
Abstract
Person re-identification (ReID) is a critical work in the field of intelligent image processing and deep learning, which has attracted the attention of industry application. Person ReID focuses on matching person images obtained from non-overlapping camera views and finding the person-of-interest. An important unresolved problem is to obtain efficient metric for measuring the similarity among pedestrian images. Lately, deep learning with metric learning has become a general method for person ReID. Yet, previous methods mainly used a variety of distance to measure the similarity among samples. The way of distance measure is more sensitive when the scale changes. In this paper, we propose angular loss with hard sample mining (ALHSM) to learn better similarity metric for the person ReID. Our work uses the angular relationship in triangles as a measure of similarity, minimizing the angle at the negative point of the triangle. ALHSM combines with hard negative mining strategies, which learn better similarity metric and achieve advanced performance on several benchmark datasets. The experimental results show that our work is competitive compared to the state-of-the-art.
Introduction
In recent years, person re-identification (ReID) has drawn significant attention in surveillance security and retrieval of suspects. Person ReID aims at matching objects/persons observed in non-overlapping camera views with feature descriptors and finding a person-of-interest (query) among a gallery of person image dataset [1]. Owing to various difficulties including changed lighting, alter of body pose, background environments and view angles, occlusions and low-resolution images, the similarity among different persons increases the difficulty, person ReID is still a challenging problem [2].
In the person ReID task, deep learning has attained better results than the traditional approach recently [3–5]. The existing methods mainly consist of two stages. One stage is extracting discriminative feature descriptors from samples. The second stage is computing the various distances of samples by feature comparison. The convolutional neural network (CNN) is frequently used for feature descriptor representation, extracts discriminative features from the query and the gallery images [6, 7]. The first stage mainly considers extracting more robust features. The second aspect involves the metric learning. Suitable distance metrics are indispensable to resolve person ReID ranking problem. The approaches of metric learning and ranking have been used to the person ReID [8]. The metric learning problem finds a mapping function, minimizes the same person samples distance and maximizes the different person samples distance. In multiple camera views, the similarity measure between person images increases due to changes in camera distance, body posture, etc. This article focuses on the metric learning phase in person ReID.
Several recent person ReID approaches show that identification loss combined with verification loss can learn a more discriminative person embedding [4, 9–11]. However, parameters of identification loss grow when the number of identities increases. Many parameters are discarded after retraining. Yet, verification loss is used to a pair of images, requires that training data contains real-valued labels, which are usually not available in practice. Meanwhile, the use of verification loss to determine the similarity of two pictures, one to one comparison, the efficiency is relatively low. Therefore, different distance loss methods, such as improved triplet loss [8], quadruplet loss [12], margin sample mining loss [2], multi-class N-pair loss [13], etc. are proposed and get better performance. However, the previous method mainly adopts the metric distance to measure the similarity of samples. The method of distance measure is more sensitive when the scale changes. Triplet loss margin selection is obviously not suitable for different intra-class. The previous measurement method mainly considered the optimization of similarity (e.g. contrastive loss) or the relative similarity (e.g. triplet loss and quadruplet loss). The loss function referred in the previous literature is defined by the distance of samples point, and other probable forms of loss function are rarelydiscussed [14].
In our work, we introduce angular loss combined with extremely hard sample mining (ALHSM), which performs better than some of metric learning losses on the person ReID problem. Our method illustrates significant performance on common person ReID datasets i.e. Market1501 [15], CUHK03 [1] and MARS [16] is competitive compared to the state-of-the-art.
Use angles rather than distances to define the core part of a measure of learning loss and describe the local structure more accurately. Combined with the existing architecture N-pair loss [13] and MSML [2], further enhance their performance. Angular loss uses the relationship of angles as a measure of similarity. Angular loss presents further accurately local structure better than distance-based triplicate loss. The approach in this paper limits the angle n described in Fig. 1 between the negative point of the two sides of the triplet triangle. The main advantage is the introduction of the scale invariance, which can resist the problem of scale change, improve the robustness of the target to the feature differences. This work captures the complementary partial structure of triplet triangles and introduces the idea of hard sample mining to achieve better convergence. To the best of our knowledge, this is the first work which explores angular loss combined with hard sample mining in person ReID field.
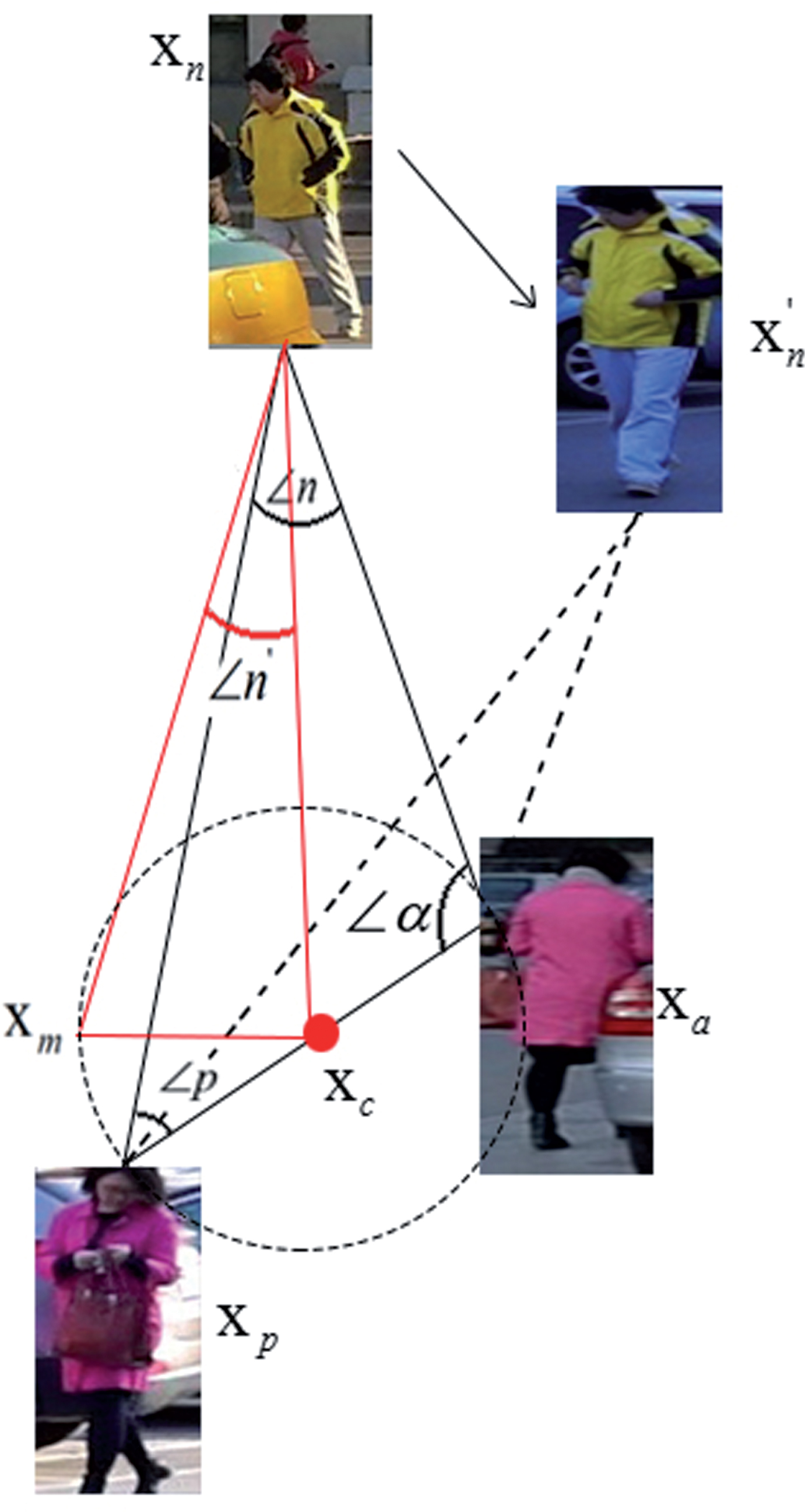
Illustration of the angular loss.
Learning Mahalanobis distance in a Euclidean space is a traditional metric learning method, such as Keep It Simple and Straightforward Metric Learning (KISSME) [17] applied in person ReID. Recently, deep metric learning methods usually extract features from CNN or other models, and then compute the feature distances in Euclidean space. Triplet loss function [5, 19] is used to investigate the relative similarity of different person images pair. In person ReID retrieval [3] and face recognition [20] tasks, triplet loss function usually was applied to solve the distance metric problem. In deep metric learning, a positive pair is two image samples of the same sample whereas a negative pair is two of different samples. One structure of triplet is made up of three samples, which comprise a positive person image pair and a negative person image pair. In order to achieve correct classification, the distance of the negative pair sample is enforced to be larger than the positive pair. The triplet loss is motivated by the threshold between pairs of positive and negative. However, the traditional triplet loss needs mining hard samples for efficient mining of similar features, otherwise training process will stagnate, training unstable and time-consuming [8]. If the sample is too difficult and will lead to training process shock, unable to converge. Traditional triplet loss may be generalized in the test set general effect, mainly since the class variance is still relatively large.
Some variant of the triplet loss is proposed [2, 22] to solve above problems. Wu et al. [21] proposed DeepLDA method which using fisher vectors combined with the LDA objective function. Yet, this method seems more difficult to train. Variations in the same id pedestrian are effectively reduced [5]. They further restrict the distance between pairs belonging to the same type based on Triplet Loss to be less than a pre-set value. Unfortunately, the method partly neglects the relative relationships between pairs. Ding et al. [22] proposed Batch All Triplet Loss which count all possible when calculating loss. The method of lifted structured feature embedding fills the batch with triplets considering all but the anchor-positive pair as negatives, meanwhile optimizes the smooth boundary of loss [7]. Hermans et al. [8] proposed a generalization of the lifted embedding loss which considers all anchor-positive pairs based on [7] and [22]. Chen et al. [12] resolved the problem of samples ranking aspect in ReID which introducing the quadruplet loss. One structure ofthe quadruplet loss including four samples which extending inter-class distances and diminishing intra-class distances. The quadruplet loss considers absolute distance between the pair of positive and negative samples. The quadruplet loss pushes away negative from positive pairs of samples. The quadruplet loss differentiates two pairs images on whether the query images are same or not.
Xiao et al. [2] proposed margin sample mining loss (MSML) with hard sample mining which absorbing quadruplet loss and TriHard loss functions advantages. The MSML loss only picks out the hardest one positive sample pair and the hardest one negative sample pair to calculate the loss. Thus, MSML is a harder sample harder than TriHard. MSML is to push the boundaries of positive and negative sample pairs away, hence the name of the boundary sample mining loss. MSML only used two pairs of samples to calculate the loss. It seems to waste a lot of training data. However, two pairs of sample pairs are chosen based on the results of the entire batch, so other images in the batch also indirectly affect the final loss. And with the increase of the training cycle, almost all the data will participate in the calculation of loss. In summary, MSML is a measure learning method that takes both relative and absolute distances into consideration and introduces the idea of a difficult sample sampling.
Based on the work of [2, 23–25], we propose angular loss combined with hard sample mining method applied on person ReID. The performance of common triplet loss method is not good in the case of large variation unbalanced class. This problem can be resolved by minimizing the angle of the negative point [25]. Angle is not only rotationally constant but also determined by the geometric nature of the triangle. This makes the goal more robust to changes in local feature mapping. Angular Loss has rotation invariance and scale invariance. ALHSM introduces the idea of hard sample mining to angular loss. In a triplet structure, the method of ALHSM employs angular relations as the distance measure, the hardest positive sample pair in batch is selected while using the hardest negative sample pairs to make the constraints.
Methodology
In this section, we introduce an angular loss with hard sample mining called ALHSM applied in person ReID, utilizing the deep network for feature extracting. Firstly, we review the common methods of triplet loss. Then the method of angular loss combined with hard sample mining is presented. We discuss the optimization of the method on a batch in detailat last.
The triplet loss and the variants
The purpose of metric embedding learning is to learn a function
We review of the method of common triplet loss. For instance, each of triplet loss {x
a
, x
p
, x
n
} contains an anchor x
a
, a positive x
p
and a negative x
n
in an iteration of the small batch. x
a
and x
p
are two pedestrian images of the same id, and x
n
is another different id person. The principle of triplet loss function is attempting to minimize the distance between an anchor sample and a positive sample. Maximize the distance between the anchor and a negative at the same time. The mathematical formulation can be formed as Equation 1,
The Euclidean distance is applied to measure the similarity of extracted feature descriptors from two input samples in triplet loss. In this paper, we use the learning metric g (x a , x p ) instead of the Euclidean distance to improve the robustness. The full derivation and proof can be found in [26]. Regardless of the threshold α triplet , the model can multiply g (x a , x p ) and g (x a , x n ) by appropriate values to meet the boundary threshold requirement. At the same time, a softmax constraint is added to obtain the similarity of [0,1].
The quadruplet loss improves the triplet loss by adding another different negative pair. A quadruplet loss function involves four different images {I
a
, I
p
, I
s
, I
t
}, where I
a
and I
p
are pedestrian images of the same id while I
s
and I
t
are pedestrian images of another two different persons separately. The quadruplet loss is formulated as Equation 2,
Furthermore, if we ignore the effects of the parameters α and β, we can represent the quadruple losses in a more general form as Equation 3,
The direct use of Lquad′ does not produce very good results because the number of quadruplets may increase dramatically as the amount of data increases. Most pairs of samples are relatively simple, which limits the performance of the model. In order to solve this problem, the margin sample mining loss (MSML) adopted the idea of TriHard loss. TriHard loss calculates triples loss in a batch for each picture in the batch, pick the hardest positive sample and the hardest negative sample and the picture form a triplet. Therefore, the loss function of MSML is defined as Equation 4,
Traditional triplet loss or contrastive loss is based on distance measurement, which cannot solve the problem of scale change. Only consider the sample second-order features. The angular loss constrains the angle of the triplet’s negative point, considering the third-order features rather than considering only the second-order features of the sample. The angular loss has scale invariance and improves the robustness of the objective function to counter the feature change. Angular loss essentially adds third-order geometric constraints, which can capture additional local structures in comparison with triplet loss or contrastive loss, as well as better convergence.
We represent the anchor, positive and negative samples in the angular loss structure, respectively, in the triangular geometry. Our purpose is to make the anchor and positive distance as large as possible, anchor and negative distance as small as possible. Intuitively, angular loss specifies that the angle of the negative point in triplet loss is less than a certain value, shown in Fig. 1. x a and x p are the same person, x n is a different negative sample. Depending on the nature of the triangle, if you want to keep negative samples away from anchor and positive samples, you need to make ∠n smaller. However, when ∠α is greater than 90°, the negative sample is closer to the anchor while minimizing the angle n, and the distance between different persons becomes larger. Therefore, a new triangle Δ mcn is formulated to moving the anchor sample x a and positive sample x p to x c and x m separately. Utilizing tangent theorem and the defined angle n, the definition of the angular loss function is to minimize the loss L ang (Equation 5).
Based on the work mentioned earlier in section 3.1, we propose the angular loss with hard sample mining method named ALHSM apply to person ReID. However, just use of L ang does not get better results. As the amount of data increases, the number of triples may increase dramatically. Most samples are relatively simple, which limits the performance of the model. The method uses two pairs of sample pairs and an angular limit to calculate the loss. The two pairs of sample pairs are picked based on the results of the entire batch, so other images in the batch also indirectly affect the final loss. And with the increase of training cycle, almost all the data will participate in the calculation of loss.
We combine the angular loss with a margin sample mining strategy. ALHSM selects the most dissimilar positive pairs and the most similar negative pair in the batch while satisfying angular loss, as Equation 6,
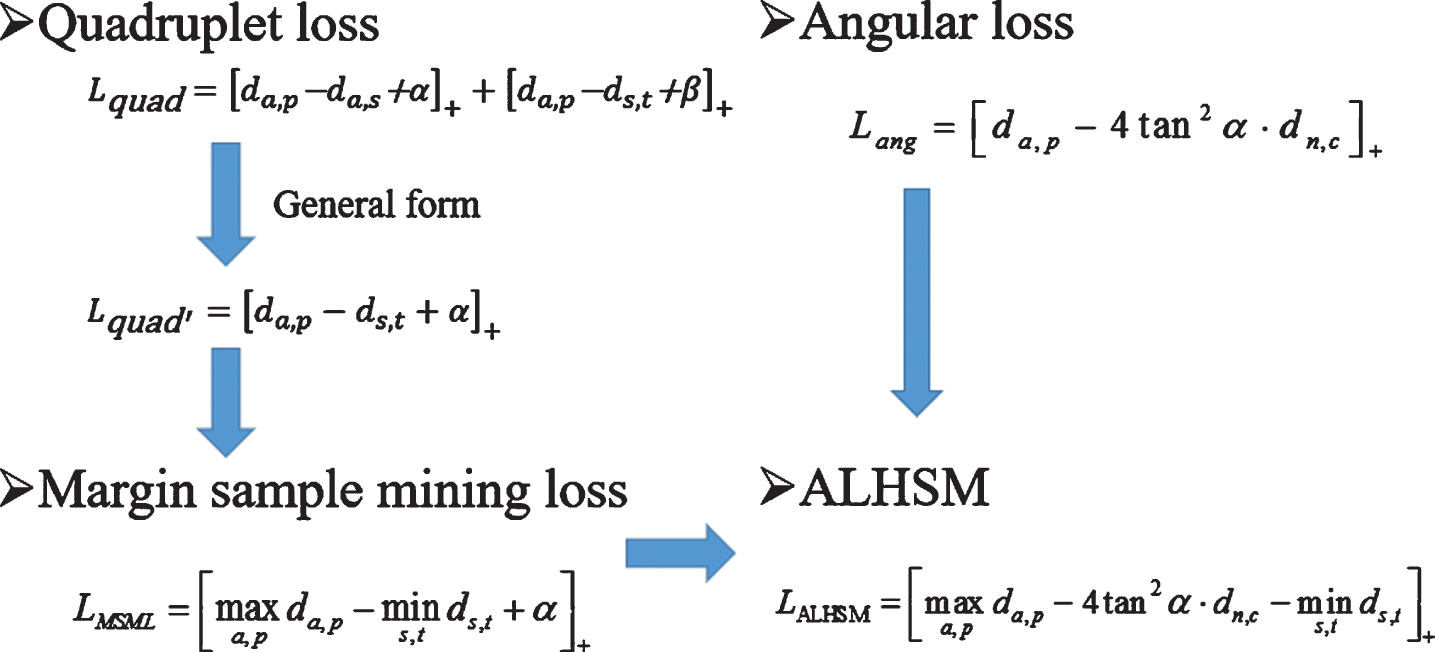
Several loss function relations.
We adjust the upper bound of the smoothness in Equation 6 in our experiments. It is assumed that the feature has a unit length in Equation 6, We use Equation 7 to represent the angle loss of a batch.
We reduce the constant term, as formulated in Equation 8, where ϒ in Equation 8 is the smallest distance persons in batch
In summary, compared with other metric learning losses, our ALHSM has following advantages. Our proposed method applies angular loss to the person ReID. In a triplet angle loss, the negative sample point is constrained by the angle. Meanwhile the method can be used to counter the scale and feature variation. Considering the relative distance and absolute distance, it combines the idea of hard sample sampling with angular loss.
In this section, we mainly assess the proposed method using three common benchmark datasets of person ReID, i.e. Market1501 [15], CUHK03 [1] and MARS [16]. We present performance results trained by GoogLeNet and ResNet-50 network structures separately. Then we contrast the proposed approach with state-of-the-art methods.
Datasets
Market1501 dataset [15] is one of most widely used datasets in the person ReID field. It contains 32,668 annotated bounding boxes of 1,501 identities collected from six cameras. It contains 19,732 images for testing and 12,936 images for training. There are 17.2 images per identity in the training set.
CUHK03 [1] contains 14,097 images of 1,467 identities collected in the CUHK campus. Each identity is captured by two cameras and has 4.8 images in average for each view. This dataset contains two kinds of bounding boxes. We evaluate our model on the bounding boxes detected by DPM, which is closer to the realistic setting. We report the averaged result after training/testing 15 times. We report the single-shot results on all the datasets.
MARS (Motion Analysis and Recognition Set) dataset [16] is an expanded version of the Market1501 dataset. This is a large video-based person ReID dataset. Since all bounding boxes and trajectories are automatically generated. MARS has a total of 20,478 tracklets, including 1,261 identities for 6 camera views.
Experiments results
The Chainer package is used throughout the experiments. Chainer [27] is an open-source deep learning framework featuring the define-by-run approach. Each image is normalized to 256×256 pixels before processing with data enhancement such as random horizontal flip, random crop and zoom. The final feature dimensions of GoogLeNet and Resnet50 are transformed to 1024 through a fully-connected layer. Adam optimizer is used and the initial learning rate is set to 0.0001. We use the SGD solver to train our model and set batch size to 120. We use HDF5 format to read and write data files, data of different types can be embedded in an HDF file.
We evaluate our method with rank-1, rank-5, rank-10 accuracy and mean average precision (mAP). We compared our method and the representative person ReID method on several benchmark datasets. The results are shown in Tables 1–3.
Comparison on Market1501 with single query
Comparison on Market1501 with single query
Comparison on CUHK03 with single query
Comparison on MARS with single query
As shown in Tables 1 and 2, BoW + KISSME [20] is the baseline experiment. We have obtained 86.87% and 87.93% rank-1 accuracy by GoogLeNet and ResNet-50, respectively on Market1501. Our model further improves performance from baselines on Market1501 dataset. Performance improvements can be observed on GoogLeNet and ResNet-50 network architecture. Specifically, we gain 1.67% and 2.73% rank-1 accuracy improvement compared with the method of MSML [2], respectively, using GoogLeNet and ResNet50 on Market1501. The comparison with several existing models on the CUHK03 and MARS dataset is presented in Table 2 and Table 3 separately. Similarly, we obtain 85.23% and 86.81% rank-1 accuracy on CUHK03 dataset in single-shot setting, using GoogLeNet and ResNet50 network. As shown in the table, our method outperforms all other methods with a margin, achieving 89.29% and 75.39% in mAP on the CUHK03 dataset and MARS dataset, respectively.
Finally, our ALHSM achieves the better accuracy on most experimental datasets for the different basic models. The results of these experiments show that our approach can handle different networks and improve their performance.
As depicted in Fig. 3, we further visualize some retrieval results on the three datasets, i.e., Market1501 [15] and CUHK03 [1]. The images in the first column are the query images. The retrieved images are sorted and shown in the second to the eleventh columns according to the similarity scores in the order of high to low. The correct and false matches are shown in green and red bounding boxes (best viewed in color), respectively. As shown in this figure, most candidate images can be retrieved correctly. The CHUK03 dataset is more challenging, which contain pedestrians with occlusions and similar appearance. Therefore, the proposed model has retrieved some incorrect candidates.

Examples of pedestrian retrieval results on three datasets using the proposed method in single query mode.
This paper has designed a model of angular loss combined with hard sample mining applied for person ReID (ALHSM). Depending on the nature of the triangle, we use angular loss to constrain the angle of the negative point of triplet, which can be used to combat scale and feature changes. We calculate the distance matrix of the batch, and restrict the angular loss by hard sampling mining, selecting the largest positive distance pair and the smallest negative distance pair to train the model, so as to improve the robustness of the model. We use GoogLeNet and ResNet-50 as base models to do some contrast experiments with different metric learning losses. On several benchmark datasets, including CUHK-03, Market1501 and MARS, the results show that our approach better performance than most of relative methods. In the feature, we will extend ALHSM to learning medical image processing from one view.
Funding
The authors acknowledge the Major Program of Natural Science Foundation of the Higher Education Institutions of Jiangsu Province (Grant: 18KJA520002), the Natural Science Foundation of Jiangsu Province (Grant: BK20171267), the Fifth Issue 333 High-Level Talent Training Project of Jiangsu Province (Grant: BRA2018333), the Horizontal Project (Grant: Z421A19830).