures alone have minor impact on prediction performance. Assessments run on more aspects of applying these measures are tabulated in Tables 3–5.
Prediction results of using weighted and temporal similarity measures
Prediction results of applying recencies of an edge’s nodes as the similarity measure
Prediction results of applying combinations of similarity measures as classification feature sets
Having the nodes’ recency of activities would yield a new feature set consisting of an edge’s sender and receiver’s nodes temporal information as a new similarity measure. The prediction result of applying nodes recencies as similarity measure would allow to examine the impact of nodes recencies of activities on their upcoming activities. The experiments classifiers are trained with feature set and the prediction results are tabulated in Table 4.
To better represent the impact of this feature set on the prediction results an AUC comparison is applied, Fig. 1. The area under the ROC curve related to the classifier learnt through recencies is more than the other ROC curves. Moreover, This ROC curve is further to the 45-degree diagonal which means that the related classifier is more accurate. The results not only indicate that the recencies of nodes are usable as similarity measure but also this similarity measure outperforms other well-known similarity measures.
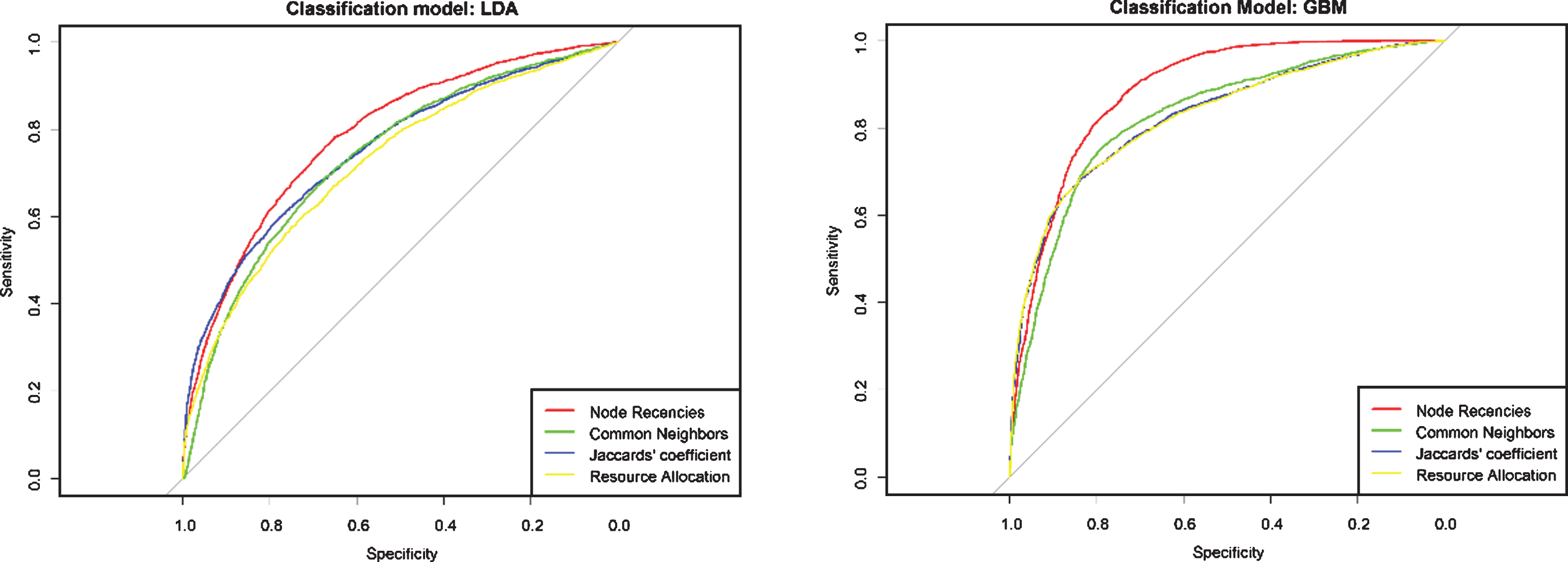
The ROC plots of different classification models learnt through Node Recencies as similarity measures and other well-known similarity measures (Common Neighbors, Jaccards’ coefficient and Resource Allocation) as feature sets. Area under these ROC curves (a.k.a AUCs) is a reliable evalution metric that indicate the classifier learnt through node recencies is more accurate and better predictor.
The next part of experiments consist of applying combinations of similarity measure as feature sets where two different combinations of similarity measures are applied in classification. The first combination consists of similarity measures which do not contain temporal information on the nodes’ activities. The second one contains temporal versions of similarity measures in addition to the former measures. These results, tabulated in Table 5; indicate the strong impact of applying temporal similarity measures in the prediction task.
The ROC plots of three different feature sets applied in the experiments; the first feature set uses temporal resource allocation as similarity measure, second feature set uses a combination of all similarity measures except temporal ones and the third feature set use all similarity measures presented in this article are illustrated in Fig. 2. As shown in the diagram areas under the ROC curves (AUCs) related to combinations feature sets are remarkably better. These curves are closer to left and top borders which indicate more accurate classifiers. The best performance is related to the feature set which contains temporal information of the nodes. This comparison leads to two results: applying a combination of similarity measures improves the prediction results and applying temporal similarity measures where containing the recency of nodes would significantly improve prediction performance.
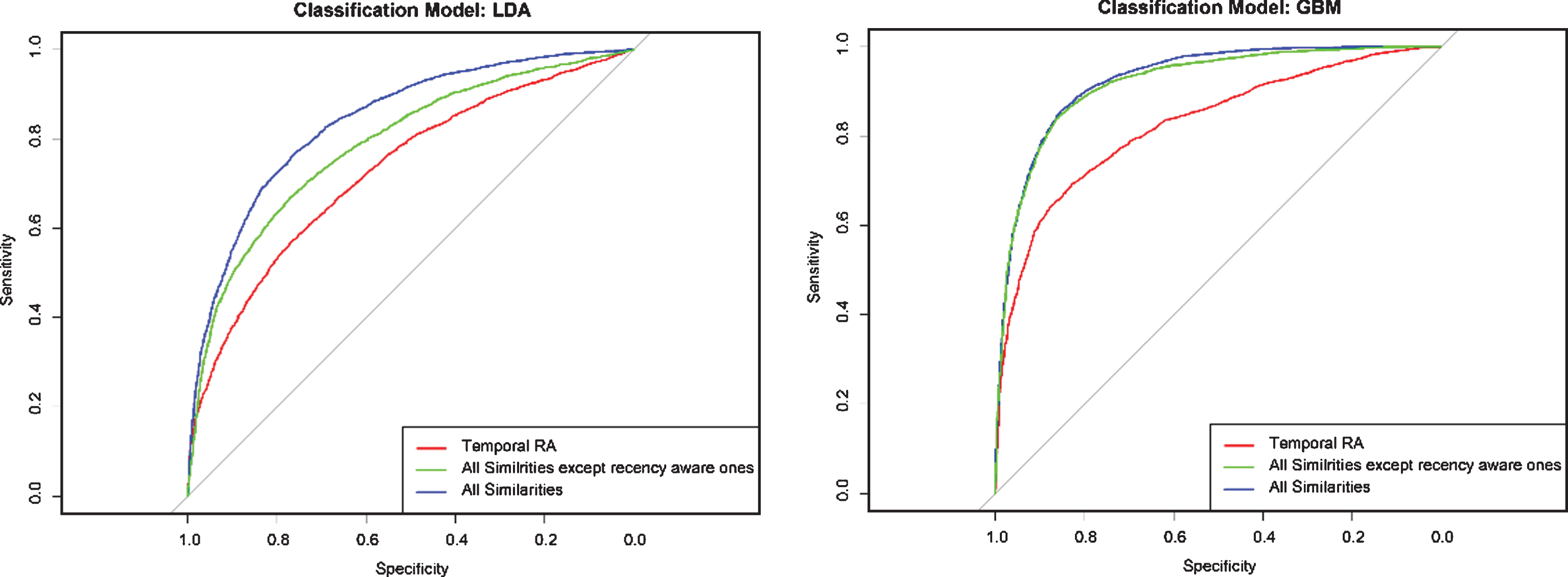
The ROC curves of different classifiers learnt through Temporal Resource Allocation, All similarity measures except Temporal measures and All similarity measures as feature sets. The ROC curve related to classifier learnt through combination of similarity measures contain node recencies has has bigger AUC which indicate better prediction capability.
Different classifiers perform differently on a particular data set, therefore, the performance comparison for different classifiers on the empirical data is made in the experiment setting. The four well-known Boosted Classification Trees (ADA) and C5.0 Decision Trees, Logistic Regression (GLM) and Random Forest (RF) classification models would be applied in addition to the former classification models. The prediction results of applying these four classifiers are presented in Table 6.
The prediction results of applying four other classification models in order to compare more. The boosted classification trees (ADA), C5.0 decision trees (C5.0), logistic regression (GLM) and random forest (RF) are applied
The results are similar to the prior classification models applied in the first experiment. Applying the proposed similarity measures alone would slightly improve prediction capability. The results indicate that applying temporal similarity measures combined with other measures would significantly increase prediction capability.
Another experiment is conducted in order to compare all of the classification models of this study. A complete combination of similarity measures presented in this article is used as the feature set. The prediction results are tabulated in Table 7. The AUC comparison of classifiers is shown in Fig. 3.
Prediction results of applying different classification models on the empirical data, trained with all of the similarity measures

ROC plots of different classifiers trained with all similarity measres a) LDA (red) b) GBM (yellow) c) ADA (green) d) C5.0 (black) e) GLM (blue) and f) RF (purple).
The random classifier illustrated by diagonal line has an accuracy of 0.5 by classifying all test data to be equal to positive or negative. ROC curves of different classifiers with a same feature set are plotted in Fig. 3. The classifier closer to the left and top borders and bigger area under ROC curve (AUC) has better prediction capability. With respect to the ROC curves of classifiers and their related AUC it is deduced that the Random Forest classifier performs better than other classifiers in supervised link prediction with an observable wider AUC.
In experiments it was observed that sometimes the weighted similarity measures perform similar or even worse that the simple versions. This observation reminds the weak ties theory, which state that sometimes the weak ties have more impact on link creation [17, 21]. Therefore the role of weak ties in link prediction is investigated.
In order to investigate the role of weak ties in link prediction, the parameter free indices for WCN, WAA and WRA are applied [18]. These indices are presented as:
The α is a free parameter that range from –1 to 1.
The weights of edges are considered in three measures of WTCN, WTAA and WTRA. Therefore, the parameter free indices for these measures are proposed as:
When α = 1, the similarity measures are equivalent to weighted indices. When α = 0, the similarity measures degenerate to the unweighted cases. The results of applying the parameter free indices in link prediction are given in Table 8 and Fig. 4. The optimal values of α are smaller than 1, which indicate that weak ties play a more important role than weights in the link prediction. These optimal values are negative, which indicate that the weak links play a more important role than the strong links.
Optimal values of parameter α subject to the highest precision

Precision as a function of parameter α. The optimal values of α are negative and smaller that 1.
Link prediction in social networks is an important issue with vast area of applications. The focus of this article is on studying nodes similarity measures and their analysis due to supervised learning algorithms for link prediction. One of the main contributions of this article is introducing innovative approaches in order to improve the similarity estimation of social networks’ nodes. For this purpose the recency of the nodes’ activities are applied as a source of knowledge. The new versions of many classic similarity measures where recency of nodes is applied are proposed in this article.
A supervised learning experiment setting is applied to assess the innovative aspects of this article. The supervised learning is chosen because of its capability to deliberate different combinations of similarity measures as feature sets. The classification models are one of the most reliable in prediction studies. Moreover, these models are capable of coping with the dynamic of social networks.
In this article categories of similarity measures are suggested which should be considered in supervised learning feature set. These categories consist of a) similarity measures of nodes based on their proximities, b) weighted version of well-known similarity measures, c) kernel based similarity measures, d) temporal versions of similarity measures where the recency of nodes is considered and e) similarity measures benefited from both weights of edges and temporal features.
The first groups of the experiments consist of comparing prediction results of applying different similarity measures in a separate manner as classification feature sets. The findings of the experiments indicate that using recency of nodes improve prediction results for some similarity measure slightly. Main improvement made in the prediction results is observed merely when recency of sender and receiver activities are applied as similarity measure of nodes.
The second groups of experiments assess the impact of applying temporal measures in feature sets. For this purpose two different combinations of similarity measures are applied as feature sets. A combination consisting of non-temporal similarity measures and a combination consisting of all measures are compared. The results indicate that applying temporal similarity measures improve the link prediction in a significant manner.
In order to more inspection prior experiments finding different classification models were applied on the data. The findings show that different classification models similarly affected by the proposed similarity measures.
The impact of applying different classification models on the prediction results is assessed too. The results have indicate that the predictions results would be improved through better classifiers.
Since it is observed that sometimes the similarity measures contain weights of edges perform similar or even worse than other measures; the parameter free versions of these measures are assessed. The results show that the weak ties play a great role in link prediction.
The general conclusion here is: regarding link prediction where supervised learning is applied, adopting temporal similarity measures in the classification would improve prediction capability. Moreover, applying recency of nodes alongside weights of edges would promote similarity measures too.
In the future it would be interesting to investigate other ways to improve similarity measures. Moreover, the temporality could be applied in other related problems such as recommender systems.
Footnotes
Funding Acknowledgement
This research received no specific grant from any funding agency in the public, commercial, or not-for-profit sectors.