
Abstract
Nowadays people are sharing their information in digitally, and their information plays the significant role in public sectors and business world assist in understanding the social behavior, statistical analysis and drafting the business policies for future direction. At the same time, users’ personal information should be preserved from adversaries while data publishing. Privacy preservation is one of the main agenda of data publishing, K-anonymity and its families likel-diversity and t-closeness which are the most familiar models to preserve the sensitive information of individuals in data publishing. Besides, data reliability is also the main factor of reliable anonymized data. Various anonymization techniques which are performed the data protection against attack models; however, the privacy models satisfy the privacy preservation effectively. The data utilization is also a vital account to achieve the purpose of data publishing. Moreover; Publisher focuses on the utilization of anonymized dataset that might be helpful to analyze the meaningful data. Otherwise, the potency of anonymization leads to diminishing the data utility of anonymized dataset and weakening the purpose of data publishing. In this proposed method aims to improve the utilization of anonymized data in data publishing with minimal information loss based on fuzzy alpha-cuts. Triangular membership function has applied over in the proposed method to generalize the quasi-identifiers by constructed alpha cut sets and taxonomy tree. The evaluation results are compared with an existing model concerning information loss and time execution time metrics. The performance of the proposed method is encouraging that based on the experimental results.
Introduction
In the current decade, sharing and publishing data are general activities in our digitally well-connected society. Concurrently, customers have rights to keep their sensitive data in secure. The business analyst should concern about customers data privacy[35–37]. So individual privacy should be protected when publish or share the data to either public or research communities. Removing sensitiveinformation from the microdata is a general practice of data publisher. Researchers apply the data mining techniques and aim to discover the knowledge from the massive volume of data. While trading with sensitive information and others, privacy preservation might be confirmed. So, the data needs to be preserved from various attacks. Privacy preservation is a crucial task in data publishing since an adversary can assume the sensitive information easily by using background knowledge of data owners. In such scenarios, the solutions can’t be deriving for privacy preservation efficiently and providing an optimal solution for all publishing scenarios is impossible. Many researchers have been proposed the anonymization techniques and models [2–4, 33] for addressing the privacy leakage and also strengthening the privacy models and algorithms. At the same time, the utilization of anonymized dataset should be considered an important point. The utility of anonymized dataset justifies the meaning and consequence of reliable published data. Strengthening the anonymization leads to increase the information loss, and the preserved data becomes useless. To achieve privacy preservation, the publishers usually try to hide or remove the sensitive attributes of an individual to whom data concern implement a set of transformations to the microdata before publishing it. These transformations include. (1) data suppression (replacing some values with a special value, indicating that the replaced values are not disclosed) [18, 21], (2) data generalization (replacing some values with apparent value in the taxonomy of an attribute. [1, 30]), and (3) Additive noise (the general idea is to replace the original sensitive value s with s + r where r is random value drawn from some distribution) [23]). Researchers focus the research on two aspects namely strengthening privacy and meaningful data utility with minimal loss of information [14]. Most of the contributions concentrate on increasing the privacy of published data and not considered the data utility. Studying the preserving privacy has been the spotlight of much research. To the best of our knowledge, most of the work in determining the optimal transformation to be performed on a database before it gets disclosed is inefficient in the sense that rising the table dimension will significantly improve the performance. Moreover, data anonymization techniques do not provide enough theoretical evidence that the disclosed table is immune from security breaches. Anonymization techniques include (1) hiding the sensitive identities by constructing each record indistinguishable from at least k–1 other records [3] (k-anonymity), assuring that the distance between the distribution of sensitive attributes in a class of records and the distribution of them in the whole table is no more than t [22] (t-closeness), and (3) ensuring that there are at least l distinct values for a given sensitive attribute in each indistinguishable group of records [5, 25] (l-diversity). Indeed, these techniques do not completely prevent re-identification [22]. It is shown in that the k-anonymity technique suffers from the curse of dimensionality and the level of information loss in k-anonymity may not be acceptable from a data mining point of view, because the specifics of the inter-attribute behavior have a potent revealing effect in the high dimensional case. A realization of t-closeness is proposed in [6], called SABRE. It partitions a table into buckets of similar sensitive attribute values in a greedy fashion, and then it redistributes tuples from each bucket into dynamically configured equivalence classes (EC). SABRE adopts the information loss measures for each EC as a unit rather than treating released records individually. It lacks the theoretical foundations for privacy guarantees and efficiency. In [12], a heuristic called ARUBA is proposed to address the tradeoff between data utility and data privacy. Although the proposed algorithm determines a personalized optimum data transformation based on predefined risk and utility models, it provides neither scalability nor theoretical foundations for privacy guarantees. The notion of Differential privacy [7, 27] has become very popular in the database communities. It requires that the distribution of outcomes of computation does not change significantly when one individual changes their input data. A randomized query satisfies differential privacy if the likelihood of obtaining a certain answer from a database x is not “too” different from the likelihood of obtaining the same answer from other databases which differ from x for only one individual. There are some different approaches such as fuzzy approaches [9, 31] take into an account of privacy preservation. L.Troiano et al. [15] and I.Diaz et al. [26] have attempted fuzzy IF-THEN rules to hide the sensitive information from the raw dataset. Fuzzy mathematics based method transformed the prime tuples for personalized the privacy preservation for both numerical and categorical quasi-identifier attributes. Manolis Terrovitis et al. have attempted to increase data utility and eliminate privacy leakage through the quasi-identifier transformation. G.R.Zhang [32] has approached the fuzzy-based method for categorical attribute and providing taxonomy tree based mapping table. I.Diaz et al. [13] have proposed a framework of fuzzy information that focuses on the counting elements that belong to equivalence class through understanding the concept of cardinality. Fuzzy partitions method overcomes some of the privacy treats by using particular properties of fuzzy sets.
Contribution
In this paper, the proposed method addresses the problem of weakening the utility of anonymized data when taking care of its risk below a certain acceptable threshold. The main agenda of the paper is to maximize the utility of anonymized dataset [16] and minimize information loss. Fuzzy logic concept applied into proposed work for generalizing each tuple of quasi-identifiers with respect to the taxonomy tree. Threshold value has introduced to create alpha-cut sets for constructing a taxonomy tree. Triangular membership function finds the fuzzy value of each tuple that the values are generalized by alpha-cut sets. Existing methods have applied the generalization anonymization until achieving the conditions of privacy models like k-anonymity, l-diversity. Existing methods those are not possible to attain privacy preservation without losing the confidence of utility maximization. For overcoming the issue, the research work focuses on the increasing utilization of anonymized dataset without following the existing privacy models and minimizes the information loss. The data flow diagram of the proposed work as shown in Fig. 1.

Workflow of the proposed method.
Fuzzy sets
Fuzzy sets expressed as an extension and generalization of the concepts of standard crisp sets [38–40]. The unit interval values between the binary numbers [0,1] which represent the degree of membership function μA(x) of fuzzy sets The degree of membership μA(x) assumes values in the range from 0 to 1, i.e., the membership is set to unit interval [0,1] or μA(x) [0,1]. A fuzzy set A in the universe of discourse U can be defined as a set of ordered pairs, and it isgiven by□
Membership function defines the fuzziness in a fuzzy set irrespective of the elements in the set, which are discrete or continuous. The membership functions are generally represented in graphical form. There exist certain limitations for the shapes used to represent a graphical form of membership. In Equation 1, μA((x) is called a membership function of A. The membership value ranges in the interval [0,1], i.e., the range of the membership function is a subset of the non-negative real numbers whose supremum is finite.
Figure 2 shows the graphical representation of the triangular membership function. It is specified by three parameters {a, b, c} as follows
Triangular-shaped membership function.
The parameters {a, b, c} (with a < b < c) determine the x coordinates of the three corners of the underlying triangular membership function.
The set A
λ
(0 < λ < 1) called lambda (λ) cut set is a crisp set of the fuzzy set. The set A
λ
is called strong lambda-cut set that consists of all elements of a fuzzy set whose membership functions have values strictly greater than a specified value. Any particular fuzzy set A can be transformed into an infinite number of the alpha-cut set as shown in Fig. 3. Because there are an infinite number of values alpha can take in the interval [0,1]
Triangular-shaped Membership Function.
Let Q be the set of quasi-identifiers Q={a1, a2, a3.… a
n
} where i = 1,2,3... n in a raw data table. Each quasi-identifier a
i
having n number of tuples t
j
where tj = 1, 2, 3 … n and It indicates that the t
j
ln a
i
. Our proposed method deals with fuzzy set theory. Therefore, the quasi-identifier a
i
where i = 1,2,3 … n transformed into fuzzy set
The Triangular membership functions are represented in graphical form. In Equation 3
The triangular curve is a function of a vector, t j , and depends on three scalar parameters R, S, andT, as given by
Let R = min(t
j
), S = Median(t
j
) and T = Max(t
j
) be the parameters that refer to the boundary of the membership function of the fuzzy set (a) α-cut sets for fuzzy set 
Taxonomy is a practice of classification of things which is a representation of the generalized attributes. In the generalization process, the alpha-cut sets involve in such a way that is constructing the taxonomy. In fig, 4b shows the taxonomy tree of alpha-cut sets α k .
Generalized alpha-cut set values
Generalized alpha-cut set values
Fuzzy value of each tuple belongs to alpha-cut sets α k in such a way that the crisp value of t j is also belongs to any one of the branches of the taxonomy tree.□
Alpha-cut set values of taxonomy transform into crisp value based on the computation steps that are given below.
Let the threshold value E = m, then the number of alpha-cut sets is m + 1, Let R, S, T are variables of triangular membership function and crisp value of alpha-cut set C(α k )
Step 1: Let g is value of difference between alpha-cut set values.
if min(α k ) then
g - abs(S − R)/m + 1.
Step 2: Let α k where k = 1
Step 3: If k = 1 then
C (α k ) = R + g
Else
C (α k ) = C (α k ) + g
Step 4: Increment the k value by 1
Step 5: do step 3 to 4 unit k = m + 1
if max(α k ) then
g = T − S/m + 1
Step 7: Let α k where k = 1
Step 8: If k = 1 then
Max(C (α k )) = S + g
Else
Max(C (α k )) = Max (C (α k )) + g
Step 9: Increment k value by 1
Step 10: do step 8 to 9 unit k = m + 1
Close
Quasi identifier a
i
= {20, 24, 28, 37, 45, 57, 64, 78,81} where i = 1,2,3 … n have transformed into fuzzy set μ (t
j
) = {0, 0.16, 0.32, 0.68, 1, 0.7, 0.47,0.08,0} where j = 1,2,3 … 7 derived triangular member function. Let set the threshold value m = 2 which generates the alpha-cut sets α
k
where k = 1, 2, 3 then the alpha-cut sets facilitate to construct the taxonomy tree as shown in Fig. 5a and 5b.
(a) Alpha-cut sets for fuzzy set a
i
with threshold value = 2. (b) Taxonomy tree of fuzzy set 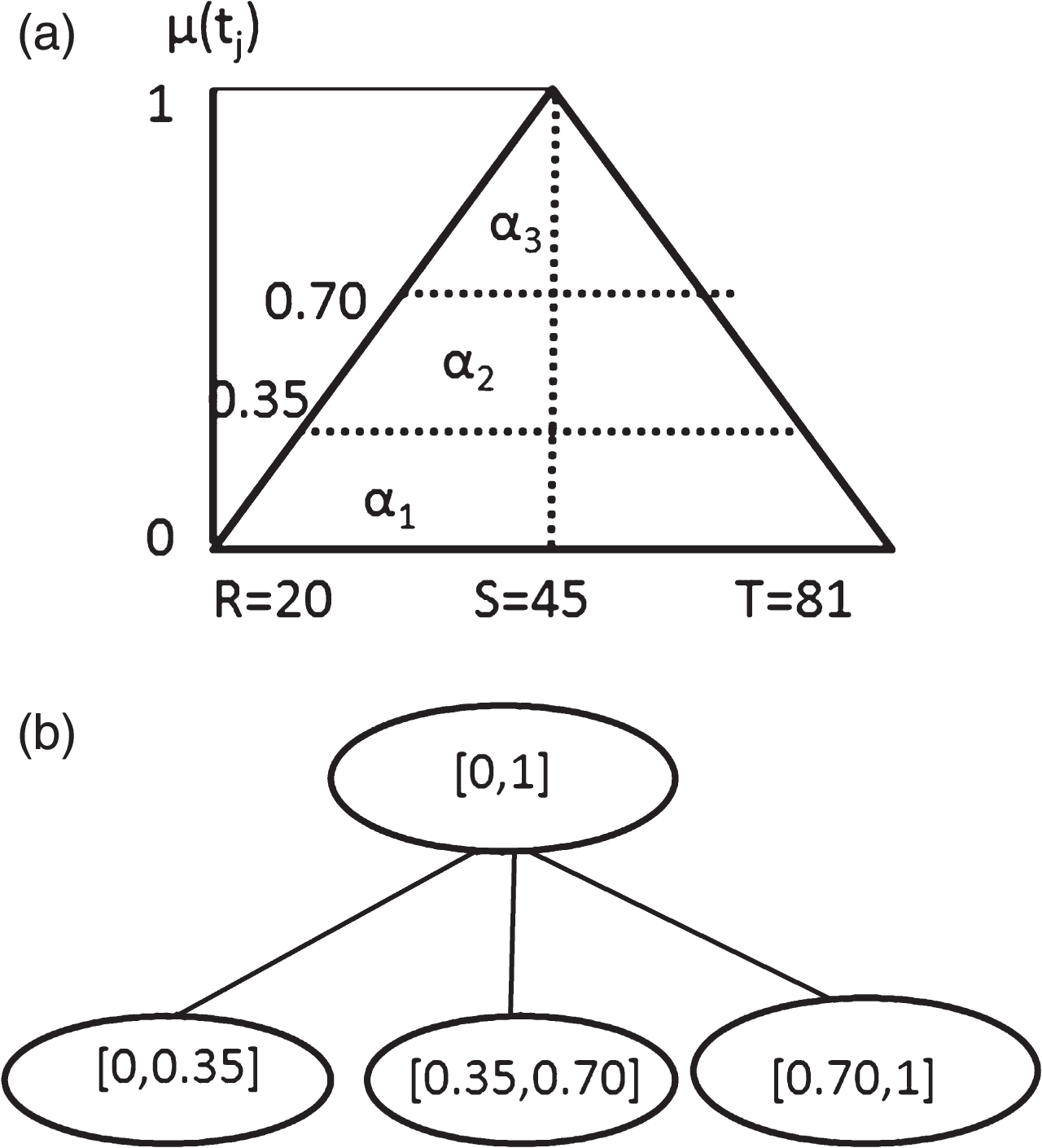
The Triangular Membership Function returns the fuzzy value
Let α k = {0.0.35, 0.7, 1}, median(S)=45, R = 20 and T = 81.
Min(α k )
Let g is a value that difference between each alpha cut set.
Maximum and minmum crisp values of alpha-cut set values
The motivation of the experimental analysis evaluates the proposed method through the comparison of other privacy models. The proposed method appraise in terms of Information loss and execution time.
The experiments have performed on 2.6 GHz Intel Core 2 Duo machine with 2 Gigabyte RAM and Windows 7 Ultimate operating system. The Netbeans java software tool has used to write Java code. Our proposed method implemented on an adult dataset which contains 32564 tuples form UD adult dataset which is a usual point of reference for privacy-preserving techniques.
Metadata about adult database

(a). Information loss, No of quasi identifiers d = 3, No of records 5000 to 30000. (b). Information loss. Set quasi identifiers d = 3, 4, 5, 6 and 7.

(a) Execution in minutes, No of quasi identifiers d = 3, No of records 5000 to 30000. (b) Execution in minutess. Set quasi identifiers d = 3, 4, 5, 6 and 7.
where; |t g | is the number of domain values that are descendants of t g
|D A | is the number of domain values in the attribute A of v g .
ILOSS(t g ) = 0 if t g is an original data value in the table.
In words, ILOSS(t g ) measures the fraction of domain values generalized by t g .
The loss of a generalized record r is given by
Where w
i
is a positive constant specifying the penalty weight of attribute A
i
. The overall loss of a generalized table T is given by
The experimental method evaluates the performance of information loss from two different trials. In the first trial, the number of records increases in each iteration from 5000 up to 30000 with interval value 5000. In Fig. 6a shows the information loss escalates gradually up to 15,000 records in x axis then the slightly go down because of the frequency value of quasi-identifier attribute values. From 20000 records the trend of information loss value steady increase up to 30000 records. According to first trial setup, the outcome of information loss metric value is encouraged when compared with existing methods. In the Second trial, the number of quasi-identifier increase in each run starts from three quasi-identifiers to seven. In Fig. 6b, the metric value starts from around 0.02 and steady increase. In the first trial, experimental configuration deals with the constant value of the number of quasi identified so that the information loss value to the number of records which increase in each run. In the second trial, the frequency value of attribute values of each quasi-identifiers which increase in each run to the number of quasi-identifier attributes. We observe that the information loss value is high when the number of quasi-identifier increasing so that the quasi-identifier attributes dominate the number of records while performing the evaluation of information loss. The outcome of the second trial experimental results shows that the metric value steadily increases with little more deviation compare to other methods and the encouraging results are shown in Fig. 6b. In Fig. 7a and 7b shows the execution time of proposed method which has evaluated in two different set up like information loss evaluation. In Fig. 7a, the spread of execution time value of all methods looks small. The alpha method looks slightly deviated after 25000 records trial configuration. The execution time metric value of the proposed method is slightly decreased when compared to existing methods. In the second approach, numbers of quasi-identifier attributes have increased gradually one by one up to six trials. The ranges of execution time values of all methods are very close to each other up to the second trial (Number of quasi-identifier 4). In the last trial, the execution time of the proposed method has decreased reasonable. The overall performance of the proposed improve significantly regarding information loss metric values and execution time.□
Discussion and conclusion
The threshold value E plays the major role in the taxonomy tree construction and drives the generalization process in effective and increase the data utilization. If the quasi-identifier attribute values have more frequency and number of interval set also less, the strength of privacy become weak. So the threshold value is the flexible parameter that claims the data utilization comfort. The publisher audit the entire dataset based on the frequency value of quasi-identifier attribute values and fix the threshold value.
The proposed method has attempted to minimize information loss and increase data utilization based on fuzzy alpha-cut sets. The threshold value and alpha cut sets have played a vital role in the entire process of the proposed method. The experimental results show the reduction of execution time and information loss minimized significantly. However, some problems are not yet resolved. In facts privacy gain and information loss are mutually exclusive, in this point of view, this work assists to preserve the privacy as well as improve the data utility. The future work is in progress to include the strengthening of privacy against various attack models and in extended data publishing scenario named multi-view publishing.