
Abstract
Online reviews play important roles in many Web Applications like e-business and government intelligence, since such user-generated-contents (UGC) contain rich user opinion. Opinion target and opinion word are a pair of core objects for user opinion expression in reviews. Extracting these two objects from reviews is crucial for the tasks of opinion mining. However, traditional extraction methods have various limitations such as ignoring the opinion relationship, the restriction of word span, the error propagation caused by iterative expansion, which would reduce the extraction performance. For the above deficiencies, we propose a supervised method based on the constrained word alignment model to extract opinion target and opinion word collectively at first. To tackle the time-consuming and error-prone problem of manual annotation encountered by the supervised method, we further devise a semi-supervised extraction method based on active learning. In this method, we design the sample uncertainty-based sampling strategy and the feature evidence-based one to choose the most informative samples for labeling manually. At last, a series of experiments on a real-world dataset show that our approaches outperform several state-of-the-art baselines significantly.
Introduction
Opinion mining, also called sentiment analysis, has received a great deal of attentions in the past few years [1], which targets at understanding what opinion users express in various medias like texts, images and music. Online review plays an important role for many practical Web applications, especially for the e-commerce and government intelligence, in the thriving Internet environment. According to a Cone Inc.’s report [2], about four-out-of-five consumers have changed their purchase intention based solely on negative information. And positive information has a similar influence on decision making. However, it is impracticable to investigate and analyze the users’ opinion from massive reviews manually. Then, it brings urgent need for dealing with suck tasks automatically.
Compared with the coarse-grained opinion mining, such as on document level [3–5] and topic level [6–8], the fine-grained one [9–11] is more suitable to meet the requirements of practical applications, since the latter explores the users’ opinion more finely and precisely. In this case, both opinion target and opinion word are the crucial objects. The former describes what is user opinion focused on, the latter indicates what type of opinion user wants to express. For example, in the sentence “the screen is clear and smooth”, “screen” is the opinion target, “light” and “smooth” are the opinion words. These objects contain all information on the user’s opinion in this comment. Thus, identifying and extracting the opinion targets and opinion words from reviews is one of the main key tasks for opinion mining.
The existing methods usually utilize modification relationship to extract the pairs of opinion target and opinion word (opinion pairs for short). These methods include the nearest neighbor-based methods [12, 13] and the syntactic pattern-based ones [14–16]. The nearest neighbor-based methods use a fix length window to mine opinion targets and the opinion words based on the words’ modification relationship, which could achieve relatively poor extraction precision due to the limitation of predefined window size. The syntactic pattern-based methods are able to avoid the limitation of word span, but the predefined syntactic patterns would reduce the extraction recall. Moreover, most of the existing methods apply an iteration expansion strategy to enlarge the opinion target set and the opinion word set alternately. In such cases, some errors occurred in previous processes would propagate to the subsequent extraction processes.
To tackle these problems above encountered by existing methods, we propose a supervised collective extraction method for opinion pairs at first. In this framework, we treat all of the possible combinations of two different words in a sentence as the opinion pair candidates. Inspired by the Word Alignment Model [17], we capture such relationship by a monolingual constrained Word Alignment Model, in which we constrain that a word would construct the opinion pair candidates with different words in the same sentence. As shown in Fig. 1, “phone” would generate five opinion pair candidates with different words in the first sentence, and “works” would generate two candidates. For these candidates, we can construct a vector space model with feature engineering. Then, the extraction problem for the opinion pair can be treated as a classification task. By this way, we avoid the limitation the word span and predefined syntactic patterns at first. On the other side, the error propagation occurred in the alternate iterative extraction process of opinion targets and opinion words would not be generated, since we extract these two objects simultaneously.

Mining the pair of opinion target and opinion word using a constrained Word Alignment Model.
In summary, our work can be concluded mainly as follows: We propose a supervised collective extraction for opinion pairs based on the constrained word alignment model, in which the extraction can be treated as a binary classification task. Compared with previous nearest-neighbor rules and syntactic patterns, the model can capture long-span modified relations and utterly avoid the problem of error propagation and dependence on parsing performance, which are encountered by existing methods. We further design a semi-supervised extraction method based on active learning, since labeling samples for training is time-consuming and error-prone. In this framework, the most informative samples will be chosen to label by human, by which we can achieve the good extraction performance with less labeled samples. In order to choose the most informative samples for labeling, we explore two sampling strategies. The first one focuses on the sample’s uncertainty, the other one is based on the feature’s evidence. We conduct a real-world data for the collective extraction of opinion pairs. Moreover, we carry out a series of experiments to verify the proposed methods. The experiment results show that our proposed methods’ extraction effectiveness are promoted significantly compared with those of several state-of-the-art competitors.
The rest of the paper is organized as follows. We introduce the related work in Section 2. Section 3 declares the problem formally. Section 4 proposes a supervised collective extraction method for opinion pairs based on the constrained word alignment model. Section 5 presents a semi-supervised extraction method for opinion pairs by integrating an active labeling process to tackle the time-consuming and error-prone problem of manual annotation, and two sampling strategies are also explored in this section. The experiments and discussions are carried out to evaluate the proposed methods in Section 6. Section 7 draws the conclusions.
Opinion mining is an active research field in recent years, in which mining the opinion targets and opinion words has received many attentions due to their importance. Previous methods mainly focused on utilizing the opinion relations among word to extract the opinion pairs, in which the intuition is that opinion target would occur together with opinion word, and there are strong modification relationship between them.
Some previous works used the nearest neighbor-based methods to capture such modification relationship, in which they regarded opinion target should be surrounded by opinion word(s) within a given window, and vice versa. Hu and Liu applied the association rule mining to find the product features at first, and then they extracted the nearest adjective that modifies the product feature as the opinion word [12]. Wang et al. used a fix length window to filter the opinion pair candidates, and calculated their association scores by a revised mutual information [13]. In such methods, modification relationship cannot be captured precisely due to the limitation of window size, especially for long-span combinations, which would reduce the extraction performance.
The syntactic information like dependency trees is another important clue to mine the opinion pairs [14, 18], then the syntactic-based methods can avoid the limitation of window size. In [15], Zhang et al. reported that the syntax-based methods could yield better performance than the nearest neighbor-based methods for small or medium corpora. Popsecu et al. used syntactic patterns to extract opinion target candidates, and they computed the point-wise mutual information (PMI) score between a candidate and a product category to refine the extracted results [14]. Kobayashi et al. used syntactic patterns learned via pattern mining to extract the opinion pairs in [19]. In [16], Li et al. extracted product features and opinion words through pattern-based bootstrapping, and exploited Prevalence and Reliability to assess both patterns and features. The performance of syntax-based methods heavily depends on the parsing performance, which would affect the extraction effectiveness due to the error propagation, because reviews could include mistakes, such as grammar mistakes, typos, improper punctuations.
Extracting opinion pairs is also regarded as a sequence labeling task [20, 21], where some classical sequence labeling methods like the Conditional Random Fields (CRFs) [22] and the Hidden Markov Model (HMM) [23] can be used to construct the extractor. These supervised methods need to label the training samples which is a time-consuming and error-prone process. Moreover, if training samples are insufficient or training samples and extracted samples belong to different domains, it would lead to poor extracting performance. Some graph-based extraction methods were proposed recently. Liu et al. presented an alignment-based approach with graph co-raking to collectively extract opinion target and opinion word in [24]. Wang et al. utilized a sorting algorithm on graph to estimate the confidence of all candidates in [25].
The Double Propagation model applies a bootstrapping strategy to implement the extraction, which can be used to generate the opinion word set and the opinion target set alternately. Qiu et al. expanded a domain sentiment lexicon and an opinion target set iteratively by a Double Propagation method. In [26], they exploited direct dependency relations between words to extract opinion targets and opinion words iteratively. Zhang et al. extended Qiu’s method with some other patterns like phrase/sentence patterns to increase the extraction recall in [15]. In this type of methods, opinion word set and opinion target set are always treated separately. Rather, these two sets are enlarged alternatively based on a predefined seed set. Our approach differs from such methods that we try to extract the pairs of opinion target and opinion word from the reviews directly.
Problem statement
For the convenience narration, we introduce some symbols firstly. Assuming S = {s1, s2, ⋯, s
n
} to be the sentence set, in which s
i
is a sentence coming from the online review corpus; O
T
is the candidate opinion target set,
Users’ opinion expression mainly depends on the opinion targets and the opinion words. Then, we can summary users’ opinion with an ordered pair
Formally, we try to learn a function for each candidate, which could find the pairs of opinion target and opinion word in reviews. Here, is the set of candidate opinion pairs and C = {0, 1}, where 1 means a candidate opinion pair is a true opinion pair and 0 means the false one. Formally, our target can be concluded as follows.
As discussed above, each word would be able to construct opinion pair candidates with different words in the same sentence in the constrained Word Alignment Model.
The constrained word alignment model
Given a sentence s
i
with N words, let the sentence’s word set
To reduce the training space, we constrain that
The probability of the constrained alignment sequence can be evaluated by Equation 4.
Some confidence estimation methods on graph can be used to determine the
Let X to be the random variable representing as an opinion pair candidate
We use seven features to represent different properties of opinion pair instances, which are shown in Table 1. F1 and F2 describe the POS information of opinion target
The feature presentation for the opinion pair instance
The feature presentation for the opinion pair instance
Based on the vectorization for instances, we can use the existing classification methods to make prediction for an unlabeled sample, such as the Logistic Regression, the Support Vector Machine. For example, the parametric model assumed by Logistic Regression is as follows.
Here, x0 = 1. In this model, we use the probability values in Equation 5 to estimate the possibility
Generally, the supervised extraction methods would have strong generalization ability and achieve good extraction effectiveness with sufficient training samples. However, labeling samples manually for training is a time-consuming and error-prone process. In fact, not all of the labeled samples would provide the same amount of information for training the model. For example, a small number of support vectors play key roles for learning the decision boundary. Then, it would be an effective way to reduce the labeling workload without loss in extraction effect by choosing the most informative samples to label for training.
Assuming we have a small labeled sample set L = {〈x(i), y(i)〉|i = 1, ⋯, N1} and a large unlabeled sample set U = {x(i)|i = 1, ⋯, N2}, N1 << N2. Now our target is to get an extractor model with relative strong generalization based on L by using less as far as possible human annotation for U. The main processes of the active learning-based semi-supervised extraction method are described in Fig. 2. Firstly, we use the small labeled sample set L to train an extraction model, which could have relatively weak generalization due to the lack of training samples. Then, the model is applied to make predictions for the unlabeled samples. For the predicting results, we would choose the most informative samples for human to label. And the new labeled samples are put into the labeled sample set for training. This process would be executed iteratively until some predetermined stop conditions hold.
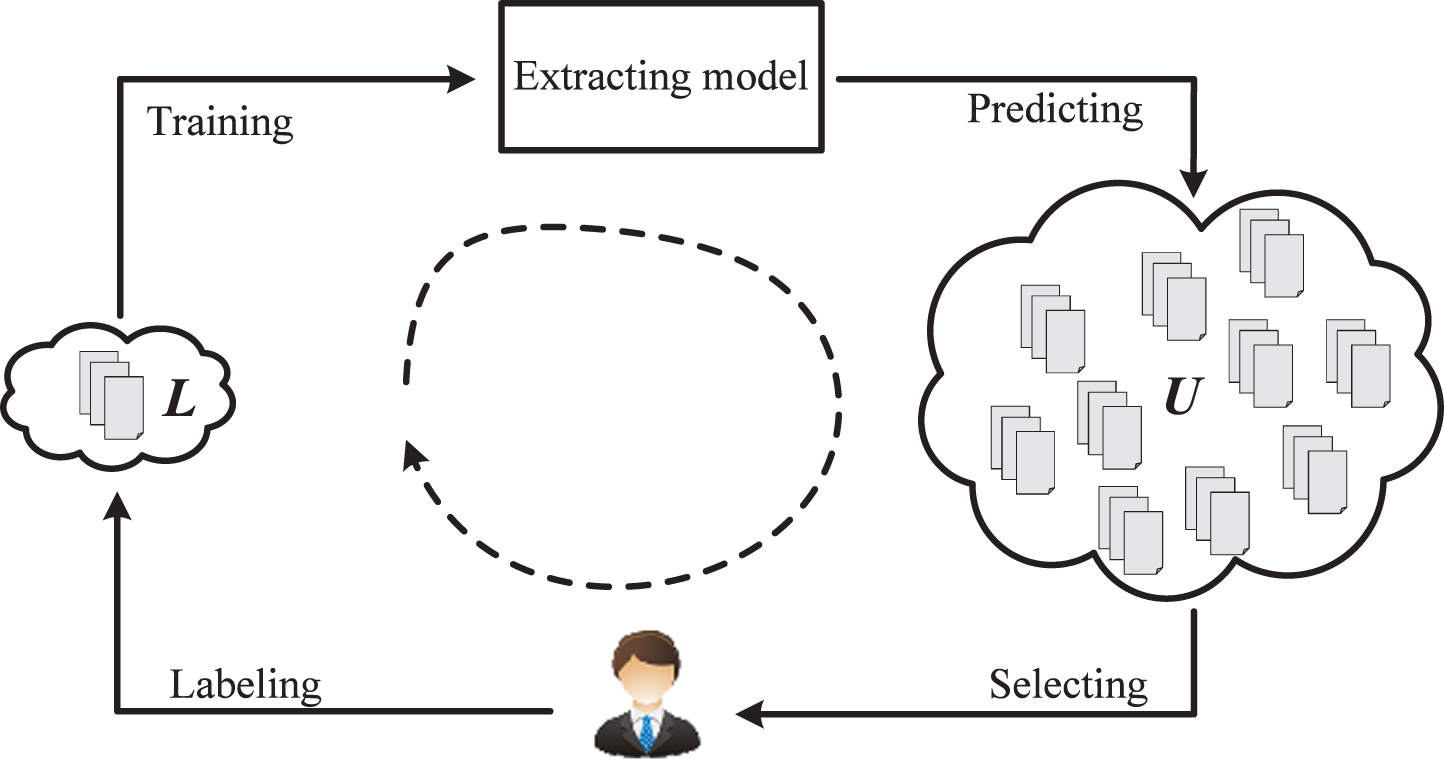
Iterative process for active Labeling.
A key problem in above process is to ensure the samples we choose for labeling manually are the most informative ones. Uncertainty sampling [28] is one of the most used methods in active learning. In this way, the extraction model would choose the samples which are most uncertain to be made predictions by the model. That means the chosen samples should be located near the decision boundary. Thus, we can use margin of confidence to measure the uncertainty:
Since we treat the extraction of opinion pairs as a binary classification problem in this work, the P (y(j)|x(i)) is equal to 1 - P (y(k)|x(i)) and (P (y(k)|x(i)) - P (y(j)|x(i))) ∝ P (y(k)|x(i)). Then, Equation 7 can be reduced as follows.
By Equation 7s, we can measure the uncertainty on sample level.
Measuring the uncertainty on sample level is one of the coarse-grained strategies. We can explore the sample’s uncertainty with finer granularity, which would achieve better effectiveness. Then, we consider to use the features’ evidences for evaluating the uncertainty based on the work in [29] further. Let P
x
(i)
is the set containing the features providing evidence for class “1” and N
x
(i)
is the set of features providing evidence for the class “0”:
Then, the evidence that instance x(i) provides for the class “1” is:
Then, we would like to choose the instances with relatively large uncertainty values, which have both large E0 (x(i)) and E1 (x(i)):
In general, we should choose top k uncertain instances for next training step to improve the efficiency. The semi-supervised extraction algorithm for opinion pairs based on active labeling is described in Algorithm 2g:ALEA. We would get an extractor with relatively weak generalization ability after the initial extraction model is trained with a small labeled sample set (Line 1). The extractor is used to make the predictions for unlabeled samples in U (Line 4 and 5). The top k uncertain instances are chosen for manual annotation (Line 6). And then, we enlarge the labeled sample set L with the manually labeled samples (Line 7). The extractor is retrained with the new training set, and we remeasure its performance (Line 9 and 10). The steps above are implemented iteratively until the change of performance is less than a predetermined threshold.
the unlabeled sample set U,
the initial model
the stop threshold λ
1: Training
2: Measuring
3:
4: Computing
5: Evaluating the uncertainty of
6: Constructing S = {〈x(i), y(i)〉} by labeling manually the top k uncertain instances in T;
7: L = L ∪ S;
8:
9: Training
10: p′ = p and remeasuring
11:
12:
Experimental setting
Some statistical information on the constructed dataset
Some statistical information on the constructed dataset
In this paper, we target at extracting the opinion pairs from online reviews. It is clear that the products or product features are the opinion targets in our experiments since our dataset is constructed based on the online reviews. Then, the first experiment focuses on the comparisons of extraction effectiveness for the proposed methods and the competitors. We compare the precisions, recalls and the F1 values of different methods for four different products in Table 3.
Extraction effectiveness comparisons for different methods in various domains
Extraction effectiveness comparisons for different methods in various domains
As shown in Table 3, we can observe that our methods overcome all of the state-of-arts in all domains. The NNR achieves the worst effectiveness. We think the main reason is that the nearest-neighbor method applies a fix-length window to harvest product features or opinion words, which limits the extraction precision and recall. The DP is a syntax pattern-based method, which can achieve a high relatively high precision, but the predefined syntax patterns lead to a low recall. Moreover, DP requires some initial opinion word seeds to bootstrap the extraction process, which would limit the extraction performance too. For the CR_WP, it assumes that the opinion targets should be nouns/noun phrases and opinion words should be adjectives. We consider that is a disadvantage of CR_WP, since users’ sentiment could be expressed with other types of words such as verbs and adverbs.
Another main observation is that both SCE and ALSE_Fea are effective extraction methods in our experiments, the former is a full supervised method and the latter is a semi-supervised one. We can see that the ALSE_Fea’s extraction is similar to the SCE’s, when ALSE_Fea reaches a stable state. However, it is worth noting that the training samples ALSE_Fea used are much less than those used by SCE. Exactly, the training sample amount of ALSE_Fea is 26% less than that of SCE in Canon, 27% in Nikon, 39% in Nokia, 31% in Creative and 29% in Apex. We will compare the SCE and ALSE_Fea further in later experiment.
In Section 4, we propose seven features to construct the vector space for candidate opinion pairs. The following experiment focuses on measuring the features’ functions for extraction effectiveness. We remove different types of features and evaluating the F1 value of SCE in different domains in Fig. 3. For example, we remove the Pos-type features (F1 and F2 in Table 1), implement the extraction based on the left features with the supervised method SCE. This method is denoted as SCE_Pos in Fig. 3. Similarly, SCE_Loc means the location-type features (F3 and F4 in Table 1) are removed, SCE_Dis removes F5, SCE_Fre removes F6 and SCE_Rel removes F7 separately.

Different features’ effectiveness.
As shown in Fig. 3, almost all features are positive to the extraction effectiveness obviously in different domains, except the distance feature (F5). Namely, the F1 value will decrease significantly after we remove the Pos-type features, location-type features, frequency feature and dependency relationship feature respectively. For the distance feature, it doesn’t seem to make sense in this experiment. We think the main reason is that the distance information could be implicated in the location-type features. Then, the extraction effectiveness varies slightly when we remove the distance feature only.
The proposed semi-supervised method is comparable with the full supervised one on extraction effectiveness in different domains, which is verified in our first experiment. We further make comparisons on extraction performance between ALSE_Fea and SCE in Fig. 4, in which the horizontal axis describes the proportion of training samples used in every experiment. For example, 0.3 means only 30% labeled samples in training set are used to train the model. We find that all effectiveness curves of ALSE_Fea locate above those of SCE in all domains. That means ALSE_Fea can achieve the better extraction effectiveness, when it uses the same amount of training samples with SCE. On the other hand, ALSE_Fea will need less labeled samples to train the model for the same F1 value.

The comparison between the supervised method and the semi-supervised one.
In the last experiment, we investigate different sampling strategies used in the active labeling processing for the semi-supervised extraction method. As discussed above, we can choose the samples for labeled manually by three sampling strategies: random sampling (ASLE_Ram), sampling based on sample’s uncertainty (ASLE_Sam) and based on feature evidence (ASLE_Fea) separately. As shown in Fig. 5, ASLE_Sam improves 25.75% in Canon, 38.7% in Nikon, 30.88% in Nokia, 23.51% in Creative and 35.94% in Apex over ASLE_Ram respectively. ASLE_Fea improves 27.99%, 39.51%, 30.14%, 26.45% and 37.34% in five different domains over ASLE_Ram respectively. Thus, both ASLE_Sam and ASLE_Fea are effective to pick up the most informative samples for labeling firstly. By contrast, ASLE_Fea shows better performs than ASLE_Sam in most domains. It means that the fine-grain evaluation method on sample uncertainty can choose more informative samples in active labeling processing for our semi-supervised extraction method.

Different strategies on choosing samples for labeling.
This paper focuses on an important task in opinion mining, namely, collective extraction of opinion target and opinion word. We propose a supervised method to extract such opinion pairs based on the constrained word alignment model. However, the supervised method would encounter the time-consuming and error-prone problem of manual annotation. Then, we propose an active labeling-based semi-supervised extraction method. To choose the most informative samples for labeling, we design the sample uncertainty-based strategy and the feature evidence-based one. At last, we construct a real world dataset on the base of an open review set to verify the proposed methods’ effectiveness. The experiment results show our approaches outperform other state-of-the-art baselines in different product domains.
In the future, we will focus on two works. Firstly, we plan to improve the extraction performance by mining the implicit targets and contrasted opinion. We will then also explore the semi-automatic techniques based on crowdsourcing for labeling the candidate opinion pairs to conduct a large scale dataset, which can be used to improve the extractor’s generalization and evaluate new methods and models on mining opinion targets and opinion words.
Footnotes
Acknowledgments
The work is supported by National Natural Science Foundation of China (Nos. 61562014, 61763007, U1501252, 61662013), the Guangxi Natural Science Foundation (No. 2015GXNSFAA139303), the project of Guangxi Key Laboratory of Trusted Software, the project of Guangxi Key Laboratory of Automatic Detecting Technology and Instruments (No. YQ17111), the general Scientific Research Project of Guangxi Provincial Department of Education (No. 2017KY0195).