
Abstract
Link prediction on heterogeneous information network (HIN) is considered as a challenge problem due to the complexity and diversity in types of nodes and links. Currently, there are remained challenges of meta-path-based link prediction in HIN. Previous works of link prediction in HIN via network embedding approach are mainly focused on exploiting features of node rather than existing relations in forms of meta-paths between nodes. In fact, predicting the existence of new links between non-linked nodes is absolutely inconvincible. Moreover, recent HIN-based embedding models also lack of thorough evaluations on the topic similarity between text-based nodes along given meta-paths. To tackle these challenges, in this paper, we proposed a novel approach of topic-driven multiple meta-path-based HIN representation learning framework, namely W-MMP2Vec. Our model leverages the quality of node representations by combining multiple meta-paths as well as calculating the topic similarity weight for each meta-path during the processes of network embedding learning in content-based HINs. To validate our approach, we apply W-TMP2Vec model in solving several link prediction tasks in both content-based and non-content-based HINs (DBLP, IMDB and BlogCatalog). The experimental outputs demonstrate the effectiveness of proposed model which outperforms recent state-of-the-art HIN representation learning models.

Introduction
Link prediction is one of the fundamental problems [1, 2, 3, 4, 5] of information network analysis and mining. It supports how to anticipate the likelihood of the existence of relationships between two nodes. In recent years, we have witnessed the proliferation of multiple online networked data resources, such as WWW, encyclopedia/knowledge-based graph (Wikipedia, YAGO, Freebase etc.), bibliographic networks (DBLP, DBIS, etc.), social networks (Facebook, Twitter, Weibo, etc.). Up to present, most of contemporary network analysis models have a common basic assumption that all type of nodes and links are the same, also called homogeneous information network (HoIN) based approach, such as authorship relation network (partial network of DBLP or DBIS, etc.), friendship relation network (partial networks of social networks like as Facebook, Twitter, etc.). However, the most real-world networks contain multi-typed nodes and links which definitely contain more important information as well as rich semantic meanings of nodes and their inter-connected links. Recently, heterogeneous information network (HIN) analysis and mining [2, 6] have been widely studied due to the changes on the views of networked data as well as developing trends in data mining. There is no doubt that most of social and information networks are heterogeneous in nature which involving diversity in types of nodes and relationships between them. In HIN, beside the directed links between two nodes, like as A[author]-P[paper], P-V[venue], etc. in DBLP network we also have rich sematic relationships between same-typed nodes are represented as undirected/sequential relations, called meta-path, such as A-P-A, A-P-V-P-A, etc.
Information network embedding (INE). Recently, the approaches of INE [7, 8, 9] have widely studied due to its potential applications for solving principal problems of network mining tasks: node similarity search [10, 11, 12], clustering [13, 14], classification [6, 15], link prediction [3, 4, 5], etc. INE aims to embed network’s nodes and links into low-dimensional vector spaces but still ensures the original network’s structure is preserved. The rise of INE has changed the ways which are applied for network analyzing and mining, including principal tasks, such as: node similarity search, clustering, classification and link prediction. A good network embedding model can help to transform nodes and links of information network into low-dimensional vector space, then network mining tasks like as link prediction can be effectively completed by applying out-off-the-shelf multidimensional distance metrics and machine learning models for vector spaces. There are several well-known network representation learning models which are applied for different network’s type, including HoIN-based INE models, such as LINE, DeepWalk, Node2Vec, etc. and HIN-based INE models, like as HIN2Vec [16], Metapath2Vec [17], Metagraph2Vec [18], SHINE [4], etc. HoIN-based INE models treat all links between nodes as the same type therefore they cannot be applied for solving multi-typed links prediction problem in HINs. To capture the rich semantics of diverse links and nodes in HIN, several studies of meta-path-based (HIN2Vec [16], Metapath2Vec [17], PME [3], etc.) and meta-graph-based (Metagraph2Vec [18]) embedding techniques have been proposed. These HIN based INE models enable to better capture different semantics of links and nodes in context of heterogeneity of complex information network.
Link prediction task with INE approach. In general, link prediction task (for both HoINs [19, 20, 21, 22] and HIN [3, 16, 17, 18]) is frequently viewed as a binary classification task, for potentially relations which might be occurred between two nodes – or predicting whether the new links might be existed (with value as 1) or not (with value as 0) [1, 5, 7]. The link prediction classification model is trained by feature vectors which are created by applying multiple activation functions in representative vectors of node-pairs [3, 16] that already have the evaluated relations. Then, the trained model will be used to predict the occurrence of these relations between candidate node-pairs (not have these relations in current) in the future. There are several HIN based prediction models have been successfully applied for capturing the possibility of occurring new meta-path-based relations between same-typed nodes. However, there are remained challenges related to how to combine dependent meta-paths in solving link prediction task as well as evaluating the topic similarities between pairwise nodes in content-based HIN.
Examples of existent meta-paths might affect the occurrence of other meta-paths in the future.
Combination of multiple meta-paths in link prediction of HIN
In the context of HoINs, most of recent link prediction models only support for capturing the existence of only one relation’s type between a single type of node which is represented as one-hop relations [1, 5]. For example, there are common link prediction practices in information network, such as the co-author (two authors write the same papers) or co-worker (two authors work at same a university, institute or organization) in DBLP all denoted as: A-A, or friendship relations (between two users) in social networks all denoted as: U[user]-U. However, in real-world context, the relationships between authors in DBLP and users in social networks are more complex than that. In fact, predicting the existence of specific relations via different meta-paths between pairwise nodes in HIN can provide more meaningful outcomes as well as accuracy than using only single type of meta-path. For example, the relationships between two authors might be carried out with more than one relation’s types which are represented as meta-paths, such as A-P-A (co-author), A-O(organization)-A (co-worker), A-P-V-P-A (two authors commonly submit their papers at the same venues/journals), A-P-K[keyword]-P-A (two authors share common keywords on their papers), etc. Each relation has its own meaning and totally different from the others. It is needless to say that the occurrence of one more relation in the future between two nodes might be affected by other current existent relations. Let take two meta-path A-P-A and A-P-V-P-A as an example which describes two authors have co-author and both submit their works at the same conferences/journals. These two types of relation which are mostly occurred between authors who already have co-worker (A-O-A) relation. By working at a same place, they might be much easier to form other’s relations such as working together on the same researches (A-P-A), inviting the other to participate on the same conferences (A-P-V-P-A), etc. (as illustrated in Fig. 1A). Another example on predicting the friendship relation between users on social networks like as Facebook, Twitter, Weibo, etc. the high possibility of user’s friendships (U-U) which will be occurred in the future might be influenced by current undirected relations between them, such as U-G[group]-U, U-C[comment]-P[post]-C-U, etc. Definitely, they might be likely to have a friendship relation if they participate in several common groups/fan-pages, or frequently comments about several posts, etc. (as shown in Fig. 1B). We come to the assumption that the occurrences of new links in given networks might depending on the existence of current links between nodes. By initial investigations on the DBLP and common social networks such as Facebook, we recognized that about
Therefore, training the prediction model for a specific relation between same-typed objects, such as co-operation between two A-A in bibliographic networks (DBLP, DBIS, etc.) or U-U in social networks (Facebook, Twitter, etc.) with only one type of meta-path is absolutely not enough in the context of heterogeneous network. Most of HIN based INE models like as Metapath2Vec, MPBP and HIN2Vec can apply only one type of meta-path to produce the embedding model, therefore they fail to preserve multiple semantics of meta-path-based relations between two same-typed nodes. The main assumption for our works in this paper is that it will be more convincible if we predict the existence of new links depending on existent links between two pairwise nodes. For example, we predict the existence of co-authorship relations in DBLP (Fig. 2A) or new movies that users likely to watch and rate in movie networks (Fig. 2B) or new friendship relations between users in social networks (Fig. 2C). The idea of producing a new network embedding model that enables to capture multiple meta-paths in the embedded spaces of network’ nodes is our main motivation in this paper.
Existent meta-paths between pairwise nodes can influence the link prediction task in HIN.
Moreover, most of real-world HINs have a large number of nodes which are composed as text documents such as papers in DBLP or comments, posts in social networks, etc. these text-based nodes are considered as important nodes because they mostly appear in all types of meta-path, like as A-P-A, A-P-V-P-A, U-C-P-C-U, etc. These types of HIN can be called as content-based HIN. As the novel points of text analysis and mining, all text-based nodes have their own covered topics, such as papers in DBLP might have several covered topics like as “data mining”, “machine learning”, etc., comments on social networks (Facebook, Twitter, etc.) might mentioned about specific subjects like as “fashion”, “politics”, “entertainment”, etc. or films in movie networks (IMDB, TMDB, Netflix, etc.) have their descriptions which cover specific topics/genres like as “romantic”, “action”, “sci-fi”, “comedy”, etc. In fact, topics or subjects of content-based nodes have critical impact on almost network analysis and mining tasks. For example, the results of author similarity search, via meta-path A-P-V-P-A, in DBLP network can be improved by evaluating both number of path instances as well as topic similarity of papers between authors, or topic similarity of comments of users with meta-path U-C-P-C-U in Facebook social networks. Similar to node similarity search, the output of link prediction in content-based HINs also can be leveraged by combining with the topic similarity weight between content-based nodes along with the evaluated meta-paths.
Topic-driven link prediction analysis in content-based heterogeneous networks like as bibliographic networks, social networks, etc. have been considered as interesting as well as emerged as a major challenge of network analysis and mining nowadays. In general, the influences of topic similarity between nodes might lead to the occurrence of new relations, for example, two authors might likely have co-authorship relation if they are interesting on the same researching fields like as groups of authors “Jiawei Han”, “Jian Pei”, “Philip S. Yu”, etc. usually cooperate on “data mining” field or “Christopher D Manning”, “Richard Socher”, “Andrew Ng”, etc. who frequently have co-authorship relations on “natural language processing” and “AI/ML” papers, etc. (as illustrated in Fig. 3). Another example of link prediction task on IMDB movie network, two users likely to watch and rate new movies if these movies have the similar themes/topics in their descriptions with their previous watched and rated movies. These relations are represented by several meta-paths, like as U-M-A[actor]-M-U (two users watch and rate for movies which are acted by the same actors), U-M-G[genres]-M-U (two users watch and rate for movies which belong to the same genres), etc.
Example of topic-driven meta-path-based link prediction in DBLP bibliographic network.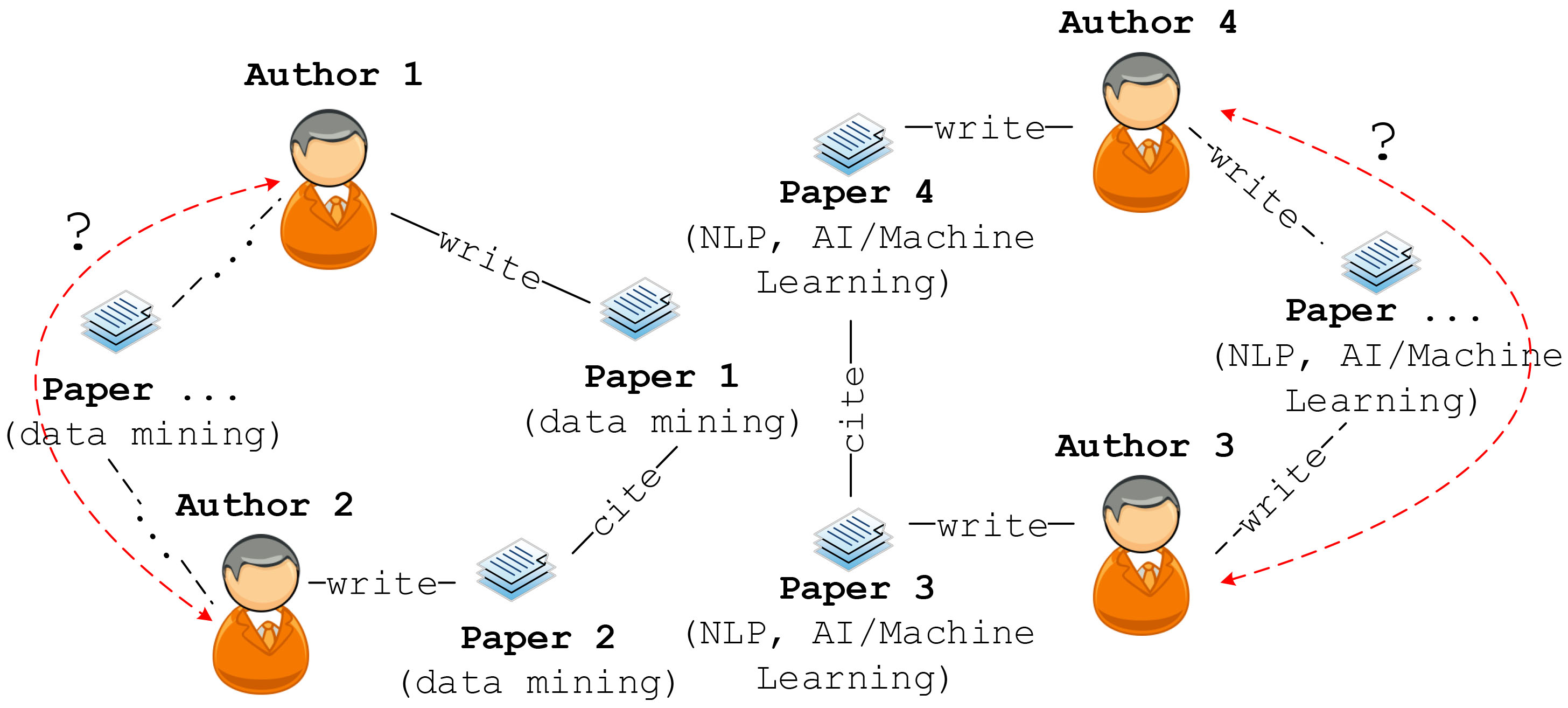
Most of recent well-known models for meta-path-based HIN embedding which can be applied to solve the link prediction task, such as: Metapath2Vec, Metagraph2Vec, SHINE, PME, etc. They focus on evaluating only the relations between nodes rather than other network’s attributes, such as topic. Therefore, it is necessary to propose a new embedding model which is able to capture not only the topological patterns of rich semantic relations but also topic similarity between content-based nodes along given meta-paths.
Our works in this paper are mainly focused on a novel integrated framework of topic-driven meta-path-based embedding model, namely W-MMP2Vec (
First of all, we proposed a novel approach of applying LDA [28] topic model for evaluating the topic distributions between text-based nodes in a given content-based HINs. Then these topic distributions of each text-based nodes will be used to compute the topic similarity scores which are used as the weights of meta-paths. Secondly, we introduce methodology of W-MMP2Vec network representation learning model which support to learn the representations of network nodes and their related meta-paths. The W-MMP2Vec model applies the random walk to generate training set and negative sampling to speed up the model training processes. In W-MPP2Vec model, we use 1-layer neural network and stochastic gradient descent are applied to train and optimize the network learning model. Finally, we conduct extensive empirical studies on proposed W-MMP2Vec by conducting a comprehensive evaluation with multiple HIN analysis and evaluation tasks, including link prediction and node similarity search. We conducted experiments on two real-world HIN datasets which are DBLP bibliographic network and MoviesLen100K movie network. The experimental outputs show the superiority of our proposed model by comparing with recent state-of-the-art information network embedding models.
The rest of this paper has four main sections. In the second section, we review the related and discussing about the advantages/dis advantages of HIN based network embedding models for link prediction. In third section, we briefly introduce about the baselines of HINs, meta-path-based INE and methodology of our proposed W-MMP2Vec model. We demonstrate experimental studies and discussions on Section 5. Finally, we draw conclusions and present our future work in Section 5.
Originally, information network embedding (INE) [7, 8] or representation learning has proposed as an approach for reducing the dimensions of distinctive features of network’s nodes and links. The ultimate goal of INE is to learn the low-dimensional latent factors which can be used to preserve the original structure of overall network. Among multiple methodologies for obtaining the network representation learning, the neural network architecture is mainly used and received important attention from researchers due to its successes in many practical implementations. At first, some previous works related to INE are concentrated only on learning embedded structure of homogeneous information networks (HoINs), such as DeepWalk [19], LINE [20], Node2Vec [22], etc. which fail to distinguish the difference in types of network’s nodes and links. Moreover, these HoINs based INE models can only preserve the directed relations between nodes and is unable to apply for capturing rich semantic sequential undirected relations in forms of meta-paths between same-typed nodes. For example, DeepWalk [19] and Node2Vec [22] models use next neighborhood random walk mechanism to generate context nodes which are used as the training set for leaning the feature vectors of network’s nodes. These models are similar to LINE [20] includes two versions which are LINE_1 and LINE_2. They enable to capture 1-hop and 2-hop neighborhood nodes to learn the network representation. To leverage the outputs of INE in heterogeneous information networks (HINs), there are several novel meta-path-based embedding approaches have been proposed to tackle challenges related to the heterogeneity of complex information network. The most well-known approach is Metapath2Vec [17] which uses meta-path-based random walk mechanism to generate the training context for each target node. Similar to Metapath2Vec, the other meta-path-based embedding models HIN2Vec [16], Metagraph2Vec [18], SHINE [4], PME [3], etc. was proposed as efficient network embedding models which have shown their effectiveness in dealing with the diversity of nodes and links in HINs. Beside the general information network embedding approaches, there is another sub-area of network embedding which is called as knowledge graph embedding approach. Knowledge-based graphs [8] such as Wikipedia, YAGO, Freebase, etc. are special type of heterogeneous networks contain multiple types of nodes/entities and labeled relations. The most well-known approaches in this sub-area are the Trans-family models, including TransE [29], TransH [30], TransR [31], etc. have been demonstrated as effective for knowledge-based graph representation learning.
Back to the problem of link prediction task in HIN by applying INE, a recent works like as Metapath2Vec/Metapath2Vec++ [17] has used a single meta-path to obtain the multi-typed node representations. However, the proposed Metapath2Vec framework only use single type of meta-path to generate the training set for each target node. Therefore, Metapath2Vec is unable to capture multiple relations in forms of meta-paths between same-typed nodes which is considered important for handling the combination of multiple meta-paths in link predict. Similar to the approach of Metapath2Vec, and Metagraph2Vec only use a specific meta-path/meta-graph to learns the latent spaces of nodes and links in HIN. Moreover, the recent HIN based INE models also mainly concentrate on evaluating the aspect of relationship between nodes only and don’t consider much about the other node’s attributes like as topic similarity. To tackle these remained challenges, in this paper we put forward a novel framework for obtain an effective network node’s representation by taking full advantage of using meta-path combination in generating the contextual neighbors of target nodes as well as applying topic similarity weight as the weights of meta-path in content-based HINs.
Methodology
Preliminaries
In this part, we first define principal baselines of information network, meta-paths as well as network embedding/representation learning.
In heterogeneous network analysis and mining, meta-path (definition 2) play an important role in defining the pattern of relation between two same-typed nodes. Meta-path is considered as a principal concept for most of HIN mining (PathSim [10], HeteSim [12], etc.) as well as both homogeneous information network (HoIN-based) and heterogeneous information network based (HIN-based) embedding approaches, such as well-known: DeepWalk [19], LINE [20], PTE [21], Node2Vec, Metapath2Vec [17], Metagraph2Vec [18], HIN2Vec [16], PME [3], etc. models.
Recently, we have witnessed tremendous raises of information network embedding (INE) (definition 3) due to its potential applications in multiple disciplines. In fact, INE has changed the ways that people normally apply for primitive information network analysis and mining tasks like as node similarity measure, clustering, classification, recommendation as well as link prediction. The approach of INE as well as other networked data embedding trends (graph embedding, knowledge-based graph embedding, etc.) are originally inspired from the Word2Vec [32] model of T. Mikolov et al. which are aimed to transform complex high-dimensional data structure into a fixed low-dimensional data structure in forms of vectors but still perverse the features and structure of original the data. In recent years, there are several practices of link predictions in HINs via INE have been proposed and attracted a lot of attentions from many researchers due to their outperformances in performance accuracy than traditional methods. However, recent HoIN-based and HIN-based models encounter problem related to the combination of existent meta-paths between pairwise nodes and weights of meta-paths during the network representation learning processes. These challenges are our main motivations for proposing W-MPP2Vec model which are carefully described in this section.
Topic similarity as meta-path weight in content-based HIN
For a given content-based HIN, all text-based nodes are considered as a documents, denoted as (
Examples of text-based nodes 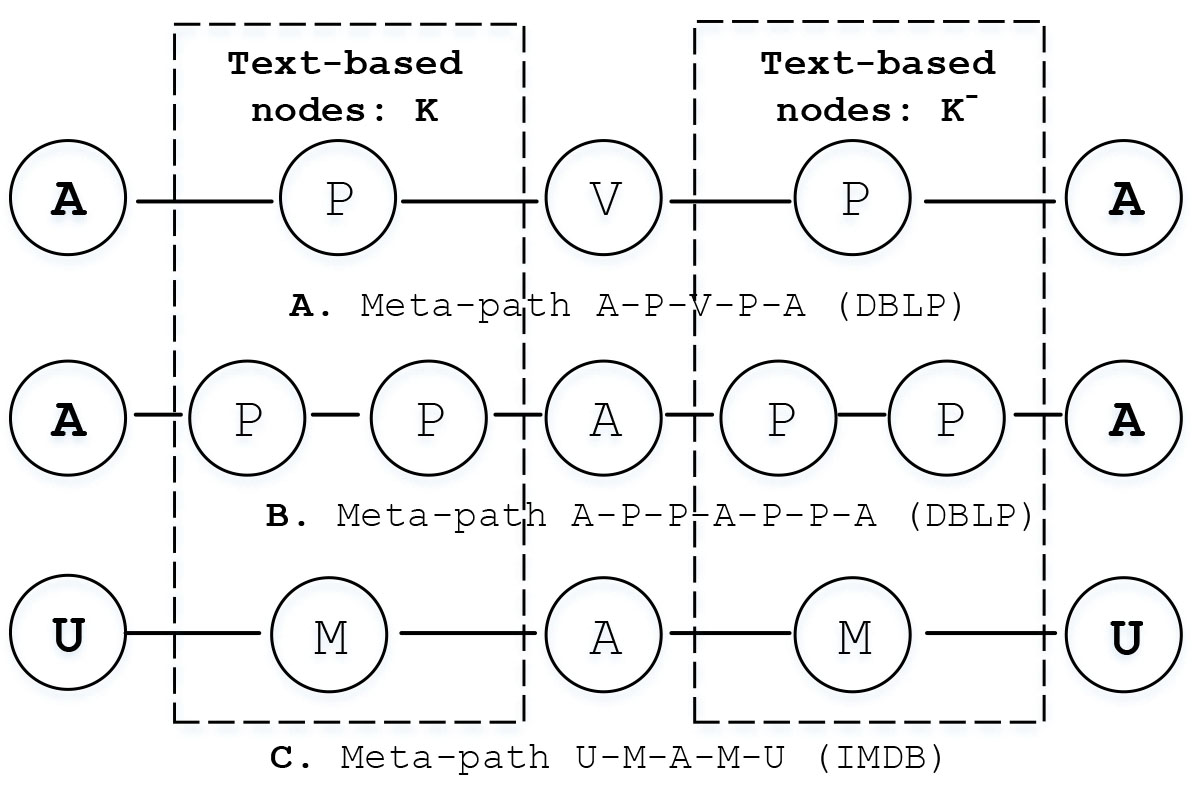
Finally, these topic distributions of these text-based nodes are used to compute the topic similarity weight of meta-paths which these nodes are occurred. Given a set of two text-based nodes
Where,
The
Goals and background assumptions
Learning objective of W-MPP2Vec model.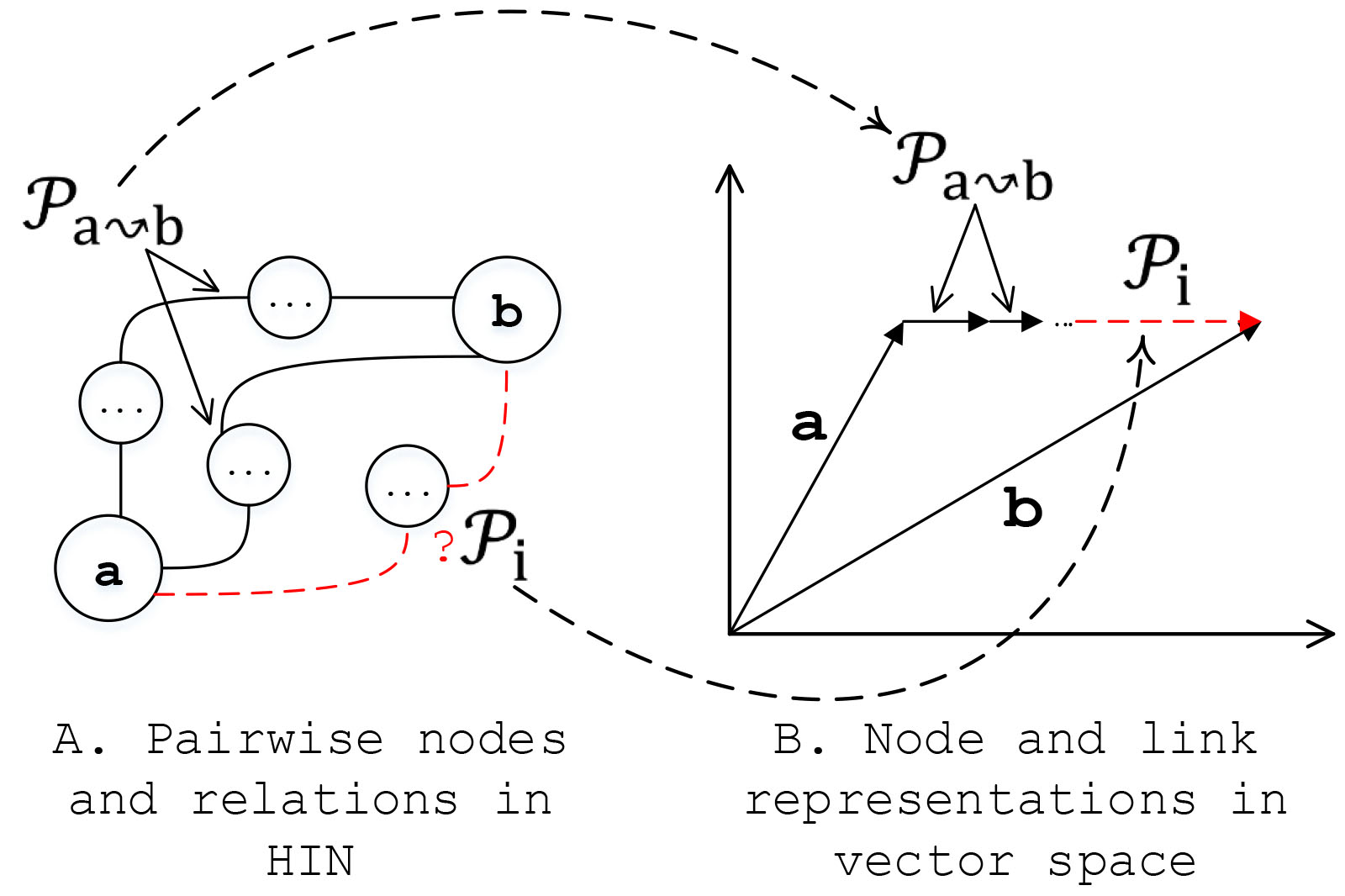
The ultimate goal of our works in this paper is to learn the vector representations of pairwise nodes in content-based HINs which support for predicting the possibility of relations in forms of meta-paths which will be occurred. As discussed previous, the new relations which might be occurred between pairwise nodes must be predicted depending the combination of multiple existent meta-paths as well as the weights of topic similarity of each meta-path. We formulate our link prediction problem in a given content-based HIN, denoted as a graph
Where,
From this idea, an intuitive approach is to build a network learning model that predict a new targeted relationships in form of meta-path
Then, with an initial (
The node representation learning flow of W-MPP2Vec model.
In overall, the conceptual methods of W-MPP2Vec model is assumed as a multiple-class classification problem for each pairwise node
Finally, to leverage we apply the topic similarity between sets of text-based nodes in each meta-path of
Weighted meta-path: meta-paths that have the pairwise text-based nodes set (
Binary meta-path: meta-paths that do not have pairwise text-based nodes set (
For each pairwise nodes
Where,
In general, from a given HIN, we generate the training data, denoted as
The objective
The feedforward and back propagation processes are repeated until the learning model is converged (illustrated in Fig. 7). The pseudo code for overall steps of our W-MPP2Vec model is described in Algorithm 1.
Illustrations feedforward and back propagation processes of W-MMP2Vec model.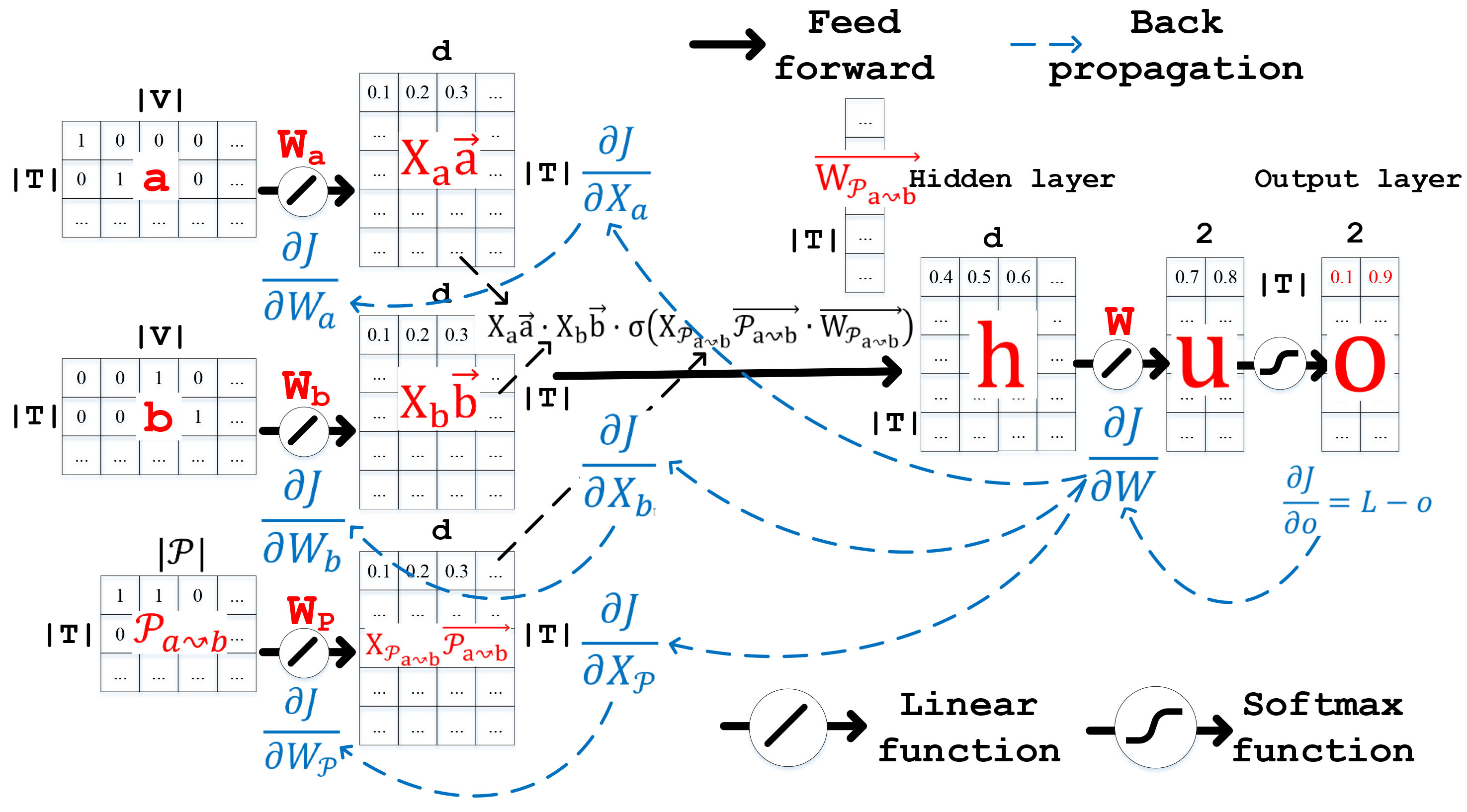
To generate training set for W-MPP2Vec model, we apply random walk mechanism (Algorithm 1 – line 2) which is guided by the expected predicting meta-path
In this section, we perform comprehensive experimental studies to demonstrate the effectiveness of our proposed W-MPP2Vec model for multiple meta-path-based heterogeneous information network representation learning via solving fundamental network mining tasks, including link prediction and node similarity search. The experimental results show the outperformance of our proposed framework by comparing with recent state-of-the-art network embedding techniques, including DeepWalk [19], LINE [20] (LINE_1, LINE_2), Node2Vec [22], PTE [21], Metapath2Vec [17], Metagraph2Vec [18] and PME [3].
Experimental settings and dataset usage
Experimental dataset usage
We perform our experiments on three main real-world datasets which are DBLP bibliographic network and MovieLens100K movie network and BlogCatalog social network. These networked datasets are:
DBLP1
DBLPdataset: AMiner dataset:
MovieLens100K3
MovieLens100K:
IMDB website:
TMDB website:
BlogCatalog6
BlogCatalog:
Arizona State University (ASU):
For the content-based HINs like DBLP and MovieLens100K, we apply both topic similarity weights of evaluated meta-paths and combination of multiple meta-paths in solving several network mining tasks including link prediction, node similarity search and clustering. With the non-content-based social network BlogCatalog, we only apply combination of multiple meta-paths aspect of W-MPP2Vec in training the network’s node representations in order to show the efficacy and efficiency of our proposed embedding framework.
We test our W-MPP2Vec model against 7 state-of-the-art information network representation learning models which are DeepWalk, LINE, Node2Vec, PTE, Metapath2Vec, Metagraph2Vec and PME. These models are setup as following:
DeepWalk [19]: is a primary network embedding model which captures the contextual nodes of each target network’s node by using uniform random walk mechanism with w-hop neighbors. DeepWalk enables to learn
LINE [20]: similar to DeepWalk on using contextual nodes for node representation, LINE has two versions called LINE_1 and LINE_2 which are applied for first-order and second-order proximities of nodes in the given information networks, respectively. LINE is also a HoIN-based INE which is unable to differentiate the diversity in types of nodes and links. For experiments, LINE is also applied Hin2HoIN and same vector dimension (
PTE [21]: this model is considered as an extended version of LINE which is designed to applied for HINs by splitting the heterogeneous network into multiple separated bipartite sub-networks. Then, it applies embedding mechanism of LINE to learn the representations of network’s nodes. To setup PTE for experiment in this paper, we also apply sub-network partitioning mechanism of PTE corresponding with specific evaluated meta-path in each experiment. Same embedding vector dimension (
Node2Vec [22]: is HoIN-based INE model uses BFS (breath-first-sampling) and DFS (deep-first-sampling) with two initialized parameters (
Metapath2Vec [17]: this is an HIN-based INE model which uses meta-path to guide the random walk process for generating contextual nodes of each target node in HINs. The Metapath2Vec uses heterogeneous skip-grams and negative sampling on same-typed nodes to speed up the network representation training process. The Metapath2Vec has two versions: Metapath2Vec and Metapath2Vec++ which are mainly applied for homogeneous and heterogeneous network embedding approaches, respectively. We only used Metapath2Vec++ version for this experimental study. In experiment, Metapath2Vec model uses the same number of walk (
Metagraph2Vec [18]: is similar to Metapath2Vec, the Metagraph2Vec defined a novel meta-graph-based random walk mechanism for the process of generating contextual nodes. Metagraph2Vec is considered as better than Metapath2Vec model in solving problems which are related to short-walks in HINs. Metagraph2Vec also has two versions for homogeneous and heterogeneous network embedding approaches which are Metagraph2Vec and Metagraph2Vec++, respectively. We only used Metagraph2Vec++ version for this experimental study. With experiments for HIN embedding tasks, Metagraph2Vec uses the same number of walk (
PME [3]: is considered as very recent HIN-based INE model for link prediction task. PME enables to learn the latent network’s node (
To sum up, all network embedding models are setup for experiments with the global model’s parameters as following (as shown in Table 1).
Experimental settings for network embedding
In this part, we demonstrate comprehensive experiments on three fundamental network mining tasks (link prediction, node similarity search and clustering) by using different network embedding models.
Link prediction task
Experimental setup. We model the link prediction task in HIN by using network embedding approach as a binary classification task to predict the existence of new relations in forms of meta-paths between two pairwise nodes. The link prediction task is solved by multiple network embedding models within three datasets. Each dataset (
Experimental metrics usage. To evaluate the performance of network embedding models in solving link prediction task, we use three main evaluation metrics: F-1 measure (Eq. (9)), Mean Average Precision (MAP) (Eq. (10)).
Where,
Where,
Meta-graphs of different datasets which are used in experiments for Metagraph2Vec model.
Experiments on DBLP dataset. For DBLP bibliographic network, we use several network embedding models to solve the co-authorship (A-P-A) prediction task. The
Performance evaluation of co-authorship A-P-A link prediction on DBLP dataset in terms of MAP and F1 metrics
Experimental outputs for co-authorship A-P-A link prediction on DBLP dataset with different training set size (%) in terms of Micro-F1 and Macro-F1
Co-authorship A-P-A link prediction accuracy in term of Micro-F1.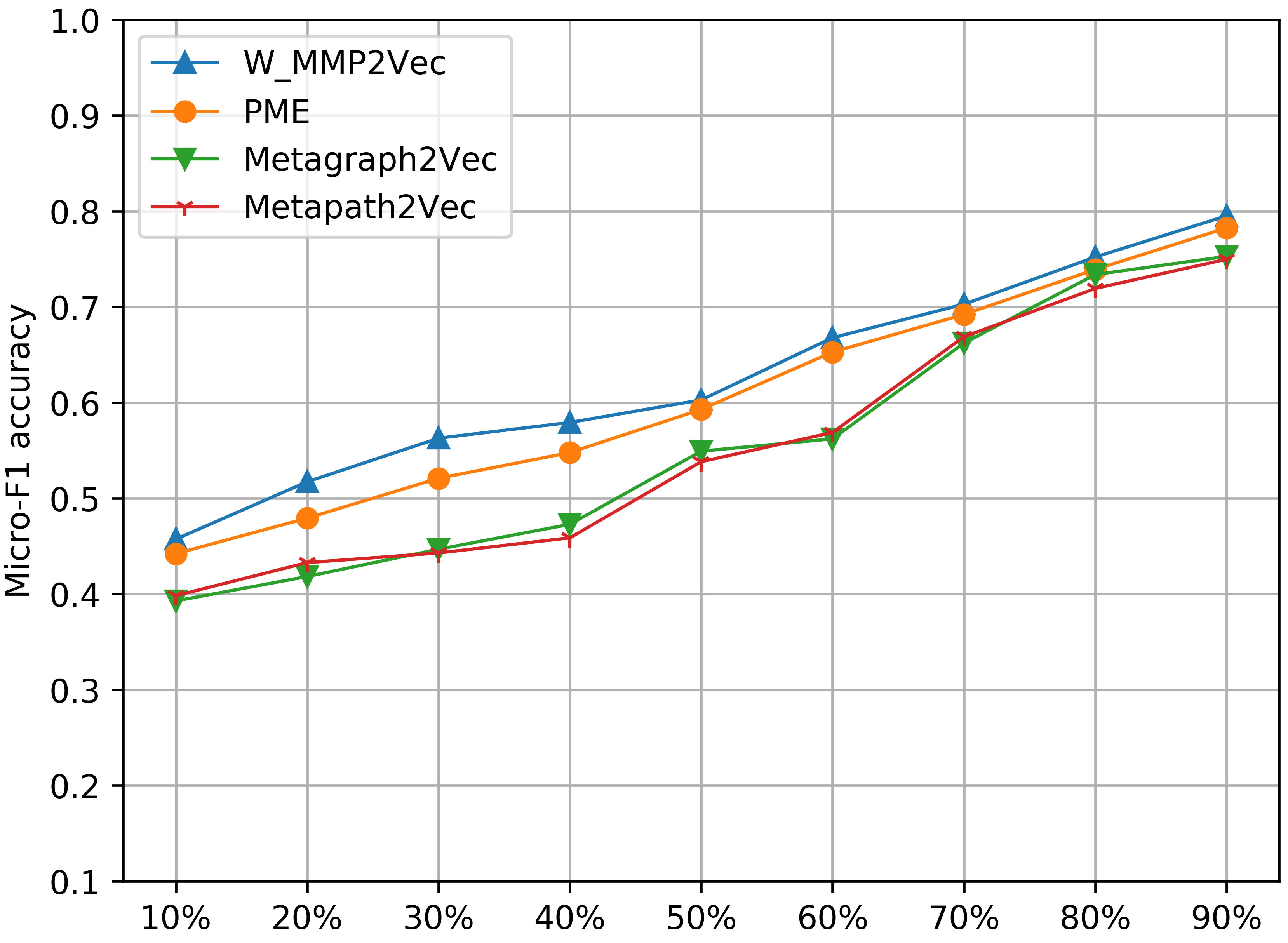
Co-authorship A-P-A link prediction accuracy in term of Macro-F1.
As shown from the experimental outputs in Table 2, our proposed W-MPP2Vec model achieves significantly better node representations for link prediction task than both HoIN-based and HIN-based state-of- the-art embedding models. In comparing with HoIN-based network embedding models like as DeepWalk, LINE_1, LINE_2, PTE and Node2Vec, W-MPP2Vec achieves relatively 12.03% and 23.27% improvements in terms of F1 measure and MAP metrics, respectively. Against HIN-based embedding models, like as Metapath2Vec, Metagraph2Vec and PME, the W-MPP2Vec model obtains better about 15.5% and 3.37% (Metapath2Vec), 13.89% and 2.73% (Metagraph2Vec), 4.14% and 1.06% (PME) in terms of F1 measure and MAP metrics, respectively. To test the stability of network embedding model with different size of dataset, we vary the size of the training set (
Experiments on MoviesLen100K & BlogCatalog datasets. For each dataset, we split the networks into two parts with different portions: training
For two datasets, we vary the size of the training set (
Performance evaluation of U-G-U and U-U link predictions on MoviesLen100K and BlogCatalog datasets in terms of MAP and F1 metrics
Experimental outputs for U-M-U link prediction on MoviesLen100K dataset with different training set size (%) in terms of Micro-F1 and Macro-F1
The experimental outputs (as shown in Table 4) shows the W-MPP2Vec model also achieves better performance in compare with recent state-of-the-art network representation models in both context-based (MoviesLen100K) and non-content-based (BlogCatalog) datasets. With content-based MoviesLen100K, W-MPP2Vec tremendously outperforms HoIN-based techniques about 25.13% and 12.97% (Node2Vec), 37.59% and 16.31% (PTE), 23.71% and 36.67% (average LINE_2 and LINE_2), 52.77% and 16.31% (DeepWalk) in terms of MAP and F1 metrics, respectively. With HIN-based approaches, our proposed W-MPP2Vec model also slightly improves the model’s accuracy for link prediction task approximately 3.93%, 5.29% and 8.34% in comparing PME, Metagraph2Vec and Metapath2Vec, respectively. For experiments on non-content-based BlogCatalog network for predict the user’s friendship (U-U) relation, W-MPP2Vec model outperforms around 21.9% and 33.79% than HoIN-based models in terms of MAP and F1 metrics. Comparing with recent HIN-based embedding models, W-MPP2Vec also consistently achieves higher performance averagely 3.54% and 1.62% in terms of MAP and F1 metrics, respectively. With these two datasets, we also evaluated the stability each embedding model by testing each one on different size of training set (varying from 10% to 90%) (as shown Fig. 11). Tables 5 and 6 show the experimental outputs for U-M-U and U-U link predictions on MoviesLen100K and BlogCatalog networks, respectively. As shown from experimental results on these tables, our proposed W-MPP2Vec framework can work stably on different size of training sets which ensure the capability of effective implementations on different types of network’s structure. To sum up, throughout several experiments for solving link prediction task on multiple types of HINs, the results show that our proposed W-MPP2Vec model generates more effective node embedding in the context of multi-typed nodes and links than up-to-date well-known network representation learning baselines. The W-MPP2Vec leverage the accuracy of link prediction task in HIN via the combination of existent relations between pairwise nodes in forms of meta-paths and calculating the topic similarity between text-based nodes as meta-path’s weights in the process of network representation learning.
Experimental outputs for friendship U-U link prediction on BlogCatalog dataset with different training set size (%) in terms of Micro-F1 and Macro-F1
Experimental outputs for U-M-U and U-U link predictions on MoviesLen100K and BlogCatalog datasets, in terms of Micro-F1 and Macro-F1, respectively.
Experimental setup. In this part, we conduct experiments on author and venue nodes similarity search with DBLP bibliographic network. Each network embedding techniques are used to transform author and venue node to embedded vectors, then we used cosine similarity to determine the top-k relevant nodes of a specific target nodes. Similar to experiments on link prediction task, we used HoIN-based network embedding models to learn the node representations of transformed Hin2HoIN networks via A-P-V-P-A (for author similarity search) and V-P-A-P-V (for venue similarity search). Similar to HoIN-based models, to setup the node similarity search for Metapath2Vec and PME models, we used the A-P-V-P-A and V-P-A-P-V as main meta-paths for authors and venues, respectively. For the Metagraph2Vec model, we used two meta-graphs which are the combinations of two meta-paths: A-P-V-P-A, A-O-A and V-P-V-P-A, V-P-P-P-V for authors and venues similarity searches similarity, respectively.
Example of subject areas/topics of “Quoc V. Le” author which are indexed by ACM Digital Library.
Example of top “Artificial Intelligence” venues/journals which are index by Google Scholar.
Experiments of node similarity search on DBLP network. To evaluate the outputs of author and venues similarity measurement, we use nDCG (normalized Discounted Cumulative Gain) metric [33] which enable to measure the accuracy of the outputs for each user’s query. To rank the outputs of each node relevance query, we use the set of topics which are assigned for author and venue as the main evaluation criteria. For author’s topics, we used the set of assigned “Subject Areas” in ACM digital library. These labelled author’s topics are categorized following the ACM Computing Classification System (CCS).8
ACM Computing Classification System:
ACM profile of Quoc V. Le:
Top venues/journals of “Artificial Intelligence” topic of Google Scholar:
The scores for level of node relevancy with the given node in query
Examples of top@5 authors and venues similar search on DBLP with W-MPP2Vec model
For author and venue node similarity search, in each test case, we randomly select 100 authors and venues from DBLP dataset and then try to find top@k relevant authors and venues. Then, the outputs for each query are applied nDCG to calculate to accuracy. These experiments are repeated 10 times and report the average performance as the final result. We performed the node similarity task by using different network embedding models to find top@5, top@10, top@20 and top@40 relevant authors and venues.
Accuracy performance for top@k author node similarity search in DBLP via different network embedding models in terms of nDCG metric
Accuracy performance for top@k venue node similarity search in DBLP via different network embedding models in terms of nDCG metric
Accuracy performance for top@k authors and venues similarity search on DBLP network.
As shown in experimental outputs for author (see Table 9) and venue (see Table 10) nodes similarity search tasks in DBLP, our proposed W-MMP2Vec performs the best in comparing with both HoIN-based and HIN-based network embedding techniques. Especially for the author relevant search task, W-MMP2Vec significantly outperforms averagely 28.39% than HoIN-based models like as DeepWalk, LINE, PTE and Node2Vec. In comparing with HIN-based models, W-MMP2Vec also achieves better performance than Metapath2Vec (2.74%), Metagraph2Vec (1.66%) and PME (2.12%). Our proposed W-MMP2Vec also gain higher accuracy in similar venue search than HoIN-based and HIN-based embedding baselines approximately 26.71% and 1.39%, respectively. In summary, the experimental results have demonstrated that W-MMP2Vec model generates better node representations than recent state-of-the-art network embedding baselines for solving the similarity search task in HINs (Fig. 14).
In this part, we study the parameter sensitivity of our proposed W-MMP2Vec embedding framework by solving venue and author nodes similarity search in DBLP network. Using the accuracy of author and venue nodes similarity search in terms of nDCG as functions, we vary values of three main parameters of W-MMP2Vec which are walks per node (
Parameters sensitivity of W-MMP2Vec model.
Model scalability comparisons between different heterogeneous network embedding model.
As we known that most real-worlds heterogeneous networks are complex and have such an impressive huge number of nodes and links, might be up to billions, like as common social networks (Facebooks, Twitter, etc.). In the scenarios of real-world applications, the designed network mining models must be feasible to be applied in complex large-scaled networks. In this section, we evaluate the scalability and optimization of our proposed W-MMP2Vec model in compare with recent state-of-the-art heterogeneous network embedding models, including: Metapath2Vec, Metagraph2Vec and PME. We conducted the experiments with the default configurations (refers as in Table 1) with DBLP dataset. Each network embedding model is applied to train the representations of DBLP network with different number of processing threads from 1 to 24. All heterogeneous network embedding models are implemented and evaluated on the same computer server with Intel
As shown from Fig. 16, the speedup rate of W-MMP2Vec model is quite close to the optimal points than other heterogeneous network embedding models. Depending on the experimental outputs, our proposed W-MMP2Vec model fasters than other embedding models about 2.59% (PME), 10.42% (Metapath2Vec) and 14.3% (Metagraph2Vec). The experiments in this section demonstrate the scalability and good optimization of our proposed model.
Conclusions
In conclusion, our works in this paper are mainly concentrated on defining a novel approach of information network embedding model which leverages the node representations by applying multiple meta-paths and topic similarity between pairwise nodes during the network representation learning processes. The W-MPP2Vec model enables to capture richer semantics of both node and their inter-connected relations in forms of meta-paths in content-based HINs. Extensive experiments demonstrate the effectiveness of our proposed topic-driven multiple meta-path-based framework in comparing with recent state-of-the-art network representation learning baselines. The W-MPP2Vec model is designed to work well on content-based HINs such as bibliographic networks (DBLP, DBIS, etc.), social networks (Facebook, Twitter, Baidu, etc.), etc. for solving multiple dependent meta-path-based link prediction task. Through thorough and comprehensive empirical studies on several real-world datasets like as DBLP, MoviesLen100K and BlogCatalog, we strongly believe that about model can be widely applied for applications related to heterogeneous network analysis and mining task. Our future works include various continuous architectural improvements and model optimizations for W-MPP2Vec to work effectively and efficiently in the context of big networked data. We all know that most of real-world HINs are composed as very large-scaled networks with a huge number of nodes (millions to billions) and uncountable relations. These such large-scaled networks are unable to handle and process on a single computer. Therefore, W-MPP2Vec need to be implemented under the distributed processing environment such as Apache Spark which enables to work effectively on very large networks.
Footnotes
Acknowledgments
This research is funded by Vietnam National University HoChiMinh City (VNU-HCM) under grant number DS2020-26-01.