
Abstract
The data of time series are massive in quantity and not conducive to subsequent processing. Therefore, the unordered time series fuzzy clustering algorithm of adaptive incremental learning has been utilized to explore the segmentation of time series in further. The research results show that the emergence of incremental learning technology can solve such problems. Also, it can continuously accumulate and increase the data, as well as improving the learning accuracy. Incremental learning technology correctly processes, retains, and utilizes the historical results, thereby reducing the training time of new samples by using historical results. Therefore, the clustering algorithm mostly clusters the cluster-liked shape of discrete datasets and uses the hierarchical clustering algorithm, which is more suitable for measuring the similarity of time series, to replace the Euclidean distance for distance metric and hierarchical clustering. The distance matrix update method is improved to reduce the computational complexity, which proves that the algorithm has higher clustering validity and reduces the operating time of the algorithm.
Introduction
The time series arranges the observation values on a time basis. The observation values are the values of the corresponding observation objects at different times. Generally, the measuring time points can be continuously distributed or discretely distributed, such as the continuous speech signals, the annual temperature data of a city, the data of closing market prices, the monthly profit data of a company, and the temperature information received by the temperature sensor at any time [1]. Time series objects are complex and widely used [2]. Due to the rise of computer technology and big data, enterprises, factories, and equipment are developing in the direction of large-scale, complicated, integrated, refined, and intelligent [3, 4]. In the actual research, most of the researches on time series are based on massive data. The data generally contain complex and valuable information. In general, the time-series data are enormous, and the information is complex; therefore, it has the features of high dimensionality and complexity, which makes it not conducive to the processing of the computer.
With the rapid development of computer technology, the traditional time series analysis method is no longer suitable for time-series data that are high-dimensional and complex. The analysis of data is mainly focused on the data analysis process of machine learning, pattern recognition, artificial intelligence, and other technologies, instead of just traditional statistics and queries [5]. Therefore, the way to effectively extract valuable information from a significant amount of time-series data becomes the most concerned issue [6]. Traditional methods based on probabilistic analysis and modeling are not suitable for discovering new tasks and are difficult to mine implicit knowledge.
In this study, the unordered time series fuzzy clustering algorithm is researched. The adaptive incremental learning technology is used to improve the learning precision. The adaptive incremental learning technology makes full use of historical training results. When new samples are added, the training time can be appropriately reduced, providing theoretical support for predictive decision research of time series data mining, which is significant for time series data mining technology.
Related work
Gonz
Yang and Jiang (2018) explored that temporal data clustering could provide the underlying technology for the discovery of intrinsic structures, which was proved to be critical in condensing or summarizing the information needed in various fields of information science from time series analysis to sequential data understanding [11]. In their research, a new hybrid elementary clustering set based on hidden Markov model (HMM) was proposed, which had a dual weighting scheme to solve the initialization and model selection problems related to time data clustering. In order to improve the performance of the ensemble technique, the proposed dual weight scheme adaptively checked the partitioning process and thus optimized the fusion of consensus functions. Specifically, three consensus functions were used to combine input partitions, and the HMM-based K models were initialized and generated under different initializations to enter a strong consensus partition. The best consensus partition was then selected from the three candidates by an objective function based on normalized mutual information. Eventually, through the HMM-based clustering algorithm combined with the tree-based similarity partitioning algorithm, the optimal consensus partitioning was further refined, resulting in the advantage that the number of clusters can be determined automatically and adaptively. Hou et al. (2018) solved the construction problem of Takagi-Sugeno-Kang (TSK) fuzzy model through clustering. The fuzzy minimum-maximal neural network based on contribution factor was developed by Simpson’s fuzzy minimum-maximal neural network (FMNN) [12]. The contribution factor (CF) was also referred to as the typical mode, and the user-specified mode can be the membership threshold of the CF of the cluster, which solved the stability problem and could avoid unnecessary overlap in the FMNN. The results showed that the algorithm had fast learning speed and excellent prediction performance. The simulation was sufficient to illustrate the clustering behavior of CFMN and the recognition performance of the obtained fuzzy inference system (CFMN-FIS). In order to solve the problem caused by the different signal distribution of inertial sensors, Zhao et al. (2018) proposed an adaptive user algorithm based on K-Means clustering, local anomaly factor (LOF), and multivariate Gaussian distribution [13]. In order to automatically cluster and annotate the activity data of specific users, an improved K-Means algorithm was designed. The algorithm adopted a novel initialization method. By quantifying the sample information degree of the marked individual data sets, the most favorable one could be selected. The measurable samples were used for activity recognition model adaptation. Through experiments, the proposed model was proved to be adaptive to new users with excellent recognition performance. Research by Chen et al. (2019) showed that the learning ability of adaptive control (including multi-model adaptive control) was limited, and the continuous excitation conditions were not met in the design of uncertain nonlinear system controllers. Therefore, an improved network control method based on regularized extreme learning, i.e., a nonlinear system machine, was proposed, which compensated for modeling errors and system uncertainty. The model was finally applied to the internal model control of the network control system, and the simulation results showed that the control scheme had excellent tracking performance, control performance, anti-jamming ability, and robustness for nonlinear system.
In summary, the classification of time series is a process of classifying similar objects into one class according to specific rules, and different objects are divided into different classes. In incremental learning, the existing incremental learning algorithms are mostly implemented by decision tree and neural network algorithm, which have the following disadvantages in different degrees. On the one hand, due to the lack of control over the expected risk of the whole sample set, the algorithm is easy to overmatch the training data. On the other hand, the lack of selective forgotten elimination mechanism for training data has dramatically affected the classification accuracy. The unordered time series clustering algorithm has no training process for the original data, and it belongs to unsupervised learning. However, most of the existing fuzzy clustering algorithms are clustering data objects, while studies on segmented series clustering on the timeline are rarely reported. Therefore, it is of considerable significance to study fuzzy clustering based on segmented unordered time series for time series data mining.
The time series fuzzy clustering algorithm based on adaptive incremental learning
The time series fuzzy clustering algorithm
The FCM algorithm is based on the division of a clustering method. The core of this method is to maximize the similarity between objects in the same cluster, while the similarity between different clusters is the smallest [15]. The FCM algorithm is an improvement of the K-means algorithm. The division of the K-means algorithm is hard, while the division of the FCM algorithm is flexible.
The FCM algorithm performs clustering by dividing n vectors xj (1, 2,..., n) into c groups Gj (i = 1, 2,..., c). Its objective function is defined as follows:
In Equation (1), ci represents the cluster center of the i-th group. When J obtains the minimum value, the best clustering result can be obtained.
The membership relation between each sample vector and the final group is represented by a c×n two-dimensional matrix U, where each element is uij, representing the membership relation between the j-th vector and the i-th group. The specific expression is as follows:
The algorithm should meet the following normalization constraints:
The ci that minimizes the Equation (1) can be obtained through the Lagrangian multiplier method:
The target function of FCM algorithm is:
By deriving Equation (7), the necessary conditions for minimizing the Equation (6) are:
In the FCM algorithm, the number of clusters c and the parameter m should be determined in advance. In general, c is much smaller than the total number of samples, and c > 1 should be guaranteed simultaneously. In addition, m is a flexible parameter. For an accurate segmentation result, the value of m must be noticed. If m is too large, it will affect the effect of clustering. If m is too small, the algorithm will approach the K-means clustering algorithm.
A time series is a collection of data collected at different points in time with constant time intervals. These sets are analyzed to understand long-term trends and to predict the future [16]. The output of the algorithm is c cluster center vector and a c×n fuzzy membership matrix. Since the algorithm uses fuzzy method to represent the membership information, the membership matrix can reflect the membership of the sample points more accurately [17]. The cluster center reflects the main features of the category and can also be used as a representative point for the entire category.
Most of the time series analysis methods, including fuzzy clustering algorithms, rely on the choice of distance measurement. When comparing two series, the critical question is the way to deal with the distortion problem, which is also a feature of time series. Ideally, shape-based clustering algorithms classify time series into the same cluster based on shape similarity, rather than amplitude and phase.
Due to the particularity of time series, more researches have focused on the innovation of distance measurement rather than the innovation of fuzzy clustering algorithm. Therefore, time series fuzzy clustering algorithm mainly relies on classical fuzzy clustering algorithm or measures the distance among them after switching them to a time series or converting the time series into appropriate data so that the existing algorithms can be used directly [18]. However, the selection of clustering algorithm affects two aspects: (i) Accuracy. The reason is that each algorithm measures the homogeneity and separation methods differently. (ii) Efficiency. The reason is that the computational complexity between methods is different.
The existing shape-based methods have two significant drawbacks: (i) These methods cannot be extended to large data sets because these methods consume a significant amount of time during computations or distance measurement. (ii) The effectiveness of existing methods is limited to specific areas or data sets. Moreover, these algorithms are not compared with classical methods such as partitioning clustering.
The proposed k-shape method is somewhat like k-means but is significantly different. The k-shape method calculates the cluster core and measures the distance in a different way of k-means. The k-shape tries to preserve the shape of the time series when comparing. Therefore, the k-shape method requires a distance measurement method of invariant transformation [19]. Different from other fuzzy clustering algorithms, k-shape adopts cross-correlation statistical method. Based on the characteristics of cross-correlation, a novel method for calculating cluster core is proposed. The time results showed that the adaptive incremental learning method is superior to ED and is as competitive as the existing limited DTW; however, it runs faster. The k-means method leads to weak performances due to the distance measurement method and the cluster core calculation method. The choice of clustering algorithm is as important as the distance measurement; the k-shape algorithm is better than all scalable methods. Also, it is better than the non-expandable method except for one same performance [20]. However, these methods need to adjust the distance measurement method and are slower than the k-shape method. Therefore, k-shape is a highly accurate and scalable time-series algorithm.
When the time series processes the new samples in the incremental learning process, some samples associated with the original learning result can be selected for operation, and the samples unrelated to the original learning result are discarded. When new samples are added, if the samples that have little effect on the results can be processed, the efficiency can be significantly improved. In specific applications, it is impossible to obtain a complete training sample data set in the early stage of training. Therefore, it is hoped that the machine learning ability can be increased due to the increase in the sample size.
The analysis of time series clustering algorithm
The analysis of time series hierarchical clustering algorithm
The condensed hierarchical clustering is a bottom-up hierarchical clustering. The clustering process first divides each object into a cluster separately; then, according to the distance between objects or clusters, the object with the least similarity according to the aggregation criterion, or the clusters, are merged until all clusters are merged into one cluster, or a termination condition of clustering is satisfied [21]. Most hierarchical clusters belong to the bottom-up hierarchical clustering class. The difference between the algorithms is mostly the calculation method of similarity between clusters and the aggregation rules. As shown in Fig. 1, excellent accuracy can be achieved. Averagely, there is still a considerable difference between the obtained performance although it is a primary data set.
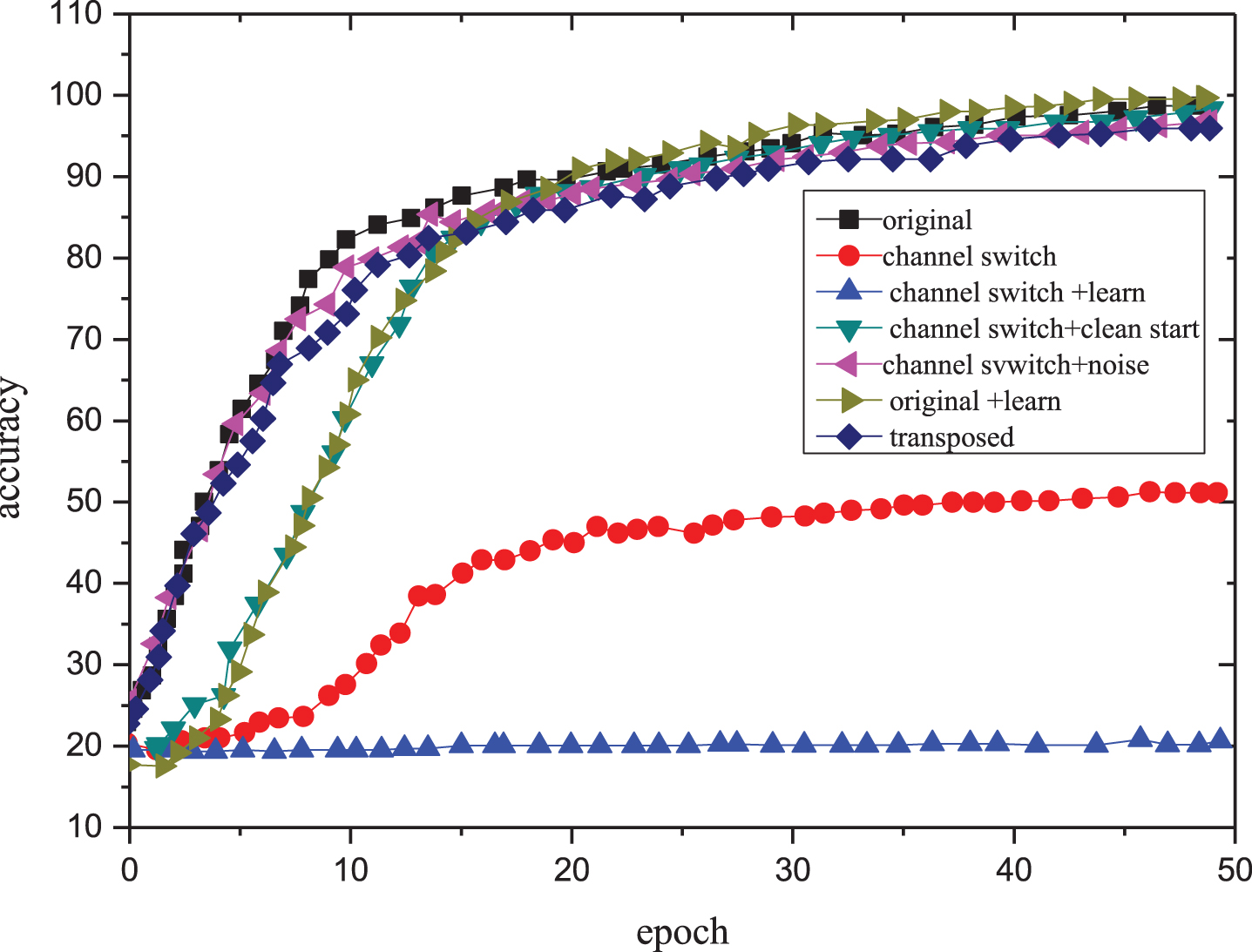
Average performance test of unordered time series fuzzy clustering algorithm for adaptive incremental learning.
The split hierarchical clustering is the opposite of the condensed hierarchical clustering algorithm. First, all the data objects are treated as a cluster; then, the two objects or families with the most considerable distance are continuously divided into multiple clusters according to the distance values until each object is subdivided into a cluster or the cluster meets certain termination conditions. For example, the number of families set in advance is reached, or the distance between any two clusters reaches a set distance threshold.
When hierarchically clustering data sets, the most critical step is to measure the similarity between the two objects. The similarity criterion is different. The distance values calculated by the same object may be completely different. Therefore, the appropriate distance measurement method is the key to the effectiveness of hierarchical clustering, as shown in Fig. 2, the final convergence accuracy of unordered time series fuzzy clustering algorithm of adaptive incremental learning.
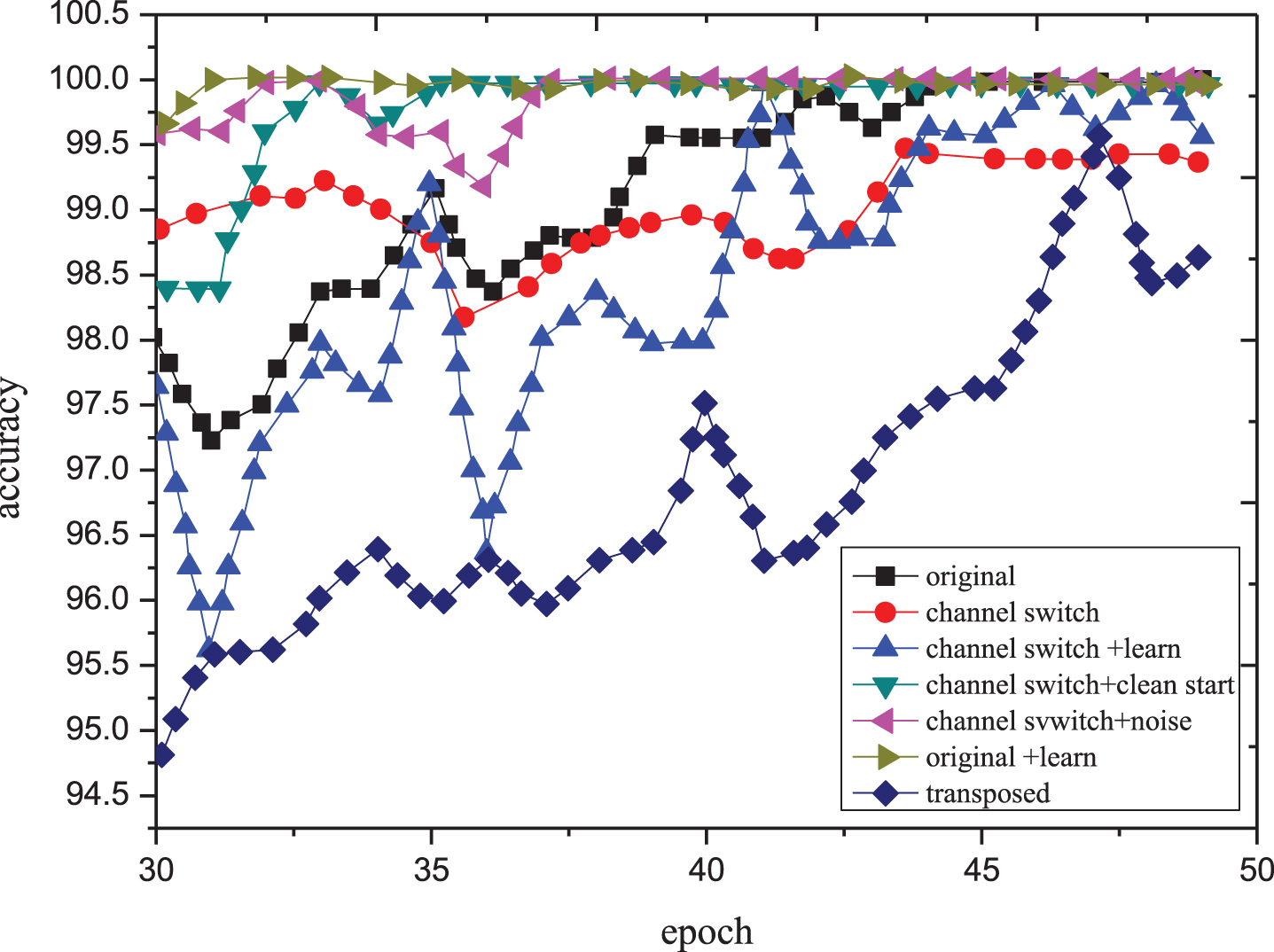
The final convergence accuracy of unordered time series fuzzy clustering algorithm of adaptive incremental learning.
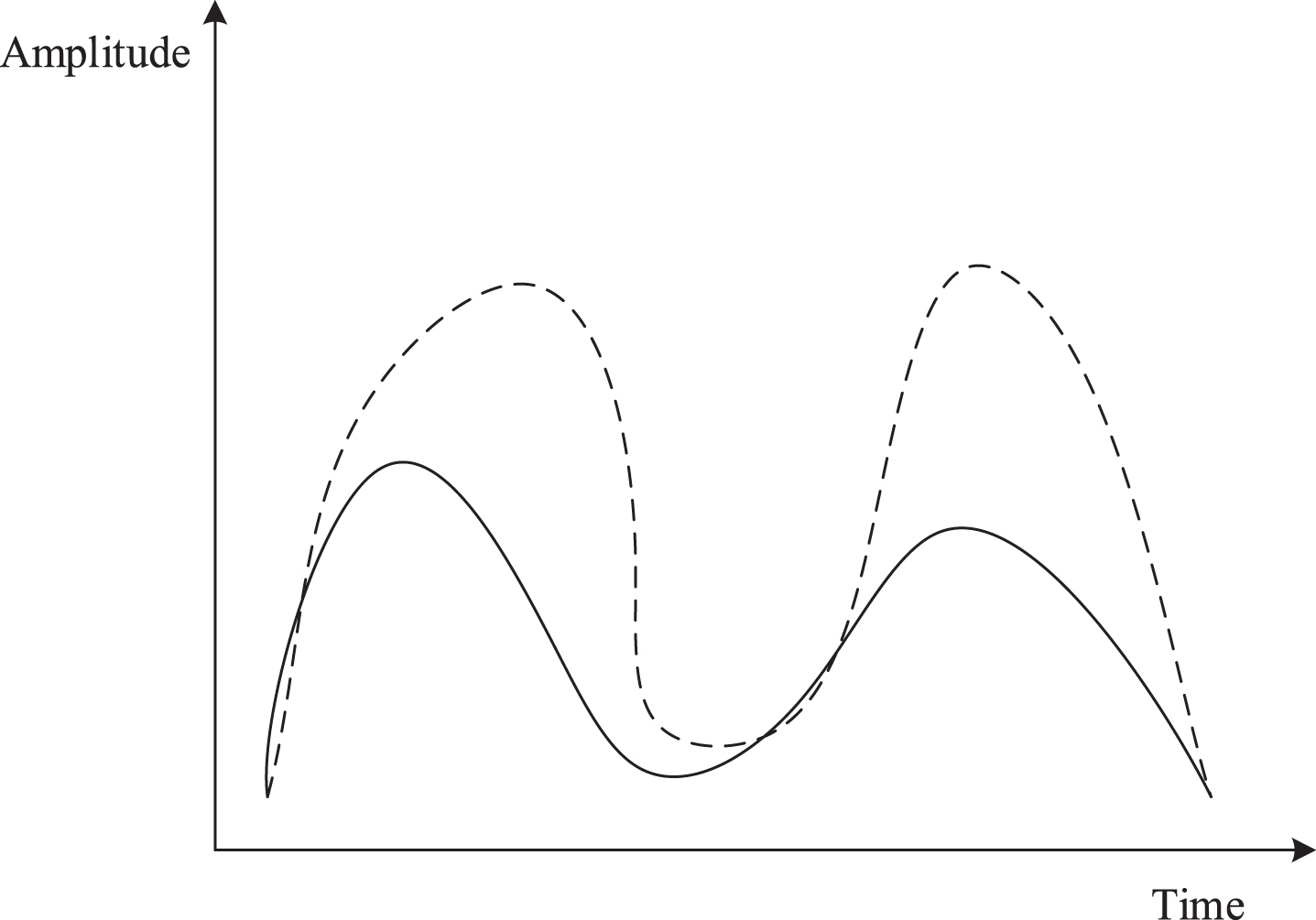
Amplitude difference.
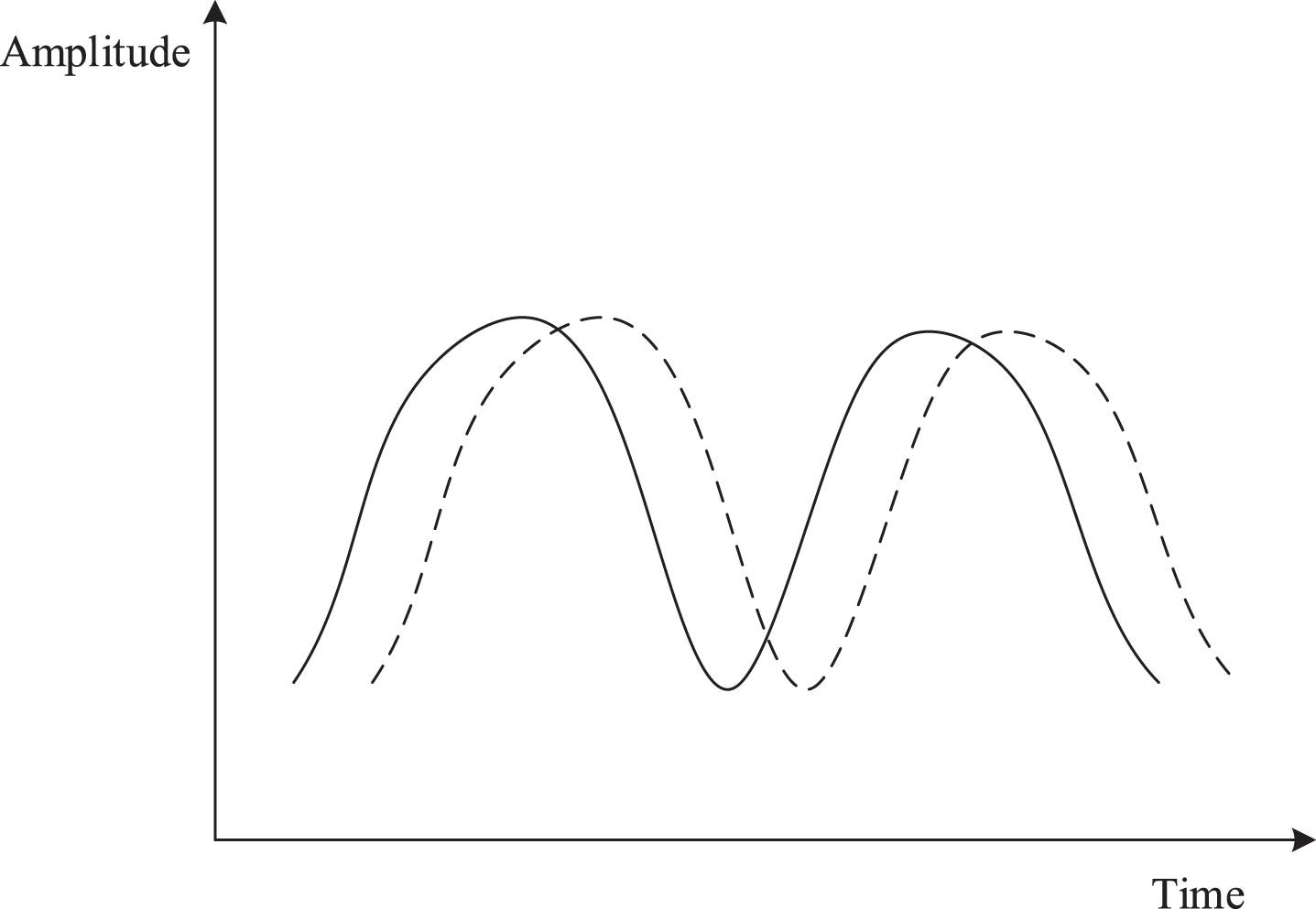
Translation on the timeline.
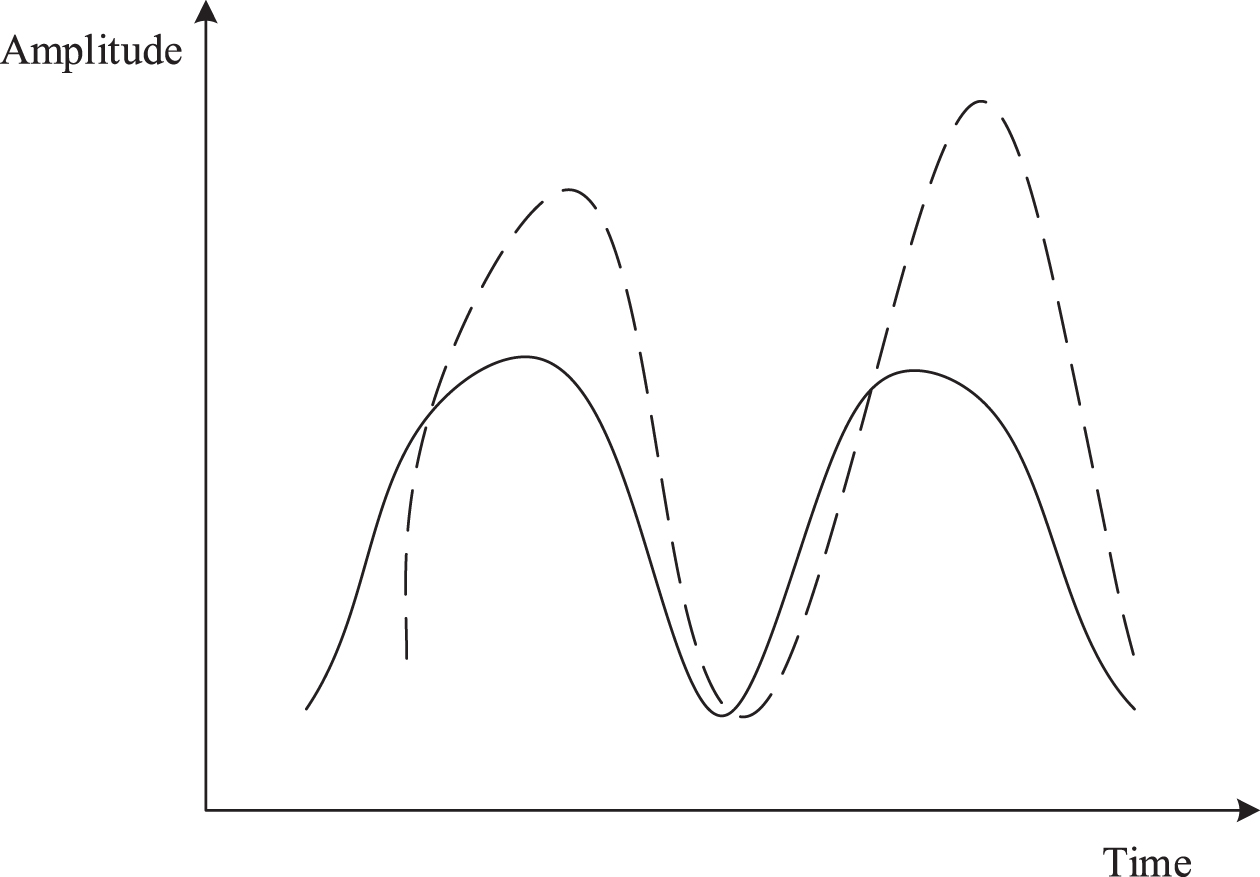
Amplitude and translation.
In the similarity measurement of the series in which the above situation is present, within a specific range, only the shape of the series needs to be considered, instead of the offset or the amplitude difference of the series [23]. The Euclidean distance is calculated by directly calculating the distance between corresponding points on the time axis. This method can only be used to calculate the distance between series of equal length and is sensitive to the stretching and translation of the series. The dynamic time warping described above can effectively deal with these deformation problems when there are amplitude differences, offsets, unequal lengths, or superpositions of several cases. It can effectively obtain the matching precision between series.
A problem exists in many hierarchical clustering algorithms. Compared with the clustering algorithm based on partitioning, hierarchical clustering no longer produces a single cluster but generates a clustering hierarchy, which can generate more clustering results since selecting cluster trees of different “height” will produce different numbers of clusters. The way to choose the most suitable cluster number and obtain the optimal clustering value from many clusters, i.e., how to define the final clustering termination condition, is the key [24, 25]. Since in the hierarchical clustering, the clustering result of each layer is determined by the corresponding number of thresholds, i.e., the clustering termination condition is determined.
In this study, the termination conditions of clustering are obtained by detecting the changes in the number of isolated series, and the symbols shown in Table 1 will be used.
Symbols and implications
Symbols and implications
If DND(a)>Do, the series a is defined as an isolated series. As shown in Table 1, DND(a) is the DTW distance of the series closest to the series a and the distance a, while Do is the threshold of the isolated series and the non-isolated series. If the Do value decreases, the number of isolated series will increase. If Do decreases to a specific value, the number of isolated series will increase sharply, and Δ No will reach the peak, indicating that there are more Do-similar series in this segment. Thus, the value of Do is continued to reduce, and the value of Δ No will decrease.
Since the peak value of Δ No indicates that the isolated series grows fastest in the distance increment between the isolated series and the non-isolated series, the similarity between the series is higher at this time; thus, the Do before the Δ No peak can be selected as the termination judgment threshold of the hierarchical clustering algorithm [26]. It is assumed that the Δ No value reaches the first peak in the i-th cycle, and the program detects that the Δ No value decreases in the i + 1th cycle. At this time, Do has decreased to the i + 2th cycle. The value of the threshold is judged as the value of Do at the i-1 cycle before the peak value, so:
In the condensed hierarchical clustering algorithm, a single object is used as the initial cluster, and the nearest cluster is gradually aggregated until the target cluster number is obtained. The previous content describes four methods of distance measurement between clusters, i.e., minimum distance, maximum distance, average distance, and average distance. The improved clustering algorithm adopts the minimum distance, i.e., the minimum value of the distance between objects in the two clusters is selected as the clustering criterion.
In the actual database, for adaptive incremental learning algorithm, the amount of data tends to increase gradually. Therefore, in terms of the new data, the learning method should be able to make specific changes to the trained system, thereby learning the knowledge contained in the new data.
In this study, the unordered time series fuzzy clustering of adaptive incremental learning is realized by the improvement of hierarchical clustering. The traditional Euclidean distance-based metrics in hierarchical clustering do not support the existence of stretching, translation, and unequal time series. The distance metric is therefore improved by updating the distance matrix approach to updating the distance matrix based on the DTW metric. In addition, hierarchical clustering does not support clustering of large-scale datasets due to its high complexity. Therefore, the updating method of the distance matrix of hierarchical clustering is further improved to reduce the time complexity of clustering, as well as improving the performance of the algorithm. In addition, the time series fuzzy clustering algorithm is studied in the analysis of time series. Since the analysis of the time series is ultimately for the prediction decision of the disordered time series, the analysis effect before the prediction is of considerable significance to the prediction result. Although this study has achieved specific results in researching the fuzzy clustering of time series, with the deepening of research, the related work needs to be improved in further. The proposed improved hierarchical clustering algorithm based on DTW distance metrics is in conformity with the minimum distance metric method. Other distance metrics need to be studied further for the improvement of time complexity of hierarchical clustering.
Funding
Supported by “National Key R&D Plan”: 2018YFB0605504 Supported by “the Fundamental Research Funds for the Central Universities”: JB2019078