
Abstract
Real world data is often interconnected, forming large and complex heterogeneous information networks (HINs) with multiple types of objects and links such as bibliographic network (DBLP) and knowledge bases (YaGo). Querying meta-paths requires exploration of path instances which can be computational cost in large HINs. However, existing meta-path based studies mostly focus on analytical applications of meta-paths, rather than systems to query meta-paths efficiently in large HINs. To bridge this gap, in this work we present SparkHINlog, a system based on Apache Spark, to handle meta-paths queries efficiently on large scale HINs. In SparkHINlog we propose an algorithm to not only translate meta-paths to Datalog rules, but also to manage the working memory area of Datalog efficiently to increase the scalability of SparkHINlog. To avoid the computing overhead of join operation to discover path instances when evaluating these rules, we leverage Motif Finding, a powerful tool of GraphFrames Library. With motif finding, SparkHINLog can speed up the time to evaluate the rules by path finding on graph instead on joining two relations. We conduct experimental comparisons with SparkDatalog, the state-of-the-art large-scale Datalog system, and verify the efficacy and effectiveness of our system in supporting meta-path queries.
Keywords
Introduction
Heterogeneous Information Network (HIN) is logical networks containing multiple types of objects and multiple types of links denoting different relations [1]. Real world data is often represented as a HIN, for example, bibliographic networks. In bibliographic networks, vertices have several vertex types such as authors, papers, venues, topics, words. These vertex types are connected via various link types such as write relation (author–[writes]⟶paper), cites relation (paper–[cites]⟶paper), publishedAt relation (paper-[publishedAt]⟶venue), to name but a few.
One of the widely-used concepts in mining HINs is meta-path, which explains how two vertices are related. A meta-path is a sequence of vertex types and link types connecting two given vertices in a HIN [2]. For example, author–[writes] → paper is a meta-path between two vertex types author and paper, capturing relationship that an author writes a paper. Another example is author–[cites] → paper ← [writes]–author. This meta-path explains the relationship between two authors that the former author cites one of the papers of the latter. In HIN research, meta-path plays an important role in many analytic applications such as Similarity Measure (PathSim [2], HeteSim [3], Clustering [4], Classification [5]). A common operation of these studies is to evaluate meta-path queries on two vertices, which explore all path instances connecting the vertices pair of interest regarding a given meta-path. Evaluating these recursive queries can be computational cost on large scale HINs. While extant meta-path based studies mostly focus on analytical applications of meta-paths [6] there is a need for a tool to query meta-paths efficiently in large HINs.
The growing demand in large scale graph analysis has encouraged recent scalable technologies on graph data sources, in particular Datalog systems. Datalog is a declarative logic programming language based on Prolog, which is used as a recursive query language in deductive databases. In graph databases, Datalog can support various recursive queries such as finding all pairs of vertices connected by some paths in a graph, or finding all vertices connected by some paths to a given source vertex. For its high-level semantics enabling natural expression of graph analysis, Datalog has been widely studied in distributed settings of large-scale monotonous graphs with single vertex types and link types [7, 8].
In this paper we propose to leverage Datalog to query meta-paths efficiently in large HINs. First we translate meta-paths to Datalog rules. We then study how to evaluate these rules efficiently. Datalog rules are building blocks of a Datalog program. A Datalog rule has a form of < head>:-< body>, in which <head>is a predicate, and <body>is a set of predicates. A predicate is often considered as a relation among set of objects. For example, in a bibliographic network, we have a predicate Write(X, P) describing the relation that author X writes paper P. Likewise, WrittenBy(P, Y) describes the “reverse” relation that paper P is written by author X. As link types in HIN also describe relations between two vertex types, we can use predicates to represent link types. Hence, Datalog rules can capture the same relation described by meta-paths.
Let us consider the meta-path author–[cites] → paper ← [writes]–author as an example. We can translate author–[cites] → paper and paper ← [writes]–author to two predicates Write(X, P) and WrittenBy(P, Y) respectively. The whole meta-path is therefore corresponding to the following Datalog rules: CoAuthor(X,Y):=Write(X,P), WrittenBy(P,Y). CoAuthor(X, Y) is an Intensional Database (IDB) predicate, which is generated by joining relation Write(X,P) with relation WrittenBy(P,Y) based on the common attribute P. This rule shares the same co-authorship relation as the meta-path: author X and author Y are co-author if they write a common paper.
Sometimes the relation in HIN can be recursive, which is denoted as (. . → . .) k. For example, in Bibliographic Network the meta-path (P → P) k represents an indirect citation between two papers. A path instance of this meta path is p1 → p2 → … p k where paper p1 cites paper p2, paper p2 cites p3, … paper pk-1 cites paper pk. We can also use Datalog rules to represent this recursive relation.
After translating meta-paths to Datalog rules, we study how to evaluate these Datalog rules efficiently. In traditional Datalog systems, Datalog rules with IDB predicates can be computational cost due to the join operation among the relations in the body of the rules. We observe that in HIN context all tuples satisfying Datalog rules would also form paths in graphs. Hence we cast the problem of evaluating Datalog rules to path finding in graphs. In particular, we utilize the motif finding function of GraphFrames Library to find paths in the graph instead of joining two relations. GraphFrames Library is a package in Apache Spark [9], a system supporting large-scale analytics in distributed environment. Therefore, we can execute finding path tasks efficiently in large-scale HINs.
To the best of our knowledge, no existing research has addressed how to use Datalog System to process meta-paths of HINs. We hold that a HIN is a graph. Therefore, we would like to focus on using Datalog for HIN analysis. Moreover, HIN is often large-scale graph. We leverage the GraphFrames Library of Apache Spark to improve the performance of HIN. To this end, we develop SparkHINlog which can analyze efficiently large scale HIN. Our contributions through SparkHINlog are as follows: We propose a systematic way of translating meta-path to Datalog rules. Based on these Datalog rules, SparkHINlog can support fundamental meta-path related tasks such as finding the instances of meta paths, evaluating PathSim [2], one of the essential meta-path based similarity scores in HIN analysis. SparkHINlog can process recursive query. We use this capability to process the recursive queries in HIN such as the influence of author or paper through citation, the propagation of topics through citation, etc. We address querying recursive meta-paths by converting them to recursive Datalog rules. Besides, SparkHINlog is the combination of Datalog and Spark GraphFrames in a distributed environment, so it can utilize the capability of Datalog recursive rules and distributed computing of Spark GraphFrames for large scale HIN analysis. We also enhance SparkHINlog to make the system scalable in working with many Datalog rules in large scale HIN. Specifically, SparkHINlog can scan the rules to decide whether a relation is retained in working memory of Datalog or not. If a relation is not used in the body part of any future rules (rules have not yet been evaluated), they will not be retained in the working memory area of SparkHINlog. This action will free the memory space for unused relations. Therefore, the system can increase the capability of scalability when working with many Datalog rules. SparkHINlog is capable of processing large scale graph by using motif finding of GraphFrames Library. Motif finding allows us to find paths in the Graph efficiently on distributed computing environment.
The rest of this paper is organized as follows 1) Introduction 2) Preliminaries 3) Methodology 4) Experiment and Discussion 5) Related Work and 6) Conclusion and Future Work.
Preliminaries
Heterogeneous information network
According to [2], we have the following definitions:
Vertex types of the DBLP HIN
Vertex types of the DBLP HIN
Link types of the DBLP HIN
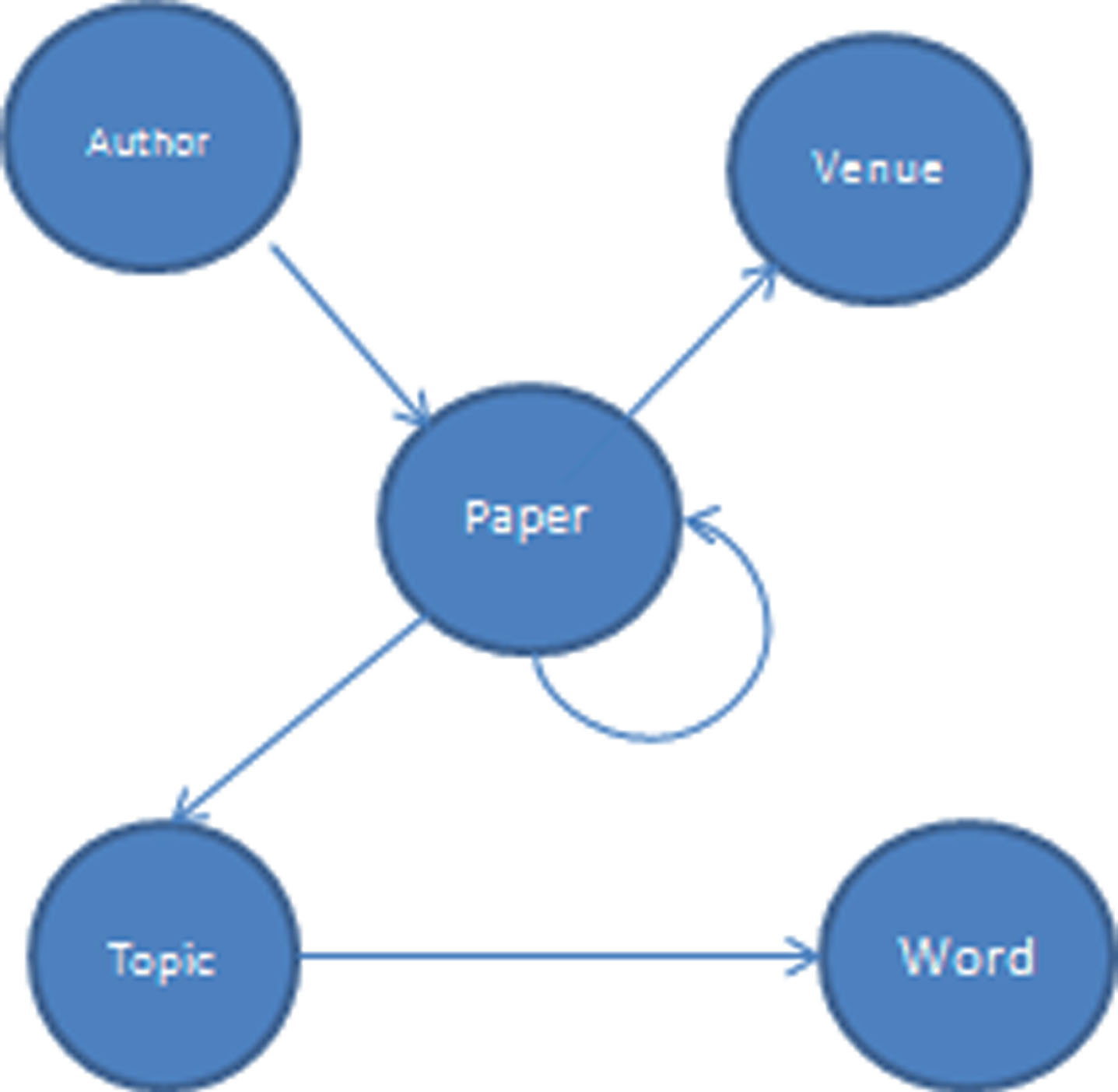
Bibliographic network.
The length of P is the number of relations in P. Further, we say a meta-path is symmetric if the relation R defined by it is symmetric. Path count is the number of path instances p between x and y following. Path count is defined as P : s (x, y) = | {p : p ∈ P} |.
Different meta-paths carry different semantics. Meta-path A → P → A expresses the information “Two authors cooperate on a paper”. Meta-path A → P → V ← P ← A expresses the information “Two authors write a paper published on the same venue”. Meta-path P → , P → P means “Paper p1 cites paper p2 and paper p2 cites paper p3”.
Where | {px→y : px→y ∈ P} | is the number of path instances of meta-path P between entity x and entity y. | {px→x : px→x ∈ P} | is the number of path instances of meta-path P starting from y and | {py→y : py→y ∈ P} | is the number of path instances of meta-path P starting from y [2].
Datalog is a Prolog-based nonprocedural query language which is first developed on the platform of relational database [11]. In this platform, a fact is an EDB (extensional database). It is a physical relation in relational database. An IDB (intensional database) is a derived relation and is generated by using a Datalog rules. Datalog has facts and rules. A fact is the same as tuple in a relation. A fact has the following structure <predicate name> (<list of constants>).
Vetex(326,Paper,“Enriching_Expressive_Power.”)
Vertex(327,Paper,“A_Lattice_Model.”)
Vertex(3753,Author,“Li_Gong”)
Vertex(3754,Author,“Xiaolei_Qian”)
Edge(52,80)
Edge(52,81)
Edge(52,82)
In relational database terms, each fact would be the same as the relation of database.
Besides of facts, Datalog has rules. Rule is a way to derive new facts. A rule has the following form <head>:-<body>.
Assume we have a rule: Q:- P. It means that if P is true then Q is true.
Normally, Datalog will translate the Datalog rules to relational operations for generating data. Some examples of facts and rules are listed as follows:
Facts
vertex(vertexId,vertexType,name)
edge(src,dst)
Relational Algebra: name
Datalog Rule:
names(Name):-Vertex(vertexId,vertexType,name) Relational Algebra:
PaperName =
Paper(vertexid):- Vetex(vertexId,vertexType, name), vertexType="Paper"
Author(vertexid):-Vetex(vertexId,vertexType, name), vertexType="Author"
Venue(vertexid):- Vetex(vertexId,vertexType, name), vertexType="Venue"
Topic(vertexid):- Vetex(vertexId,vertexType, name), vertexType="Topic"
Word(vertexid):- Vertex(vertexId,vertexType, name), vertexType="Word"
Relational Algebra:
Write(src,dst)=Edge(src,dst) raisebox - 1pt⟕ Author(src) raisebox - 1pt⟕ Paper(dst)
Datalog Rule:
Write(src,dst):-Edge(src,dst), Author(src), Paper(dst)
In SparkHINlog, we used motif finding of Spark GraphFrames Library to access graph and generate data. SparkHINlog uses path query instead of join operation in Datalog.
Datalog have recursive rules [12]. In HIN, we use Datalog recursive rules to calculate the CitingSet. CitingSet of a paper p is a set of all papers that paper p cited directly or indirectly. In other words, the CitingSet of paper p is a set of papers which has an influence on paper p. We can compute the CitingSet of paper 2394 denoted CitingSet(2394) as follows:
Path(X,Y):- Edge(X,Y)
Path(X,Y):- Edge(X,Z), Path(Z,Y)
CitingSet(X,Y)=Path(X,Y),X=2394
With these rules, we can discover the path instances of all paths which connect paper 2394 to any papers in CitingSet(2394). We can use this recursive rule to find the influence of these papers to paper 2394. We will discuss this operation in the experiment section of this paper.
Spark datalog
Apache Spark is an open source software for distributed computing environment. It was developed at the University of California, Berkeley’s AMPLab Apache Spark in 2012 to improve the limitations in the Map Reduce cluster computing paradigm [13]. Apache Spark is a general platform for large-scale data analytics. Apache Spark can run with one master and several worker computers. Apache Spark has GraphX library which can process large scale graph on distributed computing environment.
Recently Datalog has found new applications in Graph Analysis [8]. We focus on SparkDatalog and enhance SparkDatalog to HIN analysis. Based on Apache Spark, we can improve the performance of rule evaluation by using a partition strategy for distributing the graph into several partitions. The join operation will process in distributed computing in each partition then grouping for the final result of join operation. SparkDatalog has a working memory area to store the temporary instances of relation during the evaluation process. Latter, we will develop an algorithm to manage efficiently this working memory area.
Motif finding of GraphFrames library
GraphFrames Library is a package of Apache Spark which provides DaraFrames query based Graphs [9]. GraphFrames Library provides powerful tools for processing large scale graph. Motif finding is a power tool to discover structural patterns in large scale graph.
In this research, we use motif finding to find the instances of a given meta-path. A meta-path is translated to Datalog rules. When evaluating the body predicates, we used motif finding of GraphFrames Library to find the path connecting these vertices.
GraphFrames Library uses simple Domain Specific Language (DSL) for expressing the structural queries. Motif pattern contains names of vertices and edges. The basic pattern is an edge, for example edge (a)–[e] → (p) where a is an author, p is an paper. Each pattern can be joined together to generate a path.
Example the pattern (a)–[e1] → (p); (p)–[e2] → (v) specifies a path from vertex a to vertex p then from vertex p to vertex v.
Motif finding can be executed by using Scala programming language and Apache Spark GraphFrames Library. The columns of DataFrames result can be specified by using the select phrase as follows:
val motif = g.find(“(a)–[e1] → (p); (p)–[e2] → (v)”)
.filter(“a.type=”Author” and
p.type=”Paper” and v.type=”Venue”)
.select(“a.id”,“b.id”,”c.id”)
When evaluating the Datalog Rules: APA(A,P,V):-AP(A,P), PV(P,V)
In traditional Datalog, we need the instances of relation AP and relation PV. Then we use join operation to create relation APA.
In GraphFrames Library, the instances of relation AP and relation PV are the edges of HIN satisfying the Motif Finding pattern. The join operation of two relations can be replaced by motif finding of GraphFrames Library for path finding. The attributes of DataFrames which is the result of motif finding can be selected by using the select phrase as above.
Using motif finding, we can save memory space for generating body relations Moreover, the time for Motif Finding is faster than the time for join operation based on the good partition strategy of GraphFrames Library. We will conduct experiment to show the result of processing.
With Scala programming language, we have the following code for motif finding:
val g = Graphs(sqlContext) # Get example graph # Search for pairs of vertices with edges in both directions between them.
val querypat="(a) -[e] → (b); (b)-[e2] → (a)"
val motifs = g.find(querypat)
motifs.show()
We developed an algorithm to translate the meta-path to Datalog rules, then Datalog rules to motif pattern of motif finding.
WrittenBy(P,X):- Write(X,P)
CoAuthor(X,Y):- Write(X,P), WrittenBy(P,Y), X < > Y
These Datalog rules can be translated to motif pattern of motif finding as follows:
The motif pattern for relation Write(X,P)
querypat=“(a)–[w1] → (p)”
filterpat=“a.type=‘author’ and b.type=‘paper”’
val motifs = g.find(querypat).filter(filterpat)
motifs.show()
The rule: CoAuthor(X,Y):- Write(X,P),
WrittenBy(P,Y), X< >Y
This rule can be translated to motif finding:
querypat=“(a)–[w1] → (p); (p)–[w2] → (b)”
filterpat=“a.type=’author’ and b.type=’author’ and
p.type=’paper’ and a.id <> b.id”
val motifs = g.find(querypat).filter(filterpat)
motifs.show()
With these rules, we can process Datalog rules by using motif finding of Spark GraphFrames in distributed environment.
Methodology
SparkHINlog
We built our proposed SparkHINlog with the following requirements: SparkHINlog can work with large scale graph for HIN SparkHINlog can work with graph instead of relation by using Spark GraphFrames Library The join operation on two relations in SparkDatalog will be enhanced by a good repartition for improving the performance of motif finding of GraphFrames Library.
The operations of SparkHINLog are as follows: The input on SparkHINLog is meta-path such as A → P → A, A → P → V ← P ← A, A→ P → T ← P ← A … The input meta-path is translated to Datalog Rules and store in Datalog Program. The Datalog engine will evaluate the Datalog rules in Datalog Program.
SparkHINLog has following characteristics: Use GraphFrames Library for processing large scale HIN. Extract EDB and IDB predicates from HIN graph by using the motif finding of GraphFrames Library. Manage smartly the temporary memory for deductive process in which EDB and IDB relation will be generated when needed and release when they aren’t used in another rules any more. This process will help to reduce the memory space for storing the temporary EBD, IDB. Use a partition strategy of GraphFrames Library to reduce the execution time for join operation in deductive process
The structure of SparkHINlog is in Fig. 2.

Structure of SparkHINlog.
In a Datalog program, predicates can be either EDB or IDB where EDB is an extensional database and IDB is an intensional database. IDB is a relation generated by rules during evaluation process.
The algorithm to evaluate Datalog Programs can be summarized as follows.
If there is no recursive rule, we can pick an order to evaluate the IDB predicates, so that all the predicates in the body of its rules have already been evaluated.
Rule 1: RAP(x,y):- AP(y,x).
Rule 2: APA(x,p,y):- AP(x,p),RAP(p,y)
In Rule 1, the predicate in rule body is predicate AP(y,x). It is an EDB predicate. The predicate RAP(x,y) is IDB, it is evaluated by swapping the value of attribute x and attribute y of AP.
In Rule 2, the predicate in the head is APA(x,y), it is an IDB predicate. The predicate RAP(p,y) and predicate AP(x,p) are evaluated. Then relation AP(x,p) will join with relation RAP(p,y) to generate the instance of APA(x,p,y) relation.
Let’s consider Datalog rule:
APV(A,P,V):- AP(A,P), PV(P,V)
With traditional Datalog, we need the instances of relation AP(A,P) and PV(P,V). Then we join relation AP(V,A) with relation PV(P,V). This operation needs the memory space for the instances of relation AP(V,A) with relation PV(P,V) if they are large scale relation, and the time for joining two large scale relations AP(V,A) and PV(P,V) will be high. When using the GraphFrames Library, the instance of relation AP(V,A) and PV(P,V) are the edges of HIN graph. The result of joining AP(A,P) and PV(P,V) is the set of path instances of path A → P → V. We use the motif finding of GraphFrames Library to generate these path instances as follows:
val motifs = g.find(g,” (a) - [e1] - > (p); (p) - > [e2] - > (v)”).
filter(“a.type=”Author” and
p.type=”Paper” and c.type=”Venue”)
.select (“a.id”,”p.id”,”v.id”)
If Datalog program contains recursive rules as follows:
path (x,y):- edge (x,y)
path(x,y):- edge(x,z), path(z,y)
SparkDatalog will repeatedly execute the join operation between relation edge(x,y) and relation path(x,y) until relation path(x,y) is an empty set. These operations are executed by motif finding of GraphFrames Library. In the experiment section, we will discuss this improvement to reduce the execution time.
We proposed an algorithm to translate the meta-path to Datalog rules as follows:
Given a meta-path P and the reverse meta-path p-1. Meta-path
The reverse of meta-path
PA (P, A) : - RAP (A, P)
We use the join operation to process the composition of two relations.
With meta path
R1R2 (A i , A j , A k ) = R (A i , A j ) raisebox - 1pt⟕ with R2(A j , A k )
APA (A, P, B) : - AP (A, P) raisebox - 1pt⟕ PA (P, B)
There are two cases for this meta-path.
Given a meta path
For each A
i
Ai+1, we generate a predicate A
i
Ai+1 (A
i
, Ai+1). The result predicate is the join of consecutive pair relations as follows:
APV (A, P, V) : - AP (A, P) , PV (P, V)
Given a meta-path
Where P = A1A2 . . . A
l
and
This meta-path is symmetric if and only if
For the symmetric meta-path, we need only to compute a half meta-path. In this case, we compute meta-path P. Then we use the reverse of P to generate meta-path P-1.
The meta-path is decomposed into two smaller meta-paths based on the middle point of meta-path. This operation will be processed recursively until we have a length 2 meta-path. This meta-path will be an EDB or the reverse meta-path of EDB.
An example of translating meta-path A → P → V ← P ← A to Datalog rules is shown in Fig. 3. Meta path A → P → V ← P ← A, gives two smaller meta-paths A → P → V and V ← P ← A.
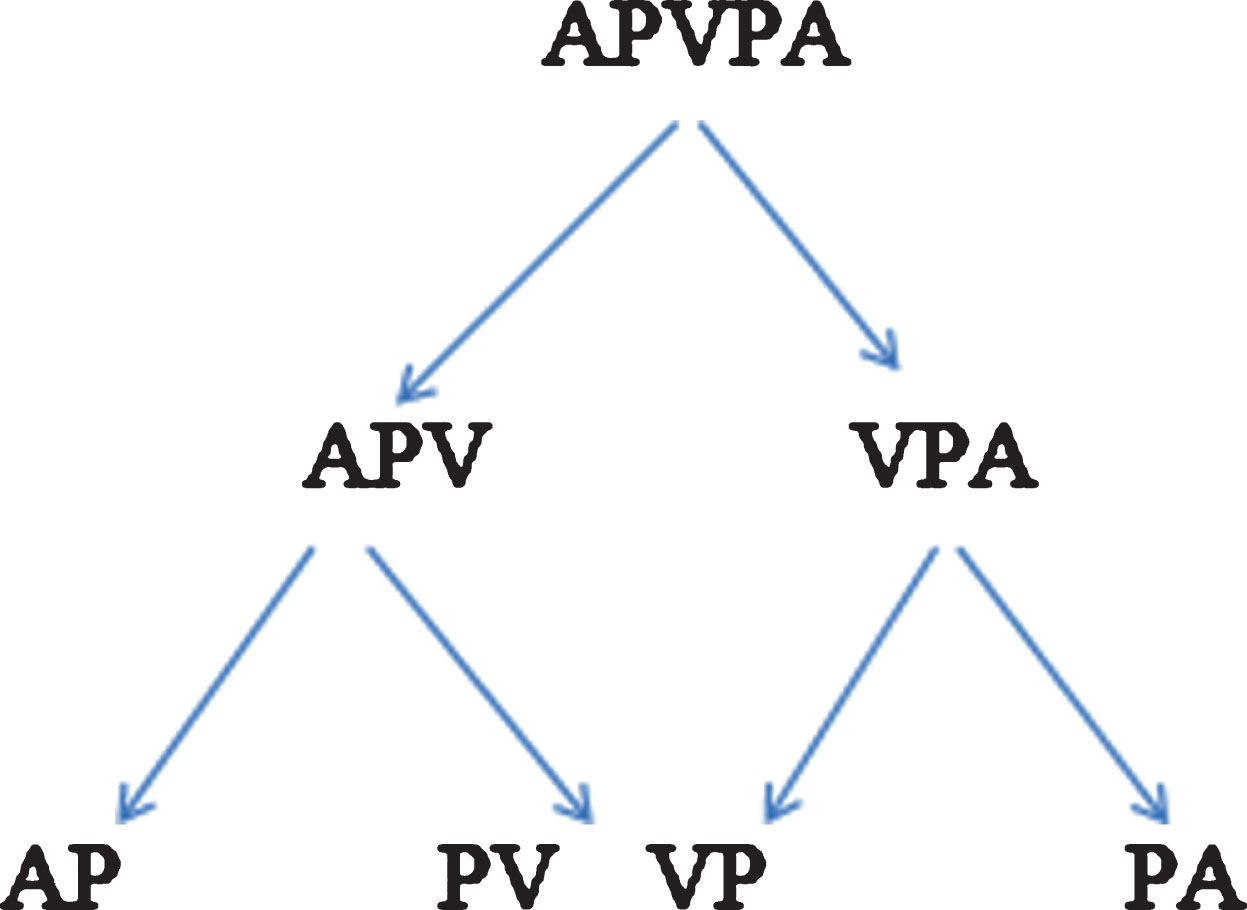
Post order tree traversal for generating Datalog rules.
Since meta-path P satisfies case 2, we generate the Datalog rules and stop.
APV (A, P, V) : - AP (A, P) , PV (P, V)
We use recursive process to decompose P into two more smaller meta- paths and do the same things we mentioned above.
For meta-path P = A → P → V, we have the following Datalog rule:
APV (A, P, V) : - AP (A, P) , PV (P, V)
For meta-path P-1 = P ← V ← A, we have the following Datalog rule:
VPA (V, P2, A2) : - APV (V, P2, A2)
Then we merge two above rules to generate the last Datalog rules as follows:
APVPA (A, P, V, P, A) : - APV (A, P1, V) ,
VPA (V, P2, A2)
We use post-order tree traversal to collect the Datalog rules as shown in Fig. 3.
The length of meta-path APTW is 4 (even), so we have:
AP(a0,p) is EDB (a0) - [AP] - > (p) PT(p,t1) is EDB (p) - [PT] - > (t1) TW(t1,w) is EDB (t1) - [TW] - > (w) APTW(a0,p,t1,w):-AP(a0,p),PT(p,t1),TW(t1,w) The EDB relations are generated by motif finding of GraphFrames Library. In this example EDB AP(a0,p) is generated by (a0)–[AP]⟶(p), relation PT(p,t1) is generated by (p)–[PT] → (t1), relation TW(t1,w) is generated by (t1)–[TW] → (w). We can use the recursive Datalog rules to compute the meta path (P → P) k . In this case, “cite” relation is expressed by using the meta-path P → P. This meta-path will be repeated by using recursive rules of Datalog as follows:
T1(x,y):- Cite(x,y).
T1(x,y):- Cite(x,z),T1(z,y).
We use this rule to find the influence of paper through CitingSet.
Datalog uses a working memory area for storing all the generated relations in the evaluation process. With the following Datalog program in Table 3:
Datalog Program
Datalog Program
We evaluate rules of Datalog program step by step and check the size of SparkHINlog’s working area as shown in Table 4.
Working memory area of the Datalog
We recognize that the size of working memory area is increased rapidly because the generation of the result of the predicates in the head of the Datalog rules.
We proposed an algorithm to manage the working memory area of SparkHINlog as follows:
The steps of checking are as follows:
We have the future rules of rule 1 are rules: 2,3,4,5
The head predicate of this rules contains predicate RAP. The predicate RAP is in the body of future rule, so it will be retained in the working memory area. The body of this rule contains AP. This predicate is in the body of future rules (rule 3), so it will be retained in the working memory area.
We have the future rules of rule 2 are rules 3,4,5
The head predicate of this rules contains predicate RPV. The predicate RPV is in the body of future rule (rule 3,4,5), so it will be retained in the working memory area. The body of this rule contains PV. This predicate is in the body of future rules, so it will be retained in the working memory area.
We have the future rules of rule 3 are rules: 4,5. The head predicate of this rules contains predicate T1. The predicate T1 is in the body of future rules (rule 4, rule 5), so it will be retained in the working memory area. The body of this rule contains AP, PV. These predicates are not in the body of any future rules, so it will be flushed out of working memory area.
We have the future rules of rule 4 is rule 5.The head predicate of this rules contains predicate T2. The predicate T2 is in the body of future rule (rule 5), so it will be retained in the Working Memory area. The body of this rule contains RAP, RPV. These predicates are not in the body of any future rule (rule 5), so it will be flushed out of working memory area. The smart management of working memory is shown inTable 5.
Smart Management of Working Memory
Based on this algorithm, we can save the working memory area in each step of evaluation process and enhance the capability of scalability.
Configuration of the distributed system
We run our program which was developed on GraphFrames Library on Spark cluster with one master and five worker computers. The process of knowledge graph will be executed on worker computers and the result will be sent back to the master worker for summary. Normally, they are join operation. We repartition the edges of graph so that edges of the same source vertices are in the same partition. After repartioning, the join operation can be executed without moving the edges among partitions. So, the time execution of join operation will be reduced.
Data set
We use a subset of DBLP Citation network with 117,210 vertices and 529,968 citation relationships. We downloaded this data set from Aminer website (https://aminer.org/citation) and store DBLP in Neo4j graph database. We used Topic Modeling LDA to discover the topic of paper [10]. We run probabilistic Topic Model LDA with 30 topics to generate topics of papers.
Translate meta-path to Datalog rules
This is the result of our proposed algorithm to translate meta-path to Datalog rules with motif pattern.
=Translate meta-path to Datalog rules=
Meta-path APTW has even length (length = 4)
AP(a0,p) is EDB
(a0) - [AP] - > (p)
PT(p,t1) is EDB
(p) - [PT] - > (t1)
TW(t1,w) is EDB
(t1) - [TW] - > (w)
APTW(a0,p,t1,w):-AP(a0,p),PT(p,t1),TW(t1,w)
==Translate meta-path to Datalog rules=
Meta-path APA is a palindrome of length 3
PA(p,a):-AP(a,p)
AP(a,p) is EDB
(a) - [AP] - > (p)
APA(a0,p,a2):-AP(a0,p),PA(p,a2)
APA(a0,p):(a0) - [AP] - > (p) PA(p,a2):(p) - [AP] - > (a2)
==Translate meta-path to Datalog rules====
Meta-path APVPA is a palindrome of length 5
PA(p,a):-AP(a,p)
AP(a,p) is EDB
(a) - [AP] - > (p)
VP(v,p):-PV(p,v)
PV(p,v) is EDB
(p) - [PV] - > (v)
APVPA(a0,p1,v,p2,a3):- APV(a0,p1,v),
VPA(v,p2,a3)
APV(a0,p,v2):-AP(a0,p),PV(p,v2)
AP(a0,p):(a0) - [AP] - > (p)
PV(p,v2):(p) - [PV] - > (v2)
VPA(v0,p,a2):-VP(v0,p),PA(p,a2)
VP(v0,p):(v0) - [VP] - > (p)
PA(p,a2):(p) - [PA] - > (a2)
Using SparkHINLog to compute the path instances of meta-path A → P ← A and pathSim
RAP(x,y):- AP(y,x).
T(x,p,y):- AP(x,p),RAP(p,y).
T1(x,p,y):- T(x,p,y),x=3785.
T2(x,p,y):- T(x,p,y),y=3786.
T3(x,p,y):- T(x,p,y),x=3785,y=3786.
=Compute meta path A⟶P←A
PathSim=
Result: T1: (ArraySeq(3785, 337, 3785)), (ArraySeq(3785, 337, 3786))
Computed 2 results.
(T1 relation, number of rows=,=,2)
Result: T2: (ArraySeq(3785, 337, 3786)), (ArraySeq(3786, 337, 3786))
Computed 2 results.
(T3 relation, number of rows=,,2)
Result: T3: (ArraySeq(3785, 337, 3786))
Computed 1 results.
(T3 relation, number of rows=,1)
APA PathSim 0.5000
In this case, the value of | {px→y : px→y ∈ P} | = |T3|=1
Using SparkHINLog to explore the influence of papers by using the recursive Datalog rules
declare Path(int v, int dist aggregate Min).
Path(x, d):- IsSource(s), Edge(s, x, d).
Path(x, d):- Path(y, da), Edge(y, x, db), d = da + db.
The result of the Datalog program is the CitingSet of paper 2394 and the impact of paper to paper 2394. The impact depends on the path length from paper 2394 to current paper. We use tree level of impact such as strong (length = 1). middle (length = 2), weak (length> =3) impact. Some results are as follows:
(source paper=,2394)
2394 “DIAL:_A_Programming_Language” 1980
8459:Brian_Berkowitz 8460:Michael_Hammer 402, 1
402 “System_R:_Relational_Approach” 1976 (path=,List(2394, 402))
2394- 8459:Brian_Berkowitz
8460:Michael_Hammer
402-
3943:W._Frank_King_III Strong impact
—————————————
1906, 2
1906 “SEQUEL:_A_Structured_English.” 1974
(path=,List(2394, 1255, 1906))
2394- 8459:Brian_Berkowitz
8460:Michael_Hammer
1255- 5976:Joachim_W._Schmidt
1906- 7399:Raymond_F._Boyce
7400:Donald_D._Chamberlin
Depending of the length of path from source paper to current paper, we discover the strength of impact.
In our experiment, if the path length is 1, then the impact will strong. If path length is 2, the impact will be middle and if the path length is 3 or greater, the impact will be weak.
Managing the working memory area
During evaluation process of Datalog on one Worker, the working memory area (WMA) contains the intermediate results. Since we work with large scale graph, we need to flush out of working memory area the relation which is not used in future rules. The size relations in working memory area in Megabytes (MB) of SparkDatalog and SparkHINlog are shown in Table 6.
Working memory of SparkDatalog and SparkHINLog for one Worker
Working memory of SparkDatalog and SparkHINLog for one Worker
The comparison of working memory area of SparkDatalog and SparkHINlog is shown in Fig. 4. In the beginning, both versions have AP, PV relation in the working memory.
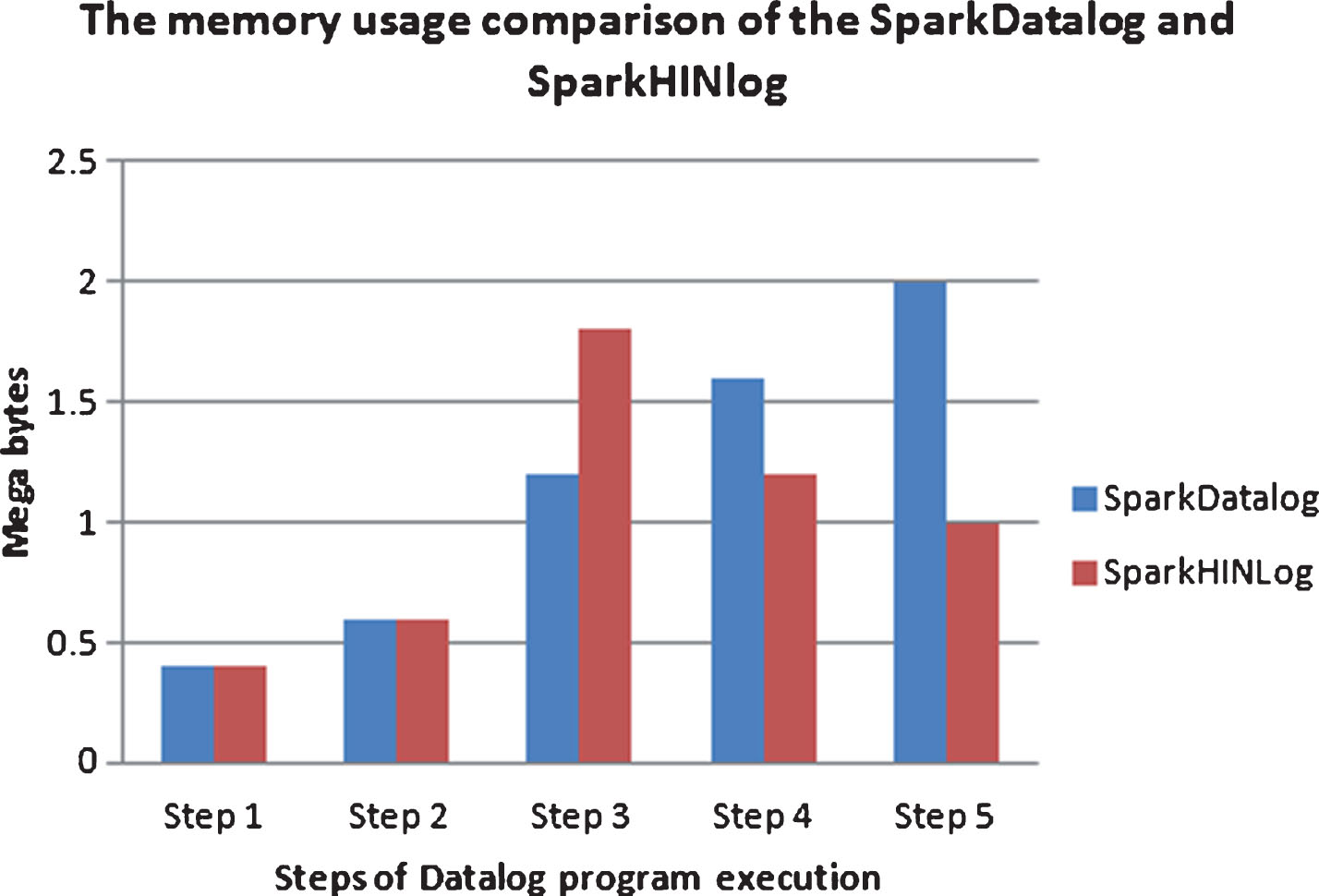
The usage of working memory area of SparkHINlog and SparkDatalog.
After evaluating rule 1, AP and PV relations are flushed out of memory. APV relation is retained in the working memory area. After evaluating rule 2, APV and VPA relation are still retained in working memory area. After evaluating rule 3, AP and PV relation are flushed out of working memory area.
We hold that SparkHINlog can reduce the working memory area with smart management algorithm.
The chart is created by executing a recursive rule for studying the paper influence. We do repartition HIN graph such as the vertices are sorted by vertextype (Author, Paper,Venue, Topic, Word) and edges are sorted by vertexID of source vertex.
We check the performance of GraphFrames Library with Motif Finding comparing with the join operation of the traditional SparkDatalog using GraphX.
Path(x, y):- Cite(x, y)
Path(x, y):- Cite(x, z), Path(z, y)
The time execution of join operation of Cite(x,y) and path(x, y) in recursive rules. It is repeated 15 times until Path(x,y) reaches empty set. Each repeated join operation is executed with repartition (SparkHINlog) and without repartition (SparkDatalog).
We use motif finding of GraphFrames Library to find the path instances instead of joining two big relations. We hold that the time execution is decreased significantly as shown in 6th iteration of Fig. 5.
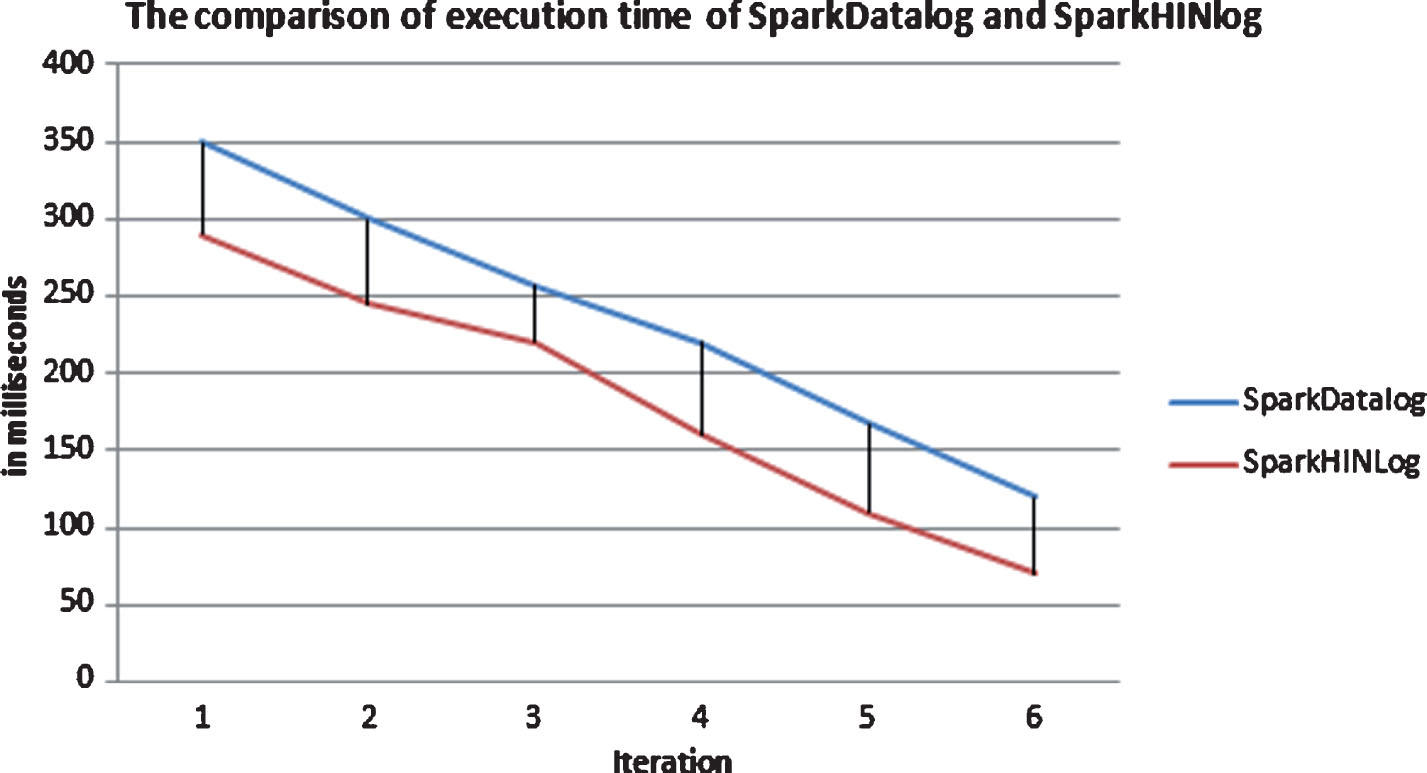
The comparison of time execution of rule evaluation of SparkHINlog and SparkDatalog.
Recently, there has been an increase of studies in expansion of Datalog. Kornellije Rabuzin developed a Deductive Graph Database- Datalog in Action, 2016 [14]. They proposed a Datalog on the platform of Graph Database instead on Relational Database. They used neo4j Graph Database to store Graph Data and use Cypher – Graph query language to generate the facts, EDB and IDB. SociaLite is a Datalog extension for efficient social network. SociaLite was developed by [7]. As a logic programming language, Datalog can process graph. The users can process graph by using the non- recursive or recursive Datalog rules. In [8] expanded Datalog. They proposed Spark Datalog which can work with a large scale database. The system addresses with a concise declarative specification of complex queries amenable to efficient evaluation. – In DatalogRA: Datalog with recursive aggregation in the Spark RDD Model, Marek Rogala, Jan HiddersJacek Srokay [15] developed a tool which extends a distributed computations platform. This tool was developed on the Apache Spark platform. It is possible to develop graph algorithms in a Datalog query language, and execute them on distributed computing environment.
Conclusions & future work
In this paper, we present our SparkHINlog which is the extension of SparkDatalog for HIN Analysis. Our SparkHINlog can translate meta-path to Datalog Rules. SparkHINlog can work with large scale HIN. SparkHINlog can use recursive Datalog rules to analyze large scale HIN. SparkHINlog used a smart management of working memory area of SparkDatalog. These predicates will be retained or flushed out of the working memory are depending on whether these predicated will be used in the future rules or not. We use motif finding of GraphFrames to find the path of graph instead of joining two relations. A repartition based on a hash algorithm has been proposed to improve the motif finding of GraphFrames Library. By conducting experiment of a subset of DBLP as Bibliographic network, we confirm the performance of SparkHINlog. In the future, we plan to expand SparkHINlog for large scale weighted HIN Analysis. We develop weighted PathSim and use SparkHINlog to calculate the weighted pathsim to measure the similarity between two objects in Weighted HIN.
Footnotes
Acknowledgments
This research is funded by Vietnam National University Ho Chi Minh City (VNU-HCMC) under the grant number B2017-26-02.