
Abstract
Fine-Grained ship classification is quite challenging because the visual differences between the subcategories are small. Due to the large intra-class similarity, it is very difficult to classify the ship objects without bounding box/part annotations. In this paper, we propose a model that combines multiple deep CNN features and use fusion strategies to explore of multi-scale features relationship. Because different levels/depths CNN features have different properties, so we combine multiple low-level local CNN features with high-level global CNN feature for object classification. The model shows a good way of tailoring pre-trained CNN models to fine-grained ship classification, which have lower cost in computation and storage compared with some state-of-the-art CNN methods and achieves the significant classification performances in FGVC-Aircraft and Stanford Cars datasets.
Introduction
Automatic ship recognition plays a key role in military and civilian fields such as precision guidance, maritime traffic management, anti-terrorism, search and rescue, etc. In recent years, the technical literatures of ship target classification based on optical images are increasing. Christina Corbane et al. [1] used statistical methods and mathematical morphology such the wavelet analysis and Radon transform to detect ship in high spatial resolution optical imagery. QingJiang Wang et al. [2] proposed an approach based on Bayesian networks and use two-step approach to classify ships. J. Antel et al. [3] identified ships from Quickbird colour images, which used a Bayessian classifier based on image-extracted features. Haiyang Chen et al. [4] presented a kind of improved FB algorithm to compute evidences with a single or more states and used fuzzy discrete dynamic Bayesian network model for ship recognition. Aleksey Vladimirovich Dolgopolov et al. [5] used deep neural network auto encoder for automatic ship feature extraction. Jiexiong Tang et al. [6] proposed a compressed-domain ship detection framework using DNN and ELM for optical space borne images. Ying Liu et al. [7] proposed a novel ship detection and classification approach which utilized deep convolutional neural network (CNN) as the ship classifier.
In the previous works, there are many problems in ship recognition which are summarized as follows: a) Due to ship images are affected by weather, light, sea conditions, image sensors and other factors, the feature extraction of ship target is often difficult. b) With the increase in the number of ship images, the traditional ship recognition pipeline: feature extraction and classifier are not satisfied with the requirements of efficient processing. c) At present, it is difficult to recognize the ships belong to the same class,because there are subtle differences within subordinate ship categories. Now fine-grained classification has received wide attention, such as bird classification [8], flower classification [9] and car classification [10]. This inspires us to use fine-grained classification method for identifying ship subordinate categorization.
In the same categories, the visual differences are subtle and which be easily overwhelmed by factors such as pose, viewpoint, or location of the object in the image [11]. Therefore, fine-grained datasets require strong annotations e.g. bounding boxes for object or even object parts. However, in practical applications, many fine-grained datasets do not have bounding boxes. Moreover, human-defined regions or the regions learned by existing unsupervised methods may not be optimal for classification [12]. Recently, many models based on convolutional neural networks (CNNs) obtained outstanding performances on several fine-grained classification. These models usually have several dozen million weights, which cannot be properly trained on mid-scale datasets for easily falling into overfitting when training. The previous researches use multiple CNNs to extract discriminative features from local object region, most of them just concatenate these features together prior to classification. However, such a direct combination does not explore the relationship between these features and utilize the feature relationships.
To address these issues mentioned previously, we propose a novel multi-feature fusion convolutional neural network (DMCFN) for fine-grained ship recognition without bounding box/part annotations. The proposed DMCFN is a stacked network, which takes the input from full images to fine-grained local regions at multiple scales.
The contributions of this work are three folds: We propose a novel multi-feature fusion convolutional neural network for fine-grained ship classification, which uses two kind of deep network models to extract global feature and local feature separately. We use more detailed local features from lower layers and achieve superior performance over the state-of-the-art approaches based on the features extracted from the top layer. We use structural regularization on the fusion layer to explore the correlations of multiple features.
The remainder of this paper is organized as follows. Section 2 briefly reviews the related works. Section 3 elaborates the proposed framework, including formulation and optimization. Extensive experimental results and comparisons with alternative methods are given in Section 4. Finally, we discuss what we learned, future work and conclusion in Section 5.
Related work
Fine-grained image recognition
Fine-grained visual categorization has been widely studied. There are some works depend on the hand-crafted feature description and encoding methods for fine-grained classification. In [13], Hierarchical Structure Learning (HSL) algorithm and Geometric Phrase Pooling (GPP) algorithm are used to capture mid-level structures for fine-grained classification. The method of [14] detected volumetric part models based on Poselets and used Stacked Evidence Trees to aggregate information about part properties.
Due to the success of deep learning, Convolutional neural networks (CNN) have been widely used in fine-grained image recognition. TsungYu Lin et al. [11] built a bilinear CNN model, which extracted two local features and multiplied these features to obtain an image descriptor. Zhicheng Yan et al. [15] proposed a Hierarchical Deep Convolutional Neural Network (HD-CNN) that decomposed fine-grained classification task into two steps.
In many recent studies, many works incorporated precise part information to improve fine-grained classification. Jonathan Krause et al. [16] proposed a method based on generating parts using co-segmentation and alignment without part annotations. Philippe-Henri Gosselin et al. [17] proposed a search-based architecture to search for more informative parts and thus improved recognition. Chen Huang et al. [18] explored a task-driven approach for progressive part detection, which provided the most discriminative visual features for the subsequent object classification. Jonathan Krause et al. [19] proposed an object representation that detects important parts in a fully unsupervised manner. Jianlong Fu et al. [20] considered the relationship between region detection and fine-grained feature learning and recursively learned discriminative region attention and region-based feature representation at multiple scales in a mutually reinforced way.
Although there are a significant performance improvement by using CNN, from the above methods we can find out that global CNN features extracted from full images are too spatially rigid to be optimal for fine-grained classification. Therefore, we consider classifying images using local information combined with global information. Results from these works show that the local features are more competitive than CNN features based on full image and can provide important complementary information.
Multi-feature fusion
Recently, several feature fusion methods have been proposed. Jiang Liu et al. [21] adopted a weighted fusion scheme to combine the content and the context features without need of human interaction. Anran Wang et al. [22] proposed a modality and component aware feature fusion framework to combine regressoes for FV features and global CNN features. Heechul Jung et al. [23] used two models to extracts temporal appearance features and temporal facial landmark points, then adopted a new integration method to boost the performance of the facial expression recognition. Zuxuan Wuet al. [24] proposed a regularized DNN to lefusion layer is adopted to impose regularizatarn feature relationships an class relationships jointly. Xin Lu et al. [25] incorporated heterogeneous inputs generated from the image, which included a global view and a local view, and unified the feature learning and classifier training in a double-column deep convolutional neural network.
Approach
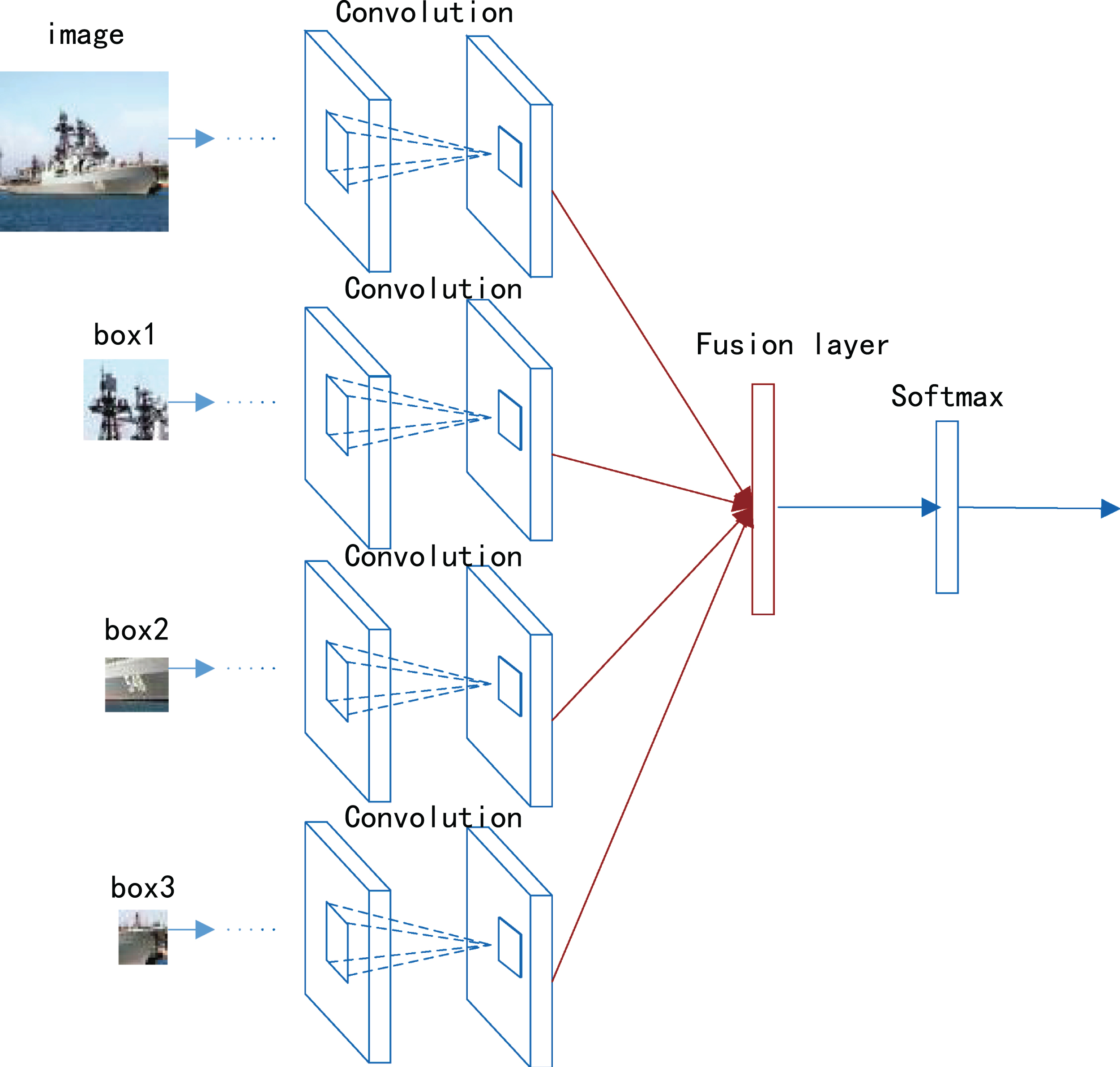
In this section, we will introduce the proposed multi-feature fusion convolutional neural network (DMCFN) for fine-grained image recognition. The DMCFN comprises two kind of deep networks: the deep coarse component network (DCCN) and the deep fine component network (DFCN). The DCCN based on a CNN, which is used to extract the high-level semantic feature necessary for ship recognition. The DFCN catches detailed local features and help to separate the target from distracters. In our work, we combine one DCCN and three DFCN to increase the ship recognition performance. Especially, this structure can be trained end to end. The architecture of our deep convolutional neural network is shown in Fig. 1.

The framework of multi-feature fusion convolutional neural network (DMCFN), which is composed by one deep coarse component network (DCCN) and three deep fine component networks (DFCN). These networks receive an image as input without any bounding box or part annotation. A fusion layer is adopted to impose regularization on the network parameters. Finally, a joint fine-tuning method is used on these networks.
In this section, we will introduce the proposed multi-feature fusion convolutional neural network(DMCFN) for fine-grained image recognition. The DMCFN comprises two kind of deep networks: the deep coarse component network (DCCN) and the deep fine component network (DFCN). The DCCN based on a CNN, which is used to extract the high-level semantic feature necessary for ship recognition. The DFCN catches more detailed local features which help to separate the target from distracters. In our work, we combine one DCCN and three DFCN to increase the ship recognition performance. Especially, this structure can be classified by end to end. The architecture of our deep convolutional neural network is shown in Fig. 1.
The basic idea for designing deep coarse component network is to extract global high-level features. There are many exist deep networks used for large-scale image datasets which have achieved outstanding performances on fine-grained classification. Their main disadvantage needs to train a large number of weights. So a complex system cannot be learned properly on a mid-scale fine-grained ship dataset. To deal with this issue, we present deep coarse component network with a moderate depth and a moderate number of parameters to avoid overfitting.
The deep coarse component network consists of three convolutional and two fully connected layers. The first convolutional layer is composed of 64 filters, filters of the first convolutional layer have size 7×7 and compute convolution at a global scale. Then the ReLU activation function is applied to the convolved patch. Next, we use a 2×2 max-pooling function in each response map with stride 2, which yields position invariance over the patches. We additionally apply convolution layer with a 5×5×64 kernel and the activation function ReLU. Max-pooling is performed the same way as in the first convolutional layer. The last convolutional layer comprises 64 filters of size 5×5. Finally, these output values are passed through the two fully connected layers and then classified using softmax. Batch Normalization (BN) is applied to the activations of these convolutional layers, following by the Rectified Linear Unit (ReLU) for non-linearity. The outputs of this network are finally normalized through a softmax step, computed as follows:
Where v is the score of filter i from previous layer and fsoftmax is the corresponding output. This structure is summarized in Table 1. For training our network, the stochastic gradient descent method is used for optimization, and dropout [26] and weight decay methods are utilized for regularization.
DCCN structure
The statistics of fine-grained datasets used in this paper
The DCCN extract global high-level features, but may discard local details, such fine-scale object parts, which are significant cues to discriminate fine-grained categories. So we propose deep fine component network to capture local visual information.
In practical application, many datasets don’t have bounding box or part annotation, besides, human-defined regions may not be optimal for image classification. Bolei Zhou et al. [27] pointed out that convolutional units in convolutional neural networks can play the role of target detector without supervised information of target location, but the ability of the convolutional layer to locate the target is lost when adding the full connection layer to the target classification. They used the global average pooling (GAP) layer to instead of the full connection layer. And the use of GAP can identify the regions in the images which are significant to the classification only through a single forward-pass.
In deep fine component network, we use class activation maps (CAM) which can identify the discriminative regions of the image by projecting back the weights of the output layer on to the convolutional feature maps. We use a simple threshold technique to segment the heatmap, and generate a bounding box. Lijun Wang et al. [28] proposed that CNN features at different levels/depths have different properties. Such a top convolutional layer captures more abstract and high-level semantic features, and a lower layer provides more detailed local features which help to separate the target from distracters. So we map the box to the lower convolution layer of the convolution neural network to get the local features information.
By using a RoI pooling layer, we extracts a fixed-size feature map from the feature maps for the corresponding box, as shown in Fig. 2. The features inside the box are converted to a small feature map with a fixed spatial extent of of the RoI pooling layer. Then the small feature map is feed into a fully connected layer. A final fully connected layer computes the score of the input image for each class. In our framework, we train three deep fine component network by using bounding boxes with three scales separately. For the training of DFCN, we use transfer learning [29] to overcome the deficit of training samples for fine-grained categories. So we use ImageNet-trained CNN and fine-tune the parameters of CNN on target datasets.

The framework of deep fine component network (DFCN).
A lot of method concatenated multiple extracted features together simply to form a high dimensional feature, usually result in limited performance since the intrinsic relations among the features extracted from the multiple models are overlooked. Therefore, we use an integration method [24] to fuse the features from DCCN and DFCN that fully leverages the complementary clues from various features.
Below we use a regularized variant which is able to accommodate the deep fusion process of multiple features from these trained networks. We utilize one additional layer for the fusion of all the features, as shown in Fig. 3. Let
The fusion layer.

Examples from (left) Vessel dataset, (center) FGVC-Aircraft dataset, and (right) Stanford Cars dataset used in our experiments.
This fusion layer can be written as the following:
Where Y
F
,
Where
The learning speed of DCCN is different from DFCN, because they have different layers. To address this issue, we develop a learning algorithm for optimizing the model parameters efficiently in two steps. First, the DCCN and DFCN are trained seperatly. Next, we retrain the entire network.
(W
P
, Ψ) are coupled with each other. Therefore, we adopt the alternative optimization method to iteratively minimize the objective with respect to
By fixing Ψ, we first consider the minimization problem over
We then minimize the objective function over Ψ with other variables being fixed. The problem in Equation 3 degenerates to:
The optimization pipeline is summarized in Algorithm 1.
Training Procedure of DMCFN
Comparison to previous works
Recognition comparison of different methods on Vessels dataset
Recognition comparison of different methods on Vessels dataset
Recognition comparison of different methods on FGVC-Aircraft dataset
Recognition comparison of different methods on FGVC-Aircraft dataset
The previous works [28, 37] show that the low-level CNN features is more sensitive to appearance variations, and compared to high-level CNN features which can balance feature representativeness and generalization ability. Therefore, we verify this on these three datasets ranging from low-level to high-level vision. The classification accuracy using the feature maps for these three datasets are demonstrated in Table 6. In our experiments, we found that in FGVC-Aircraft datasets, features from conv4-3 does well on this dataset achieving 92.8% accuracy. However, in Stanford Cars dataset, features from conv5-1 achieving 94.3% accuracy. Maybe compared to aircrafts, cars are smaller and appear in a more cluttered background. The feature maps of conv5-1 may better separate car from non-car objects and preserve more middle-level information to achieve recognition that is more accurate.
Classification accuracy using different feature maps on three datasets
Classification accuracy using different feature maps on three datasets
There are a few methods proposed for fine-grained classification. Most of them directly concatenated multiple features together prior to classification. Such a direct combination does not adequately explore the relationship between global features and local features. Therefore, we conduct the experiment to test the fusion performance.
The λ1 and λ2 parameters of DMCFN used on three datasets are given in Table 7.
The parameters of DMCFN used on vessels dataset, FGVC-Aircraft and Stanford Cars
The parameters of DMCFN used on vessels dataset, FGVC-Aircraft and Stanford Cars
In order to test the ability of the fusion layer based on our method, we evaluate the performance using regularizations on fusion layers and concatenating multiple extracted features on three datasets based on Vgg-16. We plot the performance w.r.t. the level of features in Fig. 5. Using regularizations on fusion layer clearly achieves higher performance than concatenating features straightly. And we also found when the low level features are selected, the improvement of our method is even more significant.
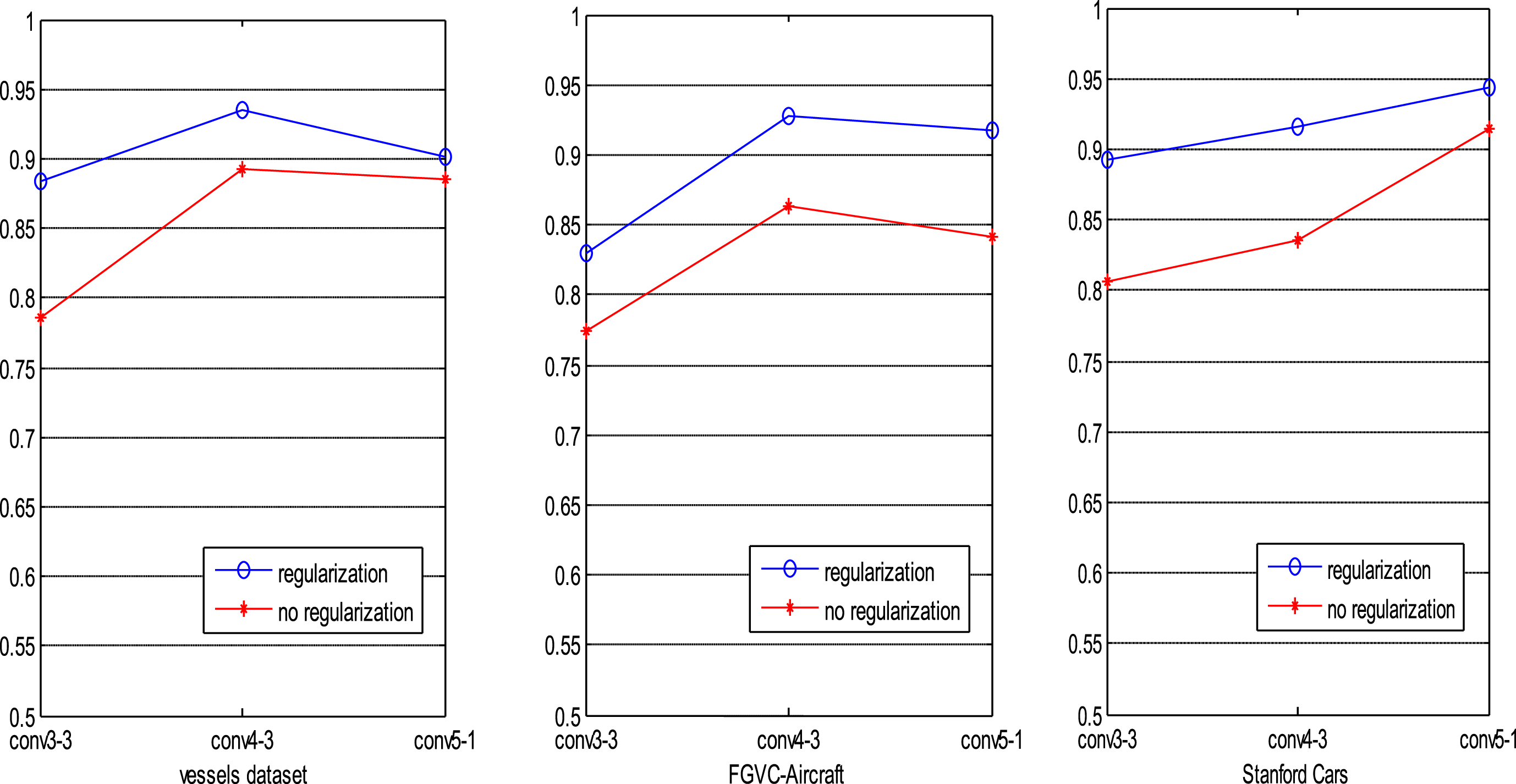
Classification performance on the three datasets using feature maps from different levels. We plot the results of DMCFN without regularization (red), DMCFN with regularization (blue).
In this paper, we propose a multi-feature fusion convolutional neural network (DMCFN) for fine-grained ship recognition. The proposed architecture does not need bounding box/part annotations for training. We observe that convolutional features at different levels have different properties, and fuse representation of multiple features to find out the correlation between global feature and local feature, which improve fine-grained classification performance obviously. We do extensive experiments demonstrate the superior performance on other fine-grained recognition tasks such as FGVC-Aircraft dataset and Stanford Cars dataset. As part of future work, we intend to investigate the applicability of the DMCFN in more complex environment. Another direction is to reduce the multiple features redundancy, computational complexity and time complexity.