
Abstract
Digital creativity is creative expression derived from cultural creativity and information technology. In order to overcome the problem in the creative generation in the condition of fuzzy and uncertain ideas, an automatic generation method of cross-modal fuzzy creativity (AGMCFC) is proposed. In this subject, fuzzy creative data sets and learning retrieval network are constructed for the sake of extracting original creative data effectively. And the logical correlations between creative objects are acquired dynamically based on the graph neural network. Creative objects and creative styles are generated by using generative adversarial nets technology and style transfer technology, respectively. Then, the projectiles, boundary markers and location words of the creative scene objects are generated by analyzing related attributes of each entity. After adjusting the layout, creative works are automatically generated. A fuzzy creative generating environment is implemented. Experimental results show that the screened number of AGMCFC method is about twice as much as that of manual method, and the accuracy rate of AGMCFC method is improved compared with the manual method. AGMCFC method performs well at creative generation of fuzzy ideas automatically.
Introduction
Fuzzy theory is used to analyze and deal with many problems in the real world. It can be divided into fuzzy mathematics, fuzzy system [4], uncertainty and information, fuzzy decision [22], fuzzy logic and artificial intelligence [1]. Fuzzy theory has been applied in Internet of Vehicles (IoV) [2], ammunitions consumption prediction [11], mechanical and electrical manufacturing [19], expert system [21], data mining [12] and many other fields. The automatic generation of digital creativity is an integrative application of fuzzy system, fuzzy logic and artificial intelligence of fuzzy theory in creativity generation.
Digital creation, as a specific digital simulation, utilizes computers to simulate the human brain to build ideas [17]. It is a new economic form produced by the integration of information technology and cultural creativity. Digital creativity is mainly based on modern digital technologies such as computer graphics, which is different from traditional cultural creativity that treats entity as the vehicle for artistic creation. The overall framework of the digital creative process consists of four layers: motivation, conception, generation and evaluation. These layers are connected closely. Therefore, when the creative idea is fuzzy or uncertain, how to generate digital creative works becomes a complex and difficult problem that fuzzy systems need to be solved. In recent years, many new technologies and methods of digital creativity have emerged, such as Long Short Term Memory (LSTM), Generative Adversarial Networks (GANs) [16], Style Transfer (ST) [25] and so on, which are applied in painting, literature, music, stage and other creative fields. LSTM is used for generating literature works with similar styles, and composing music. GANs is used for generating similar image works and series frames in the movie. ST is used for generating object style. However, all these methods are coarse-grained creative generation or only partial creative generation. These methods do not study the generation process of creative works systematically and completely, therefore, the creative works that generated by these methods are often unable to meet the needs of fuzzy creativity.
Causal reasoning is particularly important for the universal creative process of digital creativity, so the logical correlation between objects should be considered in the process of extracting creative objects and constructing creative works. General machine learning methods (such as deep learning) can only carry out object feature learning, and cannot perform well in logical analysis. However, Graph Neural Network (GNN) defines a class of relational reasoning functions for graphical structure representation as its framework structure, which is suitable for the research foundation of this aspect [20]. GNNs have been explored in many problem areas, including supervised learning tasks, semi-supervised learning tasks, and unsupervised learning tasks. It can be simply divided into three application scenarios [15]: (1) structured scenario, where the data has a clear relationship structure, such as physical system, molecular structure and knowledge graph; (2) unstructured scene, where the relationship structure is not clear, including images, text, etc.; (3) other application scenarios, such as generation model and combinatorial optimization problems. GNN framework structure includes graph neural networks, Modified Probabilistic Neural Network (MPNN) and Non-Linear Neural Network (NLNN), etc. It supports to build complex structures from simple Building Blocks (BB), which is exactly what fuzzy creativity needs to be automatically generated. The automatic generation of fuzzy creativity with the characteristics of self-organization, emergence and self-coordination seems complicated, but strong artificial intelligence technologies with causal reasoning can simulate and support the implementation process, making digital creativity follow rules.
An Automatic Generation Method of Cross-modal Fuzzy Creativity (AGMCFC) based on GNN is proposed. During the proposed method, the GNN is used to calculate the correlation between data labels, the fuzzy logic relations are deduced between various objects, and the position and layout of creative works are given. Then an automatic generator of cross-modal fuzzy creativity is generated.
The frame model of the whole universal creativity generation process
Aiming at the creative process of digital creativity, a frame model of the whole universal creativity generation process is proposed (as shown in Fig. 1).

The framework of the universal creativity generation process.
The specific steps of the framework model are described below. The cross-modal multi-label fuzzy creative data sets are constructed on the basis of word segmentation and information extraction from texts and images of the key creativity. The image data can be acquired from the Internet or the database, and also can be collected from the latest image samples by wireless sensor network at any time. In order to speed down the energy consumption of the sensors near the sink, α-fraction first strategy for hierarchical model [14] in wireless sensor networks is used. The lifetime of the sensor network is extended, then more image samples are collected. Based on the cross-modal multi-label fuzzy creative data sets, a cross-modal learning and retrieval network model is built to facilitate the classification and retrieval of image data. A graph neural network is established to analyze the logical relationship between objects. The correlation between multiple tags is calculated by using GNN and tag semantics, and then the logical relationship between objects in the same mode is deduced. Creative objects and creative styles are generated. GANs technology is adopted to generate the relevant creative objects if there is no suitable object in the material library. ST technology is adopted to generate the texture of the objects if the texture of the current image does not meet the requirements. Projective bodies, bound scripts and localizers of creative scene objects are achieved from the related attributes of each entity in the GNN, making the spatial layout of creative entities conform to the logic of realistic placement. In order to ensure the security of the generated creative works, some encryption technologies [13] and [23] can be considered to encrypt them. An EEG evaluation model based on deep learning [6] is adopted to assess the effectiveness of creativity generation.
Now, the key technologies involved in the implementation process will be analyzed and discussed in detail.
Construction of cross-modal multi-label fuzzy creative data sets and learning retrieval network
Construction of cross-modal multi-label fuzzy creative data sets
Texts and images of real-life or database are automatically collected and extracted. Due to the instability of data storage and communication transmission, some encryption techniques have been adopted to ensure that they are protected from malicious attacks. In particular, the three-party password-based authenticated key exchange technology can ensure the security in an offline environment [3]. In order to solve the problems of data space heterogeneous and semantic association of the text and image data, it is necessary to construct unified cross-modal multi-label fuzzy creative data sets. The data sets are divided into artistic conception library, object library, style paste gallery and so on.
The data sets are multi-labeled, and it is expressed as Equation (1).
The creative ontology domain consists of three parts: entities, attributes and relationships. Suppose there are M entities, N attributes and T connections in the creative ontology domain. Then, X entity ={ X1, X2, …, X M }, Y attribute ={ Y1, Y2, …, Y N }, Z relationship ={ Z1, Z2, …, Z T }.
For text-image cross-modal data objects, an entity represents an object with attributes such as name, color, emotion, and so on. Many entities constitutes cross-modal multi-label fuzzy creative data sets, as Datasetcross-mode in Equation (1). Each Entity has its own global properties, as Datasetlabel-mode in Equation (1). A relationship is a common property of two entities, as Map in Equation (1), such as above ... , growing in.., located at ... , and so on. A regular function is a function used to map entities or relationships, as Map in Equation (1), which takes one or two parameters and returns an attribute value.
We assume that X entity is traversed. ∀X i ∈ X entity , the target network resource is crawled, then the image data set L and the label set K related to X i are obtained. Crawler technology is used to automatically crawl labeled image data to expand the current creativity data set according to the entities and attributes of the creative ontology domain (as shown in Fig. 2).

Construction of multi-label fuzzy creative data sets.
The attributes related to the object are extracted from the labels of the image, and the similarity and correlation of the attributes are calculated. We take the property closest to the entity in the ontology domain as the outer label of the object, and take the original tag of the object as the inner tag. Tagging is essentially to classify the object accordingly. L is added as the ith element in Datasetimage-mode. K is added as the ith element in Datasetlabel-mode. In this way, the (Map)
i
corresponding to the current element in the Map can be expressed as the mapping relationship between L and K, which is
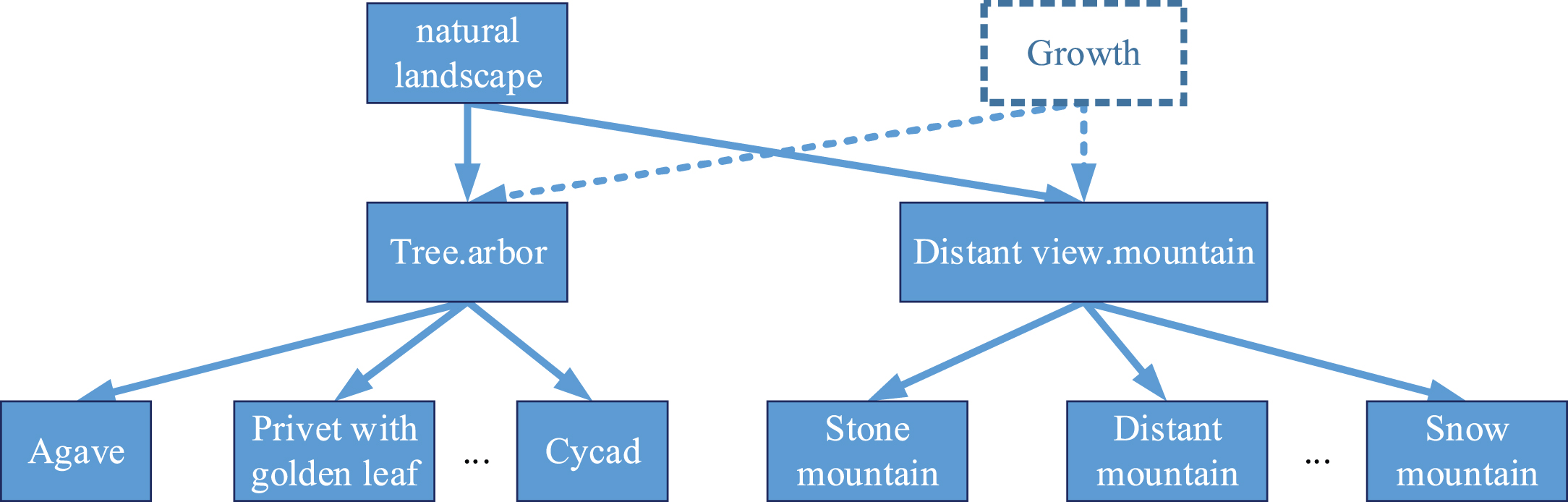
Construction of hierarchical multi-label graph network structure.
The deep network of each image is introduced to learn feature representation better. The classifier is constructed for each image, where the optimization target is punished by the dependency of label. Firstly, the weights of the deep network are trained in advance by contrast divergence method [5], and the weights of the classifier are randomly initialized. Then, the back propagation method is used to train both the deep network and the classifier. After training, an image can predict the labels of test samples by the output mean of its classifier. A cross-modal learning retrieval network is constructed as shown in Fig. 4.
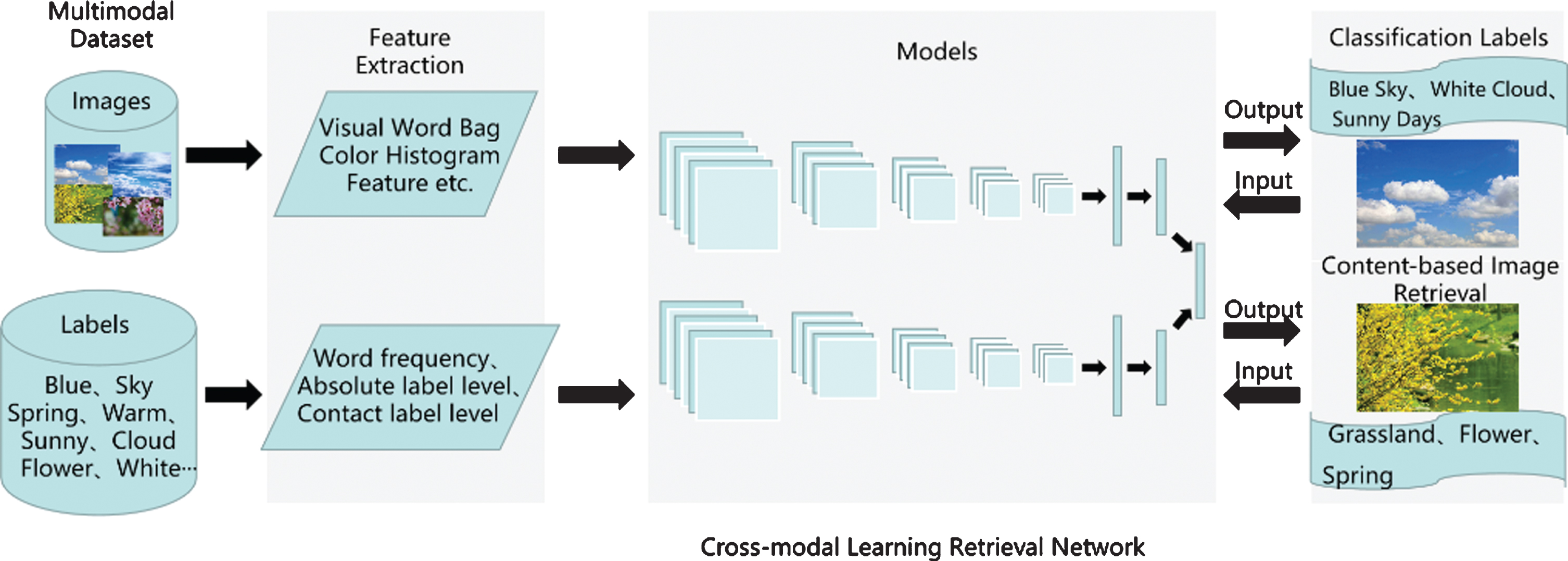
Construction of cross-modal learning retrieval network.
GNN constructs its architecture through logically reason functions of directed graph structures. GNN framework uses simple Building Blocks (BB) to construct complex structures and describes the process of fuzzy logic reasoning. As a Graph, each entity consists of three aspects: nodes, global attributes, and edge relations. A node is represented as v
i
, a Global Attributes (GA) is represented as u, and an edge is represented as e
k
. A sender node index and a receiver node index are represented as s
k
and r
k
, respectively. Then, A Graph is defined as a triple, as shown in Equation (2).
In the process of fuzzy creative automatic generation, the construction of cross-modal multi-label fuzzy creative data sets is the premise and basis of logic reasoning in GNN. Appropriate image data is selected to generate digital creative in their logical order.
This is illustrated by a picture of landscape. V = { v i } i=1:N v is represented as a collection of nodes, where v i is represented as an attribute of the node. If V is a mountain, v i may be location, color, snow and other attributes. If V is a river or lake, v i may be location, color, width, wave height and other attributes. u is represented as global attributes, such as altitude, depth, and so on. E = { (e k , r k , s k ) } k=1:N e is represented as edges, where e k is represented as an attribute of the edge, r k is represented as the receiver node index, and s k is represented as the sender node index. E may be the relationship between different objects, such as spatial relations, the projectiles, boundary markers and location words, and so on. Table 1 shows steps of computation in a full GNN block.
The GNN block calculation steps
A GNN block include three update functions ∅ and three aggregation functions ρ, as shown in Equation (3).
Then, all edges and nodes related to the graph neural network can be easily traversed and updated according to Equation (3).
In fact, the process of traversing and updating the edges and nodes of the graph neural network is to complete sequential extraction of material objects required for creative works and determination of logical correlations between objects.
At the creative stage, GANs technology is adopted to generate creative objects, and ST technology is adopted to generate creative styles. The stage scene is taken as an example to illustrate its generation process, and its principle can also be extended to other types of creative works.
GANs was first proposed by Ian Goodfellow. It extends existing neural networks for processing data represented in graph domains. Based on the idea of game theory, GANs consists of two networks, a generator and a discriminator [10]. The generator is trained to fool discriminators into producing realistic images, and the discriminator is trained not to be fooled by the generator. First, the generator extracts a noise vector Z through a simple distribution (such as a normal distribution), and upsample this vector to generate the image. In the initial loop, the images look very noisy. Then, the discriminator gets the true and false images and learns to recognize them. Subsequently, the generator receives feedback from the discriminator based on Backpropagation Algorithm, and gradually performs better in the generation of images. Finally, the distribution of the false image is as close to the true image as possible. In other words, fake images are expected to look as real as possible. The main GANs algorithm is shown in Equation (4).
After selecting the creative objects or generating the desired creative objects, the desired styles of objects are generated based on ST. The generating principle of ST is to input a white noise image and generate a style image based on it. A content image and a style image are fused based on ST to generate an output image that retains the original content and the style [18]. In other words, the main idea is to give a content object and a style map for fusion generation, and then to introduce a certain style while keeping the content unchanged.
The style-generating framework is divided into two parts, one is the Image Transform Net (ITN) T, and the other is the pre-trained Loss Network (LN) vgg - 16 (as shown in Fig. 5). T takes the content image x as input, and outputs the image y′ after style transfer. Then, content-based image yc (that is x), style-based image ys and the image y′ input the computing characteristics of vgg - 16 [7]. The loss calculation is shown below.
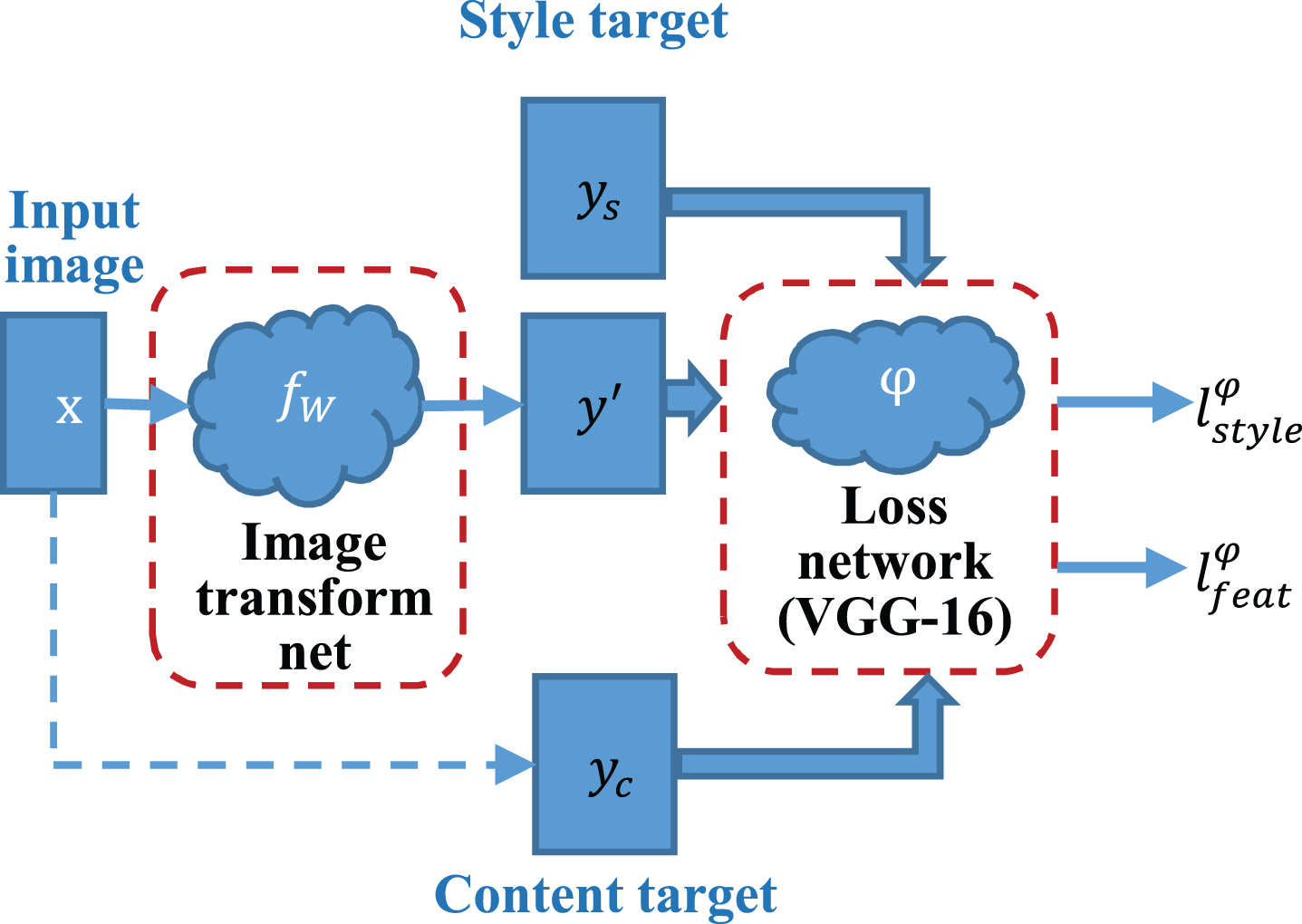
The network framework diagram of style-generating.
Content loss calculation function
Perceived loss calculation function
Total loss calculation function
The placement sequence of scene objects in a creative work
After the construction of the GNN, the order of objects in the creation work has been determined. Relevant attributes between nodes are extracted from the sender to the receiver. However, it may not specify the relationship between entities in the creative point, so the information of this part needs to be supplemented. A generation sequence model is proposed between objects to supplement this missing information. The generation process of virtual creative scenes is the same as the order of scene construction in real life, which follows the principle from bottom to top. The sequence of construction is laying foundations, covering vegetation, placing buildings, placing everyday tools, and finally placing people and animals. Basic placement sequence model is shown in Fig. 6.
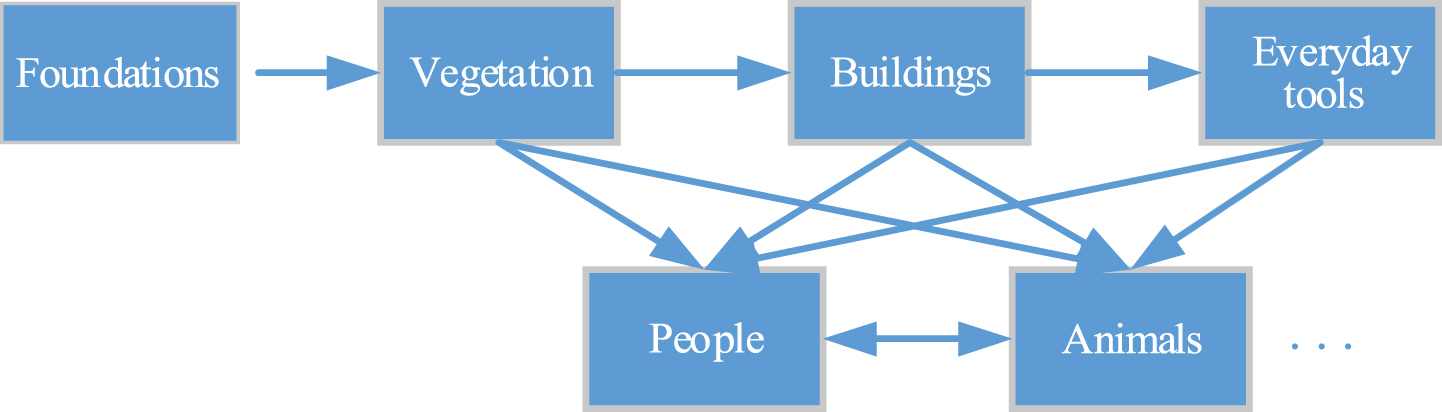
Basic placement sequence model of scene objects.
In the GNN, after global information is extracted, a basic composition method or a combination of multiple local composition methods is need for the creative works if the layout and composition of creative works is not obtained. The common basic composition methods include pyramid composition method, S shape composition method, diagonal composition method, cross composition method, lateral composition method, full composition method, symmetrical composition method, et al.
Now, an example of “bridges, rivers and houses” is given to explain the creative works generation process. After global information extraction is completed in GNN, if the lack of layout and composition information is found, the corresponding layout and composition information is added to it. Bridges should be above rivers, and the people should be above bridges. These two arrangements follow the pyramid composition method (that is to set large models under small models). Houses should be next to rivers based on both pyramid composition method and lateral composition method. This layout conforms to the logic of real life placement.
The modular script description of fuzzy creative generation process
A graph neural network is constructed based on creative points, and each node and its related attributes are extracted according to the direction of its edges to determine the logical relationship between entities. The modular script description of fuzzy creative generation process is shown in Fig. 7. The function of each model is described below. Model Searcher: Each entity of the creative node in GNN is traversed. And a < model classification table > is preset. The model files are traversed and compared that conform to relevant attributes imported from the model library of the data sets. After that, the existing models are recorded and the number of the models is counted. At the same time, all recorded model positions are cleared (0, 0, 0). Then, a < model asset table > is generated. Model Classifier: The model names of the preset < model classification table > are compared with those of the < model asset table > which is generated by the model searcher. Then, a < asset classification table > is generated. Model Collision Detector: The model collision detector is used to detect whether two models are interspersed or collided in the simulation world of fuzzy creativity generation. Composition Method Selector: Composition method selector is used to call composition methods according to the actual creative scene. These composition methods include pyramid composition method, S shape composition method and so on. Creative Scene Arranger: The models selected from the < asset classification table > are arranged according to the construction principle (as shown in Fig. 6). If a model is used, it is recorded in < model arrange table > to count the arranged models.
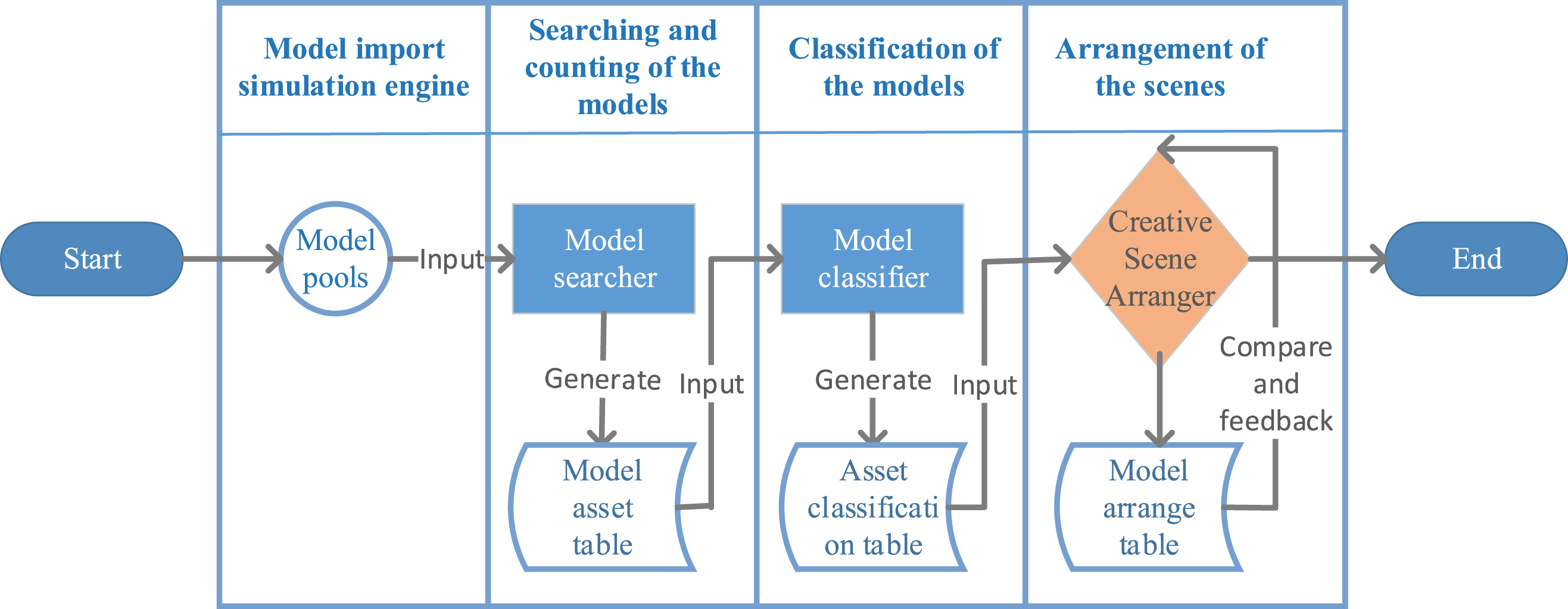
Modular script description of fuzzy creative generation process.
When placing objects, the projectiles, boundary markers and location words [8, 24] of the generated creative scene objects are analyzed by GNN, so as to adjust the appropriate position to complete the composition. If there is no specific boundary mark or location word in the attributes, based on the direction of the edges in GNN, set the boundary mark and location word of the corresponding object to complete the creative scene composition according to the given basic scene object composition order and composition method. The creative scene arranging process without boundary mark of location word in the attributes is shown in Fig. 8.
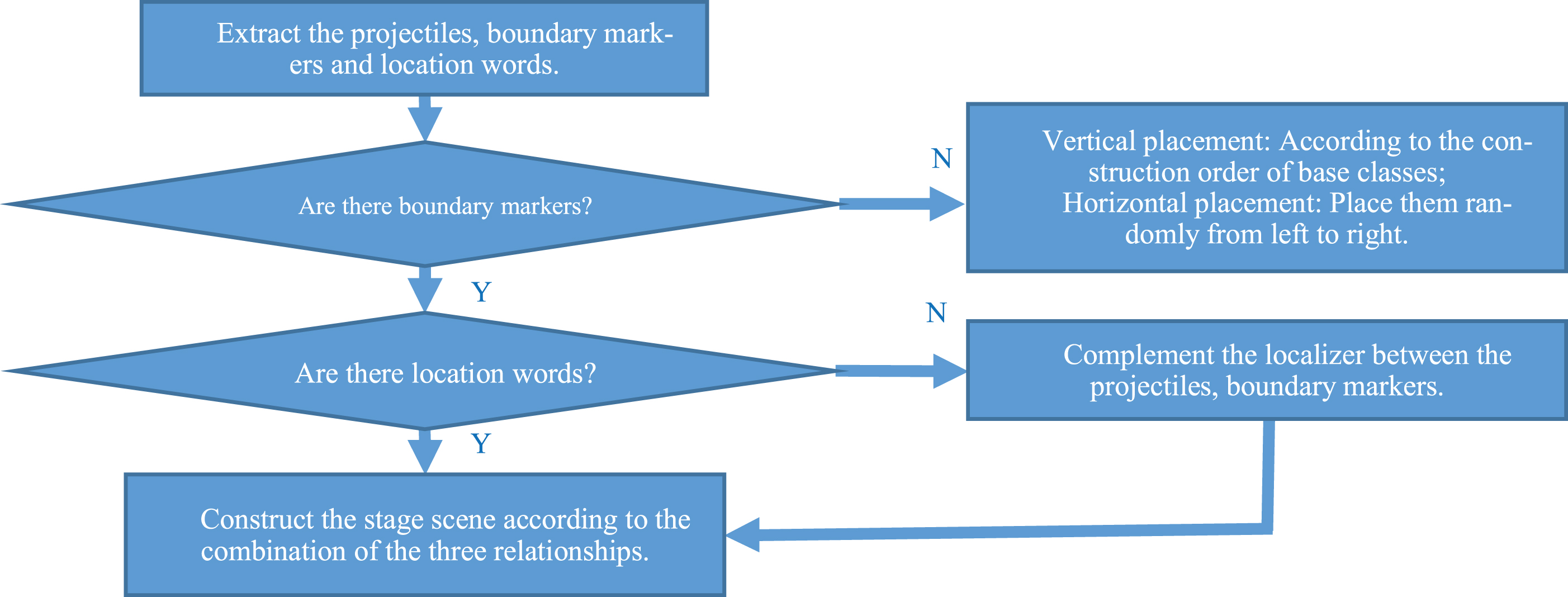
The creative scene arranging process without boundary mark of location word in the attributes.
A creativity generation environment is designed and implemented. In this environment, cross-modal digital creativity can be generated for text and image data. Besides, the performance of the proposed AGMCFC method is compared with that of the manual method.
Implementation of fuzzy creative generating environment
Description of experimental data: 15 creative points that meet the needs are extracted from 100 creative points. After word segmentation, 256 related words including entities, attributes and relationships are obtained. There are 66 entity words, 90 attribute words and 100 relationship words. Based on these entity words and attribute words, relevant document data and image data are collected. Meanwhile label data are extracted through the document data. Now, multi-label fuzzy creative data sets are constructed. Examples of multi-label fuzzy creative data sets are shown in Table 2.
Examples of cross-modal multi-label fuzzy creative data sets
Examples of cross-modal multi-label fuzzy creative data sets
The fuzzy creative generating environment is designed and implemented. Based on GNN, the logical relationship between creative objects are obtained, then related objects are extracted. The required creative works are constructed based on projective bodies, bound scripts and localizers of the creative point. GANs technology [16] and ST technology [25] are used to achieve object generation and Style generation, respectively. Finally, satisfactory creative works are screened by the EEG evaluation model [6]. The EEG evaluation model is computable. Hence, the whole process of the proposed AGMCFC is computable. An example of fuzzy creative generation process is shown in Fig. 9.
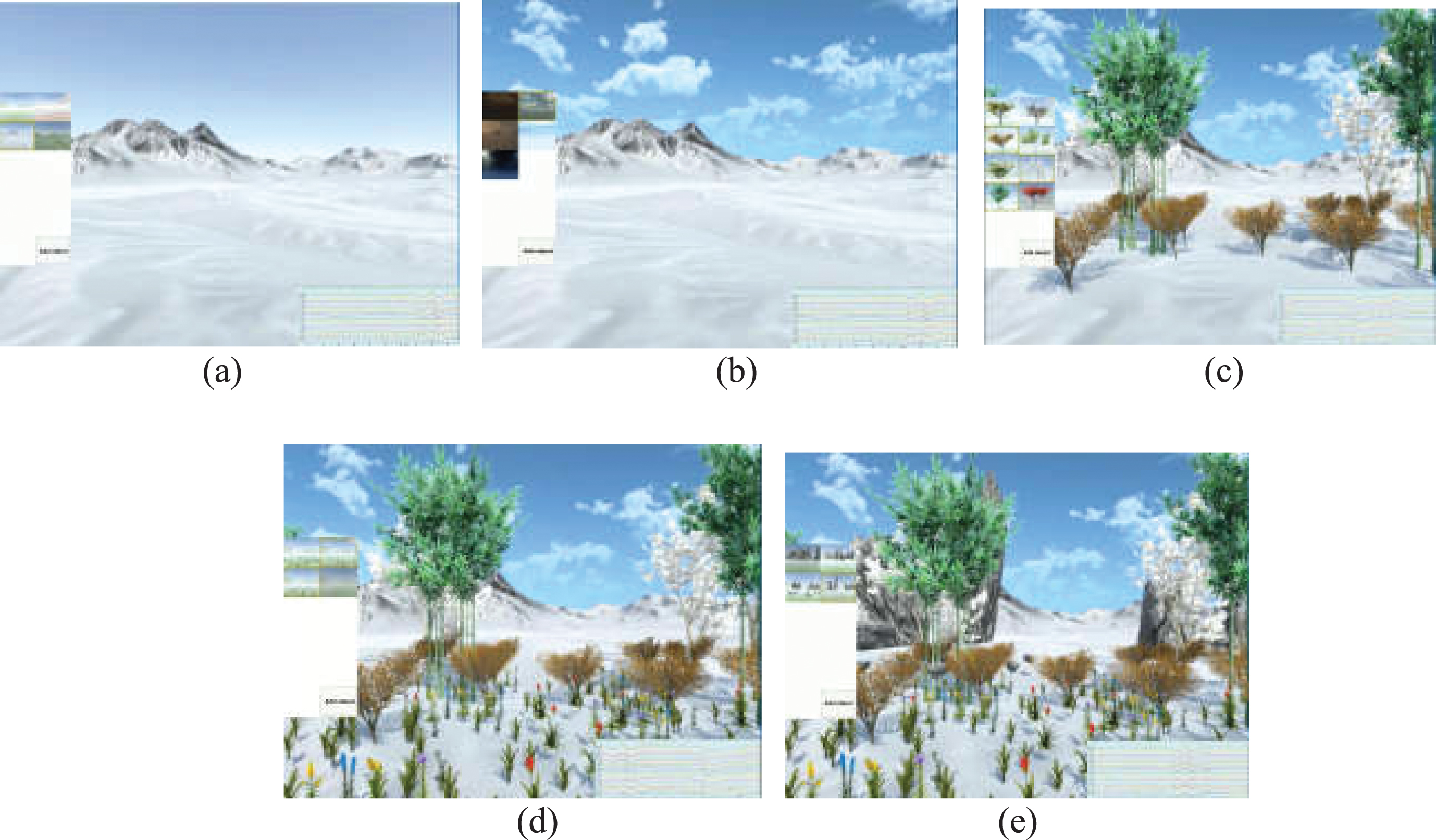
An example of fuzzy creative generating environment: (a) add a scene; (b) add a sky; (c) add trees; (d) add flowers and plants; (e) add stones.
In order to test the performance of the proposed AGMCFC method, it is compared with manual method at different periods, as shown in Fig. 10.
In Figure 10, the screened number of creative works of the proposed AGMCFC method is significantly larger than that of manual method in unit time. It is about twice as much as that of manual method. The AGMCFC method integrates information technologies with cultural creativity to solve the problem of low efficiency of traditional manual method, therefore, the generation efficiency of AGMCFC method is higher than that of manual algorithm in unit time. AGMCFC method avoids the semantic gap of object extraction by labeling multi-label semantics on each object, so as to achieve relatively accurate extraction. AGMCFC method solves the problem of inaccurate extraction to a large extent. Besides, the accuracy rates of creative generation of AGMCFC method at any time are all above 90% and the accuracy rate of AGMCFC method on average is 9.6% higher than that of manual method. Especially at Time 4 (affected by external interference), the accuracy rate of the proposed AGMCFC method is nearly 20% higher than that of manual method, which demonstrates the feasibility of replacing manual method with AGMCFC method. Hence, the AGMCFC method performs well at creative generation of fuzzy ideas automatically.
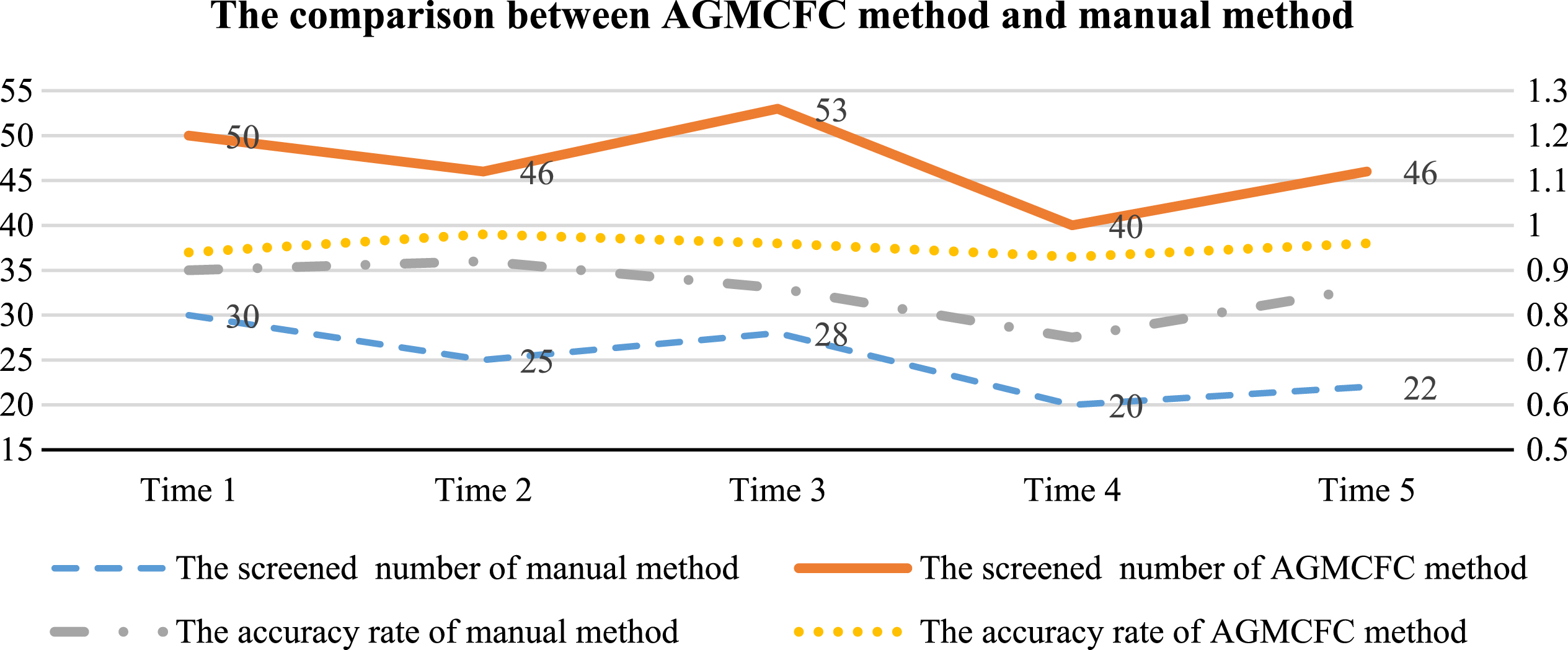
Comparison between AGMCFC method and manual method.
An automatic generation method of cross-modal fuzzy creativity is proposed. The logical correlation between objects is calculated by the proposed AGMCFC method based on GNN. The AGMCFC method realizes the automatic generation of creativity under the condition of fuzzy ideas to some extent. It is convenient to extract cross-modal creative objects on the basis of constructing of multi-label fuzzy creative data sets and learning retrieval network. GANs technology and ST technology are used to achieve object generation and style generation, respectively. The spatial layout of creative entities of the AGMCFC method conforms to the logic of realistic placement. Experimental results show that the efficiency and the accuracy of the AGMCFC method are significantly higher than that of the manual method. AGMCFC method can generate satisfactory creative works in the case of fuzzy or uncertain ideas, which demonstrates the feasibility of replacing manual method with AGMCFC method.
Footnotes
Acknowledgments
To the Research Program Foundation of Minjiang University (Grant No. MYK17021), the National Natural Science Foundation of China (Grant No. 61772254), and Beijing Finance Project (Grant No. PXM2019_178214_000004) for their support.