
Abstract
The rapid growth in the extraction of clinical events from unstructured clinical records has raised considerable challenges. In this paper, we propose the use of different features with a statical modeling method called conditional random fields, which is consider an algorithm for effectively solving problems of sequence tagging. Our goal is to determine which feature selection can affect the performance of four subtasks presented in SemEval Task-12: Clinical TempEval 2016. We applied a careful preprocessing, where the proposed method was tested on real clinical records from Task-12: Clinical TempEval 2016. The comparative analyses obtained indicate that our proposal achieves good results compared to the work presented in Task-12: Clinical TempEval 2016 challenges.
Keywords
Introduction
An important study in the clinical domain is event detection for decision making towards the improvement of the quality of life in patients. SemEval (Semantic Evaluation): Task-12: Clinical TempEval (Temporal Evaluation) challenge presents nine subtasks based on time expression identification, event expression identification, and temporal relation identification. Our study focused on event expression identification, detecting and classifying an event based on its contextual modality, polarity, and type. We recommend reading [6] for a complete description of the tasks presented in Clinical TempEval. The two contributions of this paper are: (1) a presentation of the state-of-the art of Clinical TempEval, and (2) a demostration of how our system outperforms the winning approach in the Clinical TempEval challenge. The paper is organized as follows. Section 2 introduces the state-of-the-art on event expression identification. Section 3 presents the process of conducting the analysis using CRFs with several features. Section 4 provides the experimental results to assess the effectiveness of our study. Furthermore, a comparison between our results and Clinical TempEval 2016 is included in this section. Lastly, Section 5 includes our conclusions and the proposed future work, respectively.
Related work
The coverage of related work is divided into three parts. The first part is based on literature related to the Workshop on Clinical Temporal Evaluation (SemEval) 2016 [6], where participants used a corpus with information from patients with colon cancer. The second part is based on Semeval: Clinical TempEval 2017 [7] where the corpus has additional medical reports that include brain cancer, and the last part is devoted to related work on event detection using other available corpora.
SemEval 2016: Task 12-Clinical TempEval
SemEval (Semantic Evaluation) is a workshop focusing on extracting temporal information from the medical records of real patients. Lee et al. [17] presented an approach based on supervised learning for the SemEval tasks. Their approach used several variables such as lexical, syntactic, discourse level, word representation, and external resources. Moreover, they used three toolkits for text preprocessing: Clamp (tokenization), OpenNLP (part-of-speech tagging), and ClearNLP (dependency parsing). The system was trained using hidden Markov model with support vector machine and ranked first with an F-measure of 0.903 for event identification, 0.855 for contextual modality, 0.887 for polarity, and 0.882 for type. Another approach, reported by the same author provided the second best performance with an F-measure of 0.895, 0.847, 0.880, and 0.871 for event detection, contextual modality, polarity and type, respectively. Khalifa et al. [3] introduced two systems using CRF based on CRFSuite toolkit [22], and support vector machines. In their system, they used lexical features (tokens, lemmas, part-of-speech, tags, chunk labels, etc.) extracted from CTake toolkit, along with word shape features (lowercase, numeric, etc.) using ClearTk. Their results achieved the third and fourth place, UTAHBMI-CRF provided an F-measure of 0.892 on event detection, 0.841 on contextual modality, 0.876 on polarity, and 0.866 on type. Finally, the second approach UTAHBMI-SVM achieved 0.892, 0.836, 0.874, 0.849, for event detection, contextual modality, polarity and type, respectively. Hansart et al. [14] participated only in the subtask event detection by integrating techniques previously used for preprocessing news in French, along with CRF, statical and linguistic approaches. The system achieved good accuracy based on the state-of-the-art with an F-measure of 0.885. A complete list of works presented in SemEval 2016: Task 12-Clinical TempEval can be found in [6].
SemEval 2017: Task 12-Clinical TempEval
In addition to measuring the validity of related work presented on Task 12-Clinical TempEval, we provide a brief overview of the 2017 competition, where the committee provided more clinical records unlike the competition that took place in 2016. Tourille et al. [25] provided two approaches based on supervised and unsupervised domain adaptation. The first approach is based on recurrent neural networks and features such as character and word embeddings. This approach achieved the best performance with an F-measure of 0.72 for event detection, 0.64 for contextual modality, 0.69 for polarity, and 0.70 for type. The second approach used support vector machines along with features such as words and part-of-speech tags. It achieved an F-measure of 0.76 for event detection, 0.69 for contextual modality, 0.75 for polarity and 0.75 for type. MacAvaney et al. [21] trained conditional random fields, decision tree ensembles and rules along with features such as n-grams, words, word shapes, word clusters, word embeddings, part-of-speech tags, syntactic, dependency tree, semantic roles, and UMLS concept types. They also evaluated their results into two varities of domain adaptation: supervised and unsupervised. The first domain achieved an F-measure of 0.71, 0.56, 0.65 and 0.68 for event detection, contextual modality, polarity, and type, respectively. The second domain achieved good performance with an F-measure of 0.74 for event detection, 0.66 for contextual modality, 0.58 for polarity, and 0.72 for type.
Leeuwenberg and Moens [18] presented support vector machines on features extracted from linguistic and word forms. The system achieved a good performance with an F-measure of 0.68, 0.62, 0.67, 0.66 in the tasks of event, contextual modality, polarity and type, respectively.
Other corpora
This section describes related work using different corpora to solve tasks that involve clinical events. Huesch et al. [15] evaluated chest imaging using free text reports and natural language processing for pulmonary embolism. They applied commercial text mining and predictive analytics software to preprocess the clinical text. The approach achieved good accuracy based on related work. Ben et al. [2] proposed a system using conditional random fields, and linguistic features to identify drug name recognition and classification. Tokenization, part-of-speech and parsing of the sentences are used as a preprocessing step through the Stanford parser. The proposal outperformed all teams, which participated in the DDI Detection and Classification task at SemEval 2013 with an F-measure of 0.80, and 0.658 for detection and classification, respectively. Lauren et al. [16] trained a kernel-based extreme learning machine (ELM) with multiple discriminant analysis on skip-gram and paragraph vector-distributed bag of words. The experiments showed that ELM provided a good performance when is compared with support vector machines (SVM) and multilayer perceptron (MLP). Forsyth et al. [13] described conditional random fields methods for the extraction of information from eletronic health records in regards to breast cancer symptoms. The system achieved an F-measure of 0.81. Kuteesa et al. [9] presented a survey of machine learning using HIV clinical records.
Methodology
Problems definition
In order to tackle this research, four tasks based on SemEval [6] were evaluated. We used the annotated corpus, where the events and their classification can be found, and each task was analyzed separately. A description of the classification is briefly outlined below. “actual” indicates the event which can be scheduled for the future or which has already happened. “hedged” represents events, which are strongly implied but are not a fact due to the lack of comprehensive evidence, safety, or liability. “generic” consists of events that are related to situations where a physician gives a justification for certain actions and decisions. “hypothetical” represents events which are based on assumptions. “n/a” represents the default value of an event. “aspectual” emphasizes the possibility of an event continuing or reappearing in the future. “evidential” provides information based on demonstration, evidence, confirmation or relevation which is related to tests, images, and human observation.
Data
The task 12 (Clinical TempEval) challenge for extracting temporal information from Mayo clinic medical reports provided a corpus of 750 full-text documents divided by clinical and pathological notes of patients with colon cancer [6]. Moreover, a XML format of all documents was provided from where we can extract span, contextual modality, polarity and type.
Data cleaning and preprocessing
Before applying conditional random fields, we applied some preprocessing and cleaning steps for a better understanding of the medical texts. Firstly, the texts were imported into XML format, where each individual patient record was divided into sections. The name sections were replaced by a number tag to avoid information loss and to weigh all section names. Furthermore, the exact positioning of the section within the clinical text was included. Figure 1 shows an XML format example used to parse each document. (This example was not taken from the original clinical records).

Clinical record into XML format.
Secondly, we parsed the XML format from each clinical document for the preprocessing step. The sections are divided into sentences using sent_tokenize from NLTK (Natural Language Toolkit) [8]. After that, each sentence was preprocessed to identify the words using tokenize from NLTK (Natural Language Toolkit) [8], and regular expressions when words are not separated correctly due to lack of white spaces, or to replace punctuaction marks and symbols by means of white space. The aim being to respect the position of the characters in the text for future analysis. Finally, following the domain expert, an event can be also a word combination, thus, the data preparation process includes bigrams. Notice that we use the sentence twice, first, by extracting tokens, then, by extracting bigrams. (The previously study [12] used the first part-of-speech of the first word; in this study, we used both part-of-speech of each word). A brief overview of this corpus after applying data cleaning and preprocessing is presented in Table 1.
An overview of THYME corpus used in this study
Several kinds of features were used in this study: linguistic (lemma, and part-of-speech), word-forms (word, and lowercase), and discourse level (word size, type and section information), lexical (prefix, and sufix), external resources (UMLS-Unified Medical Language System [1]), and word representation (word embeddings). Table 2 presents the feature representation used in this study. We applied two model representation: bag-of-words and bigrams. (This example is used for illustrative purposes only, and it was not taken from the clinical corpus).
Feature representation used in this work
Feature representation used in this work
In the experimental validation results, we trained and tested conditional random fields using different sets of features in order to validate and compare the influence of features in clinical records.
Word embedding
Word embeddings is distinguished for being a popular approach for capturing meaningful syntatic and semantic of words using real-valued vectors of configurable dimension. Word2vec is the most popular tool fot word embedding, which was introduced by Tomas Mikolov in order to provide semantic word embeddings and is based on unsupervised learning from selected training corpus [5, 20 24]. In this experimental layout, we trained word2vec on clinical records from SEMEVAL 2016 [6].
CRFs classifier
CRFs is an efficient supervised classifier, which is widely used for solving Natural Language Processing (NLP) tasks [12], mainly in named entity recognition. The basis of CRFs is based on the maximization of the conditional probability P (y|x) for a sequence of labels, y = y1, y2, . . . , y
n
, when an observed sequence of tokens, x = x1, x2, . . . , x
n
, is given. The time complexity of the training process [26] is shown in Equation (1):
We experimented with conditional random fields using CRFSuite 1 [22] for event detection, and Scikit-learn 2 [23] for contextual modality, polarity and type. Table 3 shows a simple example of the data format used by CRFSuite for training and tagging.
A simple example format for CRFsuite
We present experimental validation in this section and discuss conditional random fields, which was trained using the subcorpora “train” and “dev”, and was evaluated by using the “test” subcorpus. Experiments were perfomed using several types of features (LWD, LWDLE, and WR). Moreover, the best results were compared with SEMEVAL challenge [6] participating systems.
Subtask 1: Event detection
Figure 2 presents that the features LWDLE achieved a superior performance with an average F-measure of 0.926, followed by LWD with an average F-measure of 0.925. Whereas the results of WR provided an average F-measure of 0.915, when the model was tested on the test corpus. Finally, we also trained and tested on the training corpus to verify overfitting problem, where the combination LWD provided an average F-measure of 0.998 followed by WR with an average F-measure of 0.994, and LWDLE reported an average F-measure of 0.993.
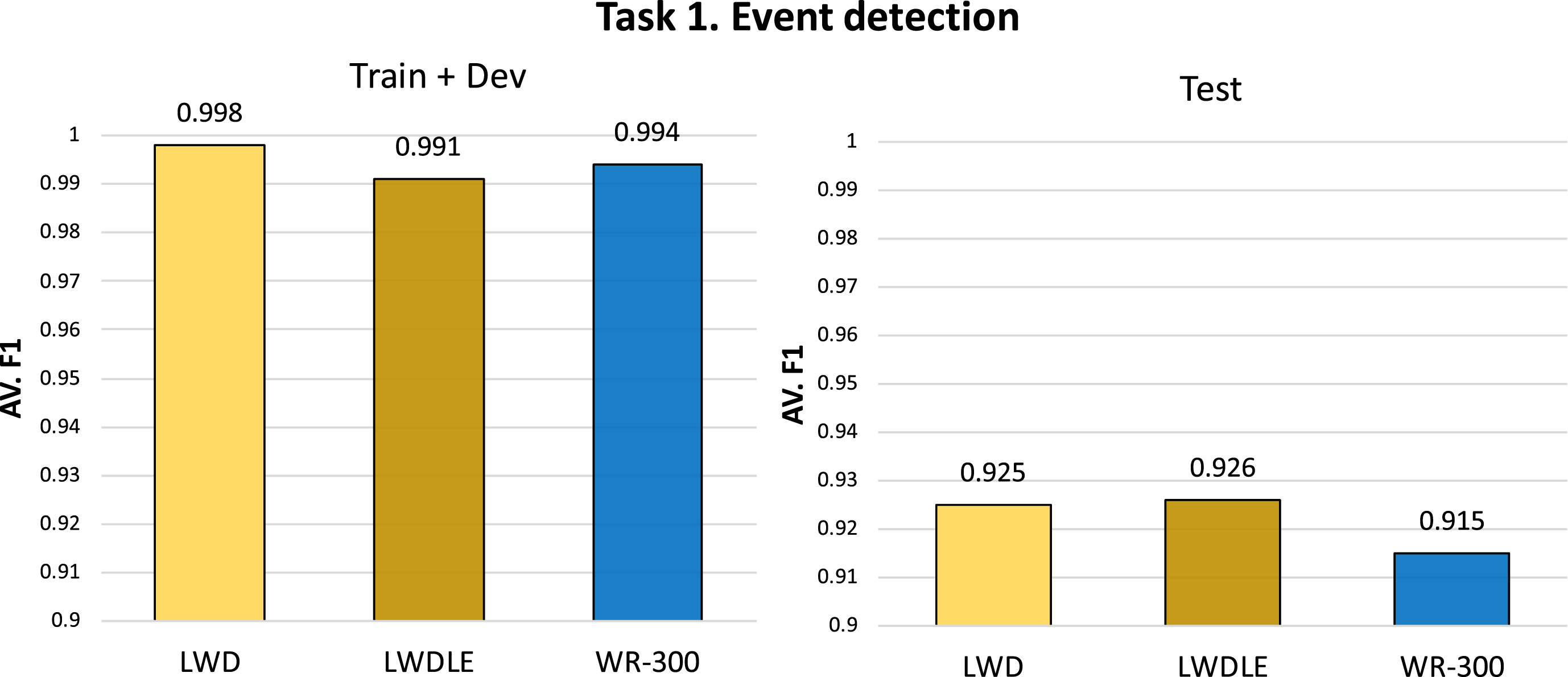
Average F-measure achieved by CRFs for the subtask: event detection.
According to the results in Table 4, the combination of features (LWDLE) gives us the best performance by reaching an average F-measure of 0.926. However, LWDLE did not get a significant improvemente when is compared with LWD or WR with 300 dimensions.
Prediction results for the task of event detection
As presented in Table 5, the best results by contextual modality were provided using LWDLE features with an average of F-measure of 0.508, followed by WR-300 and LWD with an average F-measure of 0.501 and 0.500, respectively. Regarding recall, we found that CRFs had significantly better results on predicting “actual” class than “hypothetical”, “hedged”, and “generic”.
Prediction results for the task of contextual modality
Prediction results for the task of contextual modality
As can be seen in Figure 3, CRFs produced more robust prediction over traning set with an average F-measure of 0.977, 0.971 and 0.863 using LWD, LWDLE and WR, respectively. However, it did significantly worst on predicting the test set. Such a difference in precision and recall can be due to the skewness of the dataset. This is due to the classes are unbalanced. Moreover, it can be appreciated that CRFs have an overfitting problem due to the algorithm not providing a correct generalization in testing set.
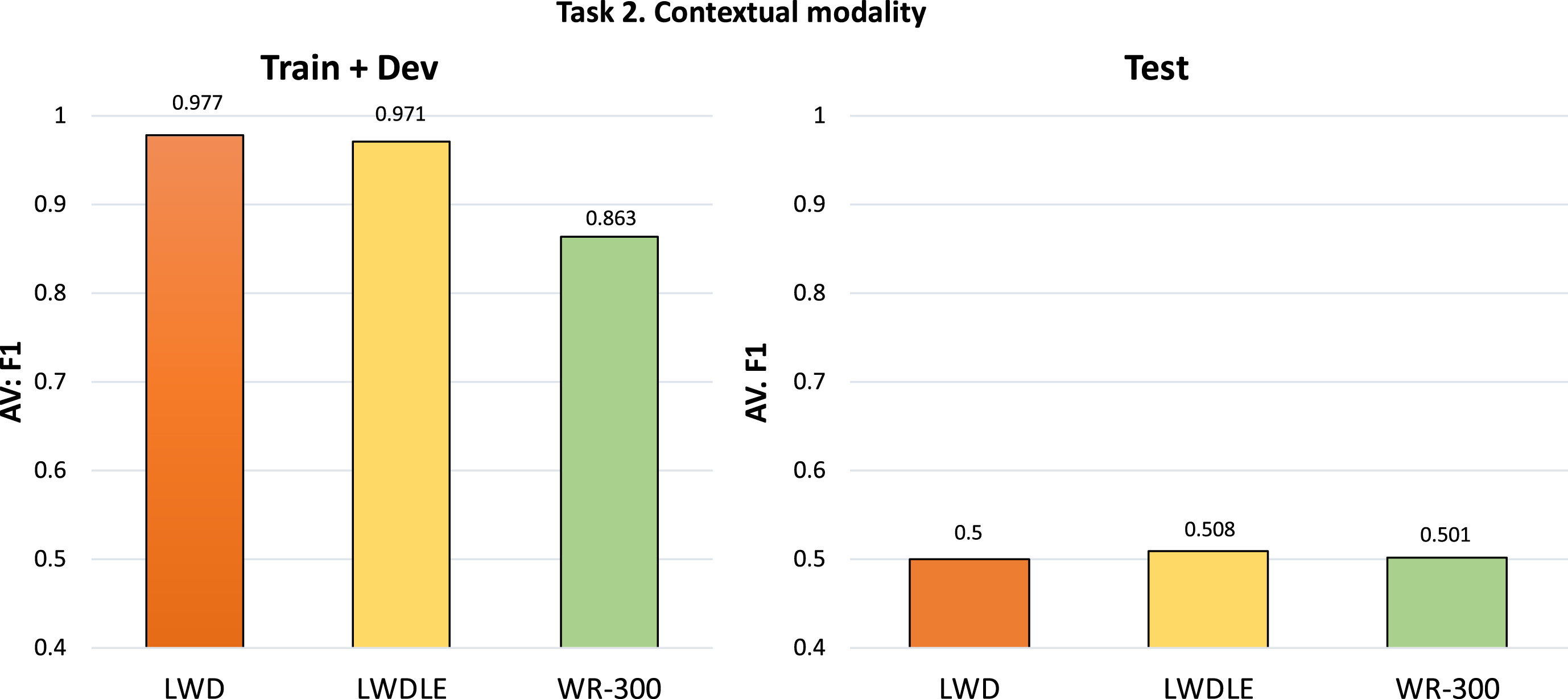
Average F-measure achieved by CRFs for the subtask: modality contextual.
For polarity classification, Figure 4 shows the best results on the test were achieved using LWD and LWDLE, instead of WR. LWD and LWDLE features achieved an improvement of 3.6% in detecting the event polarity over WR-300. Table 6, shows the recall, precision, and F-measure of polarity classification.

Average F-measure achieved by CRFs for subtask: polarity.
Prediction results for the task of polarity
A careful analysis of these results indicates that WR features provided better results than simples features: LWD and LWDLE. In fact, this is the unique task where word representation produced a best rate classification, considering that the average F-measure was 0.778.
Analyzing the results from Table 7 we see that, the difference in performance between the test and train set was larger due to overfitting problem. This is because CRFs fit very well in the training set but fail to generalize in the testing set (see Fig. 5).

Average F-measure achieved by CRFs for subtask: type.
Prediction results for the task of type
In order to directly evaluate and compare the performance of our proposals with the oficial results from SemEval 2016: Task 12 (Clinical TempEval), each clinical records was parsed into XML format based on CRFs results. We used the system provided by the SemEval challenge 3 to compute in terms of precision, recall and F-measure based on the correct number of events detected. In the academic SemEval 2016 Task 12: Clinical TempEval, it can be seen that the top system was achieved by UTHealth [17], which combined different features. For instance (a) Lexical features (b) Syntantic features (c) Discourse-level, (e) Word representation and syntactic, and (f) Features from external resources. These features were an adaptation from the state-of-the-art techniques for entity recognition, and they were used with hidden markov model and support vector machines. From Table 8, it can be seen that the top system UTHealth [17] achieved an F-measure of 0.903 for event detection, whereas, the analysis results of the proposed approach in terms of F-measure were LWDLE with 0.865, LWD with 0.862, and WR-300 with 0.844. As can be seen, our prediction model did not provide an improvement for solving event detection task. However, it provided a reasonable result due to an increase in F-measure of 11% above the worst team [4]. We believe that conditional random fields had not improved the results for this task. This can be explained by the role the skewness, and the feature extraction used in this task.
Comparison of our results with those of SemEval: Task 12 Clinical TempEval 2016, subtask of event detection. The rank is shown by F-measure. Some systems are omitted; see [6] for a complete list
Comparison of our results with those of SemEval: Task 12 Clinical TempEval 2016, subtask of event detection. The rank is shown by F-measure. Some systems are omitted; see [6] for a complete list
In Table 9, we can see what the UT-health team [17] continues to hold down first place in the competion for classification event based on its contextual modality. However, the results presented by the winning approach showed a slight improvement when is compared with our best results using LWD features (F-measure = 0.854), which are not significantly different from the first-ranked system (F-measure = 0.855).
Comparison of our results with those of SemEval: Task 12 Clinical TempEval 2016, subtask of contextual modality. The rank is shown by F-measure. Some systems are omitted; see [6] for a complete list
As presented in Table 10 the best result by polarity classification was obtained using LWDLE features. These feature combinations achieved an F-measure of 0.889, whereas the winning approach [17] achieved a result of 0.887 in terms of F-measure.
Finally, Table 11 shows the experimental results using our proposals, as compared with the official results from SemEval challenge [6] for detecting type event. LWDLE and LWD features achieved an F-measure of 0.885 and 0.884, respectively. These results outperformed the UTHealth team [17], which obtained an F-measure of 0.882.
Comparison of our results with those of SemEval: Task 12 Clinical TempEval 2016, subtask of polarity. The rank is shown by F-measure. Some systems are omitted; see [6] for a complete list
Our results in comparison to those of SemEval: Task 12 Clinical TempEval 2016, subtask of type. The rank is shown by F-measure. Some systems are omitted; see [6] for a complete list
The results obtained in this section showed that our approach of CRFs provided better F-measure for subtasks: classification based on contextual modality, polarity and type than the top system [17].
As presented earlier, the best improvements in subtask 1: event detection, 2: contextual modality, and 3: polarity were gained by LWDLE (linguistic, word-forms, discourse level, lexical and external resources) variables. Thus, we found out that simple features can be more effective in such subtasks, while word embeddings are not as helpful. However, word representation achieved the best results in Subtask 4: type, but when its results were compared with the works in SemEval 2016, these not provide competitive results. This can be explained by the fact that it was not possible to predict events correctly. As this study shows, a substantial contribution to current research is that CRFs and feature extraction can predict significantly better than the works presented in SemEval 2016 Task-12: Clinical TempEval for predicting two subtasks, 3: polarity and 4: type, where LWDLE variables play a key role in improving the performance of the before mentioned tasks. However, we could not improve he results of winnning aproach for subtask 1: event detection and subtask 2: modality contextual using the feature extraction proposal. For this reason, future work will involve several direction such as (a) usage of more clinical data, (b) deep semantic analysis, (c) evaluation of CRF against several machine learning algorithms, (d) explorarion of other types of features.