
Abstract
The image intelligent processing analysis technology uses a computer to imitate and execute some intellectual functions of the human brain, and realizes an image processing system with artificial intelligence, that is, an image processing analysis technology is an understanding of an image. The degree of intelligent automated analysis and processing is low, many operations need to be done manually, causing human error, inaccurate detection, and time-consuming and laborious. Deep learning method can extract features step by step in the original image from the bottom to the top. Therefore, based on feature analysis technology, this paper uses the deep learning method to intelligently and automatically analyse the visual image. This method only needs to send the image into the system, and then the manual analysis is not needed, and the analysis result of the final image can be obtained. The process is completely intelligent and automatically processed. First, improve the deep learning model and use massive image data to choose and optimize parameters. Results indicate that our method not only automatically derives the semantic information of the image, but also accurately understands the image accurately and improve the work efficiency.
Introduction
With the continuous improvement of people’s visual effects on images, more and more information data needs to be received, analysed and processed in the process of image processing. The intelligent automatic processing technology based on such conditions is precisely Powerful analytical, computational, and processing power is an important support for high-quality images, and the value behind it is immeasurable [1, 2]. Therefore, in-depth research and discussion of intelligent automatic processing technology in image processing is particularly important [3]. The intelligent processing technology of images is to transform the image type signals into digital type signals through intelligent means and process them on the computer [4, 5]. The technology is widely used in daily life, and the digital signals processed by it have the characteristics of high fidelity, easy storage, easy transmission, and superior anti-interference ability. It has been applied in the fields of medical equipment, aerospace, testing, industry, etc. With the rapid development of technology, this technology has gradually matured [6].
One of the main contents of image intelligent processing analysis is to use computer to imitate and execute some intellectual functions of human brain to realize image processing system with artificial intelligence [7]. Therefore, image understanding is one of the important basic theories for studying machine vision. Highly informative in today, this has become an indispensable technology for image information organization and management in image libraries [8]. The image information is processed and analysed, and the image knowledge is acquired, the image knowledge is acquired, the semantic network is used, the image knowledge base is established, and the image database is managed, thereby realizing the understanding of the image content. The method of extracting and expressing the underlying visual features and high-level semantic features is a difficult problem encountered in the image intelligent automatic processing of molecules.
A method for analyzing the characteristics of image information based on the information of time-frequency neighbors is proposed [9]. First of all, the method can extract the characteristics of image information and obtain the optimization function of blurred image. On this basis, the image is intelligently excavated and analyzed. The method is relatively simple, but there is a problem with large feature extraction error. The literature [10] is based on nonlinear dimensionality. Intelligent processing and analysis methods for image processing features. It is more efficient, but it does not provide a standard for measuring the size of image information when mining intelligent feature image information using the current method. The literature [11] focuses on the intelligent processing method of image based on SIFT feature points, which can first establish the Gauss pyramid image and change the scale of the Gauss nuclear function to give the exact position of the image feature endpoint. On this basis, the intelligent analysis of image information features is completed. The method has strong scalability, but the stability of feature mining is poor. David [12, 13] proposes a method for describing local features of images based on scale space. This method can keep the image zoomed, rotated and adjusted transformed indignity, thus being right. The image is analyzed intelligently. The SIFT feature vector extracted by the algorithm maintains geometric deformation and brightness variations such as panning, rotation, and scaling [14, 15]. It also maintains a certain degree of stability for ambient, ambient transformation, compression and noise pollution [16, 17]. However, if there are too many feature points, the calculation increases geometrically. Too little can reduce the accuracy of the alignment and even cause malfunctions. Therefore, when automatically assisting a digital image, it must be adjusted according to the pixel size and image characteristics of the pixel. The grayscales threshold of the feature point image, causes feature extraction to fail and not be able to intelligently analyze the image.
We construct a model and applies it to image intelligent automatic processing analysis. The model can extract features from bottom to top in the raw image. This method can not only automatically extract the semantic information of the image, but also understand the image accurately and improve the working efficiency.
The article is organized as follows. The construction of image intelligent processing analysis model is discussed in Section 2. In Section 3, the simulation results are given. Section 4 summarizes the main content of the paper.
Construction of image intelligent processing analysis model
Computer graphics intelligent processing analysis technology concept
The computer image intelligent processing analysis technology refers to using a computer system to input an image to be recognized, and the computer system identifies and matches the input image to identify the relevant information of the image. First, the computer system pre-processes the input image, separates the image from its background according to the characteristics of the image, and refines the overall image, so that the processing efficiency and speed of the computer system can be guaranteed in the later processing of the image. Then, the image is numerically identified, and the authenticity of the image is maximized by the computer system to remove the false part of the image. Finally, the computer image recognition intelligent processing technology can compare the image of the input system with the image in the known image library, and the search time in the image library is controllable. Through a series of processing of the image by the computer system, accurate identification and judgment of the image properties can be realized.
The intelligent processing and analysis technology for images is a new technology formed by combining intelligent technology, colour low illumination processing technology, sensors, etc., which meets the development needs of various industries and is carried out in the continuous development of various industries. The intelligent processing and analysis technology of the image can improve the recognition rate of the image in the monitoring device and the camera, and make the image clearer, thereby achieving the high visual requirements of people. Specifically, it uses high-sensitivity technology to allow surveillance devices, cameras, etc. to clearly display images in low-light or even no-light environments. In short, using this technology, the monitoring device can clearly display images regardless of day or night, thereby improving the utilization rate of the monitoring equipment at night and improving the monitoring effect.
At present, intelligent image intelligent processing and analysis technology is widely used in combination with CMOS sensors. The sensor has high sensitivity, and its image noise clearing system can obtain clear images in an environment of ultra-low light or even no light, as shown in Fig. 1. This technology meets the needs of people’s daily life and work, such as the demand for high-definition photography and the demand for high-definition surveillance. At the same time, this technology also has great application value in the intelligent processing of image recognition.
Image intelligent processing combined with sensors.
The common intelligent processing methods for computer image recognition mainly include intelligent image registration methods, intelligent image retrieval methods, intelligent image watermarking techniques, and intelligent image feature analysis techniques.
(1) Intelligent image registration method
The intelligent image registration method can superimpose or match the images obtained in different devices, different conditions and different times. This method is widely used in the intelligent processing of computer image recognition. The process of the specific intelligent image registration method is as follows: firstly, the feature is extracted from the image to obtain its feature points, then the two images are measured to find the feature points with the highest similarity and matching degree, and finally according to the found features. Point pairs acquire the spatial coordinate transformation parameters of the image to achieve registration of the image. Figure 2 shows the image matching of the sift algorithm.

Image matching of the sift algorithm.
(2) Intelligent image retrieval method
The traditional image retrieval method is a text-based (TBIR) retrieval method, which performs indexing on images by indexing information such as image name, type, and size. The TBIR method cannot analyse the visual elements in the image. The widely used intelligent image retrieval method is a content-based (CBIR) retrieval method. The retrieval clue of this method is the semantic feature of the image, and the process of stripping the image and forming an image set is performed in a massive image library. Retrieve an image similar to this. In general, content-based methods work better than text-based methods.
(3) Watermarking technology for intelligent images
Digital Watermarking (DW) is an advanced technology for maintaining data security. The role of this technology is the same as that of hiding information technology. Digital watermarking technology can use digital embedding to hide a watermark with a certain meaning into an electronic image as a voucher for image ownership, preventing someone from making an infringement of the image. In addition, the digital watermark also has the function of analysis and detection to ensure the integrity of the image information. Digital watermarking technology has been widely used in the intelligent processing method of computer image recognition. Its main outstanding features are mainly reflected in the following three aspects: First, the watermark is concealed and will not affect the normal use of electronic images; second, the watermark has high security and is difficult to tamper with or forge. Third, the watermark has high sensitivity. After the image is intelligently processed, transmitted, etc., the watermark can be made to be tampered with accurate judgment.
(4) Feature analysis technology of intelligent images
Among the intelligent processing methods of computer image recognition, image feature analysis technology is a commonly used technique. This technology can extract and analyse the feature quantity in the image. The feature quantity in the image is different according to the image. It is the premise and important basis for image processing. The feature analysis of an image usually includes the colour, texture, shape, etc. of the image. We can describe the content of the image by combining and analysing these features.
Based on the feature analysis technology, this paper uses the deep learning method to intelligently and automatically analyse the image.
The structural framework of the deep learning network DCnet designed in this paper is shown in Fig. 3, which mainly uses convolution, transposition convolution, the hole of convolution, pooling, jump connection, activation function and other techniques. There are a total of eighteen convolutional layers, including six common convolutions, six transposed convolutions, six hole convolutions, and two activation functions Relu and Sigmoid; two merge techniques add and concat are used; Maximum pooling has been added to enhance the model’s translational rotation without distortion; a total of 4.5 million trainable parameters are included.

DCnet network structure.
DCnet is inspired by the nature of empty convolution. Up-sampling is required to restore the size to the original input size. Up-sampling generally uses a transposition convolution operation. Pooling allows each pixel forecast to see a larger acceptance domain information. Therefore, the classical image segmentation network model full convolutional neural network has two key points. In the process of size change, the semantic information of the image is extracted, but in the process of zooming, it is inevitable that there will be a lot of information loss, then a reasonable assumption can be made: if an operation can be designed, the image is not reduced by pooling. The size can also have a greater sense of the field to get more information, then the network using this operation will certainly show better results.
The DCnet network adopts a self-encoder structure and is divided into four phases: an encoding phase, a feature fusion phase, a decoding phase, and a pixel classification phase. In the coding phase, a VGG-like convolution block is used. The DCnet network adopts the structure of the VGG network in the coding phase. See Table 1. The process is divided into three convolution processes. Each convolution consists of two convolution layers and one pooling layer.
Convolutional layer structure
The slight translation has no effect on the maximum pooled output, but has a great influence on the mean pooling, so the maximum pooling translation invariance is more prominent. At the same time, the input of the pooling layer is the response of the input of the convolution layer to the convolution kernel. The larger the value, the stronger the response, the more the characteristics we want, so the maximum pooling extraction is the strongest response to the convolution kernel. The characteristics are also the most effective features. Therefore, the maximum pooling is better than the mean pooling. The largest pooling is used in DCnet. The pooling size is 2×2 and the step size is 2. Figure 4 shows the maximum pooling operation.

Schematic diagram of the maximum pooling operation.
In neural networks, Sigmoid and Tanh use a wider range of activation functions. Tanh is an improved version of Sigmoid. As shown in Fig. 5, as the network layer increases and gradually accumulates, the higher the network layer, the larger the offset difference, which affects the learning speed of the neural network model, resulting in slow convergence. Tanh’s output is 0-means, which improves this shortcoming, but it can be seen that, like Sigmoid, tanh is very easy to saturate, so that the network model cannot learn useful information in recursion, which is called gradient disappearance.
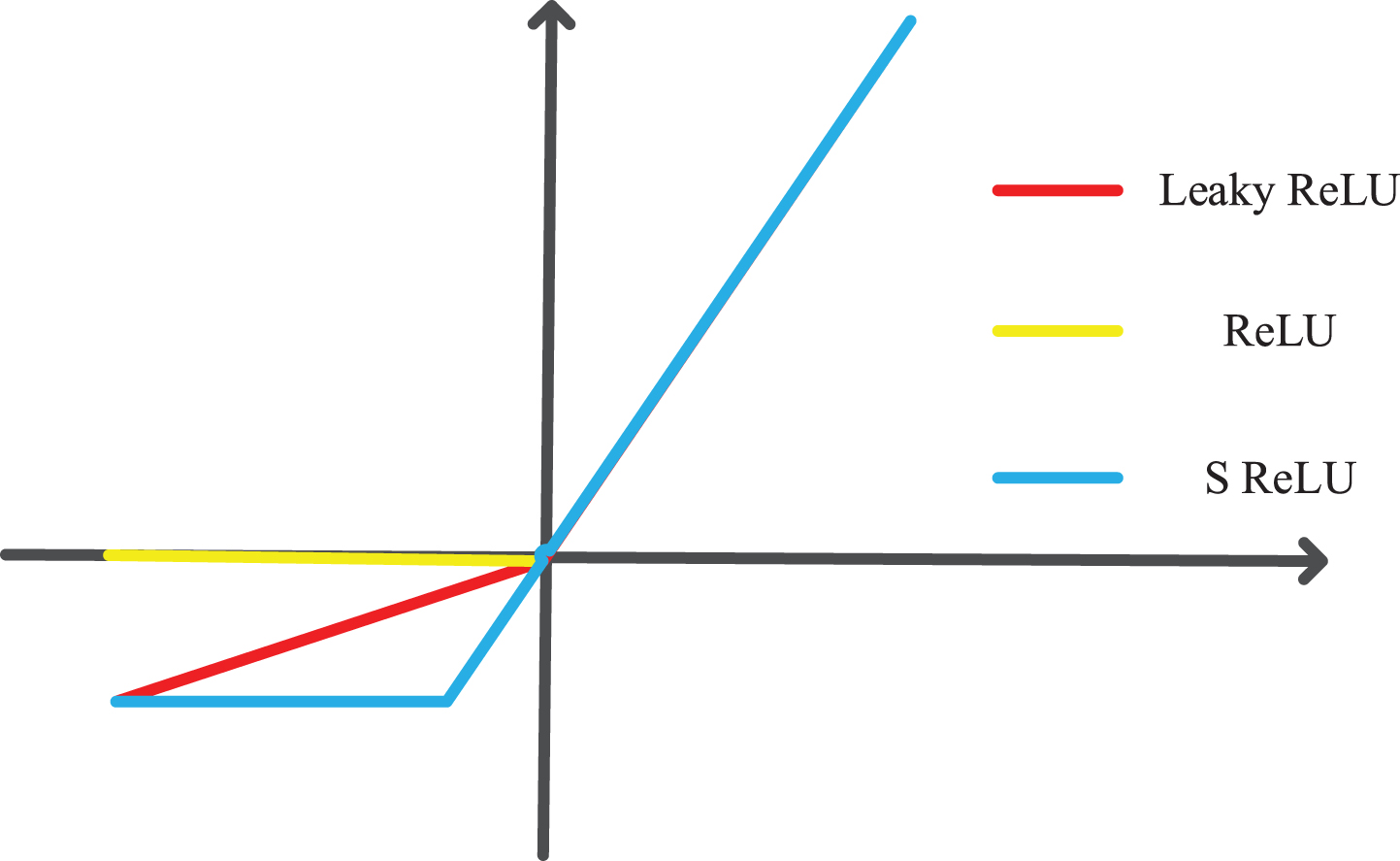
Activation function.
In image segmentation, the more information the extracted feature contains, the more likely it is that the current pixel will be correctly classified. As shown in Fig. 6, for the same image, receptive field is as shown in Fig. 6(a), it is difficult to correctly classify the pixels in the centre of the receptive field, but as shown in the Fig. 6(b), it is easy to judge the category of the current pixel.

Receptive field contrast.
Reinforce the field by increasing the convolution layer, as shown in Fig. 7, but increasing the convolution layer will increase network layers; or use the pooling layer to reduce the size of the image to increase the receptive field. Then, the result is up-sampled and restored to the original size, but in the process of reducing and then increasing the size, there is a lot of loss of detail information; another method is to use hole convolution, and the cavity convolution can be In the case of loss of information, the feeling of the field is increased. Suppose that all the convolution kernels of a convolutional neural network are kxk, and the convolution step is 1, then the receptive field of the corresponding unit of a convolution kernel, that is, the size of the pixel block used to activate the unit is (k-1)xl + 1. This is a great limitation for high-resolution input images, and more convolutional layers need to be superimposed to extract high-quality features. The proposal of empty convolution is to solve this problem. The definition of the cavity convolution in two dimensions is as follows:
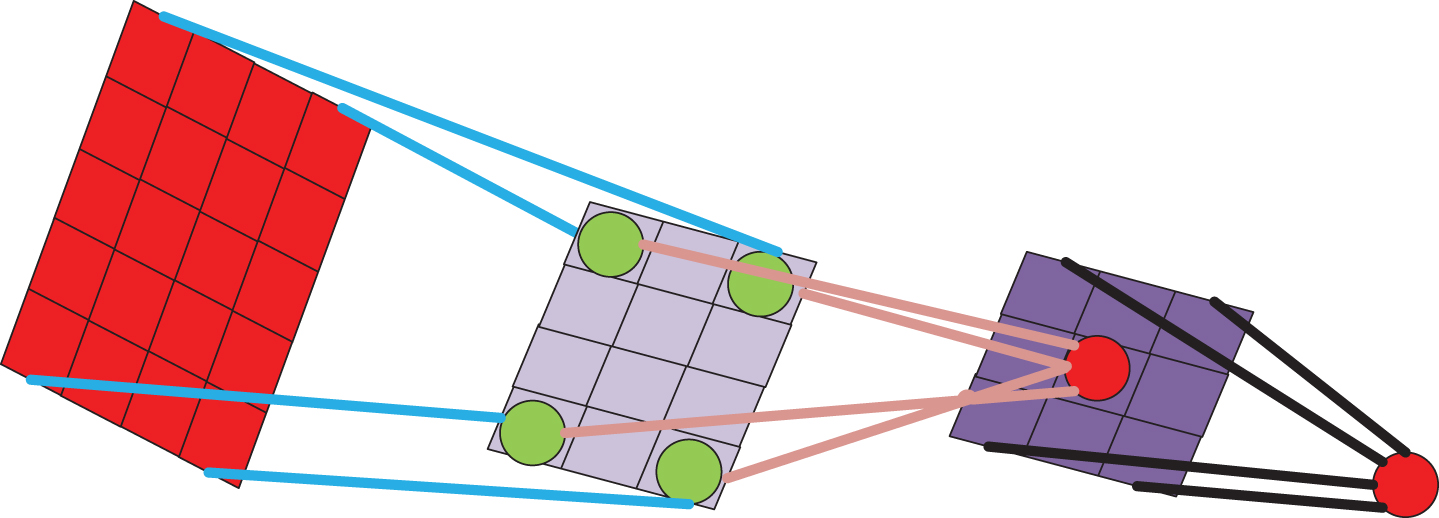
Increase the convolution layer to expand the receptive field.
Where F is the input two-dimensional signal (image), s is its domain; k is the kernel function, t is its domain; l is the coefficient of the cavity convolution; P is the domain of the hole of convolution. It can be seen that compared with the ordinary convolution, the condition of the convolution changes from s + t = P to s + lt = P, that is, each convolution kernel only operates with elements of multiples of the image F [18]. Figure 8 shows the relationship between the void convolution and the receptive field.

Cavity convolution and receptive field.
In Fig. 8, the convolution kernels are all 3×3, (a) is the receptive field when the hole convolution coefficient is 1, which is the same as the ordinary convolution operation; (b) the receptive field with the convolution coefficient of 2, feel the wild is a 7×7 image area, and only 9 points marked red are convoluted with the convolution kernel, and the remaining points are skipped; (c) is the receptive field with a coefficient of 4, and the receptive field is a 15×15 image region. Compared with itself, when the convolution kernel increases, the receptive field of the cavity convolution increases exponentially; compared with the traditional convolution operation, the receptive field increases a lot without increasing the parameters. This feature is well suited for image segmentation, so we’ve added it to our image segmentation model. Under the premise that the parameters are not increased, a good effect is achieved. In the DCnet network, after the end of the coding phase, we perform the hole of convolution of the acquired features with coefficients 1, 2, 4, 8, 16, 32, further extract features of different scales, and then perform features of different scales. Convergence gives a more expressive overall feature.
Literature [19] has proved the advantages of multiple consecutive 3×3 convolutional layers to deepen the depth of the network. (1) Deeper networks contain more activation functions. The more activation functions, the more the network pairs the nonlinear models. Describe the good month, make the decision function more discriminative; (2) effectively reduce the parameters, reduce the difficulty of model training, and speed up the training. A series of empty convolutions were then made. Each hole of convolution has a different hole with size, and information of different size blocks in the image is collected separately. Then superimpose it to get more rich combination information, which is conducive to subsequent training.
Since image segmentation is a model in which the input is equal to the output, three up-samplings are performed afterwards, using a transposition convolution operation. At the same time, each layer of transposed convolution input incorporates the down-sampled output of the corresponding location in the network, which is called a hop connection. Through the jump connection, the underlying features extracted in the early coding stage can be merged with the high-level features extracted in the decoding stage, forming a richer description of the features, which is beneficial to the subsequent classification of pixels. The final classification does not use the traditional fully connected layer, but instead uses a convolutional layer. One is to reduce the parameters of the network; the second is to support image input of any size; the third is to achieve the same effect as the full connection. The final loss function uses the mainstream softmax cross entropy, which always performs well in multi-category classifications.
Figure 9 shows the working principle and process of transposition convolution. Using a 4×4 convolution kernel to perform a transposed convolution of 2×2 input pictures with a step size of 3, the whole process can be divided into two steps:
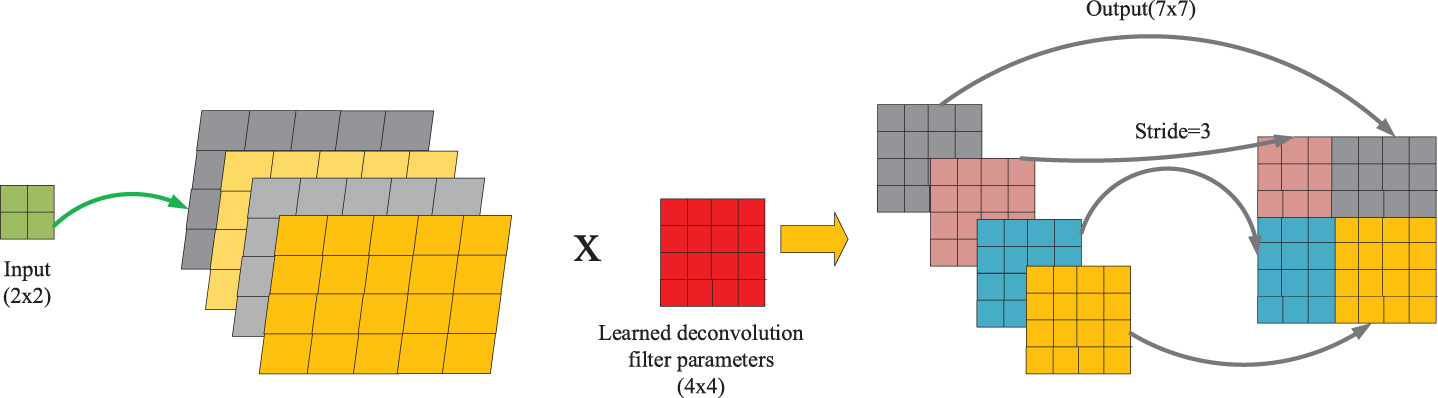
Transpose convolution process.
Using a 4×4 convolution kernel to perform a full-volume operation for each pixel. The convolution size variation formula can be used to calculate the transformed size 1 + 4-1 = 4, and a 4×4 size feature map is obtained, for a total of 4 inputs. Pixels, so I got 4 4×4 feature maps; Since the side length of the feature map is 4, and the step size of the fusion is 3, there is a poor area between the feature images, and the summation operation is directly performed on the poor area.
It is not difficult to find that convolution kernel and convolution movement determine the size of the transposed convolution result. li is the input size. Output can be calculated by Equation (2).
In the decoding phase of the DCnet network, our three up-sampling operation consists of three up-sampling operations and six transposed convolutions. Through the layer-up sampling operation, the size of the vector is continuously restored to the size of the input image. At the same time, three concatenate operations are performed, which are combined with the low-level features extracted during the coding phase to make the description of the features more abundant and effective. The concatenate operation will be described in detail in the jump connection. The structure of transposed convolution in this network is shown in Table 2.
Transposed Convolution Structure
The DCnet network is structurally symmetrical overall. The parameter quantity is only 4.5 million, which is greatly reduced compared to the current hundreds of millions of parameters, so there is an advantage in speed. Especially in the scenes where the scene is not very complicated, there is a good classification effect.
Hardware configuration
As shown in Table 3, in the software environment, the experiment uses Ubuntu 14.04 64-bit operating system, the programming language used is mainly C++ and Python, using the open source deep learning framework as the main tool for building the network, the dependencies involved.
Experimental Software Configuration Table
Experimental Software Configuration Table
As shown in Table 4, in the hardware environment, the experiment used the ASUS Z10PE-D8 WS server-class motherboard, equipped with a dual Xeon E5 2670 V3 processor, and equipped with Nvidia GTX TitanX 12 G memory card. In addition, the 256GB memory and 480GB SSD and the network port of the aggregated dual Gigabit Ethernet card are powerful enough to support the training requirements of deep learning networks.
Experimental hardware configuration table
Through 10 times of cross-validation on all training data, the optimal DCnet network structure is found. We built a DCnet network with different hidden layers, and then repeated experiments for each network structure. In the experiment, we found that when the number of hidden layers exceeds 12 times in the experiment, the average accuracy rate will gradually stabilize without big fluctuations, as shown in Fig. 10. Therefore, we use 12 hidden layer autoencoder network structures to build the analysis model of medical image data.
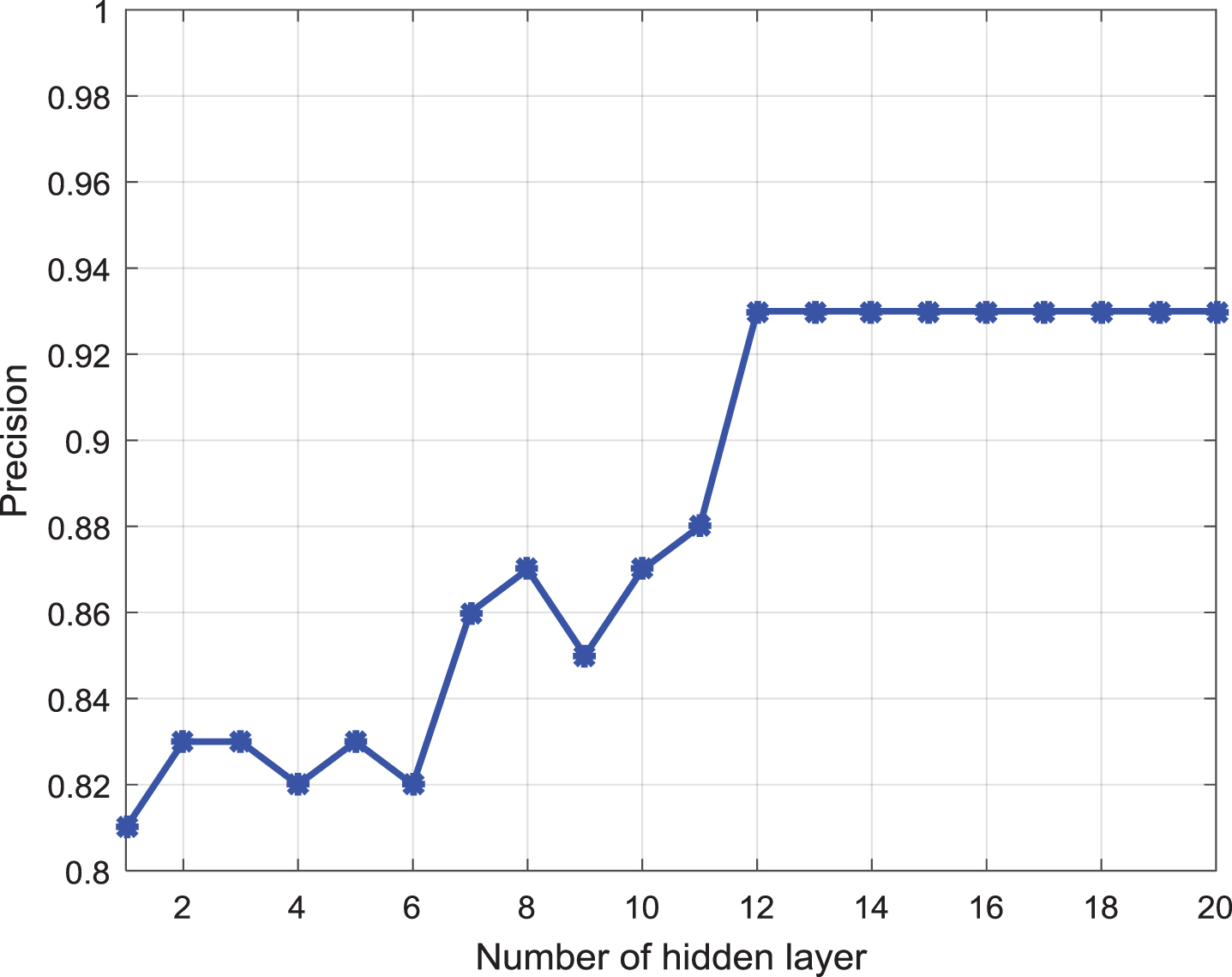
Different number of hidden layers of DCnet model test accuracy.
Data set was pre-trained on the basis of the VGG model, and then 1000 iterations were trained with 10,000 simulation data sets. Then, the 800th, 900th, and 1000th saved models were selected and trained on the CamVid dataset.
Figures 12 and 13 show the training set correctness and loss curves for 4000 iterations based on 800 pre-training models. Due to better pre-training, although the learning rate is set very small, the network still converges quickly, and we believe that the design of the residual structure plays a key role. A total of 4000 iterations, in fact, the loss function values almost never change after 2000 iterations.
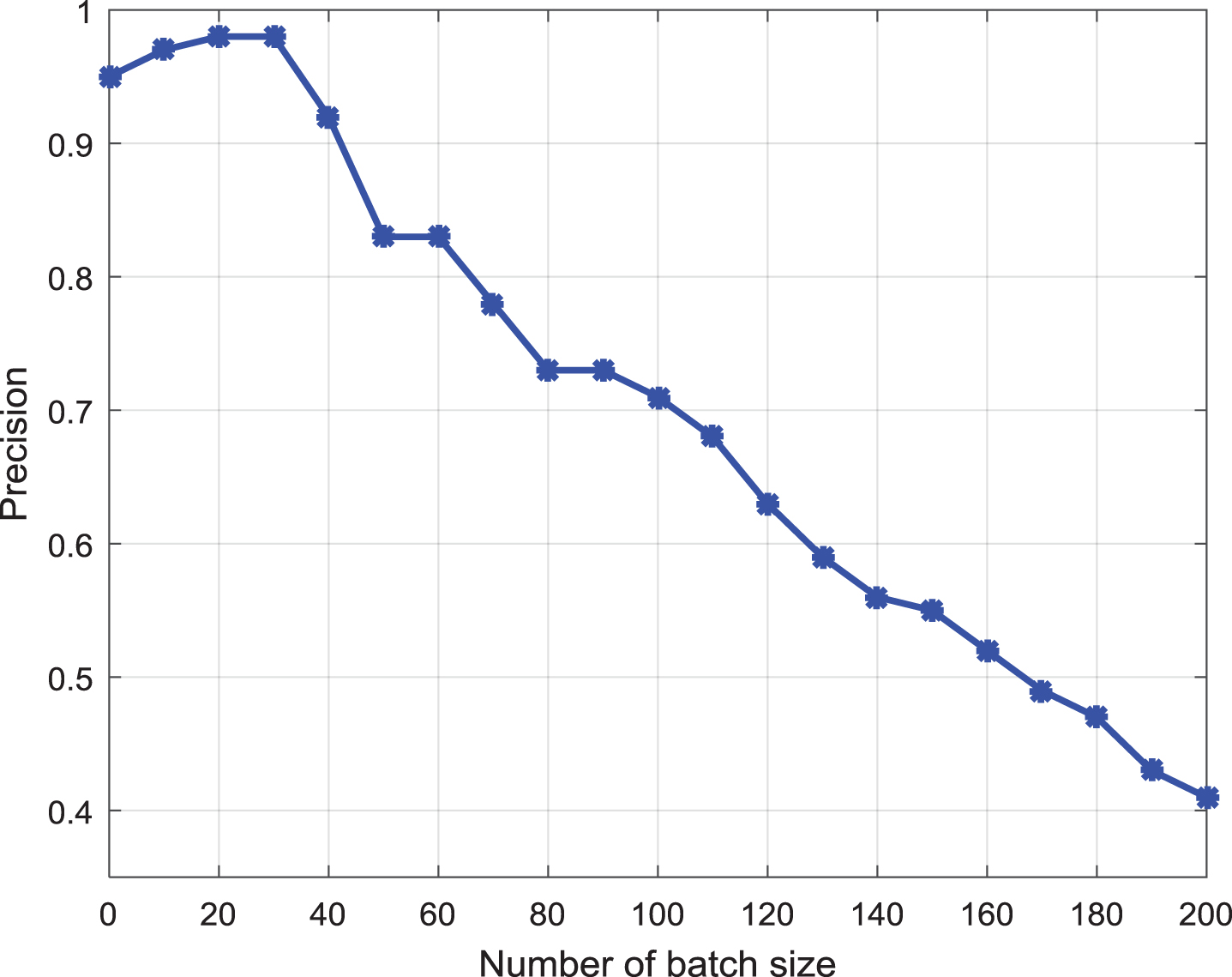
The accuracy of data analysis accuracy with batch size.
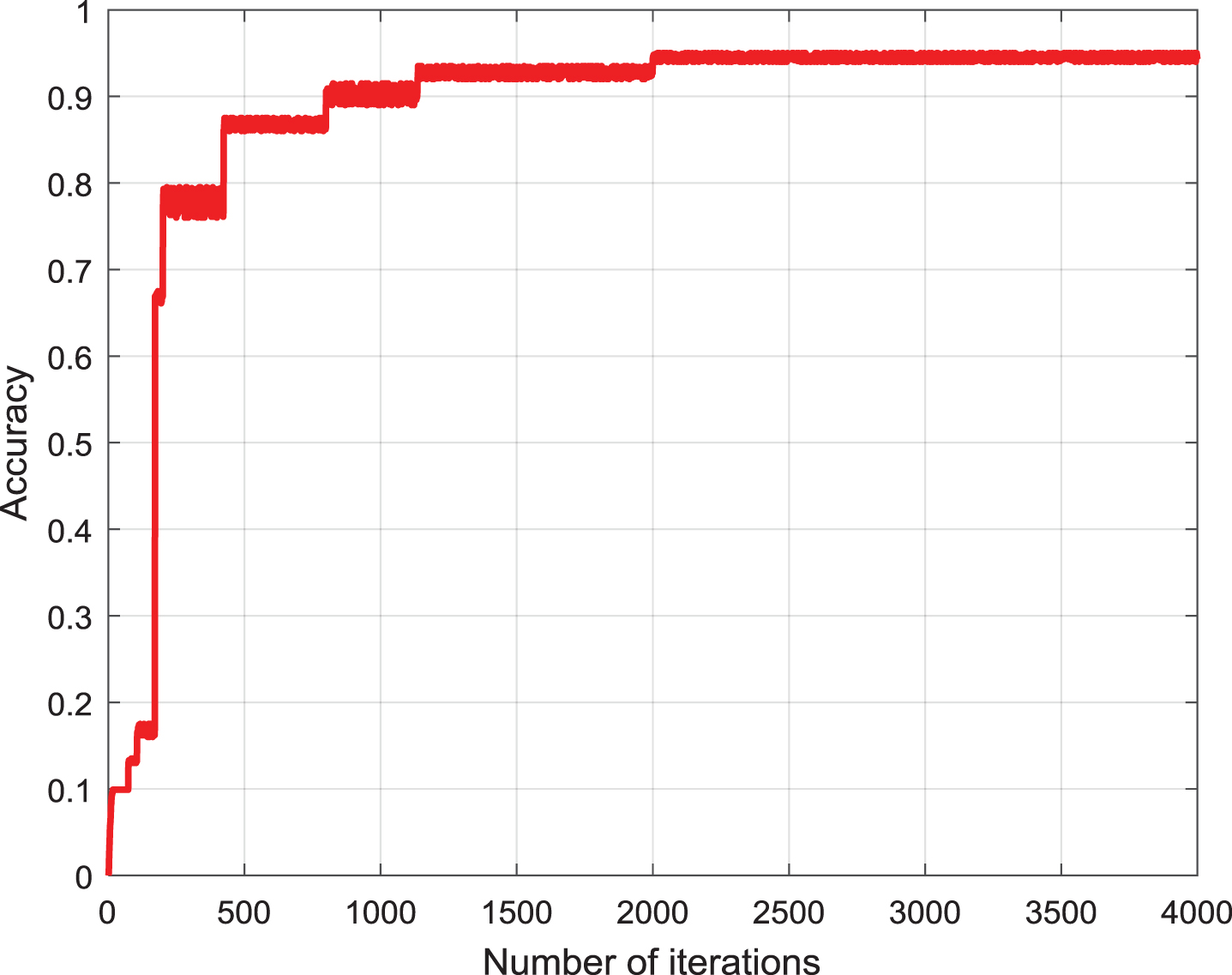
Global correct rate change on training set based on 800 pre-training model iterations.
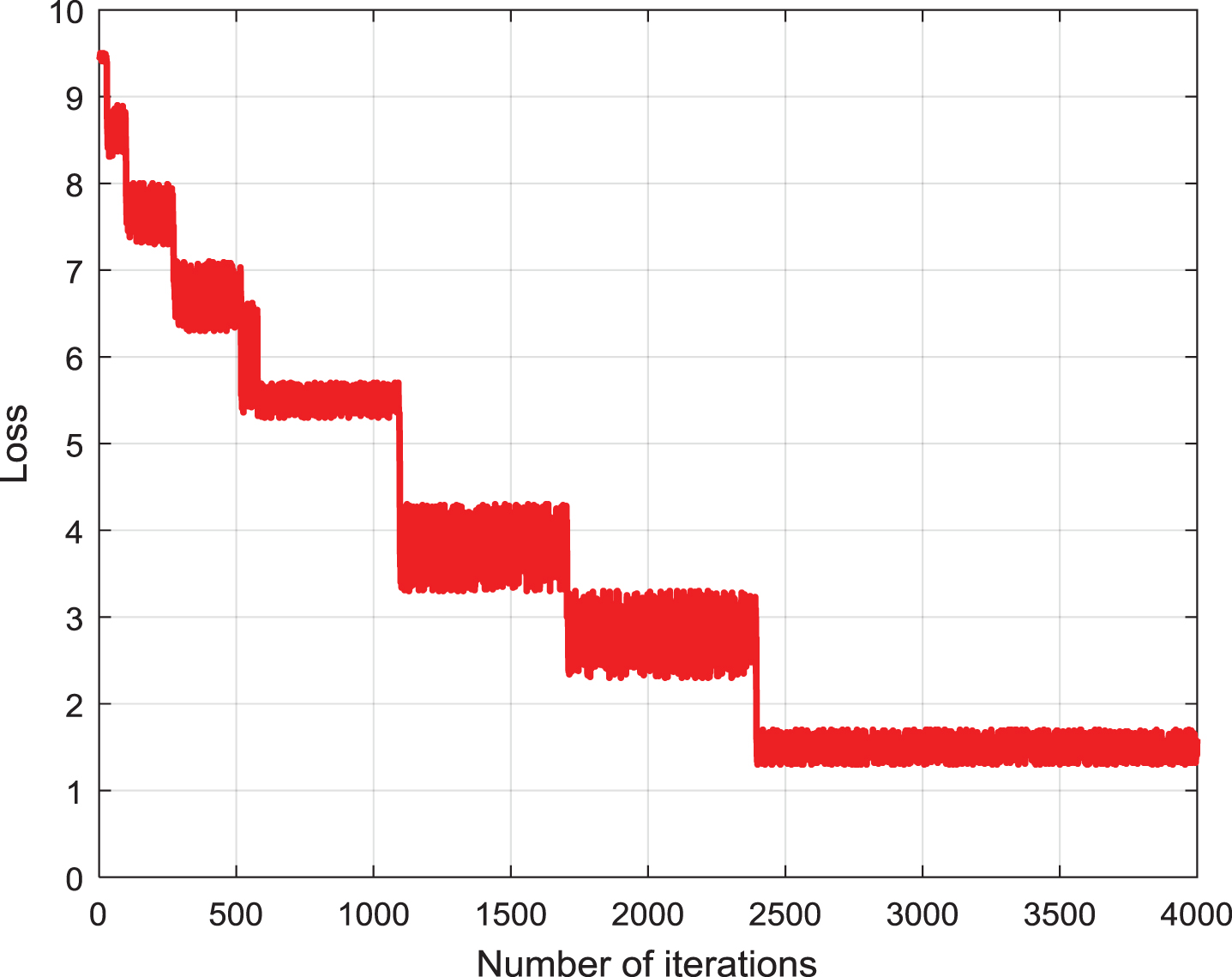
Variation of loss values on the training set during iteration based on 800 pre-training models.
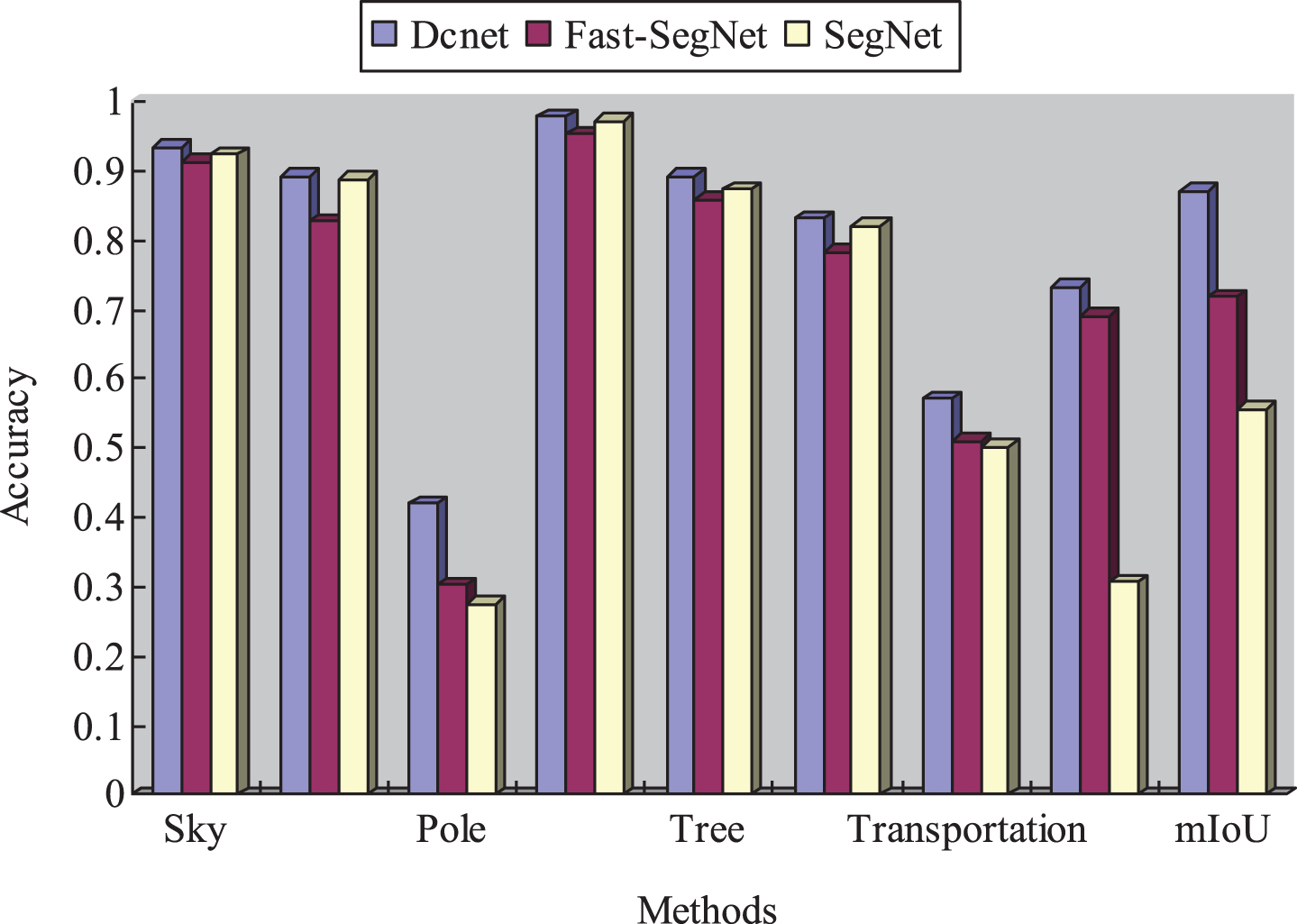
Figure 14 compares the performance of our designed DCnet network and Fast-SegNet [20] and SegNet network [21] on the Camvid dataset. It can be seen that our model improves the classification effect in 8 categories, among which traffic there are significant improvements in the three categories of logos and fences and bicycles. We believe that this is inseparable from the sparse convolution described earlier in this paper and the high-level features and underlying feature fusion structures designed in this paper. It is precisely because of this structure. The design makes the segmentation effect more subtle, and the classifications that originally appear smaller or less in the image can be segmented.
CamVid data set segmentation results.
Nowadays, the rise of image intelligent processing and analysis technology has attracted great attention in various fields. Therefore, the shadow of intelligent image technology has been seen in many fields. It can be said that the value behind it is already immeasurable. Therefore, in the increasingly fierce market competition, it is necessary to conduct in-depth research on intelligent processing analysis technology, and better play the role of intelligent processing analysis technology, so that it can be applied to more fields, which is also in the future, people’s needs, the direction of market and technology development. Based on the feature analysis technology, this paper uses the deep learning method to intelligently and automatically analyse the image. Results indicate our method can not only automatically derive the semantic information of the image, but also accurately understand the image accurately and improve the work efficiency.
Footnotes
Acknowledgments
This work is supported by Collaborative Innovation Major Project of Zhengzhou (20XTZX06013).